Data Types in Python
BeginnerSkill Level
4 Std.
69.5K learners
Code aus diesem Tutorial online ausführen und bearbeiten
Code ausführen
Wenn du dir die Ausgabe der Variablen dataScientist und dataEngineer oben ansiehst, bemerkst du, dass die Werte in der Menge nicht in der Reihenfolge sind, in der sie hinzugefügt wurden. Das liegt daran, dass Mengen nicht geordnet sind.
Sets, die Werte enthalten, können auch durch geschweifte Klammern initialisiert werden.
dataScientist = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
dataEngineer = {'Python', 'Java', 'Scala', 'Git', 'SQL', 'Hadoop'}
Beachte, dass geschweifte Klammern nur verwendet werden können, um eine Menge mit Werten zu initialisieren. Das Bild unten zeigt, dass die Verwendung von geschweiften Klammern ohne Werte eine der Möglichkeiten ist, ein Wörterbuch und nicht ein Set zu initialisieren.

Um Werte zu einem Set hinzuzufügen oder zu entfernen, musst du zunächst ein Set initialisieren.
# Initialize set with values
graphicDesigner = {'InDesign', 'Photoshop', 'Acrobat', 'Premiere', 'Bridge'}Du kannst die Methode add verwenden, um einen Wert zu einer Menge hinzuzufügen.
graphicDesigner.add('Illustrator')
Es ist wichtig zu wissen, dass du nur unveränderliche Werte (wie Strings oder Tupel) zu einer Menge hinzufügen kannst. Du würdest zum Beispiel einen TypeError erhalten, wenn du versuchst, eine Liste zu einem Set hinzuzufügen.
graphicDesigner.add(['Powerpoint', 'Blender'])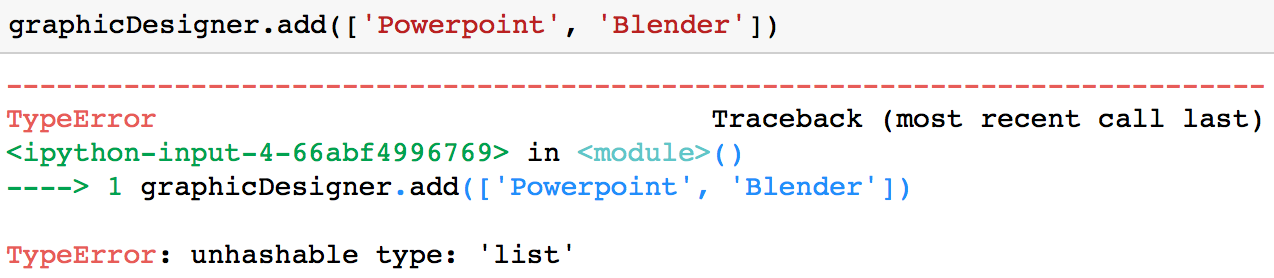
Es gibt mehrere Möglichkeiten, einen Wert aus einem Set zu entfernen.
Option 1: Du kannst die Methode remove verwenden, um einen Wert aus einer Menge zu entfernen.
graphicDesigner.remove('Illustrator')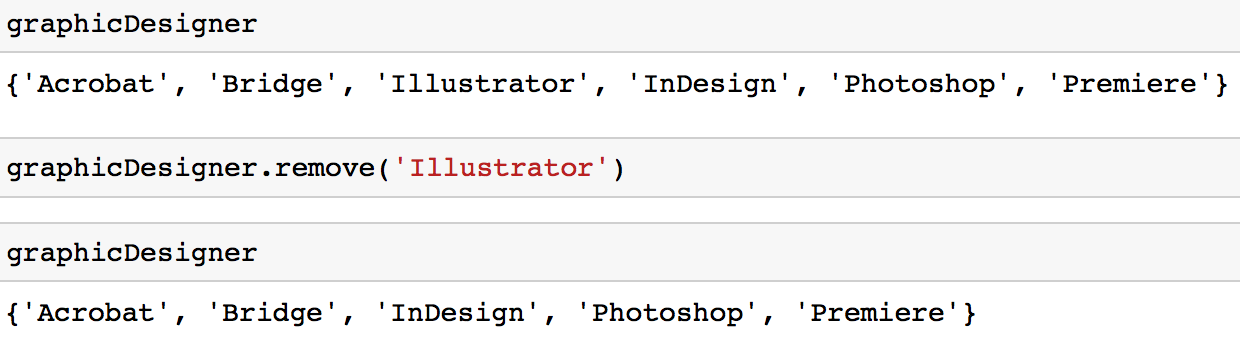
Der Nachteil dieser Methode ist, dass du einen KeyError bekommst, wenn du versuchst, einen Wert zu entfernen, der nicht in deinem Set ist.
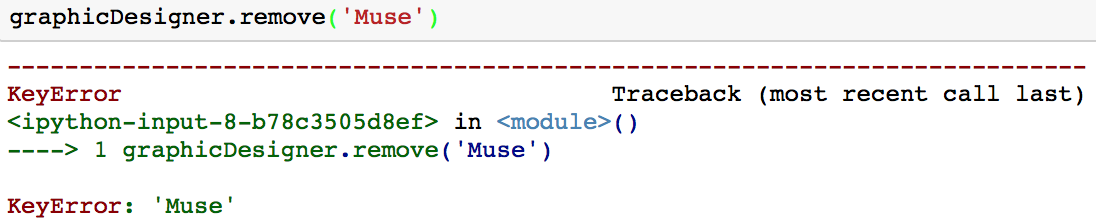
Option 2: Du kannst die Methode discard verwenden, um einen Wert aus einer Menge zu entfernen.
