
Programa
Engenheiro de dados Em Python
40 h
Trabalhar com grandes conjuntos de dados geralmente apresenta o desafio de extrair padrões e percepções significativas e, ao mesmo tempo, manter o desempenho. Quando seus aplicativos armazenam dados no MongoDB, a execução de consultas e transformações complexas diretamente no banco de dados pode ser muito mais rápida do que mover os dados para ferramentas de análise externas. Os pipelines de agregação do MongoDB oferecem uma solução, permitindo que você processe, transforme e analise os dados exatamente onde eles estão.
Você pode criar fluxos de trabalho de processamento de dados personalizados conectando operações simples em sequência. Cada estágio do pipeline transforma documentos e passa os resultados para o próximo estágio. Por exemplo, você pode precisar filtrar registros por intervalo de datas, agrupá-los por categoria, calcular medidas estatísticas e formatar o resultado - tudo isso realizado por meio de uma única operação de banco de dados que processa dados próximos à sua origem.
Neste artigo, você aprenderá a criar pipelines de agregação para resolver desafios comuns de dados, com todos os exemplos demonstrados no PyMongo (o cliente Python oficial do MongoDB).
Embora este artigo se concentre em pipelines de agregação, se você é novo no uso do MongoDB com Python, o curso Introduction to MongoDB in Python oferece um ponto de partida abrangente. Você obterá base suficiente com este artigo para traduzir esses conceitos de agregação para a linguagem de consulta do MongoDB por conta própria ou com a ajuda de modelos de linguagem.
Imagine você precisando analisar as avaliações dos clientes em vários produtos para entender as tendências de satisfação. As consultas tradicionais podem recuperar os dados, mas não ajudam a combinar, analisar e transformar essas informações em resumos úteis.
Os pipelines de agregação do MongoDB resolvem isso fornecendo uma maneira estruturada de processar dados por meio de uma série de operações que se baseiam umas nas outras.
Pense nos pipelines de agregação como linhas de montagem para seus dados. Cada documento da sua coleção entra em uma extremidade do pipeline e passa por várias estações (estágios) onde é filtrado, transformado, agrupado ou enriquecido.
O resultado de um estágio torna-se a entrada para o próximo, permitindo que você divida transformações complexas de dados em etapas menores e gerenciáveis.
Esses pipelines usam uma abordagem declarativa; você especifica o que deseja em cada estágio em vez de como computá-lo. Essa abordagem deixa claras as suas intenções de processamento de dados e permite que o MongoDB cuide dos detalhes da execução. O banco de dados pode então aplicar várias otimizações com base na estrutura do pipeline.
A ordem dos estágios é importante para o projeto do pipeline. A filtragem antecipada de documentos (antes do agrupamento ou de cálculos complexos) reduz a quantidade de dados que fluem pelo pipeline.
Essa abordagem pode melhorar drasticamente o desempenho quando você trabalha com grandes coleções. Um pipeline bem estruturado processa somente os dados necessários para os resultados finais.
Os estágios de agregação do MongoDB se dividem em quatro categorias principais com base em sua finalidade. Os estágios de filtragem, como $match, funcionam como consultas, selecionando apenas os documentos que atendem a critérios específicos. Isso ajuda a restringir seu conjunto de dados antes de realizar operações mais complexas.
Os estágios de remodelagem transformam a estrutura do documento. Usando $project ou $addFields, você pode incluir, excluir ou renomear campos, ou criar campos calculados com base em valores existentes. Esses estágios ajudam a simplificar os documentos, mantendo apenas as informações relevantes e adicionando os valores computados necessários para a análise.
Quando você precisa combinar vários documentos com base em características compartilhadas, os estágios de agrupamento entram em ação. O estágio $group é a força de trabalho aqui, permitindo que você calcule contagens, somas, médias e outros valores agregados em grupos de documentos. Isso transforma milhares de registros individuais em resumos significativos que respondem às suas perguntas analíticas.
Para completar o quadro de dados, os estágios de união, como $lookup, permitem que você combine informações de várias coleções. Isso permite que você enriqueça documentos com dados relacionados, de forma semelhante às junções SQL, mas adaptadas ao modelo de documento do MongoDB. A capacidade de referenciar dados em coleções ajuda a manter a normalização adequada dos dados e, ao mesmo tempo, fornece resultados completos em uma única operação.
