Curso
Importando e Gerenciando Dados Financeiros em R
5 h
20.9K

O R é uma ferramenta estatística avançada. Em comparação com outros softwares, como o Microsoft Excel, o R nos oferece carregamento de dados mais rápido, limpeza de dados automatizada e análise estatística e preditiva aprofundada. Tudo isso é feito com o uso de pacotes R de código aberto, e vamos aprender a usá-los para importar vários tipos de conjuntos de dados.
Usaremos o DataLab para executar exemplos de código. Ele vem com pacotes pré-instalados e com o ambiente R. Você não precisa configurar nada e começa a programar em segundos. É um serviço gratuito e vem com uma grande seleção de conjuntos de dados. Você também pode integrar seu servidor SQL para começar a realizar análises exploratórias de dados.
Depois de carregar a pasta de trabalho do DataLab, você precisa instalar alguns pacotes que não são populares, mas que são necessários para carregar arquivos do SAS, SPSS, Stata e Matlab.
Observação: Certifique-se de instalar as dependências usando o parâmetro `dependency=T` na função `install.packages`.
O pacote Tidyverse vem com vários pacotes que permitem que você leia arquivos simples, limpe dados, execute a manipulação e a visualização de dados e muito mais.
install.packages(c('quantmod','ff','foreign','R.matlab'),dependency=T)
suppressPackageStartupMessages(library(tidyverse))Neste tutorial, aprenderemos a carregar arquivos de dados CSV, TXT, Excel, JSON, banco de dados e XML/HTML comumente usados no R. Além disso, também examinaremos formatos de arquivos menos usados, como SAS, SPSS, Stata, Matlab e Binary.
Você aprenderá sobre todos os formatos de dados populares e os carregará usando vários pacotes do R. Além disso, usaremos URLs para extrair tabelas HTML e dados XML do site com poucas linhas de código.
Nesta seção, leremos dados em r carregando um arquivo CSV do Hotel Booking Demand. Esse conjunto de dados consiste em dados de reserva de um hotel urbano e de um hotel resort. Para importar o arquivo CSV, usaremos a função `read_csv` do pacote readr. Assim como no Pandas, ele exige que você insira o local do arquivo para processá-lo e carregá-lo como um dataframe.
Você também pode usar as funções `read.csv` ou `read.delim` do pacote utils para carregar arquivos CSV.
data1 <- read_csv('data/hotel_bookings_clean.csv',show_col_types = FALSE)
head(data1, 5)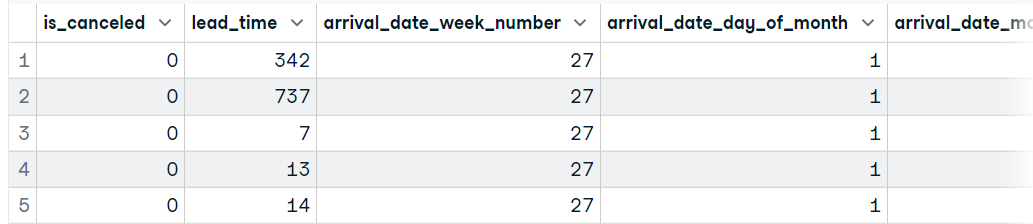
Semelhante a `read_csv`, você também pode usar a função read.table para carregar o arquivo. Verifique se você está adicionando o delimitador "," e o cabeçalho = 1. Ele definirá a primeira linha como nomes de coluna em vez de "V1", "V2",...
data2 <- read.table('data/hotel_bookings_clean.csv', sep=",", header = 1)
head(data2, 5)Nesta parte, usaremos o conjunto de dados Drake Lyrics para carregar um arquivo de texto. O arquivo consiste em letras de músicas do cantor Drake. Podemos usar a função `readLines` para carregar o arquivo simples, mas temos que executar tarefas adicionais para convertê-lo em um dataframe.

Imagem do autor | Arquivo de texto
Usaremos a função alternativa do read.table, `read.delim`, para carregar o arquivo de texto como um dataframe do R. Outras funções alternativas do read.table são read.csv, read.csv2 e read.delim2.
Observação: por padrão, você está separando os valores em Tab (sep = "\t")
O arquivo de texto consiste em letras e não tem uma linha de cabeçalho. Para exibir todas as letras em uma linha, precisamos definir `header = F`.
Você também pode usar outros parâmetros para personalizar seu dataframe, por exemplo, o parâmetro fill, que define o campo em branco a ser adicionado às linhas de comprimento desigual.
Leia a documentação para saber mais sobre cada parâmetro das funções alternativas do read.table.
data3 <- read.delim('data/drake_lyrics.txt',header = F)
head(data3, 5)
Nesta seção, usaremos o conjunto de dados Tesla Deaths do Kaggle para importar do Excel para o R. O conjunto de dados é sobre acidentes trágicos com veículos da Tesla que resultaram na morte de um motorista, ocupante, ciclista ou pedestre.
O conjunto de dados contém um arquivo CSV, e usaremos o MS Excel para convertê-lo em um arquivo Excel, conforme mostrado abaixo.
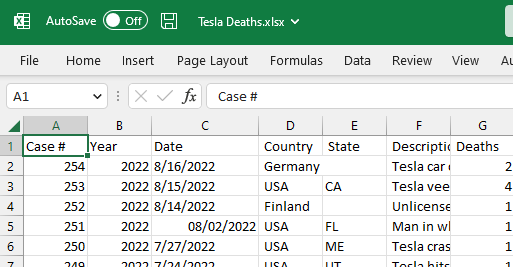
Imagem do autor
Usaremos a função `read_excel` do pacote readxl para ler uma única planilha de um arquivo do Excel. O pacote vem com tiddyvers, mas não é a parte principal dele, portanto, precisamos carregar o pacote antes de usar a função.
A função requer a localização dos dados e o número da planilha. Também podemos modificar a aparência do nosso dataframe lendo a descrição de outros parâmetros na documentação do read_excel.
library(readxl)
data4 <- read_excel("data/Tesla Deaths.xlsx", sheet = 1)
head(data4, 5)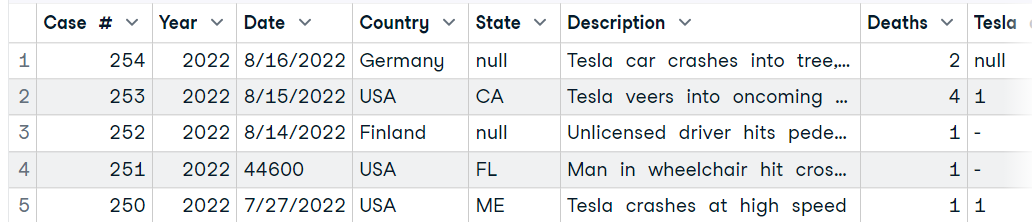
Nesta parte, carregaremos JSON no R usando um arquivo do conjunto de dados Drake Lyrics. Ele contém letras, título da música, título do álbum, URL e contagem de visualizações das músicas do Drake.

Imagem do autor
Para carregar um arquivo JSON, carregaremos o pacote rjson e usaremos `fromJSON` para analisar o arquivo JSON.
library(rjson)
JsonData <- fromJSON(file = 'data/drake_data.json')
print(JsonData[1])Saída:
[[1]]
[[1]]$album
[1] "Certified Lover Boy"
[[1]]$lyrics_title
[1] "Certified Lover Boy* Lyrics"
[[1]]$lyrics_url
[1] "https://genius.com/Drake-certified-lover-boy-lyrics"
[[1]]$lyrics
[1] "Lyrics from CLB Merch\n\n[Verse]\nPut my feelings on ice\nAlways been a gem\nCertified lover boy, somehow still heartless\nHeart is only gettin' colder"
[[1]]$track_views
[1] "8.7K"Para converter os dados JSON em um dataframe do R, usaremos a função `as.data.frame` do pacote data.table.
data5 = as.data.frame(JsonData[1])
data5
Nesta parte, usaremos o conjunto de dados Mental Health in the Tech Industry do Kaggle para carregar bancos de dados SQLite usando o R. Para extrair os dados dos bancos de dados usando a consulta SQL, usaremos o pacote DBI e a função SQLite e criaremos a conexão. Você também pode usar sintaxe semelhante para carregar dados de outros servidores SQL.
Carregaremos o pacote RSQLite e carregaremos o banco de dados usando a função dbConnect.
Observação: você pode usar o dbConnect para carregar dados do MySQL, PostgreSQL e outros servidores SQL populares.
Depois de carregar o banco de dados, exibiremos os nomes das tabelas.
library(RSQLite)
conn <- dbConnect(RSQLite::SQLite(), "data/mental_health.sqlite")
dbListTables(conn)
# 'Answer''Question''Survey'Para executar uma consulta e exibir os resultados, usaremos a função `dbGetQuery`. Basta adicionar um objeto de conexão SQLite e uma consulta SQL como uma string.
dbGetQuery(conn, "SELECT * FROM Survey")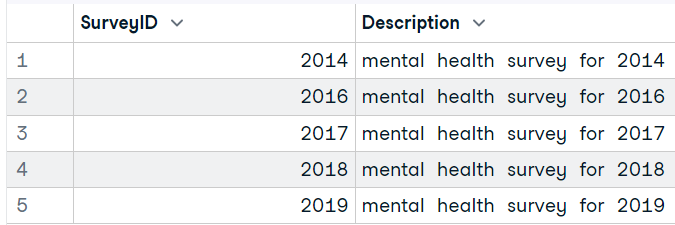
O uso do SQL no R oferece a você maior controle da ingestão e análise de dados.
data6 = dbGetQuery(conn, "SELECT * FROM Question LIMIT 3")
data6
Saiba mais sobre como executar consultas SQL no R seguindo o tutorial Como executar consultas SQL no Python e no R. Ele ensinará a você como carregar bancos de dados e usar SQL com dplyr e ggplot.
Nesta seção, carregaremos os dados XML de plant_catalog do w3schools usando o pacote xml2.
Observação: Você também pode usar a função `xmlTreeParse` do pacote XML para carregar os dados.
Assim como a função `read_csv`, podemos carregar os dados XML fornecendo um link de URL para o site XML. Ele carregará a página e analisará os dados XML.
library(xml2)
plant_xml <- read_xml('https://www.w3schools.com/xml/plant_catalog.xml')
plant_xml_parse <- xmlParse(plant_xml)Posteriormente, você pode converter dados XML em um quadro de dados R usando a função `xmlToDataFrame`.
1. Extrair conjunto de nós de dados XML.
2. Adicione o nó `plant_node` à função `xmlToDataFrame` e exiba as cinco primeiras linhas do dataframe do R.
plant_nodes= getNodeSet(plant_xml_parse, "//PLANT")
data9 <- xmlToDataFrame(nodes=plant_nodes)
head(data9,5)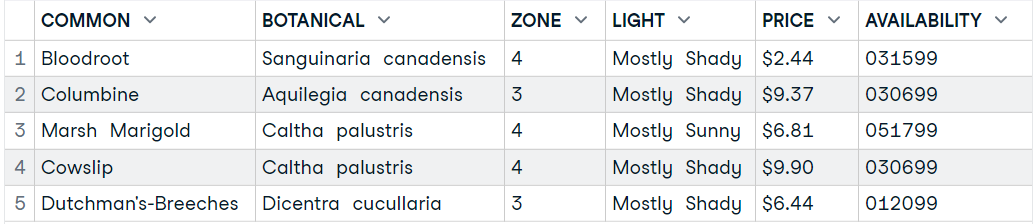
Esta seção é divertida, pois vamos raspar a página da Wikipedia da seleção argentina de futebol para extrair a tabela HTML e convertê-la em um quadro de dados com poucas linhas de código.
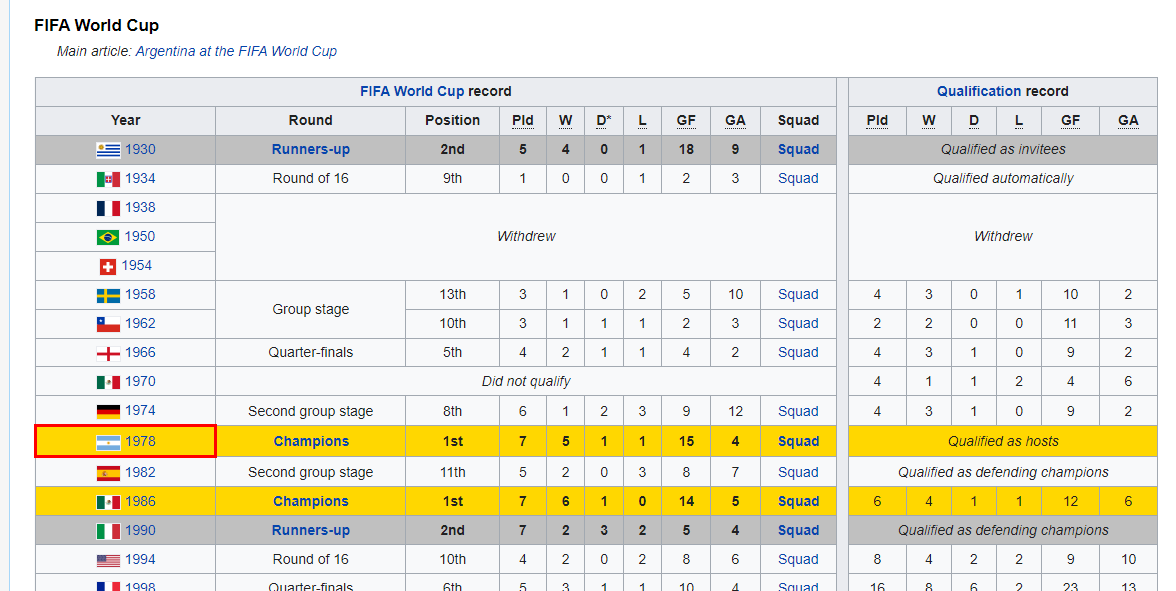
Imagem da Wikipedia
Para carregar uma tabela HTML, usaremos os pacotes XML e RCurl. Forneceremos o URL da Wikipédia à função `getURL` e, em seguida, adicionaremos o objeto à função `readHTMLTable`, conforme mostrado abaixo.
A função extrairá todas as tabelas HTML do site, e você só precisará explorá-las individualmente para selecionar a que deseja.
library(XML)
library(RCurl)
url <- getURL("https://en.wikipedia.org/wiki/Brazil_national_football_team")
tables <- readHTMLTable(url)
data7 <- tables[31]
data7$`NULL`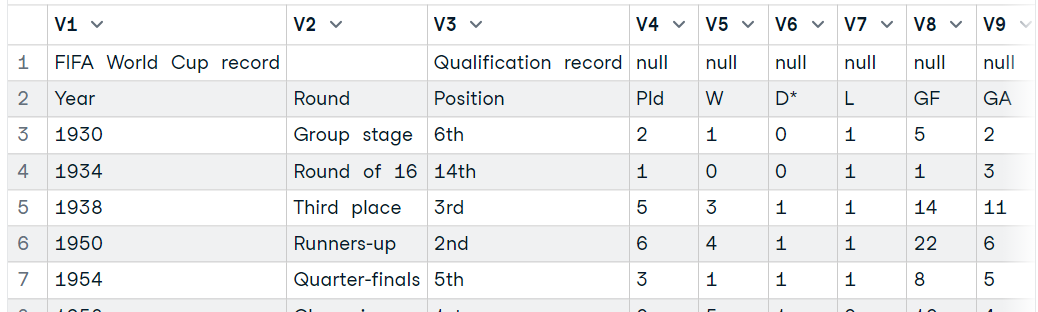
Além disso, você pode usar o pacote rvest para ler HTML usando URL, extrair todas as tabelas e exibi-las como um dataframe.
library(rvest)
url <- "https://en.wikipedia.org/wiki/Argentina_national_football_team"
file<-read_html(url)
tables<-html_nodes(file, "table")
data8 <- html_table(tables[25])
View(data8)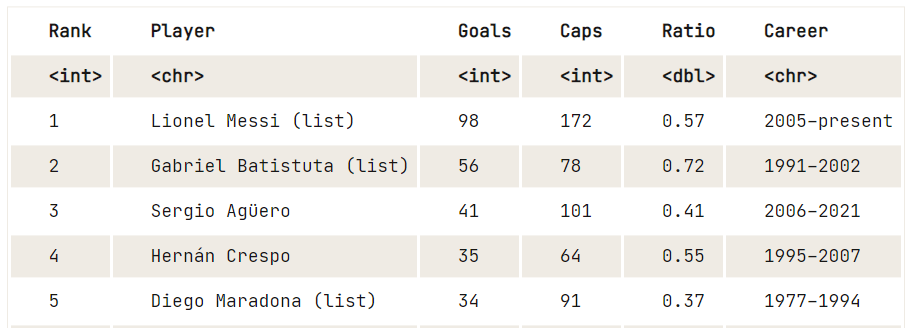
Se tiver problemas ao seguir o tutorial, você sempre poderá consultar a pasta de trabalho do DataLab com todo o código para este tutorial. Basta fazer uma cópia e começar a praticar.
Os outros tipos de dados menos populares, mas essenciais, são de software estatístico, Matlab e dados binários.
Nesta seção, usaremos o pacote haven para importar arquivos SAS. Você pode fazer o download dos dados no blog GeeksforGeeks. O pacote haven permite que você carregue arquivos SAS, SPSS e Stata no R com o mínimo de código.
Forneça o diretório do arquivo para a função `read_sas` para carregar o arquivo `.sas7bdat` como um dataframe. Leia a documentação da função para saber mais sobre ela.
library(haven)
data10 <- read_sas('data/lond_small.sas7bdat')
# display data
head(data10,5)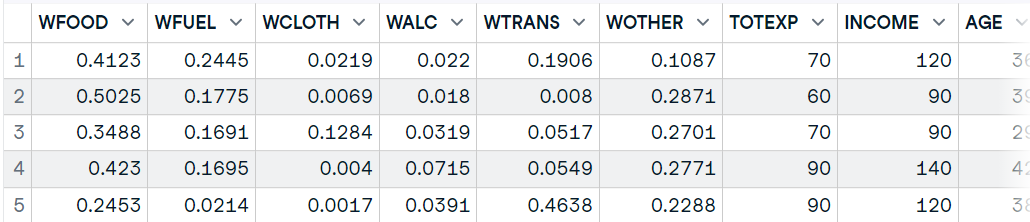
Como já sabemos, também podemos usar o pacote haven para carregar arquivos SPSS no R. Você pode baixar os dados do blog GeeksforGeeks e usar a função `read_sav` apenas para carregar o arquivo SPSS sav.
Ele requer o diretório do arquivo como uma cadeia de caracteres e você pode modificar o dataframe usando argumentos adicionais, como encoding, col_select e compress.
library(haven)
data11 <- read_sav("data/airline_passengers.sav")
head(data11,5)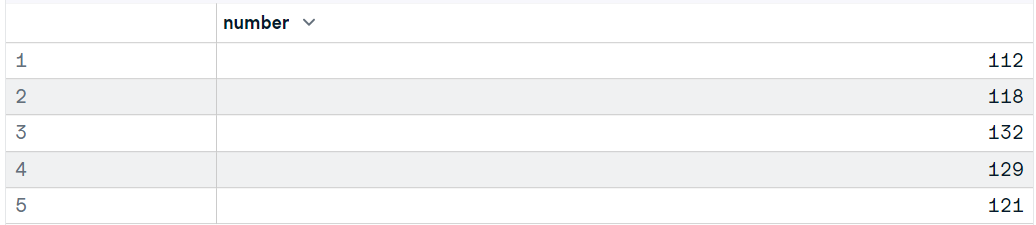
Você também pode usar um pacote externo para carregar um arquivo `.sav` como um dataframe usando a função `read.spss`. A função requer apenas dois argumentos: file e to.data.frame. Para saber mais sobre outros argumentos, leia a documentação da função.
Observação: o pacote estrangeiro também permite que você carregue os formatos de arquivo Minitab, S, SAS, SPSS, Stata, Systat, Weka e Octave.
library("foreign")
data12 <- read.spss("data/airline_passengers.sav", to.data.frame = TRUE)
head(data12,5)
Nesta parte, usaremos o pacote foreign para carregar o arquivo Stata do site ucla.edu.
O read.dta lê um arquivo nos formatos binários do Stata versão 5-12 e o converte em um quadro de dados.
"É simples assim."
library("foreign")
data13 <- read.dta("data/friendly.dta")
head(data13,5)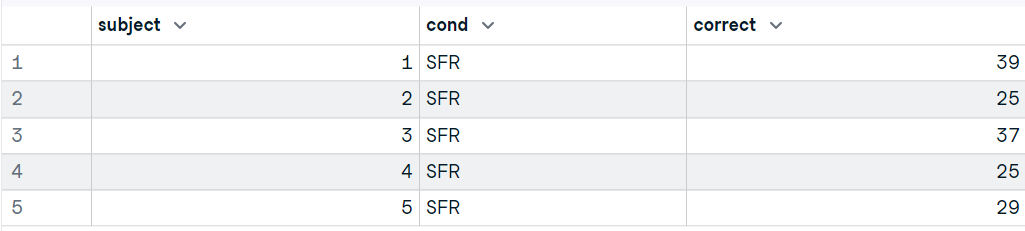
O Matlab é bastante famoso entre estudantes e pesquisadores. O R.matlab nos permite carregar o arquivo`.mat`, para que possamos realizar a análise de dados e executar simulações no R.
Faça o download dos arquivos Matlab do Kaggle para experimentar você mesmo.
library(R.matlab)
data14 <- readMat("data/cross_dsads.mat")
head(data14$data.dsads)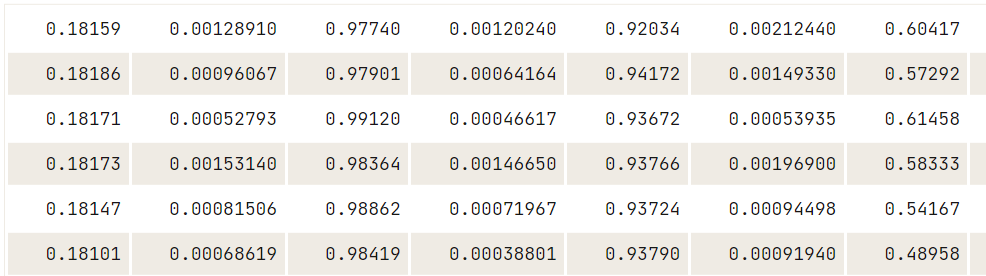
Nesta parte, primeiro criaremos um arquivo binário e, em seguida, leremos o arquivo usando a função `readBin`.
Observação: o exemplo de código é uma versão modificada do blog Working with Binary Files in R Programming.
Primeiro, precisamos criar um dataframe com quatro colunas e quatro linhas.
df = data.frame(
"ID" = c(1, 2, 3, 4),
"Name" = c("Abid", "Matt", "Sara", "Dean"),
"Age" = c(34, 25, 27, 50),
"Pin" = c(234512, 765345, 345678, 098567)
)Depois disso, crie um objeto de conexão usando uma função `file`.
con = file("data/binary_data.dat", "wb")Escreva os nomes das colunas no arquivo usando a função `writeBin`.
writeBin(colnames(df), con)Escreva o valor de cada coluna no arquivo.
writeBin(c(df$ID, df$Name, df$Age, df$Pin), con)Feche a conexão depois de gravar os dados no arquivo.
close(con)Para ler o arquivo binário, precisamos criar uma conexão com o arquivo e usar a função `readBin` para exibir os dados como um número inteiro.
Argumentos usados na função:
con = file("data/binary_data.dat", "rb")
data15_1 = readBin(con, integer(), n = 25)
print(data15_1)Saída:
[1] 1308640329 6647137 6645569 7235920 3276849 3407923
[7] 1684628033 1952533760 1632829556 1140875634 7233893 838874163
[13] 926023733 3159296 892613426 922759729 875771190 875757621
[19] 943142453 892877056Você também pode converter os dados de binário para string, substituindo "integer()" por "character()" no argumento `what`.
Leia a documentação da função readBin para saber mais.
con = file("data/binary_data.dat", "rb")
data15_2 = readBin(con, character(), n = 25)
print(data15_2)Saída:
[1] "ID" "Name" "Age" "Pin" "1" "2" "3" "4"
[9] "Abid" "Matt" "Sara" "Dean" "34" "25" "27" "50"
[17] "234512" "765345" "345678" "98567" Aprenda a importar arquivos simples, software estatístico, bancos de dados ou dados diretamente da Web com o curso Intermediate Importing Data in R.
O quantmod é uma estrutura de modelagem e negociação financeira para o R. Vamos usá-lo para fazer download e carregar os dados de negociação mais recentes na forma de um dataframe.
Usaremos a função `getSymbols` do quantmod para carregar os dados históricos das ações do Google, fornecendo as datas "from" e "to" e a "frequency". Para saber mais sobre o pacote quantmod, leia a documentação.
library(quantmod)
getSymbols("GOOGL",
from = "2022/12/1",
to = "2023/1/15",
periodicity = "daily")
# 'GOOGL'Os dados são carregados em um objeto `GOOGL` e podemos visualizar as cinco primeiras linhas usando a função `head()`.
head(GOOGL,5)Saída:
GOOGL.Open GOOGL.High GOOGL.Low GOOGL.Close GOOGL.Volume
2022-12-01 101.02 102.25 100.25 100.99 28687100
2022-12-02 99.05 100.77 98.90 100.44 21480700
2022-12-05 99.40 101.38 99.00 99.48 24405100
2022-12-06 99.30 99.78 96.42 96.98 24910700
2022-12-07 96.41 96.88 94.72 94.94 31045400
GOOGL.Adjusted
2022-12-01 100.99
2022-12-02 100.44
2022-12-05 99.48
2022-12-06 96.98
2022-12-07 94.94A importação de um arquivo grande é complicada. Você precisa garantir que a função seja otimizada para armazenamento eficiente de memória e acesso rápido.
Nesta seção, veremos as funções populares usadas para carregar arquivos CSV com mais de 1 GB. Estamos usando o conjunto de dados US Accidents (2016 - 2021) do Kaggle, que tem cerca de 1,15 GB de tamanho e 2.845.342 registros.
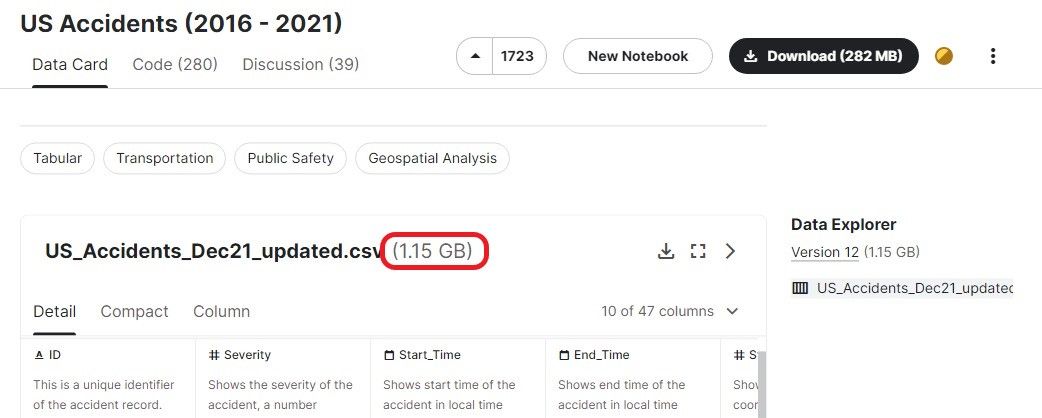
Podemos carregar o arquivo zip diretamente na função read.table do utilsusando a função `unz`. Você economizará tempo para extrair e depois carregar o arquivo CSV.
file <- unz("data/US Accidents.zip", "US_Accidents_Dec21_updated.csv")
data16 <- read.table(file, header=T, sep=",",nrow=10000)
data16
Da mesma forma que `read.table`, podemos usar a função `read_csv` do readr para carregar o arquivo CSV. Em vez de nrow, usaremos n_max para ler um número limitado de registros.
No nosso caso, não estamos restringindo nenhum dado e permitindo que a função carregue dados completos.
Observação: você levou quase um minuto para carregar os dados completos. Você pode alterar o número de threads para reduzir o tempo de carregamento. Para saber mais, leia a documentação da função.
data17 <- read_csv('data/US_Accidents_Dec21_updated.csv')
data17
Também podemos usar o pacote ff para otimizar o tempo de carregamento e o armazenamento. A função read.table.ffdf carrega dados em partes, reduzindo o tempo de carregamento.
Primeiro, descompactaremos o arquivo e leremos os dados usando a função `read.table.ffdf`.
unzip('data/US Accidents.zip',exdir='data')
library(ff)
data18 <- read.table.ffdf(file="data/US_Accidents_Dec21_updated.csv",
nrows=10000,
header = TRUE,
sep = ',')
data18[1:5,1:25]
No final, veremos a função `fread` mais comumente usada do pacote data.table para ler as primeiras 10.000 linhas. A função pode entender automaticamente o formato do arquivo, mas, em casos raros, você precisa fornecer um argumento sep.
library(data.table)
data19 <- fread("data/US_Accidents_Dec21_updated.csv",
sep=',',
nrows = 10000,
na.strings = c("NA","N/A",""),
stringsAsFactors=FALSE
)
data19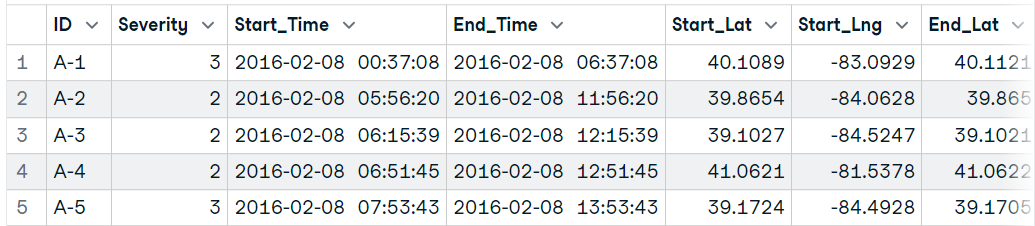
Se você quiser experimentar os exemplos de código por conta própria, aqui está a lista de todos os conjuntos de dados usados no tutorial.
O R é uma linguagem incrível e vem com todos os tipos de integração. Você pode carregar qualquer tipo de conjunto de dados, limpá-lo e manipulá-lo, realizar análises exploratórias e preditivas de dados e publicar relatórios de alta qualidade.
Neste tutorial, aprendemos a carregar todos os tipos de conjuntos de dados usando os pacotes populares do R para melhorar o armazenamento e o desempenho. Se você deseja iniciar sua carreira em ciência de dados com o R, confira a trilha de carreira de Cientista de Dados com R . Ele consiste em 24 cursos interativos que ensinarão a você tudo sobre programação em R, análise estatística, manipulação de dados e análise preditiva. Além disso, você pode fazer um exame de certificação após concluir o curso para entrar no mercado de trabalho.
Confira também a pasta de trabalho Import Data Into R DataLab, que vem com código-fonte, resultados e um repositório de dados. Você pode fazer uma cópia e começar a aprender por conta própria.
Saiba mais sobre o R
Curso
Curso
Curso
blog
Karlijn Willems
15 min
Tutorial
Vidhi Chugh
Tutorial
DataCamp Team
Tutorial
Natassha Selvaraj
Tutorial
Kurtis Pykes