
Lernpfad
Dateningenieur in Python
40 Std.
Die Arbeit mit großen Datensätzen stellt oft eine Herausforderung dar, wenn es darum geht, aussagekräftige Muster und Erkenntnisse zu extrahieren und gleichzeitig die Leistung zu erhalten. Wenn deine Anwendungen Daten in MongoDB speichern, kann die Ausführung komplexer Abfragen und Transformationen direkt in der Datenbank viel schneller sein als das Verschieben von Daten in externe Analysetools. MongoDB-Aggregationspipelines bieten eine Lösung, indem sie es dir ermöglichen, Daten direkt dort zu verarbeiten, umzuwandeln und zu analysieren, wo sie sich befinden.
Du kannst benutzerdefinierte Datenverarbeitungsabläufe erstellen, indem du einfache Vorgänge hintereinander schaltest. Jede Stufe in der Pipeline wandelt Dokumente um und leitet die Ergebnisse an die nächste Stufe weiter. Du musst z. B. Datensätze nach Datumsbereichen filtern, sie nach Kategorien gruppieren, statistische Kennzahlen berechnen und die Ausgabe formatieren - und das alles mit einer einzigen Datenbankoperation, die die Daten nahe an ihrer Quelle verarbeitet.
In diesem Artikel lernst du, wie du Aggregationspipelines zur Lösung gängiger Datenprobleme erstellst. Alle Beispiele werden in PyMongo (dem offiziellen Python-Client von MongoDB) demonstriert.
Dieser Artikel konzentriert sich zwar auf Aggregationspipelines, aber wenn du MongoDB mit Python noch nicht kennst , bietet dir der Kurs Einführung in MongoDB in Python einen umfassenden Ausgangspunkt. In diesem Artikel erhältst du genügend Grundlagen, um diese Aggregationskonzepte selbstständig oder mit Hilfe von Sprachmodellen in die Abfragesprache von MongoDB zu übertragen.
Stell dir vor, du musst Kundenrezensionen über mehrere Produkte hinweg analysieren, um Zufriedenheitstrends zu verstehen. Herkömmliche Abfragen können zwar die Daten abrufen, aber sie helfen nicht bei der Kombination, Analyse und Umwandlung dieser Informationen in nützliche Zusammenfassungen.
Die Aggregationspipelines von MongoDB lösen dieses Problem, indem sie einen strukturierten Weg zur Verarbeitung von Daten durch eine Reihe von aufeinander aufbauenden Operationen bieten.
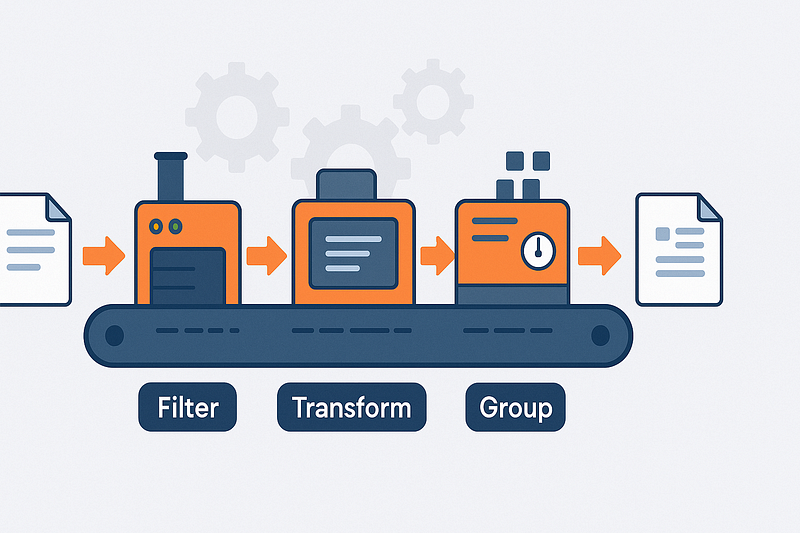
Betrachte die Aggregationspipelines als Fließband für deine Daten. Jedes Dokument aus deiner Sammlung gelangt an ein Ende der Pipeline und durchläuft verschiedene Stationen (Stufen), an denen es gefiltert, umgewandelt, gruppiert oder angereichert wird.
Der Output einer Stufe wird zum Input für die nächste. So kannst du komplexe Datenumwandlungen in kleinere, überschaubare Schritte unterteilen.
Diese Pipelines verwenden einen deklarativen Ansatz: Du gibst in jeder Phase an, was du willst, und nicht, wie es berechnet werden soll. Dieser Ansatz macht die Absichten deiner Datenverarbeitung deutlich und überlässt MongoDB die Ausführung der Details. Die Datenbank kann dann auf der Grundlage deiner Pipelinestruktur verschiedene Optimierungen vornehmen.
Die Reihenfolge der Stufen ist wichtig für die Gestaltung deiner Pipeline. Das frühzeitige Filtern von Dokumenten (vor der Gruppierung oder komplexen Berechnungen) reduziert die Datenmenge, die durch die Pipeline fließt.
