Curso
Introdução ao Python
4 h
6.9M
Execute e edite o código deste tutorial online
Executar códigoMuitas vezes você já deve ter visto uma nuvem com muitas palavras em tamanhos diferentes, que representam a frequência ou a importância de cada palavra. Isso é chamado de nuvem de tags ou nuvem de palavras. Neste tutorial, você aprenderá a criar uma nuvem de palavras em Python e a personalizá-la como achar melhor. Essa ferramenta será útil para você explorar dados de texto e tornar seu relatório mais dinâmico.
Pratique a geração de um WordCloud em Python com este exercício prático.
Neste tutorial, usaremos um conjunto de dados de avaliação de vinhos do site Wine Enthusiast para aprender:
É importante lembrar que, embora as nuvens de palavras sejam úteis para visualizar palavras comuns em um texto ou conjunto de dados, elas geralmente são úteis apenas como uma visão geral de alto nível dos temas. Eles são semelhantes aos blots de barras, mas geralmente são mais atraentes visualmente (embora, às vezes, mais difíceis de interpretar). As nuvens de palavras podem ser particularmente úteis quando você quiser:
No entanto, é importante ter em mente que as nuvens de palavras não fornecem nenhum contexto ou entendimento mais profundo das palavras e frases que estão sendo usadas. Portanto, eles devem ser usados em conjunto com outros métodos para analisar e interpretar dados de texto.
Para começar a criar uma nuvem de palavras em Python, você precisará instalar alguns pacotes abaixo:
A biblioteca numpy é uma das bibliotecas mais populares e úteis usadas para manipular matrizes e arrays multidimensionais. Ele também é usado em conjunto com a biblioteca pandas para realizar a análise de dados.
O módulo Python os é uma biblioteca integrada, portanto, você não precisa instalá-lo. Para saber mais sobre como lidar com arquivos com o módulo os, este tutorial do DataCamp sobre leitura e gravação de arquivos em Python será útil.
Para visualização, matplotlib é uma biblioteca básica que permite que muitas outras bibliotecas sejam executadas e plotadas em sua base, incluindo seaborn ou wordcloud, que você usará neste tutorial. A biblioteca pillow é um pacote que permite a leitura de imagens. O Pillow é um wrapper para a PIL (Python Imaging Library). Você precisará dessa biblioteca para ler a imagem como a máscara para a nuvem de palavras.
wordcloud pode ser um pouco complicado de instalar. Se você precisar dele apenas para plotar uma nuvem de palavras básica, pip install wordcloud ou conda install -c conda-forge wordcloud serão suficientes. No entanto, a versão mais recente, com a capacidade de mascarar a nuvem em qualquer formato de sua escolha, requer um método diferente de instalação, conforme abaixo:
git clone https://github.com/amueller/word_cloud.git
cd word_cloud
pip install .Este tutorial usa o conjunto de dados de avaliação de vinhos do Kaggle. Essa coleção é um ótimo conjunto de dados para aprendizado, sem valores ausentes (que levarão tempo para serem tratados) e com muitos dados de texto (avaliações de vinhos), categóricos e numéricos.
Em primeiro lugar, você deve carregar todas as bibliotecas necessárias:
# Start with loading all necessary libraries
import numpy as np
import pandas as pd
from os import path
from PIL import Image
from wordcloud import WordCloud, STOPWORDS, ImageColorGeneratorimport matplotlib.pyplot as plt
% matplotlib inlinec:\intelpython3\lib\site-packages\matplotlib\__init__.py:
import warnings
warnings.filterwarnings("ignore")
Se você tiver mais de 10 bibliotecas, organize-as por seções (como bibliotecas básicas, visualização, modelos etc.). O uso de comentários no código tornará seu código limpo e fácil de seguir.
Agora, você está usando o pandas read_csv para carregar o dataframe. Observe o uso de index_col=0, o que significa que não lemos o nome da linha (índice) como uma coluna separada.
# Load in the dataframe
df = pd.read_csv("data/winemag-data-130k-v2.csv", index_col=0)# Looking at first 5 rows of the dataset
df.head()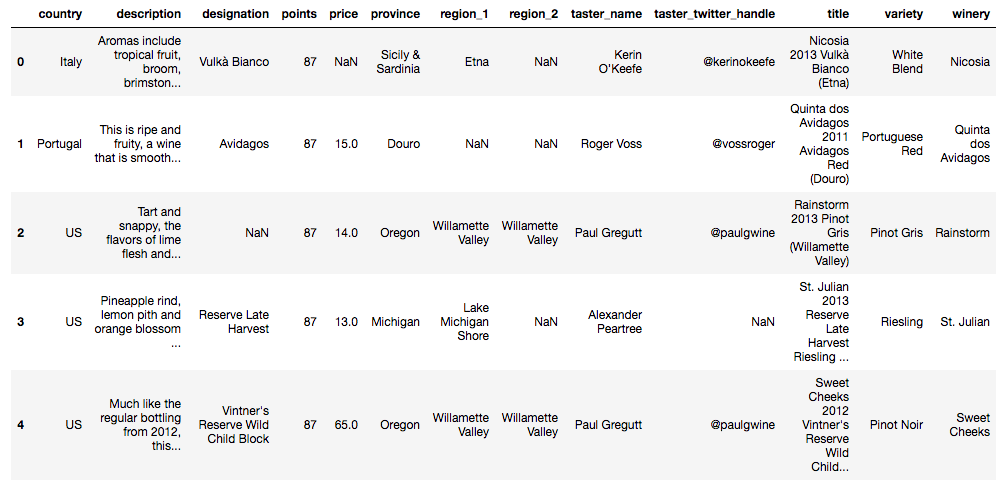
Você pode imprimir algumas informações básicas sobre o conjunto de dados usando print() combinado com .format() para obter uma boa impressão.
print("There are {} observations and {} features in this dataset. \n".format(df.shape[0],df.shape[1]))
print("There are {} types of wine in this dataset such as {}... \n".format(len(df.variety.unique()),
", ".join(df.variety.unique()[0:5])))
print("There are {} countries producing wine in this dataset such as {}... \n".format(len(df.country.unique()),
", ".join(df.country.unique()[0:5])))There are 129971 observations and 13 features in this dataset.
There are 708 types of wine in this dataset such as White Blend, Portuguese Red, Pinot Gris, Riesling, Pinot Noir...
There are 44 countries producing wine in this dataset such as Italy, Portugal, US, Spain, France...df[["country", "description","points"]].head()| país | descrição | pontos | |
|---|---|---|---|
| 0 | Itália | Os aromas incluem frutas tropicais, vassoura, brimston... | 87 |
| 1 | Portugal | É maduro e frutado, um vinho que é suave... | 87 |
| 2 | US | Azedo e rápido, os sabores da polpa do limão e... | 87 |
| 3 | US | Casca de abacaxi, caroço de limão e flor de laranjeira ... | 87 |
| 4 | US | Muito parecido com o engarrafamento regular de 2012, esse... | 87 |
Para fazer comparações entre grupos de um recurso, você pode usar groupby() e computar estatísticas resumidas.
Com o conjunto de dados de vinhos, você pode agrupar por país e examinar as estatísticas resumidas dos pontos e preços de todos os países ou selecionar os mais populares e caros.
# Groupby by country
country = df.groupby("country")
# Summary statistic of all countries
country.describe().head()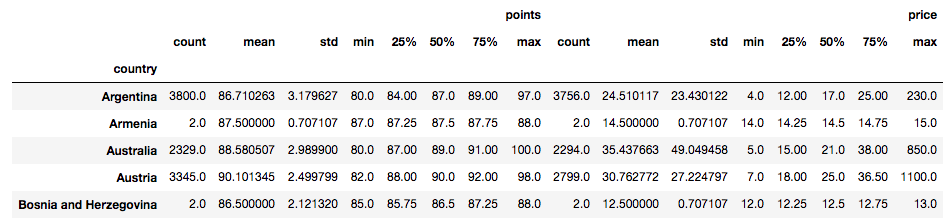
Isso seleciona os 5 pontos médios mais altos entre todos os 44 países:
country.mean().sort_values(by="points",ascending=False).head()| país | pontos | preço |
|---|---|---|
| Inglaterra | 91.581081 | 51.681159 |
| Índia | 90.222222 | 13.333333 |
| Áustria | 90.101345 | 30.762772 |
| Alemanha | 89.851732 | 42.257547 |
| Canadá | 89.369650 | 35.712598 |
Você pode plotar o número de vinhos por país usando o método de plotagem do Pandas DataFrame e do Matplotlib. Se você não estiver familiarizado com o Matplotlib, dê uma olhada rápida no nosso tutorial do Matplotlib.
plt.figure(figsize=(15,10))
country.size().sort_values(ascending=False).plot.bar()
plt.xticks(rotation=50)
plt.xlabel("Country of Origin")
plt.ylabel("Number of Wines")
plt.show()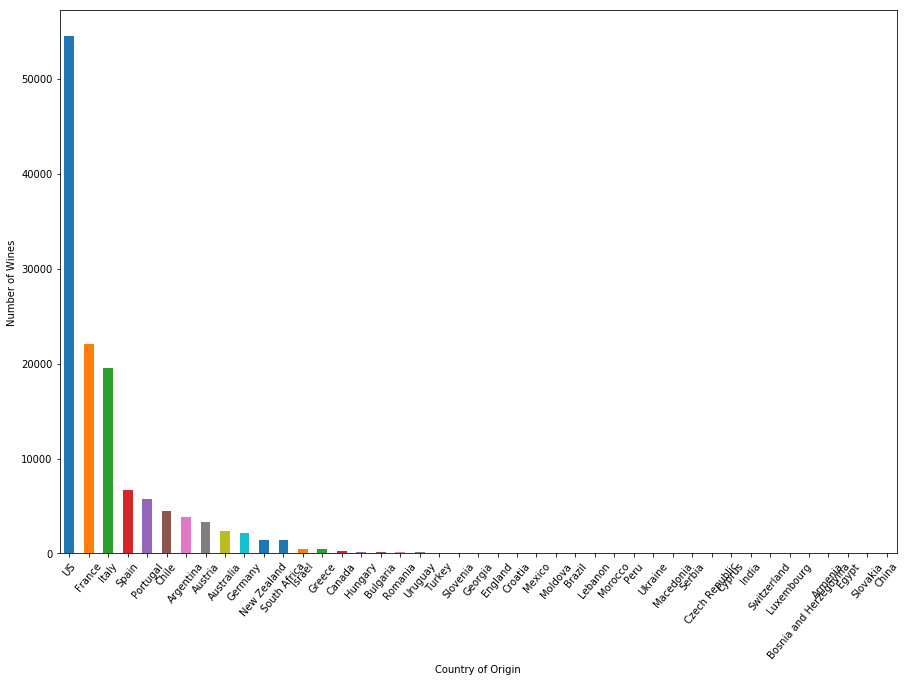
Entre os 44 países produtores de vinho, os EUA têm mais de 50.000 tipos no conjunto de dados de análise de vinhos, o dobro do próximo na classificação, a França - o país famoso por seu vinho. A Itália também produz muitos vinhos de qualidade, com quase 20.000 vinhos abertos para avaliação.
Vamos agora dar uma olhada no gráfico de todos os 44 países de acordo com o vinho mais bem classificado, usando a mesma técnica de gráfico acima:
plt.figure(figsize=(15,10))
country.max().sort_values(by="points",ascending=False)["points"].plot.bar()
plt.xticks(rotation=50)
plt.xlabel("Country of Origin")
plt.ylabel("Highest point of Wines")
plt.show()
Austrália, EUA, Portugal, Itália e França têm vinhos com 100 pontos. Se você observar, Portugal está em 5º lugar e a Austrália em 9º lugar no número de vinhos produzidos no conjunto de dados, e ambos os países têm menos de 8.000 tipos de vinho.
Isso é um pouco de exploração de dados para conhecer o conjunto de dados que você está usando hoje. Agora você começará a mergulhar no prato principal da refeição: a nuvem de palavras.
Uma nuvem de palavras é uma técnica para mostrar quais palavras são as mais frequentes em um determinado texto. Podemos usar uma biblioteca Python para nos ajudar com isso. A primeira coisa que você pode querer fazer antes de usar qualquer função é verificar a documentação da função e ver todos os argumentos obrigatórios e opcionais. Para isso, digite ?function e execute-o para obter todas as informações.
?WordCloud[1;31mInit signature:[0m [0mWordCloud[0m[1;33m([0m[0mfont_path[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mwidth[0m[1;33m=[0m[1;36m400[0m[1;33m,[0m [0mheight[0m[1;33m=[0m[1;36m200[0m[1;33m,[0m [0mmargin[0m[1;33m=[0m[1;36m2[0m[1;33m,[0m [0mranks_only[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mprefer_horizontal[0m[1;33m=[0m[1;36m0.9[0m[1;33m,[0m [0mmask[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mscale[0m[1;33m=[0m[1;36m1[0m[1;33m,[0m [0mcolor_func[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mmax_words[0m[1;33m=[0m[1;36m200[0m[1;33m,[0m [0mmin_font_size[0m[1;33m=[0m[1;36m4[0m[1;33m,[0m [0mstopwords[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mrandom_state[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mbackground_color[0m[1;33m=[0m[1;34m'black'[0m[1;33m,[0m [0mmax_font_size[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mfont_step[0m[1;33m=[0m[1;36m1[0m[1;33m,[0m [0mmode[0m[1;33m=[0m[1;34m'RGB'[0m[1;33m,[0m [0mrelative_scaling[0m[1;33m=[0m[1;36m0.5[0m[1;33m,[0m [0mregexp[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mcollocations[0m[1;33m=[0m[1;32mTrue[0m[1;33m,[0m [0mcolormap[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mnormalize_plurals[0m[1;33m=[0m[1;32mTrue[0m[1;33m,[0m [0mcontour_width[0m[1;33m=[0m[1;36m0[0m[1;33m,[0m [0mcontour_color[0m[1;33m=[0m[1;34m'black'[0m[1;33m)[0m[1;33m[0m[0m
[1;31mDocstring:[0m
Word cloud object for generating and drawing.
Parameters
----------
font_path : string
Font path to the font that will be used (OTF or TTF).
Defaults to DroidSansMono path on a Linux machine. If you are on
another OS or don't have this font; you need to adjust this path.
width : int (default=400)
Width of the canvas.
height : int (default=200)
Height of the canvas.
prefer_horizontal : float (default=0.90)
The ratio of times to try horizontal fitting as opposed to vertical.
If prefer_horizontal < 1, the algorithm will try rotating the word
if it doesn't fit. (There is currently no built-in way to get only
vertical words.)
mask : nd-array or None (default=None)
If not None, gives a binary mask on where to draw words. If mask is not
None, width and height will be ignored, and the shape of mask will be
used instead. All white (#FF or #FFFFFF) entries will be considered
"masked out" while other entries will be free to draw on. [This
changed in the most recent version!]
contour_width: float (default=0)
If mask is not None and contour_width > 0, draw the mask contour.
contour_color: color value (default="black")
Mask contour color.
scale : float (default=1)
Scaling between computation and drawing. For large word-cloud images,
using scale instead of larger canvas size is significantly faster, but
might lead to a coarser fit for the words.
min_font_size : int (default=4)
Smallest font size to use. Will stop when there is no more room in this
size.
font_step : int (default=1)
Step size for the font. font_step > 1 might speed up computation but
give a worse fit.
max_words : number (default=200)
The maximum number of words.
stopwords : set of strings or None
The words that will be eliminated. If None, the build-in STOPWORDS
list will be used.
background_color : color value (default="black")
Background color for the word cloud image.
max_font_size : int or None (default=None)
Maximum font size for the largest word. If None, the height of the image is
used.
mode : string (default="RGB")
Transparent background will be generated when mode is "RGBA" and
background_color is None.
relative_scaling : float (default=.5)
Importance of relative word frequencies for font-size. With
relative_scaling=0, only word-ranks are considered. With
relative_scaling=1, a word that is twice as frequent will have twice
the size. If you want to consider the word frequencies and not only
their rank, relative_scaling around .5 often looks good.
.. versionchanged: 2.0
Default is now 0.5.
color_func : callable, default=None
Callable with parameters word, font_size, position, orientation,
font_path, random_state that returns a PIL color for each word.
Overwrites "colormap".
See colormap for specifying a matplotlib colormap instead.
regexp : string or None (optional)
Regular expression to split the input text into tokens in process_text.
If None is specified, ``r"\w[\w']+"`` is used.
collocations : bool, default=True
Whether to include collocations (bigrams) of two words.
.. versionadded: 2.0
colormap : string or matplotlib colormap, default="viridis"
Matplotlib colormap to randomly draw colors from for each word.
Ignored if "color_func" is specified.
.. versionadded: 2.0
normalize_plurals : bool, default=True
Whether to remove trailing 's' from words. If True and a word
appears with and without a trailing 's', the one with trailing 's'
is removed and its counts are added to the version without
trailing 's' -- unless the word ends with 'ss'.
Attributes
----------
``words_`` : dict of string to float
Word tokens with associated frequency.
.. versionchanged: 2.0
``words_`` is now a dictionary
``layout_`` : list of tuples (string, int, (int, int), int, color))
Encodes the fitted word cloud. Encodes for each word the string, font
size, position, orientation, and color.
Notes
-----
Larger canvases will make the code significantly slower. If you need a
large word cloud, try a lower canvas size, and set the scale parameter.
The algorithm might give more weight to the ranking of the words
then their actual frequencies, depending on the ``max_font_size`` and the
scaling heuristic.
[1;31mFile:[0m c:\intelpython3\lib\site-packages\wordcloud\wordcloud.py
[1;31mType:[0m typeVocê pode ver que o único argumento necessário para um objeto WordCloud é o textenquanto todos os outros são opcionais.
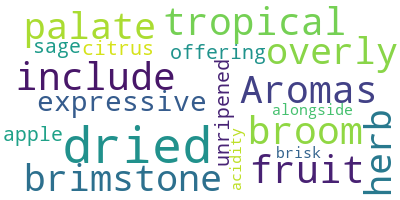
Então, vamos começar com um exemplo simples: usando a descrição da primeira observação como entrada para a nuvem de palavras. As três etapas são:
# Start with one review:
text = df.description[0]
# Create and generate a word cloud image:
wordcloud = WordCloud().generate(text)
# Display the generated image:
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
Ótimo! Você pode ver que a primeira avaliação mencionou muito sobre os sabores secos e os aromas do vinho.
Agora, altere alguns argumentos opcionais da nuvem de palavras, como max_font_size, max_word e background_color.
# lower max_font_size, change the maximum number of word and lighten the background:
wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white").generate(text)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
Parece que usar o max_font_size aqui pode não ser uma boa ideia. Isso torna mais difícil ver as diferenças entre as frequências das palavras. No entanto, ao clarear o plano de fundo, você facilita a leitura da nuvem.
Se você quiser salvar a imagem, o WordCloud oferece a função to_file
# Save the image in the img folder:
wordcloud.to_file("img/first_review.png")<wordcloud.wordcloud.WordCloud at 0x16f1d704978>O resultado será parecido com este quando você os carregar:
Você provavelmente notou o argumento interpolation="bilinear" no site plt.imshow(). Isso faz com que a imagem exibida apareça com mais suavidade. Para obter mais informações sobre a escolha, este tutorial sobre métodos de interpolação para o imshow é um recurso útil.
Portanto, agora você combinará todas as avaliações de vinhos em um grande texto e criará uma grande nuvem para ver quais características são mais comuns nesses vinhos.
text = " ".join(review for review in df.description)
print ("There are {} words in the combination of all review.".format(len(text)))
There are 31661073 words in the combination of all review.
# Create stopword list:
stopwords = set(STOPWORDS)
stopwords.update(["drink", "now", "wine", "flavor", "flavors"])
# Generate a word cloud image
wordcloud = WordCloud(stopwords=stopwords, background_color="white").generate(text)
# Display the generated image:
# the matplotlib way:
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()

Parece que cereja preta e encorpado são as características mais mencionadas, e o Cabernet Sauvignon é o mais popular de todos. Isso se alinha ao fato de que a Cabernet Sauvignon "é uma das variedades de uva de vinho tinto mais reconhecidas do mundo. Ela é cultivada em quase todos os principais países produtores de vinho em um espectro diversificado de climas, desde o Vale Okanagan, no Canadá, até o Vale Beqaa, no Líbano".[1]
Agora, vamos colocar essas palavras em uma taça (ou até mesmo em uma garrafa) de vinho!
Para criar uma forma para a nuvem de palavras, primeiro você precisa encontrar um arquivo PNG para se tornar a máscara. Abaixo você encontra uma boa opção que está disponível na Internet:

Nem todas as imagens de máscara têm o mesmo formato, o que resulta em resultados diferentes, fazendo com que a função WordCloud não funcione corretamente. Para ter certeza de que sua máscara funciona, vamos dar uma olhada nela na forma de matriz numpy:
wine_mask = np.array(Image.open("img/wine_mask.png"))
wine_mask
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=uint8)
A maneira como as funções de mascaramento funcionam é exigindo que toda a parte branca da máscara seja 255 e não 0 (tipo inteiro). Esse valor representa a "intensidade" do pixel. Valores de 255 são branco puro, enquanto valores de 1 são preto. Aqui, você pode usar a função fornecida abaixo para transformar sua máscara se ela tiver o mesmo formato acima. Observe que, se você tiver uma máscara em que o plano de fundo não seja 0, mas 1 ou 2, ajuste a função para corresponder à sua máscara.
Primeiro, você usa a função transform_format() para trocar os números de 0 a 255.
def transform_format(val):
if val == 0:
return 255
else:
return val
Em seguida, crie uma nova máscara com o mesmo formato da máscara que você tem em mãos e aplique a função transform_format() a cada valor em cada linha da máscara anterior.
# Transform your mask into a new one that will work with the function:
transformed_wine_mask = np.ndarray((wine_mask.shape[0],wine_mask.shape[1]), np.int32)
for i in range(len(wine_mask)):
transformed_wine_mask[i] = list(map(transform_format, wine_mask[i]))
Agora, você tem uma nova máscara no formato correto. Imprimir a máscara transformada é a melhor maneira de verificar se a função funciona bem.
# Check the expected result of your mask
transformed_wine_mask
array([[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
...,
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255]])
Com a máscara correta, você pode começar a criar a nuvem de palavras com a forma selecionada. Observe que na função WordCloud há um argumento mask que recebe a máscara transformada que você criou acima. O contour_width e o contour_color são, como o nome sugere, argumentos para ajustar as características de contorno da nuvem. A garrafa de vinho que você tem aqui é uma garrafa de vinho vermelha, portanto, o tijolo de fogo parece ser uma boa opção para a cor do contorno. Para obter mais opções de cores, você pode dar uma olhada nesta tabela de códigos de cores.
# Create a word cloud image
wc = WordCloud(background_color="white", max_words=1000, mask=transformed_wine_mask,
stopwords=stopwords, contour_width=3, contour_color='firebrick')
# Generate a wordcloud
wc.generate(text)
# store to file
wc.to_file("img/wine.png")
# show
plt.figure(figsize=[20,10])
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()

Voila! Você criou uma nuvem de palavras no formato de uma garrafa de vinho! Parece que as descrições de vinho mencionam com mais frequência cereja preta, sabores de frutas e características encorpadas do vinho. Agora, vamos dar uma olhada mais de perto nas avaliações de cada país e traçar a nuvem de palavras usando a bandeira de cada país. Abaixo está um exemplo que você criará em breve:

Você pode combinar todas as avaliações dos cinco países que têm mais vinhos. Para encontrar esses países, você pode observar o gráfico país vs. número de vinhos acima ou usar o grupo que você obteve acima para encontrar o número de observações para cada país (cada grupo) e sort_values() com o argumento ascending=False para classificar de forma decrescente.
country.size().sort_values(ascending=False).head()
country
US 54504
France 22093
Italy 19540
Spain 6645
Portugal 5691
dtype: int64
Portanto, agora você tem 5 países principais: EUA, França, Itália, Espanha e Portugal. Você pode alterar o número de países colocando o número escolhido dentro do site head(), como abaixo
country.size().sort_values(ascending=False).head(10)
country
US 54504
France 22093
Italy 19540
Spain 6645
Portugal 5691
Chile 4472
Argentina 3800
Austria 3345
Australia 2329
Germany 2165
dtype: int64
Por enquanto, cinco países devem ser suficientes.
Para obter todas as avaliações de cada país, você pode concatenar todas as avaliações usando a sintaxe " ".join(list), que une todos os elementos de uma lista, separando-os por espaços em branco.
# Join all reviews of each country:
usa = " ".join(review for review in df[df["country"]=="US"].description)
fra = " ".join(review for review in df[df["country"]=="France"].description)
ita = " ".join(review for review in df[df["country"]=="Italy"].description)
spa = " ".join(review for review in df[df["country"]=="Spain"].description)
por = " ".join(review for review in df[df["country"]=="Portugal"].description)
Em seguida, você pode criar a nuvem de palavras conforme descrito acima. Você pode combinar as duas etapas de criação e geração em uma só, como mostrado abaixo. O mapeamento de cores é feito logo antes de você traçar a nuvem usando a função ImageColorGenerator da biblioteca do WordCloud.
# Generate a word cloud image
mask = np.array(Image.open("img/us.png"))
wordcloud_usa = WordCloud(stopwords=stopwords, background_color="white", mode="RGBA", max_words=1000, mask=mask).generate(usa)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_usa.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/us_wine.png", format="png")
plt.show()

Parece bom! Agora vamos repetir com uma análise da França.
# Generate a word cloud image
mask = np.array(Image.open("img/france.png"))
wordcloud_fra = WordCloud(stopwords=stopwords, background_color="white", mode="RGBA", max_words=1000, mask=mask).generate(fra)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_fra.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/fra_wine.png", format="png")
#plt.show()
Observe que você deve salvar a imagem após a plotagem para ter a nuvem de palavras com o padrão de cores desejado.

# Generate a word cloud image
mask = np.array(Image.open("img/italy.png"))
wordcloud_ita = WordCloud(stopwords=stopwords, background_color="white", max_words=1000, mask=mask).generate(ita)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_ita.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/ita_wine.png", format="png")
#plt.show()

Depois da Itália, vem a Espanha:
# Generate a word cloud image
mask = np.array(Image.open("img/spain.png"))
wordcloud_spa = WordCloud(stopwords=stopwords, background_color="white", max_words=1000, mask=mask).generate(spa)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_spa.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/spa_wine.png", format="png")
#plt.show()

Finalmente, Portugal:
# Generate a word cloud image
mask = np.array(Image.open("img/portugal.png"))
wordcloud_por = WordCloud(stopwords=stopwords, background_color="white", max_words=1000, mask=mask).generate(por)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_por.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/por_wine.png", format="png")
#plt.show()

O resultado final está na tabela abaixo para você comparar as máscaras e as nuvens de palavras. Qual deles é o que você mais gosta?
Portanto, já vimos vários exemplos de nuvens de palavras e como criá-las em Python. No entanto, vale a pena explorar como você pode interpretar essas visualizações de dados. Em geral, o tamanho de cada palavra na nuvem representa sua frequência ou importância no texto. Normalmente, quanto mais frequentemente uma palavra aparece no texto, maior ela aparecerá na nuvem de palavras.
Há vários aspectos que você deve ter em mente ao interpretar as nuvens de palavras:
Em geral, uma nuvem de palavras pode ser uma ferramenta útil para visualizar rapidamente os principais temas e ideias em um texto. No entanto, é importante ter em mente que essa é apenas uma ferramenta entre muitas outras para analisar dados de texto e deve ser usada em conjunto com outros métodos para uma análise e compreensão mais profundas.
Você conseguiu! Você aprendeu várias maneiras de desenhar uma nuvem de palavras em Python usando a biblioteca WordCloud, que seria útil para a visualização de qualquer análise de texto. Você também aprenderá a mascarar a nuvem em qualquer forma, usando qualquer cor de sua escolha. Se você quiser praticar suas habilidades, considere o projeto do DataCamp: Os tópicos mais quentes em aprendizado de máquina
Se você estiver interessado em saber mais sobre o processamento de linguagem natural, faça nosso curso Fundamentos do processamento de linguagem natural em Python.
Cursos de Python
Curso
Curso
Curso
Tutorial
Joleen Bothma
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan