Cours
Introduction à R
4 h
3M
Exécutez et modifiez le code de ce tutoriel en ligne
Exécuter le codeVous souhaitez en savoir plus sur la manipulation des données dans R avec dplyr? Jetez un coup d'œil au cours DataCamp's Data Manipulation in R with dplyr.
Pour comprendre ce qu'est l'opérateur pipe dans R et ce que vous pouvez faire avec lui, il est nécessaire de considérer l'ensemble du tableau, d'apprendre l'histoire qui le sous-tend. Des questions telles que "d'où vient cette étrange combinaison de symboles et pourquoi a-t-elle été créée de la sorte ?" vous viennent peut-être à l'esprit. Vous trouverez les réponses à ces questions et à bien d'autres dans cette section.
Vous pouvez maintenant examiner l'histoire de trois points de vue : d'un point de vue mathématique, d'un point de vue holistique des langages de programmation et du point de vue du langage R lui-même. Vous découvrirez ces trois aspects dans les pages qui suivent !
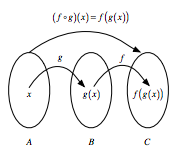
Si vous avez deux fonctions, disons $f : B → C$ et $g : A → B$, vous pouvez enchaîner ces fonctions en prenant la sortie d'une fonction et en l'insérant dans la suivante. En bref, le "chaînage" signifie que vous passez un résultat intermédiaire à la fonction suivante, mais nous y reviendrons plus tard.
Par exemple, vous pouvez dire : $f(g(x))$ : $g(x)$ sert d'entrée à $f()$, tandis que $x$, bien sûr, sert d'entrée à $g()$.
Si vous souhaitez noter cela, vous utiliserez la notation $f ◦ g$, qui se lit comme "f suit g". Vous pouvez également représenter cela visuellement comme suit :
Comme mentionné dans l'introduction de cette section, cet opérateur n'est pas nouveau en programmation : dans le Shell ou le Terminal, vous pouvez passer des commandes de l'une à l'autre avec le caractère pipeline |. De même, le F# dispose d'un opérateur "forward pipe", qui s'avérera important par la suite ! Enfin, il est également bon de savoir que Haskell contient de nombreuses opérations de tuyauterie dérivées du Shell ou du Terminal.
Maintenant que vous avez vu l'historique de l'opérateur pipe dans d'autres langages de programmation, il est temps de se concentrer sur R. L'histoire de cet opérateur dans R commence le 17 janvier 2012, lorsqu'un utilisateur anonyme a posé la question suivante dans ce post de Stack Overflow:
Comment pouvez-vous implémenter l'opérateur forward pipe de F# dans R ? L'opérateur permet d'enchaîner facilement une séquence de calculs. Par exemple, lorsque vous disposez de données d'entrée et que vous souhaitez appeler les fonctions
fooetbardans l'ordre, vous pouvez écriredata |> foo |> bar?
La réponse est venue de Ben Bolker, professeur à l'université McMaster, qui a répondu :
Je ne sais pas si cela résisterait à une utilisation réelle, mais cela semble ( ?) faire ce que vous voulez, au moins pour les fonctions à un seul argument ...
"%>%" <- function(x,f) do.call(f,list(x)) pi %>% sin [1] 1.224606e-16 pi %>% sin %>% cos [1] 1 cos(sin(pi)) [1] 1
Environ neuf mois plus tard, Hadley Wickham a créé le paquet dplyr sur GitHub. Vous connaissez peut-être Hadley, Chief Scientist chez RStudio, en tant qu'auteur de nombreux packages R populaires (comme ce dernier package !) et en tant qu'instructeur du cours Writing Functions in R de DataCamp.
Cependant, ce n'est qu'en 2013 que le premier tuyau %.% apparaît dans ce paquet. Comme le mentionne à juste titre Adolfo Álvarez dans son billet de blog, la fonction a été baptisée chain(), dans le but de simplifier la notation pour l'application de plusieurs fonctions à un seul cadre de données dans R.
Le tuyau %.% n'a pas duré longtemps, car Stefan Bache a proposé une alternative le 29 décembre 2013 qui incluait l'opérateur tel que vous le connaissez maintenant :
iris %>%
subset(Sepal.Length > 5) %>%
aggregate(. ~ Species, ., mean)
Bache a continué à travailler avec cette entreprise de tuyauterie et, à la fin de l'année 2013, le paquet magrittr a vu le jour. Entre-temps, Hadley Wickham a continué à travailler sur dplyr et en avril 2014, l'opérateur %.% a été remplacé par celui que vous connaissez maintenant, %>%.
Plus tard dans l'année, Kun Ren a publié sur GitHub le paquet pipeR, qui intègre un opérateur de tuyauterie différent, %>>%, conçu pour ajouter plus de flexibilité au processus de tuyauterie. Cependant, on peut dire que le site %>% est désormais bien établi dans le langage R, en particulier avec la récente popularité du Tidyverse.
Connaître l'histoire est une chose, mais cela ne vous donne toujours pas une idée de ce qu'est l'opérateur forward pipe de F# ni de ce qu'il fait réellement dans R.
En F#, l'opérateur "pipe-forward" |> est un sucre syntaxique pour les appels de méthodes enchaînés. Ou, plus simplement, elle vous permet de transmettre un résultat intermédiaire à la fonction suivante.
N'oubliez pas que le "chaînage" signifie que vous faites appel à plusieurs méthodes. Comme chaque méthode renvoie un objet, vous pouvez enchaîner les appels dans une seule instruction, sans avoir besoin de variables pour stocker les résultats intermédiaires.
En R, l'opérateur pipe est, comme vous l'avez déjà vu, %>%. Si vous n'êtes pas familier avec F#, vous pouvez considérer que cet opérateur est similaire à + dans une déclaration ggplot2. Sa fonction est très similaire à celle de l'opérateur F# que vous avez vu : il prend la sortie d'une instruction et en fait l'entrée de l'instruction suivante. Lorsque vous le décrivez, vous pouvez l'assimiler à un "ALORS".
Prenez, par exemple, le morceau de code suivant et lisez-le à haute voix :
iris %>%
subset(Sepal.Length > 5) %>%
aggregate(. ~ Species, ., mean)
Vous avez raison, le morceau de code ci-dessus se traduira par quelque chose comme "vous prenez les données Iris, puis vous sous-ensemblez les données et enfin vous agrégez les données".
C'est l'une des choses les plus puissantes du Tidyverse. En fait, le fait de disposer d'une chaîne normalisée d'actions de traitement est appelé "pipeline". Il est intéressant de créer des pipelines pour un format de données, car vous pouvez appliquer ce pipeline à des données entrantes ayant le même format et les produire dans un format adapté à ggplot2, par exemple.
R est un langage fonctionnel, ce qui signifie que votre code contient souvent de nombreuses parenthèses, ( et ). Lorsque vous avez un code complexe, cela signifie souvent que vous devez imbriquer ces parenthèses les unes dans les autres. Cela rend votre code R difficile à lire et à comprendre. C'est ici que %>% vient à la rescousse !
Regardez l'exemple suivant, qui est un exemple typique de code imbriqué :
# Initialize `x`
x <- c(0.109, 0.359, 0.63, 0.996, 0.515, 0.142, 0.017, 0.829, 0.907)
# Compute the logarithm of `x`, return suitably lagged and iterated differences,
# compute the exponential function and round the result
round(exp(diff(log(x))), 1)
Avec l'aide de %<%, vous pouvez réécrire le code ci-dessus comme suit :
# Import `magrittr`
library(magrittr)
# Perform the same computations on `x` as above
x %>% log() %>%
diff() %>%
exp() %>%
round(1)
Cela vous semble-t-il difficile ? Ne vous inquiétez pas ! Vous en saurez plus sur la façon de procéder plus loin dans ce tutoriel.
Notez que vous devez importer la bibliothèquemagrittr pour que le code ci-dessus fonctionne. C'est parce que l'opérateur pipe fait partie, comme vous l'avez lu plus haut, de la bibliothèque magrittr et, depuis 2014, également de dplyr. Si vous oubliez d'importer la bibliothèque, vous obtiendrez une erreur du type Error in eval(expr, envir, enclos): could not find function "%>%".
Notez également qu'il n'est pas obligatoire d'ajouter des parenthèses après log, diff et exp, mais, au sein de la communauté R, certains l'utilisent pour améliorer la lisibilité du code.
En résumé, voici quatre raisons pour lesquelles vous devriez utiliser les pipes dans R :
Ces raisons sont tirées de la documentation demagrittr . Implicitement, les arguments de lisibilité et de flexibilité reviennent.