Dieser Ansatz kann die Leistung bei der Arbeit mit großen Sammlungen drastisch verbessern. Eine gut strukturierte Pipeline verarbeitet nur die Daten, die du für deine endgültigen Ergebnisse brauchst.
Die MongoDB-Aggregationsstufen lassen sich je nach Zweck in vier Hauptkategorien einteilen. Filterstufen wie $match funktionieren wie Abfragen und wählen nur Dokumente aus, die bestimmte Kriterien erfüllen. So kannst du deinen Datensatz eingrenzen, bevor du komplexere Operationen durchführst.
Umformungsphasen verändern die Dokumentenstruktur. Mit $project oder $addFields kannst du Felder einschließen, ausschließen oder umbenennen oder berechnete Felder auf der Grundlage vorhandener Werte erstellen. Diese Stufen helfen dabei, Dokumente zu vereinfachen, indem nur relevante Informationen beibehalten und für die Analyse benötigte Werte hinzugefügt werden.
Wenn du mehrere Dokumente anhand gemeinsamer Merkmale zusammenfassen musst, kommen Gruppierungsstufen ins Spiel. Die Stufe $group ist hier das Arbeitspferd, mit dem du Zählungen, Summen, Durchschnitte und andere aggregierte Werte über Gruppen von Dokumenten berechnen kannst. Dadurch werden Tausende von Einzeldatensätzen in aussagekräftige Zusammenfassungen verwandelt, die deine analytischen Fragen beantworten.
Um dein Datenbild zu vervollständigen, kannst du mit Join-Stufen wie $lookup Informationen aus verschiedenen Sammlungen kombinieren. Damit kannst du Dokumente mit verwandten Daten anreichern, ähnlich wie bei SQL-Joins, aber angepasst an das Dokumentenmodell von MongoDB. Die Möglichkeit, Daten über verschiedene Sammlungen hinweg zu referenzieren, hilft dabei, die Daten zu normalisieren und trotzdem vollständige Ergebnisse in einem einzigen Vorgang zu liefern.
$match anhand von Kriterien auswählen$project und $addFields$group für aggregierte Werte$lookupEine vollständige Referenz zu den Fähigkeiten und Operatoren findest du im MongoDB Aggregation Pipeline Manual.
Bevor du dich mit MongoDB-Aggregationspipelines beschäftigst, brauchst du eine Arbeitsumgebung mit PyMongo und Zugang zu einem Beispieldatensatz. Dieser Abschnitt führt dich durch den Einrichtungsprozess mit dem sample_analytics-Datensatz, der Finanzdaten enthält, die sich perfekt zur Demonstration von Aggregationskonzepten eignen.
PyMongo ist der offizielle Python-Treiber von MongoDB. Du kannst es mit pip sowohl unter macOS als auch unter Windows installieren:
# Install PyMongo using pip
pip install pymongo
# Or if you're using conda
conda install -c conda-forge pymongoMongoDB bietet Beispieldatensätze, die du verwenden kannst, ohne deine eigenen Daten zu erstellen. Am einfachsten ist es, MongoDB Atlas (die Cloud-Version) zu verwenden:
