Curso
Introdução ao R
4 h
3M
Execute e edite o código deste tutorial online
Executar códigoVocê tem interesse em aprender mais sobre a manipulação de dados em R com dplyr? Dê uma olhada no curso DataCamp's Data Manipulation in R with dplyr.
Para entender o que é o operador pipe no R e o que você pode fazer com ele, é necessário considerar o quadro completo e conhecer a história por trás dele. Perguntas como "de onde vem essa estranha combinação de símbolos e por que ela foi feita assim?" podem estar em sua mente. Você descobrirá as respostas para essas e outras perguntas nesta seção.
Agora, você pode analisar a história de três perspectivas: de um ponto de vista matemático, de um ponto de vista holístico das linguagens de programação e do ponto de vista da própria linguagem R. Você abordará todos os três no que se segue!
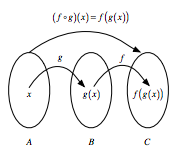
Se você tiver duas funções, digamos $f : B → C$ e $g : A → B$, você pode encadear essas funções pegando a saída de uma função e inserindo-a na próxima. Em resumo, "encadeamento" significa que você passa um resultado intermediário para a próxima função, mas você verá mais sobre isso mais tarde.
Por exemplo, você pode dizer $f(g(x))$: $g(x)$ serve como entrada para $f()$, enquanto $x$, é claro, serve como entrada para $g()$.
Se quiser anotar isso, você usará a notação $f ◦ g$, que significa "f segue g". Como alternativa, você pode representar isso visualmente como:
Conforme mencionado na introdução desta seção, esse operador não é novo na programação: no Shell ou no Terminal, você pode passar o comando de um para o outro com o caractere de pipeline |. Da mesma forma, o F# tem um operador de pipe para frente, que se mostrará importante mais adiante! Por fim, também é bom saber que o Haskell contém muitas operações de piping derivadas do Shell ou do Terminal.
Agora que você já viu um pouco da história do operador pipe em outras linguagens de programação, é hora de focar no R. A história desse operador no R começa em 17 de janeiro de 2012, quando um usuário anônimo fez a seguinte pergunta neste post do Stack Overflow:
Como você pode implementar o operador forward pipe do F# no R? O operador possibilita o encadeamento fácil de uma sequência de cálculos. Por exemplo, quando você tem um dado de entrada e deseja chamar as funções
fooebarem sequência, você pode escreverdata |> foo |> bar?
A resposta veio de Ben Bolker, professor da Universidade McMaster, que respondeu:
Não sei até que ponto isso se sustentaria em um uso real, mas isso parece (?) fazer o que você quer, pelo menos para funções de argumento único...
"%>%" <- function(x,f) do.call(f,list(x)) pi %>% sin [1] 1.224606e-16 pi %>% sin %>% cos [1] 1 cos(sin(pi)) [1] 1
Cerca de nove meses depois, Hadley Wickham iniciou o pacote dplyr no GitHub. Talvez você já conheça Hadley, cientista-chefe do RStudio, como autor de muitos pacotes populares do R (como este último pacote!) e como instrutor do curso Writing Functions in R do DataCamp.
No entanto, foi somente em 2013 que o primeiro tubo %.% apareceu nesse pacote. Como Adolfo Álvarez menciona corretamente em sua postagem no blog, a função foi denominada chain(), que tinha o objetivo de simplificar a notação para a aplicação de várias funções a um único quadro de dados no R.
O tubo %.% não ficaria por muito tempo, pois Stefan Bache propôs uma alternativa em 29 de dezembro de 2013 que incluía a operadora como você a conhece agora:
iris %>%
subset(Sepal.Length > 5) %>%
aggregate(. ~ Species, ., mean)
A Bache continuou a trabalhar com essa operação de tubulação e, no final de 2013, o pacote magrittr foi criado. Nesse meio tempo, Hadley Wickham continuou a trabalhar em dplyr e, em abril de 2014, o operador %.% foi substituído por aquele que você conhece agora, %>%.
Mais tarde naquele ano, Kun Ren publicou o pacote pipeR no GitHub, que incorporou um operador de tubulação diferente, %>>%, que foi projetado para adicionar mais flexibilidade ao processo de tubulação. No entanto, é seguro dizer que o %>% agora está estabelecido na linguagem R, especialmente com a recente popularidade do Tidyverse.
Conhecer a história é uma coisa, mas isso ainda não lhe dá uma ideia do que é o operador forward pipe do F# nem o que ele realmente faz no R.
No F#, o operador de pipe-forward |> é um açúcar sintático para chamadas de método encadeadas. Ou, dito de forma mais simples, permite que você passe um resultado intermediário para a próxima função.
Lembre-se de que "encadeamento" significa que você invoca várias chamadas de método. Como cada método retorna um objeto, é possível permitir que as chamadas sejam encadeadas em uma única instrução, sem a necessidade de variáveis para armazenar os resultados intermediários.
No R, o operador de pipe é, como você já viu, %>%. Se não estiver familiarizado com o F#, você pode pensar nesse operador como sendo semelhante ao + em uma instrução ggplot2. Sua função é muito semelhante àquela que você viu do operador F#: ele pega a saída de uma instrução e a transforma na entrada da próxima instrução. Ao descrevê-lo, você pode pensar nele como um "ENTÃO".
Pegue, por exemplo, o seguinte trecho de código e leia-o em voz alta:
iris %>%
subset(Sepal.Length > 5) %>%
aggregate(. ~ Species, ., mean)
Você está certo, o trecho de código acima será traduzido para algo como "você pega os dados do Iris, depois faz um subconjunto dos dados e, em seguida, agrega os dados".
Essa é uma das coisas mais poderosas do Tidyverse. De fato, ter uma cadeia padronizada de ações de processamento é chamado de "pipeline". Criar pipelines para um formato de dados é ótimo, porque você pode aplicar esse pipeline a dados de entrada que tenham a mesma formatação e fazer com que eles sejam gerados em um formato amigável em ggplot2, por exemplo.
O R é uma linguagem funcional, o que significa que seu código geralmente contém muitos parênteses, ( e ). Quando você tem um código complexo, isso geralmente significa que você terá que aninhar esses parênteses. Isso torna seu código R difícil de ler e entender. É aqui que o %>% entra em cena para ajudar!
Dê uma olhada no exemplo a seguir, que é um exemplo típico de código aninhado:
# Initialize `x`
x <- c(0.109, 0.359, 0.63, 0.996, 0.515, 0.142, 0.017, 0.829, 0.907)
# Compute the logarithm of `x`, return suitably lagged and iterated differences,
# compute the exponential function and round the result
round(exp(diff(log(x))), 1)
Com a ajuda do site %<%, você pode reescrever o código acima da seguinte forma:
# Import `magrittr`
library(magrittr)
# Perform the same computations on `x` as above
x %>% log() %>%
diff() %>%
exp() %>%
round(1)
Isso parece difícil para você? Não se preocupe! Você saberá mais sobre como fazer isso mais adiante neste tutorial.
Observe que você precisa importar a bibliotecamagrittr para que o código acima funcione. Isso ocorre porque o operador de pipe, como você leu acima, faz parte da biblioteca magrittr e, desde 2014, também faz parte de dplyr. Se você esquecer de importar a biblioteca, receberá um erro como Error in eval(expr, envir, enclos): could not find function "%>%".
Observe também que não é um requisito formal adicionar parênteses após log, diff e exp, mas, na comunidade do R, algumas pessoas o usarão para aumentar a legibilidade do código.
Em resumo, aqui estão quatro motivos pelos quais você deve usar pipes no R:
Esses motivos foram extraídos da própria documentação do sitemagrittr . Implicitamente, você vê os argumentos de legibilidade e flexibilidade retornando.
Embora %>% seja o operador de pipe (principal) do pacote magrittr, há alguns outros operadores que você deve conhecer e que fazem parte do mesmo pacote:
%<>%;# Initialize `x`
x <- rnorm(100)
# Update value of `x` and assign it to `x`
x %<>% abs %>% sort
%T>%;rnorm(200) %>%
matrix(ncol = 2) %T>%
plot %>%
colSums
Observe que, por enquanto, é bom saber que o trecho de código acima é, na verdade, um atalho para:
rnorm(200) %>%
matrix(ncol = 2) %T>%
{ plot(.); . } %>%
colSums
Mas você verá mais sobre isso mais tarde!
%$%.data.frame(z = rnorm(100)) %$%
ts.plot(z)
Obviamente, esses três operadores funcionam de forma ligeiramente diferente do operador principal do %>%. Você verá mais sobre suas funcionalidades e seu uso mais adiante neste tutorial.
Observe que, embora na maioria das vezes você veja os tubos do magrittr, você também poderá encontrar outros tubos ao longo do caminho! Alguns exemplos são wrapr's dot arrow pipe %.>% ou to dot pipe %>.%, ou o Bizarro pipe ->.;.
Agora que você sabe como o operador %>% se originou, o que ele realmente é e por que você deve usá-lo, é hora de descobrir como você pode realmente usá-lo a seu favor. Você verá que há várias maneiras de usá-lo!
Antes de entrar nos usos mais avançados do operador, é bom dar uma olhada nos exemplos mais básicos que usam o operador. Em essência, você verá que há três regras que podem ser seguidas quando você está começando:
f(x) pode ser reescrito como x %>% fEm resumo, isso significa que as funções que recebem um argumento, function(argument), podem ser reescritas da seguinte forma: argument %>% function(). Dê uma olhada no exemplo mais prático a seguir para entender como esses dois são equivalentes:
# Compute the logarithm of `x`
log(x)
# Compute the logarithm of `x`
x %>% log()
f(x, y) pode ser reescrito como x %>% f(y)É claro que há muitas funções que não recebem apenas um argumento, mas vários. Esse é o caso aqui: você vê que a função recebe dois argumentos, x e y. De modo semelhante ao que você viu no primeiro exemplo, é possível reescrever a função seguindo a estrutura argument1 %>% function(argument2), em que argument1 é o espaço reservado magrittr e argument2 a chamada da função.
Tudo isso parece bastante teórico. Vamos dar uma olhada em um exemplo mais prático:
# Round pi
round(pi, 6)
# Round pi
pi %>% round(6)
x %>% f %>% g %>% h pode ser reescrito como h(g(f(x)))Isso pode parecer complexo, mas não é bem assim quando você olha para um exemplo real do R:
# Import `babynames` data
library(babynames)
# Import `dplyr` library
library(dplyr)
# Load the data
data(babynames)
# Count how many young boys with the name "Taylor" are born
sum(select(filter(babynames,sex=="M",name=="Taylor"),n))
# Do the same but now with `%>%`
babynames%>%filter(sex=="M",name=="Taylor")%>%
select(n)%>%
sum
Observe como você trabalha de dentro para fora ao reescrever o código aninhado: primeiro você coloca babynames, depois usa %>% para primeiro filter() os dados. Depois disso, você selecionará n e, por fim, sum() tudo.
Lembre-se também de que você já viu outro exemplo desse código aninhado que foi convertido em um código mais legível no início deste tutorial, no qual você usou as funções log(), diff(), exp() e round() para realizar cálculos em x.
Infelizmente, há algumas exceções às regras mais gerais descritas na seção anterior. Vamos dar uma olhada em alguns deles aqui.
Considere este exemplo, em que você usa a função assign() para atribuir o valor 10 à variável x.
# Assign `10` to `x`
assign("x", 10)
# Assign `100` to `x`
"x" %>% assign(100)
# Return `x`
x
10
Você vê que a segunda chamada com a função assign(), em combinação com o pipe, não funciona corretamente. O valor de x não é atualizado.
Por que isso acontece?