Bien que %>% soit l'opérateur pipe (principal) du paquet magrittr, il existe quelques autres opérateurs que vous devez connaître et qui font partie du même paquet :
%<>%;# Initialize `x`
x <- rnorm(100)
# Update value of `x` and assign it to `x`
x %<>% abs %>% sort
%T>%;rnorm(200) %>%
matrix(ncol = 2) %T>%
plot %>%
colSums
Notez qu' il est bon de savoir pour l'instant que le morceau de code ci-dessus est en fait un raccourci pour :
rnorm(200) %>%
matrix(ncol = 2) %T>%
{ plot(.); . } %>%
colSums
Mais vous en saurez plus plus tard !
%$%.data.frame(z = rnorm(100)) %$%
ts.plot(z)
Bien entendu, ces trois opérateurs fonctionnent légèrement différemment de l'opérateur principal %>%. Vous en saurez plus sur leurs fonctionnalités et leur utilisation plus loin dans ce tutoriel.
Notez que même si vous verrez le plus souvent les tuyaux magrittr, vous pourrez également rencontrer d'autres tuyaux au fur et à mesure de votre progression ! Voici quelques exemples wraprLe tuyau point arrow de 's' %.>% ou le tuyau to dot %>.%, ou le tuyau Bizarro ->.;.
Maintenant que vous connaissez l'origine de l'opérateur %>%, ce qu'il est réellement et pourquoi vous devez l'utiliser, il est temps pour vous de découvrir comment vous pouvez l'utiliser à votre avantage. Vous verrez qu'il y a plusieurs façons de l'utiliser !
Avant d'aborder les utilisations plus avancées de l'opérateur, il est bon de jeter un coup d'œil aux exemples les plus basiques qui utilisent l'opérateur. En substance, vous verrez qu'il existe trois règles à suivre lorsque vous commencez à travailler :
f(x) peut être réécrite comme suit x %>% fEn bref, cela signifie que les fonctions qui prennent un argument, function(argument), peuvent être réécrites comme suit : argument %>% function(). Regardez l'exemple suivant, plus pratique, pour comprendre comment ces deux éléments sont équivalents :
# Compute the logarithm of `x`
log(x)
# Compute the logarithm of `x`
x %>% log()
f(x, y) peut être réécrite comme suit x %>% f(y)Bien entendu, il existe de nombreuses fonctions qui ne prennent pas seulement un argument, mais plusieurs. C'est le cas ici : vous voyez que la fonction prend deux arguments, x et y. Comme dans le premier exemple, vous pouvez réécrire la fonction en suivant la structure argument1 %>% function(argument2), où argument1 est l'espace réservé magrittr et argument2 l'appel de la fonction.
Tout cela semble bien théorique. Prenons un exemple plus concret :
# Round pi
round(pi, 6)
# Round pi
pi %>% round(6)
x %>% f %>% g %>% h peut être réécrite comme suit h(g(f(x)))Cela peut sembler complexe, mais ce n'est pas tout à fait le cas lorsque vous examinez un exemple R réel :
# Import `babynames` data
library(babynames)
# Import `dplyr` library
library(dplyr)
# Load the data
data(babynames)
# Count how many young boys with the name "Taylor" are born
sum(select(filter(babynames,sex=="M",name=="Taylor"),n))
# Do the same but now with `%>%`
babynames%>%filter(sex=="M",name=="Taylor")%>%
select(n)%>%
sum
Notez que vous travaillez de l'intérieur vers l'extérieur lorsque vous réécrivez le code imbriqué : vous introduisez d'abord babynames, puis vous utilisez %>% pour commencer filter() les données. Ensuite, vous sélectionnerez n et, enfin, vous ferez en sorte que tout soit sum().
Rappelez-vous également que vous avez déjà vu un autre exemple d'un tel code imbriqué qui a été converti en un code plus lisible au début de ce tutoriel, où vous avez utilisé les fonctions log(), diff(), exp() et round() pour effectuer des calculs sur x.
Malheureusement, il existe quelques exceptions aux règles générales exposées dans la section précédente. Nous allons en examiner quelques-uns ici.
Prenons l'exemple suivant, dans lequel vous utilisez la fonction assign() pour affecter la valeur 10 à la variable x.