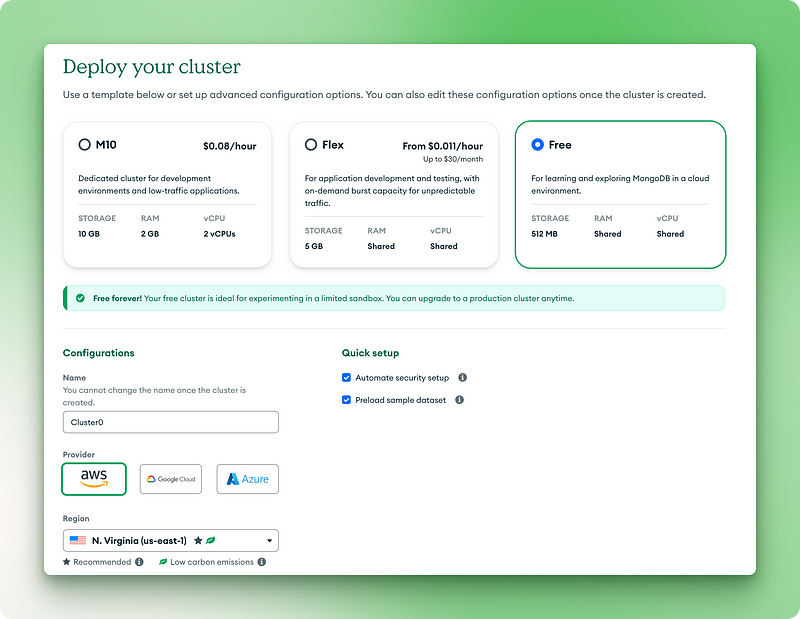
2.1. Wähle die kostenlose Version für immer
2.2. Benenne deinen Cluster
2.3. Klick auf "Bereitstellen"
2.4. Kopiere deinen Benutzernamen und dein Passwort an einen sicheren Ort
2.5. Klicke auf "Datenbankbenutzer erstellen".
2.6. Wähle "Treiber" für deine Verbindungsmethode
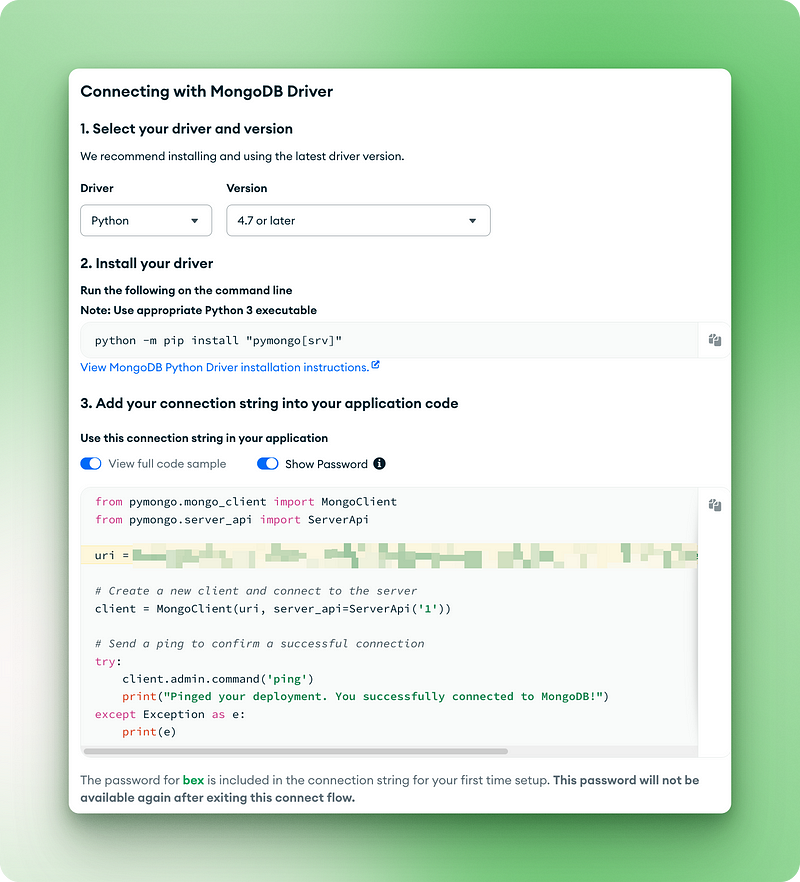
2.7. Kopiere die Verbindungs-URI für den nächsten Schritt
3.1. Klicke auf die drei Punkte in deiner Clusteransicht
3.2. Wähle "Beispieldatensatz laden".
3.3. Wähle aus der Liste sample_analytics und warte, bis sie geladen ist.
Bei lokalen MongoDB-Installationen kannst du die Beispieldatensätze mit laden:
# Download and restore the sample dataset
python -m pip install pymongo[srv]
python -c "from pymongo import MongoClient; MongoClient().admin.command('getParameter', '*')"sample_analytics ist klein genug (~10MB), um gut auf dem Free Tier zu funktionieren.Jetzt, wo du MongoDB und den Beispieldatensatz bereit hast, können wir den Code schreiben, um eine Verbindung herzustellen und unsere Einrichtung zu überprüfen:
from pymongo.mongo_client import MongoClient
from pymongo.server_api import ServerApi
uri = "mongodb+srv://bex:gTVAbSjPzuhRUiyE@cluster0.jdohtoe.mongodb.net/?retryWrites=true&w=majority&appName=Cluster0"
# Create a new client and connect to the server
client = MongoClient(uri, server_api=ServerApi('1'))
# Send a ping to confirm a successful connection
try:
client.admin.command('ping')
print("Pinged your deployment. You successfully connected to MongoDB!")
except Exception as e:
print(e)
Pinged your deployment. You successfully connected to MongoDB!
# Access the sample_analytics database
db = client.sample_analytics
# Verify connection by counting documents in collections
customer_count = db.customers.count_documents({})
account_count = db.accounts.count_documents({})
print(f"Found {customer_count} customers and {account_count} accounts in sample_analytics")
# Preview one document from each collection
print("\nSample customer document:")
print(db.customers.find_one())
print("\nSample account document:")
print(db.accounts.find_one())Ausgabe:
Found 500 customers and 1746 accounts in sample_analytics
Sample customer document:
{'_id': ObjectId('5ca4bbcea2dd94ee58162a68'), 'username': 'fmiller', 'name': 'Elizabeth Ray', 'address': '9286 Bethany Glens\nVasqueztown, CO 22939', 'birthdate': datetime.datetime(1977, 3, 2, 2, 20, 31), 'email': 'arroyocolton@gmail.com', 'active': True, 'accounts': [371138, 324287, 276528, 332179, 422649, 387979], 'tier_and_details': {'0df078f33aa74a2e9696e0520c1a828a': {'tier': 'Bronze', 'id': '0df078f33aa74a2e9696e0520c1a828a', 'active': True, 'benefits': ['sports tickets']}, '699456451cc24f028d2aa99d7534c219': {'tier': 'Bronze', 'benefits': ['24 hour dedicated line', 'concierge services'], 'active': True, 'id': '699456451cc24f028d2aa99d7534c219'}}}
Sample account document:
{'_id': ObjectId('5ca4bbc7a2dd94ee5816238c'), 'account_id': 371138, 'limit': 9000, 'products': ['Derivatives', 'InvestmentStock']}Wenn du diesen Code ausführst, solltest du eine Ausgabe sehen, die die Anzahl der Dokumente und eine Vorschau der Kunden- und Kontodokumente anzeigt. Dies bestätigt, dass deine Umgebung für die Aggregationspipeline-Beispiele bereit ist, die wir in den nächsten Abschnitten untersuchen werden.
