Introduction au traitement du langage naturel en Python
121.1K learners
Exécutez et modifiez le code de ce tutoriel en ligne
Exécuter le codeVous avez peut-être déjà vu un nuage rempli de mots de tailles différentes, qui représentent la fréquence ou l'importance de chaque mot. C'est ce qu'on appelle un nuage de tags ou un nuage de mots. Pour ce tutoriel, vous allez apprendre à créer un nuage de mots en Python et à le personnaliser à votre guise. Cet outil vous permettra d'explorer des données textuelles et de rendre votre rapport plus vivant.
Entraînez-vous à générer un nuage de mots en Python grâce à cet exercice pratique.
Dans ce tutoriel, nous utiliserons un ensemble de données de commentaires sur le vin provenant du site Web Wine Enthusiast pour apprendre :
Il est important de se rappeler que si les nuages de mots sont utiles pour visualiser les mots communs dans un texte ou un ensemble de données, ils ne sont généralement utiles que pour obtenir une vue d'ensemble des thèmes. Elles sont similaires aux taches de couleur, mais sont souvent plus attrayantes visuellement (même si elles sont parfois plus difficiles à interpréter). Les nuages de mots peuvent être particulièrement utiles lorsque vous souhaitez :
Cependant, il est important de garder à l'esprit que les nuages de mots ne fournissent pas de contexte ou de compréhension plus approfondie des mots et des phrases utilisés. Elles doivent donc être utilisées conjointement avec d'autres méthodes d'analyse et d'interprétation des données textuelles.
Pour commencer à créer un nuage de mots en Python, vous devrez installer certains paquets ci-dessous :
La bibliothèque numpy est l'une des bibliothèques les plus populaires et les plus utiles pour manipuler des tableaux et des matrices multidimensionnels. Il est également utilisé en combinaison avec la bibliothèque pandas pour effectuer des analyses de données.
Le module Python os est une bibliothèque intégrée, vous n'avez donc pas besoin de l'installer. Pour en savoir plus sur la manipulation des fichiers avec le module os, ce tutoriel de DataCamp sur la lecture et l'écriture de fichiers en Python vous sera utile.
Pour la visualisation, matplotlib est une bibliothèque de base qui permet à de nombreuses autres bibliothèques de fonctionner et d'effectuer des tracés sur sa base, notamment seaborn ou wordcloud que vous utiliserez dans ce tutoriel. La bibliothèque pillow est un paquetage qui permet la lecture d'images. Python est un wrapper pour PIL - Python Imaging Library. Vous aurez besoin de cette bibliothèque pour lire l'image comme masque pour le nuage de mots.
wordcloud peut être un peu difficile à installer. Si vous n'en avez besoin que pour tracer un nuage de mots basique, pip install wordcloud ou conda install -c conda-forge wordcloud suffiront. Cependant, la dernière version, avec la possibilité de masquer le nuage dans la forme de votre choix, nécessite une méthode d'installation différente, comme ci-dessous :
git clone https://github.com/amueller/word_cloud.git
cd word_cloud
pip install .Ce tutoriel utilise l'ensemble de données de Kaggle sur les évaluations de vins. Cette collection est un excellent ensemble de données pour l'apprentissage, sans valeurs manquantes (ce qui prendra du temps à traiter) et avec beaucoup de texte (critiques de vin), de données catégorielles et numériques.
Tout d'abord, vous devez charger toutes les bibliothèques nécessaires :
# Start with loading all necessary libraries
import numpy as np
import pandas as pd
from os import path
from PIL import Image
from wordcloud import WordCloud, STOPWORDS, ImageColorGeneratorimport matplotlib.pyplot as plt
% matplotlib inlinec:\intelpython3\lib\site-packages\matplotlib\__init__.py:
import warnings
warnings.filterwarnings("ignore")
Si vous avez plus de 10 bibliothèques, organisez-les par sections (telles que les bibliothèques de base, la visualisation, les modèles, etc.) L'utilisation de commentaires dans le code rendra votre code propre et facile à suivre.
Maintenant, utilisez pandas read_csv pour charger le DataFrame. Remarquez l'utilisation de index_col=0, ce qui signifie que nous ne lisons pas le nom de la ligne (index) comme une colonne distincte.
# Load in the dataframe
df = pd.read_csv("data/winemag-data-130k-v2.csv", index_col=0)# Looking at first 5 rows of the dataset
df.head()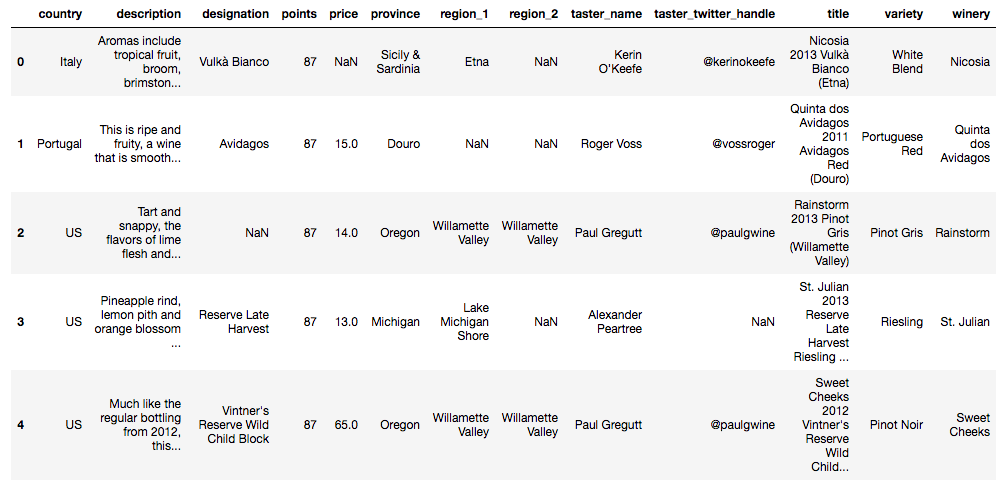
Vous pouvez imprimer quelques informations de base sur l'ensemble de données en utilisant print() combiné avec .format() pour obtenir une impression agréable.
print("There are {} observations and {} features in this dataset. \n".format(df.shape[0],df.shape[1]))
print("There are {} types of wine in this dataset such as {}... \n".format(len(df.variety.unique()),
", ".join(df.variety.unique()[0:5])))
print("There are {} countries producing wine in this dataset such as {}... \n".format(len(df.country.unique()),
", ".join(df.country.unique()[0:5])))There are 129971 observations and 13 features in this dataset.
There are 708 types of wine in this dataset such as White Blend, Portuguese Red, Pinot Gris, Riesling, Pinot Noir...
There are 44 countries producing wine in this dataset such as Italy, Portugal, US, Spain, France...df[["country", "description","points"]].head()| pays | description | points | |
|---|---|---|---|
| 0 | Italie | Arômes de fruits tropicaux, de genêt, de brimston... | 87 |
| 1 | Portugal | C'est un vin mûr et fruité, d'une grande douceur... | 87 |
| 2 | US | Tartare et vif, les saveurs de la chair du citron vert et de la... | 87 |
| 3 | US | Écorce d'ananas, moelle de citron et fleur d'oranger ... | 87 |
| 4 | US | Tout comme l'embouteillage normal de 2012, ce... | 87 |
Pour établir des comparaisons entre les groupes d'une caractéristique, vous pouvez utiliser groupby() et calculer des statistiques sommaires.
Avec l'ensemble de données sur le vin, vous pouvez regrouper par pays et consulter les statistiques récapitulatives pour les points et les prix de tous les pays ou sélectionner les plus populaires et les plus chers.
# Groupby by country
country = df.groupby("country")
# Summary statistic of all countries
country.describe().head()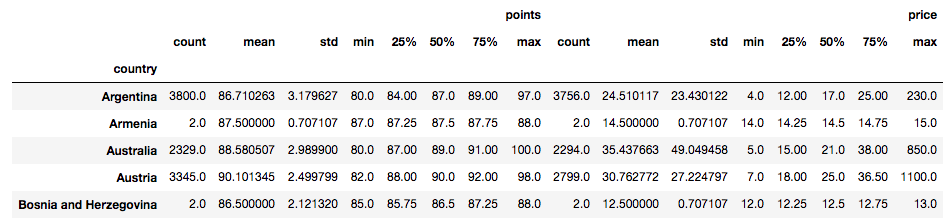
Cette méthode permet de sélectionner les 5 points moyens les plus élevés parmi les 44 pays :
country.mean().sort_values(by="points",ascending=False).head()| pays | points | prix |
|---|---|---|
| Angleterre | 91.581081 | 51.681159 |
| Inde | 90.222222 | 13.333333 |
| Autriche | 90.101345 | 30.762772 |
| Allemagne | 89.851732 | 42.257547 |
| Canada | 89.369650 | 35.712598 |
Vous pouvez représenter graphiquement le nombre de vins par pays en utilisant la méthode plot de Pandas DataFrame et Matplotlib. Si vous n'êtes pas familier avec Matplotlib, jetez un coup d'œil à notre tutoriel Matplotlib.
plt.figure(figsize=(15,10))
country.size().sort_values(ascending=False).plot.bar()
plt.xticks(rotation=50)
plt.xlabel("Country of Origin")
plt.ylabel("Number of Wines")
plt.show()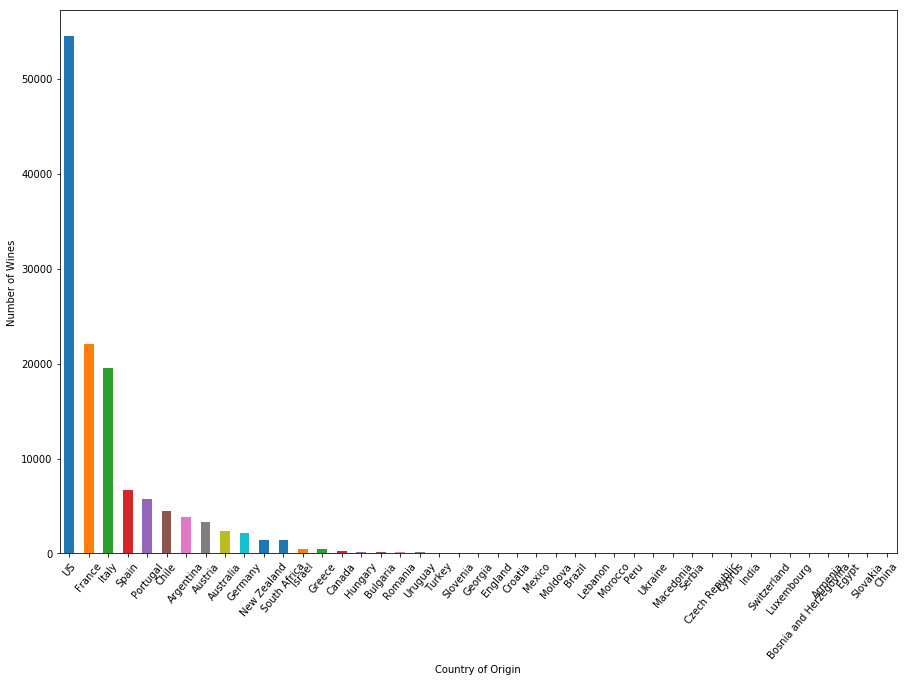
Parmi les 44 pays producteurs de vin, les États-Unis comptent plus de 50 000 types de vins dans l'ensemble de données, soit deux fois plus que le pays suivant dans le classement, la France - le pays célèbre pour son vin. L'Italie produit également beaucoup de vins de qualité, avec près de 20 000 vins ouverts à la dégustation.
Examinons maintenant le graphique des 44 pays en fonction de leur vin le mieux noté, en utilisant la même technique de traçage que ci-dessus :
plt.figure(figsize=(15,10))
country.max().sort_values(by="points",ascending=False)["points"].plot.bar()
plt.xticks(rotation=50)
plt.xlabel("Country of Origin")
plt.ylabel("Highest point of Wines")
plt.show()
L'Australie, les États-Unis, le Portugal, l'Italie et la France ont tous des vins à 100 points. Si vous remarquez, le Portugal se classe au 5e rang et l'Australie au 9e rang pour le nombre de vins produits dans l'ensemble de données, et les deux pays ont moins de 8 000 types de vins.
Voilà un peu d'exploration de données pour apprendre à connaître l'ensemble de données que vous utilisez aujourd'hui. Vous allez maintenant commencer à plonger dans le plat principal du repas : le nuage de mots.
Un nuage de mots est une technique permettant de montrer quels sont les mots les plus fréquents dans un texte donné. Nous pouvons utiliser une bibliothèque Python pour nous aider dans cette tâche. La première chose à faire avant d'utiliser une fonction est de consulter la docstring de la fonction et de voir tous les arguments requis et optionnels. Pour ce faire, tapez ?function et exécutez le programme pour obtenir toutes les informations.
?WordCloud[1;31mInit signature:[0m [0mWordCloud[0m[1;33m([0m[0mfont_path[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mwidth[0m[1;33m=[0m[1;36m400[0m[1;33m,[0m [0mheight[0m[1;33m=[0m[1;36m200[0m[1;33m,[0m [0mmargin[0m[1;33m=[0m[1;36m2[0m[1;33m,[0m [0mranks_only[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mprefer_horizontal[0m[1;33m=[0m[1;36m0.9[0m[1;33m,[0m [0mmask[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mscale[0m[1;33m=[0m[1;36m1[0m[1;33m,[0m [0mcolor_func[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mmax_words[0m[1;33m=[0m[1;36m200[0m[1;33m,[0m [0mmin_font_size[0m[1;33m=[0m[1;36m4[0m[1;33m,[0m [0mstopwords[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mrandom_state[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mbackground_color[0m[1;33m=[0m[1;34m'black'[0m[1;33m,[0m [0mmax_font_size[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mfont_step[0m[1;33m=[0m[1;36m1[0m[1;33m,[0m [0mmode[0m[1;33m=[0m[1;34m'RGB'[0m[1;33m,[0m [0mrelative_scaling[0m[1;33m=[0m[1;36m0.5[0m[1;33m,[0m [0mregexp[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mcollocations[0m[1;33m=[0m[1;32mTrue[0m[1;33m,[0m [0mcolormap[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mnormalize_plurals[0m[1;33m=[0m[1;32mTrue[0m[1;33m,[0m [0mcontour_width[0m[1;33m=[0m[1;36m0[0m[1;33m,[0m [0mcontour_color[0m[1;33m=[0m[1;34m'black'[0m[1;33m)[0m[1;33m[0m[0m
[1;31mDocstring:[0m
Word cloud object for generating and drawing.
Parameters
----------
font_path : string
Font path to the font that will be used (OTF or TTF).
Defaults to DroidSansMono path on a Linux machine. If you are on
another OS or don't have this font; you need to adjust this path.
width : int (default=400)
Width of the canvas.
height : int (default=200)
Height of the canvas.
prefer_horizontal : float (default=0.90)
The ratio of times to try horizontal fitting as opposed to vertical.
If prefer_horizontal < 1, the algorithm will try rotating the word
if it doesn't fit. (There is currently no built-in way to get only
vertical words.)
mask : nd-array or None (default=None)
If not None, gives a binary mask on where to draw words. If mask is not
None, width and height will be ignored, and the shape of mask will be
used instead. All white (#FF or #FFFFFF) entries will be considered
"masked out" while other entries will be free to draw on. [This
changed in the most recent version!]
contour_width: float (default=0)
If mask is not None and contour_width > 0, draw the mask contour.
contour_color: color value (default="black")
Mask contour color.
scale : float (default=1)
Scaling between computation and drawing. For large word-cloud images,
using scale instead of larger canvas size is significantly faster, but
might lead to a coarser fit for the words.
min_font_size : int (default=4)
Smallest font size to use. Will stop when there is no more room in this
size.
font_step : int (default=1)
Step size for the font. font_step > 1 might speed up computation but
give a worse fit.
max_words : number (default=200)
The maximum number of words.
stopwords : set of strings or None
The words that will be eliminated. If None, the build-in STOPWORDS
list will be used.
background_color : color value (default="black")
Background color for the word cloud image.
max_font_size : int or None (default=None)
Maximum font size for the largest word. If None, the height of the image is
used.
mode : string (default="RGB")
Transparent background will be generated when mode is "RGBA" and
background_color is None.
relative_scaling : float (default=.5)
Importance of relative word frequencies for font-size. With
relative_scaling=0, only word-ranks are considered. With
relative_scaling=1, a word that is twice as frequent will have twice
the size. If you want to consider the word frequencies and not only
their rank, relative_scaling around .5 often looks good.
.. versionchanged: 2.0
Default is now 0.5.
color_func : callable, default=None
Callable with parameters word, font_size, position, orientation,
font_path, random_state that returns a PIL color for each word.
Overwrites "colormap".
See colormap for specifying a matplotlib colormap instead.
regexp : string or None (optional)
Regular expression to split the input text into tokens in process_text.
If None is specified, ``r"\w[\w']+"`` is used.
collocations : bool, default=True
Whether to include collocations (bigrams) of two words.
.. versionadded: 2.0
colormap : string or matplotlib colormap, default="viridis"
Matplotlib colormap to randomly draw colors from for each word.
Ignored if "color_func" is specified.
.. versionadded: 2.0
normalize_plurals : bool, default=True
Whether to remove trailing 's' from words. If True and a word
appears with and without a trailing 's', the one with trailing 's'
is removed and its counts are added to the version without
trailing 's' -- unless the word ends with 'ss'.
Attributes
----------
``words_`` : dict of string to float
Word tokens with associated frequency.
.. versionchanged: 2.0
``words_`` is now a dictionary
``layout_`` : list of tuples (string, int, (int, int), int, color))
Encodes the fitted word cloud. Encodes for each word the string, font
size, position, orientation, and color.
Notes
-----
Larger canvases will make the code significantly slower. If you need a
large word cloud, try a lower canvas size, and set the scale parameter.
The algorithm might give more weight to the ranking of the words
then their actual frequencies, depending on the ``max_font_size`` and the
scaling heuristic.
[1;31mFile:[0m c:\intelpython3\lib\site-packages\wordcloud\wordcloud.py
[1;31mType:[0m typeVous pouvez constater que le seul argument requis pour un objet WordCloud est l'élément textealors que tous les autres sont facultatifs.
Commençons donc par un exemple simple : utiliser la description de la première observation comme entrée du nuage de mots. Les trois étapes sont les suivantes :
# Start with one review:
text = df.description[0]
# Create and generate a word cloud image:
wordcloud = WordCloud().generate(text)
# Display the generated image:
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
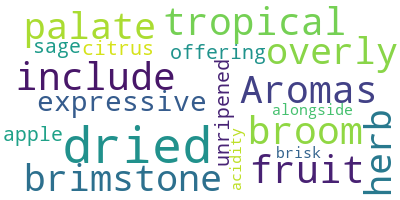
Excellent ! Vous pouvez constater que le premier commentaire mentionnait beaucoup de saveurs séchées et d'arômes du vin.
Modifiez maintenant certains arguments facultatifs du nuage de mots comme max_font_size, max_word, et background_color.
# lower max_font_size, change the maximum number of word and lighten the background:
wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white").generate(text)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
Il semble que l'utilisation de max_font_size ne soit pas une bonne idée. Il est plus difficile de voir les différences entre les fréquences des mots. Cependant, l'éclaircissement de l'arrière-plan rend le nuage plus lisible.
Si vous souhaitez enregistrer l'image, WordCloud propose la fonction suivante to_file
# Save the image in the img folder:
wordcloud.to_file("img/first_review.png")<wordcloud.wordcloud.WordCloud at 0x16f1d704978>Le résultat ressemblera à ceci lorsque vous les chargerez :
Vous avez probablement remarqué l'argument interpolation="bilinear" dans le site plt.imshow(). Cela permet de rendre l'image affichée plus fluide. Pour plus d'informations sur ce choix, ce tutoriel sur les méthodes d'interpolation pour imshow est une ressource utile.
Vous allez donc maintenant combiner toutes les critiques de vin en un seul texte et créer un gros nuage pour voir quelles sont les caractéristiques les plus courantes dans ces vins.
text = " ".join(review for review in df.description)
print ("There are {} words in the combination of all review.".format(len(text)))
There are 31661073 words in the combination of all review.
# Create stopword list:
stopwords = set(STOPWORDS)
stopwords.update(["drink", "now", "wine", "flavor", "flavors"])
# Generate a word cloud image
wordcloud = WordCloud(stopwords=stopwords, background_color="white").generate(text)
# Display the generated image:
# the matplotlib way:
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()

Il semble que la cerise noire et le caractère corsé soient les caractéristiques les plus mentionnées, et le cabernet sauvignon est le plus populaire d'entre eux. Cela correspond au fait que le cabernet sauvignon "est l'un des cépages de vin rouge les plus connus au monde". Il est cultivé dans presque tous les grands pays producteurs de vin, dans une gamme variée de climats, de la vallée de l'Okanagan au Canada à la vallée de la Beqaa au Liban".[1]
Maintenant, versons ces mots dans une tasse (ou même une bouteille) de vin !
Afin de créer une forme pour votre nuage de mots, vous devez tout d'abord trouver un fichier PNG qui deviendra le masque. Vous trouverez ci-dessous un exemple intéressant disponible sur l'internet :

Toutes les images de masque n'ont pas le même format, ce qui donne des résultats différents, et la fonction WordCloud ne fonctionne donc pas correctement. Pour vous assurer que votre masque fonctionne, examinons-le sous la forme d'un tableau numpy :
wine_mask = np.array(Image.open("img/wine_mask.png"))
wine_mask
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=uint8)
La fonction de masquage fonctionne de la manière suivante : toute la partie blanche du masque doit être égale à 255 et non à 0 (type entier). Cette valeur représente l'"intensité" du pixel. Les valeurs de 255 correspondent à du blanc pur, tandis que les valeurs de 1 correspondent à du noir. Ici, vous pouvez utiliser la fonction fournie ci-dessous pour transformer votre masque si celui-ci a le même format que ci-dessus. Notez que si vous avez un masque dont l'arrière-plan n'est pas 0, mais 1 ou 2, ajustez la fonction pour qu'elle corresponde à votre masque.
Tout d'abord, vous utilisez la fonction transform_format() pour permuter les nombres 0 à 255.
def transform_format(val):
if val == 0:
return 255
else:
return val
Ensuite, créez un nouveau masque ayant la même forme que le masque que vous avez en main et appliquez la fonction transform_format() à chaque valeur de chaque ligne du masque précédent.
# Transform your mask into a new one that will work with the function:
transformed_wine_mask = np.ndarray((wine_mask.shape[0],wine_mask.shape[1]), np.int32)
for i in range(len(wine_mask)):
transformed_wine_mask[i] = list(map(transform_format, wine_mask[i]))
Vous disposez maintenant d'un nouveau masque de forme correcte. L'impression du masque transformé est le meilleur moyen de vérifier si la fonction fonctionne correctement.
# Check the expected result of your mask
transformed_wine_mask
array([[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
...,
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255]])
Avec le bon masque, vous pouvez commencer à réaliser le nuage de mots avec la forme que vous avez sélectionnée. Remarquez que la fonction WordCloud comporte un argument mask qui reprend le masque transformé que vous avez créé ci-dessus. Les sites contour_width et contour_color sont, comme leur nom l'indique, des arguments permettant d'ajuster les caractéristiques de contour du nuage. La bouteille de vin que vous voyez ici est une bouteille de vin rouge, la brique réfractaire semble donc être un bon choix pour la couleur du contour. Pour plus de choix de couleurs, vous pouvez consulter ce tableau de codes de couleurs.
# Create a word cloud image
wc = WordCloud(background_color="white", max_words=1000, mask=transformed_wine_mask,
stopwords=stopwords, contour_width=3, contour_color='firebrick')
# Generate a wordcloud
wc.generate(text)
# store to file
wc.to_file("img/wine.png")
# show
plt.figure(figsize=[20,10])
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()

Voilà ! Vous avez créé un nuage de mots en forme de bouteille de vin ! Il semble que les descriptions de vin mentionnent le plus souvent la cerise noire, les arômes de fruits et les caractéristiques corsées du vin. Examinons maintenant de plus près les critiques de chaque pays et traçons le nuage de mots à l'aide du drapeau de chaque pays. Vous trouverez ci-dessous un exemple que vous créerez bientôt :

Vous pouvez combiner tous les commentaires des cinq pays qui ont le plus de vins. Pour trouver ces pays, vous pouvez soit regarder le graphique pays vs nombre de vins ci-dessus, soit utiliser le groupe que vous avez obtenu ci-dessus pour trouver le nombre d'observations pour chaque pays (chaque groupe) et sort_values() avec l'argument ascending=False pour trier en ordre décroissant.
country.size().sort_values(ascending=False).head()
country
US 54504
France 22093
Italy 19540
Spain 6645
Portugal 5691
dtype: int64
Vous avez donc maintenant cinq pays en tête : les États-Unis, la France, l'Italie, l'Espagne et le Portugal. Vous pouvez changer le nombre de pays en insérant le nombre de votre choix à l'intérieur de head() comme ci-dessous
country.size().sort_values(ascending=False).head(10)
country
US 54504
France 22093
Italy 19540
Spain 6645
Portugal 5691
Chile 4472
Argentina 3800
Austria 3345
Australia 2329
Germany 2165
dtype: int64
Pour l'instant, cinq pays devraient suffire.
Pour obtenir tous les avis pour chaque pays, vous pouvez concaténer tous les avis à l'aide de la syntaxe " ".join(list), qui réunit tous les éléments d'une liste en les séparant par des espaces.
# Join all reviews of each country:
usa = " ".join(review for review in df[df["country"]=="US"].description)
fra = " ".join(review for review in df[df["country"]=="France"].description)
ita = " ".join(review for review in df[df["country"]=="Italy"].description)
spa = " ".join(review for review in df[df["country"]=="Spain"].description)
por = " ".join(review for review in df[df["country"]=="Portugal"].description)
Ensuite, vous pouvez créer le nuage de mots comme indiqué ci-dessus. Vous pouvez combiner les deux étapes de création et de génération en une seule, comme indiqué ci-dessous. Le mappage des couleurs est effectué juste avant de tracer le nuage à l'aide de la fonction ImageColorGenerator de la bibliothèque WordCloud.
# Generate a word cloud image
mask = np.array(Image.open("img/us.png"))
wordcloud_usa = WordCloud(stopwords=stopwords, background_color="white", mode="RGBA", max_words=1000, mask=mask).generate(usa)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_usa.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/us_wine.png", format="png")
plt.show()

Il a l'air bien ! Reprenons maintenant avec une critique de la France.
# Generate a word cloud image
mask = np.array(Image.open("img/france.png"))
wordcloud_fra = WordCloud(stopwords=stopwords, background_color="white", mode="RGBA", max_words=1000, mask=mask).generate(fra)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_fra.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/fra_wine.png", format="png")
#plt.show()
Veuillez noter que vous devez enregistrer l'image après l'avoir tracée pour que le nuage de mots ait la couleur souhaitée.

# Generate a word cloud image
mask = np.array(Image.open("img/italy.png"))
wordcloud_ita = WordCloud(stopwords=stopwords, background_color="white", max_words=1000, mask=mask).generate(ita)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_ita.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/ita_wine.png", format="png")
#plt.show()

L'Espagne suit l'Italie :
# Generate a word cloud image
mask = np.array(Image.open("img/spain.png"))
wordcloud_spa = WordCloud(stopwords=stopwords, background_color="white", max_words=1000, mask=mask).generate(spa)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_spa.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/spa_wine.png", format="png")
#plt.show()

Enfin, le Portugal :
# Generate a word cloud image
mask = np.array(Image.open("img/portugal.png"))
wordcloud_por = WordCloud(stopwords=stopwords, background_color="white", max_words=1000, mask=mask).generate(por)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_por.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/por_wine.png", format="png")
#plt.show()

Le résultat final se trouve dans le tableau ci-dessous pour comparer les masques et les nuages de mots. Laquelle est votre préférée ?
Nous avons donc vu plusieurs exemples de nuages de mots et comment les créer en Python. Cependant, il est intéressant d'étudier comment interpréter ces visualisations de données. En général, la taille de chaque mot dans le nuage représente sa fréquence ou son importance dans le texte. En règle générale, plus un mot apparaît fréquemment dans le texte, plus il apparaîtra en grand dans le nuage de mots.
Plusieurs éléments doivent être pris en compte lors de l'interprétation des nuages de mots :
Dans l'ensemble, un nuage de mots peut être un outil utile pour visualiser rapidement les thèmes et idées clés d'un texte. Cependant, il est important de garder à l'esprit qu'il ne s'agit que d'un outil parmi d'autres pour analyser des données textuelles, et qu'il doit être utilisé en conjonction avec d'autres méthodes pour une analyse et une compréhension plus approfondies.
Vous avez réussi ! Vous avez appris plusieurs façons de dessiner un nuage de mots en Python à l'aide de la bibliothèque WordCloud, ce qui serait utile pour la visualisation de toute analyse de texte. Vous apprenez également à masquer le nuage pour lui donner n'importe quelle forme, en utilisant la couleur de votre choix. Si vous souhaitez mettre vos compétences en pratique, pensez au projet du DataCamp : Les sujets les plus brûlants de l'apprentissage automatique
Si vous souhaitez en savoir plus sur le traitement du langage naturel, suivez notre cours Natural Language Processing Fundamentals in Python.
Cours de Python
Cours
Cours
Cours