# Assign `10` to `x`
assign("x", 10)
# Assign `100` to `x`
"x" %>% assign(100)
# Return `x`
x
10
Vous voyez que le deuxième appel à la fonction assign(), en combinaison avec le tuyau, ne fonctionne pas correctement. La valeur de x n'est pas mise à jour.
Comment cela se fait-il ?
En effet, la fonction attribue la nouvelle valeur 100 à un environnement temporaire utilisé par %>%. Par conséquent, si vous souhaitez utiliser assign() avec le pipe, vous devez être explicite quant à l'environnement :
# Define your environment
env <- environment()
# Add the environment to `assign()`
"x" %>% assign(100, envir = env)
# Return `x`
x
100
Les arguments des fonctions ne sont calculés que lorsque la fonction les utilise dans R. Cela signifie qu'aucun argument n'est calculé avant que vous n'appeliez votre fonction. Cela signifie également que le tuyau calcule chaque élément de la fonction à tour de rôle.
Ce problème se pose notamment à l'adresse tryCatch(), qui vous permet de capturer et de gérer les erreurs, comme dans l'exemple suivant :
tryCatch(stop("!"), error = function(e) "An error")
stop("!") %>%
tryCatch(error = function(e) "An error")
Une erreur
Error in eval(expr, envir, enclos): !
Traceback:
1. stop("!") %>% tryCatch(error = function(e) "An error")
2. eval(lhs, parent, parent)
3. eval(expr, envir, enclos)
4. stop("!")
Vous constaterez que la manière imbriquée d'écrire cette ligne de code fonctionne parfaitement, alors que la solution avec le tuyau renvoie une erreur. D'autres fonctions ayant le même comportement sont try(), suppressMessages(), et suppressWarnings() dans la base R.
Dans certains cas, vous pouvez également utiliser l'opérateur pipe pour remplacer un argument. Examinez les exemples suivants :
f(x, y) peut être réécrite comme suit y %>% f(x, .)Dans certains cas, vous ne voudrez pas que la valeur ou le caractère générique magrittr de l'appel de fonction se trouve en première position, ce qui a été le cas dans tous les exemples que vous avez vus jusqu'à présent. Reconsidérez cette ligne de code :
pi %>% round(6)
Si vous réécriviez cette ligne de code, pi serait le premier argument de votre fonction round(). Mais qu'en est-il si vous souhaitez remplacer le deuxième, le troisième, ... argument et l'utiliser comme magrittr placeholder pour votre appel de fonction ?
Regardez cet exemple, où la valeur se trouve en fait à la troisième position dans l'appel de fonction :
"Ceci n'est pas une pipe" %>% gsub("une", "un", .)
Ceci n'est pas un tuyau
f(y, z = x) peut être réécrite comme suit x %>% f(y, z = .)De même, vous pouvez souhaiter que la valeur d'un argument spécifique dans votre appel de fonction soit le caractère générique magrittr. Considérez la ligne de code suivante :
6 %>% round(pi, digits=.)
Il est facile d'utiliser le caractère générique plusieurs fois dans une expression de droite. Toutefois, lorsque le caractère générique n'apparaît que dans une expression imbriquée, magrittr applique toujours la règle du premier argument. La raison en est que, dans la plupart des cas, cela permet d'obtenir un code plus propre.
Voici quelques "règles" générales que vous pouvez prendre en compte lorsque vous travaillez avec des caractères de remplacement d'argument dans des appels de fonction imbriqués :
f(x, y = nrow(x), z = ncol(x)) peut être réécrite comme suit x %>% f(y = nrow(.), z = ncol(.))# Initialize a matrix `ma`
ma <- matrix(1:12, 3, 4)
# Return the maximum of the values inputted
max(ma, nrow(ma), ncol(ma))
# Return the maximum of the values inputted
ma %>% max(nrow(ma), ncol(ma))
12
12
Ce comportement peut être annulé en plaçant le côté droit entre accolades :
f(y = nrow(x), z = ncol(x)) peut être réécrite comme suit x %>% {f(y = nrow(.), z = ncol(.))}# Only return the maximum of the `nrow(ma)` and `ncol(ma)` input values
ma %>% {max(nrow(ma), ncol(ma))}
4
Pour conclure, jetez également un coup d'œil à l'exemple suivant, dans lequel vous pourriez éventuellement vouloir ajuster le fonctionnement de l'espace réservé à l'argument dans l'appel de fonction imbriqué :
# The function that you want to rewrite
paste(1:5, letters[1:5])
# The nested function call with dot placeholder
1:5 %>%
paste(., letters[.])
Vous voyez que si le placeholder n'est utilisé que dans un appel de fonction imbriqué, le placeholder magrittr sera également placé comme premier argument ! Si vous voulez éviter cela, vous pouvez utiliser les parenthèses fléchées { et }:
# The nested function call with dot placeholder and curly brackets
1:5 %>% {
paste(letters[.])
}
# Rewrite the above function call
paste(letters[1:5])
Les fonctions unaires sont des fonctions qui prennent un seul argument. Tout pipeline composé d'un point ., suivi de fonctions et enchaîné avec %>% peut être utilisé ultérieurement si vous souhaitez l'appliquer à des valeurs. Examinez l'exemple suivant d'un tel pipeline :
. %>% cos %>% sin
Ce pipeline prendrait une entrée, après quoi les fonctions cos() et sin() lui seraient appliquées.
Mais vous n'en êtes pas encore là ! Si vous voulez que ce pipeline fasse exactement ce que vous venez de lire, vous devez d'abord l'affecter à une variable f, par exemple. Vous pouvez ensuite le réutiliser pour effectuer les opérations contenues dans le pipeline sur d'autres valeurs.
# Unary function
f <- . %>% cos %>% sin
f
structure(function (value)
freduce(value, `_function_list`), class = c("fseq", "function"
))N'oubliez pas non plus que vous pouvez mettre des parenthèses après les fonctions cos() et sin() dans la ligne de code si vous souhaitez améliorer la lisibilité. Considérez le même exemple avec des parenthèses : . %>% cos() %>% sin().
Vous voyez, construire des fonctions dans magrittr est très similaire à construire des fonctions avec base R ! Si vous n'êtes pas sûr de leur similitude, regardez la ligne ci-dessus et comparez-la avec la ligne de code suivante ; les deux lignes donnent le même résultat !
# is equivalent to
f <- function(.) sin(cos(.))
f
function (.)
sin(cos(.))Dans certains cas, vous souhaitez écraser la valeur du côté gauche, comme dans l'exemple ci-dessous. Intuitivement, vous utiliserez l'opérateur d'affectation <- pour ce faire.
# Load in the Iris data
iris <- read.csv(url("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"), header = FALSE)
# Add column names to the Iris data
names(iris) <- c("Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width", "Species")
# Compute the square root of `iris$Sepal.Length` and assign it to the variable
iris$Sepal.Length <-
iris$Sepal.Length %>%
sqrt()
Toutefois, il existe un opérateur de pipe d'affectation composé, qui vous permet d'utiliser une notation abrégée pour affecter le résultat de votre pipeline immédiatement au côté gauche :
# Compute the square root of `iris$Sepal.Length` and assign it to the variable
iris$Sepal.Length %<>% sqrt
# Return `Sepal.Length`
iris$Sepal.Length
Notez que l'opérateur d'affectation composé %<>% doit être le premier opérateur de tuyauterie de la chaîne pour que cela fonctionne. Ceci est tout à fait conforme à ce que vous venez de lire sur le fait que l'opérateur est une notation abrégée pour une notation plus longue avec répétition, où vous utilisez l'opérateur d'affectation ordinaire <-.
Par conséquent, cet opérateur affectera le résultat d'un pipeline au lieu de le renvoyer.