graphicDesigner.discard('Premiere')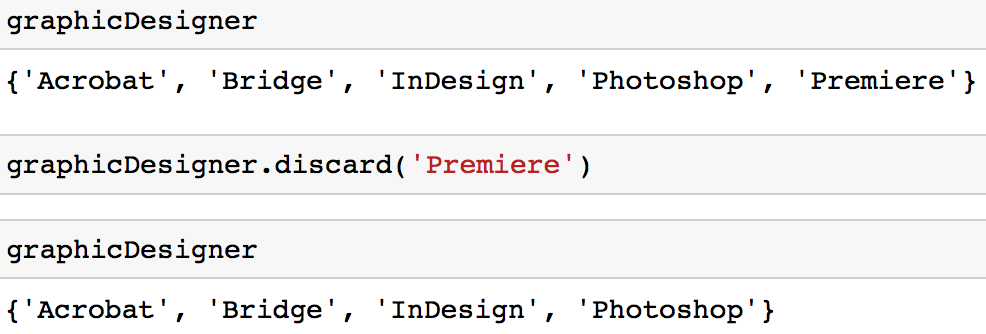
Der Vorteil dieses Ansatzes gegenüber der Methode remove ist, dass du keinen KeyError bekommst, wenn du versuchst, einen Wert zu entfernen, der nicht Teil der Menge ist. Wenn du dich mit Wörterbüchern auskennst, wirst du feststellen, dass dies ähnlich funktioniert wie die Wörterbuchmethode get.
Option 3: Du kannst auch die Methode pop verwenden, um einen beliebigen Wert aus einer Menge zu entfernen und zurückzugeben.
graphicDesigner.pop()
Es ist wichtig zu beachten, dass die Methode einen KeyError auslöst, wenn die Menge leer ist.
Du kannst die Methode clear verwenden, um alle Werte aus einer Menge zu entfernen.
graphicDesigner.clear()
Die Aktualisierungsmethode fügt die Elemente aus einer Menge zu einer Menge hinzu. Sie benötigt ein einzelnes Argument, das eine Menge, eine Liste, ein Tupel oder ein Wörterbuch sein kann. Die Methode .update() wandelt andere Datentypen automatisch in Sets um und fügt sie dem Set hinzu.
Im Beispiel haben wir drei Sets initialisiert und eine Aktualisierungsfunktion verwendet, um Elemente aus Set2 zu Set1 und dann aus Set3 zu Set1 hinzuzufügen.
# Initialize 3 sets
set1 = set([7, 10, 11, 13])
set2 = set([11, 8, 9, 12, 14, 15])
set3 = {'d', 'f', 'h'}
# Update set1 with set2
set1.update(set2)
print(set1)
# Update set1 with set3
set1.update(set3)
print(set1)
Wie viele Standard-Python-Datentypen ist es möglich, durch eine Menge zu iterieren.
# Initialize a set
dataScientist = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
for skill in dataScientist:
print(skill)
Wenn du dir die Ausgabe der einzelnen Werte in dataScientist ansiehst, bemerkst du, dass die Werte in der Menge nicht in der Reihenfolge gedruckt werden, in der sie hinzugefügt wurden. Das liegt daran, dass Mengen nicht geordnet sind.
In diesem Lernprogramm wurde betont, dass Mengen ungeordnet sind. Wenn du die Werte aus deiner Menge in geordneter Form brauchst, kannst du die Funktion sorted verwenden, die eine geordnete Liste ausgibt.
type(sorted(dataScientist))
Der folgende Code gibt die Werte in der Menge dataScientist in absteigender alphabetischer Reihenfolge aus (in diesem Fall Z-A).
sorted(dataScientist, reverse = True)
Ein Teil des Inhalts dieses Abschnitts wurde bereits im Tutorial 18 Most Common Python List Questions behandelt, aber es ist wichtig zu betonen, dass Sets die schnellste Methode sind, um Duplikate aus einer Liste zu entfernen. Um dies zu zeigen, wollen wir den Leistungsunterschied zwischen zwei Ansätzen untersuchen.
Ansatz 1: Verwende ein Set, um Duplikate aus einer Liste zu entfernen.
print(list(set([1, 2, 3, 1, 7])))Ansatz 2: Verwende ein Listenverständnis, um Duplikate aus einer Liste zu entfernen (Wenn du eine Auffrischung über Listenverständnisse brauchst , schau dir dieses Tutorial an).
def remove_duplicates(original):
unique = []
[unique.append(n) for n in original if n not in unique]
return(unique)
print(remove_duplicates([1, 2, 3, 1, 7]))Der Leistungsunterschied kann mit der Bibliothek timeit gemessen werden, mit der du deinen Python-Code zeitlich steuern kannst. Der folgende Code führt den Code für jeden Ansatz 10000 Mal aus und gibt die Gesamtzeit in Sekunden aus.
import timeit
# Approach 1: Execution time
print(timeit.timeit('list(set([1, 2, 3, 1, 7]))', number=10000))
# Approach 2: Execution time
print(timeit.timeit('remove_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=10000))
Der Vergleich dieser beiden Ansätze zeigt, dass die Verwendung von Sets zum Entfernen von Duplikaten effizienter ist. Auch wenn es nach einem kleinen Zeitunterschied aussieht, kannst du damit viel Zeit sparen, wenn du sehr große Listen hast.
Eine häufige Verwendung von Mengen in Python ist die Berechnung von mathematischen Standardoperationen wie Vereinigung, Schnittmenge, Differenz und symmetrische Differenz. Die folgende Abbildung zeigt ein paar mathematische Standardoperationen für zwei Mengen A und B. Der rote Teil jedes Venn-Diagramms ist die Ergebnismenge einer bestimmten Mengenoperation.
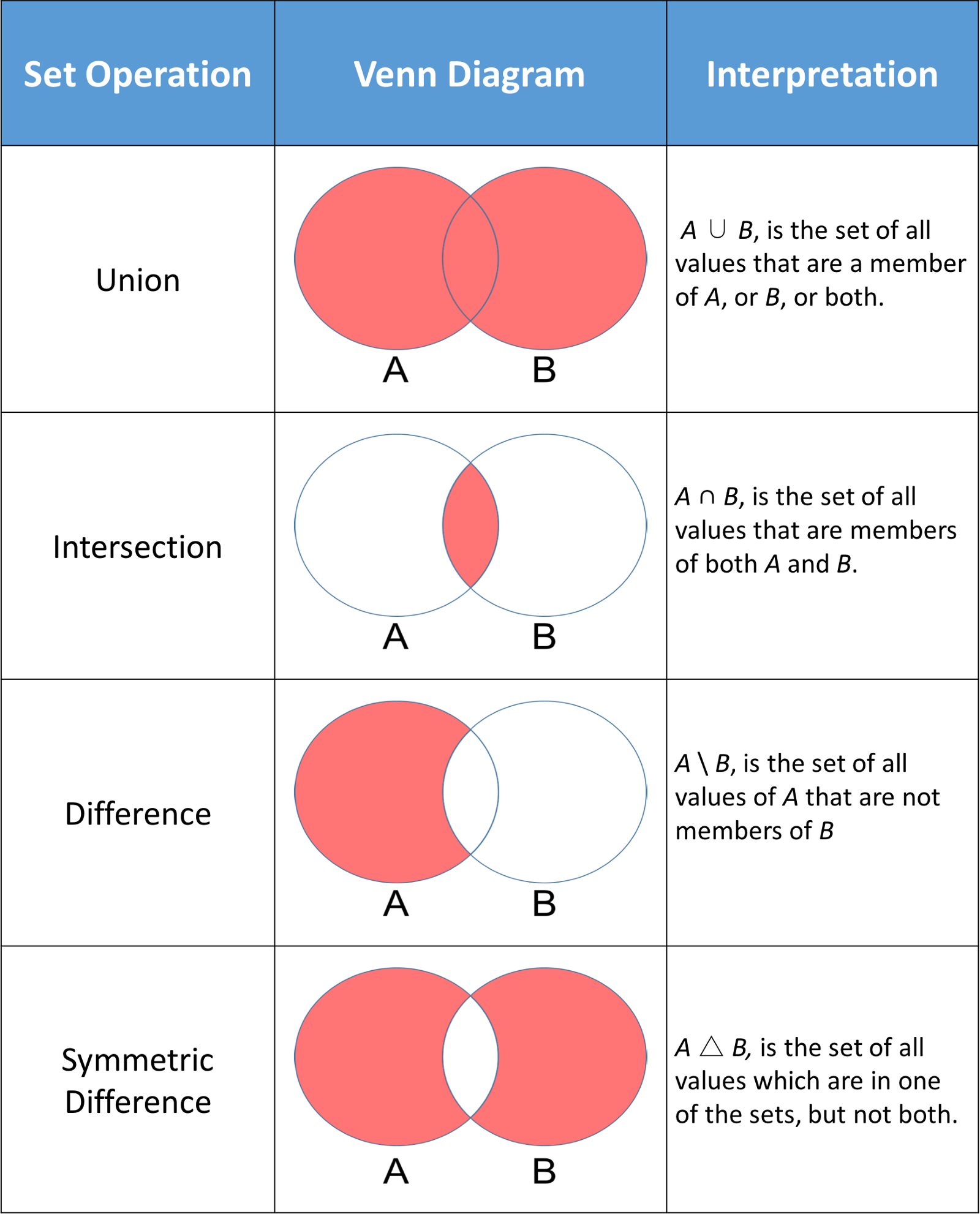
Python-Sets verfügen über Methoden, mit denen du diese mathematischen Operationen durchführen kannst, sowie über Operatoren, die dir gleichwertige Ergebnisse liefern.
Bevor wir diese Methoden erkunden, beginnen wir mit der Initialisierung der beiden Sets dataScientist und dataEngineer.
dataScientist = set(['Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'])
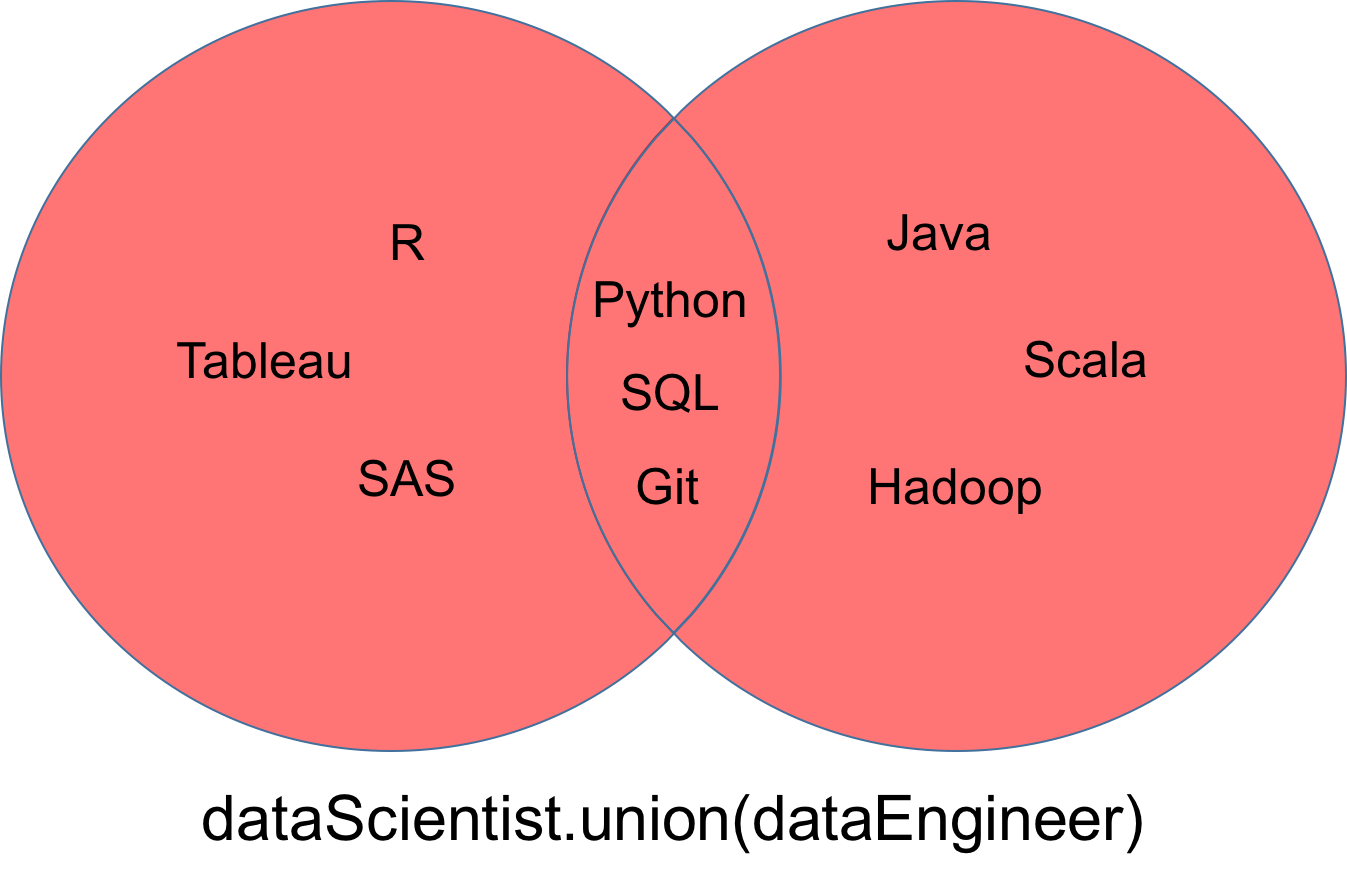
dataEngineer = set(['Python', 'Java', 'Scala', 'Git', 'SQL', 'Hadoop'])Eine Vereinigung, bezeichnet als dataScientist ∪ dataEngineer, ist die Menge aller Werte, die Werte von dataScientist oder dataEngineer oder von beiden sind. Du kannst die Methode union verwenden, um alle eindeutigen Werte in zwei Mengen herauszufinden.
# set built-in function union
dataScientist.union(dataEngineer)
# Equivalent Result
dataScientist | dataEngineer
Die Menge, die sich aus der Vereinigung ergibt, kann als roter Teil des Venn-Diagramms unten visualisiert werden.
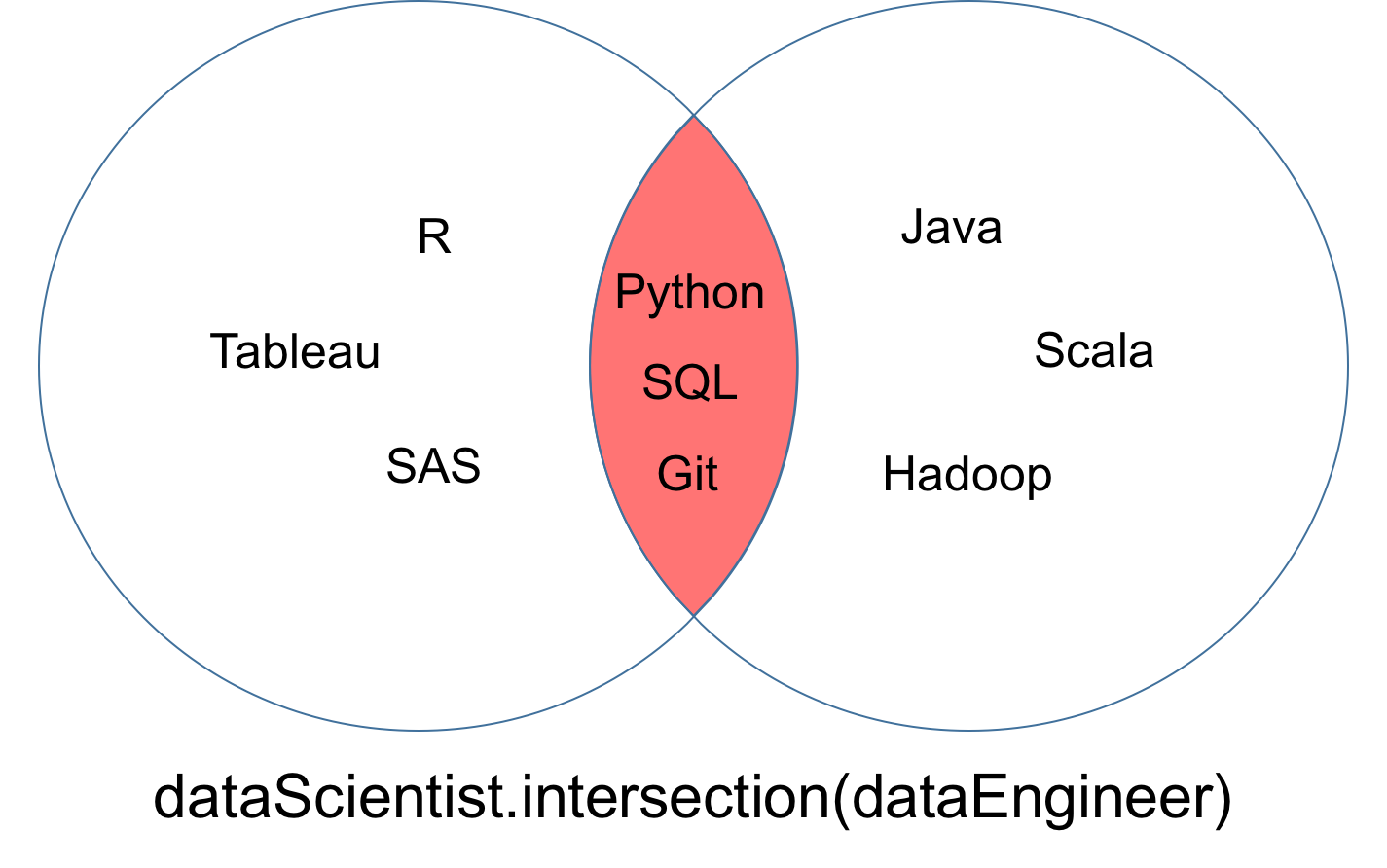
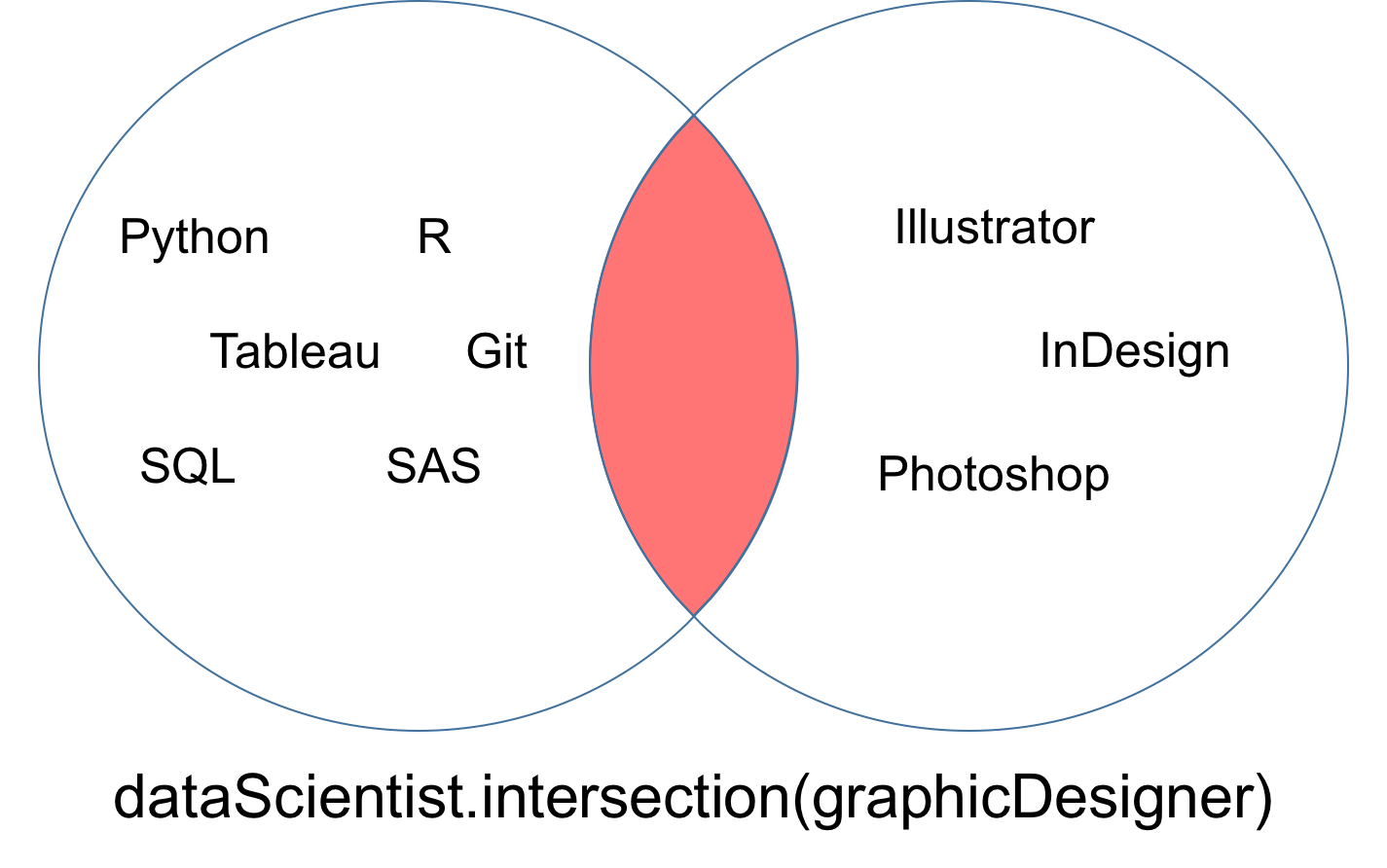
Eine Schnittmenge von zwei Mengen dataScientist und dataEngineer, bezeichnet als dataScientist ∩ dataEngineer, ist die Menge aller Werte, die sowohl Werte von dataScientist als auch von dataEngineer sind.
# Intersection operation
dataScientist.intersection(dataEngineer)
# Equivalent Result
dataScientist & dataEngineer
Die Menge, die sich aus der Kreuzung ergibt, kann als roter Teil des Venn-Diagramms unten dargestellt werden.
Es kann sein, dass du auf einen Fall stößt, in dem du sicherstellen willst, dass zwei Mengen keinen gemeinsamen Wert haben. Mit anderen Worten: Du willst zwei Mengen, deren Schnittpunkt leer ist. Diese beiden Mengen werden als disjunkte Mengen bezeichnet. Du kannst auf disjunkte Mengen testen, indem du die Methode isdisjoint verwendest.
# Initialize a set
graphicDesigner = {'Illustrator', 'InDesign', 'Photoshop'}
# These sets have elements in common so it would return False
dataScientist.isdisjoint(dataEngineer)
# These sets have no elements in common so it would return True
dataScientist.isdisjoint(graphicDesigner)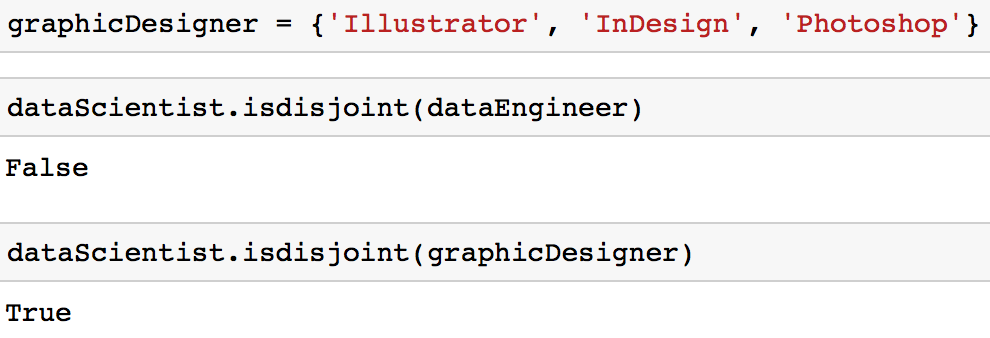
Im Venn-Diagramm unten kannst du sehen, dass die disjunkten Mengen dataScientist und graphicDesigner keine gemeinsamen Werte haben.
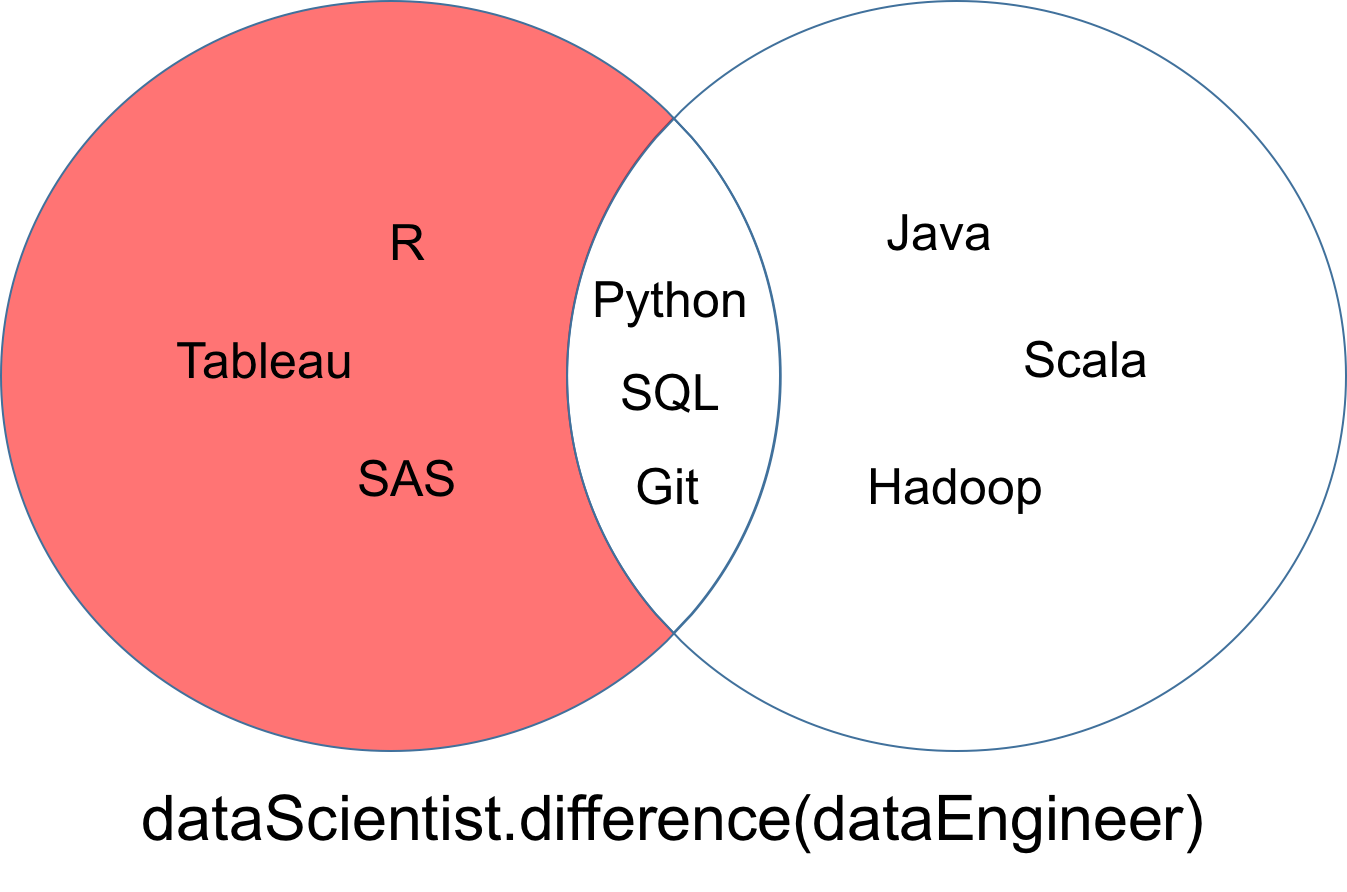
Eine Differenz zwischen zwei Mengen dataScientist und dataEngineer, bezeichnet als dataScientist \ dataEngineer, ist die Menge aller Werte von dataScientist, die nicht Werte von dataEngineer sind.
# Difference Operation
dataScientist.difference(dataEngineer)
# Equivalent Result
dataScientist - dataEngineer
Die Menge, die sich aus der Differenz ergibt, kann als roter Teil des Venn-Diagramms unten visualisiert werden.
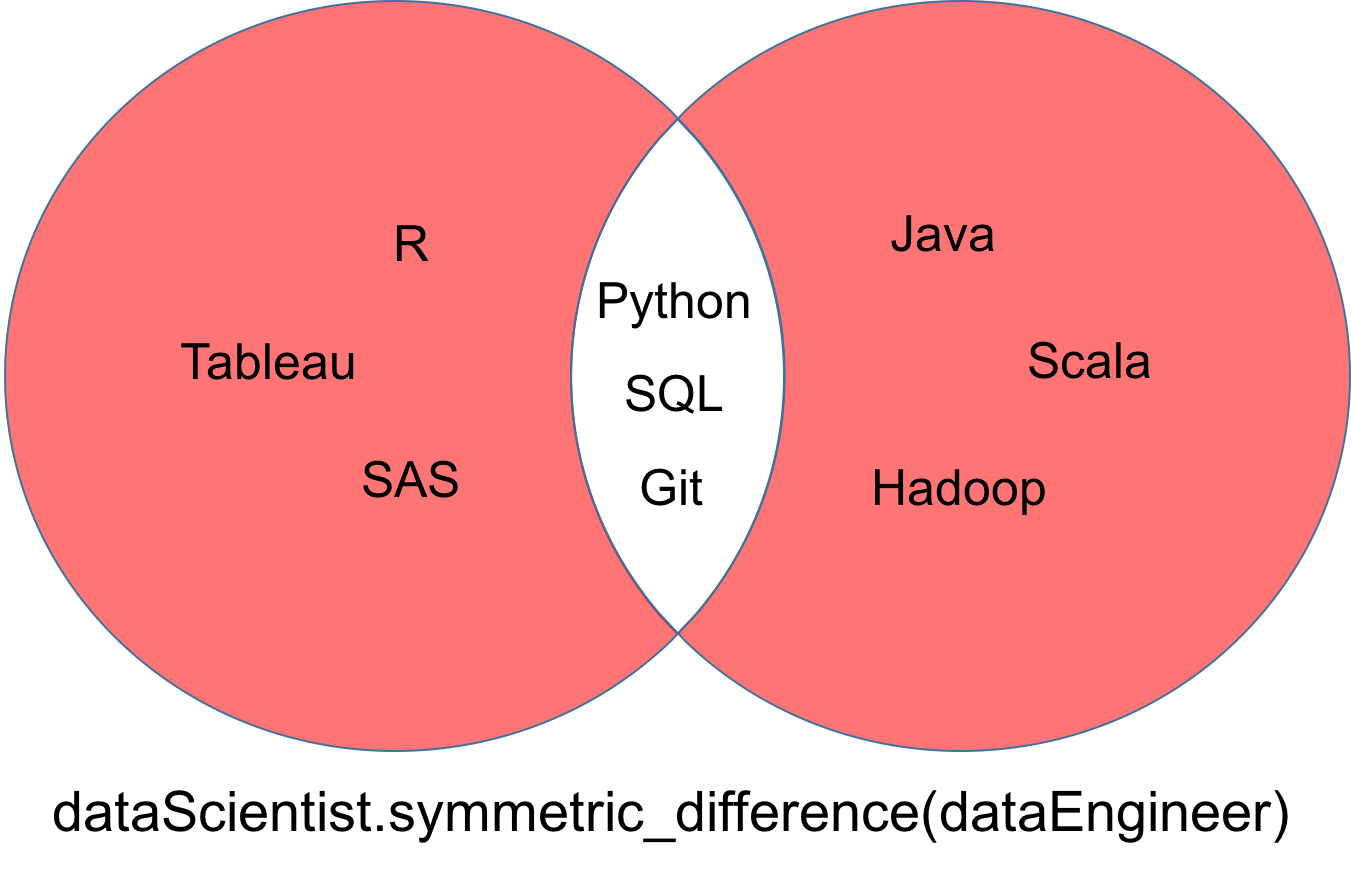
Eine symmetrische Differenz von zwei Mengen dataScientist und dataEngineer, bezeichnet als dataScientist △ dataEngineer, ist die Menge aller Werte, die genau zu einer der beiden Mengen gehören, aber nicht zu beiden.
# Symmetric Difference Operation
dataScientist.symmetric_difference(dataEngineer)
# Equivalent Result
dataScientist ^ dataEngineer
Die Menge, die durch die symmetrische Differenz zurückgegeben wird, kann als roter Teil des Venn-Diagramms unten visualisiert werden.
Du hast vielleicht schon etwas über Listen-, Wörterbuch- und Generatorverstehensaufgaben gelernt. Es gibt auch Python Mengenverständnisse. Mengenverständnisse sind sehr ähnlich. Mengenkomplexe in Python können wie folgt aufgebaut sein:
{skill for skill in ['SQL', 'SQL', 'PYTHON', 'PYTHON']}
Die obige Ausgabe ist eine Menge mit 2 Werten, denn Mengen können nicht mehrere Vorkommen desselben Elements haben.
Die Idee hinter der Verwendung von Set Comprehensions ist, dass du im Code genauso schreiben und argumentieren kannst, wie du Mathematik von Hand machen würdest.
{skill for skill in ['GIT', 'PYTHON', 'SQL'] if skill not in {'GIT', 'PYTHON', 'JAVA'}}Der obige Code ähnelt einem Satzunterschied, den du bereits kennengelernt hast. Es sieht nur ein bisschen anders aus.
Zugehörigkeitstests prüfen, ob ein bestimmtes Element in einer Sequenz enthalten ist, z. B. in Strings, Listen, Tupeln oder Mengen. Einer der Hauptvorteile der Verwendung von Sets in Python ist, dass sie für Mitgliedschaftstests optimiert sind. Mit Sets lassen sich zum Beispiel Zugehörigkeitstests viel effizienter durchführen als mit Listen. Falls du aus der Informatik kommst, liegt das daran, dass die durchschnittliche Zeitkomplexität von Zugehörigkeitstests in Mengen O(1) gegenüber O(n) für Listen ist.
Der folgende Code zeigt einen Mitgliedschaftstest mit einer Liste.
# Initialize a list
possibleList = ['Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS', 'Java', 'Spark', 'Scala']
# Membership test
'Python' in possibleList
Etwas Ähnliches kann für Sets gemacht werden. Sets sind einfach effizienter.
# Initialize a set
possibleSet = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS', 'Java', 'Spark', 'Scala'}
# Membership test
'Python' in possibleSet
Da possibleSet eine Menge ist und der Wert 'Python' ein Wert von possibleSet ist, kann dies als 'Python' ∈ possibleSet bezeichnet werden.
Wenn du einen Wert hättest, der nicht Teil der Menge ist, wie 'Fortran', würde er als 'Fortran' ∉ possibleSet bezeichnet werden.
Eine praktische Anwendung des Verständnisses von Zugehörigkeit sind Teilmengen.
Lass uns zunächst zwei Sets initialisieren.
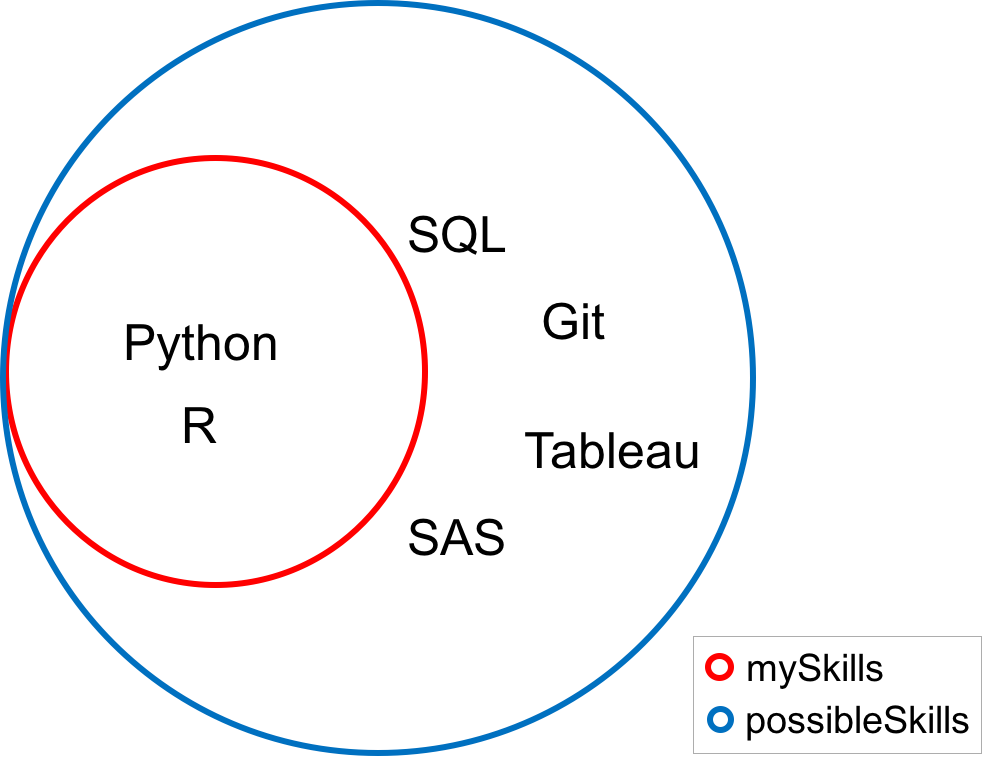
possibleSkills = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
mySkills = {'Python', 'R'}Wenn jeder Wert der Menge mySkills auch ein Wert der Menge possibleSkills ist, dann sagt man, dass mySkills eine Teilmenge von possibleSkills ist, mathematisch geschrieben mySkills ⊆ possibleSkills.
Du kannst mit der Methode issubset prüfen, ob eine Menge eine Teilmenge einer anderen ist.
mySkills.issubset(possibleSkills)
Da die Methode in diesem Fall True zurückgibt, handelt es sich um eine Teilmenge. In dem folgenden Venn-Diagramm siehst du, dass jeder Wert der Menge mySkills auch ein Wert der Menge possibleSkills ist.
Du hast bereits verschachtelte Listen und Tupel kennengelernt.
# Nested Lists and Tuples
nestedLists = [['the', 12], ['to', 11], ['of', 9], ['and', 7], ['that', 6]]
nestedTuples = (('the', 12), ('to', 11), ('of', 9), ('and', 7), ('that', 6))
Das Problem mit verschachtelten Sets ist, dass du normalerweise keine verschachtelten Python-Sets haben kannst, da Sets keine veränderbaren Werte enthalten können, auch keine Sets.
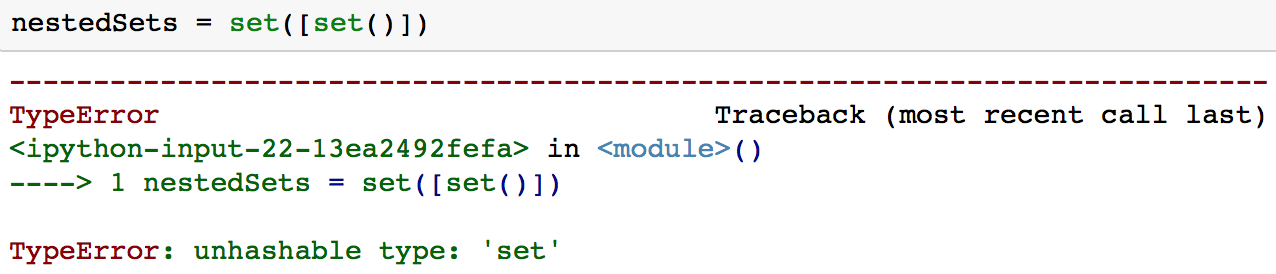
Das ist eine Situation, in der du ein Frozenset verwenden solltest. Ein Frozenset ist einem Set sehr ähnlich, mit dem Unterschied, dass ein Frozenset unveränderlich ist.
Du machst ein Frozenset, indem du frozenset() benutzt.
# Initialize a frozenset
immutableSet = frozenset()
Du kannst ein verschachteltes Set erstellen, wenn du ein Frozenset ähnlich dem unten stehenden Code verwendest.
nestedSets = set([frozenset()])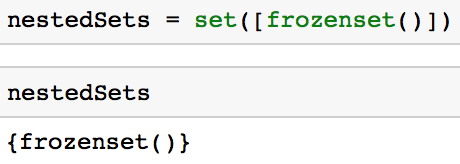
Ein großer Nachteil von Frozensets ist, dass sie unveränderlich sind, das heißt, du kannst keine Werte hinzufügen oder entfernen.
Die Python-Sets sind sehr nützlich, um doppelte Werte effizient aus einer Sammlung wie einer Liste zu entfernen und um gängige mathematische Operationen wie Vereinigungen und Schnittmengen durchzuführen. Eine der Herausforderungen, auf die Menschen oft stoßen, ist die Frage, wann sie die verschiedenen Datentypen verwenden sollen. Wenn du dir zum Beispiel nicht sicher bist, wann es von Vorteil ist, ein Wörterbuch und wann ein Set zu verwenden, empfehle ich dir, den täglichen Übungsmodus von DataCamp auszuprobieren. Wenn du Fragen oder Gedanken zum Tutorial hast, melde dich unten in den Kommentaren oder auf Twitter.
Python-Kurse
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.