Kurs
Einführung in Python
4 Std.
6.9M
Code aus diesem Tutorial online ausführen und bearbeiten
Code ausführenVielleicht hast du schon einmal eine Wolke mit vielen Wörtern in verschiedenen Größen gesehen, die die Häufigkeit oder Wichtigkeit der einzelnen Wörter darstellen. Das nennt man eine Tag Cloud oder Wortwolke. In diesem Tutorial lernst du, wie du eine Wortwolke in Python erstellst und sie nach deinen Vorstellungen anpasst. Dieses Tool ist praktisch, um Textdaten zu untersuchen und deinen Bericht lebendiger zu gestalten.
Übe mit dieser praktischen Übung, eine WordCloud in Python zu erstellen.
In diesem Lernprogramm werden wir einen Datensatz mit Weinrezensionen von der Wine Enthusiast Website verwenden, um zu lernen:
Es ist wichtig, daran zu denken, dass Wortwolken zwar nützlich sind, um häufig vorkommende Wörter in einem Text oder Datensatz zu visualisieren, dass sie aber in der Regel nur einen Überblick über die Themen bieten. Sie ähneln den Bar Blots, sind aber oft visuell ansprechender (wenn auch manchmal schwieriger zu interpretieren). Wortwolken können besonders hilfreich sein, wenn du das möchtest:
Es ist jedoch wichtig zu bedenken, dass Wortwolken keinen Kontext oder ein tieferes Verständnis der verwendeten Wörter und Ausdrücke liefern. Daher sollten sie in Verbindung mit anderen Methoden zur Analyse und Interpretation von Textdaten verwendet werden.
Um mit der Erstellung einer Wortwolke in Python zu beginnen, musst du einige der folgenden Pakete installieren:
Die Bibliothek numpy ist eine der beliebtesten und hilfreichsten Bibliotheken, die für den Umgang mit mehrdimensionalen Arrays und Matrizen verwendet wird. Sie wird auch in Kombination mit der pandas Bibliothek verwendet, um Datenanalysen durchzuführen.
Das Python-Modul os ist eine integrierte Bibliothek, du musst es also nicht installieren. Um mehr über den Umgang mit Dateien mit dem os-Modul zu erfahren, ist dieses DataCamp-Tutorial zum Lesen und Schreiben von Dateien in Python hilfreich.
Für die Visualisierung ist matplotlib eine Basisbibliothek, die es vielen anderen Bibliotheken ermöglicht, auf ihrer Grundlage zu arbeiten und zu plotten. seaborn oder wordcloud, die du in diesem Lernprogramm verwenden wirst. Die pillow Bibliothek ist ein Paket, das das Lesen von Bildern ermöglicht. Pillow ist ein Wrapper für PIL - Python Imaging Library. Du brauchst diese Bibliothek, um das Bild als Maske für die Wortwolke einzulesen.
wordcloud kann ein wenig schwierig zu installieren sein. Wenn du nur eine einfache Wortwolke erstellen willst, reicht pip install wordcloud oder conda install -c conda-forge wordcloud aus. Die neueste Version mit der Möglichkeit, die Wolke in jede beliebige Form zu bringen, erfordert jedoch eine andere Installationsmethode (siehe unten):
git clone https://github.com/amueller/word_cloud.git
cd word_cloud
pip install .Dieses Tutorial verwendet den Weinbewertungsdatensatz von Kaggle. Diese Sammlung ist ein großartiger Datensatz zum Lernen, da es keine fehlenden Werte gibt (was Zeit kostet) und viele Text- (Weinbewertungen), kategoriale und numerische Daten.
Als Erstes lädst du alle notwendigen Bibliotheken:
# Start with loading all necessary libraries
import numpy as np
import pandas as pd
from os import path
from PIL import Image
from wordcloud import WordCloud, STOPWORDS, ImageColorGeneratorimport matplotlib.pyplot as plt
% matplotlib inlinec:\intelpython3\lib\site-packages\matplotlib\__init__.py:
import warnings
warnings.filterwarnings("ignore")
Wenn du mehr als 10 Bibliotheken hast, ordne sie nach Abschnitten (z. B. Basislibs, Visualisierung, Modelle usw.). Durch die Verwendung von Kommentaren im Code wird dein Code sauber und leicht nachvollziehbar.
