Kurs
Einführung in R
4 Std.
3M
Code aus diesem Tutorial online ausführen und bearbeiten
Code ausführenWillst du mehr über die Datenmanipulation in R mit dplyr erfahren? Wirf einen Blick auf den DataCamp-Kurs Datenbearbeitung in R mit dplyr.
Um zu verstehen, was der Pipe-Operator in R ist und was du mit ihm machen kannst, musst du das Gesamtbild betrachten und die Geschichte dahinter kennenlernen. Fragen wie "Woher kommt diese seltsame Kombination von Symbolen und warum wurde sie so gemacht?" könnten dir durch den Kopf gehen. Die Antworten auf diese und weitere Fragen findest du in diesem Abschnitt.
Du kannst die Geschichte aus drei Perspektiven betrachten: aus mathematischer Sicht, aus der ganzheitlichen Sicht von Programmiersprachen und aus der Sicht der Sprache R selbst. Im Folgenden wirst du alle drei Themen behandeln!
Wenn du zwei Funktionen hast, z.B. $f : B → C$ und $g : A → B$, kannst du diese Funktionen miteinander verketten, indem du die Ausgabe der einen Funktion in die nächste einfügst. Kurz gesagt, bedeutet "Verkettung", dass du ein Zwischenergebnis an die nächste Funktion weitergibst, aber dazu später mehr.
Du kannst zum Beispiel sagen: $f(g(x))$: $g(x)$ dient als Eingabe für $f()$, während $x$ natürlich als Eingabe für $g()$ dient.
Wenn du das notieren möchtest, verwendest du die Notation $f ◦ g$, was so viel heißt wie "f folgt g". Alternativ kannst du dies auch visuell darstellen:
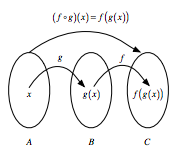
Wie in der Einleitung zu diesem Abschnitt erwähnt, ist dieser Operator in der Programmierung nicht neu: In der Shell oder im Terminal kannst du mit dem Pipelinezeichen | Befehle von einem zum nächsten weitergeben. Ebenso verfügt F# über einen Forward-Pipe-Operator, der sich später noch als wichtig erweisen wird! Zu guter Letzt ist es auch gut zu wissen, dass Haskell viele Piping-Operationen enthält, die von der Shell oder dem Terminal abgeleitet sind.
Nachdem du nun die Geschichte des Pipe-Operators in anderen Programmiersprachen kennengelernt hast, ist es an der Zeit, sich auf R zu konzentrieren. Die Geschichte dieses Operators in R beginnt am 17. Januar 2012, als ein anonymer Benutzer in diesem Stack Overflow-Post die folgende Frage stellte:
Wie kannst du den Forward-Pipe-Operator von F# in R implementieren? Der Operator ermöglicht es, eine Reihe von Berechnungen einfach zu verketten. Wenn du zum Beispiel Eingabedaten hast und die Funktionen
fooundbarnacheinander aufrufen willst, kannst dudata |> foo |> barschreiben ?
Die Antwort kam von Ben Bolker, Professor an der McMaster University, der antwortete:
Ich weiß nicht, wie gut es sich in der Praxis bewährt, aber es scheint (?) das zu tun, was du willst, zumindest für Funktionen mit nur einem Argument ...
"%>%" <- function(x,f) do.call(f,list(x)) pi %>% sin [1] 1.224606e-16 pi %>% sin %>% cos [1] 1 cos(sin(pi)) [1] 1
Etwa neun Monate später startete Hadley Wickham das Paket dplyr auf GitHub. Vielleicht kennst du Hadley, Chief Scientist bei RStudio, als Autor vieler beliebter R-Pakete (wie dieses letzte Paket!) und als Dozent des DataCamp-Kurses Writing Functions in R.
Aber erst 2013 erschien das erste Rohr %.% in diesem Paket. Wie Adolfo Álvarez in seinem Blogbeitrag richtig erwähnt, wurde die Funktion als chain() bezeichnet, um die Notation für die Anwendung mehrerer Funktionen auf einen einzigen Datenrahmen in R zu vereinfachen.
Das Rohr %.% würde nicht lange existieren, denn Stefan Bache schlug am 29. Dezember 2013 eine Alternative vor, die den Betreiber, wie du ihn jetzt vielleicht kennst, einschloss:
iris %>%
subset(Sepal.Length > 5) %>%
aggregate(. ~ Species, ., mean)
Bache arbeitete weiter mit diesem Rohrbetrieb zusammen, und Ende 2013 wurde das magrittr Paket geschnürt. In der Zwischenzeit arbeitete Hadley Wickham weiter an dplyr und im April 2014 wurde der Betreiber von %.% durch denjenigen ersetzt, den du jetzt kennst: %>%.
Später im selben Jahr veröffentlichte Kun Ren das Paket pipeR auf GitHub, das einen anderen Pipe-Operator, %>>%, enthielt, der den Piping-Prozess flexibler machen sollte. Man kann jedoch mit Sicherheit sagen, dass %>% in der Sprache R etabliert ist, vor allem mit der jüngsten Popularität von Tidyverse.
Die Geschichte zu kennen ist eine Sache, aber das gibt dir immer noch keine Vorstellung davon, was der Forward-Pipe-Operator von F# ist und was er in R tatsächlich tut.
In F# ist der Pipe-Forward-Operator |> ein syntaktischer Zucker für verkettete Methodenaufrufe. Oder, einfacher ausgedrückt, du kannst ein Zwischenergebnis an die nächste Funktion weitergeben.
Denke daran, dass "Verkettung" bedeutet, dass du mehrere Methodenaufrufe machst. Da jede Methode ein Objekt zurückgibt, kannst du die Aufrufe in einer einzigen Anweisung aneinanderreihen, ohne dass du Variablen zum Speichern der Zwischenergebnisse benötigst.
In R ist der Pipe-Operator, wie du bereits gesehen hast, %>%. Wenn du mit F# nicht vertraut bist, kannst du dir diesen Operator ähnlich wie den + in einer ggplot2 Anweisung vorstellen. Seine Funktion ist der des F#-Operators sehr ähnlich: Er nimmt die Ausgabe einer Anweisung und macht sie zur Eingabe für die nächste Anweisung. Wenn du es beschreibst, kannst du es dir als "DANN" vorstellen.
Nimm zum Beispiel den folgenden Codeabschnitt und lies ihn laut vor:
iris %>%
subset(Sepal.Length > 5) %>%
aggregate(. ~ Species, ., mean)
Du hast recht, der obige Codeausschnitt bedeutet so viel wie "Du nimmst die Iris-Daten, dann unterteilst du die Daten und dann aggregierst du die Daten".
Das ist eines der stärksten Dinge am Tidyverse. Eine standardisierte Kette von Verarbeitungsvorgängen wird als "Pipeline" bezeichnet. Die Erstellung von Pipelines für ein Datenformat ist großartig, denn du kannst diese Pipeline auf eingehende Daten anwenden, die dasselbe Format haben, und sie z. B. in einem ggplot2 freundlichen Format ausgeben lassen.
R ist eine funktionale Sprache, was bedeutet, dass dein Code oft eine Menge Klammern, ( und ) enthält. Bei komplexem Code bedeutet das oft, dass du die Klammern ineinander verschachteln musst. Das macht deinen R-Code schwer zu lesen und zu verstehen. Hier kommt %>% zur Rettung!
Sieh dir das folgende Beispiel an, das ein typisches Beispiel für verschachtelten Code ist:
# Initialize `x`
x <- c(0.109, 0.359, 0.63, 0.996, 0.515, 0.142, 0.017, 0.829, 0.907)
# Compute the logarithm of `x`, return suitably lagged and iterated differences,
# compute the exponential function and round the result
round(exp(diff(log(x))), 1)
Mit Hilfe von %<% kannst du den obigen Code wie folgt umschreiben:
# Import `magrittr`
library(magrittr)
# Perform the same computations on `x` as above
x %>% log() %>%
diff() %>%
exp() %>%
round(1)
Erscheint dir das schwierig? Mach dir keine Sorgen! Wie du das machst, erfährst du später in diesem Lernprogramm.
Beachte, dass du die magrittr Bibliothek importieren musst, damit der obige Code funktioniert. Das liegt daran, dass der Pipe-Operator, wie du oben gelesen hast, Teil der magrittr Bibliothek ist und seit 2014 auch ein Teil von dplyr ist. Wenn du vergisst, die Bibliothek zu importieren, bekommst du eine Fehlermeldung wie Error in eval(expr, envir, enclos): could not find function "%>%".
Beachte auch, dass es keine formale Vorschrift ist, Klammern nach log, diff und exp hinzuzufügen, aber in der R-Gemeinschaft verwenden einige dies, um die Lesbarkeit des Codes zu verbessern.
Kurz gesagt, hier sind vier Gründe, warum du Pipes in R verwenden solltest:
Diese Gründe sind der Dokumentation vonmagrittr entnommen. Du siehst also, dass die Argumente der Lesbarkeit und Flexibilität zurückkehren.
Auch wenn %>% der (wichtigste) Pipe-Operator des magrittr Pakets ist, gibt es noch ein paar andere Operatoren, die du kennen solltest und die Teil desselben Pakets sind:
%<>%;# Initialize `x`
x <- rnorm(100)
# Update value of `x` and assign it to `x`
x %<>% abs %>% sort
%T>%;rnorm(200) %>%
matrix(ncol = 2) %T>%
plot %>%
colSums
Es ist gut zu wissen, dass der obige Codeabschnitt eigentlich eine Abkürzung für ist:
rnorm(200) %>%
matrix(ncol = 2) %T>%
{ plot(.); . } %>%
colSums
Aber dazu später mehr!
%$%.data.frame(z = rnorm(100)) %$%
ts.plot(z)
Natürlich funktionieren diese drei Operatoren etwas anders als der Hauptoperator %>%. Mehr über ihre Funktionen und ihre Verwendung erfährst du später in diesem Lernprogramm.
Beachte, dass du, obwohl du am häufigsten die Rohre von magrittr sehen wirst, auch auf andere Rohre stoßen kannst! Einige Beispiele sind wraprdie Punkt-Pfeil-Pipe %.>% oder die Punkt-Pipe %>.%, oder die Bizarro-Pipe ->.;.
Jetzt, wo du weißt, wie der %>% Operator entstanden ist, was er eigentlich ist und warum du ihn benutzen solltest, ist es an der Zeit, dass du herausfindest, wie du ihn tatsächlich zu deinem Vorteil nutzen kannst. Du wirst sehen, dass es eine ganze Reihe von Möglichkeiten gibt, wie du sie nutzen kannst!
Bevor du dich mit den fortgeschrittenen Anwendungen des Operators beschäftigst, ist es gut, einen Blick auf die grundlegenden Beispiele zu werfen, die den Operator verwenden. Im Wesentlichen wirst du sehen, dass es drei Regeln gibt, die du befolgen kannst, wenn du anfängst:
f(x) kann umgeschrieben werden als x %>% fKurz gesagt bedeutet dies, dass Funktionen, die ein Argument, function(argument), benötigen, wie folgt umgeschrieben werden können: argument %>% function(). Sieh dir das folgende, praktischere Beispiel an, um zu verstehen, wie diese beiden gleichwertig sind:
# Compute the logarithm of `x`
log(x)
# Compute the logarithm of `x`
x %>% log()
f(x, y) kann umgeschrieben werden als x %>% f(y)Natürlich gibt es viele Funktionen, die nicht nur ein Argument brauchen, sondern mehrere. Das ist hier der Fall: Du siehst, dass die Funktion zwei Argumente braucht, x und y. Ähnlich wie im ersten Beispiel kannst du die Funktion umschreiben, indem du der Struktur argument1 %>% function(argument2) folgst, wobei argument1 der Platzhalter magrittr und argument2 der Funktionsaufruf ist.
Das scheint alles sehr theoretisch zu sein. Schauen wir uns ein praktischeres Beispiel an:
# Round pi
round(pi, 6)
# Round pi
pi %>% round(6)
x %>% f %>% g %>% h kann umgeschrieben werden als h(g(f(x)))Das mag komplex erscheinen, ist es aber nicht ganz, wenn du dir ein echtes R-Beispiel ansiehst:
# Import `babynames` data
library(babynames)
# Import `dplyr` library
library(dplyr)
# Load the data
data(babynames)
# Count how many young boys with the name "Taylor" are born
sum(select(filter(babynames,sex=="M",name=="Taylor"),n))
# Do the same but now with `%>%`
babynames%>%filter(sex=="M",name=="Taylor")%>%
select(n)%>%
sum
Beachte, wie du von innen nach außen arbeitest, wenn du den verschachtelten Code umschreibst: Zuerst fügst du babynames ein, dann verwendest du %>%, um die Daten zuerst filter(). Danach wählst du n und zum Schluss sum() aus.
Erinnere dich auch daran, dass du bereits ein anderes Beispiel eines solchen verschachtelten Codes gesehen hast, der zu Beginn dieses Tutorials in einen besser lesbaren Code umgewandelt wurde, wo du die Funktionen log(), diff(), exp() und round() benutzt hast, um Berechnungen auf x durchzuführen.
Leider gibt es einige Ausnahmen von den allgemeinen Regeln, die im vorherigen Abschnitt beschrieben wurden. Schauen wir uns einige von ihnen hier an.
In diesem Beispiel verwendest du die Funktion assign(), um den Wert 10 der Variablen x zuzuweisen.
# Assign `10` to `x`
assign("x", 10)
# Assign `100` to `x`
"x" %>% assign(100)
# Return `x`
x
10
Du siehst, dass der zweite Aufruf mit der Funktion assign() in Kombination mit der Pipe nicht richtig funktioniert. Der Wert von x wird nicht aktualisiert.
Warum ist das so?
Das liegt daran, dass die Funktion den neuen Wert 100 einer temporären Umgebung zuweist, die von %>% verwendet wird. Wenn du also assign() mit der Pipe verwenden willst, musst du die Umgebung explizit angeben:
# Define your environment
env <- environment()
# Add the environment to `assign()`
"x" %>% assign(100, envir = env)
# Return `x`
x
100
Argumente innerhalb von Funktionen werden erst berechnet, wenn die Funktion sie in R verwendet. Das bedeutet, dass keine Argumente berechnet werden, bevor du deine Funktion aufrufst. Das bedeutet auch, dass die Pipe jedes Element der Funktion nacheinander berechnet.
Ein Ort, an dem das ein Problem ist, ist tryCatch(). Damit kannst du Fehler erfassen und behandeln, wie in diesem Beispiel:
tryCatch(stop("!"), error = function(e) "An error")
stop("!") %>%
tryCatch(error = function(e) "An error")
'Ein Fehler'
Error in eval(expr, envir, enclos): !
Traceback:
1. stop("!") %>% tryCatch(error = function(e) "An error")
2. eval(lhs, parent, parent)
3. eval(expr, envir, enclos)
4. stop("!")
Du wirst sehen, dass der verschachtelte Weg, diese Codezeile zu schreiben, perfekt funktioniert, während die Piping-Alternative einen Fehler liefert. Andere Funktionen mit demselben Verhalten sind try(), suppressMessages() und suppressWarnings() in Base R.
Es gibt auch Fälle, in denen du den Pipe-Operator als Platzhalter für ein Argument verwenden kannst. Sieh dir die folgenden Beispiele an:
f(x, y) kann umgeschrieben werden als y %>% f(x, .)In manchen Fällen willst du den Wert oder den Platzhalter magrittr nicht an der ersten Stelle des Funktionsaufrufs haben, was in allen Beispielen, die du bisher gesehen hast, der Fall war. Überdenke diese Code-Zeile noch einmal:
pi %>% round(6)
Wenn du diese Codezeile neu schreiben würdest, wäre pi das erste Argument in deiner round() Funktion. Was aber, wenn du das zweite, dritte, ... Argument ersetzen und dieses als magrittr Platzhalter für deinen Funktionsaufruf verwenden möchtest?
Sieh dir dieses Beispiel an, bei dem der Wert tatsächlich an der dritten Stelle des Funktionsaufrufs steht:
"Ceci n'est pas une pipe" %>% gsub("une", "un", .)
'Ceci n\'est pas un pipe'
f(y, z = x) kann umgeschrieben werden als x %>% f(y, z = .)Du könntest auch den Wert eines bestimmten Arguments innerhalb deines Funktionsaufrufs zum Platzhalter magrittr machen wollen. Betrachte die folgende Code-Zeile:
6 %>% round(pi, digits=.)
Es ist ganz einfach, den Platzhalter mehrmals in einem Ausdruck auf der rechten Seite zu verwenden. Wenn der Platzhalter jedoch nur in verschachtelten Ausdrücken vorkommt, wendet magrittr weiterhin die Regel des ersten Arguments an. Der Grund dafür ist, dass dies in den meisten Fällen zu einem saubereren Code führt.
Hier sind einige allgemeine "Regeln", die du berücksichtigen kannst, wenn du mit Argumentplatzhaltern in verschachtelten Funktionsaufrufen arbeitest:
f(x, y = nrow(x), z = ncol(x)) kann umgeschrieben werden als x %>% f(y = nrow(.), z = ncol(.))# Initialize a matrix `ma`
ma <- matrix(1:12, 3, 4)
# Return the maximum of the values inputted
max(ma, nrow(ma), ncol(ma))
# Return the maximum of the values inputted
ma %>% max(nrow(ma), ncol(ma))
12
12
Das Verhalten kann außer Kraft gesetzt werden, indem die rechte Seite in geschweifte Klammern eingeschlossen wird:
f(y = nrow(x), z = ncol(x)) kann umgeschrieben werden als x %>% {f(y = nrow(.), z = ncol(.))}# Only return the maximum of the `nrow(ma)` and `ncol(ma)` input values
ma %>% {max(nrow(ma), ncol(ma))}
4
Sieh dir zum Abschluss auch das folgende Beispiel an, in dem du möglicherweise die Funktionsweise des Argumentplatzhalters im verschachtelten Funktionsaufruf anpassen möchtest:
# The function that you want to rewrite
paste(1:5, letters[1:5])
# The nested function call with dot placeholder
1:5 %>%
paste(., letters[.])
Du siehst, dass, wenn der Platzhalter nur in einem verschachtelten Funktionsaufruf verwendet wird, der magrittr Platzhalter auch als erstes Argument gesetzt wird! Wenn du das vermeiden willst, kannst du die geschweiften Klammern { und } verwenden:
# The nested function call with dot placeholder and curly brackets
1:5 %>% {
paste(letters[.])
}
# Rewrite the above function call
paste(letters[1:5])
Unäre Funktionen sind Funktionen, die nur ein Argument benötigen. Jede Pipeline, die du erstellst, die aus einem Punkt . besteht, gefolgt von Funktionen und die mit %>% verkettet ist, kann später verwendet werden, wenn du sie auf Werte anwenden willst. Sieh dir das folgende Beispiel für eine solche Pipeline an:
. %>% cos %>% sin
Diese Pipeline würde einige Eingaben entgegennehmen, auf die dann sowohl die cos() als auch die sin() Funktionen angewendet werden.
Aber so weit bist du noch nicht! Wenn du willst, dass diese Pipeline genau das tut, was du gerade gelesen hast, musst du sie zuerst einer Variablen zuweisen, zum Beispiel f. Danach kannst du sie später wiederverwenden, um die Operationen, die in der Pipeline enthalten sind, an anderen Werten durchzuführen.
# Unary function
f <- . %>% cos %>% sin
f
structure(function (value)
freduce(value, `_function_list`), class = c("fseq", "function"
))Denke auch daran, dass du Klammern nach den Funktionen cos() und sin() in der Codezeile setzen kannst, wenn du die Lesbarkeit verbessern willst. Betrachte das gleiche Beispiel mit Klammern: . %>% cos() %>% sin().
Du siehst, dass das Erstellen von Funktionen in magrittr dem Erstellen von Funktionen in R sehr ähnlich ist! Wenn du dir nicht sicher bist, wie ähnlich sie tatsächlich sind, schau dir die Zeile oben an und vergleiche sie mit der nächsten Codezeile; beide Zeilen haben das gleiche Ergebnis!
# is equivalent to
f <- function(.) sin(cos(.))
f
function (.)
sin(cos(.))Es gibt Situationen, in denen du den Wert der linken Seite überschreiben möchtest, so wie im Beispiel unten rechts. Intuitiv benutzt du dafür den Zuweisungsoperator <-.
# Load in the Iris data
iris <- read.csv(url("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"), header = FALSE)
# Add column names to the Iris data
names(iris) <- c("Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width", "Species")
# Compute the square root of `iris$Sepal.Length` and assign it to the variable
iris$Sepal.Length <-
iris$Sepal.Length %>%
sqrt()
Es gibt jedoch einen zusammengesetzten Zuweisungs-Pipe-Operator, mit dem du eine Kurzschrift verwenden kannst, um das Ergebnis deiner Pipeline direkt auf der linken Seite zuzuweisen:
# Compute the square root of `iris$Sepal.Length` and assign it to the variable
iris$Sepal.Length %<>% sqrt
# Return `Sepal.Length`
iris$Sepal.Length
Beachte, dass der zusammengesetzte Zuweisungsoperator %<>% der erste Pipe-Operator in der Kette sein muss, damit dies funktioniert. Das stimmt mit dem überein, was du gerade gelesen hast: Der Operator ist eine Kurzschrift für eine längere Notation mit Wiederholungen, bei der du den regulären <- Zuweisungsoperator verwendest.
Daher wird dieser Operator ein Ergebnis einer Pipeline zuweisen, anstatt es zurückzugeben.
Der Tee-Operator funktioniert genau wie %>%, aber er gibt den Wert der linken Seite zurück und nicht das mögliche Ergebnis der Operationen auf der rechten Seite.
Das bedeutet, dass der T-Stück-Operator in Situationen nützlich sein kann, in denen du Funktionen eingebaut hast, die für ihren Nebeneffekt verwendet werden, wie z.B. das Plotten mit plot() oder das Drucken in eine Datei.
Mit anderen Worten: Funktionen wie plot() geben normalerweise nichts zurück. Das bedeutet, dass deine Pipeline zum Beispiel nach dem Aufruf von plot() enden würde. Im folgenden Beispiel kannst du jedoch mit dem T-Operator %T>% deine Pipeline fortsetzen, auch wenn du plot() verwendet hast:
set.seed(123)
rnorm(200) %>%
matrix(ncol = 2) %T>%
plot %>%
colSums
Wenn du mit R arbeitest, wirst du feststellen, dass viele Funktionen ein data Argument benötigen. Betrachte zum Beispiel die Funktionlm() oder die Funktionwith() . Diese Funktionen sind nützlich in einer Pipeline, in der deine Daten zuerst verarbeitet und dann an die Funktion übergeben werden.
Bei Funktionen, die kein data Argument haben, wie z.B. die cor() Funktion, ist es trotzdem praktisch, wenn du die Variablen in den Daten offenlegen kannst. Hier kommt der %$% Betreiber ins Spiel. Betrachte das folgende Beispiel:
iris %>%
subset(Sepal.Length > mean(Sepal.Length)) %$%
cor(Sepal.Length, Sepal.Width)
0.336696922252551
Mit Hilfe von %$% stellst du sicher, dass Sepal.Length und Sepal.Width auf cor() zu sehen sind. Du siehst auch, dass die Daten in der Funktion data.frame() an ts.plot() weitergegeben werden, um mehrere Zeitreihen in einem gemeinsamen Diagramm darzustellen:
data.frame(z = rnorm(100)) %$%
ts.plot(z)
dplyr und magrittrIn der Einführung zu diesem Lernprogramm hast du bereits erfahren, dass die Entwicklung von dplyr und magrittr ungefähr zur gleichen Zeit stattfand, nämlich um 2013-2014. Und, wie du gelesen hast, ist das magrittr Paket auch Teil des Tidyverse.
In diesem Abschnitt wirst du entdecken, wie spannend es sein kann, wenn du beide Pakete in deinem R-Code kombinierst.
Diejenigen unter euch, die das Paket dplyr noch nicht kennen, sollten wissen, dass dieses R-Paket um fünf Verben herum aufgebaut wurde, nämlich "select", "filter", "arrange", "mutate" und "summarize". Wenn du schon einmal Daten für ein Data-Science-Projekt bearbeitet hast, wirst du wissen, dass diese Verben den Großteil der Datenbearbeitungsaufgaben ausmachen, die du in der Regel mit deinen Daten durchführen musst.
Nimm ein Beispiel für einen traditionellen Code, der diese dplyr Funktionen nutzt:
library(hflights)
grouped_flights <- group_by(hflights, Year, Month, DayofMonth)
flights_data <- select(grouped_flights, Year:DayofMonth, ArrDelay, DepDelay)
summarized_flights <- summarise(flights_data,
arr = mean(ArrDelay, na.rm = TRUE),
dep = mean(DepDelay, na.rm = TRUE))
final_result <- filter(summarized_flights, arr > 30 | dep > 30)
final_result
| Jahr | Monat | DayofMonth | arr | dep |
|---|---|---|---|---|
| 2011 | 2 | 4 | 44.08088 | 47.17216 |
| 2011 | 3 | 3 | 35.12898 | 38.20064 |
| 2011 | 3 | 14 | 46.63830 | 36.13657 |
| 2011 | 4 | 4 | 38.71651 | 27.94915 |
| 2011 | 4 | 25 | 37.79845 | 22.25574 |
| 2011 | 5 | 12 | 69.52046 | 64.52039 |
| 2011 | 5 | 20 | 37.02857 | 26.55090 |
| 2011 | 6 | 22 | 65.51852 | 62.30979 |
| 2011 | 7 | 29 | 29.55755 | 31.86944 |
| 2011 | 9 | 29 | 39.19649 | 32.49528 |
| 2011 | 10 | 9 | 61.90172 | 59.52586 |
| 2011 | 11 | 15 | 43.68134 | 39.23333 |
| 2011 | 12 | 29 | 26.30096 | 30.78855 |
| 2011 | 12 | 31 | 46.48465 | 54.17137 |
Wenn du dir dieses Beispiel ansiehst, verstehst du sofort, warum dplyr und magrittr so gut zusammenarbeiten können:
hflights %>%
group_by(Year, Month, DayofMonth) %>%
select(Year:DayofMonth, ArrDelay, DepDelay) %>%
summarise(arr = mean(ArrDelay, na.rm = TRUE), dep = mean(DepDelay, na.rm = TRUE)) %>%
filter(arr > 30 | dep > 30)
Beide Codeabschnitte sind ziemlich lang, aber man könnte argumentieren, dass der zweite Codeabschnitt übersichtlicher ist, wenn du alle Operationen nachvollziehen willst. Durch das Anlegen von Zwischenvariablen im ersten Codeabschnitt kannst du möglicherweise den "Fluss" des Codes verlieren. Mit %>% bekommst du einen besseren Überblick über die Operationen, die an den Daten durchgeführt werden!
Kurz gesagt: dplyr und magrittr sind dein Dreamteam für die Datenmanipulation in R!
Das Hinzufügen all dieser Pipes zu deinem R-Code kann eine Herausforderung sein! Um dir das Leben leichter zu machen, hat John Mount, Mitbegründer und Principal Consultant bei Win-Vector, LLC und DataCamp-Dozent, ein Paket mit einigen RStudio-Add-ins veröffentlicht, mit denen du Tastaturkürzel für Pipes in R erstellen kannst. Add-ins sind eigentlich R-Funktionen mit ein paar speziellen Registrierungsmetadaten. Ein Beispiel für ein einfaches Addin kann zum Beispiel eine Funktion sein, die einen häufig verwendeten Textausschnitt einfügt, aber es kann auch sehr komplex werden!
Mit diesen Addins kannst du R-Funktionen interaktiv in der RStudio-IDE ausführen, entweder über Tastaturkürzel oder über das Menü Addins.
Beachte, dass dieses Paket eigentlich ein Fork des ursprünglichen Add-in-Pakets von RStudio ist. Aber Vorsicht: Die Unterstützung für Addins ist nur in der neuesten Version von RStudio verfügbar! In diesem Artikel über RStudio-Addins erfährst du mehr über dieses Thema.
Du kannst die Add-Ins und Tastaturkürzel von GitHub herunterladen.
In diesem Abschnitt hast du gesehen, dass du Pipes auf jeden Fall verwenden solltest, wenn du mit R programmierst. Genauer gesagt, hast du das anhand einiger Fälle gesehen, in denen sich Pipes als sehr nützlich erweisen! Es gibt jedoch einige Situationen, die Hadley Wickham in "R for Data Science" beschreibt, in denen du sie am besten vermeiden kannst:
In solchen Fällen ist es besser, Zwischenobjekte mit aussagekräftigen Namen zu erstellen. Es wird nicht nur einfacher für dich, deinen Code zu debuggen, sondern du wirst deinen Code auch besser verstehen und es wird für andere einfacher sein, deinen Code zu verstehen.
Wenn du nicht ein primäres Objekt transformierst, sondern zwei oder mehr Objekte miteinander kombinierst, ist es besser, die Pipe nicht zu verwenden.
Pipes sind grundsätzlich linear und komplexe Beziehungen mit ihnen auszudrücken wird nur zu komplexem Code führen, der schwer zu lesen und zu verstehen ist.
Die Verwendung von Pipes bei der Entwicklung interner Pakete ist ein No-Go, da es die Fehlersuche erschwert!
Weitere Überlegungen zu diesem Thema findest du in dieser Stack Overflow-Diskussion. Andere Situationen, die in dieser Diskussion auftauchen, sind Schleifen, Paketabhängigkeiten, Argumentreihenfolge und Lesbarkeit.
Kurz gesagt könnte man das Ganze wie folgt zusammenfassen: Behalte die beiden Dinge im Hinterkopf, die dieses Konstrukt so großartig machen, nämlich Lesbarkeit und Flexibilität. Sobald einer dieser beiden großen Vorteile gefährdet ist, könntest du einige Alternativen zu Gunsten der Rohre in Betracht ziehen.
Nach all dem, was du gelesen hast, interessieren dich vielleicht auch einige Alternativen, die es in der Programmiersprache R gibt. Einige der Lösungen, die du in diesem Lernprogramm gesehen hast, waren die folgenden:
Anstatt alle Operationen miteinander zu verketten und ein einziges Ergebnis auszugeben, solltest du die Kette aufbrechen und sicherstellen, dass du Zwischenergebnisse in separaten Variablen speicherst. Sei vorsichtig mit der Benennung dieser Variablen: Das Ziel sollte immer sein, deinen Code so verständlich wie möglich zu machen!
Einer der möglichen Einwände, die du gegen Pipes haben könntest, ist die Tatsache, dass sie dem "Fluss" zuwiderlaufen, an den du dich mit Base R gewöhnt hast. Die Lösung ist dann, bei der Verschachtelung deines Codes zu bleiben! Aber was machst du, wenn du keine Rohre magst, aber auch denkst, dass Verschachtelungen ziemlich verwirrend sein können? Die Lösung kann hier sein, die Hierarchie mit Hilfe von Tabs hervorzuheben.
Du hast in diesem R-Pipes-Tutorial schon viel gelernt: Du hast gesehen, woher %>% kommt, was es genau ist, warum du es benutzen solltest und wie du es benutzen solltest. Du hast gesehen, dass die Pakete dplyr und magrittr wunderbar zusammenarbeiten und dass es noch mehr Anbieter gibt. Schließlich hast du auch einige Fälle gesehen, in denen du sie bei der Programmierung in R nicht verwenden solltest und welche Alternativen du in solchen Fällen nutzen kannst.
Wenn du mehr über Tidyverse erfahren möchtest, solltest du den DataCamp-Kurs "Einführung in Tidyverse " besuchen.
R Kurse
Kurs
Kurs
Kurs