Eine Einführung in PyMongo und das lokale MongoDB-Setup findest du in unserem PyMongo-Tutorial für Anfänger.
Nachdem wir nun unsere Verbindung bestätigt und die Dokumentenstruktur erkundet haben, können wir uns mit dem Aggregations-Framework von MongoDB beschäftigen. Diese leistungsstarke Funktion ermöglicht es uns, Daten direkt in der Datenbank zu verarbeiten und umzuwandeln. In diesem Abschnitt werden wir die gängigsten Pipeline-Phasen anhand von praktischen Beispielen mit unserem Beispieldatensatz untersuchen.
Auf der Seite $match werden die Dokumente nach bestimmten Kriterien gefiltert. Betrachte es als eine Möglichkeit, dich auf die Daten zu konzentrieren, die dich interessieren, bevor du komplexere Operationen durchführst.
Lass uns alle Premium-Konten mit einem Limit von über 9.000 $ finden:
pipeline = [
{"$match": {"limit": {"$gt": 9000}}}
]
premium_accounts = list(db.accounts.aggregate(pipeline))
print(f"Found {len(premium_accounts)} premium accounts")
print(premium_accounts[0])Diese Pipeline verwendet die Stufe $match mit einem Vergleichsoperator $gt (größer als), um Konten zu filtern. Sie funktioniert genau wie die Methode find(), aber im Kontext einer Pipeline. Die Abfrage prüft jedes Dokument in der Kontensammlung und behält nur diejenigen, bei denen das Grenzwertfeld 9000 übersteigt.
Ausgabe:
Found 1701 premium accounts
{'_id': ObjectId('5ca4bbc7a2dd94ee5816238d'), 'account_id': 557378, 'limit': 10000, 'products': ['InvestmentStock', 'Commodity', 'Brokerage', 'CurrencyService']}Wenn wir uns die Ergebnisse anschauen, sehen wir, dass die Pipeline 1701 Premium-Konten von den insgesamt 1746 Konten in unserer Datenbank identifiziert hat. Dieser Filterschritt grenzt unseren Fokus ein und macht die anschließende Analyse effizienter und gezielter. In deinen eigenen Projekten könntest du diese Technik nutzen, um dich auf aktive Nutzer/innen, Transaktionen über einem bestimmten Betrag oder Produkte in einer bestimmten Kategorie zu konzentrieren, bevor du eine tiefere Analyse dieser Dokumente durchführst.
Diese Stufen helfen dir zu kontrollieren, welche Felder du einbeziehen und wie du deine Ergebnisse organisieren willst. Hier ist ein Beispiel, das die Top 5 Konten mit den höchsten Limits auflistet und nur die wichtigsten Informationen anzeigt:
pipeline = [
{"$project": {
"_id": 0,
"account_id": 1,
"limit": 1,
"product_count": {"$size": "$products"}
}},
{"$sort": {"limit": -1}},
{"$limit": 5}
]
top_accounts = list(db.accounts.aggregate(pipeline))
for account in top_accounts:
print(account)Diese Pipeline besteht aus drei Stufen, die zusammenarbeiten:
1. In der Phase $project wird jedes Dokument umgestaltet:
_id ausschließen (auf 0 setzen)account_id und limit einbeziehen (sie auf 1 setzen)product_count, das den $size Operator (einenvon vielen Aggregations-Pipeline-Operatoren), um die Elemente im Array "Produkte" zu zählen2. Die $sort Stufe ordnet die Ergebnisse nach dem limit Feld in absteigender Reihenfolge (-1)
3. Die $limit Stufe behält nur die ersten 5 Dokumente nach der Sortierung
Ausgabe:
{'account_id': 674364, 'limit': 10000, 'product_count': 1}
{'account_id': 278603, 'limit': 10000, 'product_count': 2}
{'account_id': 383777, 'limit': 10000, 'product_count': 5}
{'account_id': 557378, 'limit': 10000, 'product_count': 4}
{'account_id': 198100, 'limit': 10000, 'product_count': 3}Die Ausgabe zeigt die fünf Konten mit den höchsten Limits, die alle bei 10.000 USD liegen. Über unser berechnetes Feld product_count können wir auch sehen, wie viele Produkte jedes Konto enthält.
Dies ermöglicht eine übersichtlichere Darstellung der Daten, die sich genau auf das konzentriert, was benötigt wird, anstatt alle Felder zurückzugeben. Wenn du Dashboards oder Berichte für deine eigenen Anwendungen erstellst, kannst du ähnliche Techniken anwenden, um den Nutzern nur die wichtigsten Informationen zu präsentieren, den Datentransfer zu reduzieren und die Benutzeroberfläche zu vereinfachen.
Auf der Seite $group ist die Aggregation besonders gut zu sehen. Du kannst Dokumente in Kategorien einteilen und Kennzahlen für jede Gruppe berechnen. Lass uns das durchschnittliche Kontolimit nach Produktart ermitteln:
pipeline = [
{"$unwind": "$products"}, # First unwind the products array
{"$group": {
"_id": "$products",
"avg_limit": {"$avg": "$limit"},
"count": {"$sum": 1}
}},
{"$sort": {"avg_limit": -1}}
]
product_analysis = list(db.accounts.aggregate(pipeline))
for product in product_analysis:
print(f"Product: {product['_id']}")
print(f" Average limit: ${product['avg_limit']:.2f}")
print(f" Number of accounts: {product['count']}")Diese Pipeline verwendet mehrere Operatoren, um die Produktdaten zu analysieren:
$group Bühne also:_id in $group bestimmt den Gruppierungsschlüssel)$avg Akkumulators$sum: 1 (wobei für jedes Dokument 1 hinzugefügt wird)3. Die $sort stage orders Ergebnisse nach Durchschnittslimit in absteigender Reihenfolge
Output:
Product: Commodity
Average limit: $9963.89
Number of accounts: 720
Product: Brokerage
Average limit: $9960.86
Number of accounts: 741
Product: InvestmentStock
Average limit: $9955.90
Number of accounts: 1746
Product: InvestmentFund
Average limit: $9951.92
Number of accounts: 728
Product: Derivatives
Average limit: $9951.84
Number of accounts: 706
Product: CurrencyService
Average limit: $9946.09
Number of accounts: 742Die Ergebnisse zeigen, dass die Commodity Produkte mit den höchsten durchschnittlichen Kontolimits verbunden sind, während die CurrencyService Produkte die niedrigsten haben .
Diese Art der Analyse hilft dabei, Zusammenhänge zwischen dem Produktangebot und der Kaufkraft der Kunden zu erkennen.
In deinen eigenen Anwendungen könntest du ähnliche Techniken verwenden, um die Verkäufe nach Kategorien, das Nutzerengagement nach Merkmalen oder die Fehler nach Modulen zu analysieren - jedes Szenario, in dem du Daten über Gruppen hinweg zusammenfassen musst, anstatt einzelne Datensätze zu untersuchen.
Wenn sich deine Daten über mehrere Sammlungen erstrecken, hilft dir $lookup, sie zusammenzuführen. Lass uns die Kunden mit ihren zugehörigen Konten finden:
pipeline = [
{"$match": {"username": "fmiller"}}, # Find a specific customer
{"$lookup": {
"from": "accounts", # Collection to join with
"localField": "accounts", # Field from customers collection
"foreignField": "account_id", # Field from accounts collection
"as": "account_details" # Name for the new array field
}},
{"$project": {
"name": 1,
"accounts": 1,
"account_details.account_id": 1,
"account_details.limit": 1,
"account_details.products": 1
}}
]
customer_accounts = list(db.customers.aggregate(pipeline))
print(f"Customer: {customer_accounts[0]['name']}")
print(f"Has {len(customer_accounts[0]['account_details'])} accounts:")
for account in customer_accounts[0]['account_details']:
print(f" Account {account['account_id']}: ${account['limit']} limit with products: {', '.join(account['products'])}")Diese Pipeline zeigt, wie man zusammenhängende Daten über Sammlungen hinweg verbindet:
$match findet einen bestimmten Kunden anhand seines Benutzernamens$lookup führt einen Left Outer Join mit der Kontensammlung durch:from: gibt an, welche Sammlung mit der anderen verbunden werden solllocalField: das Feld in der aktuellen Sammlung (Kunden), das abgeglichen werden sollforeignField: das Feld in der Zielsammlung (Konten), das mitas: der Name für das neue Array-Feld, das die übereinstimmenden Dokumente enthalten wird3. Auf der Seite $project wird die Ausgabe so gestaltet, dass nur relevante Felder angezeigt werden.
Ausgabe:
Customer: Elizabeth Ray
Has 6 accounts:
Account 371138: $9000 limit with products: Derivatives, InvestmentStock
Account 324287: $10000 limit with products: Commodity, CurrencyService, Derivatives, InvestmentStock
Account 276528: $10000 limit with products: InvestmentFund, InvestmentStock
Account 332179: $10000 limit with products: Commodity, CurrencyService, InvestmentFund, Brokerage, InvestmentStock
Account 422649: $10000 limit with products: CurrencyService, InvestmentStock
Account 387979: $10000 limit with products: Brokerage, Derivatives, InvestmentFund, Commodity, InvestmentStockDie Ausgabe bietet einen umfassenden Überblick über das Finanzportfolio von Elizabeth Ray und zeigt alle sechs Konten und die dazugehörigen Produkte in einem einzigen Abfrageergebnis.
Dies ermöglicht einen vollständigen 360-Grad-Blick auf deine Datenbeziehungen, ohne dass mehrere Abfragen oder clientseitige Joins erforderlich sind.
Für deine eigenen Anwendungen solltest du überlegen, ob du die Daten aus Gründen der Normalisierung in verschiedene Sammlungen aufgeteilt hast, sie aber für die Analyse oder Anzeige wieder zusammenführen musst. Häufige Beispiele sind Nutzerprofile mit Aktivitätsverlauf, Produkte mit Inventarstatus oder Inhalte mit zugehörigen Kommentaren.
Kommen wir nun zu einer etwas komplizierteren Geschäftsfrage: "Wie hoch sind die durchschnittlichen Kontolimits für die Kunden, gruppiert nach ihrer Leistungsstufe?" Dazu müssen wir ein verschachteltes Objekt innerhalb unserer Kundendokumente behandeln (tier_and_details ) und diese Informationen dann mit der accounts Sammlung verknüpfen.
Um die Struktur zu verstehen, mit der wir es in der Sammlung customers zu tun haben, sehen wir uns zunächst das Feld tier_and_details und das Feld accounts für einen Beispielkunden an. Das Feld tier_and_details ist ein Objekt, bei dem jeder Schlüssel eine Kennung für ein Tier-Abonnement ist und der Wert Details wie den Tier-Namen enthält. Das Feld accounts ist eine Reihe von Konto-IDs, die mit diesem Kunden verbunden sind.
# First, let's look at the structure of 'tier_and_details' again
sample_customer = db.customers.find_one({"username": "fmiller"}) # Using a known customer for consistency
print("Tier structure example for customer 'fmiller':")
print(sample_customer['tier_and_details'])
print(f"Customer 'fmiller' has account IDs: {sample_customer['accounts']}")Ausgabe:
Tier structure example for customer 'fmiller':
{'0df078f33aa74a2e9696e0520c1a828a': {'tier': 'Bronze', 'id': '0df078f33aa74a2e9696e0520c1a828a', 'active': True, 'benefits': ['sports tickets']}, '699456451cc24f028d2aa99d7534c219': {'tier': 'Bronze', 'benefits': ['24 hour dedicated line', 'concierge services'], 'active': True, 'id': '699456451cc24f028d2aa99d7534c219'}}
Customer 'fmiller' has account IDs: [371138, 324287, 276528, 332179, 422649, 387979]pipeline = [
# Step 1: Project necessary fields, including 'accounts' and convert 'tier_and_details'
{"$project": {
"tiers_array": {"$objectToArray": "$tier_and_details"}, # Convert object to array
"customer_account_ids": "$accounts", # Explicitly carry over the customer's account IDs
"_id": 1 # Keep customer _id for later
}},
# Step 2: Unwind the new 'tiers_array' to process each tier object separately
{"$unwind": "$tiers_array"},
# Step 3: Reshape to clearly define the tier and keep customer account IDs
{"$project": {
"tier": "$tiers_array.v.tier", # Extract the tier name
"customer_account_ids": 1, # Ensure account IDs are still present
"customer_id": "$_id" # Rename _id to customer_id for clarity
}},
# Step 4: Look up account details using the customer_account_ids
{"$lookup": {
"from": "accounts", # Target collection
"localField": "customer_account_ids", # Array of account IDs from the customer
"foreignField": "account_id", # Field in the 'accounts' collection
"as": "matched_account_details" # New array with joined account documents
}},
# Step 5: Unwind the 'matched_account_details' array.
{"$unwind": "$matched_account_details"},
# Step 6: Group by tier to calculate statistics
{"$group": {
"_id": "$tier", # Group by the tier name
"avg_limit": {"$avg": "$matched_account_details.limit"}, # Calculate average limit
"total_accounts_in_tier": {"$sum": 1}, # Count how many accounts fall into this tier
"unique_customers_in_tier": {"$addToSet": "$customer_id"} # Count unique customers in this tier
}},
# Step 7: Format the final output
{"$project": {
"tier_name": "$_id", # Rename _id to tier_name
"average_account_limit": "$avg_limit",
"number_of_accounts": "$total_accounts_in_tier",
"number_of_customers": {"$size": "$unique_customers_in_tier"}, # Get the count of unique customers
"_id": 0 # Exclude the default _id
}},
# Step 8: Sort by average limit
{"$sort": {"average_account_limit": -1}}
]
tier_analysis = list(db.customers.aggregate(pipeline))
print("\nTier Analysis Results:")
for tier_data in tier_analysis:
print(f"Tier: {tier_data['tier_name']}")
print(f" Average Account Limit: ${tier_data['average_account_limit']:.2f}")
print(f" Number of Accounts in this Tier: {tier_data['number_of_accounts']}")
print(f" Number of Unique Customers in this Tier: {tier_data['number_of_customers']}")Diese Pipeline unterteilt die komplexe Analyse in acht überschaubare Schritte:
$project: Wir beginnen mit der Umwandlung des tier_and_details Objekts. Der $objectToArray-Operator wandelt dieses Objekt in ein Array von Schlüssel-Wert-Paaren um (tiers_array). Das ist wichtig, weil Bühnen wie $unwind mit Arrays arbeiten. Entscheidend ist, dass wir auch das accounts Array aus dem Kundendokument als customer_account_ids und das _id des Kunden explizit übertragen.$unwind: In dieser Phase wird die tiers_array dekonstruiert, indem für jede Stufe, die ein Kunde hat, ein eigenes Dokument erstellt wird. Jedes neue Dokument enthält weiterhin die customer_account_ids und den ursprünglichen Kunden _id.$project: Wir formen das Dokument um, um den Namen der Ebene (z.B. "Bronze") eindeutig aus der verschachtelten Struktur ($tiers_array.v.tier) zu extrahieren und benennen den Kunden _id in customer_id um, um Klarheit zu schaffen. Die customer_account_ids werden durchgereicht.$lookup: Hier schließen wir uns der Sammlung accounts an. Wir verwenden die customer_account_ids (das Array der Kontonummern aus dem Kundendokument) als localField. Die foreignField ist account_id aus der accounts Kollektion. MongoDB findet alle Konten, deren account_id is present in the customer_account_ids array, adding them as an array to the matched_account_details field.: We unwind matched_account_details. Now, if a customer-tier combination was linked to multiple accounts, we get a separate document for each specific account, associated with that customer and tier.: We group the documents by tier. For each tier, we calculate the avg_limit using $avg on the limit from the joined account details. We count the total_accounts_in_tier using $sum: 1. We also use $addToSet with customer_id to collect the unique customer IDs belonging to each tier.: The final shaping of our output. We rename _id (which is the tier name from the group stage) to tier_name. We use $size to get the count of unique_customers_in_tier.: We order the results by average_account_limit` in absteigender Reihenfolge, damit die Stufe mit dem höchsten Durchschnittslimit zuerst erscheint.Tier Analysis Results:
Tier: Silver
Average Account Limit: $9974.55
Number of Accounts in this Tier: 393
Number of Unique Customers in this Tier: 95
Tier: Bronze
Average Account Limit: $9964.11
Number of Accounts in this Tier: 418
Number of Unique Customers in this Tier: 93
Tier: Platinum
Average Account Limit: $9962.53
Number of Accounts in this Tier: 427
Number of Unique Customers in this Tier: 101
Tier: Gold
Average Account Limit: $9962.44
Number of Accounts in this Tier: 426
Number of Unique Customers in this Tier: 99Die Ergebnisse zeigen nun eine etwas andere Hierarchie: Kunden der Stufe Silver haben im Durchschnitt die Konten mit den höchsten Limits, gefolgt von Bronze, dann Platinum und schließlich Gold. T
iese Art von Einblick ist wertvoll für das Verständnis von Kundensegmenten. Ein Finanzinstitut könnte diese Informationen zum Beispiel nutzen, um zu untersuchen, warum Silver und Bronze so hohe Durchschnittslimits haben, oder um Marketingkampagnen anzupassen oder Premiumdienste anzubieten .
Die Verwendung von $objectToArray war der Schlüssel, um die Daten der verschachtelten Ebenen zu entschlüsseln, und die sorgfältige Weitergabe von customer_account_ids stellte sicher, dass unser $lookup die Kunden mit ihren spezifischen Konten verbinden konnte.
Wenn du in deinen eigenen Datensätzen auf verschachtelte Objekte stößt, die du in Aggregationen verwenden musst (wie user preferences, product attributes oder configuration settings ), erinnere dich an die $objectToArray Technik .
Achte immer darauf, dass alle Felder, die für spätere Phasen benötigt werden, insbesondere für $lookup, explizit in deinen $project Phasen enthalten sind. Dieser strukturierte Ansatz zum Aufschlüsseln komplexer Daten hilft dabei, direkt in MongoDB aussagekräftige Erkenntnisse zu gewinnen.
Neben sequenziellen Transformationen bietet das Aggregations-Framework von MongoDB ausgefeilte Muster, um komplexe analytische Abfragen zu bewältigen. Wenn du Daten aus mehreren Blickwinkeln gleichzeitig analysieren oder Berechnungen auf der Grundlage einer fortlaufenden Reihe von Dokumenten durchführen musst, bieten diese fortschrittlichen Muster leistungsstarke Lösungen direkt in der Datenbank.
Die $facet-Stufe ermöglicht es dir, mehrere Aggregations-Sub-Pipelines innerhalb einer einzigen Stufe auszuführen und dabei denselben Satz von Eingabedokumenten zu verwenden. Stell dir vor, du musst Produkte nach Preisklassen kategorisieren und gleichzeitig die Top 5 der beliebtesten Produktmarken aus derselben Produktkollektion auflisten. $facet verarbeitet diese verschiedenen Analyseperspektiven parallel.
