
Kursus
Extreme Gradient Boosting dengan XGBoost
4 Hr
61.1K
Python adalah salah satu bahasa pemrograman paling populer yang digunakan di berbagai disiplin teknologi, terutama dalam data science dan machine learning. Python menawarkan bahasa tingkat tinggi yang berorientasi objek dan mudah dikodekan, dengan koleksi library yang luas untuk beragam use case. Ada lebih dari 200.000 library.
Salah satu alasan Python sangat berharga bagi data science adalah koleksinya yang sangat banyak untuk manipulasi data, visualisasi data, machine learning, dan deep learning. Karena ekosistem library data science Python begitu kaya, hampir tidak mungkin membahas semuanya dalam satu artikel. Daftar library teratas di sini berfokus hanya pada lima area utama:
Masih banyak area lain yang tidak tercakup dalam daftar ini; misalnya, MLOps, Big Data, dan Computer Vision. Daftar dalam blog ini tidak mengikuti urutan tertentu dan tidak dimaksudkan sebagai peringkat dalam bentuk apa pun.
NumPy adalah salah satu library Python open-source yang paling banyak digunakan dan terutama dipakai untuk komputasi ilmiah. Fungsi matematis bawaan memungkinkan komputasi super cepat dan dapat mendukung data multidimensi dan matriks besar. NumPy juga digunakan dalam aljabar linear. Array NumPy sering lebih dipilih daripada list karena menggunakan lebih sedikit memori serta lebih praktis dan efisien.
Menurut situs NumPy, ini adalah proyek open-source yang bertujuan memampukan komputasi numerik dengan Python. Dibuat pada 2005 dan dibangun dari hasil kerja awal library Numeric dan Numarray. Salah satu keunggulan besar NumPy adalah dirilis di bawah lisensi BSD yang dimodifikasi, sehingga akan selalu gratis untuk semua orang.
NumPy dikembangkan secara terbuka di GitHub dengan konsensus komunitas NumPy dan komunitas Python ilmiah yang lebih luas. Anda dapat mempelajarinya lebih lanjut dalam kursus pengantar Numpy kami.
⭐ Bintang GitHub: 25K | Total Unduhan: 2,4 miliar
Pandas adalah library open-source yang umum digunakan dalam data science. Utamanya dipakai untuk analisis data, manipulasi data, dan pembersihan data. Pandas memungkinkan pemodelan data dan operasi analisis data secara sederhana tanpa perlu menulis banyak kode. Seperti tertulis di situs mereka, pandas adalah alat analisis dan manipulasi data open-source yang cepat, andal, fleksibel, dan mudah digunakan. Beberapa fitur kunci library ini meliputi:
Memulai dengan pandas itu mudah dan lugas. Anda dapat melihat Analyzing Police Activity with pandas dari DataCamp untuk mempelajari cara menggunakan pandas pada set data dunia nyata.
⭐ Bintang GitHub: 41K | Total Unduhan: 1,6 miliar
Sementara Pandas tetap menjadi default untuk data kecil, Polars telah menjadi standar untuk pemrosesan data berkinerja tinggi. Ditulis dalam Rust, ia menggunakan mesin "lazy evaluation" untuk memproses dataset (10GB–100GB+) yang biasanya akan crash pada mesin dengan keterbatasan RAM. Berbeda dengan Pandas yang mengeksekusi operasi secara berurutan, Polars mengoptimalkan kueri dari ujung ke ujung dan menjalankannya secara paralel di semua inti CPU yang tersedia.
Dirancang sebagai peningkatan drop-in untuk beban kerja berat, Polars menawarkan sintaks yang sering kali lebih mudah dibaca dan 10–50x lebih cepat daripada DataFrame tradisional.
Berikut contoh kode untuk memuat seleksi yang difilter, dikelompokkan, dan diagregasi dari dataset CSV raksasa:
import polars as pl
# Lazy evaluation: Nothing runs until .collect() is called
# allowing Polars to optimize the query plan beforehand
q = (
pl.scan_csv("massive_dataset.csv")
.filter(pl.col("category") == "Technology")
.group_by("region")
.agg(pl.col("sales").sum())
)
df = q.collect() # Executes in parallel⭐ Bintang GitHub: 40K+ | Status: Standar Kinerja Tinggi
Matplotlib adalah library luas untuk membuat visualisasi Python statis, interaktif, dan animasi. Banyak paket pihak ketiga memperluas dan membangun fungsi Matplotlib, termasuk beberapa antarmuka plotting tingkat lebih tinggi (Seaborn, HoloViews, ggplot, dll.)
Matplotlib dirancang agar fungsional seperti MATLAB, dengan manfaat tambahan dapat menggunakan Python. Ia juga memiliki keunggulan gratis dan open source. Pengguna dapat memvisualisasikan data dengan beragam jenis plot, termasuk namun tidak terbatas pada scatterplot, histogram, bagan batang, bagan galat, dan boxplot. Selain itu, semua visualisasi dapat diimplementasikan hanya dengan beberapa baris kode.
Contoh Plot yang Dikembangkan menggunakan Matplotlib
Mulai di Matplotlib dengan tutorial langkah demi langkah ini.
⭐ Bintang GitHub: 18,7K | Total Unduhan: 653 juta
Satu lagi kerangka kerja visualisasi data Python berbasis Matplotlib yang populer, Seaborn adalah antarmuka tingkat tinggi untuk membuat visual statistik yang menarik dan bermanfaat, yang penting untuk mempelajari dan memahami data. Library Python ini sangat terkait dengan struktur data NumPy dan pandas. Prinsip pendorong di balik Seaborn adalah menjadikan visualisasi sebagai komponen esensial dari analisis dan eksplorasi data; karenanya, algoritma plotting-nya menggunakan data frame yang mencakup seluruh dataset.
Galeri Contoh Seaborn
Tutorial Seaborn untuk pemula ini adalah sumber yang bagus untuk membantu Anda mengenal library visualisasi yang dinamis ini.
⭐ Bintang GitHub: 11,6K | Total Unduhan: 180 juta
Library grafik open-source Plotly yang sangat populer dapat digunakan untuk membuat visualisasi data interaktif. Plotly dibangun di atas library JavaScript Plotly (plotly.js) dan dapat digunakan untuk membuat visualisasi data berbasis web yang dapat disimpan sebagai file HTML atau ditampilkan di Jupyter notebook dan aplikasi web menggunakan Dash.
Ia menyediakan lebih dari 40 jenis bagan unik, seperti scatter plot, histogram, line chart, bar chart, pie chart, error bar, box plot, sumbu ganda, sparklines, dendrogram, dan bagan 3D. Plotly juga menawarkan contour plot, yang tidak umum di library visualisasi data lainnya.
Jika Anda menginginkan visualisasi interaktif atau grafik mirip dasbor, Plotly adalah alternatif yang baik untuk Matplotlib dan Seaborn. Saat ini tersedia di bawah lisensi MIT.
Anda dapat mulai menguasai Plotly hari ini dengan kursus visualisasi Plotly ini.
⭐ Bintang GitHub: 14,7K | Total Unduhan: 190 juta
Istilah machine learning dan scikit-learn tak terpisahkan. Scikit-learn adalah salah satu library machine learning paling banyak digunakan di Python. Dibangun di atas NumPy, SciPy, dan Matplotlib, ini adalah library Python open-source yang dapat digunakan secara komersial di bawah lisensi BSD. Ini adalah alat yang sederhana dan efisien untuk tugas analisis data prediktif.
Awalnya diluncurkan pada 2007 sebagai proyek Google Summer of Code, Scikit-learn adalah proyek yang digerakkan komunitas; meskipun demikian, hibah institusi dan swasta membantu memastikan keberlanjutannya.
Hal terbaik dari scikit-learn adalah sangat mudah digunakan.
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# Use only one feature
diabetes_X = diabetes_X[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)Kredit: Kode direproduksi dari dokumentasi resmi scikit-learn.
Anda dapat mencoba scikit-learn sendiri dengan tutorial scikit-learn untuk pemula ini.
⭐ Bintang GitHub: 57K | Total Unduhan: 703 juta
Masa ketika Data Scientist hanya menyerahkan laporan PDF statis sudah berlalu. Streamlit mengubah skrip Python menjadi aplikasi web interaktif yang dapat dibagikan dalam hitungan menit. Tidak memerlukan pengetahuan HTML, CSS, atau JavaScript. Secara luas digunakan pada 2025 untuk membangun alat internal, prototipe dasbor, dan demo model interaktif bagi pemangku kepentingan.
Dengan pemanggilan API sederhana seperti st.write() dan st.slider(), Anda dapat membangun frontend yang bereaksi terhadap perubahan data secara real-time, menjembatani kesenjangan antara analisis dan rekayasa.
⭐ Bintang GitHub: 42K+ | Status: Esensial untuk Delivery
Awalnya alat pengembangan web, Pydantic kini menjadi landasan tumpuan tumpukan AI. Ia melakukan validasi data dan manajemen pengaturan menggunakan anotasi tipe Python. Di era LLM, memastikan bahwa data (dan keluaran model) secara ketat cocok dengan skema tertentu adalah hal yang kritis.
Pydantic menjadi mesin yang mendayai library seperti LangChain dan Hugging Face, memastikan keluaran JSON yang berantakan dari model AI dipaksa menjadi objek Python terstruktur dan valid yang tidak akan merusak kode hilir Anda.
⭐ Bintang GitHub: 26K+ | Status: Infrastruktur Kritis
LightGBM adalah library gradient boosting open-source yang sangat populer yang menggunakan algoritme berbasis pohon. Ia menawarkan keunggulan berikut:
Dapat digunakan untuk tugas klasifikasi dan regresi terawasi. Anda dapat melihat dokumentasi resmi atau GitHub mereka untuk mempelajari lebih lanjut tentang framework hebat ini.
⭐ Bintang GitHub: 15,8K | Total Unduhan: 162 juta
XGBoost adalah library gradient boosting terdistribusi lain yang banyak digunakan, dibuat agar portabel, fleksibel, dan efisien. Ia memungkinkan implementasi algoritme machine learning dalam kerangka kerja gradient boosting. XGBoost menawarkan (GBDT) gradient boosted decision tree, boosting pohon paralel yang memberikan solusi untuk banyak masalah data science secara cepat dan akurat. Kode yang sama berjalan di lingkungan terdistribusi utama (Hadoop, SGE, MPI) dan dapat menyelesaikan banyak sekali masalah.
XGBoost memperoleh popularitas besar dalam beberapa tahun terakhir karena membantu individu dan tim memenangkan hampir setiap kompetisi data terstruktur Kaggle. Keunggulan XGBoost meliputi:
XGBoost dikembangkan dan dipelihara oleh anggota komunitas yang aktif dan dilisensikan di bawah lisensi Apache. Tutorial XGBoost ini adalah sumber yang bagus jika Anda ingin belajar lebih lanjut.
⭐ Bintang GitHub: 25,2K | Total Unduhan: 179 juta
Catboost adalah library gradient boosting pada decision tree yang cepat, dapat diskalakan, dan berkinerja tinggi, digunakan untuk ranking, klasifikasi, regresi, dan tugas machine learning lainnya untuk Python, R, Java, dan C++. Mendukung komputasi pada CPU dan GPU.
Sebagai penerus algoritme MatrixNet, ia banyak digunakan untuk tugas pemeringkatan, peramalan, dan pemberian rekomendasi. Berkat sifatnya yang universal, dapat diterapkan di berbagai bidang dan untuk beragam masalah.
Keunggulan CatBoost menurut repositori mereka adalah:
⭐ Bintang GitHub: 7,5K | Total Unduhan: 53 juta
Statsmodels menyediakan kelas dan fungsi yang memungkinkan pengguna memperkirakan berbagai model statistik, melakukan uji statistik, dan eksplorasi data statistik. Daftar statistik hasil yang komprehensif kemudian diberikan untuk setiap estimator. Akurasi hasil kemudian dapat diuji terhadap paket statistik yang sudah ada.
Hasil sebagian besar pengujian di library ini telah diverifikasi dengan setidaknya satu paket statistik lain: R, Stata, atau SAS. Beberapa fitur statsmodels adalah:
Kursus statsmodels untuk pemula ini adalah tempat yang sangat baik untuk mulai jika Anda ingin belajar lebih lanjut.
⭐ Bintang GitHub: 9,2K | Total Unduhan: 161 juta
Suit library perangkat lunak open-source RAPIDS mengeksekusi pipeline data science dan analitik dari ujung ke ujung sepenuhnya di GPU. Ia diskalakan mulus dari workstation GPU ke server multi-GPU dan klaster multi-node dengan Dask. Proyek ini didukung oleh NVIDIA dan juga bergantung pada Numba, Apache Arrow, dan banyak proyek open-source lainnya.
cuDF adalah library DataFrame GPU yang digunakan untuk memuat, menggabungkan, mengagregasi, memfilter, dan memanipulasi data. Dikembangkan berdasarkan format memori kolumnar yang ditemukan di Apache Arrow. Ia menyediakan API mirip pandas yang akan familier bagi data engineer & data scientist, sehingga mereka dapat dengan mudah mempercepat alur kerja tanpa masuk ke detail pemrograman CUDA.
cuML adalah rangkaian library yang mengimplementasikan algoritme machine learning dan fungsi primitif matematika yang memiliki API kompatibel dengan proyek RAPIDS lainnya. Ini memungkinkan data scientist, peneliti, dan software engineer menjalankan tugas ML tabular tradisional di GPU tanpa masuk ke detail pemrograman CUDA. API Python cuML biasanya cocok dengan API scikit-learn.
Kerangka kerja open-source untuk optimasi hiperparameter ini digunakan terutama untuk mengotomatisasi pencarian hiperparameter. Ia menggunakan loop, kondisional, dan sintaks Python untuk secara otomatis mencari hiperparameter optimal dan dapat menjelajahi ruang besar serta memangkas percobaan yang kurang menjanjikan untuk hasil yang lebih cepat. Yang terbaik, ia mudah diparalelkan dan diskalakan pada dataset besar.
Fitur utama menurut repositori GitHub mereka:
⭐ Bintang GitHub: 9,1K | Total Unduhan: 18 juta
Library machine learning open-source yang sangat populer ini mengotomatisasi workflow machine learning di Python dengan sangat sedikit kode. Ini adalah alat end-to-end untuk manajemen model dan machine learning yang dapat mempercepat siklus eksperimen secara drastis.
Dibandingkan library machine learning open-source lainnya, PyCaret menawarkan solusi low-code yang dapat menggantikan ratusan baris kode hanya dengan beberapa baris. Hal ini membuat eksperimen menjadi sangat cepat dan efisien.
PyCaret saat ini tersedia di bawah lisensi MIT. Untuk mempelajari lebih lanjut tentang PyCaret, Anda dapat melihat dokumentasi resmi atau repositori GitHub mereka atau simak tutorial pengantar PyCaret ini.
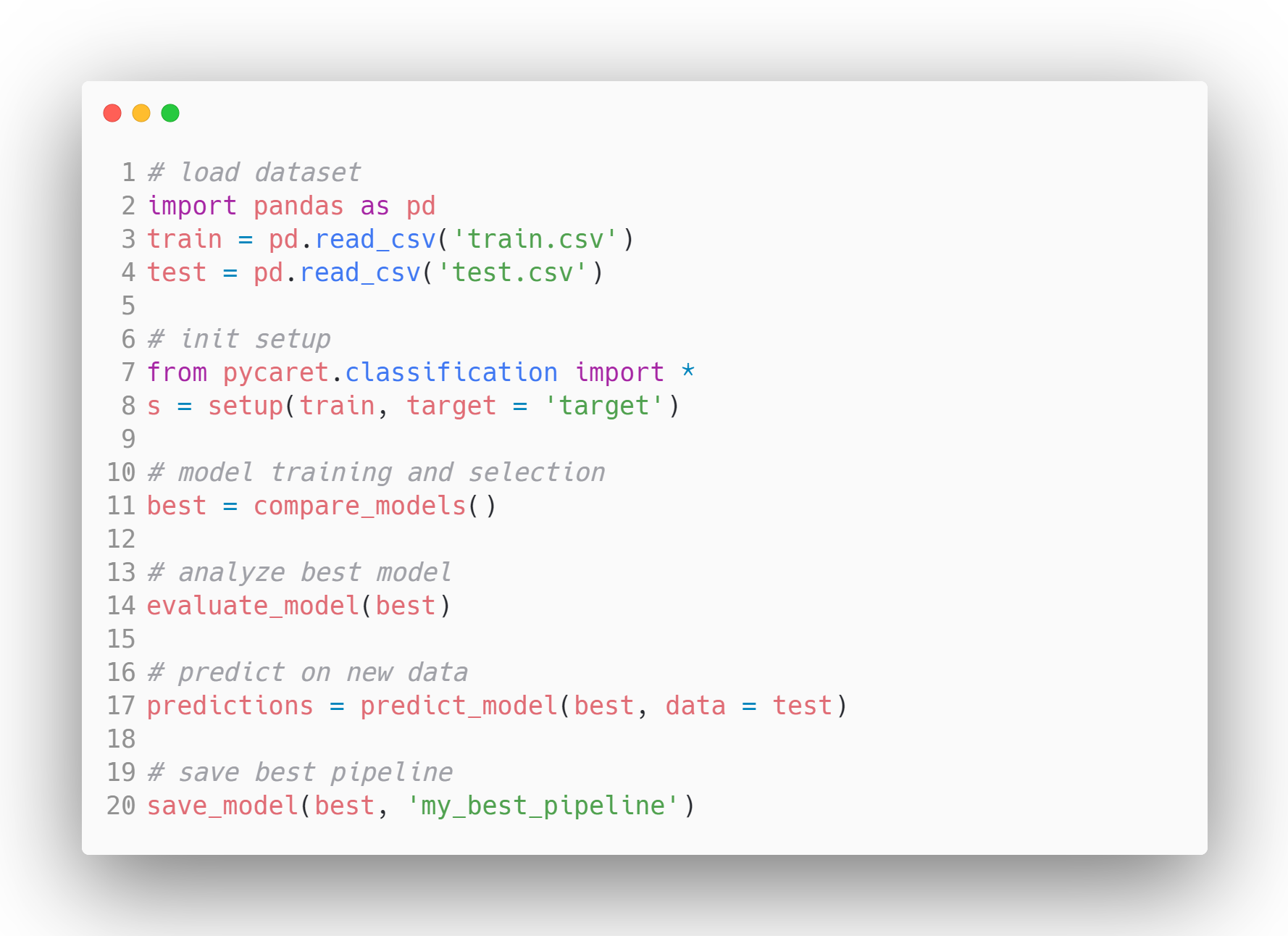
Contoh Alur Kerja Model di PyCaret - Sumber
⭐ Bintang GitHub: 8,1K | Total Unduhan: 3,9 juta
H2O adalah platform machine learning dan analitik prediktif yang memungkinkan pembangunan model machine learning pada big data. Ia juga menyediakan kemudahan produksi model-model tersebut di lingkungan enterprise.
Kode inti H2O ditulis dalam Java. Algoritmenya menggunakan kerangka kerja Java Fork/Join untuk multi-threading dan diimplementasikan di atas kerangka kerja Map/Reduce terdistribusi H2O.
H2O dilisensikan di bawah Apache License, Versi 2.0, dan tersedia untuk bahasa Python, R, dan Java. Untuk mempelajari lebih lanjut tentang H2O AutoML, lihat dokumentasi resmi mereka.
⭐ Bintang GitHub: 10,6K | Total Unduhan: 15,1 juta
Auto-sklearn adalah toolkit automated machine learning dan pengganti yang cocok untuk model scikit-learn. Ia melakukan penyetelan hiperparameter dan pemilihan algoritme secara otomatis, menghemat banyak waktu bagi praktisi machine learning. Desainnya mencerminkan kemajuan terbaru dalam meta-learning, konstruksi ensemble, dan optimisasi Bayesian.
Dibangun sebagai add-on untuk scikit-learn, auto-sklearn menggunakan prosedur pencarian Optimisasi Bayesian untuk mengidentifikasi pipeline model berkinerja terbaik untuk suatu dataset.
Auto-sklearn sangat mudah digunakan, dan dapat diterapkan untuk tugas klasifikasi dan regresi terawasi.
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)Sumber: Contoh direproduksi dari dokumentasi resmi auto-sklearn.
Untuk mempelajari lebih lanjut tentang auto-sklearn, lihat repositori GitHub mereka.
⭐ Bintang GitHub: 7,3K | Total Unduhan: 675K
FLAML adalah library Python yang ringan yang secara otomatis mengidentifikasi model machine learning yang akurat. Ia memilih learner dan hiperparameter secara otomatis, menghemat banyak waktu dan upaya praktisi machine learning. Menurut repositori GitHub mereka, beberapa fitur FLAML adalah:
Hanya dengan tiga baris kode, Anda dapat memperoleh estimator bergaya scikit-learn dengan mesin AutoML yang cepat ini.
from flaml import AutoML
automl = AutoML()
automl.fit(X_train, y_train, task="classification")Sumber: Contoh direproduksi dari repositori GitHub resmi
⭐ Bintang GitHub: 3,5K | Total Unduhan: 456K
Sementara library AutoML lain berfokus pada kecepatan, AutoGluon (dikembangkan oleh Amazon) berfokus pada ketangguhan dan akurasi terdepan. Ia terkenal dengan strategi "multi-layer stack ensembling" yang sering kali memungkinkannya mengungguli model yang disetel manusia pada benchmark data tabular.
Ia tidak hanya mendukung data tabular, tetapi juga masalah multimodal. Artinya, Anda dapat melatih satu predictor pada dataset yang berisi kolom teks, gambar, dan angka secara bersamaan tanpa rekayasa fitur yang kompleks.
Cuplikan kode berikut menunjukkan sintaks AutoGluon:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label='class').fit(train_data)
# AutoGluon automatically trains, tunes, and ensembles multiple models⭐ Bintang GitHub: 10K+ | Status: Akurasi Kelas Terbaik
TensorFlow adalah library open-source populer untuk komputasi numerik berkinerja tinggi yang dikembangkan oleh tim Google Brain di Google, dan menjadi andalan dalam riset deep learning.
Seperti disebutkan di situs resminya, TensorFlow adalah platform open-source end-to-end untuk machine learning. Ia menawarkan beragam alat, library, dan sumber daya komunitas yang luas dan serbaguna untuk peneliti dan pengembang machine learning.
Beberapa fitur TensorFlow yang membuatnya populer dan banyak digunakan sebagai library deep learning:
Untuk mempelajari lebih lanjut tentang TensorFlow, lihat panduan resmi atau repositori GitHub, atau coba sendiri dengan mengikuti tutorial TensorFlow langkah demi langkah ini.
⭐ Bintang GitHub: 180K | Total Unduhan: 384 juta
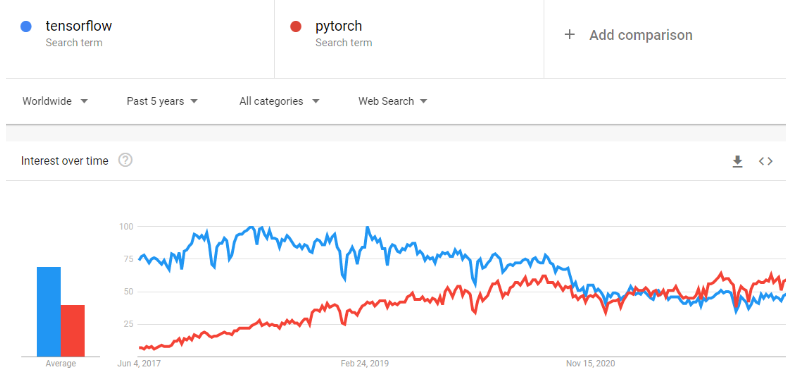
PyTorch adalah kerangka kerja machine learning yang secara drastis mempercepat perjalanan dari prototipe riset ke deployment produksi. Ini adalah library tensor yang dioptimalkan untuk deep learning menggunakan GPU dan CPU, dan dianggap sebagai alternatif untuk TensorFlow. Seiring waktu, popularitas PyTorch tumbuh melampaui TensorFlow di Google Trends.
Dikembangkan dan dipelihara oleh Facebook dan saat ini tersedia untuk digunakan di bawah BSD.
Menurut situs resmi, fitur kunci PyTorch adalah:
⭐ Bintang GitHub: 74K | Total Unduhan: 119 juta
FastAI adalah library deep learning yang menawarkan komponen tingkat tinggi untuk menghasilkan hasil mutakhir dengan mudah. Ia juga mencakup komponen tingkat rendah yang dapat ditukar untuk mengembangkan pendekatan baru. Tujuannya melakukan keduanya tanpa secara substansial mengorbankan kemudahan penggunaan, fleksibilitas, atau performa.
Fitur:
Untuk mempelajari lebih lanjut tentang proyek ini, lihat dokumentasi resmi mereka.
⭐ Bintang GitHub: 25,1K | Total Unduhan: 6,1 juta
Keras adalah API deep learning yang dirancang untuk manusia, bukan mesin. Keras mengikuti praktik terbaik untuk mengurangi beban kognitif: menawarkan API yang konsisten dan sederhana, meminimalkan jumlah tindakan pengguna yang diperlukan untuk use case umum, serta menyediakan pesan kesalahan yang jelas dan dapat ditindaklanjuti. Keras begitu intuitif hingga TensorFlow mengadopsi Keras sebagai API default pada rilis TF 2.0.
Keras menawarkan mekanisme yang lebih sederhana untuk mengekspresikan neural network dan juga memuat beberapa alat terbaik untuk mengembangkan model, pemrosesan dataset, visualisasi grafik, dan lainnya.
Fitur:
Untuk mempelajari lebih lanjut tentang Keras, lihat dokumentasi resmi atau ambil kursus pengantar ini: Deep Learning with Keras.
⭐ Bintang GitHub: 60,2K | Total Unduhan: 163 juta
PyTorch Lightning menawarkan antarmuka tingkat tinggi untuk PyTorch. Kerangka kerja yang ringan dan berkinerja tinggi ini dapat menata kode PyTorch untuk memisahkan riset dari rekayasa, membuat eksperimen deep learning lebih mudah dipahami dan direproduksi. Ia dikembangkan untuk membuat model deep learning yang dapat diskalakan dan berjalan mulus pada perangkat keras terdistribusi.
Menurut situs resmi, PyTorch Lightning dirancang agar Anda dapat menghabiskan lebih banyak waktu untuk riset dan lebih sedikit untuk rekayasa. Refactor cepat akan memungkinkan Anda untuk:
Untuk mempelajari lebih lanjut tentang library ini, lihat situs resminya.
⭐ Bintang GitHub: 25,6K | Total Unduhan: 18,2 juta
JAX adalah library komputasi numerik berkinerja tinggi yang dikembangkan oleh Google. Sementara PyTorch adalah standar ramah pengguna, JAX adalah "mobil Formula 1" yang digunakan para peneliti (termasuk DeepMind) yang membutuhkan kecepatan ekstrem. Ia memungkinkan kode NumPy dikompilasi secara otomatis untuk berjalan pada akselerator (GPU/TPU) melalui XLA (Accelerated Linear Algebra).
Kemampuannya melakukan diferensiasi otomatis pada fungsi Python native membuatnya digemari untuk mengembangkan algoritme baru dari nol, khususnya dalam pemodelan generatif dan simulasi fisika.
⭐ Bintang GitHub: 35K+ | Status: Standar Riset
spaCy adalah library pemrosesan bahasa alami open-source kelas industri di Python. spaCy unggul dalam tugas ekstraksi informasi skala besar. Ia ditulis dari nol dalam Cython dengan manajemen memori yang cermat. spaCy adalah library ideal jika aplikasi Anda perlu memproses dump web yang masif.
Fitur:
Untuk mempelajari lebih lanjut tentang spaCy, lihat situs resmi atau repositori GitHub-nya. Anda juga dapat cepat mengenal fungsionalitasnya menggunakan lembar contekan spaCY yang praktis ini.
⭐ Bintang GitHub: 28K | Total Unduhan: 81 juta
Hugging Face Transformers adalah library open-source dari Hugging Face. Transformers memungkinkan API untuk dengan mudah mengunduh dan melatih model pra-latih terdepan. Menggunakan model pra-latih dapat mengurangi biaya komputasi, jejak karbon, dan menghemat waktu Anda dari pelatihan model dari nol. Modelnya cocok untuk berbagai modalitas, termasuk:
Library transformers mendukung integrasi mulus antara tiga library deep learning paling populer: PyTorch, TensorFlow, dan JAX. Anda dapat melatih model dalam tiga baris kode pada satu kerangka kerja, dan memuatnya untuk inferensi dengan yang lain. Arsitektur setiap transformer didefinisikan dalam modul Python mandiri, sehingga mudah dikustomisasi untuk eksperimen dan riset.
Library ini saat ini tersedia untuk digunakan di bawah Apache License 2.0.
Untuk mempelajari lebih lanjut tentang transformers, lihat situs resmi mereka atau repositori GitHub dan simak tutorial kami tentang menggunakan Transformers dan Hugging Face.
⭐ Bintang GitHub: 119K | Total Unduhan: 62 juta
LangChain adalah kerangka orkestrasi standar industri untuk Large Language Model (LLM). Ini memungkinkan pengembang untuk "merantai" berbagai komponen, misalnya menghubungkan LLM (seperti GPT 5.2) ke sumber komputasi atau pengetahuan lainnya.
Ia mengabstraksi kompleksitas bekerja dengan prompt, memungkinkan Anda dengan mudah membangun "Agen" yang dapat menggunakan alat (seperti kalkulator, Google Search, atau Python REPL) untuk menyelesaikan masalah penalaran multi-langkah.
from langchain.chains import LLMChain
# Example: Creating a chain that takes user input and formats it
# before sending to an LLM
chain = prompt | llm | output_parser
result = chain.invoke({"topic": "Data Science"})⭐ Bintang GitHub: 123K+ | Status: Esensial GenAI
Sementara LangChain menangani penalaran, LlamaIndex menangani data. Ini adalah kerangka kerja terdepan untuk RAG (Retrieval-Augmented Generation). Ia mengkhususkan diri dalam mengimpor, mengindeks, dan mengambil data privat Anda (PDF, basis data SQL, lembar Excel) agar LLM dapat menjawab pertanyaan tentangnya secara akurat.
Pada 2025, "mengobrol dengan dokumen Anda" adalah kebutuhan standar bisnis, dan LlamaIndex menyediakan struktur data yang dioptimalkan untuk membuatnya efisien dan bebas halusinasi.
⭐ Bintang GitHub: 35K+ | Status: Standar RAG
Untuk membuat LLM "mengingat" informasi, Anda memerlukan Basis Data Vektor. ChromaDB adalah basis data vektor open-source, AI-native yang telah menjadi default bagi pengembang Python. Ia menangani kompleksitas embedding teks (mengonversi kata menjadi daftar angka) dan menyimpannya untuk pencarian semantik.
Berbeda dengan basis data SQL tradisional yang mencocokkan kata kunci persis, ChromaDB memungkinkan Anda melakukan kueri berdasarkan makna, menjadikannya memori jangka panjang untuk backend aplikasi AI modern.
⭐ Bintang GitHub: 25K+ | Status: Standar Vector Store
Memilih library Python yang tepat untuk tugas data science, machine learning, atau pemrosesan bahasa alami adalah keputusan krusial yang dapat berdampak signifikan pada keberhasilan proyek Anda. Dengan banyaknya library yang tersedia, penting untuk mempertimbangkan berbagai faktor agar dapat membuat pilihan yang tepat. Berikut pertimbangan kunci sebagai panduan Anda:
Dengan mengevaluasi faktor-faktor ini secara cermat, Anda dapat membuat keputusan yang tepat saat memilih library Python untuk upaya data science atau machine learning Anda. Ingat bahwa library terbaik bagi proyek Anda bergantung pada kebutuhan spesifik dan tujuan yang ingin Anda capai.
Untuk memulai karier Anda di data science, ikuti jalur karier Data Scientist in Python.
Kursus untuk Library Python di DataCamp
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