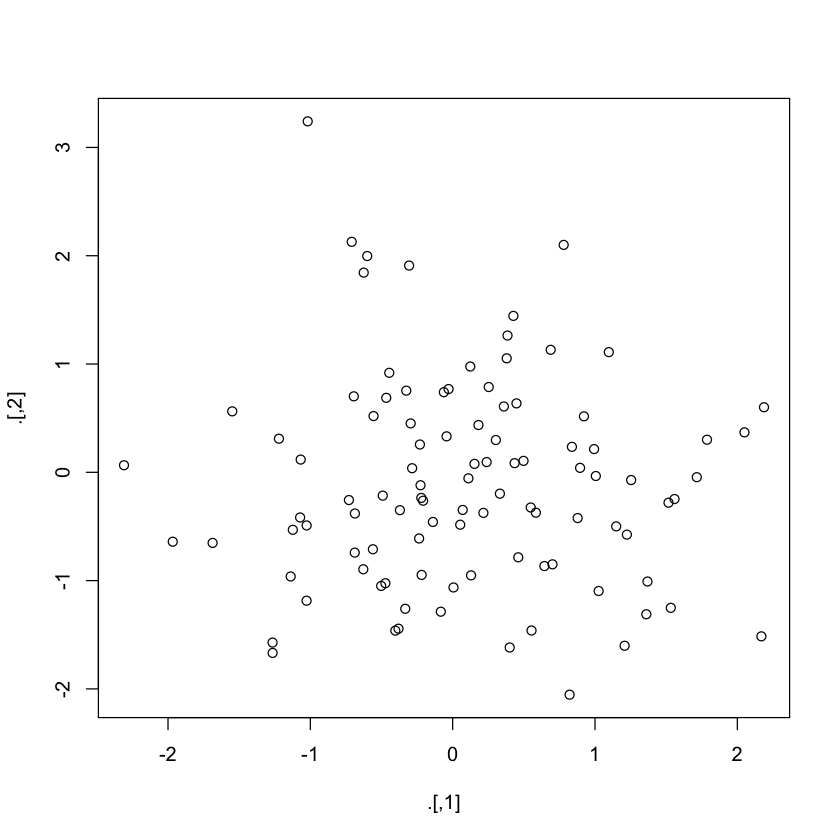
L'opérateur tee fonctionne exactement comme %>%, mais il renvoie la valeur du côté gauche plutôt que le résultat potentiel des opérations du côté droit.
Cela signifie que l'opérateur tee peut s'avérer utile dans les situations où vous avez inclus des fonctions qui sont utilisées pour leur effet secondaire, comme le traçage avec plot() ou l'impression dans un fichier.
En d'autres termes, les fonctions telles que plot() ne renvoient généralement rien. Cela signifie qu'après avoir appelé plot(), par exemple, votre pipeline se termine. Cependant, dans l'exemple suivant, l'opérateur tee %T>% vous permet de continuer votre pipeline même après avoir utilisé plot():
set.seed(123)
rnorm(200) %>%
matrix(ncol = 2) %T>%
plot %>%
colSums
Lorsque vous travaillez avec R, vous constatez que de nombreuses fonctions prennent un argument data. Considérez, par exemple, la fonctionlm() ou la fonctionwith() . Ces fonctions sont utiles dans un pipeline où vos données sont d'abord traitées, puis transmises à la fonction.
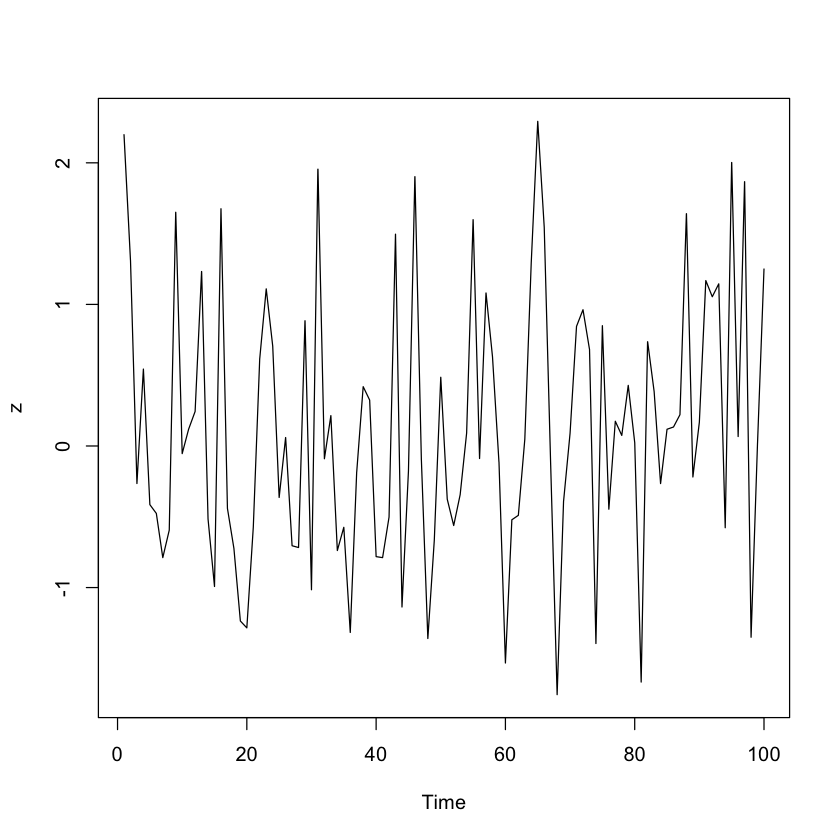
Pour les fonctions qui n'ont pas d'argument data, comme la fonction cor(), il est toujours utile de pouvoir exposer les variables dans les données. C'est là qu'intervient l'opérateur %$%. Prenons l'exemple suivant :
iris %>%
subset(Sepal.Length > mean(Sepal.Length)) %$%
cor(Sepal.Length, Sepal.Width)
0.336696922252551
Avec l'aide de %$%, vous vous assurez que Sepal.Length et Sepal.Width sont exposés à cor(). De même, vous voyez que les données de la fonction data.frame() sont transmises à la fonction ts.plot() pour tracer plusieurs séries temporelles sur un graphique commun :
data.frame(z = rnorm(100)) %$%
ts.plot(z)
dplyr et magrittrDans l'introduction de ce tutoriel, vous avez déjà appris que le développement de dplyr et magrittr a eu lieu à peu près au même moment, à savoir vers 2013-2014. Et, comme vous l'avez lu, le paquet magrittr fait également partie du Tidyverse.