Jede Sub-Pipeline innerhalb von $facet arbeitet unabhängig von den Eingabedokumenten und produziert ihre eigene Reihe von Ausgabedokumenten. Das bedeutet, dass du verschiedene Metriken oder Zusammenfassungen - wie sie für ein umfassendes Dashboard benötigt werden - in einer einzigen Datenbankabfrage sammeln kannst.
Du könntest zum Beispiel die Gesamtzahl der aktiven Nutzer/innen, eine Aufschlüsselung der Nutzer/innen nach Abonnementstufe und eine Liste der kürzlich beigetretenen Nutzer/innen gleichzeitig aus demselben Nutzerdatensatz abrufen. Dies ermöglicht die Erstellung umfangreicher, vielschichtiger Berichte ohne den Overhead mehrerer Datenbankaufrufe und vereinfacht die Datenabfrage für komplexe Ansichten.
Die in MongoDB 5.0 eingeführten Fensterfunktionen führen Berechnungen in einer Reihe von Dokumenten durch, die mit dem aktuellen Dokument, dem sogenannten "Fenster", verbunden sind.
Dies ist nützlich für Zeitreihendaten oder jeden geordneten Datensatz, bei dem der Kontext von benachbarten Dokumenten wichtig ist. Du könntest zum Beispiel einen gleitenden 7-Tage-Durchschnitt der Verkäufe berechnen oder die kumulierte Summe der Transaktionen für jeden Kunden im Laufe der Zeit ermitteln.
Fensterfunktionen werden normalerweise in der Phase $setWindowFields verwendet. In dieser Phase kannst du Partitionen (Gruppen von Dokumenten, z. B. Verkäufe pro Produkt) und die Sortierreihenfolge innerhalb dieser Partitionen (z. B. nach Datum) festlegen.
Dann kannst du Fensterfunktionen wie $avg, $sum, $min, $max oder spezielle Funktionen wie $derivative oder $integral auf ein bestimmtes Fenster anwenden (z. B. die 3 vorangegangenen Dokumente und das aktuelle Dokument).
Ziehe in Erwägung, eine laufende Summe der Produktverkäufe zu berechnen. Eine Pipeline, die $setWindowFields verwendet, könnte wie folgt aussehen:
pipeline = [
{"$match": {"category": "Electronics"}}, # Filter for electronics
{"$sort": {"sale_date": 1}}, # Sort by sale date
{"$setWindowFields": {
"partitionBy": "$product_id", # Calculate running total per product
"sortBy": {"sale_date": 1},
"output": {
"running_total_sales": {
"$sum": "$sale_amount",
"window": {
"documents": ["unbounded", "current"] # Sum from start to current document
}
}
}
}}
]
# electronics_sales_with_running_total = list(db.sales.aggregate(pipeline))In dieser konzeptionellen Pipeline wird für jeden elektronischen Verkauf ein Feld running_total_sales hinzugefügt. Dieses Feld stellt die Summe der sale_amount für dieses Produkt vom frühesten Verkauf bis zum aktuellen Verkauf dar.
Solche Berechnungen, die bisher eine komplexe Client-seitige Logik oder mehrere Abfragen erforderten, können jetzt direkt in der Datenbank durchgeführt werden, was den Anwendungscode vereinfacht und die Leistung bei Trendanalysen oder Vergleichen zwischen verschiedenen Zeiträumen verbessert.
MongoDB-Aggregationspipelines bieten eine strukturierte Methode zur Verarbeitung von Daten direkt in deiner Datenbank. Durch die Verknüpfung verschiedener Arbeitsschritte kannst du komplexe Datenmanipulationen durchführen, z. B. Datensätze filtern, Dokumente umgestalten, Informationen gruppieren und Daten aus verschiedenen Sammlungen kombinieren.
Dieser Ansatz hilft dir, deine Daten-Workflows zu verfeinern und schneller eine Bedeutung aus großen Datensätzen zu extrahieren, wie die PyMongo-Beispiele zeigen. Die Verarbeitung von Daten in der Nähe ihrer Quelle kann oft zu einer besseren Leistung bei analytischen Abfragen führen.
Wenn du dich mit Aggregationspipelines auskennst, bist du für viele Herausforderungen der Datenanalyse gerüstet. Um das Gelernte anzuwenden, könntest du ein praktisches Projekt wie den Aufbau einer Retail Data Pipeline ausprobieren.
Wenn du eine umfassendere Perspektive auf Datensysteme haben möchtest und wissen willst, wie sich MongoDB-Fähigkeiten in das Gesamtbild einfügen, bietet der Lernpfad Data Engineer with Python vertiefende Informationen. Wenn du beruflich weiterkommen willst, kann es auch hilfreich sein, die üblichen MongoDB-Interview-Fragen durchzugehen, um die typischen Erwartungen an die Problemlösung zu verstehen.
Top DataCamp Kurse
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
