Cours
Importer et gérer des données financières avec R
5 h
20.9K

R est un outil statistique puissant. Comparé à d'autres logiciels comme Microsoft Excel, R nous permet de charger les données plus rapidement, de les nettoyer automatiquement et d'effectuer des analyses statistiques et prédictives approfondies. Nous allons apprendre à les utiliser pour importer différents types d'ensembles de données.
Nous utiliserons DataLab pour exécuter des exemples de code. Il est livré avec des paquets préinstallés et l'environnement R. Vous n'avez rien à installer et vous pouvez commencer à coder en quelques secondes. Il s'agit d'un service gratuit qui s'accompagne d'une large sélection d'ensembles de données. Vous pouvez également intégrer votre serveur SQL pour commencer à effectuer des analyses exploratoires de données.
Après avoir chargé le classeur DataLab, vous devez installer quelques paquets peu connus mais nécessaires pour charger les fichiers SAS, SPSS, Stata et Matlab.
Note: Assurez-vous d'installer les dépendances en utilisant le paramètre `dependency=T` dans la fonction `install.packages`.
Le paquet Tidyverse est livré avec différents paquets qui vous permettent de lire des fichiers plats, de nettoyer des données, d'effectuer des manipulations de données et des visualisations, et bien plus encore.
install.packages(c('quantmod','ff','foreign','R.matlab'),dependency=T)
suppressPackageStartupMessages(library(tidyverse))Dans ce tutoriel, nous apprendrons à charger des fichiers de données CSV, TXT, Excel, JSON, Database, et XML/HTML dans R. En outre, nous examinerons également des formats de fichiers moins courants tels que SAS, SPSS, Stata, Matlab, et Binary.
Nous apprendrons à connaître tous les formats de données courants et à les charger à l'aide de divers packages R. En outre, nous utiliserons les URL pour extraire des tableaux HTML et des données XML du site web avec quelques lignes de code.
Dans cette section, nous allons lire des données dans r en chargeant un fichier CSV de Hotel Booking Demand. Cet ensemble de données se compose de données de réservation provenant d'un hôtel urbain et d'un hôtel de villégiature. Pour importer le fichier CSV, nous utiliserons la fonction `read_csv` du paquetage readr. Comme dans Pandas, vous devez saisir l'emplacement du fichier pour le traiter et le charger en tant qu'image de données.
Vous pouvez également utiliser les fonctions `read.csv` ou `read.delim` du paquetage utils pour charger des fichiers CSV.
data1 <- read_csv('data/hotel_bookings_clean.csv',show_col_types = FALSE)
head(data1, 5)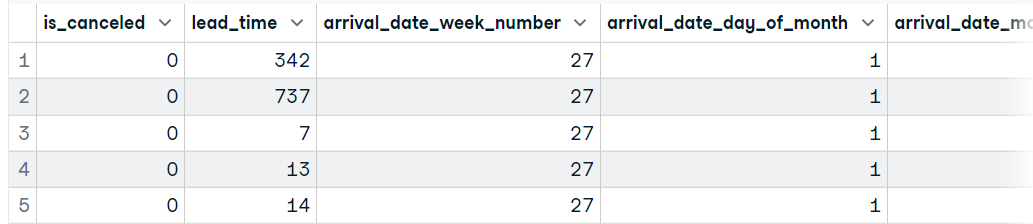
Comme pour `read_csv`, vous pouvez également utiliser la fonction read.table pour charger le fichier. Assurez-vous que vous ajoutez le délimiteur "," et l'en-tête = 1. Il définira la première ligne comme nom de colonne au lieu de "V1", "V2",...
data2 <- read.table('data/hotel_bookings_clean.csv', sep=",", header = 1)
head(data2, 5)Dans cette partie, nous utiliserons l'ensemble de données Drake Lyrics pour charger un fichier texte. Ce fichier contient des paroles du chanteur Drake. Nous pouvons utiliser la fonction `readLines` pour charger le fichier simple, mais nous devons effectuer des tâches supplémentaires pour le convertir en dataframe.

Image par l'auteur | Fichier texte
Nous utiliserons la fonction alternative de read.table, `read.delim` pour charger le fichier texte en tant que dataframe R. Les autres fonctions alternatives de read.table sont read.csv, read.csv2 et read.delim2.
Note: par défaut, les valeurs sont séparées par une tabulation (sep = "\t").
Le fichier texte est constitué de paroles et ne comporte pas de ligne d'en-tête. Pour afficher toutes les paroles sur une même ligne, nous devons définir `header = F`.
Vous pouvez également utiliser d'autres paramètres pour personnaliser votre cadre de données, par exemple le paramètre fill, qui définit le champ vide à ajouter aux lignes de longueur inégale.
Lisez la documentation pour en savoir plus sur chaque paramètre des fonctions alternatives de read.table.
data3 <- read.delim('data/drake_lyrics.txt',header = F)
head(data3, 5)
Dans cette section, nous utiliserons l'ensemble de données Tesla Deaths de Kaggle pour l'importer d'Excel vers R. L'ensemble de données concerne les accidents tragiques de véhicules Tesla qui ont entraîné la mort d'un conducteur, d'un occupant, d'un cycliste ou d'un piéton.
L'ensemble de données contient un fichier CSV, et nous utiliserons MS Excel pour le convertir en un fichier Excel, comme indiqué ci-dessous.
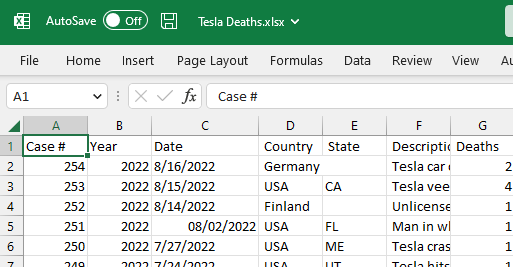
Image par l'auteur
Nous allons utiliser la fonction `read_excel` du paquet readxl pour lire une seule feuille d'un fichier Excel. Le paquet est livré avec tiddyvers, mais ce n'est pas la partie principale du paquet, nous devons donc charger le paquet avant d'utiliser la fonction.
La fonction requiert l'emplacement des données et le numéro de la feuille. Nous pouvons également modifier l'aspect de notre dataframe en lisant la description des autres paramètres dans la documentation de read_excel.
library(readxl)
data4 <- read_excel("data/Tesla Deaths.xlsx", sheet = 1)
head(data4, 5)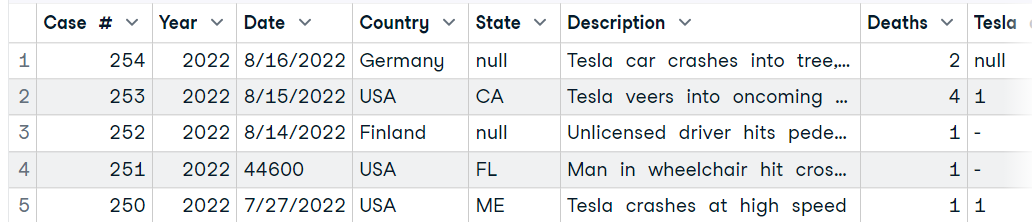
Dans cette partie, nous allons charger JSON dans R à l'aide d'un fichier provenant de l'ensemble de données Drake Lyrics. Il contient les paroles, le titre de la chanson, le titre de l'album, l'URL et le nombre de vues des chansons de Drake.

Image par l'auteur
Pour charger un fichier JSON, nous allons charger le paquet rjson et utiliser `fromJSON` pour analyser le fichier JSON.
library(rjson)
JsonData <- fromJSON(file = 'data/drake_data.json')
print(JsonData[1])Sortie:
[[1]]
[[1]]$album
[1] "Certified Lover Boy"
[[1]]$lyrics_title
[1] "Certified Lover Boy* Lyrics"
[[1]]$lyrics_url
[1] "https://genius.com/Drake-certified-lover-boy-lyrics"
[[1]]$lyrics
[1] "Lyrics from CLB Merch\n\n[Verse]\nPut my feelings on ice\nAlways been a gem\nCertified lover boy, somehow still heartless\nHeart is only gettin' colder"
[[1]]$track_views
[1] "8.7K"Pour convertir les données JSON en un cadre de données R, nous utiliserons la fonction `as.data.frame` du paquet data.table.
data5 = as.data.frame(JsonData[1])
data5
Dans cette partie, nous allons utiliser le jeu de données Mental Health in the Tech Industry de Kaggle pour charger des bases de données SQLite à l'aide de R. Pour extraire les données des bases de données à l'aide d'une requête SQL, nous utiliserons le package DBI et la fonction SQLite et créerons la connexion. Vous pouvez également utiliser une syntaxe similaire pour charger des données à partir d'autres serveurs SQL.
Nous allons charger le paquet RSQLite et charger la base de données à l'aide de la fonction dbConnect.
Remarque: vous pouvez utiliser dbConnect pour charger des données à partir de MySQL, PostgreSQL et d'autres serveurs SQL courants.
Après avoir chargé la base de données, nous afficherons les noms des tables.
library(RSQLite)
conn <- dbConnect(RSQLite::SQLite(), "data/mental_health.sqlite")
dbListTables(conn)
# 'Answer''Question''Survey'Pour lancer une requête et afficher les résultats, nous utiliserons la fonction `dbGetQuery`. Il suffit d'ajouter un objet de connexion SQLite et une requête SQL sous forme de chaîne.
dbGetQuery(conn, "SELECT * FROM Survey")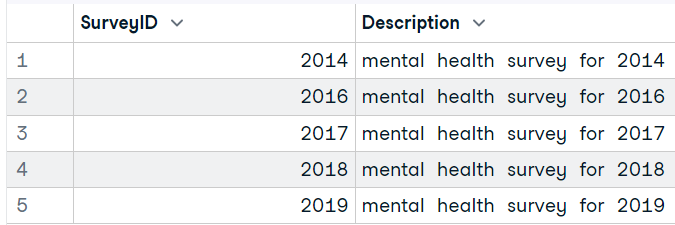
L'utilisation de SQL dans R vous permet de mieux contrôler l'ingestion et l'analyse des données.
data6 = dbGetQuery(conn, "SELECT * FROM Question LIMIT 3")
data6
Pour en savoir plus sur l'exécution de requêtes SQL dans R, suivez le tutoriel Comment exécuter des requêtes SQL en Python et R. Il vous apprendra à charger des bases de données et à utiliser SQL avec dplyr et ggplot.
Dans cette section, nous allons charger les données XML de plant_catalog à partir de w3schools en utilisant le paquetage xml2.
Note: Vous pouvez également utiliser la fonction `xmlTreeParse` du paquet XML pour charger les données.
Tout comme la fonction `read_csv`, nous pouvons charger les données XML en fournissant un lien URL vers le site XML. Il chargera la page et analysera les données XML.
library(xml2)
plant_xml <- read_xml('https://www.w3schools.com/xml/plant_catalog.xml')
plant_xml_parse <- xmlParse(plant_xml)Par la suite, vous pouvez convertir des données XML en un cadre de données R à l'aide de la fonction `xmlToDataFrame`.
1. Extraction d'un ensemble de nœuds à partir de données XML.
2. Ajoutez le `plant_node` à la fonction `xmlToDataFrame` et affichez les cinq premières lignes du dataframe R.
plant_nodes= getNodeSet(plant_xml_parse, "//PLANT")
data9 <- xmlToDataFrame(nodes=plant_nodes)
head(data9,5)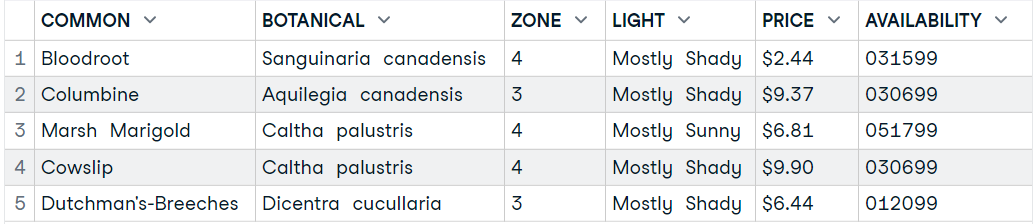
Cette section est amusante, car nous allons récupérer la page Wikipedia de l'équipe nationale de football d'Argentine pour extraire le tableau HTML et le convertir en un cadre de données avec quelques lignes de code.
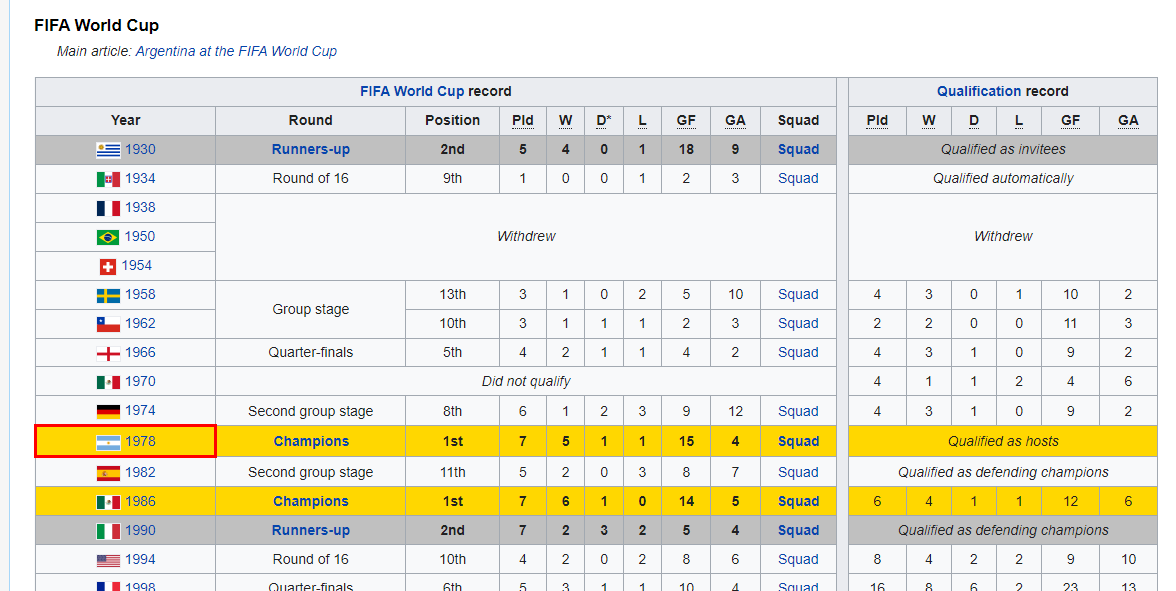
Image de Wikipedia
Pour charger un tableau HTML, nous utiliserons les paquets XML et RCurl. Nous fournirons l'URL de Wikipedia à la fonction `getURL` et ajouterons ensuite l'objet à la fonction `readHTMLTable`, comme indiqué ci-dessous.
La fonction extrait tous les tableaux HTML du site web et nous n'avons plus qu'à les explorer individuellement pour sélectionner celui que nous voulons.
library(XML)
library(RCurl)
url <- getURL("https://en.wikipedia.org/wiki/Brazil_national_football_team")
tables <- readHTMLTable(url)
data7 <- tables[31]
data7$`NULL`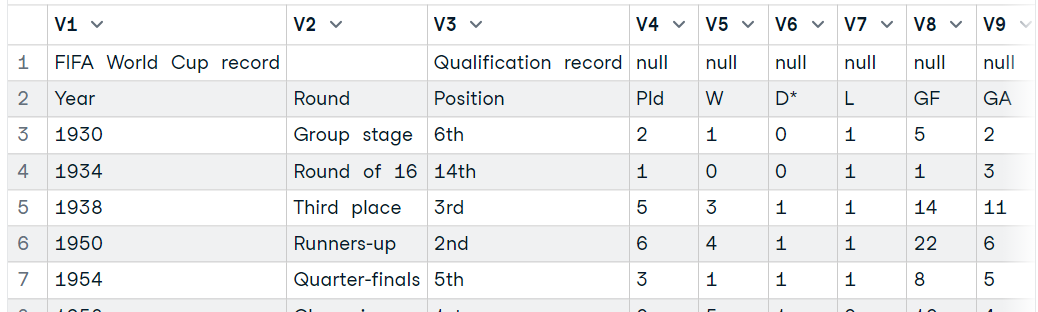
En outre, vous pouvez utiliser le paquetage rvest pour lire le code HTML à l'aide d'une URL, extraire toutes les tables et les afficher sous la forme d'un cadre de données.
library(rvest)
url <- "https://en.wikipedia.org/wiki/Argentina_national_football_team"
file<-read_html(url)
tables<-html_nodes(file, "table")
data8 <- html_table(tables[25])
View(data8)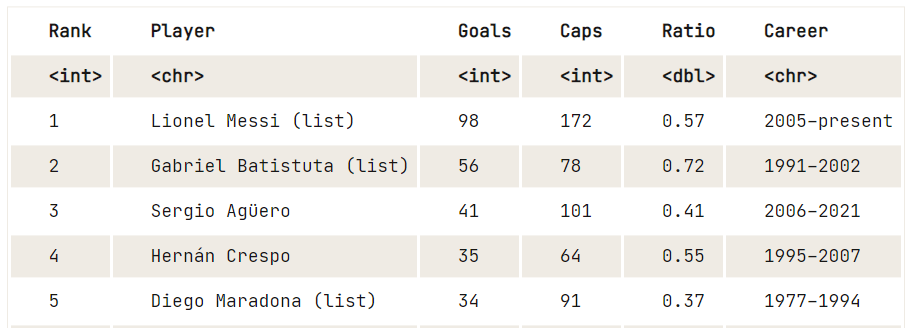
Si vous rencontrez des problèmes en suivant le tutoriel, vous pouvez toujours consulter le classeur DataLab contenant tout le code de ce tutoriel. Il suffit de faire une copie et de commencer à s'entraîner.
Les autres types de données, moins populaires mais essentiels, proviennent de logiciels statistiques, de Matlab et de données binaires.
Dans cette section, nous utiliserons le paquet haven pour importer des fichiers SAS. Vous pouvez télécharger les données sur le blog GeeksforGeeks. Le paquet haven vous permet de charger des fichiers SAS, SPSS et Stata dans R avec un minimum de code.
Fournissez le répertoire du fichier à la fonction `read_sas` pour charger le fichier `.sas7bdat` en tant qu'image de données. Lisez la documentation de la fonction pour en savoir plus.
library(haven)
data10 <- read_sas('data/lond_small.sas7bdat')
# display data
head(data10,5)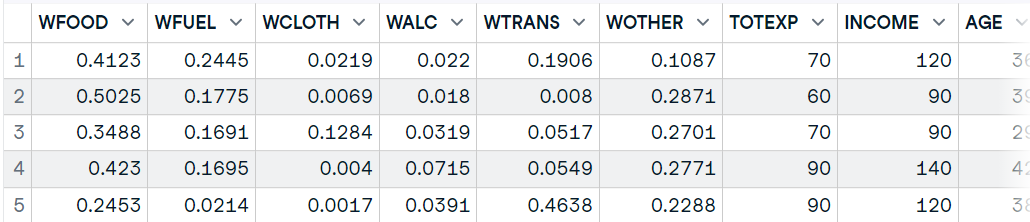
Comme nous le savons déjà, nous pouvons également utiliser le paquet haven pour charger des fichiers SPSS dans R. Vous pouvez télécharger les données à partir du blog GeeksforGeeks et utiliser la fonction `read_sav` uniquement pour charger le fichier SPSS sav.
Il requiert le répertoire du fichier sous la forme d'une chaîne et vous pouvez modifier votre cadre de données en utilisant des arguments supplémentaires tels que encoding, col_select et compress.
library(haven)
data11 <- read_sav("data/airline_passengers.sav")
head(data11,5)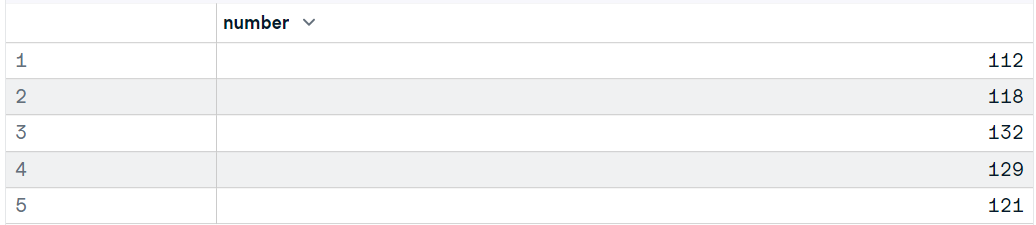
Vous pouvez également utiliser un paquet étranger pour charger un fichier `.sav` en tant que dataframe en utilisant la fonction `read.spss`. La fonction ne nécessite que deux arguments : file et to.data.frame. Pour en savoir plus sur les autres arguments, consultez la documentation de la fonction.
Remarque: le paquet étranger vous permet également de charger les formats de fichiers Minitab, S, SAS, SPSS, Stata, Systat, Weka et Octave.
library("foreign")
data12 <- read.spss("data/airline_passengers.sav", to.data.frame = TRUE)
head(data12,5)
Dans cette partie, nous utiliserons le package foreign pour charger le fichier Stata de ucla.edu.
Le fichier read.dta lit un fichier aux formats binaires de Stata version 5--12 et le convertit en une base de données.
"C'est aussi simple que cela.
library("foreign")
data13 <- read.dta("data/friendly.dta")
head(data13,5)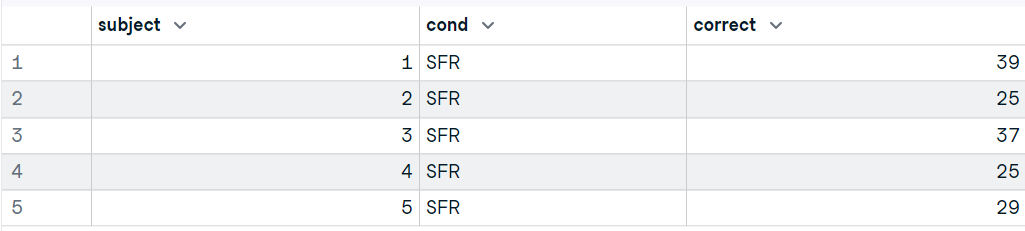
Matlab est très connu des étudiants et des chercheurs. R.matlab nous permet de charger le fichier `.mat`, afin que nous puissions effectuer des analyses de données et des simulations dans R.
Téléchargez les fichiers Matlab à partir de Kaggle pour essayer par vous-même.
library(R.matlab)
data14 <- readMat("data/cross_dsads.mat")
head(data14$data.dsads)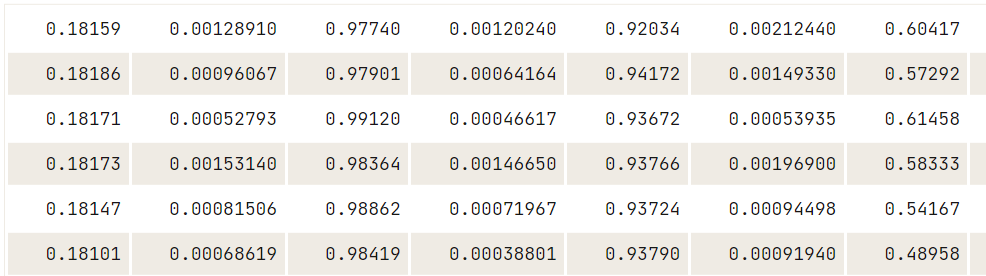
Dans cette partie, nous allons d'abord créer un fichier binaire et ensuite lire le fichier en utilisant la fonction `readBin`.
Remarque: l'exemple de code est une version modifiée du blog Working with Binary Files in R Programming.
Tout d'abord, nous devons créer un cadre de données comportant quatre colonnes et quatre lignes.
df = data.frame(
"ID" = c(1, 2, 3, 4),
"Name" = c("Abid", "Matt", "Sara", "Dean"),
"Age" = c(34, 25, 27, 50),
"Pin" = c(234512, 765345, 345678, 098567)
)Ensuite, créez un objet de connexion en utilisant la fonction `file`.
con = file("data/binary_data.dat", "wb")Inscrivez les noms des colonnes dans le fichier à l'aide de la fonction `writeBin`.
writeBin(colnames(df), con)Inscrivez la valeur de chaque colonne dans le fichier.
writeBin(c(df$ID, df$Name, df$Age, df$Pin), con)Fermez la connexion après avoir écrit les données dans le fichier.
close(con)Pour lire le fichier binaire, nous devons créer une connexion au fichier et utiliser la fonction `readBin` pour afficher les données sous la forme d'un entier.
Arguments utilisés dans la fonction :
con = file("data/binary_data.dat", "rb")
data15_1 = readBin(con, integer(), n = 25)
print(data15_1)Sortie:
[1] 1308640329 6647137 6645569 7235920 3276849 3407923
[7] 1684628033 1952533760 1632829556 1140875634 7233893 838874163
[13] 926023733 3159296 892613426 922759729 875771190 875757621
[19] 943142453 892877056Vous pouvez également convertir les données binaires en chaînes de caractères en remplaçant "integer()" par "character()" dans l'argument `what`.
Lisez la documentation de la fonction readBin pour en savoir plus.
con = file("data/binary_data.dat", "rb")
data15_2 = readBin(con, character(), n = 25)
print(data15_2)Sortie:
[1] "ID" "Name" "Age" "Pin" "1" "2" "3" "4"
[9] "Abid" "Matt" "Sara" "Dean" "34" "25" "27" "50"
[17] "234512" "765345" "345678" "98567" Apprenez à importer des fichiers plats, des logiciels statistiques, des bases de données ou des données directement depuis le web en suivant le cours Intermédiaire Importer des données dans R.
Quantmod est un outil de modélisation financière et de trading pour R. Nous l'utiliserons pour télécharger et charger les dernières données de trading sous la forme d'un cadre de données.
Nous utiliserons la fonction `getSymbols` de quantmod pour charger les données historiques de l'action Google en fournissant les dates "from" et "to" et la "fréquence". Pour en savoir plus sur le paquet quantmod, lisez la documentation.
library(quantmod)
getSymbols("GOOGL",
from = "2022/12/1",
to = "2023/1/15",
periodicity = "daily")
# 'GOOGL'Les données sont chargées dans un objet `GOOGL`, et nous pouvons voir les cinq premières lignes en utilisant la fonction `head()`.
head(GOOGL,5)Sortie:
GOOGL.Open GOOGL.High GOOGL.Low GOOGL.Close GOOGL.Volume
2022-12-01 101.02 102.25 100.25 100.99 28687100
2022-12-02 99.05 100.77 98.90 100.44 21480700
2022-12-05 99.40 101.38 99.00 99.48 24405100
2022-12-06 99.30 99.78 96.42 96.98 24910700
2022-12-07 96.41 96.88 94.72 94.94 31045400
GOOGL.Adjusted
2022-12-01 100.99
2022-12-02 100.44
2022-12-05 99.48
2022-12-06 96.98
2022-12-07 94.94L'importation d'un fichier volumineux est délicate. Vous devez vous assurer que la fonction est optimisée pour un stockage efficace de la mémoire et un accès rapide.
Dans cette section, nous examinerons les fonctions les plus courantes utilisées pour charger des fichiers CSV de plus de 1 Go. Nous utilisons le jeu de données US Accidents (2016 - 2021) de Kaggle, qui a une taille d'environ 1,15 Go et contient 2 845 342 enregistrements.
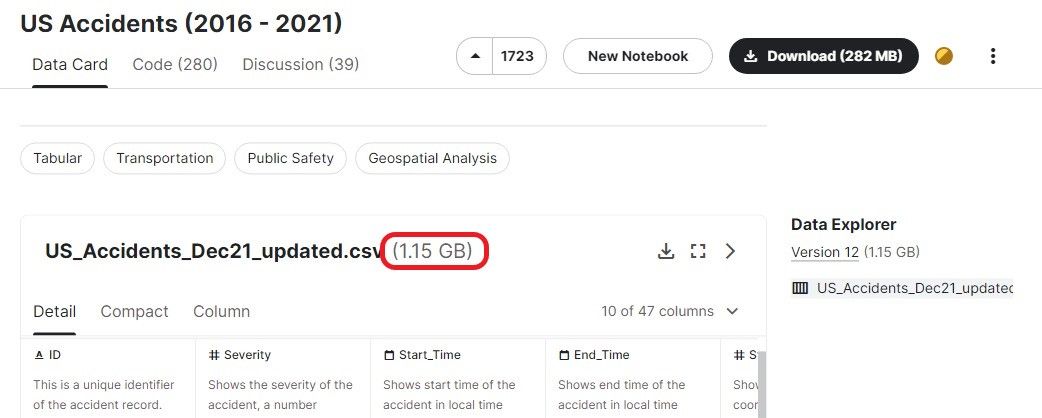
Nous pouvons charger le fichier zip directement dans la fonction read.table d'utilsen utilisant la fonction `unz`. Vous gagnerez du temps en extrayant puis en chargeant le fichier CSV.
file <- unz("data/US Accidents.zip", "US_Accidents_Dec21_updated.csv")
data16 <- read.table(file, header=T, sep=",",nrow=10000)
data16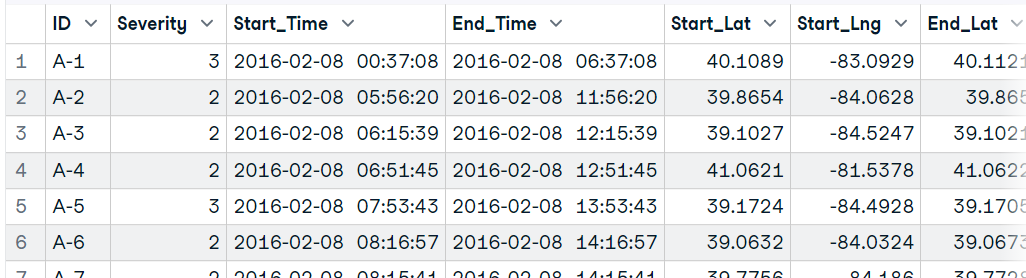
Comme pour `read.table`, nous pouvons utiliser la fonction `read_csv` de readr pour charger le fichier CSV. Au lieu de nrow, nous utiliserons n_max pour lire un nombre limité d'enregistrements.
Dans notre cas, nous ne restreignons aucune donnée et nous autorisons la fonction à charger des données complètes.
Remarque: le chargement des données complètes a pris presque une minute. Vous pouvez modifier le nombre de threads pour réduire le temps de chargement. Pour en savoir plus, consultez la documentation de la fonction.
data17 <- read_csv('data/US_Accidents_Dec21_updated.csv')
data17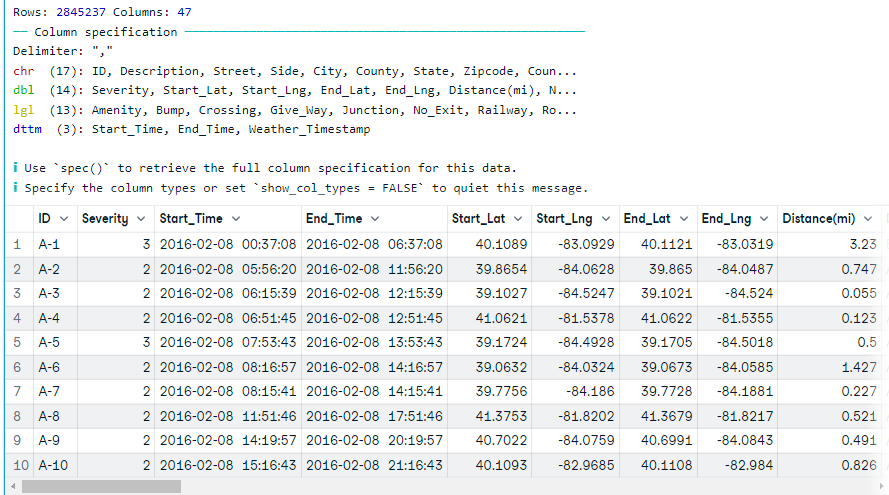
Nous pouvons également utiliser le paquet ff pour optimiser le temps de chargement et le stockage. La fonction read.table.ffdf charge les données par morceaux, ce qui réduit le temps de chargement.
Nous allons d'abord décompresser le fichier et lire les données en utilisant la fonction `read.table.ffdf`.
unzip('data/US Accidents.zip',exdir='data')
library(ff)
data18 <- read.table.ffdf(file="data/US_Accidents_Dec21_updated.csv",
nrows=10000,
header = TRUE,
sep = ',')
data18[1:5,1:25]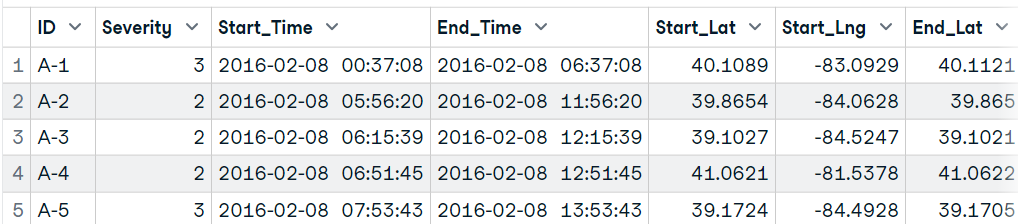
Pour finir, nous utiliserons la fonction la plus couramment utilisée `fread` du package data.table pour lire les 10 000 premières lignes. La fonction peut comprendre automatiquement le format du fichier, mais dans de rares cas, vous devez fournir un argument sep.
library(data.table)
data19 <- fread("data/US_Accidents_Dec21_updated.csv",
sep=',',
nrows = 10000,
na.strings = c("NA","N/A",""),
stringsAsFactors=FALSE
)
data19
Si vous souhaitez essayer les exemples de code par vous-même, voici la liste de tous les ensembles de données utilisés dans le didacticiel.
R est un langage extraordinaire, et il est livré avec toutes sortes d'intégrations. Vous pouvez charger n'importe quel type d'ensemble de données, les nettoyer et les manipuler, effectuer des analyses de données exploratoires et prédictives, et publier des rapports de haute qualité.
Dans ce tutoriel, nous avons appris à charger toutes sortes d'ensembles de données à l'aide des paquets R les plus populaires pour un meilleur stockage et de meilleures performances. Si vous souhaitez commencer votre carrière en science des données avec R, consultez le parcours Data Scientist with R. Il se compose de 24 cours interactifs qui vous apprendront tout sur la programmation R, l'analyse statistique, le traitement des données et l'analyse prédictive. En outre, vous pouvez passer un examen de certification après avoir suivi la formation pour entrer sur le marché du travail.
Consultez également le classeur Importation de données dans R DataLab, qui contient le code source, les résultats et un référentiel de données. Vous pouvez en faire une copie et commencer à apprendre par vous-même.
En savoir plus sur R
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Moez Ali
Tutoriel
Sejal Jaiswal
Tutoriel
Aditya Sharma
Tutoriel
DataCamp Team
Tutoriel