Benutze jetzt Pandas read_csv, um den Datenrahmen zu laden. Beachte die Verwendung von index_col=0, was bedeutet, dass wir den Zeilennamen (Index) nicht als separate Spalte einlesen.
# Load in the dataframe
df = pd.read_csv("data/winemag-data-130k-v2.csv", index_col=0)# Looking at first 5 rows of the dataset
df.head()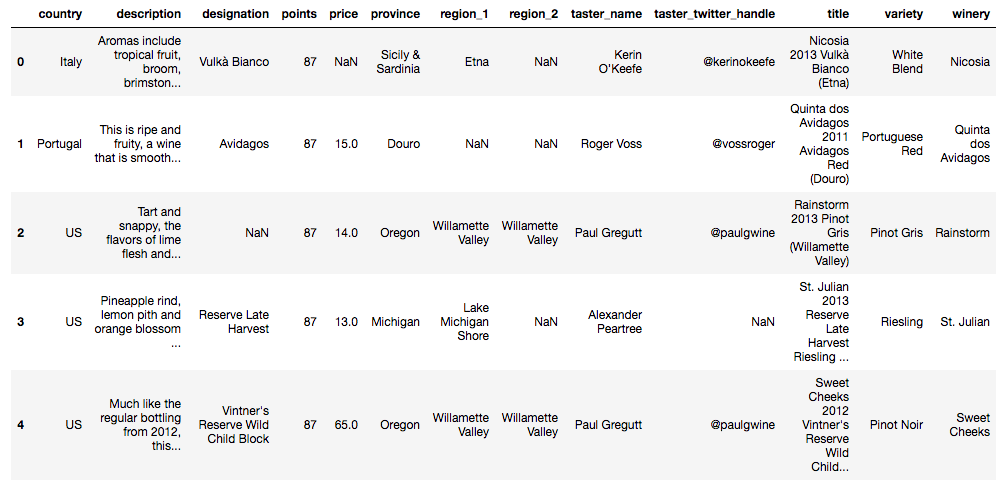
Du kannst einige grundlegende Informationen über den Datensatz ausdrucken, indem du print() mit .format() kombinierst, um einen schönen Ausdruck zu erhalten.
print("There are {} observations and {} features in this dataset. \n".format(df.shape[0],df.shape[1]))
print("There are {} types of wine in this dataset such as {}... \n".format(len(df.variety.unique()),
", ".join(df.variety.unique()[0:5])))
print("There are {} countries producing wine in this dataset such as {}... \n".format(len(df.country.unique()),
", ".join(df.country.unique()[0:5])))There are 129971 observations and 13 features in this dataset.
There are 708 types of wine in this dataset such as White Blend, Portuguese Red, Pinot Gris, Riesling, Pinot Noir...
There are 44 countries producing wine in this dataset such as Italy, Portugal, US, Spain, France...df[["country", "description","points"]].head()| Land | Beschreibung | Punkte | |
|---|---|---|---|
| 0 | Italien | Aromen von tropischen Früchten, Ginster, Brimston und... | 87 |
| 1 | Portugal | Er ist reif und fruchtig, ein Wein, der geschmeidig und... | 87 |
| 2 | US | Herb und spritzig, die Aromen von Limettenfleisch und... | 87 |
| 3 | US | Ananasschalen, Zitronenmark und Orangenblüten ... | 87 |
| 4 | US | Ähnlich wie die reguläre Abfüllung von 2012 ist diese... | 87 |
Um Vergleiche zwischen Gruppen eines Merkmals anzustellen, kannst du groupby() verwenden und eine zusammenfassende Statistik berechnen.