$match com base em critérios$project e $addFields$group para valores agregados$lookupPara obter uma referência completa sobre recursos e operadores, você pode consultar o Manual do pipeline de agregação do MongoDB.
Antes de mergulhar nos pipelines de agregação do MongoDB, você precisa de um ambiente de trabalho com o PyMongo e acesso a um conjunto de dados de amostra. Esta seção orienta você no processo de configuração com o conjunto de dados sample_analytics, que contém dados financeiros perfeitos para demonstrar conceitos de agregação.
PyMongo é o driver Python oficial do MongoDB. Você pode instalá-lo usando o pip no macOS e no Windows:
# Install PyMongo using pip
pip install pymongo
# Or if you're using conda
conda install -c conda-forge pymongoO MongoDB oferece conjuntos de dados de amostra que você pode usar sem criar seus próprios dados. A abordagem mais fácil é usar o MongoDB Atlas (a versão em nuvem):
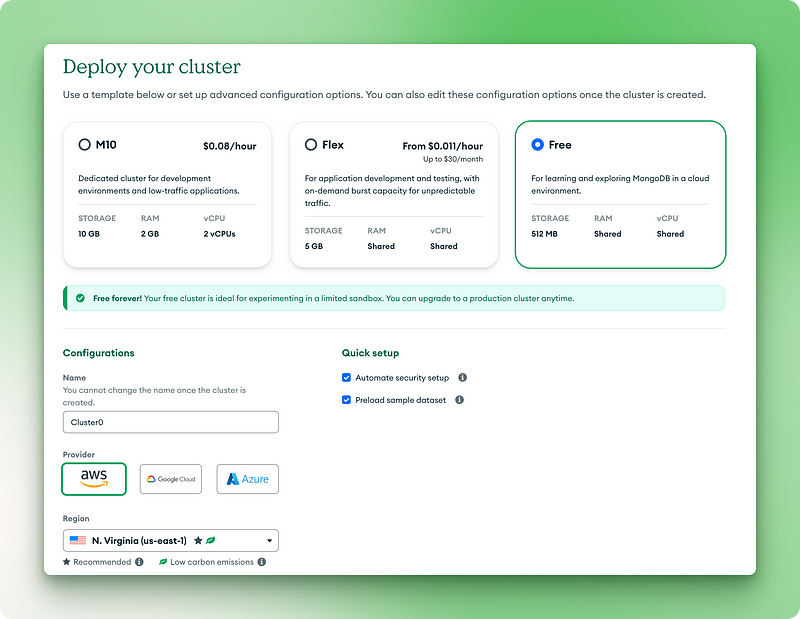
2.1. Escolha a versão gratuita para sempre
2.2. Dê um nome ao seu cluster
2.3. Clique em "Deploy" (Implantar)
2.4. Copie seu nome de usuário e senha para um local seguro
2.5. Clique em "Create database user" (Criar usuário do banco de dados)
2.6. Escolha "Drivers" para seu método de conexão
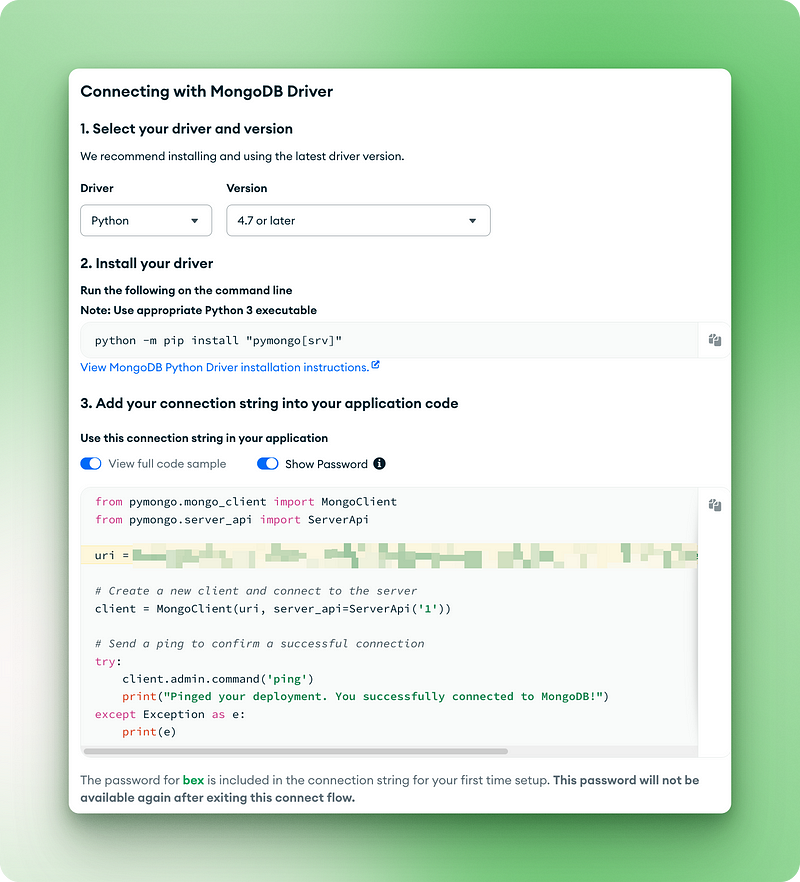
2.7. Copie o URI de conexão para a próxima etapa
3.1. Clique nos três pontos em sua visualização de clusters
3.2. Escolha "Load sample dataset" (Carregar conjunto de dados de amostra)
3.3. Na lista, selecione sample_analytics e aguarde o carregamento.
Para instalações locais do MongoDB, você pode carregar os conjuntos de dados de amostra usando:
# Download and restore the sample dataset
python -m pip install pymongo[srv]
python -c "from pymongo import MongoClient; MongoClient().admin.command('getParameter', '*')"sample_analytics é pequeno o suficiente (~10 MB) para funcionar bem na camada gratuitaAgora que você tem o MongoDB e o conjunto de dados de amostra prontos, vamos escrever o código para conectar e verificar nossa configuração:
from pymongo.mongo_client import MongoClient
from pymongo.server_api import ServerApi
uri = "mongodb+srv://bex:gTVAbSjPzuhRUiyE@cluster0.jdohtoe.mongodb.net/?retryWrites=true&w=majority&appName=Cluster0"
# Create a new client and connect to the server
client = MongoClient(uri, server_api=ServerApi('1'))
# Send a ping to confirm a successful connection
try:
client.admin.command('ping')
print("Pinged your deployment. You successfully connected to MongoDB!")
except Exception as e:
print(e)
Pinged your deployment. You successfully connected to MongoDB!
# Access the sample_analytics database
db = client.sample_analytics
# Verify connection by counting documents in collections
customer_count = db.customers.count_documents({})
account_count = db.accounts.count_documents({})
print(f"Found {customer_count} customers and {account_count} accounts in sample_analytics")
# Preview one document from each collection
print("\nSample customer document:")
print(db.customers.find_one())
print("\nSample account document:")
print(db.accounts.find_one())Saída:
Found 500 customers and 1746 accounts in sample_analytics
Sample customer document:
{'_id': ObjectId('5ca4bbcea2dd94ee58162a68'), 'username': 'fmiller', 'name': 'Elizabeth Ray', 'address': '9286 Bethany Glens\nVasqueztown, CO 22939', 'birthdate': datetime.datetime(1977, 3, 2, 2, 20, 31), 'email': 'arroyocolton@gmail.com', 'active': True, 'accounts': [371138, 324287, 276528, 332179, 422649, 387979], 'tier_and_details': {'0df078f33aa74a2e9696e0520c1a828a': {'tier': 'Bronze', 'id': '0df078f33aa74a2e9696e0520c1a828a', 'active': True, 'benefits': ['sports tickets']}, '699456451cc24f028d2aa99d7534c219': {'tier': 'Bronze', 'benefits': ['24 hour dedicated line', 'concierge services'], 'active': True, 'id': '699456451cc24f028d2aa99d7534c219'}}}
Sample account document:
{'_id': ObjectId('5ca4bbc7a2dd94ee5816238c'), 'account_id': 371138, 'limit': 9000, 'products': ['Derivatives', 'InvestmentStock']}Ao executar esse código, você verá uma saída mostrando a contagem de documentos e uma visualização dos documentos do cliente e da conta. Isso confirma que seu ambiente está pronto para os exemplos de pipeline de agregação que exploraremos nas próximas seções.
Para obter uma introdução ao PyMongo e à configuração local do MongoDB, confira nosso tutorial PyMongo para iniciantes.
Agora que confirmamos nossa conexão e exploramos a estrutura do documento, vamos nos aprofundar na estrutura de agregação do MongoDB. Esse poderoso recurso nos permite processar e transformar dados diretamente no banco de dados. Nesta seção, exploraremos os estágios mais comuns do pipeline com exemplos práticos usando nosso conjunto de dados de amostra.
O estágio $match filtra documentos com base em critérios especificados. Pense nisso como uma forma de se concentrar apenas nos dados que interessam a você antes de realizar operações mais complexas.
Vamos encontrar todas as contas premium com um limite superior a US$ 9.000:
pipeline = [
{"$match": {"limit": {"$gt": 9000}}}
]
premium_accounts = list(db.accounts.aggregate(pipeline))
print(f"Found {len(premium_accounts)} premium accounts")
print(premium_accounts[0])Esse pipeline usa o estágio $match com um operador de comparação $gt (maior que) para filtrar contas. Funciona exatamente como o método find(), mas no contexto de um pipeline. A consulta examina cada documento na coleção de contas e mantém apenas aqueles em que o campo de limite excede 9000.
Saída:
Found 1701 premium accounts
{'_id': ObjectId('5ca4bbc7a2dd94ee5816238d'), 'account_id': 557378, 'limit': 10000, 'products': ['InvestmentStock', 'Commodity', 'Brokerage', 'CurrencyService']}Observando os resultados, podemos ver que o pipeline identificou 1701 contas premium de um total de 1746 contas em nosso banco de dados. Essa etapa de filtragem restringe nosso foco, tornando a análise subsequente mais eficiente e direcionada. Em seus próprios projetos, você pode usar essa técnica para se concentrar em usuários ativos, transações acima de um determinado valor ou produtos em uma categoria específica antes de realizar uma análise mais profunda desses documentos.
Esses estágios ajudam você a controlar quais campos devem ser incluídos e como organizar os resultados. Aqui está um exemplo que obtém as cinco principais contas com os limites mais altos, mostrando apenas as informações essenciais:
pipeline = [
{"$project": {
"_id": 0,
"account_id": 1,
"limit": 1,
"product_count": {"$size": "$products"}
}},
{"$sort": {"limit": -1}},
{"$limit": 5}
]
top_accounts = list(db.accounts.aggregate(pipeline))
for account in top_accounts:
print(account)Esse pipeline tem três estágios trabalhando juntos:
1. O estágio $project reformula cada documento:
_id (definindo-o como 0)account_id e limit (definindo-os como 1)product_count que usa o operador $size (umdos muitos operadores de pipeline de agregação) para contar itens na matriz de produtos2. O estágio $sort ordena os resultados pelo campo limit em ordem decrescente (-1)
3. O estágio $limit mantém apenas os primeiros 5 documentos após a classificação
Saída:
{'account_id': 674364, 'limit': 10000, 'product_count': 1}
{'account_id': 278603, 'limit': 10000, 'product_count': 2}
{'account_id': 383777, 'limit': 10000, 'product_count': 5}
{'account_id': 557378, 'limit': 10000, 'product_count': 4}
{'account_id': 198100, 'limit': 10000, 'product_count': 3}O resultado mostra as cinco contas com os limites mais altos, todas no valor de US$ 10.000. Também podemos ver quantos produtos cada conta possui por meio do nosso campo calculado product_count.
Isso permite uma apresentação de dados mais limpa e focada exatamente no que é necessário, em vez de retornar todos os campos. Ao criar painéis ou relatórios para seus próprios aplicativos, você pode usar técnicas semelhantes para apresentar apenas as informações mais relevantes aos usuários, reduzindo a transferência de dados e simplificando a interface do usuário.
O estágio $group é onde a agregação realmente se destaca. Você pode categorizar documentos e calcular métricas em cada grupo. Vamos descobrir o limite médio da conta por tipo de produto:
pipeline = [
{"$unwind": "$products"}, # First unwind the products array
{"$group": {
"_id": "$products",
"avg_limit": {"$avg": "$limit"},
"count": {"$sum": 1}
}},
{"$sort": {"avg_limit": -1}}
]
product_analysis = list(db.accounts.aggregate(pipeline))
for product in product_analysis:
print(f"Product: {product['_id']}")
print(f" Average limit: ${product['avg_limit']:.2f}")
print(f" Number of accounts: {product['count']}")Esse pipeline usa vários operadores para analisar os dados do produto:
$group:_id em $group determina a chave de agrupamento)$avg$sum: 1 (adicionando 1 para cada documento)3. Os resultados das ordens do estágio $sort por limite médio em ordem decrescente
Saída:
Product: Commodity
Average limit: $9963.89
Number of accounts: 720
Product: Brokerage
Average limit: $9960.86
Number of accounts: 741
Product: InvestmentStock
Average limit: $9955.90
Number of accounts: 1746
Product: InvestmentFund
Average limit: $9951.92
Number of accounts: 728
Product: Derivatives
Average limit: $9951.84
Number of accounts: 706
Product: CurrencyService
Average limit: $9946.09
Number of accounts: 742Os resultados revelam que os produtos Commodity estão associados aos limites médios de conta mais altos, enquanto os produtos CurrencyService têm os mais baixos .
Esse tipo de análise ajuda a identificar correlações entre as ofertas de produtos e a capacidade de gastos dos clientes.
Em seus próprios aplicativos, você pode usar técnicas semelhantes para analisar as vendas por categoria, o envolvimento do usuário por recurso ou os erros por módulo - qualquer cenário em que seja necessário resumir os dados em grupos em vez de examinar registros individuais.
Quando seus dados abrangem várias coleções, o site $lookup ajuda você a reuni-los. Vamos encontrar clientes com suas contas associadas:
pipeline = [
{"$match": {"username": "fmiller"}}, # Find a specific customer
{"$lookup": {
"from": "accounts", # Collection to join with
"localField": "accounts", # Field from customers collection
"foreignField": "account_id", # Field from accounts collection
"as": "account_details" # Name for the new array field
}},
{"$project": {
"name": 1,
"accounts": 1,
"account_details.account_id": 1,
"account_details.limit": 1,
"account_details.products": 1
}}
]
customer_accounts = list(db.customers.aggregate(pipeline))
print(f"Customer: {customer_accounts[0]['name']}")
print(f"Has {len(customer_accounts[0]['account_details'])} accounts:")
for account in customer_accounts[0]['account_details']:
print(f" Account {account['account_id']}: ${account['limit']} limit with products: {', '.join(account['products'])}")Esse pipeline demonstra como você pode unir dados relacionados em coleções:
$match localiza um cliente específico por nome de usuário$lookup executa uma união externa esquerda com a coleção de contas:fromEspecifica com qual coleção você deve se unirlocalField: o campo na coleção atual (clientes) para fazer a correspondênciaforeignField: o campo na coleção de destino (contas) para fazer a correspondência comas: o nome do novo campo de matriz que conterá os documentos correspondentes3. O estágio $project molda a saída para mostrar apenas os campos relevantes
Saída:
Customer: Elizabeth Ray
Has 6 accounts:
Account 371138: $9000 limit with products: Derivatives, InvestmentStock
Account 324287: $10000 limit with products: Commodity, CurrencyService, Derivatives, InvestmentStock
Account 276528: $10000 limit with products: InvestmentFund, InvestmentStock
Account 332179: $10000 limit with products: Commodity, CurrencyService, InvestmentFund, Brokerage, InvestmentStock
Account 422649: $10000 limit with products: CurrencyService, InvestmentStock
Account 387979: $10000 limit with products: Brokerage, Derivatives, InvestmentFund, Commodity, InvestmentStockO resultado fornece uma visão abrangente do portfólio financeiro de Elizabeth Ray, mostrando todas as seis contas dela e seus produtos associados em um único resultado de consulta.
Isso permite que você tenha uma visão completa de 360 graus dos relacionamentos de dados sem precisar de várias consultas ou uniões no lado do cliente.
Para seus próprios aplicativos, considere os casos em que você dividiu os dados entre coleções para fins de normalização, mas precisa reuni-los novamente para análise ou exibição. Exemplos comuns incluem perfis de usuários com histórico de atividades, produtos com status de estoque ou conteúdo com comentários relacionados.
Agora, vamos abordar uma questão comercial mais complexa: "Quais são os limites médios de conta para os clientes, agrupados por seu nível de serviço?" Isso exige que você manipule um objeto aninhado nos documentos do cliente (tier_and_details ) e vincule essas informações à coleção accounts.
Primeiro, para entender a estrutura com a qual estamos lidando na coleção customers, vamos inspecionar o campo tier_and_details e o campo accounts de um cliente de amostra. O campo tier_and_details é um objeto em que cada chave é um identificador de uma assinatura de camada e o valor contém detalhes como o nome da camada. O campo accounts é uma matriz de IDs de contas associadas a esse cliente.
# First, let's look at the structure of 'tier_and_details' again
sample_customer = db.customers.find_one({"username": "fmiller"}) # Using a known customer for consistency
print("Tier structure example for customer 'fmiller':")
print(sample_customer['tier_and_details'])
print(f"Customer 'fmiller' has account IDs: {sample_customer['accounts']}")Saída:
Tier structure example for customer 'fmiller':
{'0df078f33aa74a2e9696e0520c1a828a': {'tier': 'Bronze', 'id': '0df078f33aa74a2e9696e0520c1a828a', 'active': True, 'benefits': ['sports tickets']}, '699456451cc24f028d2aa99d7534c219': {'tier': 'Bronze', 'benefits': ['24 hour dedicated line', 'concierge services'], 'active': True, 'id': '699456451cc24f028d2aa99d7534c219'}}
Customer 'fmiller' has account IDs: [371138, 324287, 276528, 332179, 422649, 387979]pipeline = [
# Step 1: Project necessary fields, including 'accounts' and convert 'tier_and_details'
{"$project": {
"tiers_array": {"$objectToArray": "$tier_and_details"}, # Convert object to array
"customer_account_ids": "$accounts", # Explicitly carry over the customer's account IDs
"_id": 1 # Keep customer _id for later
}},
# Step 2: Unwind the new 'tiers_array' to process each tier object separately
{"$unwind": "$tiers_array"},
# Step 3: Reshape to clearly define the tier and keep customer account IDs
{"$project": {
"tier": "$tiers_array.v.tier", # Extract the tier name
"customer_account_ids": 1, # Ensure account IDs are still present
"customer_id": "$_id" # Rename _id to customer_id for clarity
}},
# Step 4: Look up account details using the customer_account_ids
{"$lookup": {
"from": "accounts", # Target collection
"localField": "customer_account_ids", # Array of account IDs from the customer
"foreignField": "account_id", # Field in the 'accounts' collection
"as": "matched_account_details" # New array with joined account documents
}},
# Step 5: Unwind the 'matched_account_details' array.
{"$unwind": "$matched_account_details"},
# Step 6: Group by tier to calculate statistics
{"$group": {
"_id": "$tier", # Group by the tier name
"avg_limit": {"$avg": "$matched_account_details.limit"}, # Calculate average limit
"total_accounts_in_tier": {"$sum": 1}, # Count how many accounts fall into this tier
"unique_customers_in_tier": {"$addToSet": "$customer_id"} # Count unique customers in this tier
}},
# Step 7: Format the final output
{"$project": {
"tier_name": "$_id", # Rename _id to tier_name
"average_account_limit": "$avg_limit",
"number_of_accounts": "$total_accounts_in_tier",
"number_of_customers": {"$size": "$unique_customers_in_tier"}, # Get the count of unique customers
"_id": 0 # Exclude the default _id
}},
# Step 8: Sort by average limit
{"$sort": {"average_account_limit": -1}}
]
tier_analysis = list(db.customers.aggregate(pipeline))
print("\nTier Analysis Results:")
for tier_data in tier_analysis:
print(f"Tier: {tier_data['tier_name']}")
print(f" Average Account Limit: ${tier_data['average_account_limit']:.2f}")
print(f" Number of Accounts in this Tier: {tier_data['number_of_accounts']}")
print(f" Number of Unique Customers in this Tier: {tier_data['number_of_customers']}")Esse pipeline divide a análise complexa em oito etapas gerenciáveis:
$project: Começamos transformando o objeto tier_and_details. O operador $objectToArray converte esse objeto em uma matriz de pares de valores-chave (tiers_array). Isso é essencial porque estágios como $unwind operam em matrizes. É importante ressaltar que também levamos explicitamente adiante a matriz accounts do documento do cliente como customer_account_ids e o _id do cliente.$unwind: Esse estágio desconstrói o site tiers_array, criando um documento separado para cada entrada de nível que um cliente possa ter. Cada novo documento ainda contém o endereço customer_account_ids e o cliente original _id.$project: Reformulamos o documento para extrair claramente o nome da camada (por exemplo, "Bronze") da estrutura aninhada ($tiers_array.v.tier) e renomeamos o cliente _id para customer_id para maior clareza. Você pode acessar o site customer_account_ids.$lookup: É aqui que nos juntamos à coleção accounts. Usamos o customer_account_ids (a matriz de números de conta do documento do cliente) como localField. O foreignField é o account_id da coleção accounts. O MongoDB encontrará todas as contas cujos account_id is present in the customer_account_ids array, adding them as an array to the matched_account_details field.: We unwind matched_account_details. Now, if a customer-tier combination was linked to multiple accounts, we get a separate document for each specific account, associated with that customer and tier.: We group the documents by tier. For each tier, we calculate the avg_limit using $avg on the limit from the joined account details. We count the total_accounts_in_tier using $sum: 1. We also use $addToSet with customer_id to collect the unique customer IDs belonging to each tier.: The final shaping of our output. We rename _id (which is the tier name from the group stage) to tier_name. We use $size to get the count of unique_customers_in_tier.: We order the results by average_account_limit` em ordem decrescente, para que a camada com o limite médio mais alto apareça primeiro.Tier Analysis Results:
Tier: Silver
Average Account Limit: $9974.55
Number of Accounts in this Tier: 393
Number of Unique Customers in this Tier: 95
Tier: Bronze
Average Account Limit: $9964.11
Number of Accounts in this Tier: 418
Number of Unique Customers in this Tier: 93
Tier: Platinum
Average Account Limit: $9962.53
Number of Accounts in this Tier: 427
Number of Unique Customers in this Tier: 101
Tier: Gold
Average Account Limit: $9962.44
Number of Accounts in this Tier: 426
Number of Unique Customers in this Tier: 99Os resultados agora mostram uma hierarquia ligeiramente diferente: os clientes do nível Silver, em média, têm contas com os limites mais altos, seguidos por Bronze, depois Platinum e, por fim, Gold. T
Esse tipo de insight é valioso para entender os segmentos de clientes. Por exemplo, uma instituição financeira pode usar essas informações para investigar por que os níveis Silver e Bronze têm limites médios tão altos, ou para adaptar campanhas de marketing ou oferecer serviços premium .
O uso do $objectToArray foi fundamental para desbloquear os dados de camadas aninhadas, e a passagem cuidadosa do customer_account_ids garantiu que o nosso $lookup pudesse conectar os clientes às suas contas específicas.
Quando você encontrar objetos aninhados em seus próprios conjuntos de dados que precisem ser usados em agregações (como user preferences, product attributes, ou configuration settings ), lembre-se da técnica $objectToArray .
Certifique-se sempre de que todos os campos necessários para os estágios posteriores, especialmente para as operações do $lookup, estejam explicitamente incluídos nos estágios do $project. Essa abordagem estruturada para decompor dados complexos ajuda a obter insights significativos diretamente no MongoDB.
Além das transformações sequenciais, a estrutura de agregação do MongoDB oferece padrões sofisticados para que você possa lidar com consultas analíticas complexas. Quando você precisa analisar dados de vários ângulos simultaneamente ou realizar cálculos com base em um conjunto contínuo de documentos, esses padrões avançados oferecem soluções poderosas diretamente no banco de dados.
O estágio $facet permite que você execute vários subpipelines de agregação em um único estágio, usando o mesmo conjunto de documentos de entrada. Imagine que você precise categorizar os produtos por faixa de preço e, ao mesmo tempo, listar as cinco marcas de produtos mais populares da mesma coleção de produtos. $facet lida com essas diferentes perspectivas analíticas em paralelo.
Cada subpipeline no site $facet opera de forma independente nos documentos de entrada e produz sua própria matriz de documentos de saída. Isso significa que você pode reunir várias métricas ou resumos - como os necessários para um painel abrangente - tudo em uma única consulta ao banco de dados.
Por exemplo, você pode obter uma contagem do total de usuários ativos, um detalhamento dos usuários por nível de assinatura e uma lista de usuários que ingressaram recentemente, tudo a partir do mesmo conjunto de dados de usuários simultaneamente. Isso permite a criação de relatórios ricos e multifacetados sem a sobrecarga de várias chamadas ao banco de dados, simplificando a recuperação de dados para exibições complexas.
Introduzidas no MongoDB 5.0, as funções de janela realizam cálculos em um conjunto de documentos relacionados ao documento atual, conhecido como "janela".
Isso é útil para dados de séries temporais ou qualquer conjunto de dados ordenados em que o contexto de documentos vizinhos seja importante. Por exemplo, você pode querer calcular uma média móvel de sete dias de vendas ou encontrar a soma cumulativa de transações para cada cliente ao longo do tempo.
As funções de janela são normalmente usadas no estágio $setWindowFields. Essa etapa permite que você defina partições (grupos de documentos, como vendas por produto) e ordem de classificação dentro dessas partições (como por data).
Em seguida, você pode aplicar funções de janela como $avg, $sum, $min, $max, ou funções especializadas como $derivative ou $integral em uma janela definida (por exemplo, os 3 documentos anteriores e o documento atual).
Considere o cálculo de um total de vendas de produtos em andamento. Um pipeline usando o site $setWindowFields pode ter a seguinte aparência:
pipeline = [
{"$match": {"category": "Electronics"}}, # Filter for electronics
{"$sort": {"sale_date": 1}}, # Sort by sale date
{"$setWindowFields": {
"partitionBy": "$product_id", # Calculate running total per product
"sortBy": {"sale_date": 1},
"output": {
"running_total_sales": {
"$sum": "$sale_amount",
"window": {
"documents": ["unbounded", "current"] # Sum from start to current document
}
}
}
}}
]
# electronics_sales_with_running_total = list(db.sales.aggregate(pipeline))Nesse pipeline conceitual, para cada venda eletrônica, um campo running_total_sales é adicionado. Esse campo representa a soma de sale_amount para esse produto desde a venda mais antiga até a venda atual .
Esses cálculos, que antes exigiam lógica complexa do lado do cliente ou várias consultas, agora podem ser feitos diretamente no banco de dados, simplificando o código do aplicativo e melhorando o desempenho da análise de tendências ou de comparações entre períodos.
Os pipelines de agregação do MongoDB fornecem um método estruturado para processar dados diretamente no banco de dados. Ao vincular estágios operacionais distintos, você pode realizar manipulações de dados envolvidas, como filtragem de registros, reformulação de documentos, agrupamento de informações e combinação de dados de várias coleções.
Essa abordagem ajuda a refinar seus fluxos de trabalho de dados, permitindo a extração mais rápida do significado de grandes conjuntos de dados, conforme mostrado nos exemplos do PyMongo. O processamento de dados próximo à sua origem pode, muitas vezes, levar a um melhor desempenho das consultas analíticas.
O desenvolvimento da proficiência com pipelines de agregação prepara você para muitos desafios de análise de dados. Para aplicar o que aprendeu, você pode tentar um projeto prático, como o Building a Retail Data Pipeline.
Para que você tenha uma perspectiva mais ampla dos sistemas de dados e de como as habilidades do MongoDB se encaixam no quadro geral, o programa Engenheiro de dados com Python oferece um aprendizado aprofundado. Se você está procurando progredir na carreira, analisar as perguntas comuns da entrevista do MongoDB também pode ser útil para entender as expectativas típicas de solução de problemas.
Principais cursos da DataCamp
Programa
Curso
Curso
Tutorial
Natassha Selvaraj
Tutorial
Joleen Bothma
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Sejal Jaiswal