Cours
Introduction à R
4 h
3M
Dans ce tutoriel, nous allons visualiser des distributions de données en traçant des histogrammes à l'aide du langage de programmation R. Nous verrons ce qu'est un histogramme, comment lire des données dans R, comment créer un histogramme et comment personnaliser le tracé.
Nous utiliserons le langage de programmation de base R sans aucun autre package. Cette approche est particulièrement utile lorsqu'il n'est pas possible d'utiliser d'autres logiciels ou lorsque vous souhaitez effectuer des analyses exploratoires rapides. Dans d'autres cas, vous pouvez envisager d'utiliser ggplot2, comme indiqué dans notre tutoriel How to Make a ggplot2 Histogram in R (Comment faire un histogramme avec ggplot2 dans R).
Pour exécuter facilement vous-même tous les exemples de code de ce tutoriel, vous pouvez créer gratuitement un classeur DataLab dans lequel R est préinstallé et qui contient tous les exemples de code. Pour en savoir plus sur la création d'un histogramme dans R, consultez cet exercice pratique de DataCamp.
Un histogramme est un graphique très populaire utilisé pour montrer les distributions de fréquence des variables continues (numériques). Les histogrammes nous permettent de voir le nombre d'observations dans les données à l'intérieur des plages que la variable couvre.
Les histogrammes ressemblent à des diagrammes à barres. Une différence essentielle entre les deux est que les diagrammes en bâtons ont une valeur associée à une catégorie spécifique ou à une variable discrète, alors qu'un histogramme visualise des fréquences pour des variables continues.
Nous utiliserons cet ensemble de données sur le logement qui comprend des détails sur différentes listes de maisons, y compris la taille de la maison, le nombre de pièces, le prix et des informations sur l'emplacement. Nous pouvons lire les données à l'aide de la fonction read.csv(), soit directement à partir de l'URL, soit en téléchargeant le fichier csv dans un répertoire et en le lisant à partir de notre stockage local. Nous pouvons également spécifier que nous ne voulons stocker que les colonnes qui nous intéressent dans le cadre de ce tutoriel : le prix et la condition.
home_data <- read.csv("https://raw.githubusercontent.com/rashida048/Datasets/master/home_data.csv")[ ,c('price', 'condition')]Examinons les premières lignes de données à l'aide de la fonction head().
head(home_data, 5)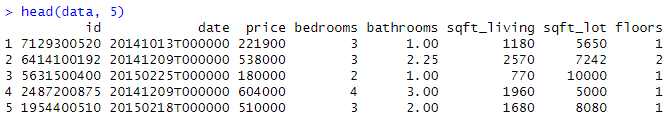
Ensuite, nous allons créer un histogramme à l'aide de la fonction hist() afin d'examiner la distribution des prix dans notre ensemble de données.
hist(home_data$price)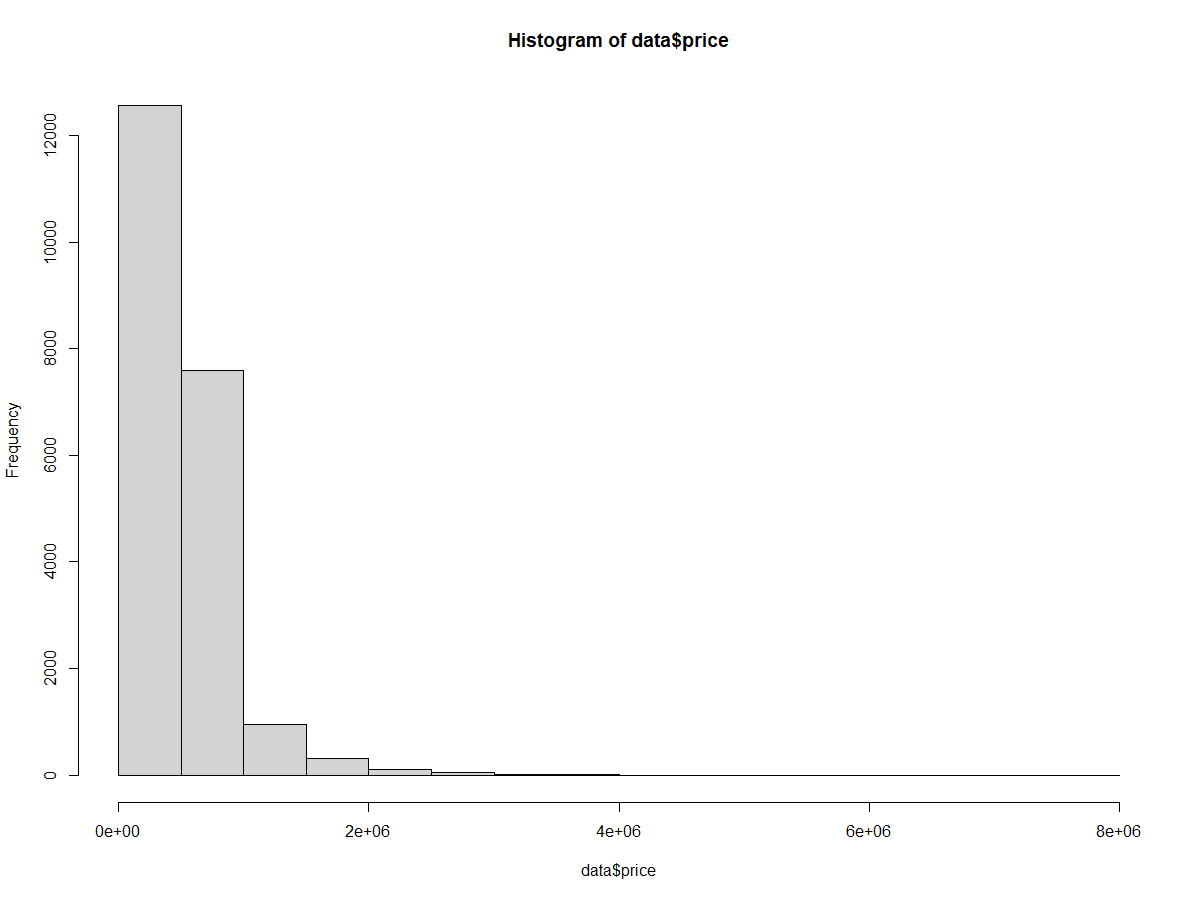
Histogramme de base des prix de l'immobilier. Image par l'auteur.
Nous pouvons ajouter des statistiques descriptives à l'histogramme à l'aide de la fonction abline(). Cela ajoute une ligne verticale au tracé.
v à la position de la ligne verticale sur l'axe des x. Ici, nous obtenons le prix moyen des maisons en utilisant mean().col définit la couleur de la ligne, dans ce cas-ci en rouge.lwd définit la largeur de la ligne. Une valeur de 3 augmente l'épaisseur de la ligne pour la rendre plus facile à voir.hist(home_data$price)
abline(v = mean(home_data$price), col='red', lwd = 3)Pour ajouter une ligne de densité de probabilité à l'histogramme, nous modifions d'abord l'axe des ordonnées pour qu'il soit mis à l'échelle de la densité. Dans l'appel à hist(), nous fixons l'argument probability à TRUE.
La ligne de densité de probabilité est obtenue par une combinaison de density(), qui calcule la position de la courbe de densité de probabilité, et de lines(), qui ajoute la ligne au tracé existant.
hist(home_data$price, probability = TRUE)
abline(v = mean(home_data$price), col='red', lwd = 3)
lines(density(home_data$price), col = 'green', lwd = 3)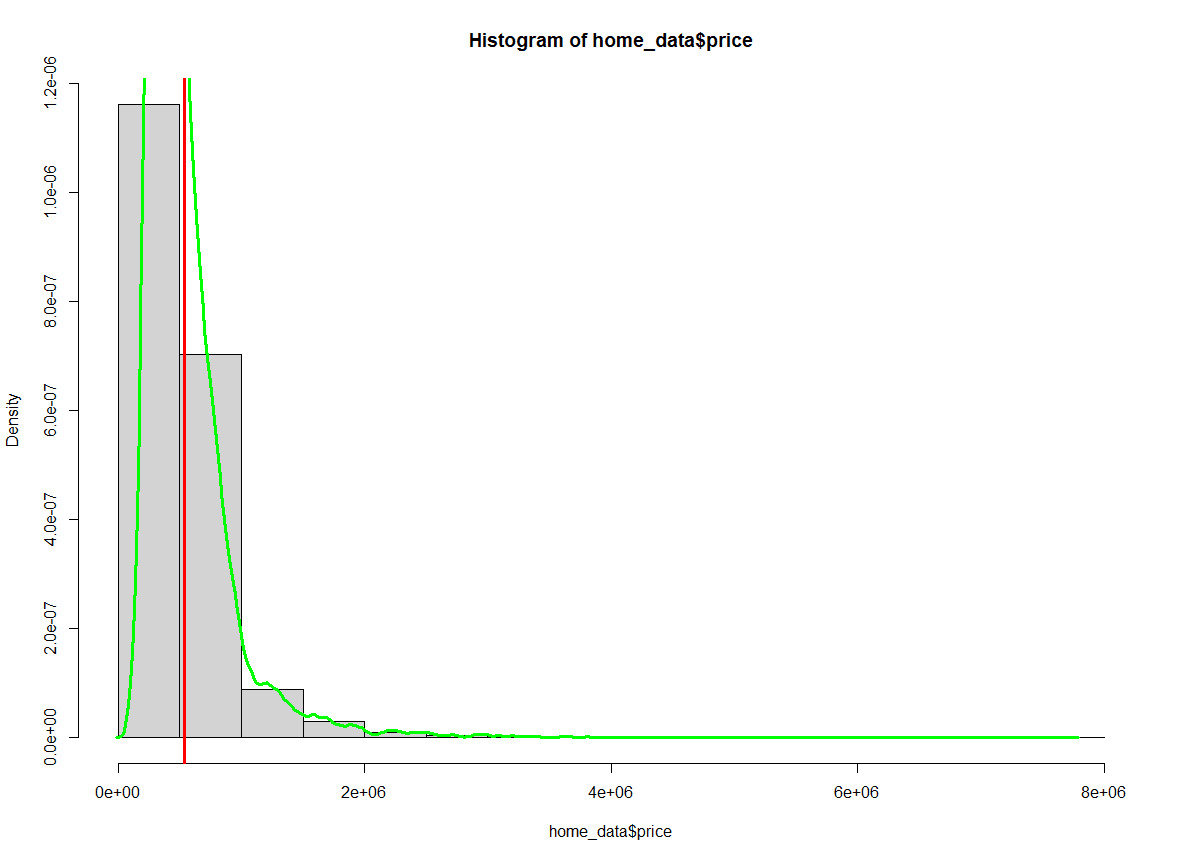
Histogramme des prix des logements avec la moyenne en surbrillance. Image par l'auteur.
Remarquez que les chiffres de l'axe des ordonnées ont changé.
Nous pouvons modifier les couleurs à l'intérieur des cellules de l'histogramme en utilisant le paramètre col de la fonction hist(). Nous allons changer le remplissage en bleu. Nous pouvons également modifier la couleur du contour des barres à l'aide du paramètre border. Nous allons changer la couleur des contours en blanc.
hist(home_data$price, col = 'blue', border = "white")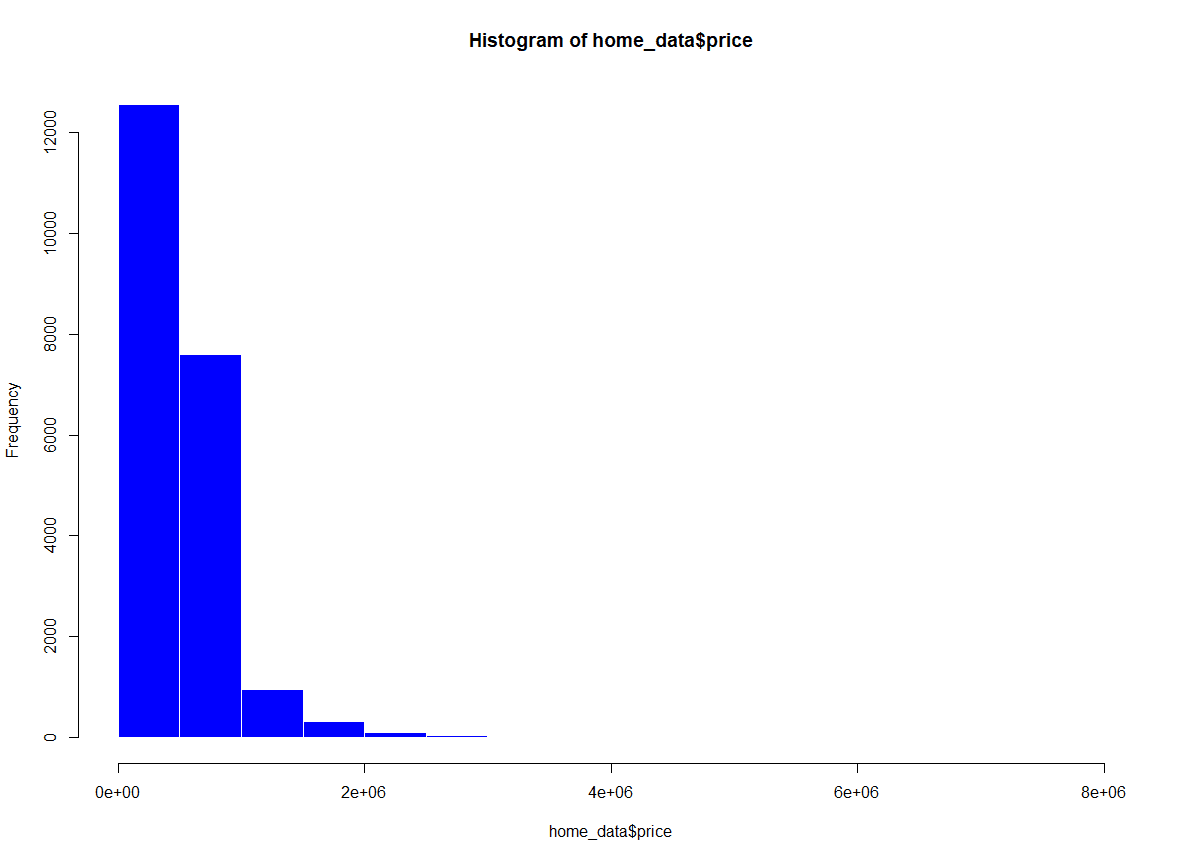 Histogramme des prix des logements avec ajout de couleurs. Image par l'auteur.
Histogramme des prix des logements avec ajout de couleurs. Image par l'auteur.
Nous pouvons modifier les étiquettes du graphique pour le rendre plus lisible et plus présentable. Cette fonction est utile si vous partagez l'intrigue avec d'autres personnes.
xlab définit l'étiquette de l'axe des xylab définit l'étiquette de l'axe des ymain définit le titre de l'intriguehist(home_data$price, xlab = 'Price (USD)', ylab = 'Number of Listings', main = 'Distribution of House Prices')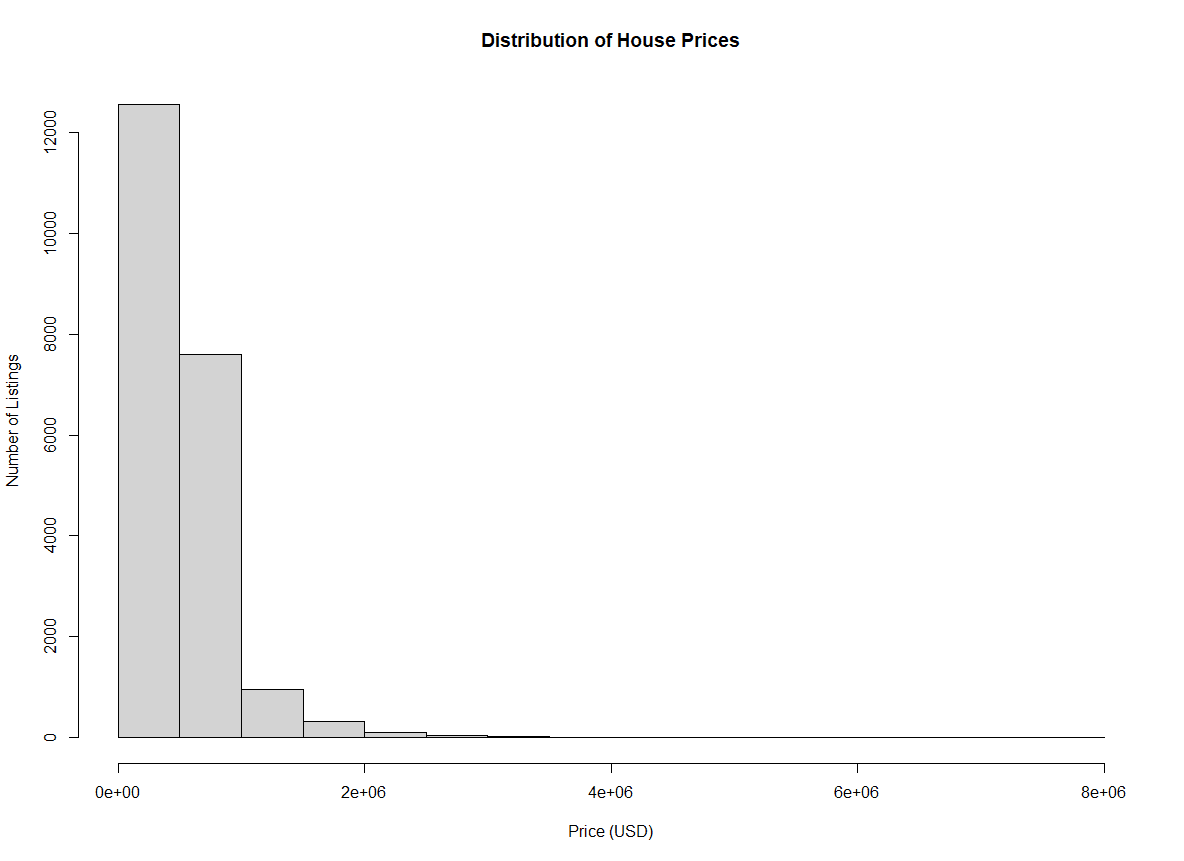 Histogramme des prix de l'immobilier avec des étiquettes d'axe. Image par l'auteur.
Histogramme des prix de l'immobilier avec des étiquettes d'axe. Image par l'auteur.
Avec les arguments par défaut, il est difficile de voir la distribution complète des prix du logement dans la gamme des prix. Nous pouvons voir qu'ils sont centralisés dans les premiers bacs, mais ils ne sont pas très descriptifs.
Il est possible d'ajouter d'autres bacs à l'aide du paramètre breaks. Avec cet argument, nous pouvons passer un vecteur de points d'arrêt spécifiques à utiliser, une fonction pour calculer les points d'arrêt, un nombre de points d'arrêt souhaité ou une fonction pour calculer le nombre de cellules.
Pour cet exemple, nous transmettrons le nombre de bacs que nous souhaitons. Ce nombre est spécifique au contexte, en fonction de ce que vous essayez de montrer dans votre graphique.
hist(home_data$price, breaks = 100)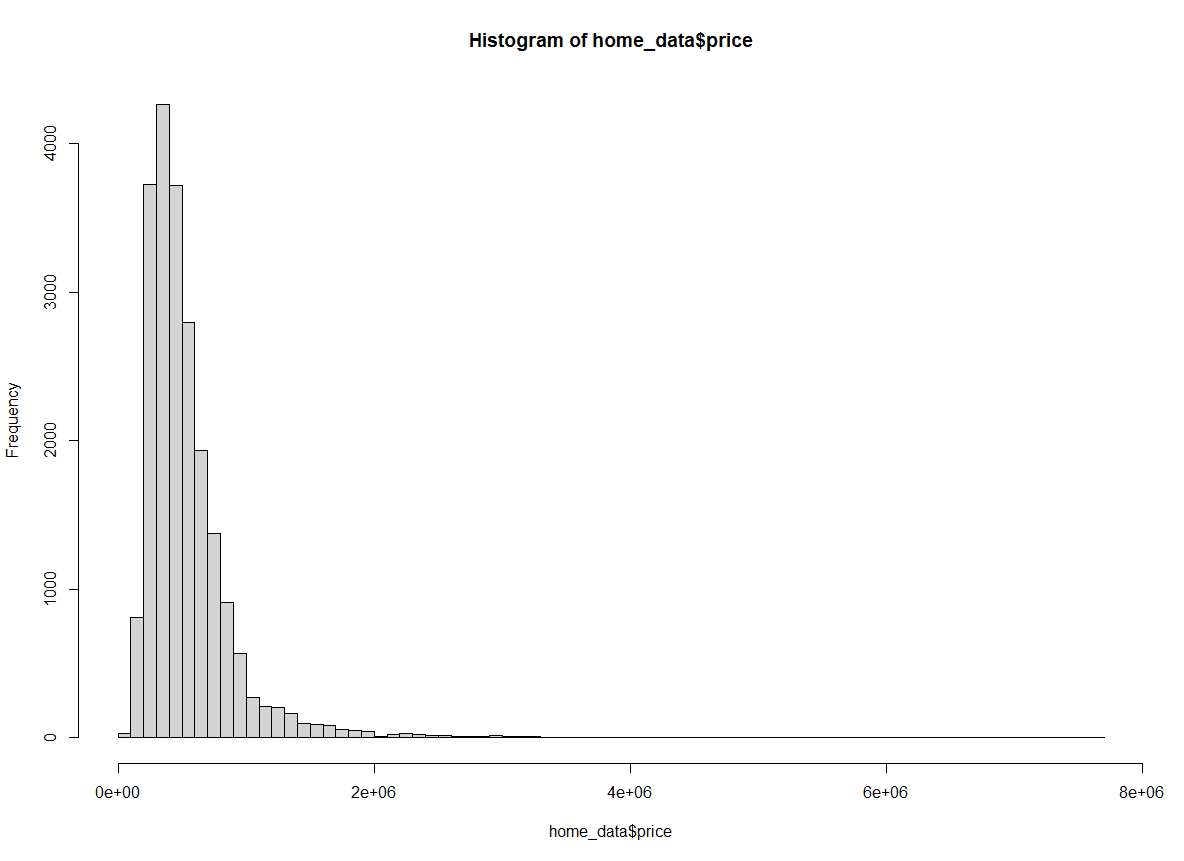 Histogramme des prix de l'immobilier dont la largeur des cases a été modifiée. Image par l'auteur.
Histogramme des prix de l'immobilier dont la largeur des cases a été modifiée. Image par l'auteur.
Avec breaks fixé à 100, nous avons beaucoup plus de visibilité sur la distribution dans les premiers seaux.
Nous pouvons également spécifier le nombre de ruptures en utilisant les noms des calculs courants pour calculer les ruptures optimales dans un histogramme. Par défaut, hist() utilise la méthode “Sturges”. Nous spécifions ici la méthode de manière explicite.
hist(home_data$price, breaks = "Sturges")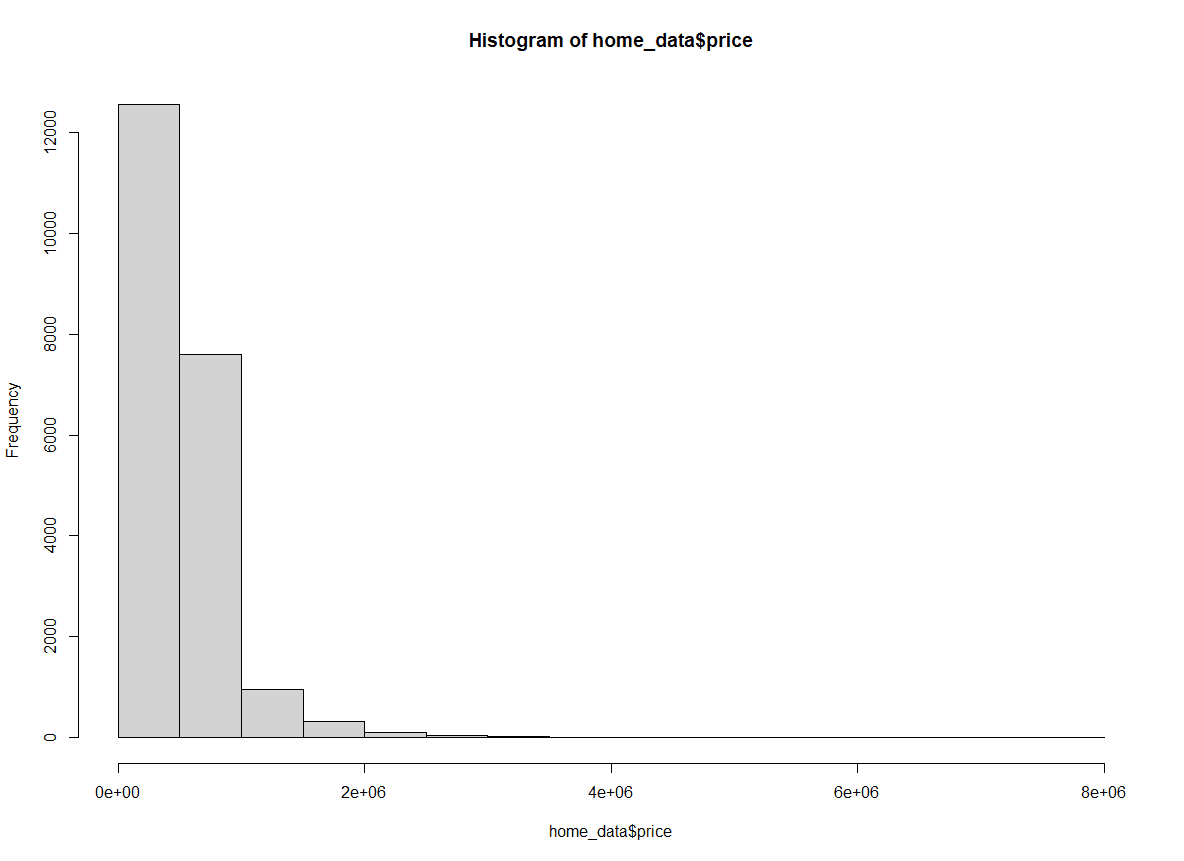 Histogramme des prix de l'immobilier selon la méthode Sturges. Image par l'auteur.
Histogramme des prix de l'immobilier selon la méthode Sturges. Image par l'auteur.
Nous pouvons également passer “Scott” comme argument pour l'attribut breaks afin d'utiliser la méthode Scott.
hist(home_data$price, breaks = "Scott")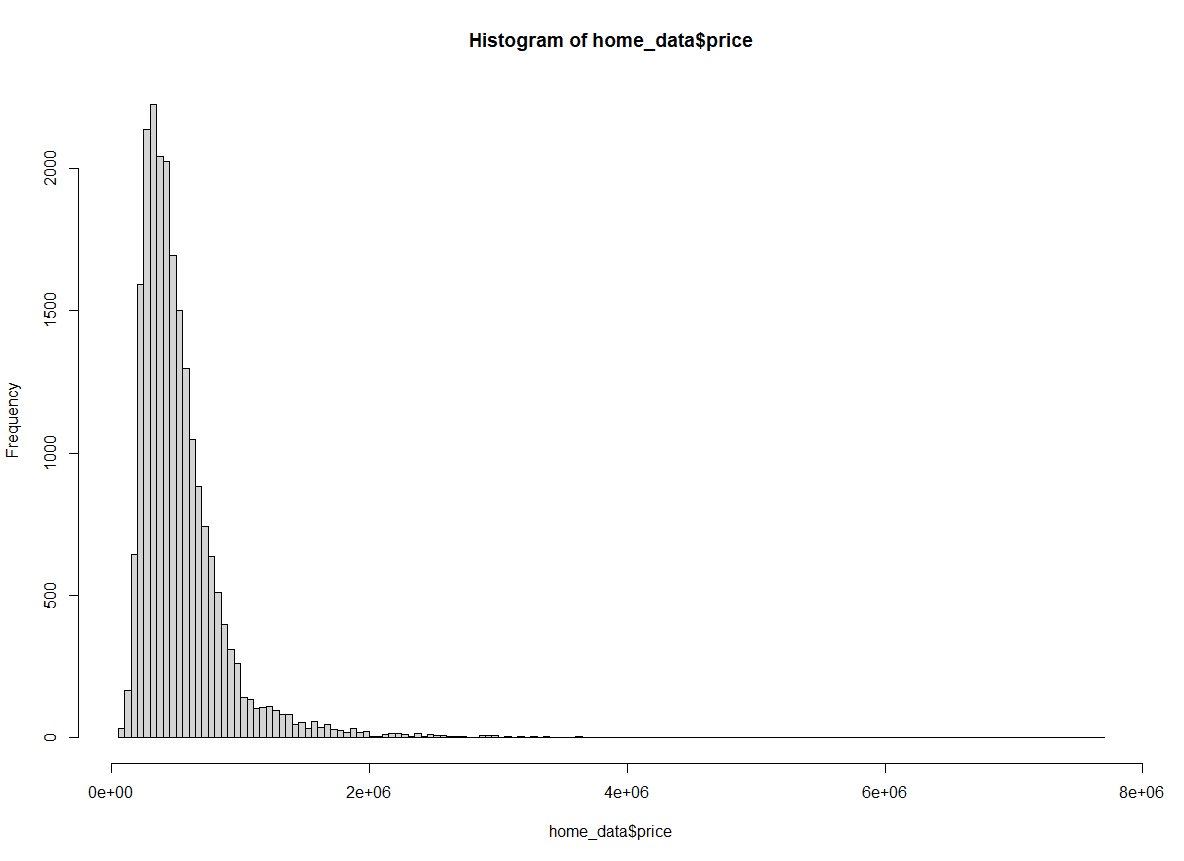
Histogramme des prix des logements utilisant la méthode Scott. Image par l'auteur.
Enfin, nous pourrions également utiliser la méthode Freedman-Diaconis (FD).
hist(home_data$price, breaks = "Freedman-Diaconis")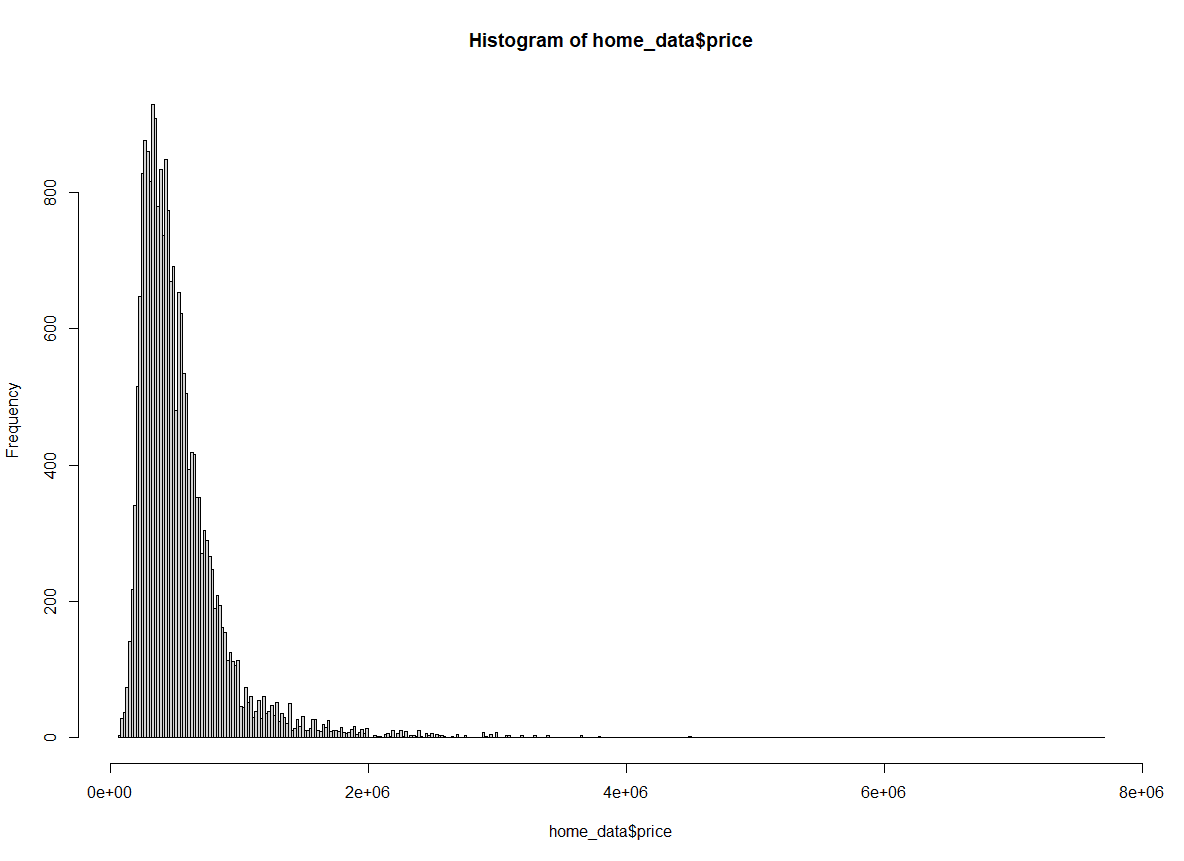 Histogramme des prix des logements selon la méthode Freedman-Diaconis. Image par l'auteur.
Histogramme des prix des logements selon la méthode Freedman-Diaconis. Image par l'auteur.
Nous pouvons définir les limites de l'axe x de notre graphique en utilisant l'argument xlim pour zoomer sur les données qui nous intéressent. Par exemple, il est parfois utile de se concentrer sur la partie centrale de la distribution, plutôt que sur la longue queue que l'on voit actuellement lorsque l'on regarde l'ensemble du graphique.
Il est également possible de modifier les limites de l'axe des ordonnées (en utilisant l'argument ylim ), mais cela est moins utile pour les histogrammes car les valeurs calculées automatiquement sont presque toujours idéales.
Nous nous concentrerons sur les prix compris entre 0 et 2 millions de dollars.
hist(home_data$price, breaks = 100, xlim = c(0, 2000000))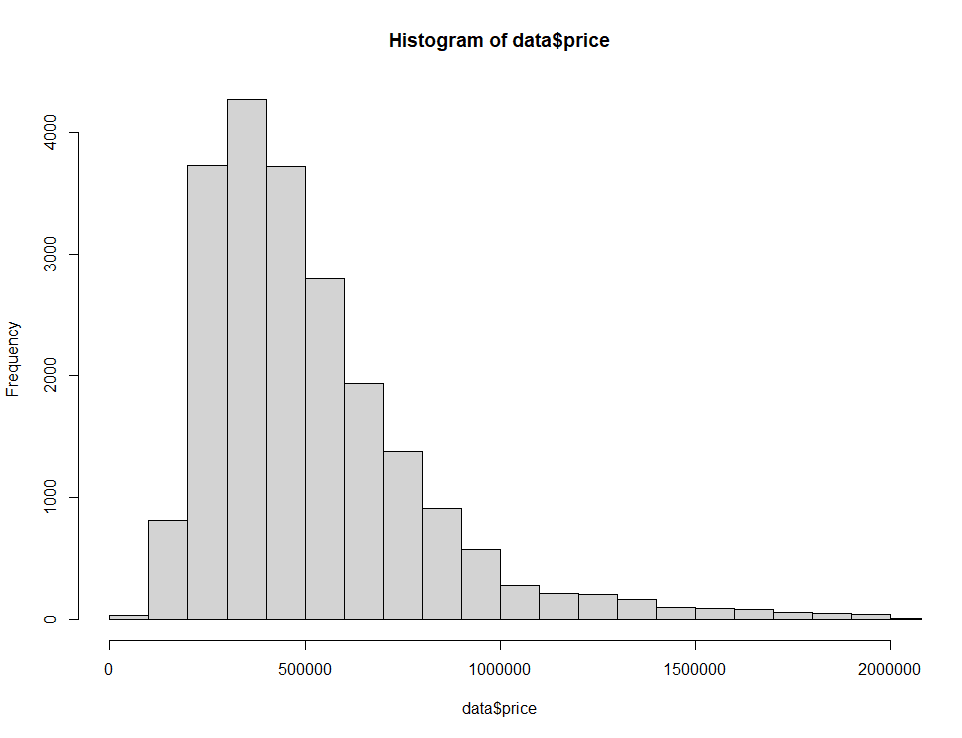 Histogramme des prix de l'immobilier avec les limites de l'axe modifiées. Image par l'auteur.
Histogramme des prix de l'immobilier avec les limites de l'axe modifiées. Image par l'auteur.
Au fur et à mesure que vous vous familiarisez avec R, vous pouvez explorer des packages plus puissants qui facilitent la création de visualisations plus intéressantes et plus utiles. Une bibliothèque très populaire et facile à utiliser pour les tracés dans R s'appelle ggplot2. Vous trouverez ci-dessous une vue intéressante de la répartition des prix en fonction du nombre de chambres à coucher dans la maison.
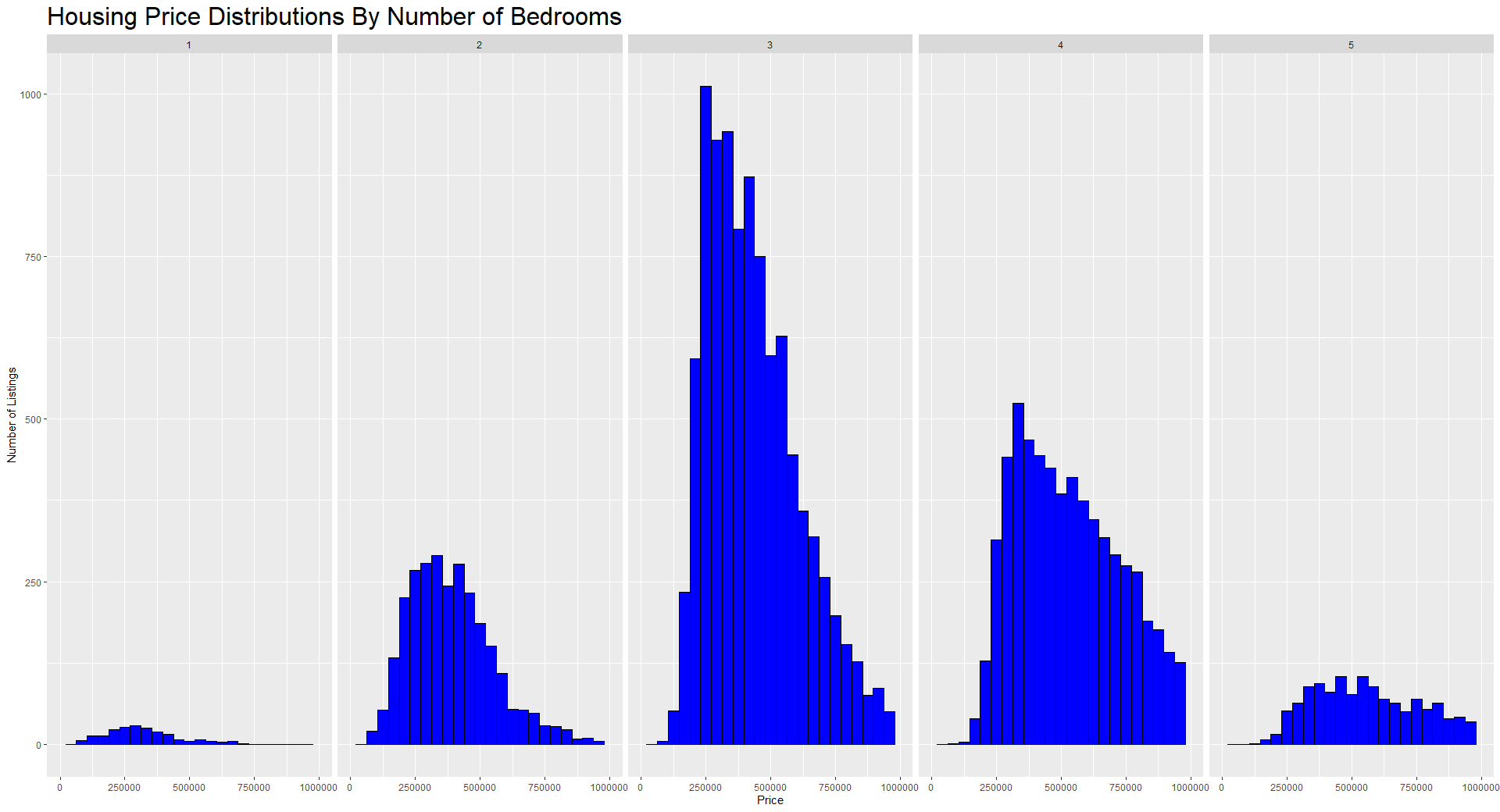 Histogramme des prix de l'immobilier à l'aide de ggplot2. Image par l'auteur.
Histogramme des prix de l'immobilier à l'aide de ggplot2. Image par l'auteur.
ggplot2 est le meilleur moyen de visualiser des données dans R, et vous pouvez apprendre à l'utiliser pour créer des histogrammes dans le tutoriel How to make a histogram in R in ggplot2. Consultez notre cours Introduction à ggplot2 et notre cours Intermédiaire ggplot2 pour apprendre à réaliser des visualisations plus intéressantes en R.
Dans ce tutoriel, nous avons appris que les histogrammes sont d'excellentes visualisations pour examiner les distributions de variables continues. Nous avons appris à créer un histogramme dans R, à tracer des statistiques sommaires au-dessus de notre histogramme, à personnaliser les caractéristiques du graphique comme les titres des axes, la couleur, la façon dont nous répartissons l'axe des x et à définir des limites sur les axes. Enfin, nous avons démontré la puissance de la bibliothèque ggplot2.
Pour d'autres lectures et ressources DataCamp, consultez nos cours interactifs :
Apprenez R avec DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
DataCamp Team
Tutoriel
Sejal Jaiswal
Tutoriel
Aditya Sharma
Tutoriel
Aditya Sharma
Tutoriel
