Types de données pour la science des données en Python
65.5K learners
Exécutez et modifiez le code de ce tutoriel en ligne
Exécuter le code
Si vous regardez la sortie des variables dataScientist et dataEngineer ci-dessus, vous remarquerez que les valeurs de l'ensemble ne sont pas dans l'ordre où elles ont été ajoutées. En effet, les ensembles ne sont pas ordonnés.
Les ensembles contenant des valeurs peuvent également être initialisés en utilisant des accolades.
dataScientist = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
dataEngineer = {'Python', 'Java', 'Scala', 'Git', 'SQL', 'Hadoop'}
N'oubliez pas que les accolades ne peuvent être utilisées que pour initialiser un ensemble de valeurs. L'image ci-dessous montre que l'utilisation d'accolades sans valeurs est l'une des façons d'initialiser un dictionnaire et non un ensemble.

Pour ajouter ou supprimer des valeurs d'un ensemble, vous devez d'abord initialiser l'ensemble.
# Initialize set with values
graphicDesigner = {'InDesign', 'Photoshop', 'Acrobat', 'Premiere', 'Bridge'}Vous pouvez utiliser la méthode add pour ajouter une valeur à un ensemble.
graphicDesigner.add('Illustrator')
Il est important de noter que vous ne pouvez ajouter qu'une valeur immuable (comme une chaîne de caractères ou un tuple) à un ensemble. Par exemple, vous obtiendrez une TypeError si vous essayez d'ajouter une liste à un ensemble.
graphicDesigner.add(['Powerpoint', 'Blender'])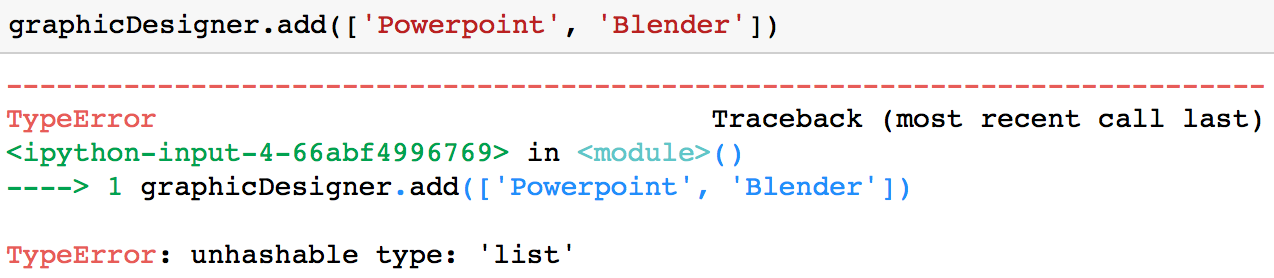
Il existe plusieurs façons de supprimer une valeur d'un ensemble.
Option 1 : Vous pouvez utiliser la méthode remove pour supprimer une valeur d'un ensemble.
graphicDesigner.remove('Illustrator')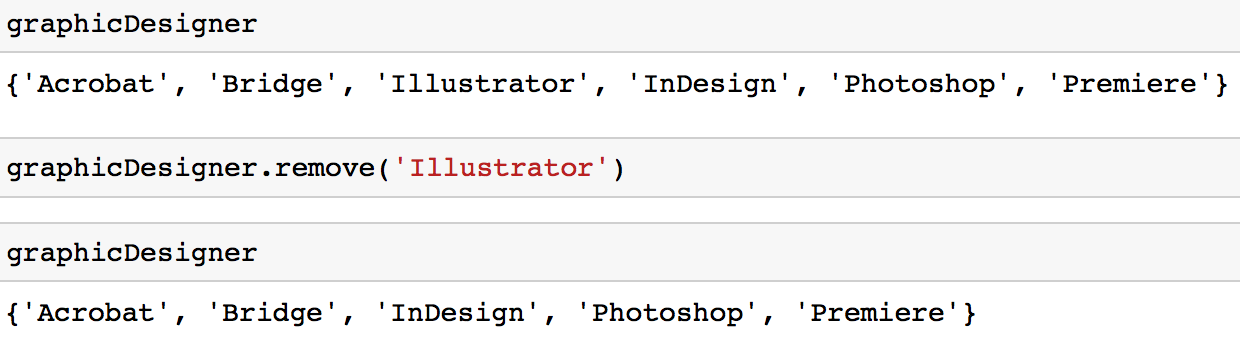
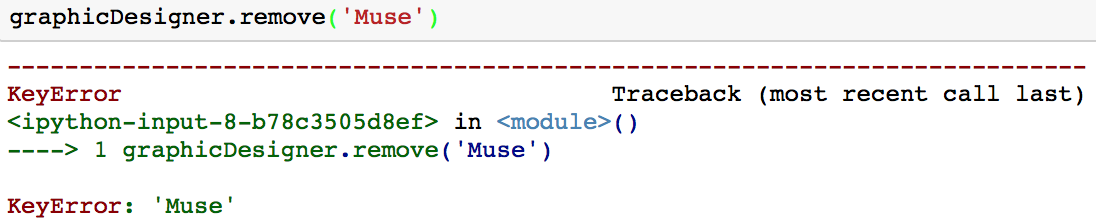
L'inconvénient de cette méthode est que si vous essayez de supprimer une valeur qui ne fait pas partie de votre ensemble, vous obtiendrez une KeyError.
Option 2 : Vous pouvez utiliser la méthode discard pour supprimer une valeur d'un ensemble.
graphicDesigner.discard('Premiere')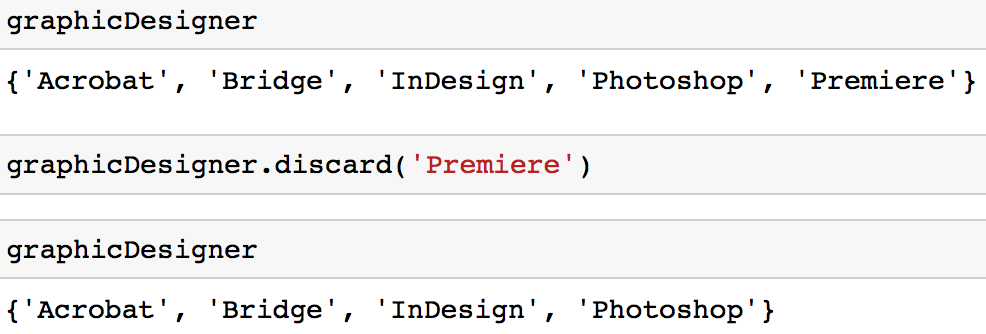
L'avantage de cette approche par rapport à la méthode remove est que si vous essayez de supprimer une valeur qui ne fait pas partie de l'ensemble, vous n'obtiendrez pas d'erreur KeyError. Si vous êtes familier avec les dictionnaires, vous constaterez que cette méthode fonctionne de la même manière que la méthode get du dictionnaire.
Option 3 : Vous pouvez également utiliser la méthode pop pour retirer et renvoyer une valeur arbitraire d'un ensemble.
graphicDesigner.pop()
Il est important de noter que la méthode soulève une KeyError si l'ensemble est vide.
Vous pouvez utiliser la méthode clear pour supprimer toutes les valeurs d'un ensemble.
graphicDesigner.clear()
La méthode de mise à jour ajoute les éléments d'un ensemble à un autre ensemble. Il nécessite un seul argument qui peut être un ensemble, une liste, des tuples ou un dictionnaire. La méthode .update() convertit automatiquement les autres types de données en ensembles et les ajoute à l'ensemble.
Dans l'exemple, nous avons initialisé trois ensembles et utilisé une fonction de mise à jour pour ajouter des éléments de l'ensemble 2 à l'ensemble 1, puis de l'ensemble 3 à l'ensemble 1.
# Initialize 3 sets
set1 = set([7, 10, 11, 13])
set2 = set([11, 8, 9, 12, 14, 15])
set3 = {'d', 'f', 'h'}
# Update set1 with set2
set1.update(set2)
print(set1)
# Update set1 with set3
set1.update(set3)
print(set1)
Comme de nombreux types de données standard de Python, il est possible d'itérer à travers un ensemble.
# Initialize a set
dataScientist = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
for skill in dataScientist:
print(skill)
Si vous regardez le résultat de l'impression de chacune des valeurs dans dataScientist, vous remarquerez que les valeurs imprimées dans l'ensemble ne sont pas dans l'ordre dans lequel elles ont été ajoutées. En effet, les ensembles ne sont pas ordonnés.
Ce cours a mis l'accent sur le fait que les ensembles ne sont pas ordonnés. Si vous avez besoin d'obtenir les valeurs de votre ensemble sous une forme ordonnée, vous pouvez utiliser la fonction sorted, qui produit une liste ordonnée.
type(sorted(dataScientist))
Le code ci-dessous affiche les valeurs de l'ensemble dataScientist dans l'ordre alphabétique décroissant (Z-A dans ce cas).
sorted(dataScientist, reverse = True)
Une partie du contenu de cette section a été précédemment explorée dans le didacticiel 18 Questions les plus courantes sur les listes de Python, mais il est important de souligner que les ensembles constituent le moyen le plus rapide de supprimer les doublons d'une liste. Pour le démontrer, étudions la différence de performance entre deux approches.
Approche 1 : Utilisez un ensemble pour supprimer les doublons d'une liste.
print(list(set([1, 2, 3, 1, 7])))Approche 2 : Utilisez une compréhension de liste pour supprimer les doublons d'une liste (si vous souhaitez un rappel sur les compréhensions de liste, consultez ce tutoriel).
def remove_duplicates(original):
unique = []
[unique.append(n) for n in original if n not in unique]
return(unique)
print(remove_duplicates([1, 2, 3, 1, 7]))La différence de performance peut être mesurée à l'aide de la bibliothèque timeit qui vous permet de chronométrer votre code Python. Le code ci-dessous exécute le code de chaque approche 10000 fois et indique le temps total en secondes.
import timeit
# Approach 1: Execution time
print(timeit.timeit('list(set([1, 2, 3, 1, 7]))', number=10000))
# Approach 2: Execution time
print(timeit.timeit('remove_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=10000))
La comparaison de ces deux approches montre qu'il est plus efficace d'utiliser des ensembles pour supprimer les doublons. Bien que la différence de temps puisse sembler minime, elle peut vous faire gagner beaucoup de temps si vous avez de très grandes listes.
Une utilisation courante des ensembles dans Python est le calcul d'opérations mathématiques standard telles que l'union, l'intersection, la différence et la différence symétrique. L'image ci-dessous montre quelques opérations mathématiques standard sur deux ensembles A et B. La partie rouge de chaque diagramme de Venn représente l'ensemble résultant d'une opération donnée sur un ensemble.