Mit dem Weindatensatz kannst du nach Ländern gruppieren und dir entweder die zusammenfassenden Statistiken für alle Länder nach Punkten und Preis ansehen oder die beliebtesten und teuersten auswählen.
# Groupby by country
country = df.groupby("country")
# Summary statistic of all countries
country.describe().head()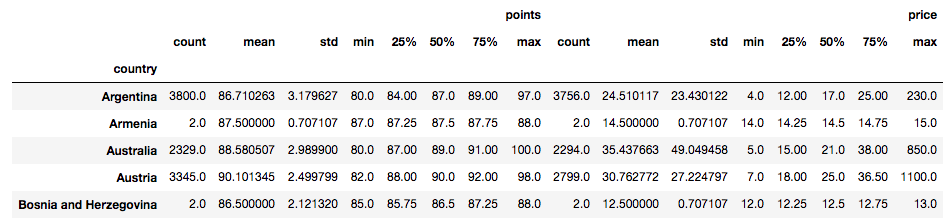
So werden die Top 5 der höchsten Durchschnittspunkte aller 44 Länder ermittelt:
country.mean().sort_values(by="points",ascending=False).head()| Land | Punkte | Preis |
|---|---|---|
| England | 91.581081 | 51.681159 |
| Indien | 90.222222 | 13.333333 |
| Österreich | 90.101345 | 30.762772 |
| Deutschland | 89.851732 | 42.257547 |
| Kanada | 89.369650 | 35.712598 |
Du kannst die Anzahl der Weine nach Land mit der Plot-Methode von Pandas DataFrame und Matplotlib darstellen. Wenn du mit Matplotlib nicht vertraut bist, wirf einen Blick auf unser Matplotlib-Tutorial.
plt.figure(figsize=(15,10))
country.size().sort_values(ascending=False).plot.bar()
plt.xticks(rotation=50)
plt.xlabel("Country of Origin")
plt.ylabel("Number of Wines")
plt.show()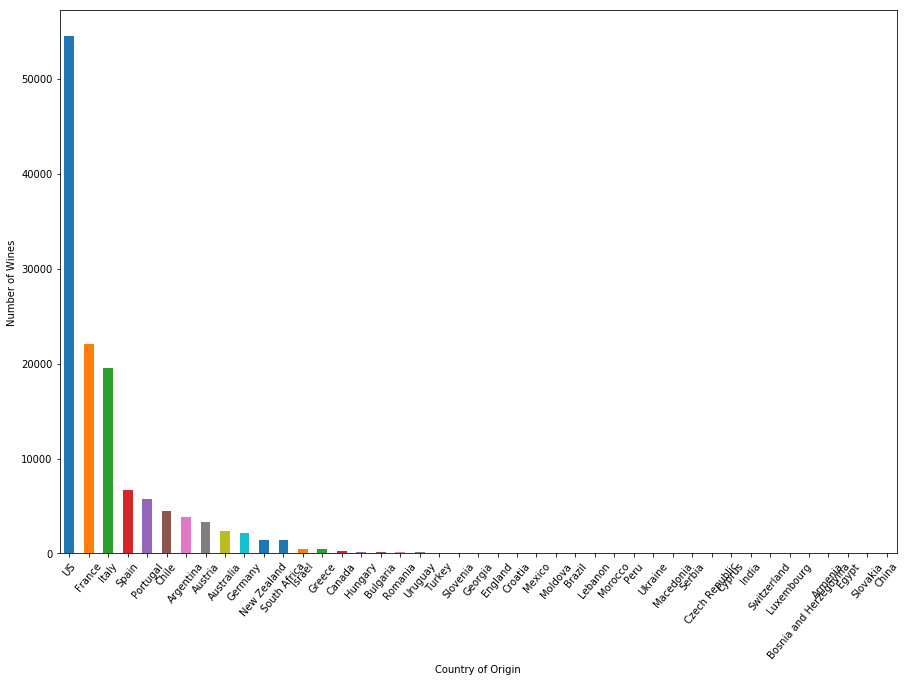
Unter den 44 Ländern, die Wein produzieren, haben die USA mehr als 50.000 Weintypen im Datensatz der Weinkritik, doppelt so viele wie das nächste Land auf der Rangliste, Frankreich - das Land, das für seinen Wein berühmt ist. Italien produziert auch viele Qualitätsweine und hat fast 20.000 Weine, die du bewerten kannst.
Werfen wir nun einen Blick auf die Darstellung aller 44 Länder nach dem am höchsten bewerteten Wein, wobei wir die gleiche Technik wie oben anwenden:
plt.figure(figsize=(15,10))
country.max().sort_values(by="points",ascending=False)["points"].plot.bar()
plt.xticks(rotation=50)
plt.xlabel("Country of Origin")
plt.ylabel("Highest point of Wines")
plt.show()
Australien, die USA, Portugal, Italien und Frankreich haben alle 100-Punkte-Weine. Wie du siehst, liegt Portugal auf Platz 5 und Australien auf Platz 9, was die Anzahl der produzierten Weine im Datensatz angeht, und beide Länder haben weniger als 8000 Weinsorten.
Das ist ein bisschen Datenexploration, um den Datensatz kennenzulernen, den du heute benutzt. Jetzt tauchst du in den Hauptgang der Mahlzeit ein: die Wortwolke.
Eine Wortwolke ist eine Technik, die zeigt, welche Wörter in einem bestimmten Text am häufigsten vorkommen. Wir können eine Python-Bibliothek verwenden, die uns dabei hilft. Das erste, was du tun solltest, bevor du eine Funktion verwendest, ist, dir den Docstring der Funktion anzusehen und alle erforderlichen und optionalen Argumente zu überprüfen. Dazu gibst du ?function ein und führst es aus, um alle Informationen zu erhalten.
?WordCloud[1;31mInit signature:[0m [0mWordCloud[0m[1;33m([0m[0mfont_path[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mwidth[0m[1;33m=[0m[1;36m400[0m[1;33m,[0m [0mheight[0m[1;33m=[0m[1;36m200[0m[1;33m,[0m [0mmargin[0m[1;33m=[0m[1;36m2[0m[1;33m,[0m [0mranks_only[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mprefer_horizontal[0m[1;33m=[0m[1;36m0.9[0m[1;33m,[0m [0mmask[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mscale[0m[1;33m=[0m[1;36m1[0m[1;33m,[0m [0mcolor_func[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mmax_words[0m[1;33m=[0m[1;36m200[0m[1;33m,[0m [0mmin_font_size[0m[1;33m=[0m[1;36m4[0m[1;33m,[0m [0mstopwords[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mrandom_state[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mbackground_color[0m[1;33m=[0m[1;34m'black'[0m[1;33m,[0m [0mmax_font_size[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mfont_step[0m[1;33m=[0m[1;36m1[0m[1;33m,[0m [0mmode[0m[1;33m=[0m[1;34m'RGB'[0m[1;33m,[0m [0mrelative_scaling[0m[1;33m=[0m[1;36m0.5[0m[1;33m,[0m [0mregexp[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mcollocations[0m[1;33m=[0m[1;32mTrue[0m[1;33m,[0m [0mcolormap[0m[1;33m=[0m[1;32mNone[0m[1;33m,[0m [0mnormalize_plurals[0m[1;33m=[0m[1;32mTrue[0m[1;33m,[0m [0mcontour_width[0m[1;33m=[0m[1;36m0[0m[1;33m,[0m [0mcontour_color[0m[1;33m=[0m[1;34m'black'[0m[1;33m)[0m[1;33m[0m[0m
[1;31mDocstring:[0m
Word cloud object for generating and drawing.
Parameters
----------
font_path : string
Font path to the font that will be used (OTF or TTF).
Defaults to DroidSansMono path on a Linux machine. If you are on
another OS or don't have this font; you need to adjust this path.
width : int (default=400)
Width of the canvas.
height : int (default=200)
Height of the canvas.
prefer_horizontal : float (default=0.90)
The ratio of times to try horizontal fitting as opposed to vertical.
If prefer_horizontal < 1, the algorithm will try rotating the word
if it doesn't fit. (There is currently no built-in way to get only
vertical words.)
mask : nd-array or None (default=None)
If not None, gives a binary mask on where to draw words. If mask is not
None, width and height will be ignored, and the shape of mask will be
used instead. All white (#FF or #FFFFFF) entries will be considered
"masked out" while other entries will be free to draw on. [This
changed in the most recent version!]
contour_width: float (default=0)
If mask is not None and contour_width > 0, draw the mask contour.
contour_color: color value (default="black")
Mask contour color.
scale : float (default=1)
Scaling between computation and drawing. For large word-cloud images,
using scale instead of larger canvas size is significantly faster, but
might lead to a coarser fit for the words.
min_font_size : int (default=4)
Smallest font size to use. Will stop when there is no more room in this
size.
font_step : int (default=1)
Step size for the font. font_step > 1 might speed up computation but
give a worse fit.
max_words : number (default=200)
The maximum number of words.
stopwords : set of strings or None
The words that will be eliminated. If None, the build-in STOPWORDS
list will be used.
background_color : color value (default="black")
Background color for the word cloud image.
max_font_size : int or None (default=None)
Maximum font size for the largest word. If None, the height of the image is
used.
mode : string (default="RGB")
Transparent background will be generated when mode is "RGBA" and
background_color is None.
relative_scaling : float (default=.5)
Importance of relative word frequencies for font-size. With
relative_scaling=0, only word-ranks are considered. With
relative_scaling=1, a word that is twice as frequent will have twice
the size. If you want to consider the word frequencies and not only
their rank, relative_scaling around .5 often looks good.
.. versionchanged: 2.0
Default is now 0.5.
color_func : callable, default=None
Callable with parameters word, font_size, position, orientation,
font_path, random_state that returns a PIL color for each word.
Overwrites "colormap".
See colormap for specifying a matplotlib colormap instead.
regexp : string or None (optional)
Regular expression to split the input text into tokens in process_text.
If None is specified, ``r"\w[\w']+"`` is used.
collocations : bool, default=True
Whether to include collocations (bigrams) of two words.
.. versionadded: 2.0
colormap : string or matplotlib colormap, default="viridis"
Matplotlib colormap to randomly draw colors from for each word.
Ignored if "color_func" is specified.
.. versionadded: 2.0
normalize_plurals : bool, default=True
Whether to remove trailing 's' from words. If True and a word
appears with and without a trailing 's', the one with trailing 's'
is removed and its counts are added to the version without
trailing 's' -- unless the word ends with 'ss'.
Attributes
----------
``words_`` : dict of string to float
Word tokens with associated frequency.
.. versionchanged: 2.0
``words_`` is now a dictionary
``layout_`` : list of tuples (string, int, (int, int), int, color))
Encodes the fitted word cloud. Encodes for each word the string, font
size, position, orientation, and color.
Notes
-----
Larger canvases will make the code significantly slower. If you need a
large word cloud, try a lower canvas size, and set the scale parameter.
The algorithm might give more weight to the ranking of the words
then their actual frequencies, depending on the ``max_font_size`` and the
scaling heuristic.
[1;31mFile:[0m c:\intelpython3\lib\site-packages\wordcloud\wordcloud.py
[1;31mType:[0m typeDu kannst sehen, dass das einzige erforderliche Argument für ein WordCloud-Objekt die Textist, während alle anderen optional sind.
Beginnen wir also mit einem einfachen Beispiel: Wir verwenden die erste Beobachtungsbeschreibung als Eingabe für die Wortwolke. Die drei Schritte sind:
# Start with one review:
text = df.description[0]
# Create and generate a word cloud image:
wordcloud = WordCloud().generate(text)
# Display the generated image:
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
Toll! Wie du siehst, wurde in der ersten Bewertung viel über den Trockengeschmack und die Aromen des Weins geschrieben.
Ändere nun einige optionale Argumente der Wortwolke wie max_font_size, max_word und background_color.
# lower max_font_size, change the maximum number of word and lighten the background:
wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white").generate(text)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
Es scheint, als wäre es keine gute Idee, max_font_size hier zu verwenden. Dadurch wird es schwieriger, die Unterschiede zwischen den Worthäufigkeiten zu erkennen. Wenn du den Hintergrund aufhellst, ist die Wolke jedoch leichter zu lesen.
Wenn du das Bild speichern möchtest, bietet WordCloud die Funktion to_file
# Save the image in the img folder:
wordcloud.to_file("img/first_review.png")<wordcloud.wordcloud.WordCloud at 0x16f1d704978>Das Ergebnis wird so aussehen, wenn du sie einlädst:
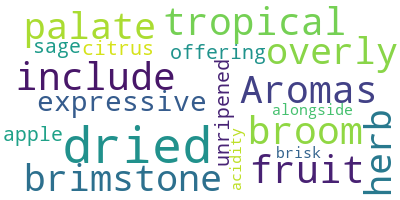
Du hast wahrscheinlich das Argument interpolation="bilinear" in der plt.imshow() bemerkt. Dadurch wird das angezeigte Bild flüssiger dargestellt. Wenn du mehr über die Auswahl wissen willst, ist dieses Tutorial über Interpolationsmethoden für imshow eine nützliche Ressource.
Jetzt fasst du also alle Weinbewertungen in einem großen Text zusammen und erstellst eine große fette Wolke, um zu sehen, welche Eigenschaften bei diesen Weinen am häufigsten vorkommen.
text = " ".join(review for review in df.description)
print ("There are {} words in the combination of all review.".format(len(text)))
There are 31661073 words in the combination of all review.
# Create stopword list:
stopwords = set(STOPWORDS)
stopwords.update(["drink", "now", "wine", "flavor", "flavors"])
# Generate a word cloud image
wordcloud = WordCloud(stopwords=stopwords, background_color="white").generate(text)
# Display the generated image:
# the matplotlib way:
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()

Es scheint, als wären Schwarzkirsche und Vollmundigkeit die am häufigsten genannten Eigenschaften, und Cabernet Sauvignon ist der beliebteste von allen. Das deckt sich mit der Tatsache, dass Cabernet Sauvignon "eine der bekanntesten Rotweinrebsorten der Welt ist. Er wird in fast allen großen Weinbauländern angebaut, und zwar in den unterschiedlichsten Klimazonen, vom kanadischen Okanagan Valley bis zum Beqaa Valley im Libanon.[1]
Jetzt lass uns diese Worte in eine Tasse (oder sogar eine Flasche) Wein gießen!
Um eine Form für deine Wortwolke zu erstellen, musst du zunächst eine PNG-Datei finden, die als Maske dienen soll. Im Folgenden findest du ein schönes Exemplar, das im Internet verfügbar ist:

Nicht alle Maskenbilder haben das gleiche Format, was zu unterschiedlichen Ergebnissen führt, so dass die WordCloud-Funktion nicht richtig funktioniert. Um sicherzustellen, dass deine Maske funktioniert, schauen wir sie uns in Form eines Numpy-Arrays an:
wine_mask = np.array(Image.open("img/wine_mask.png"))
wine_mask
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=uint8)
Die Maskierungsfunktionen erfordern, dass der weiße Anteil der Maske 255 und nicht 0 ist (Ganzzahl). Dieser Wert stellt die "Intensität" des Pixels dar. Werte von 255 sind rein weiß, während Werte von 1 schwarz sind. Hier kannst du die unten stehende Funktion verwenden, um deine Maske umzuwandeln, wenn deine Maske das gleiche Format wie oben hat. Beachte, wenn du eine Maske hast, bei der der Hintergrund nicht 0, sondern 1 oder 2 ist, passe die Funktion an deine Maske an.
Zuerst benutzt du die Funktion transform_format(), um die Zahlen 0 bis 255 zu tauschen.
def transform_format(val):
if val == 0:
return 255
else:
return val
Erstelle dann eine neue Maske mit der gleichen Form wie die Maske, die du gerade in der Hand hast, und wende die Funktion transform_format() auf jeden Wert in jeder Zeile der vorherigen Maske an.
# Transform your mask into a new one that will work with the function:
transformed_wine_mask = np.ndarray((wine_mask.shape[0],wine_mask.shape[1]), np.int32)
for i in range(len(wine_mask)):
transformed_wine_mask[i] = list(map(transform_format, wine_mask[i]))
Jetzt hast du eine neue Maske in der richtigen Form. Der Ausdruck der umgewandelten Maske ist der beste Weg, um zu überprüfen, ob die Funktion gut funktioniert.
# Check the expected result of your mask
transformed_wine_mask
array([[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
...,
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255]])
Mit der richtigen Maske kannst du beginnen, die Wortwolke mit deiner ausgewählten Form zu erstellen. Beachte, dass es in der Funktion WordCloud ein Argument mask gibt, das die transformierte Maske enthält, die du oben erstellt hast. contour_width und contour_color sind, wie der Name schon sagt, Argumente, um die Umrissmerkmale der Wolke anzupassen. Die Weinflasche, die du hier hast, ist eine Rotweinflasche, also scheint Feuerstein eine gute Wahl für die Konturfarbe zu sein. Für weitere Farbauswahlen kannst du einen Blick auf diese Farbcodetabelle werfen.
# Create a word cloud image
wc = WordCloud(background_color="white", max_words=1000, mask=transformed_wine_mask,
stopwords=stopwords, contour_width=3, contour_color='firebrick')
# Generate a wordcloud
wc.generate(text)
# store to file
wc.to_file("img/wine.png")
# show
plt.figure(figsize=[20,10])
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()

Voila! Du hast eine Wortwolke in Form einer Weinflasche erstellt! Es scheint, dass in den Weinbeschreibungen am häufigsten schwarze Kirschen, Fruchtaromen und vollmundige Eigenschaften des Weins erwähnt werden. Schauen wir uns nun die Bewertungen für jedes Land genauer an und stellen die Wortwolke mit der Flagge des jeweiligen Landes dar. Im Folgenden findest du ein Beispiel, das du bald erstellen wirst:

Du kannst alle Bewertungen der fünf Länder mit den meisten Weinen kombinieren. Um diese Länder zu finden, kannst du entweder das Diagramm Land vs. Anzahl der Weine oben betrachten oder die Gruppe verwenden, die du oben erhalten hast, um die Anzahl der Beobachtungen für jedes Land (jede Gruppe) zu finden und sort_values() mit dem Argument ascending=False absteigend zu sortieren.
country.size().sort_values(ascending=False).head()
country
US 54504
France 22093
Italy 19540
Spain 6645
Portugal 5691
dtype: int64
Jetzt hast du also 5 Top-Länder: die USA, Frankreich, Italien, Spanien und Portugal. Du kannst die Anzahl der Länder ändern, indem du die gewünschte Anzahl in head() einträgst.
country.size().sort_values(ascending=False).head(10)
country
US 54504
France 22093
Italy 19540
Spain 6645
Portugal 5691
Chile 4472
Argentina 3800
Austria 3345
Australia 2329
Germany 2165
dtype: int64
Für den Moment sollten fünf Länder genug sein.
Um alle Rezensionen für jedes Land zu erhalten, kannst du alle Rezensionen mit der " ".join(list) Syntax verketten, die alle Elemente in einer Liste verbindet und sie durch Leerzeichen trennt.
# Join all reviews of each country:
usa = " ".join(review for review in df[df["country"]=="US"].description)
fra = " ".join(review for review in df[df["country"]=="France"].description)
ita = " ".join(review for review in df[df["country"]=="Italy"].description)
spa = " ".join(review for review in df[df["country"]=="Spain"].description)
por = " ".join(review for review in df[df["country"]=="Portugal"].description)
Dann kannst du die Wortwolke wie oben beschrieben erstellen. Du kannst die beiden Schritte des Erstellens und Erzeugens wie folgt kombinieren. Die Farbzuordnung wird direkt vor dem Plotten der Wolke mit der Funktion ImageColorGenerator aus der WordCloud-Bibliothek durchgeführt.
# Generate a word cloud image
mask = np.array(Image.open("img/us.png"))
wordcloud_usa = WordCloud(stopwords=stopwords, background_color="white", mode="RGBA", max_words=1000, mask=mask).generate(usa)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_usa.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/us_wine.png", format="png")
plt.show()

Sieht gut aus! Jetzt wiederholen wir das Ganze mit einem Bericht aus Frankreich.
# Generate a word cloud image
mask = np.array(Image.open("img/france.png"))
wordcloud_fra = WordCloud(stopwords=stopwords, background_color="white", mode="RGBA", max_words=1000, mask=mask).generate(fra)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_fra.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/fra_wine.png", format="png")
#plt.show()
Bitte beachte, dass du das Bild nach dem Plotten speichern solltest, um die Wortwolke mit dem gewünschten Farbmuster zu erhalten.

# Generate a word cloud image
mask = np.array(Image.open("img/italy.png"))
wordcloud_ita = WordCloud(stopwords=stopwords, background_color="white", max_words=1000, mask=mask).generate(ita)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_ita.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/ita_wine.png", format="png")
#plt.show()

Nach Italien folgt Spanien:
# Generate a word cloud image
mask = np.array(Image.open("img/spain.png"))
wordcloud_spa = WordCloud(stopwords=stopwords, background_color="white", max_words=1000, mask=mask).generate(spa)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_spa.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/spa_wine.png", format="png")
#plt.show()

Finally, Portugal:
# Generate a word cloud image
mask = np.array(Image.open("img/portugal.png"))
wordcloud_por = WordCloud(stopwords=stopwords, background_color="white", max_words=1000, mask=mask).generate(por)
# create coloring from image
image_colors = ImageColorGenerator(mask)
plt.figure(figsize=[7,7])
plt.imshow(wordcloud_por.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# store to file
plt.savefig("img/por_wine.png", format="png")
#plt.show()

Das Endergebnis findest du in der Tabelle unten, um die Masken und die Wortwolken zu vergleichen. Welches ist dein Favorit?
Wir haben nun einige Beispiele für Wortwolken gesehen und wie man sie in Python erstellt. Es lohnt sich jedoch zu erforschen, wie man diese Datenvisualisierungen interpretieren kann. Im Allgemeinen steht die Größe jedes Worts in der Wolke für seine Häufigkeit oder Wichtigkeit im Text. Je häufiger ein Wort im Text vorkommt, desto größer wird es in der Wortwolke angezeigt.
Bei der Interpretation von Wortwolken gibt es einige Dinge zu beachten:
Insgesamt kann eine Wortwolke ein nützliches Instrument sein, um die wichtigsten Themen und Ideen in einem Text schnell zu visualisieren. Es ist jedoch wichtig zu bedenken, dass es nur ein Werkzeug unter vielen für die Analyse von Textdaten ist und in Verbindung mit anderen Methoden für eine tiefere Analyse und ein besseres Verständnis verwendet werden sollte.
Du hast es geschafft! Du hast verschiedene Möglichkeiten kennengelernt, wie du mit der WordCloud-Bibliothek eine Wortwolke in Python zeichnen kannst, die für die Visualisierung einer Textanalyse hilfreich ist. Du lernst auch, wie du die Wolke in jede beliebige Form maskieren kannst, indem du eine Farbe deiner Wahl verwendest. Wenn du deine Fähigkeiten üben willst, solltest du das Projekt des DataCamps in Betracht ziehen: Die heißesten Themen im maschinellen Lernen
Wenn du mehr über die Verarbeitung natürlicher Sprache erfahren möchtest, besuche unseren Kurs Grundlagen der natürlichen Sprachverarbeitung in Python.
Python-Kurse
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach