Kurs
Importing and Managing Financial Data in R
5 Std.
20.9K

R ist ein leistungsstarkes statistisches Werkzeug. Im Vergleich zu anderer Software wie Microsoft Excel ermöglicht uns R ein schnelleres Laden der Daten, eine automatische Datenbereinigung und tiefgreifende statistische und prädiktive Analysen. Wir werden lernen, wie wir mit Hilfe von Open-Source-R-Paketen verschiedene Arten von Datensätzen importieren können.
Wir werden DataLab für die Ausführung von Codebeispielen verwenden. Es wird mit vorinstallierten Paketen und der R-Umgebung geliefert. Du musst nichts einrichten und kannst innerhalb von Sekunden mit dem Coding beginnen. Es ist ein kostenloser Service und bietet eine große Auswahl an Datensätzen. Du kannst auch deinen SQL-Server integrieren, um mit der explorativen Datenanalyse zu beginnen.
Nachdem du die DataLab-Arbeitsmappe geladen hast, musst du ein paar Pakete installieren, die nicht sehr verbreitet sind, aber notwendig sind, um SAS-, SPSS-, Stata- und Matlab-Dateien zu laden.
Hinweis: Stelle sicher, dass du die Abhängigkeiten installierst, indem du den Parameter `dependency=T` in der Funktion `install.packages` verwendest.
Das Tidyverse-Paket enthält verschiedene Pakete, mit denen du Flat Files lesen, Daten bereinigen, Daten manipulieren und visualisieren kannst und vieles mehr.
install.packages(c('quantmod','ff','foreign','R.matlab'),dependency=T)
suppressPackageStartupMessages(library(tidyverse))In diesem Tutorium lernen wir, wie man gängige CSV-, TXT-, Excel-, JSON-, Datenbank- und XML/HTML-Datendateien in R lädt. Außerdem schauen wir uns auch weniger verbreitete Dateiformate wie SAS, SPSS, Stata, Matlab und Binary an.
Wir werden alle gängigen Datenformate kennenlernen und sie mit verschiedenen R-Paketen laden. Außerdem werden wir URLs verwenden, um HTML-Tabellen und XML-Daten von der Website mit wenigen Zeilen Code zu scrapen.
In diesem Abschnitt werden wir Daten in r lesen, indem wir eine CSV-Datei von Hotel Booking Demand laden. Dieser Datensatz besteht aus Buchungsdaten von einem Stadthotel und einem Ferienhotel. Um die CSV-Datei zu importieren, verwenden wir die Funktion "read_csv" aus dem readr-Paket. Genau wie in Pandas musst du den Speicherort der Datei eingeben, um die Datei zu verarbeiten und als Datenrahmen zu laden.
Du kannst auch die Funktionen `read.csv` oder `read.delim` aus dem Paket utils verwenden, um CSV-Dateien zu laden.
data1 <- read_csv('data/hotel_bookings_clean.csv',show_col_types = FALSE)
head(data1, 5)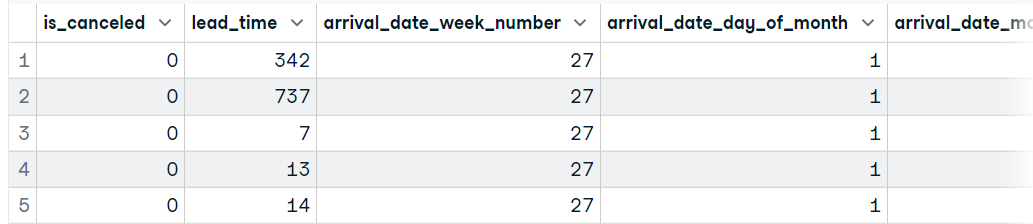
Ähnlich wie bei `read_csv` kannst du auch die Funktion read.table verwenden, um die Datei zu laden. Achte darauf, dass du das Trennzeichen "," und header = 1 hinzufügst. Es wird die erste Zeile als Spaltennamen anstelle von "V1", "V2",... setzen.
data2 <- read.table('data/hotel_bookings_clean.csv', sep=",", header = 1)
head(data2, 5)In diesem Teil werden wir den Drake Lyrics-Datensatz verwenden, um eine Textdatei zu laden. Die Datei besteht aus Lyrics des Sängers Drake. Wir können die Funktion `readLines` verwenden, um die einfache Datei zu laden, aber wir müssen zusätzliche Aufgaben durchführen, um sie in einen Datenrahmen zu konvertieren.

Bild vom Autor | Textdatei
Wir werden die alternative Funktion von read.table, `read.delim`, verwenden, um die Textdatei als R-Datenframe zu laden. Andere alternative Funktionen von read.table sind read.csv, read.csv2 und read.delim2.
Hinweis: Standardmäßig werden die Werte mit Tabulator (sep = "\t") getrennt.
Die Textdatei besteht aus Liedtexten und hat keine Kopfzeile. Um alle Liedtexte in einer Reihe anzuzeigen, müssen wir `header = F` setzen.
Du kannst auch andere Parameter verwenden, um deinen Datenrahmen anzupassen, z. B. den Parameter fill, der festlegt, dass Zeilen mit ungleicher Länge ein leeres Feld hinzugefügt wird.
Lies die Dokumentation, um mehr über jeden Parameter der alternativen Funktionen von read.table zu erfahren.
data3 <- read.delim('data/drake_lyrics.txt',header = F)
head(data3, 5)
In diesem Abschnitt werden wir den Datensatz Tesla Deaths von Kaggle verwenden, um ihn von Excel nach R zu importieren. Der Datensatz enthält tragische Unfälle mit Tesla-Fahrzeugen, bei denen ein Fahrer, Insasse, Radfahrer oder Fußgänger ums Leben kam.
Der Datensatz enthält eine CSV-Datei, die wir mit MS Excel in eine Excel-Datei umwandeln werden, wie unten gezeigt.
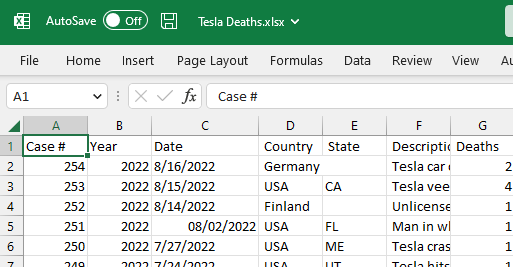
Bild vom Autor
Wir werden die Funktion `read_excel` des readxl-Pakets verwenden, um ein einzelnes Blatt aus einer Excel-Datei zu lesen. Das Paket wird mit tiddyvers ausgeliefert, aber es ist nicht der Kern des Pakets, also müssen wir das Paket laden, bevor wir die Funktion verwenden.
Die Funktion benötigt den Ort der Daten und die Blattnummer. Wir können auch ändern, wie unser Datenrahmen aussieht, indem wir die Beschreibung der anderen Parameter in der read_excel-Dokumentation lesen.
library(readxl)
data4 <- read_excel("data/Tesla Deaths.xlsx", sheet = 1)
head(data4, 5)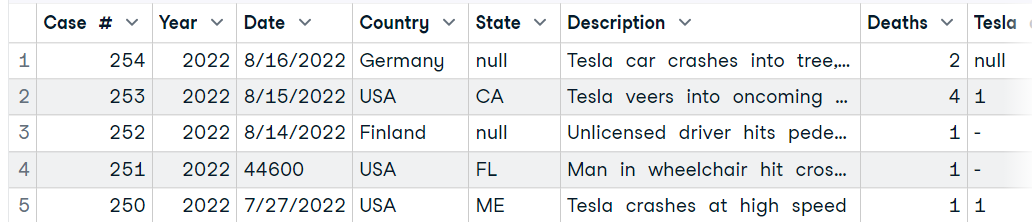
In diesem Teil werden wir JSON in R laden, indem wir eine Datei aus dem Drake Lyrics-Datensatz verwenden. Sie enthält Liedtexte, Songtitel, Albumtitel, URL und die Anzahl der Aufrufe von Drake-Songs.

Bild vom Autor
Um eine JSON-Datei zu laden, laden wir das rjson-Paket und benutzen `fromJSON`, um die JSON-Datei zu parsen.
library(rjson)
JsonData <- fromJSON(file = 'data/drake_data.json')
print(JsonData[1])Ausgabe:
[[1]]
[[1]]$album
[1] "Certified Lover Boy"
[[1]]$lyrics_title
[1] "Certified Lover Boy* Lyrics"
[[1]]$lyrics_url
[1] "https://genius.com/Drake-certified-lover-boy-lyrics"
[[1]]$lyrics
[1] "Lyrics from CLB Merch\n\n[Verse]\nPut my feelings on ice\nAlways been a gem\nCertified lover boy, somehow still heartless\nHeart is only gettin' colder"
[[1]]$track_views
[1] "8.7K"Um die JSON-Daten in einen R-Datenrahmen umzuwandeln, verwenden wir die Funktion "as.data.frame" des Pakets data.table.
data5 = as.data.frame(JsonData[1])
data5
In diesem Teil werden wir den Datensatz "Mental Health in the Tech Industry " von Kaggle verwenden, um SQLite-Datenbanken mit R zu laden. Um die Daten mit einer SQL-Abfrage aus den Datenbanken zu extrahieren, werden wir das DBI-Paket und die SQLite-Funktion verwenden und die Verbindung herstellen. Du kannst eine ähnliche Syntax auch verwenden, um Daten von anderen SQL-Servern zu laden.
Wir laden das RSQLite-Paket und laden die Datenbank mit der Funktion dbConnect.
Hinweis: Du kannst dbConnect verwenden, um Daten von MySQL, PostgreSQL und anderen gängigen SQL-Servern zu laden.
Nachdem wir die Datenbank geladen haben, zeigen wir die Namen der Tabellen an.
library(RSQLite)
conn <- dbConnect(RSQLite::SQLite(), "data/mental_health.sqlite")
dbListTables(conn)
# 'Answer''Question''Survey'Um eine Abfrage auszuführen und die Ergebnisse anzuzeigen, verwenden wir die Funktion `dbGetQuery`. Füge einfach ein SQLite-Verbindungsobjekt und eine SQL-Abfrage als String hinzu.
dbGetQuery(conn, "SELECT * FROM Survey")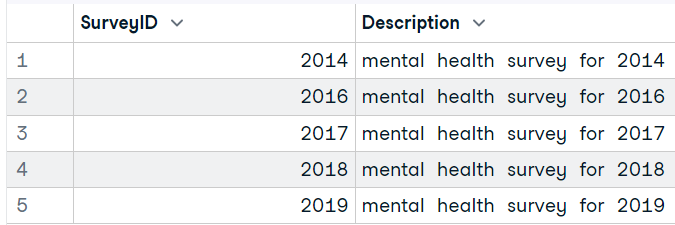
Die Verwendung von SQL in R bietet dir eine bessere Kontrolle über die Dateneingabe und -analyse.
data6 = dbGetQuery(conn, "SELECT * FROM Question LIMIT 3")
data6
Mehr über das Ausführen von SQL-Abfragen in R erfährst du in dem Tutorial How to Execute SQL Queries in Python and R. Hier lernst du, wie du Datenbanken lädst und SQL mit dplyr und ggplot verwendest.
In diesem Abschnitt laden wir die XML-Daten von plant_catalog aus w3schools mit dem Paket xml2.
Hinweis: Du kannst auch die Funktion `xmlTreeParse` des XML-Pakets verwenden, um die Daten zu laden.
Genau wie bei der Funktion `read_csv` können wir die XML-Daten laden, indem wir einen URL-Link zu der XML-Seite angeben. Sie lädt die Seite und analysiert die XML-Daten.
library(xml2)
plant_xml <- read_xml('https://www.w3schools.com/xml/plant_catalog.xml')
plant_xml_parse <- xmlParse(plant_xml)Später kannst du XML-Daten mit der Funktion "xmlToDataFrame" in einen R-Datenrahmen umwandeln.
1. Extrahiere die Knotenmenge aus den XML-Daten.
2. Füge die Funktion "plant_node" zur Funktion "xmlToDataFrame" hinzu und zeige die ersten fünf Zeilen des R-Datenrahmens an.
plant_nodes= getNodeSet(plant_xml_parse, "//PLANT")
data9 <- xmlToDataFrame(nodes=plant_nodes)
head(data9,5)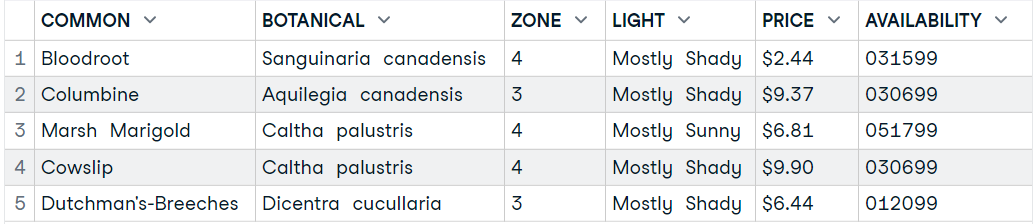
Dieser Abschnitt macht Spaß, denn wir werden die Wikipedia-Seite der argentinischen Fußballnationalmannschaft scrapen, um die HTML-Tabelle zu extrahieren und sie mit wenigen Zeilen Code in einen Datenrahmen zu konvertieren.
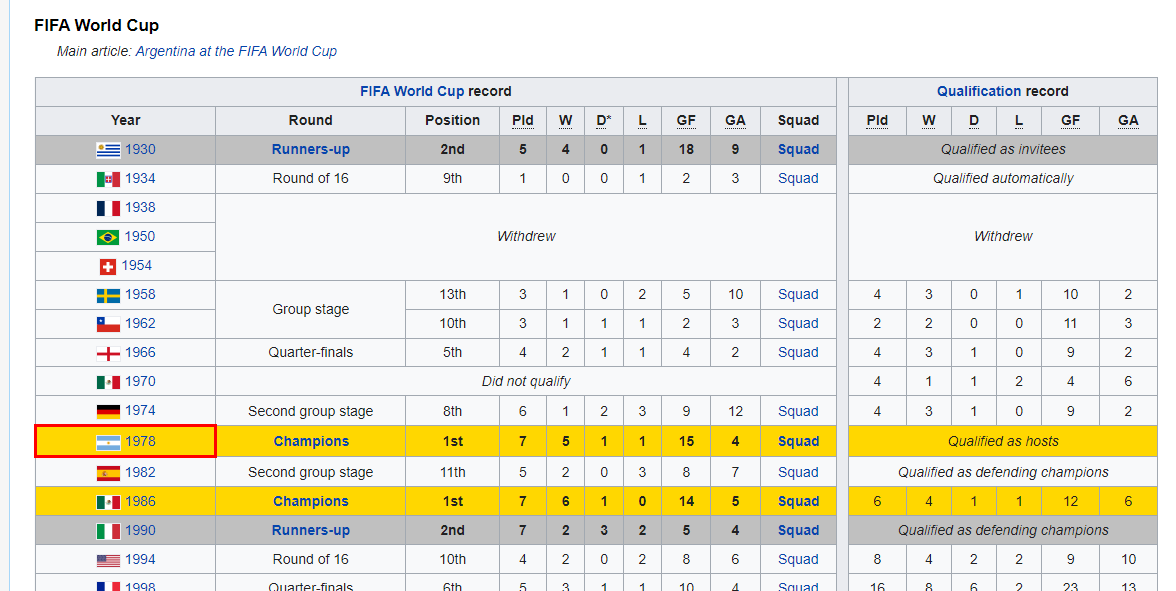
Bild aus Wikipedia
Um eine HTML-Tabelle zu laden, werden wir die Pakete XML und RCurl verwenden. Wir übergeben die Wikipedia-URL an die Funktion "getURL" und fügen das Objekt dann der Funktion "readHTMLTable" hinzu, wie unten gezeigt.
Die Funktion extrahiert alle HTML-Tabellen aus der Website und wir müssen sie nur noch einzeln untersuchen, um die gewünschte Tabelle auszuwählen.
library(XML)
library(RCurl)
url <- getURL("https://en.wikipedia.org/wiki/Brazil_national_football_team")
tables <- readHTMLTable(url)
data7 <- tables[31]
data7$`NULL`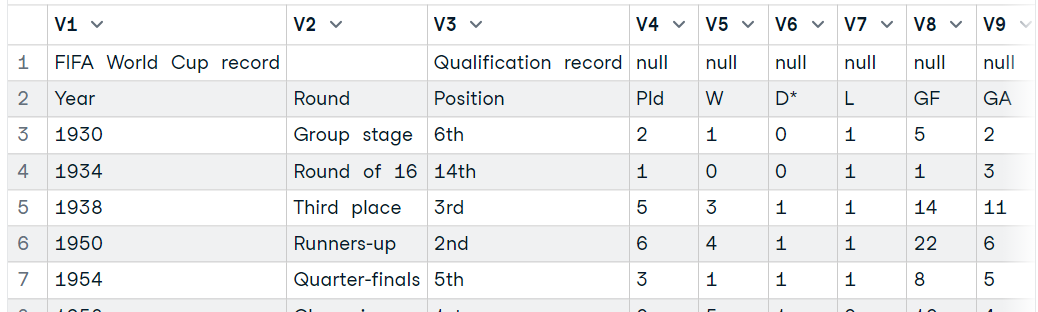
Außerdem kannst du das rvest-Paket verwenden, um HTML über eine URL zu lesen, alle Tabellen zu extrahieren und sie als Datenrahmen anzuzeigen.
library(rvest)
url <- "https://en.wikipedia.org/wiki/Argentina_national_football_team"
file<-read_html(url)
tables<-html_nodes(file, "table")
data8 <- html_table(tables[25])
View(data8)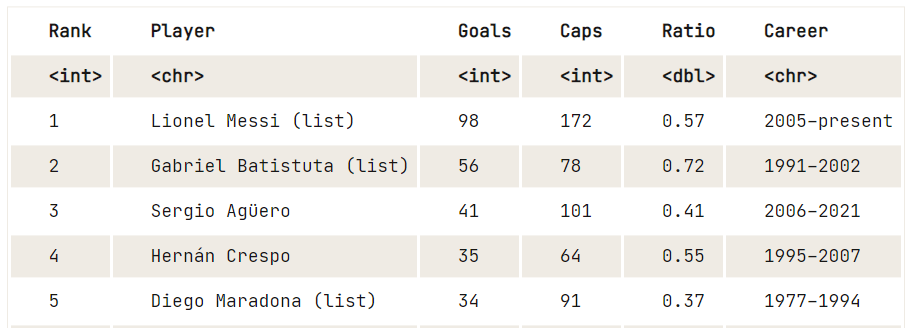
Wenn du Probleme hast, dem Tutorial zu folgen, kannst du dir jederzeit die DataLab-Arbeitsmappe mit dem gesamten Code für dieses Tutorial ansehen. Mach einfach eine Kopie und fang an zu üben.
Die anderen weniger beliebten, aber wichtigen Datentypen stammen aus Statistiksoftware, Matlab und Binärdaten.
In diesem Abschnitt werden wir das haven-Paket verwenden, um SAS-Dateien zu importieren. Du kannst die Daten auf dem GeeksforGeeks-Blog herunterladen. Mit dem haven-Paket kannst du SAS-, SPSS- und Stata-Dateien mit minimalem Code in R laden.
Gib der Funktion `read_sas` das Dateiverzeichnis an, um die Datei `.sas7bdat` als Datenrahmen zu laden. Lies die Dokumentation der Funktion, um mehr über sie zu erfahren.
library(haven)
data10 <- read_sas('data/lond_small.sas7bdat')
# display data
head(data10,5)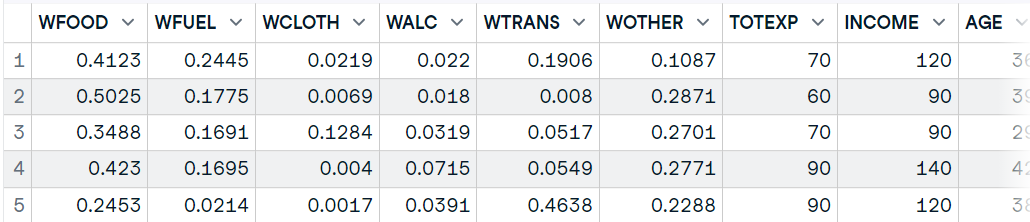
Wie wir bereits wissen, können wir auch das haven-Paket verwenden, um SPSS-Dateien in R zu laden. Du kannst die Daten vom GeeksforGeeks-Blog herunterladen und die Funktion `read_sav` verwenden, um einfach die SPSS sav-Datei zu laden.
Sie benötigt das Dateiverzeichnis als String und du kannst deinen Datenrahmen mit zusätzlichen Argumenten wie encoding, col_select und compress anpassen.
library(haven)
data11 <- read_sav("data/airline_passengers.sav")
head(data11,5)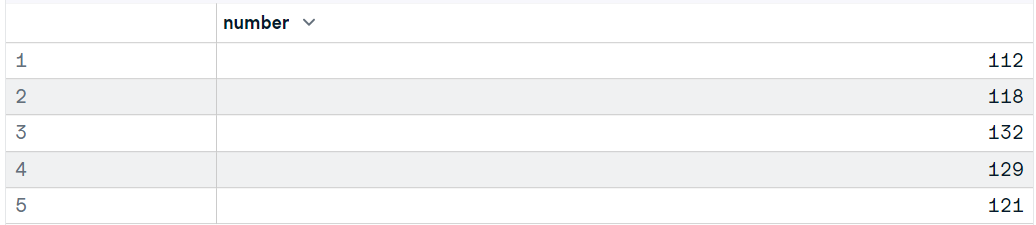
Du kannst auch ein fremdes Paket verwenden, um eine `.sav`-Datei mit der Funktion `read.spss` als Datenrahmen zu laden. Die Funktion benötigt nur zwei Argumente : file und to.data.frame. Erfahre mehr über andere Argumente, indem du die Dokumentation der Funktion liest.
Hinweis: Mit dem Fremdpaket kannst du auch die Dateiformate Minitab, S, SAS, SPSS, Stata, Systat, Weka und Octave laden.
library("foreign")
data12 <- read.spss("data/airline_passengers.sav", to.data.frame = TRUE)
head(data12,5)
In diesem Teil werden wir das Fremdpaket verwenden, um die Stata-Datei von ucla.edu zu laden.
read.dta liest eine Datei in den Binärformaten von Stata Version 5-12 und wandelt sie in einen Datenrahmen um.
"So einfach ist das."
library("foreign")
data13 <- read.dta("data/friendly.dta")
head(data13,5)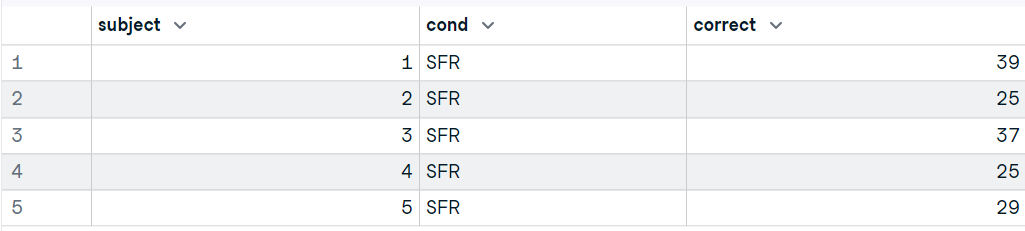
Matlab ist bei Studenten und Forschern sehr beliebt. Mit R.matlab können wir die Datei `.mat` laden, so dass wir Datenanalysen und Simulationen in R durchführen können.
Lade die Matlab-Dateien von Kaggle herunter, um es selbst zu versuchen.
library(R.matlab)
data14 <- readMat("data/cross_dsads.mat")
head(data14$data.dsads)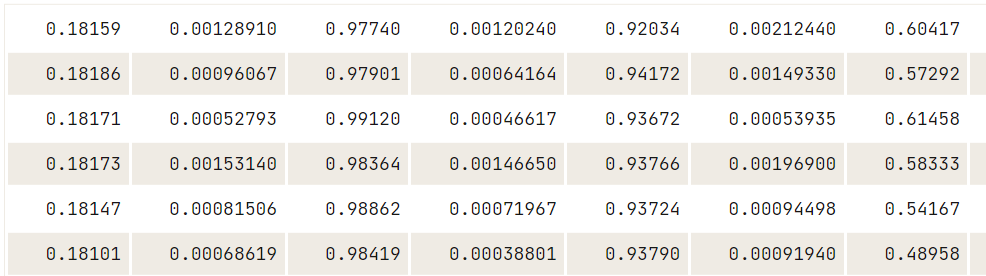
In diesem Teil werden wir zuerst eine Binärdatei erstellen und dann die Datei mit der Funktion `readBin` lesen.
Hinweis: Das Codebeispiel ist eine modifizierte Version des Blogs Working with Binary Files in R Programming.
Zuerst müssen wir einen Datenrahmen mit vier Spalten und vier Zeilen erstellen.
df = data.frame(
"ID" = c(1, 2, 3, 4),
"Name" = c("Abid", "Matt", "Sara", "Dean"),
"Age" = c(34, 25, 27, 50),
"Pin" = c(234512, 765345, 345678, 098567)
)Danach erstellst du ein Verbindungsobjekt mit der Funktion "Datei".
con = file("data/binary_data.dat", "wb")Schreibe die Spaltennamen mit der Funktion `writeBin` in die Datei.
writeBin(colnames(df), con)Schreibe die Werte der einzelnen Spalten in die Datei.
writeBin(c(df$ID, df$Name, df$Age, df$Pin), con)Beende die Verbindung, nachdem du die Daten in die Datei geschrieben hast.
close(con)Um die Binärdatei zu lesen, müssen wir eine Verbindung zur Datei herstellen und die Funktion `readBin` verwenden, um die Daten als Ganzzahl anzuzeigen.
Argumente, die in der Funktion verwendet werden:
con = file("data/binary_data.dat", "rb")
data15_1 = readBin(con, integer(), n = 25)
print(data15_1)Ausgabe:
[1] 1308640329 6647137 6645569 7235920 3276849 3407923
[7] 1684628033 1952533760 1632829556 1140875634 7233893 838874163
[13] 926023733 3159296 892613426 922759729 875771190 875757621
[19] 943142453 892877056Du kannst die Daten auch von binär in string umwandeln, indem du "integer()" durch "character()" im Argument `what` ersetzt.
Lies die Dokumentation der Funktion readBin, um mehr zu erfahren.
con = file("data/binary_data.dat", "rb")
data15_2 = readBin(con, character(), n = 25)
print(data15_2)Ausgabe:
[1] "ID" "Name" "Age" "Pin" "1" "2" "3" "4"
[9] "Abid" "Matt" "Sara" "Dean" "34" "25" "27" "50"
[17] "234512" "765345" "345678" "98567" Lerne im Kurs Intermediate Importing Data in R, wie du Flat Files, Statistiksoftware, Datenbanken oder Daten direkt aus dem Internet importierst.
Quantmod ist ein Finanzmodellierungs- und Handelsframework für R. Wir werden es verwenden, um die neuesten Handelsdaten in Form eines Datenrahmens herunterzuladen und zu laden.
Wir verwenden die Funktion `getSymbols` von quantmod, um die historischen Daten von Google Stock zu laden, indem wir das Datum "von" und "bis" sowie die "Häufigkeit" angeben. Erfahre mehr über das quantmod-Paket, indem du die Dokumentation liest.
library(quantmod)
getSymbols("GOOGL",
from = "2022/12/1",
to = "2023/1/15",
periodicity = "daily")
# 'GOOGL'Die Daten werden in ein "GOOGL"-Objekt geladen, und wir können uns die ersten fünf Zeilen mit der Funktion "head()" ansehen.
head(GOOGL,5)Ausgabe:
GOOGL.Open GOOGL.High GOOGL.Low GOOGL.Close GOOGL.Volume
2022-12-01 101.02 102.25 100.25 100.99 28687100
2022-12-02 99.05 100.77 98.90 100.44 21480700
2022-12-05 99.40 101.38 99.00 99.48 24405100
2022-12-06 99.30 99.78 96.42 96.98 24910700
2022-12-07 96.41 96.88 94.72 94.94 31045400
GOOGL.Adjusted
2022-12-01 100.99
2022-12-02 100.44
2022-12-05 99.48
2022-12-06 96.98
2022-12-07 94.94Das Importieren einer großen Datei ist knifflig. Du musst darauf achten, dass die Funktion für eine speichereffiziente Speicherung und einen schnellen Zugriff optimiert ist.
In diesem Abschnitt befassen wir uns mit gängigen Funktionen zum Laden von CSV-Dateien, die größer als 1 GB sind. Wir verwenden den US-Unfalldatensatz (2016 - 2021) von Kaggle, der etwa 1,15 GB groß ist und 2.845.342 Datensätze enthält.
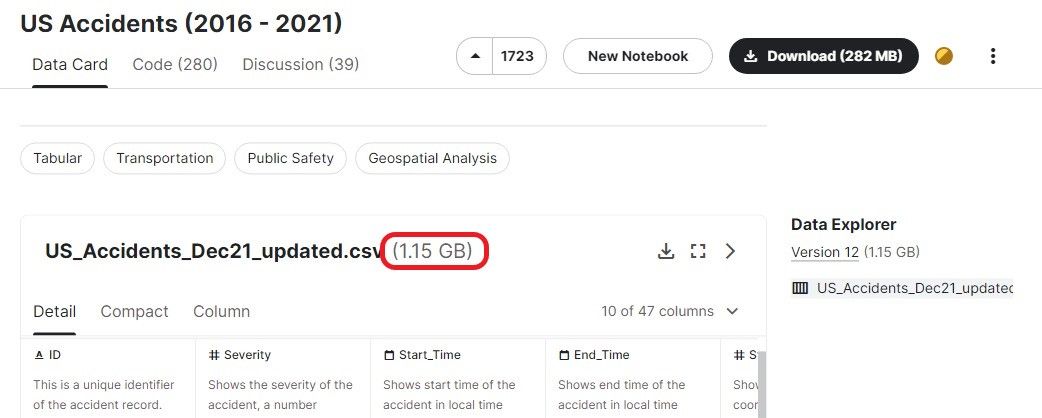
Wir können die Zip-Datei direkt in die Funktion read.table von utilsladen, indem wir die Funktion `unz` verwenden. So sparst du Zeit beim Extrahieren und Laden der CSV-Datei.
file <- unz("data/US Accidents.zip", "US_Accidents_Dec21_updated.csv")
data16 <- read.table(file, header=T, sep=",",nrow=10000)
data16
Ähnlich wie bei `read.table` können wir die Funktion `read_csv` von readr verwenden, um die CSV-Datei zu laden. Anstelle von nrow verwenden wir n_max, um eine begrenzte Anzahl von Datensätzen zu lesen.
In unserem Fall schränken wir keine Daten ein und erlauben der Funktion, alle Daten zu laden.
Hinweis: Es hat fast eine Minute gedauert, bis alle Daten geladen waren. Du kannst die Anzahl der Threads ändern, um die Ladezeit zu verkürzen. Erfahre mehr, indem du die Dokumentation der Funktion liest.
data17 <- read_csv('data/US_Accidents_Dec21_updated.csv')
data17
Wir können auch das ff-Paket nutzen, um Ladezeit und Speicherung zu optimieren. Die Funktion read.table.ffdf lädt die Daten in Paketen und verkürzt so die Ladezeit.
Zuerst entpacken wir die Datei und lesen die Daten mit der Funktion "read.table.ffdf".
unzip('data/US Accidents.zip',exdir='data')
library(ff)
data18 <- read.table.ffdf(file="data/US_Accidents_Dec21_updated.csv",
nrows=10000,
header = TRUE,
sep = ',')
data18[1:5,1:25]
Zum Schluss schauen wir uns die am häufigsten verwendete Funktion `fread` aus dem data.table Paket an, um die ersten 10.000 Zeilen zu lesen. Die Funktion kann das Dateiformat automatisch verstehen, aber in seltenen Fällen musst du ein sep-Argument angeben.
library(data.table)
data19 <- fread("data/US_Accidents_Dec21_updated.csv",
sep=',',
nrows = 10000,
na.strings = c("NA","N/A",""),
stringsAsFactors=FALSE
)
data19
Wenn du die Code-Beispiele selbst ausprobieren möchtest, findest du hier eine Liste mit allen Datensätzen, die im Tutorial verwendet werden.
R ist eine fantastische Sprache, die alle möglichen Integrationen mitbringt. Du kannst jede Art von Datensatz laden, ihn bereinigen und bearbeiten, explorative und prädiktive Datenanalysen durchführen und hochwertige Berichte veröffentlichen.
In diesem Tutorium haben wir gelernt, wie man alle Arten von Datensätzen mit den beliebten R-Paketen für eine bessere Speicherung und Leistung lädt. Wenn du deine Karriere in den Datenwissenschaften mit R beginnen möchtest, schau dir den Karrierepfad Data Scientist with R an. Es besteht aus 24 interaktiven Kursen, in denen du alles über R-Programmierung, statistische Analyse, Datenverarbeitung und prädiktive Analyse lernst. Außerdem kannst du nach Abschluss des Kurses eine Zertifizierungsprüfung ablegen, um in den Arbeitsmarkt einzusteigen.
Schau dir auch die Arbeitsmappe Import Data Into R DataLab an, die den Quellcode, die Ausgaben und ein Daten-Repository enthält. Du kannst dir eine Kopie machen und selbst anfangen zu lernen.
Erfahre mehr über R
Kurs
Kurs
Kurs
Tutorial
Moez Ali
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
Tutorial
Aditya Sharma
Tutorial
Matt Crabtree
Tutorial
DataCamp Team