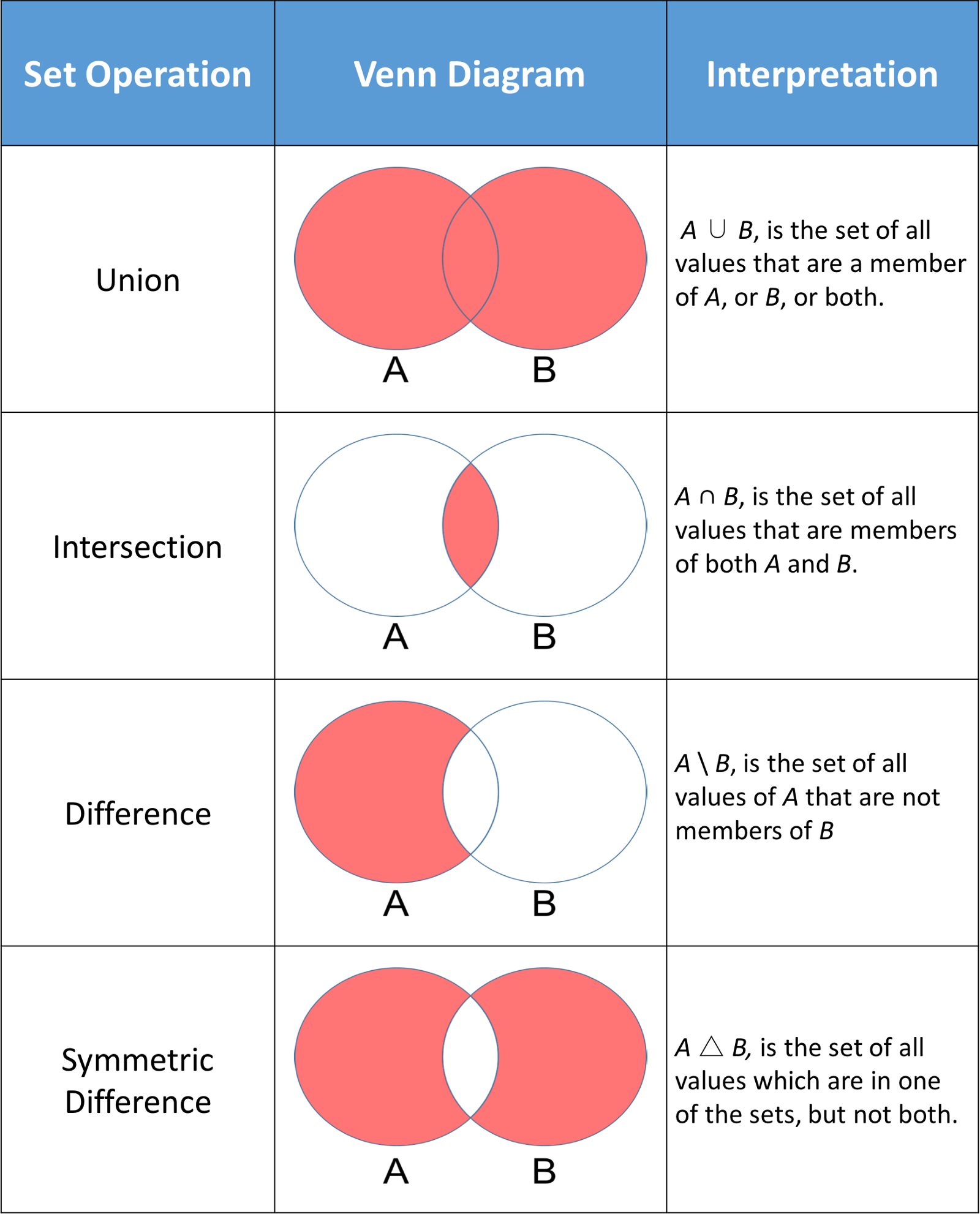
Les ensembles Python disposent de méthodes qui vous permettent d'effectuer ces opérations mathématiques ainsi que d'opérateurs qui vous donnent des résultats équivalents.
Avant d'explorer ces méthodes, commençons par initialiser deux ensembles, dataScientist et dataEngineer.
dataScientist = set(['Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'])
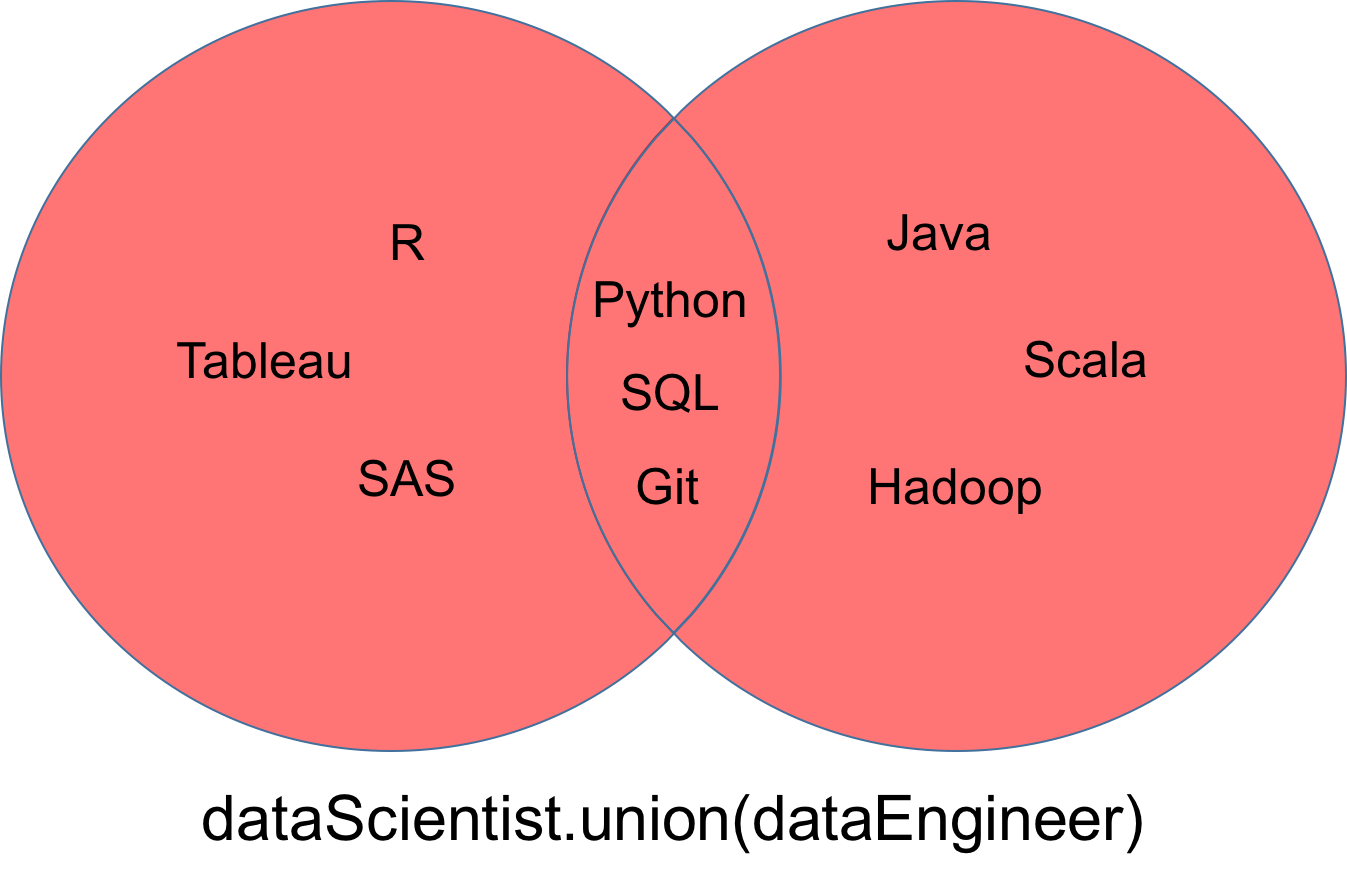
dataEngineer = set(['Python', 'Java', 'Scala', 'Git', 'SQL', 'Hadoop'])Une union, notée dataScientist ∪ dataEngineer, est l'ensemble de toutes les valeurs qui sont des valeurs de dataScientist, ou de dataEngineer, ou des deux. Vous pouvez utiliser la méthode union pour trouver toutes les valeurs uniques dans deux ensembles.