Dans cette section, vous découvrirez à quel point il peut être intéressant de combiner les deux paquets dans votre code R.
Pour ceux d'entre vous qui ne connaissent pas le paquet dplyr, sachez que ce paquet R a été construit autour de cinq verbes, à savoir "select", "filter", "arrange", "mutate" et "summarize". Si vous avez déjà manipulé des données dans le cadre d'un projet de science des données, vous savez que ces verbes constituent la majorité des tâches de manipulation de données que vous devez généralement effectuer sur vos données.
Prenons l'exemple d'un code traditionnel qui utilise ces fonctions dplyr:
library(hflights)
grouped_flights <- group_by(hflights, Year, Month, DayofMonth)
flights_data <- select(grouped_flights, Year:DayofMonth, ArrDelay, DepDelay)
summarized_flights <- summarise(flights_data,
arr = mean(ArrDelay, na.rm = TRUE),
dep = mean(DepDelay, na.rm = TRUE))
final_result <- filter(summarized_flights, arr > 30 | dep > 30)
final_result
| Année | Mois | Jour du mois | arr | dep |
|---|---|---|---|---|
| 2011 | 2 | 4 | 44.08088 | 47.17216 |
| 2011 | 3 | 3 | 35.12898 | 38.20064 |
| 2011 | 3 | 14 | 46.63830 | 36.13657 |
| 2011 | 4 | 4 | 38.71651 | 27.94915 |
| 2011 | 4 | 25 | 37.79845 | 22.25574 |
| 2011 | 5 | 12 | 69.52046 | 64.52039 |
| 2011 | 5 | 20 | 37.02857 | 26.55090 |
| 2011 | 6 | 22 | 65.51852 | 62.30979 |
| 2011 | 7 | 29 | 29.55755 | 31.86944 |
| 2011 | 9 | 29 | 39.19649 | 32.49528 |
| 2011 | 10 | 9 | 61.90172 | 59.52586 |
| 2011 | 11 | 15 | 43.68134 | 39.23333 |
| 2011 | 12 | 29 | 26.30096 | 30.78855 |
| 2011 | 12 | 31 | 46.48465 | 54.17137 |
Lorsque vous regardez cet exemple, vous comprenez immédiatement pourquoi dplyr et magrittr sont capables de travailler si bien ensemble :
hflights %>%
group_by(Year, Month, DayofMonth) %>%
select(Year:DayofMonth, ArrDelay, DepDelay) %>%
summarise(arr = mean(ArrDelay, na.rm = TRUE), dep = mean(DepDelay, na.rm = TRUE)) %>%
filter(arr > 30 | dep > 30)
Les deux morceaux de code sont assez longs, mais on pourrait dire que le deuxième morceau de code est plus clair si vous voulez suivre toutes les opérations. En créant des variables intermédiaires dans le premier morceau de code, vous risquez de perdre le "flux" du code. En utilisant %>%, vous obtenez une vue d'ensemble plus claire des opérations effectuées sur les données !
En bref, dplyr et magrittr sont l'équipe idéale pour manipuler des données dans R !