Isso ocorre porque a função atribui o novo valor 100 a um ambiente temporário usado por %>%. Portanto, se você quiser usar o assign() com o pipe, deverá ser explícito sobre o ambiente:
# Define your environment
env <- environment()
# Add the environment to `assign()`
"x" %>% assign(100, envir = env)
# Return `x`
x
100
Os argumentos dentro das funções são computados somente quando a função os utiliza no R. Isso significa que nenhum argumento é computado antes de você chamar a função. Isso também significa que o pipe calcula cada elemento da função por vez.
Um lugar em que isso é um problema é tryCatch(), que permite capturar e tratar erros, como neste exemplo:
tryCatch(stop("!"), error = function(e) "An error")
stop("!") %>%
tryCatch(error = function(e) "An error")
'Um erro'
Error in eval(expr, envir, enclos): !
Traceback:
1. stop("!") %>% tryCatch(error = function(e) "An error")
2. eval(lhs, parent, parent)
3. eval(expr, envir, enclos)
4. stop("!")
Você verá que a maneira aninhada de escrever essa linha de código funciona perfeitamente, enquanto a alternativa canalizada retorna um erro. Outras funções com o mesmo comportamento são try(), suppressMessages() e suppressWarnings() na base R.
Também há casos em que você pode usar o operador pipe como espaço reservado para argumentos. Dê uma olhada nos exemplos a seguir:
f(x, y) pode ser reescrito como y %>% f(x, .)Em alguns casos, você não vai querer o valor ou o espaço reservado magrittr para a chamada de função na primeira posição, o que tem sido o caso em todos os exemplos que você viu até agora. Reconsidere essa linha de código:
pi %>% round(6)
Se você reescrevesse essa linha de código, pi seria o primeiro argumento em sua função round(). Mas e se você quiser substituir o segundo, terceiro, ... argumento e usá-lo como espaço reservado magrittr para sua chamada de função?
Dê uma olhada neste exemplo, em que o valor está, na verdade, na terceira posição da chamada de função:
"Ceci n'est pas une pipe" %>% gsub("une", "un", .)
'Ceci n\'est pas un pipe' (Não é mais um cachimbo)
f(y, z = x) pode ser reescrito como x %>% f(y, z = .)Da mesma forma, talvez você queira fazer com que o valor de um argumento específico em sua função chame o espaço reservado magrittr. Considere a seguinte linha de código:
6 %>% round(pi, digits=.)
É simples usar o espaço reservado várias vezes em uma expressão do lado direito. No entanto, quando o espaço reservado aparecer apenas em uma expressão aninhada, o site magrittr ainda aplicará a regra do primeiro argumento. O motivo é que, na maioria dos casos, isso resulta em um código mais limpo.
Aqui estão algumas "regras" gerais que você pode levar em conta quando estiver trabalhando com placeholders de argumentos em chamadas de funções aninhadas:
f(x, y = nrow(x), z = ncol(x)) pode ser reescrito como x %>% f(y = nrow(.), z = ncol(.))# Initialize a matrix `ma`
ma <- matrix(1:12, 3, 4)
# Return the maximum of the values inputted
max(ma, nrow(ma), ncol(ma))
# Return the maximum of the values inputted
ma %>% max(nrow(ma), ncol(ma))
12
12
O comportamento pode ser anulado colocando o lado direito entre colchetes:
f(y = nrow(x), z = ncol(x)) pode ser reescrito como x %>% {f(y = nrow(.), z = ncol(.))}# Only return the maximum of the `nrow(ma)` and `ncol(ma)` input values
ma %>% {max(nrow(ma), ncol(ma))}
4
Para concluir, dê uma olhada no exemplo a seguir, em que é possível que você queira ajustar o funcionamento do espaço reservado para argumentos na chamada de função aninhada:
# The function that you want to rewrite
paste(1:5, letters[1:5])
# The nested function call with dot placeholder
1:5 %>%
paste(., letters[.])
Veja que, se o espaço reservado for usado somente em uma chamada de função aninhada, o espaço reservado magrittr também será colocado como o primeiro argumento! Se quiser evitar que isso aconteça, você pode usar os colchetes { e }:
# The nested function call with dot placeholder and curly brackets
1:5 %>% {
paste(letters[.])
}
# Rewrite the above function call
paste(letters[1:5])
As funções unárias são funções que recebem um argumento. Qualquer pipeline que você possa criar e que consista em um ponto ., seguido de funções e que seja encadeado com %>% pode ser usado posteriormente se você quiser aplicá-lo a valores. Dê uma olhada no exemplo a seguir desse pipeline:
. %>% cos %>% sin
Esse pipeline receberia algumas entradas, após as quais as funções cos() e sin() seriam aplicadas a ele.
Mas você ainda não chegou lá! Se quiser que esse pipeline faça exatamente o que você acabou de ler, será necessário atribuí-lo primeiro a uma variável f, por exemplo. Depois disso, você pode reutilizá-lo mais tarde para fazer as operações contidas no pipeline em outros valores.
# Unary function
f <- . %>% cos %>% sin
f
structure(function (value)
freduce(value, `_function_list`), class = c("fseq", "function"
))Lembre-se também de que você pode colocar parênteses após as funções cos() e sin() na linha de código se quiser melhorar a legibilidade. Considere o mesmo exemplo com parênteses: . %>% cos() %>% sin().
Veja bem, a criação de funções em magrittr é muito semelhante à criação de funções com o R básico! Se não tiver certeza da semelhança entre elas, verifique a linha acima e compare-a com a próxima linha de código; ambas as linhas têm o mesmo resultado!
# is equivalent to
f <- function(.) sin(cos(.))
f
function (.)
sin(cos(.))Há situações em que você deseja sobrescrever o valor do lado esquerdo, como no exemplo abaixo. Intuitivamente, você usará o operador de atribuição <- para fazer isso.
# Load in the Iris data
iris <- read.csv(url("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"), header = FALSE)
# Add column names to the Iris data
names(iris) <- c("Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width", "Species")
# Compute the square root of `iris$Sepal.Length` and assign it to the variable
iris$Sepal.Length <-
iris$Sepal.Length %>%
sqrt()
No entanto, há um operador de pipe de atribuição composto, que permite usar uma notação abreviada para atribuir o resultado do pipeline imediatamente ao lado esquerdo:
# Compute the square root of `iris$Sepal.Length` and assign it to the variable
iris$Sepal.Length %<>% sqrt
# Return `Sepal.Length`
iris$Sepal.Length
Observe que o operador de atribuição composta %<>% precisa ser o primeiro operador de pipe na cadeia para que isso funcione. Isso está totalmente de acordo com o que você acabou de ler sobre o operador ser uma notação abreviada para uma notação mais longa com repetição, em que você usa o operador de atribuição regular <-.
Como resultado, esse operador atribuirá um resultado de um pipeline em vez de retorná-lo.
O operador tee funciona exatamente como %>%, mas retorna o valor do lado esquerdo em vez do resultado potencial das operações do lado direito.
Isso significa que o operador tee pode ser útil em situações em que você incluiu funções que são usadas para seu efeito colateral, como plotagem com plot() ou impressão em um arquivo.
Em outras palavras, funções como plot() normalmente não retornam nada. Isso significa que, depois de chamar plot(), por exemplo, seu pipeline terminaria. No entanto, no exemplo a seguir, o operador tee %T>% permite que você continue o pipeline mesmo depois de ter usado plot():
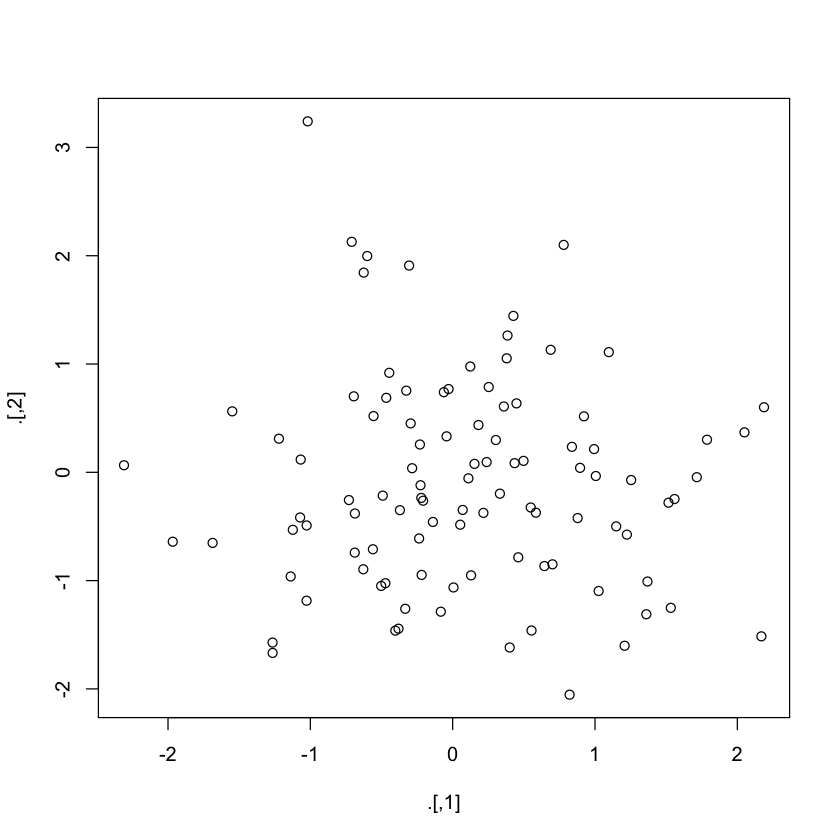
set.seed(123)
rnorm(200) %>%
matrix(ncol = 2) %T>%
plot %>%
colSums
Ao trabalhar com o R, você verá que muitas funções recebem um argumento data. Considere, por exemplo, a funçãolm() ou a funçãowith() . Essas funções são úteis em um pipeline em que os dados são primeiro processados e depois passados para a função.
Para funções que não têm um argumento data, como a função cor(), ainda é útil se você puder expor as variáveis nos dados. É aí que entra o operador do %$%. Considere o exemplo a seguir:
iris %>%
subset(Sepal.Length > mean(Sepal.Length)) %$%
cor(Sepal.Length, Sepal.Width)
0.336696922252551
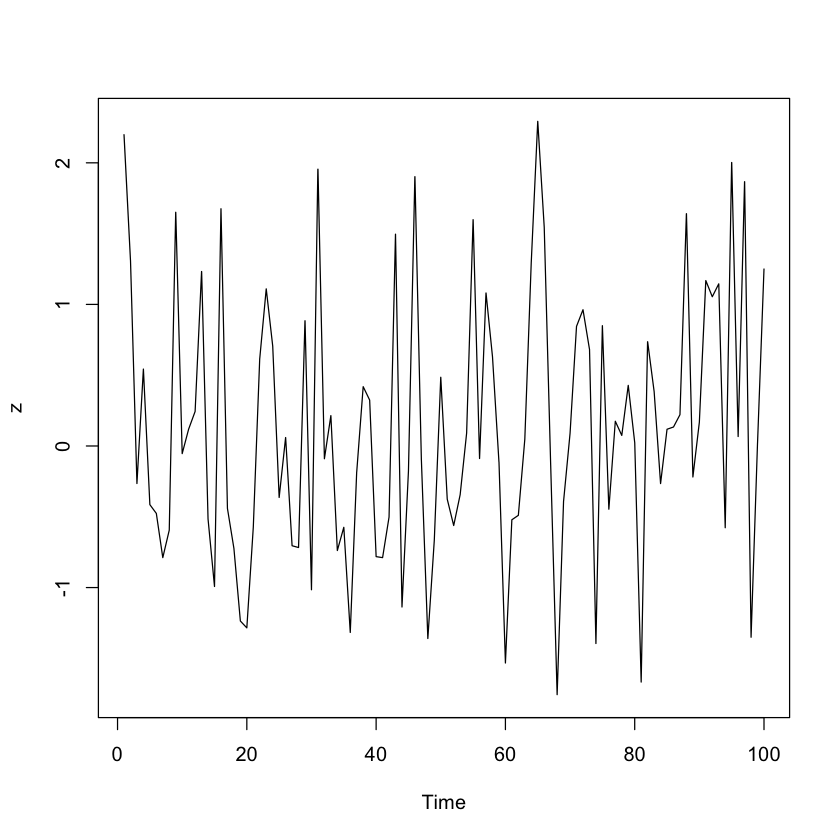
Com a ajuda de %$%, você garante que Sepal.Length e Sepal.Width sejam expostos a cor(). Da mesma forma, você vê que os dados da função data.frame() são passados para ts.plot() para plotar várias séries temporais em um gráfico comum:
data.frame(z = rnorm(100)) %$%
ts.plot(z)
dplyr e magrittrNa introdução deste tutorial, você já aprendeu que o desenvolvimento do dplyr e do magrittr ocorreu mais ou menos na mesma época, ou seja, por volta de 2013-2014. E, como você leu, o pacote magrittr também faz parte do Tidyverse.
Nesta seção, você descobrirá como é interessante combinar os dois pacotes no seu código R.
Se você não conhece o pacote dplyr, saiba que esse pacote R foi criado com base em cinco verbos, a saber, "select" (selecionar), "filter" (filtrar), "arrange" (organizar), "mutate" (mutar) e "summarize" (resumir). Se você já manipulou dados para algum projeto de ciência de dados, saberá que esses verbos constituem a maioria das tarefas de manipulação de dados que você geralmente precisa executar em seus dados.
Veja um exemplo de código tradicional que faz uso dessas funções dplyr:
library(hflights)
grouped_flights <- group_by(hflights, Year, Month, DayofMonth)
flights_data <- select(grouped_flights, Year:DayofMonth, ArrDelay, DepDelay)
summarized_flights <- summarise(flights_data,
arr = mean(ArrDelay, na.rm = TRUE),
dep = mean(DepDelay, na.rm = TRUE))
final_result <- filter(summarized_flights, arr > 30 | dep > 30)
final_result
| Ano | Mês | DayofMonth | arr | dep |
|---|---|---|---|---|
| 2011 | 2 | 4 | 44.08088 | 47.17216 |
| 2011 | 3 | 3 | 35.12898 | 38.20064 |
| 2011 | 3 | 14 | 46.63830 | 36.13657 |
| 2011 | 4 | 4 | 38.71651 | 27.94915 |
| 2011 | 4 | 25 | 37.79845 | 22.25574 |
| 2011 | 5 | 12 | 69.52046 | 64.52039 |
| 2011 | 5 | 20 | 37.02857 | 26.55090 |
| 2011 | 6 | 22 | 65.51852 | 62.30979 |
| 2011 | 7 | 29 | 29.55755 | 31.86944 |
| 2011 | 9 | 29 | 39.19649 | 32.49528 |
| 2011 | 10 | 9 | 61.90172 | 59.52586 |
| 2011 | 11 | 15 | 43.68134 | 39.23333 |
| 2011 | 12 | 29 | 26.30096 | 30.78855 |
| 2011 | 12 | 31 | 46.48465 | 54.17137 |
Ao analisar esse exemplo, você entende imediatamente por que dplyr e magrittr conseguem trabalhar tão bem juntos:
hflights %>%
group_by(Year, Month, DayofMonth) %>%
select(Year:DayofMonth, ArrDelay, DepDelay) %>%
summarise(arr = mean(ArrDelay, na.rm = TRUE), dep = mean(DepDelay, na.rm = TRUE)) %>%
filter(arr > 30 | dep > 30)
Ambos os blocos de código são bastante longos, mas você poderia argumentar que o segundo bloco de código é mais claro se você quiser acompanhar todas as operações. Com a criação de variáveis intermediárias no primeiro trecho de código, é possível que você perca o "fluxo" do código. Ao usar o site %>%, você obtém uma visão geral mais clara das operações que estão sendo executadas nos dados!
Em resumo, dplyr e magrittr são a equipe dos sonhos para manipular dados no R!
Adicionar todos esses pipes ao seu código R pode ser uma tarefa desafiadora! Para facilitar a sua vida, John Mount, cofundador e consultor principal da Win-Vector, LLC e instrutor do DataCamp, lançou um pacote com alguns suplementos do RStudio que permitem criar atalhos de teclado para pipes no R. Os suplementos são, na verdade, funções do R com um pouco de metadados de registro especiais. Um exemplo de um addin simples pode ser, por exemplo, uma função que insere um trecho de texto comumente usado, mas também pode ser muito complexo!
Com esses suplementos, você poderá executar funções R de forma interativa no IDE RStudio, usando atalhos de teclado ou acessando o menu Addins.
Observe que esse pacote é, na verdade, uma bifurcação do pacote de suplementos original do RStudio. Mas tenha cuidado: o suporte a suplementos está disponível somente na versão mais recente do RStudio! Confira este artigo sobre suplementos do RStudio para saber mais sobre o assunto.
Você pode baixar os suplementos e os atalhos de teclado do GitHub.
No texto acima, você viu que os pipes são definitivamente algo que você deve usar quando estiver programando com o R. Mais especificamente, você viu isso ao cobrir alguns casos em que os pipes são muito úteis! No entanto, há algumas situações, descritas por Hadley Wickham em "R for Data Science", em que é melhor evitá-las:
Em casos como esse, é melhor criar objetos intermediários com nomes significativos. Não só será mais fácil para você depurar seu código, mas você também entenderá melhor seu código e será mais fácil para outras pessoas entenderem seu código.
Se você não estiver transformando um objeto primário, mas dois ou mais objetos forem combinados, é melhor não usar o pipe.
Os pipes são fundamentalmente lineares e expressar relações complexas com eles resultará apenas em um código complexo que será difícil de ler e entender.
O uso de pipes no desenvolvimento de pacotes internos é proibido, pois dificulta a depuração!
Para obter mais reflexões sobre esse tópico, confira esta discussão no Stack Overflow. Outras situações que aparecem nessa discussão são os loops, as dependências de pacotes, a ordem dos argumentos e a legibilidade.
Em suma, você poderia resumir tudo da seguinte forma: tenha em mente os dois aspectos que tornam essa construção tão boa, ou seja, legibilidade e flexibilidade. Assim que uma dessas duas grandes vantagens for comprometida, você poderá considerar algumas alternativas em favor dos tubos.
Depois de tudo o que você leu, talvez também se interesse por algumas alternativas existentes na linguagem de programação R. Algumas das soluções que você viu neste tutorial foram as seguintes:
Em vez de encadear todas as operações e gerar um único resultado, divida a cadeia e certifique-se de salvar os resultados intermediários em variáveis separadas. Tenha cuidado com a nomenclatura dessas variáveis: o objetivo deve ser sempre tornar seu código o mais compreensível possível!
Uma das possíveis objeções que você poderia ter contra os pipes é o fato de que eles vão contra o "fluxo" ao qual você está acostumado com o R básico. Mas o que fazer se você não gosta de pipes, mas também acha que o aninhamento pode ser bastante confuso? A solução aqui pode ser usar guias para destacar a hierarquia.
Você já cobriu muita coisa neste tutorial de pipes do R: viu de onde vem o %>%, o que ele é exatamente, por que você deve usá-lo e como deve usá-lo. Você viu que os pacotes dplyr e magrittr funcionam maravilhosamente bem juntos e que há ainda mais operadores por aí. Por fim, você também viu alguns casos em que não deve usá-lo quando estiver programando em R e quais alternativas pode usar nesses casos.
Se você estiver interessado em saber mais sobre o Tidyverse, considere o curso Introdução ao Tidyverse do DataCamp.
Cursos R
Curso
Curso
Curso
blog
Karlijn Willems
15 min
Tutorial
DataCamp Team
Tutorial
Elena Kosourova
Tutorial
Eladio Montero Porras
Tutorial
Kevin Babitz