# set built-in function union
dataScientist.union(dataEngineer)
# Equivalent Result
dataScientist | dataEngineer
L'ensemble résultant de l'union peut être représenté par la partie rouge du diagramme de Venn ci-dessous.
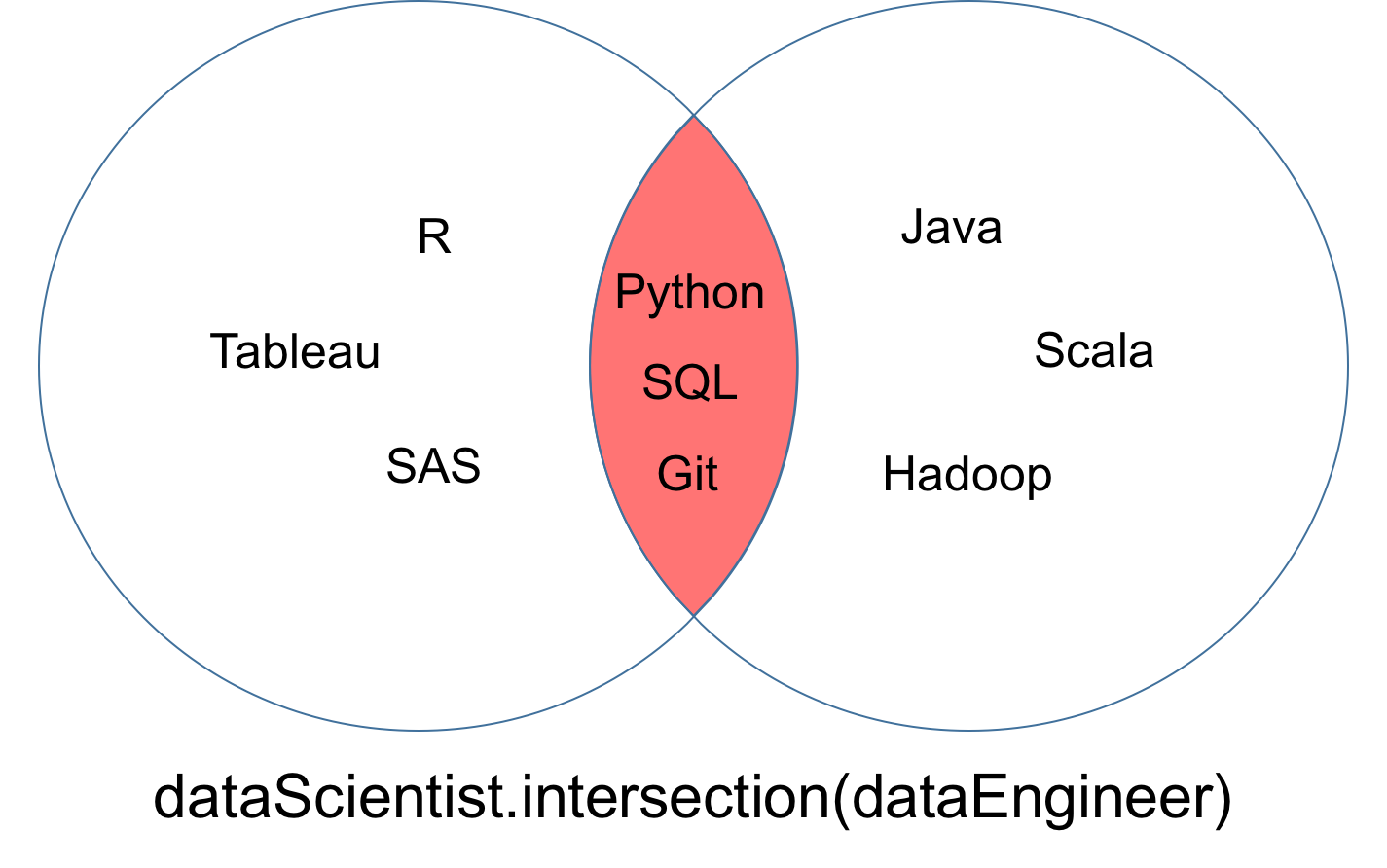
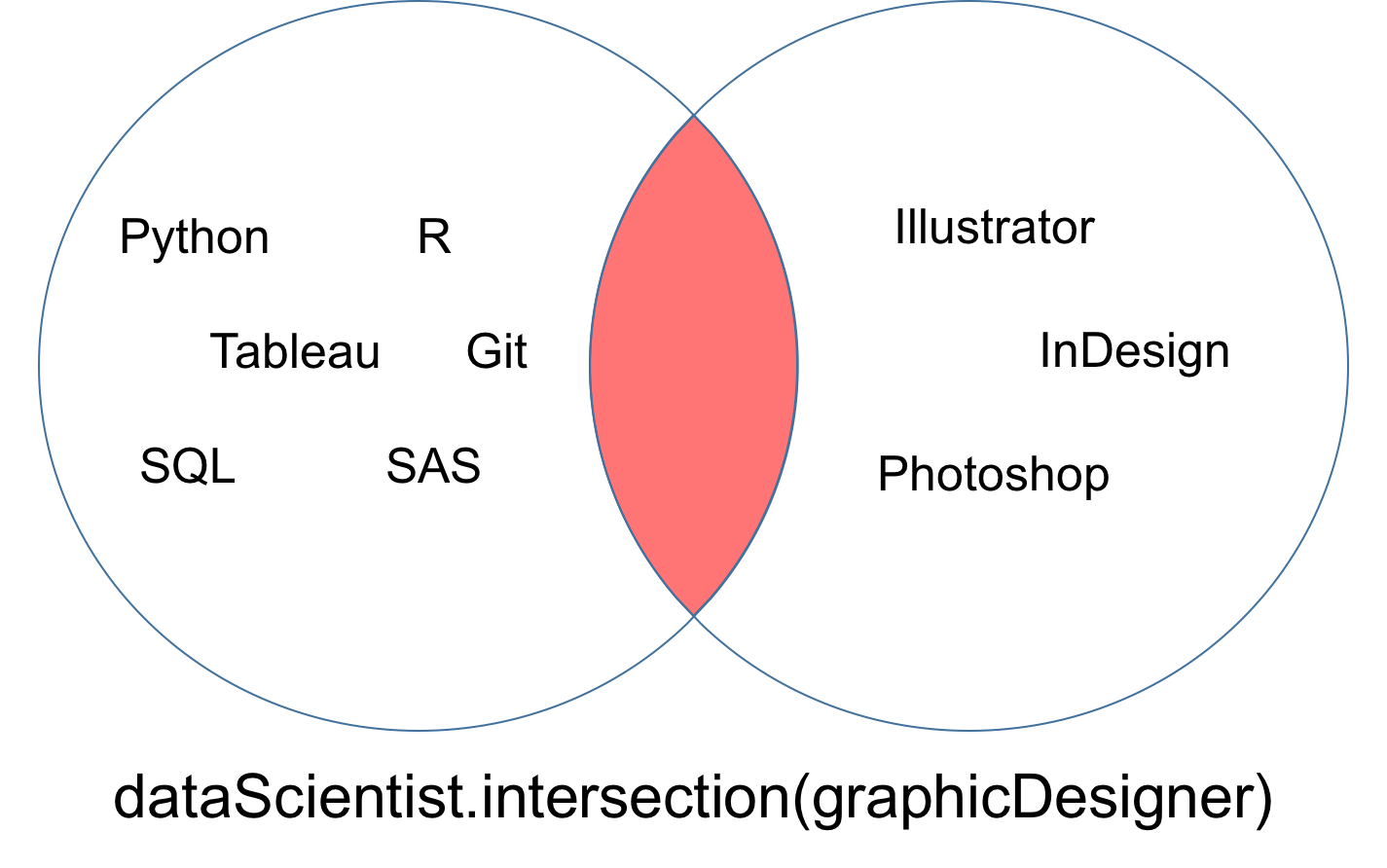
L'intersection de deux ensembles dataScientist et dataEngineer, notée dataScientist ∩ dataEngineer, est l'ensemble de toutes les valeurs qui sont à la fois des valeurs de dataScientist et de dataEngineer.
# Intersection operation
dataScientist.intersection(dataEngineer)
# Equivalent Result
dataScientist & dataEngineer
L'ensemble résultant de l'intersection peut être représenté par la partie rouge du diagramme de Venn ci-dessous.
Il se peut que vous soyez confronté à un cas où vous voulez vous assurer que deux ensembles n'ont aucune valeur en commun. En d'autres termes, vous voulez deux ensembles dont l'intersection est vide. Ces deux ensembles sont appelés ensembles disjoints. Vous pouvez tester l'existence d'ensembles disjoints en utilisant la méthode isdisjoint.
# Initialize a set
graphicDesigner = {'Illustrator', 'InDesign', 'Photoshop'}
# These sets have elements in common so it would return False
dataScientist.isdisjoint(dataEngineer)
# These sets have no elements in common so it would return True
dataScientist.isdisjoint(graphicDesigner)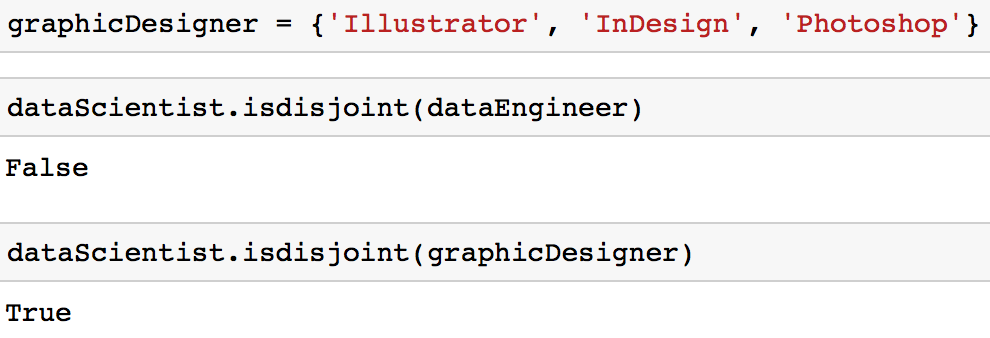
Vous pouvez remarquer dans l'intersection illustrée dans le diagramme de Venn ci-dessous que les ensembles disjoints dataScientist et graphicDesigner n'ont aucune valeur en commun.
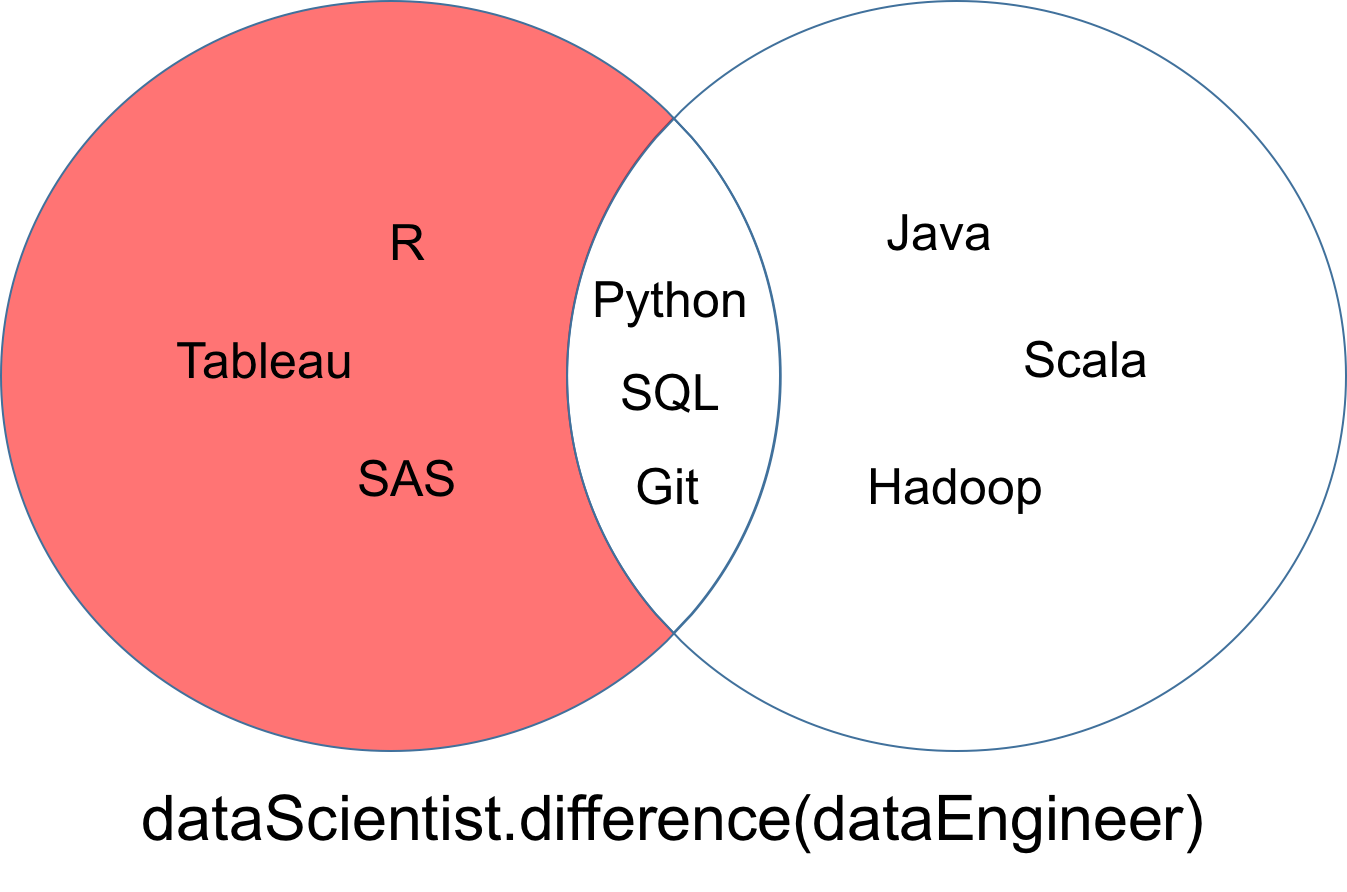
Une différence entre deux ensembles dataScientist et dataEngineer, notée dataScientist \ dataEngineer, est l'ensemble de toutes les valeurs de dataScientist qui ne sont pas des valeurs de dataEngineer.
# Difference Operation
dataScientist.difference(dataEngineer)
# Equivalent Result
dataScientist - dataEngineer
L'ensemble résultant de la différence peut être représenté par la partie rouge du diagramme de Venn ci-dessous.
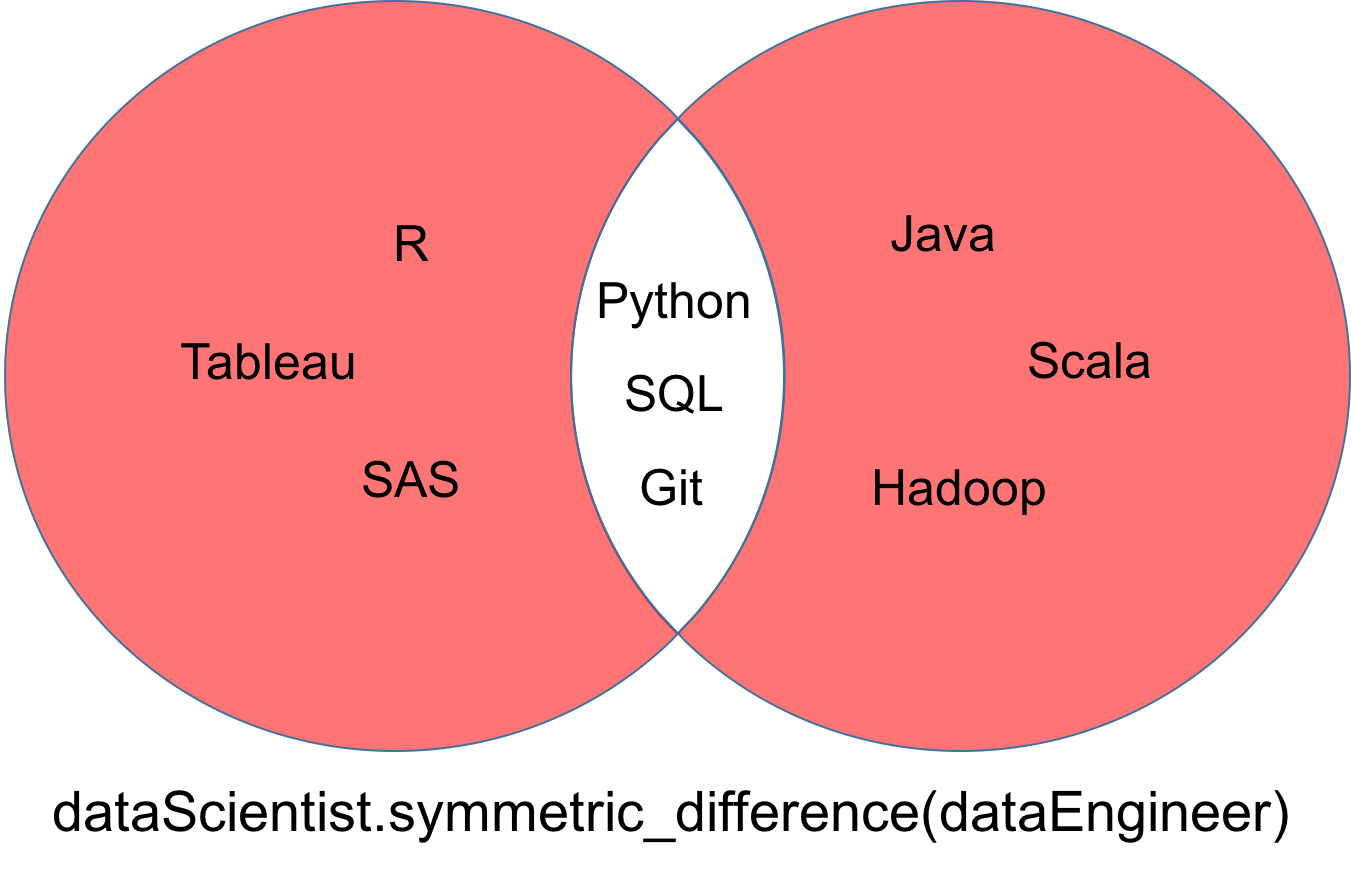
Une différence symétrique de deux ensembles dataScientist et dataEngineer, notée dataScientist △ dataEngineer, est l'ensemble de toutes les valeurs qui sont des valeurs d'exactement l'un des deux ensembles, mais pas des deux.
# Symmetric Difference Operation
dataScientist.symmetric_difference(dataEngineer)
# Equivalent Result
dataScientist ^ dataEngineer
L'ensemble résultant de la différence symétrique peut être représenté par la partie rouge du diagramme de Venn ci-dessous.
Vous avez peut-être déjà appris ce que sont les compréhensions de liste, les compréhensions de dictionnaire et les compréhensions de générateur. Il existe également des compréhensions d'ensembles en Python. Les compréhensions d'ensembles sont très similaires. Les compréhensions d'ensembles en Python peuvent être construites comme suit :
{skill for skill in ['SQL', 'SQL', 'PYTHON', 'PYTHON']}
Le résultat ci-dessus est un ensemble de 2 valeurs car les ensembles ne peuvent pas avoir plusieurs occurrences du même élément.
L'idée derrière l'utilisation des compréhensions d'ensembles est de vous permettre d'écrire et de raisonner en code de la même manière que vous feriez des mathématiques à la main.
{skill for skill in ['GIT', 'PYTHON', 'SQL'] if skill not in {'GIT', 'PYTHON', 'JAVA'}}Le code ci-dessus est similaire à une différence d'ensemble que vous avez apprise plus tôt. Il est juste un peu différent.
Les tests d'appartenance vérifient si un élément spécifique est contenu dans une séquence, telle que des chaînes de caractères, des listes, des tuples ou des ensembles. L'un des principaux avantages de l'utilisation des ensembles en Python est qu'ils sont très optimisés pour les tests d'appartenance. Par exemple, les ensembles permettent d'effectuer des tests d'appartenance de manière beaucoup plus efficace que les listes. Si vous avez des connaissances en informatique, cela s'explique par le fait que la complexité temporelle moyenne des tests d'appartenance aux ensembles est de O(1) contre O(n) pour les listes.
Le code ci-dessous montre un test d'appartenance utilisant une liste.
# Initialize a list
possibleList = ['Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS', 'Java', 'Spark', 'Scala']
# Membership test
'Python' in possibleList
Il est possible de faire quelque chose de similaire pour les ensembles. Les ensembles sont simplement plus efficaces.
# Initialize a set
possibleSet = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS', 'Java', 'Spark', 'Scala'}
# Membership test
'Python' in possibleSet
Puisque possibleSet est un ensemble et que la valeur 'Python' est une valeur de possibleSet, on peut l'appeler 'Python' ∈ possibleSet.
Si vous aviez une valeur qui ne faisait pas partie de l'ensemble, comme 'Fortran', elle serait désignée par 'Fortran' ∉ possibleSet.
Une application pratique de la compréhension de l'appartenance est celle des sous-ensembles.
Initialisons d'abord deux ensembles.
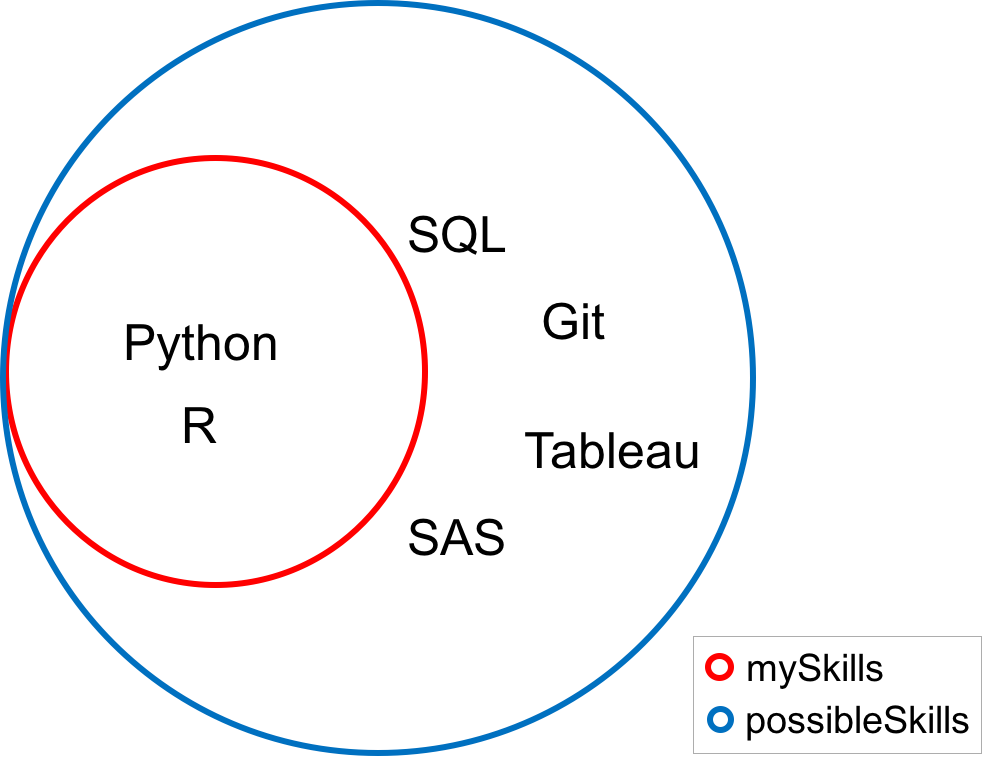
possibleSkills = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
mySkills = {'Python', 'R'}Si chaque valeur de l'ensemble mySkills est également une valeur de l'ensemble possibleSkills, on dit que mySkills est un sous-ensemble de possibleSkills, écrit mathématiquement mySkills ⊆ possibleSkills.
Vous pouvez vérifier si un ensemble est un sous-ensemble d'un autre en utilisant la méthode issubset.
mySkills.issubset(possibleSkills)
Puisque la méthode renvoie True dans ce cas, il s'agit d'un sous-ensemble. Dans le diagramme de Venn ci-dessous, remarquez que chaque valeur de l'ensemble mySkills est également une valeur de l'ensemble possibleSkills.
Vous avez déjà rencontré des listes imbriquées et des tuples.
# Nested Lists and Tuples
nestedLists = [['the', 12], ['to', 11], ['of', 9], ['and', 7], ['that', 6]]
nestedTuples = (('the', 12), ('to', 11), ('of', 9), ('and', 7), ('that', 6))
Le problème avec les ensembles imbriqués est que vous ne pouvez normalement pas avoir d'ensembles Python imbriqués, car les ensembles ne peuvent pas contenir de valeurs mutables, y compris les ensembles.
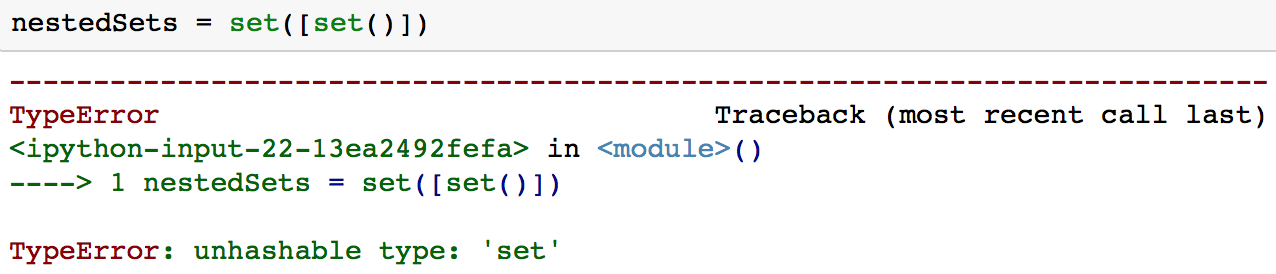
C'est l'une des situations dans lesquelles vous pouvez souhaiter utiliser un gelzenset. Un frozenset est très similaire à un ensemble, sauf qu'il est immuable.
Vous créez un frozenset en utilisant frozenset().
# Initialize a frozenset
immutableSet = frozenset()
Vous pouvez créer un ensemble imbriqué en utilisant un frozenset similaire au code ci-dessous.
nestedSets = set([frozenset()])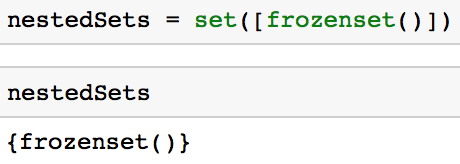
Il est important de garder à l'esprit que l'un des principaux inconvénients d'un frozenset est qu'il est immuable, ce qui signifie que vous ne pouvez pas ajouter ou supprimer des valeurs.
Les ensembles de Python sont très utiles pour supprimer efficacement les valeurs en double d'une collection telle qu'une liste et pour effectuer des opérations mathématiques courantes telles que les unions et les intersections. La question de savoir quand utiliser les différents types de données est souvent un défi pour les utilisateurs. Par exemple, si vous ne savez pas exactement quand il est avantageux d'utiliser un dictionnaire plutôt qu'un ensemble, je vous encourage à consulter le mode pratique quotidien de DataCamp. Si vous avez des questions ou des commentaires sur le tutoriel, n'hésitez pas à les poser dans les commentaires ci-dessous ou sur Twitter.
Cours de Python
Cours
Cours
Cours