
Cursus
Ingénieur de données en Python
40 h
Travailler avec de grands ensembles de données présente souvent le défi d'extraire des modèles et des informations significatifs tout en maintenant les performances. Lorsque vos applications stockent des données dans MongoDB, l'exécution de requêtes et de transformations complexes directement dans la base de données peut s'avérer beaucoup plus rapide que le transfert des données vers des outils d'analyse externes. Les pipelines d'agrégation MongoDB offrent une solution en vous permettant de traiter, de transformer et d'analyser les données là où elles se trouvent.
Vous pouvez créer des flux de traitement de données personnalisés en enchaînant des opérations simples. Chaque étape du pipeline transforme les documents et transmet les résultats à l'étape suivante. Par exemple, vous pouvez avoir besoin de filtrer les enregistrements par plage de dates, de les regrouper par catégorie, de calculer des mesures statistiques et de formater le résultat, le tout grâce à une seule opération de base de données qui traite les données à proximité de leur source.
Dans cet article, vous apprendrez à construire des pipelines d'agrégation pour résoudre des défis courants en matière de données, tous les exemples étant démontrés dans PyMongo (le client Python officiel de MongoDB).
Bien que cet article se concentre sur les pipelines d'agrégation, si vous êtes novice dans l'utilisation de MongoDB avec Python, le cours Introduction à MongoDB en Python offre un point de départ complet. Cet article vous apportera suffisamment de bases pour traduire ces concepts d'agrégation dans le langage d'interrogation de MongoDB, seul ou avec l'aide de modèles de langage.
Imaginez que vous ayez besoin d'analyser les avis des clients sur plusieurs produits pour comprendre les tendances en matière de satisfaction. Les requêtes traditionnelles peuvent récupérer les données, mais elles ne permettent pas de combiner, d'analyser et de transformer ces informations en résumés utiles.
Les pipelines d'agrégation de MongoDB résolvent ce problème en fournissant un moyen structuré de traiter les données par le biais d'une série d'opérations qui s'appuient les unes sur les autres.
Considérez les pipelines d'agrégation comme des chaînes de montage pour vos données. Chaque document de votre collection entre à une extrémité du pipeline et passe par différentes stations (étapes) où il est filtré, transformé, regroupé ou enrichi.
La sortie d'une étape devient l'entrée de la suivante, ce qui vous permet de diviser les transformations de données complexes en étapes plus petites et plus faciles à gérer.
Ces pipelines utilisent une approche déclarative ; vous spécifiez ce que vous voulez à chaque étape plutôt que la manière de le calculer. Cette approche rend vos intentions de traitement des données claires et permet à MongoDB de gérer les détails d'exécution. La base de données peut alors appliquer diverses optimisations basées sur la structure de votre pipeline.
L'ordre des étapes est important dans la conception de votre pipeline. Le filtrage précoce des documents (avant le regroupement ou les calculs complexes) réduit la quantité de données circulant dans le pipeline.
Cette approche peut améliorer considérablement les performances lorsque vous travaillez avec de grandes collections. Un pipeline bien structuré ne traite que les données nécessaires à l'obtention des résultats finaux.
Les étapes d'agrégation de MongoDB se répartissent en quatre catégories principales en fonction de leur objectif. Les étapes de filtrage telles que $match fonctionnent comme des requêtes, sélectionnant uniquement les documents qui répondent à des critères spécifiques. Cela permet de restreindre votre ensemble de données avant d'effectuer des opérations plus complexes.
Les étapes de remodelage transforment la structure du document. En utilisant $project ou $addFields, vous pouvez inclure, exclure ou renommer des champs, ou créer des champs calculés basés sur des valeurs existantes. Ces étapes permettent de simplifier les documents en ne conservant que les informations pertinentes et en ajoutant les valeurs calculées nécessaires à l'analyse.
Lorsque vous devez combiner plusieurs documents sur la base de caractéristiques communes, les étapes de regroupement entrent en jeu. L'étape $group est l'outil de travail par excellence, car elle vous permet de calculer des comptes, des sommes, des moyennes et d'autres valeurs agrégées pour des groupes de documents. Des milliers d'enregistrements individuels sont ainsi transformés en résumés significatifs qui répondent à vos questions analytiques.
Pour compléter votre tableau de données, des étapes de jonction telles que $lookup vous permettent de combiner des informations provenant de plusieurs collections. Cela vous permet d'enrichir les documents avec des données connexes, de manière similaire aux jointures SQL, mais adaptées au modèle de document de MongoDB. La possibilité de référencer les données dans les différentes collections permet de maintenir une normalisation correcte des données tout en fournissant des résultats complets en une seule opération.
$match en fonction de critères$project et $addFields$group pour les valeurs agrégées$lookupPour une référence complète sur les capacités et les opérateurs, vous pouvez consulter le MongoDB Aggregation Pipeline Manual.
Avant de plonger dans les pipelines d'agrégation MongoDB, vous avez besoin d'un environnement de travail avec PyMongo et d'un accès à un échantillon de données. Cette section vous guide tout au long du processus de configuration avec le jeu de données sample_analytics, qui contient des données financières parfaites pour démontrer les concepts d'agrégation.
PyMongo est le pilote Python officiel de MongoDB. Vous pouvez l'installer à l'aide de pip sur macOS et Windows :
# Install PyMongo using pip
pip install pymongo
# Or if you're using conda
conda install -c conda-forge pymongoMongoDB propose des échantillons de données que vous pouvez utiliser sans créer vos propres données. L'approche la plus simple consiste à utiliser MongoDB Atlas (la version cloud) :
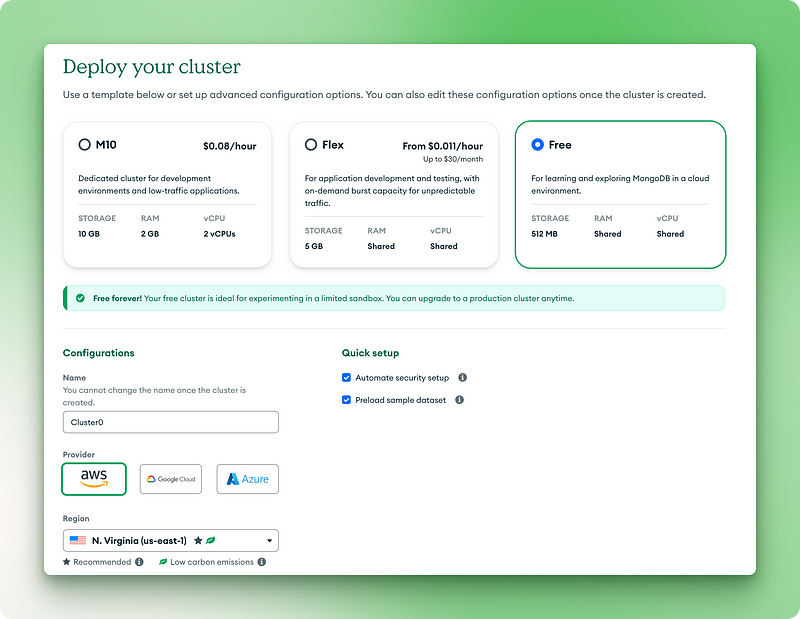
2.1. Choisissez la version gratuite pour toujours
2.2. Nommez votre cluster
2.3. Cliquez sur "Déployer"
2.4. Copiez votre nom d'utilisateur et votre mot de passe dans un endroit sûr
2.5. Cliquez sur "Créer un utilisateur de base de données"
2.6. Choisissez "Drivers" pour votre méthode de connexion
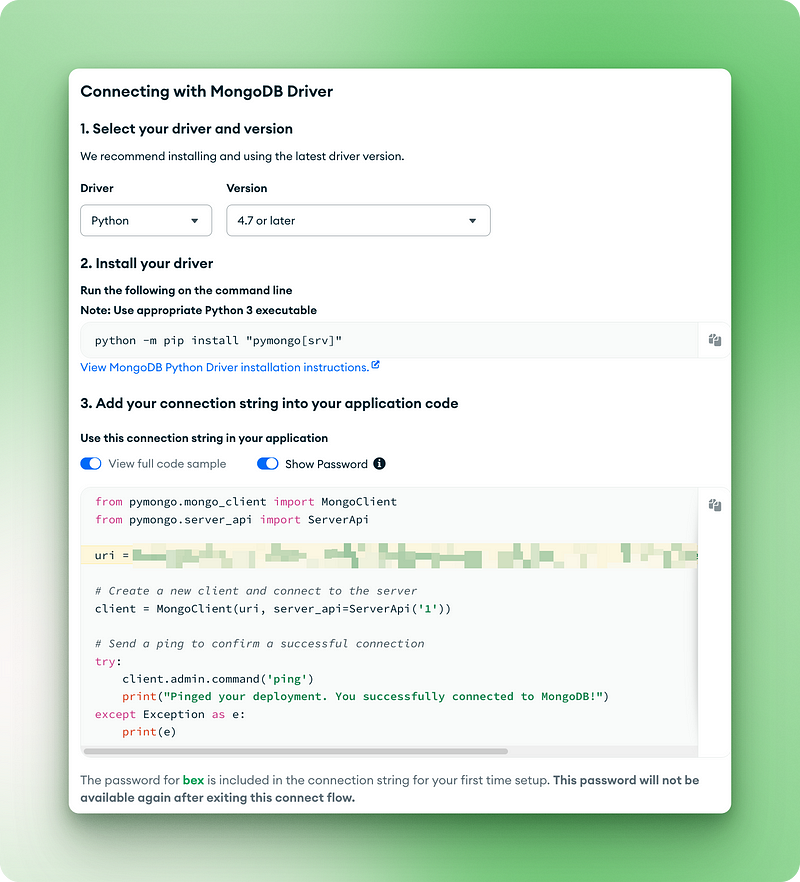
2.7. Copiez l'URI de connexion pour l'étape suivante
3.1. Cliquez sur les trois points dans votre vue des grappes.
3.2. Choisissez "Charger un échantillon de données"
3.3. Dans la liste, sélectionnez sample_analytics et attendez qu'elle se charge.
Pour les installations locales de MongoDB, vous pouvez charger les ensembles de données d'exemple en utilisant :
# Download and restore the sample dataset
python -m pip install pymongo[srv]
python -c "from pymongo import MongoClient; MongoClient().admin.command('getParameter', '*')"sample_analytics est suffisamment petit (~10MB) pour fonctionner correctement sur le niveau gratuit.Maintenant que MongoDB et l'échantillon de données sont prêts, écrivons le code pour nous connecter et vérifier notre configuration :
from pymongo.mongo_client import MongoClient
from pymongo.server_api import ServerApi
uri = "mongodb+srv://bex:gTVAbSjPzuhRUiyE@cluster0.jdohtoe.mongodb.net/?retryWrites=true&w=majority&appName=Cluster0"
# Create a new client and connect to the server
client = MongoClient(uri, server_api=ServerApi('1'))
# Send a ping to confirm a successful connection
try:
client.admin.command('ping')
print("Pinged your deployment. You successfully connected to MongoDB!")
except Exception as e:
print(e)
Pinged your deployment. You successfully connected to MongoDB!
# Access the sample_analytics database
db = client.sample_analytics
# Verify connection by counting documents in collections
customer_count = db.customers.count_documents({})
account_count = db.accounts.count_documents({})
print(f"Found {customer_count} customers and {account_count} accounts in sample_analytics")
# Preview one document from each collection
print("\nSample customer document:")
print(db.customers.find_one())
print("\nSample account document:")
print(db.accounts.find_one())Sortie :
Found 500 customers and 1746 accounts in sample_analytics
Sample customer document:
{'_id': ObjectId('5ca4bbcea2dd94ee58162a68'), 'username': 'fmiller', 'name': 'Elizabeth Ray', 'address': '9286 Bethany Glens\nVasqueztown, CO 22939', 'birthdate': datetime.datetime(1977, 3, 2, 2, 20, 31), 'email': 'arroyocolton@gmail.com', 'active': True, 'accounts': [371138, 324287, 276528, 332179, 422649, 387979], 'tier_and_details': {'0df078f33aa74a2e9696e0520c1a828a': {'tier': 'Bronze', 'id': '0df078f33aa74a2e9696e0520c1a828a', 'active': True, 'benefits': ['sports tickets']}, '699456451cc24f028d2aa99d7534c219': {'tier': 'Bronze', 'benefits': ['24 hour dedicated line', 'concierge services'], 'active': True, 'id': '699456451cc24f028d2aa99d7534c219'}}}
Sample account document:
{'_id': ObjectId('5ca4bbc7a2dd94ee5816238c'), 'account_id': 371138, 'limit': 9000, 'products': ['Derivatives', 'InvestmentStock']}Lorsque vous exécutez ce code, vous devez obtenir un résultat indiquant le nombre de documents et un aperçu des documents du client et du compte. Cela confirme que votre environnement est prêt pour les exemples de pipelines d'agrégation que nous allons explorer dans les sections suivantes.
Pour une introduction à PyMongo et à la configuration locale de MongoDB, consultez notre tutoriel PyMongo pour débutants.
Maintenant que nous avons confirmé notre connexion et exploré la structure du document, plongeons dans le cadre d'agrégation de MongoDB. Cette fonction puissante nous permet de traiter et de transformer les données directement dans la base de données. Dans cette section, nous allons explorer les étapes les plus courantes du pipeline à l'aide d'exemples pratiques en utilisant notre échantillon de données.
L'étape $match permet de filtrer les documents en fonction de critères spécifiques. Considérez-le comme un moyen de vous concentrer sur les données qui vous intéressent avant d'effectuer des opérations plus complexes.
Recherchez tous les comptes premium dont la limite est supérieure à 9 000 $ :
pipeline = [
{"$match": {"limit": {"$gt": 9000}}}
]
premium_accounts = list(db.accounts.aggregate(pipeline))
print(f"Found {len(premium_accounts)} premium accounts")
print(premium_accounts[0])Ce pipeline utilise l'étape $match avec un opérateur de comparaison $gt (plus grand que) pour filtrer les comptes. Elle fonctionne comme la méthode find(), mais dans le contexte d'un pipeline. La requête examine chaque document de la collection de comptes et ne conserve que ceux dont le champ limite est supérieur à 9000.
Sortie:
Found 1701 premium accounts
{'_id': ObjectId('5ca4bbc7a2dd94ee5816238d'), 'account_id': 557378, 'limit': 10000, 'products': ['InvestmentStock', 'Commodity', 'Brokerage', 'CurrencyService']}Si l'on examine les résultats, on constate que le pipeline a permis d'identifier 1701 comptes premium sur les 1746 comptes que compte notre base de données. Cette étape de filtrage réduit notre champ d'action, ce qui rend l'analyse ultérieure plus efficace et plus ciblée. Dans vos propres projets, vous pouvez utiliser cette technique pour vous concentrer sur les utilisateurs actifs, les transactions dépassant un certain montant ou les produits d'une catégorie spécifique avant d'effectuer une analyse plus approfondie de ces documents.
Ces étapes vous permettent de contrôler les champs à inclure et la manière d'organiser vos résultats. Voici un exemple qui permet d'obtenir les 5 premiers comptes avec les limites les plus élevées, en ne montrant que les informations essentielles :
pipeline = [
{"$project": {
"_id": 0,
"account_id": 1,
"limit": 1,
"product_count": {"$size": "$products"}
}},
{"$sort": {"limit": -1}},
{"$limit": 5}
]
top_accounts = list(db.accounts.aggregate(pipeline))
for account in top_accounts:
print(account)Cette canalisation comporte trois étapes qui fonctionnent ensemble :
1. L' étape $project permet de remodeler chaque document :
_id (le mettre à 0)account_id et limit (en leur attribuant la valeur 1)product_count qui utilise l' opérateur $size (l'undes nombreux opérateurs du pipeline d'agrégation) pour compter les éléments du tableau des produits2. L' étape $sort classe les résultats par ordre décroissant (-1) selon le champ limit.
3. L' étape $limit ne conserve que les 5 premiers documents après le tri.
Sortie :
{'account_id': 674364, 'limit': 10000, 'product_count': 1}
{'account_id': 278603, 'limit': 10000, 'product_count': 2}
{'account_id': 383777, 'limit': 10000, 'product_count': 5}
{'account_id': 557378, 'limit': 10000, 'product_count': 4}
{'account_id': 198100, 'limit': 10000, 'product_count': 3}Le résultat montre les cinq comptes ayant les limites les plus élevées, toutes de 10 000 $. Nous pouvons également voir combien de produits chaque compte détient grâce à notre champ calculé product_count.
Cela permet de présenter les données de manière plus claire, en se concentrant exactement sur ce qui est nécessaire, plutôt que de renvoyer tous les champs. Lorsque vous créez des tableaux de bord ou des rapports pour vos propres applications, vous pouvez utiliser des techniques similaires pour ne présenter que les informations les plus pertinentes aux utilisateurs, en réduisant le transfert de données et en simplifiant l'interface utilisateur.
C'est à l'étape $group que l'agrégation est la plus efficace. Vous pouvez classer les documents par catégories et calculer des indicateurs pour chaque groupe. Déterminons la limite moyenne du compte par type de produit :
pipeline = [
{"$unwind": "$products"}, # First unwind the products array
{"$group": {
"_id": "$products",
"avg_limit": {"$avg": "$limit"},
"count": {"$sum": 1}
}},
{"$sort": {"avg_limit": -1}}
]
product_analysis = list(db.accounts.aggregate(pipeline))
for product in product_analysis:
print(f"Product: {product['_id']}")
print(f" Average limit: ${product['avg_limit']:.2f}")
print(f" Number of accounts: {product['count']}")Ce pipeline utilise plusieurs opérateurs pour analyser les données relatives aux produits :
$group alors :_id dans $group détermine la clé de regroupement)$avg$sum: 1 (en ajoutant 1 pour chaque document).3. Les résultats des ordres d'étape $sort sont classés par ordre décroissant de la limite moyenne.
Sortie:
Product: Commodity
Average limit: $9963.89
Number of accounts: 720
Product: Brokerage
Average limit: $9960.86
Number of accounts: 741
Product: InvestmentStock
Average limit: $9955.90
Number of accounts: 1746
Product: InvestmentFund
Average limit: $9951.92
Number of accounts: 728
Product: Derivatives
Average limit: $9951.84
Number of accounts: 706
Product: CurrencyService
Average limit: $9946.09
Number of accounts: 742Les résultats révèlent que les produits Commodity sont associés aux limites de compte moyennes les plus élevées, tandis que les produits CurrencyService ont les limites les plus basses .
Ce type d'analyse permet d'identifier les corrélations entre les offres de produits et la capacité de dépense des clients.
Dans vos propres applications, vous pouvez utiliser des techniques similaires pour analyser les ventes par catégorie, l'engagement des utilisateurs par fonctionnalité ou les erreurs par module, c'est-à-dire tout scénario dans lequel vous devez résumer des données sur des groupes plutôt que d'examiner des enregistrements individuels.
Lorsque vos données s'étendent sur plusieurs collections, $lookup vous aide à les rassembler. Recherchez les clients et les comptes qui leur sont associés :
pipeline = [
{"$match": {"username": "fmiller"}}, # Find a specific customer
{"$lookup": {
"from": "accounts", # Collection to join with
"localField": "accounts", # Field from customers collection
"foreignField": "account_id", # Field from accounts collection
"as": "account_details" # Name for the new array field
}},
{"$project": {
"name": 1,
"accounts": 1,
"account_details.account_id": 1,
"account_details.limit": 1,
"account_details.products": 1
}}
]
customer_accounts = list(db.customers.aggregate(pipeline))
print(f"Customer: {customer_accounts[0]['name']}")
print(f"Has {len(customer_accounts[0]['account_details'])} accounts:")
for account in customer_accounts[0]['account_details']:
print(f" Account {account['account_id']}: ${account['limit']} limit with products: {', '.join(account['products'])}")Ce pipeline montre comment joindre des données connexes dans des collections :
$match permet de trouver un client spécifique par son nom d'utilisateur.$lookup effectue une jointure externe gauche avec la collection de comptes :from: spécifie la collection à laquelle se rattacherlocalField: le champ de la collection actuelle (clients) sur lequel la correspondance doit être établie.foreignFieldle champ de la collection cible (comptes) avec lequel il faut établir une correspondanceas: le nom du nouveau champ du tableau qui contiendra les documents correspondants3. L' étape $project permet d'afficher uniquement les champs pertinents.
Sortie :
Customer: Elizabeth Ray
Has 6 accounts:
Account 371138: $9000 limit with products: Derivatives, InvestmentStock
Account 324287: $10000 limit with products: Commodity, CurrencyService, Derivatives, InvestmentStock
Account 276528: $10000 limit with products: InvestmentFund, InvestmentStock
Account 332179: $10000 limit with products: Commodity, CurrencyService, InvestmentFund, Brokerage, InvestmentStock
Account 422649: $10000 limit with products: CurrencyService, InvestmentStock
Account 387979: $10000 limit with products: Brokerage, Derivatives, InvestmentFund, Commodity, InvestmentStockLe résultat fournit une vue d'ensemble du portefeuille financier d'Elizabeth Ray, montrant les six comptes et leurs produits associés dans un seul résultat de recherche.
Cela permet d'obtenir une vue complète à 360 degrés de vos relations de données sans avoir à effectuer de multiples requêtes ou des jointures côté client.
Pour vos propres applications, pensez à la situation où vous avez réparti des données dans des collections à des fins de normalisation, mais où vous devez les réassembler pour les analyser ou les afficher. Parmi les exemples courants, on peut citer les profils d'utilisateurs avec l'historique des activités, les produits avec l'état des stocks ou le contenu avec les commentaires associés.
Abordons maintenant une question commerciale plus complexe : "Quelles sont les limites moyennes des comptes des clients, regroupés par niveau de service ? Pour ce faire, nous devons traiter un objet imbriqué dans nos documents clients (tier_and_details ), puis relier ces informations à la collection accounts.
Tout d'abord, pour comprendre la structure de la collection customers, examinons les champs tier_and_details et accounts pour un exemple de client. Le champ tier_and_details est un objet dont chaque clé est un identifiant pour un abonnement à un niveau, et la valeur contient des détails tels que le nom du niveau. Le champ accounts est un tableau d'identifiants de comptes associés à ce client.
# First, let's look at the structure of 'tier_and_details' again
sample_customer = db.customers.find_one({"username": "fmiller"}) # Using a known customer for consistency
print("Tier structure example for customer 'fmiller':")
print(sample_customer['tier_and_details'])
print(f"Customer 'fmiller' has account IDs: {sample_customer['accounts']}")Sortie:
Tier structure example for customer 'fmiller':
{'0df078f33aa74a2e9696e0520c1a828a': {'tier': 'Bronze', 'id': '0df078f33aa74a2e9696e0520c1a828a', 'active': True, 'benefits': ['sports tickets']}, '699456451cc24f028d2aa99d7534c219': {'tier': 'Bronze', 'benefits': ['24 hour dedicated line', 'concierge services'], 'active': True, 'id': '699456451cc24f028d2aa99d7534c219'}}
Customer 'fmiller' has account IDs: [371138, 324287, 276528, 332179, 422649, 387979]pipeline = [
# Step 1: Project necessary fields, including 'accounts' and convert 'tier_and_details'
{"$project": {
"tiers_array": {"$objectToArray": "$tier_and_details"}, # Convert object to array
"customer_account_ids": "$accounts", # Explicitly carry over the customer's account IDs
"_id": 1 # Keep customer _id for later
}},
# Step 2: Unwind the new 'tiers_array' to process each tier object separately
{"$unwind": "$tiers_array"},
# Step 3: Reshape to clearly define the tier and keep customer account IDs
{"$project": {
"tier": "$tiers_array.v.tier", # Extract the tier name
"customer_account_ids": 1, # Ensure account IDs are still present
"customer_id": "$_id" # Rename _id to customer_id for clarity
}},
# Step 4: Look up account details using the customer_account_ids
{"$lookup": {
"from": "accounts", # Target collection
"localField": "customer_account_ids", # Array of account IDs from the customer
"foreignField": "account_id", # Field in the 'accounts' collection
"as": "matched_account_details" # New array with joined account documents
}},
# Step 5: Unwind the 'matched_account_details' array.
{"$unwind": "$matched_account_details"},
# Step 6: Group by tier to calculate statistics
{"$group": {
"_id": "$tier", # Group by the tier name
"avg_limit": {"$avg": "$matched_account_details.limit"}, # Calculate average limit
"total_accounts_in_tier": {"$sum": 1}, # Count how many accounts fall into this tier
"unique_customers_in_tier": {"$addToSet": "$customer_id"} # Count unique customers in this tier
}},
# Step 7: Format the final output
{"$project": {
"tier_name": "$_id", # Rename _id to tier_name
"average_account_limit": "$avg_limit",
"number_of_accounts": "$total_accounts_in_tier",
"number_of_customers": {"$size": "$unique_customers_in_tier"}, # Get the count of unique customers
"_id": 0 # Exclude the default _id
}},
# Step 8: Sort by average limit
{"$sort": {"average_account_limit": -1}}
]
tier_analysis = list(db.customers.aggregate(pipeline))
print("\nTier Analysis Results:")
for tier_data in tier_analysis:
print(f"Tier: {tier_data['tier_name']}")
print(f" Average Account Limit: ${tier_data['average_account_limit']:.2f}")
print(f" Number of Accounts in this Tier: {tier_data['number_of_accounts']}")
print(f" Number of Unique Customers in this Tier: {tier_data['number_of_customers']}")Cette filière décompose l'analyse complexe en huit étapes gérables :
$project: Nous commençons par transformer l'objet tier_and_details. L' opérateur $objectToArray convertit cet objet en un tableau de paires clé-valeur (tiers_array). C'est essentiel car les étapes comme $unwind fonctionnent sur des tableaux. Il est important de noter que nous reprenons explicitement le tableau accounts du document du client en tant que customer_account_ids et le tableau _id du client.$unwind: Cette étape consiste à déconstruire le site tiers_array, en créant un document distinct pour chaque niveau d'entrée qu'un client pourrait avoir. Chaque nouveau document contient toujours le customer_account_ids et le client original _id.$project: Nous remodelons le document pour extraire clairement le nom du niveau (par exemple, "Bronze") de la structure imbriquée ($tiers_array.v.tier) et renommer le client _id en customer_id pour plus de clarté. Le site customer_account_ids est traversé.$lookup: C'est ici que nous rejoignons la collection accounts. Nous utilisons le site customer_account_ids (le tableau des numéros de compte figurant dans le document du client) comme localField. Le site foreignField est account_id de la collection accounts. MongoDB trouvera tous les comptes dont account_id is present in the customer_account_ids array, adding them as an array to the matched_account_details field.: We unwind matched_account_details. Now, if a customer-tier combination was linked to multiple accounts, we get a separate document for each specific account, associated with that customer and tier.: We group the documents by tier. For each tier, we calculate the avg_limit using $avg on the limit from the joined account details. We count the total_accounts_in_tier using $sum : 1. We also use $addToSet with customer_id to collect the unique customer IDs belonging to each tier.: The final shaping of our output. We rename _id (which is the tier name from the group stage) to tier_name. We use $size to get the count of unique_customers_in_tier.: We order the results by average_account_limit` dans l'ordre décroissant, de sorte que le niveau avec la limite moyenne la plus élevée apparaisse en premier.Tier Analysis Results:
Tier: Silver
Average Account Limit: $9974.55
Number of Accounts in this Tier: 393
Number of Unique Customers in this Tier: 95
Tier: Bronze
Average Account Limit: $9964.11
Number of Accounts in this Tier: 418
Number of Unique Customers in this Tier: 93
Tier: Platinum
Average Account Limit: $9962.53
Number of Accounts in this Tier: 427
Number of Unique Customers in this Tier: 101
Tier: Gold
Average Account Limit: $9962.44
Number of Accounts in this Tier: 426
Number of Unique Customers in this Tier: 99Les résultats montrent maintenant une hiérarchie légèrement différente : les clients du niveau Silver ont, en moyenne, les comptes avec les limites les plus élevées, suivis par Bronze, puis Platinum, et enfin Gold. T
Ce type d'information est précieux pour comprendre les segments de clientèle. Par exemple, une institution financière peut utiliser ces informations pour étudier les raisons pour lesquelles les niveaux Silver et Bronze ont des limites moyennes aussi élevées, ou pour adapter les campagnes de marketing ou offrir des services haut de gamme.
L'utilisation de $objectToArray était essentielle pour déverrouiller les données des niveaux imbriqués, et le fait de passer soigneusement customer_account_ids a permis à $lookup de relier les clients à leurs comptes spécifiques.
Lorsque vous rencontrez des objets imbriqués dans vos propres ensembles de données que vous devez utiliser dans des agrégations (comme user preferences, product attributes, ou configuration settings ), rappelez-vous la technique $objectToArray .
Veillez toujours à ce que les champs requis pour les étapes ultérieures, en particulier pour les opérations $lookup, soient explicitement inclus dans vos étapes $project. Cette approche structurée de la décomposition de données complexes permet d'obtenir des informations significatives directement dans MongoDB.
Au-delà des transformations séquentielles, le cadre d'agrégation de MongoDB offre des modèles sophistiqués pour répondre à des requêtes analytiques complexes. Lorsque vous devez analyser des données sous plusieurs angles simultanément ou effectuer des calculs sur la base d'un ensemble de documents, ces modèles avancés fournissent des solutions puissantes directement dans la base de données.
L' étape $facet vous permet d'exécuter plusieurs sous-pipelines d'agrégation au sein d'une même étape, en utilisant le même ensemble de documents d'entrée. Imaginez que vous ayez besoin de classer les produits par gamme de prix et, en même temps, de dresser la liste des 5 marques les plus populaires à partir de la même collection de produits. $facet traite ces différentes perspectives analytiques en parallèle.
Chaque sous-pipeline au sein de $facet opère indépendamment sur les documents d'entrée et produit son propre tableau de documents de sortie. Cela signifie que vous pouvez rassembler diverses mesures ou résumés - comme ceux nécessaires pour un tableau de bord complet - en une seule requête de base de données.
Par exemple, vous pouvez obtenir simultanément un décompte du nombre total d'utilisateurs actifs, une répartition des utilisateurs par niveau d'abonnement et une liste des utilisateurs récemment inscrits, le tout à partir du même ensemble de données d'utilisateurs. Cela permet de créer des rapports riches et variés sans avoir à faire appel à plusieurs bases de données, ce qui simplifie la recherche de données pour les vues complexes.
Introduites dans MongoDB 5.0, les fonctions de fenêtre effectuent des calculs sur un ensemble de documents liés au document actuel, appelé "fenêtre".
Ceci est utile pour les données de séries temporelles ou tout autre ensemble de données ordonnées où le contexte des documents voisins est important. Par exemple, vous pourriez vouloir calculer une moyenne mobile des ventes sur 7 jours ou trouver la somme cumulée des transactions pour chaque client au fil du temps.
Les fonctions de fenêtre sont généralement utilisées à l'étape $setWindowFields. Cette étape vous permet de définir des partitions (groupes de documents, comme les ventes par produit) et un ordre de tri à l'intérieur de ces partitions (par exemple par date).
Vous pouvez ensuite appliquer des fonctions de fenêtre telles que $avg, $sum, $min, $max, ou des fonctions spécialisées telles que $derivative ou $integral sur une fenêtre définie (par exemple, les 3 documents précédents et le document actuel).
Envisagez de calculer un total courant des ventes de produits. Un pipeline utilisant $setWindowFields pourrait ressembler à ceci :
pipeline = [
{"$match": {"category": "Electronics"}}, # Filter for electronics
{"$sort": {"sale_date": 1}}, # Sort by sale date
{"$setWindowFields": {
"partitionBy": "$product_id", # Calculate running total per product
"sortBy": {"sale_date": 1},
"output": {
"running_total_sales": {
"$sum": "$sale_amount",
"window": {
"documents": ["unbounded", "current"] # Sum from start to current document
}
}
}
}}
]
# electronics_sales_with_running_total = list(db.sales.aggregate(pipeline))Dans cette filière conceptuelle, pour chaque vente électronique, un champ running_total_sales est ajouté. Ce champ représente la somme de sale_amount pour ce produit depuis la première vente jusqu'à la vente actuelle .
Ces calculs, qui nécessitaient auparavant une logique complexe côté client ou des requêtes multiples, peuvent désormais être effectués directement dans la base de données, ce qui simplifie le code de l'application et améliore les performances pour l'analyse des tendances ou les comparaisons d'une période à l'autre.
Les pipelines d'agrégation MongoDB fournissent une méthode structurée pour traiter les données directement dans votre base de données. En reliant des étapes opérationnelles distinctes, vous pouvez effectuer des manipulations de données complexes, telles que le filtrage d'enregistrements, le remodelage de documents, le regroupement d'informations et la combinaison de données provenant de diverses collections.
Cette approche permet d'affiner vos flux de données et d'extraire plus rapidement du sens à partir de grands ensembles de données, comme le montrent les exemples de PyMongo. Le traitement des données à proximité de leur source permet souvent d'améliorer les performances des requêtes analytiques.
La maîtrise des pipelines d'agrégation vous prépare à relever de nombreux défis en matière d'analyse de données. Pour mettre en pratique ce que vous avez appris, vous pouvez essayer un projet pratique tel que Construire un pipeline de données pour le commerce de détail.
Pour une perspective plus large sur les systèmes de données et la façon dont les compétences MongoDB s'inscrivent dans le tableau plus large, le cursus Data Engineer with Python offre un apprentissage approfondi. Si vous souhaitez progresser dans votre carrière, l'examen des questions d'entretien les plus courantes sur MongoDB peut également être utile pour comprendre les attentes typiques en matière de résolution de problèmes.
Les meilleurs cours de DataCamp
Cursus
Cours
Cours