L'ajout de tous ces tuyaux à votre code R peut être un véritable défi ! Pour vous faciliter la vie, John Mount, cofondateur et consultant principal de Win-Vector, LLC et instructeur à DataCamp, a publié un paquet contenant des compléments RStudio qui vous permettent de créer des raccourcis clavier pour les tuyaux dans R. Les compléments sont en fait des fonctions R avec un peu de métadonnées d'enregistrement spéciales. Un addin simple peut, par exemple, être une fonction qui insère un extrait de texte couramment utilisé, mais il peut aussi être très complexe !
Grâce à ces compléments, vous pourrez exécuter des fonctions R de manière interactive à partir de l'IDE RStudio, soit en utilisant des raccourcis clavier, soit en passant par le menu Compléments.
Notez que ce paquet est en fait un dérivé du paquet de modules d'extension original de RStudio. Attention cependant, la prise en charge des addins n'est disponible que dans la version la plus récente de RStudio ! Consultez cet article sur les addins RStudio pour en savoir plus sur le sujet.
Vous pouvez télécharger les compléments et les raccourcis clavier sur GitHub.
Dans ce qui précède, vous avez vu que les pipes sont définitivement quelque chose que vous devriez utiliser lorsque vous programmez avec R. Plus précisément, vous l'avez vu en couvrant quelques cas dans lesquels les pipes s'avèrent être très utiles ! Cependant, il existe certaines situations, décrites par Hadley Wickham dans "R for Data Science", dans lesquelles vous pouvez les éviter au mieux :
Dans de tels cas, il est préférable de créer des objets intermédiaires avec des noms significatifs. Il vous sera non seulement plus facile de déboguer votre code, mais vous comprendrez également mieux votre code et il sera plus facile pour les autres de comprendre votre code.
Si vous ne transformez pas un objet primaire, mais que deux objets ou plus sont combinés ensemble, il est préférable de ne pas utiliser le tuyau.
Les tuyaux sont fondamentalement linéaires et l'expression de relations complexes avec eux n'aboutira qu'à un code complexe qui sera difficile à lire et à comprendre.
L'utilisation de tuyaux pour le développement de paquets internes est à proscrire, car elle rend le débogage plus difficile !
Pour plus de réflexions sur ce sujet, consultez cette discussion Stack Overflow. Les boucles, les dépendances des paquets, l'ordre des arguments et la lisibilité sont d'autres situations qui apparaissent dans cette discussion.
En bref, vous pourriez résumer la situation comme suit : gardez à l'esprit les deux éléments qui font la force de cette construction, à savoir la lisibilité et la flexibilité. Dès que l'un de ces deux grands avantages est compromis, vous pouvez envisager des alternatives en faveur des tuyaux.
Après tout ce que vous avez lu, vous serez peut-être intéressé par les alternatives qui existent dans le langage de programmation R. Certaines des solutions que vous avez vues dans ce tutoriel étaient les suivantes :
Au lieu d'enchaîner toutes les opérations et de produire un seul résultat, décomposez la chaîne et veillez à enregistrer les résultats intermédiaires dans des variables distinctes. Faites attention au nom de ces variables : l'objectif doit toujours être de rendre votre code aussi compréhensible que possible !
L'une des objections possibles que vous pourriez avoir contre les pipes est le fait que cela va à l'encontre du "flux" auquel vous avez été habitué avec la base R. La solution est alors de s'en tenir à l'imbrication de votre code ! Mais que faire si vous n'aimez pas les tuyaux et que vous pensez que l'imbrication peut être déroutante ? La solution peut consister à utiliser des onglets pour mettre en évidence la hiérarchie.
Vous avez couvert beaucoup de terrain dans ce tutoriel sur les pipes R : vous avez vu d'où vient %>%, ce qu'il est exactement, pourquoi vous devriez l'utiliser et comment vous devriez l'utiliser. Vous avez vu que les paquets dplyr et magrittr fonctionnent parfaitement ensemble et qu'il existe encore d'autres opérateurs. Enfin, vous avez également vu quelques cas dans lesquels vous ne devriez pas l'utiliser lorsque vous programmez en R et quelles alternatives vous pouvez utiliser dans ces cas.
Si vous souhaitez en savoir plus sur le Tidyverse, vous pouvez suivre le cours Introduction au Tidyverse de DataCamp.
R Cours
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach