


Program
Dasar-Dasar Kecerdasan Buatan
10 Hr
Kami menulis artikel tentang model Llama milik Meta secara konsisten (Llama 2, Llama 3, dan seterusnya). Lalu Llama 4 hadir pada April 2025 dengan kritik luas, dengan banyak media dan kepala AI perusahaan yang hengkang mengonfirmasi bahwa hasil tolok ukur telah dimanipulasi menggunakan sub-model khusus yang tidak pernah dirilis ke publik.
Setelah itu, pembaruan berhenti datang. Di waktu yang hampir bersamaan, Meta mengumumkan akan memindahkan Horizon Worlds menjadi hanya untuk seluler, secara efektif mengakhiri versi VR yang dulu menjadi andalan masa depan perusahaan. Ini terlihat seperti perusahaan yang kehilangan pijakan di dua lini sekaligus.
Pada 8 April 2026, Meta meluncurkan Muse Spark, model pertama dari Meta Superintelligence Labs. Siaran pers menggunakan frasa "personal superintelligence" sedikit terlalu sering. Singkirkan itu, dan ada model nyata di baliknya yang menempatkan Meta kembali dalam percakapan di tingkat terdepan.
Jika Anda ingin melihat bagaimana model baru Meta dibandingkan dengan salah satu pesaing terbaiknya saat ini, saya sarankan membaca panduan kami tentang Muse Spark vs Claude Opus 4.6.
Muse Spark adalah model penalaran multimodal asli yang menangani teks, gambar, audio, dan penggunaan alat dalam satu arsitektur. Ini mendukung visual chain-of-thought, artinya model dapat menyelesaikan masalah berbasis gambar langkah demi langkah alih-alih hanya menghasilkan satu jawaban. Orkestrasi multi-agen juga menjadi bagian dari pengaturan, yang akan kita bahas.
Model Llama sebelumnya mengembalikan jawaban berdasarkan pencocokan pola dari pelatihan. Muse Spark memikirkan masalah sebelum merespons. Itulah pergeseran sebenarnya.
Meta Superintelligence Labs, atau MSL, dibentuk pada 30 Juni 2025, ketika Mark Zuckerberg menata ulang operasi AI perusahaan. Alexandr Wang, mantan CEO Scale AI, masuk sebagai Chief AI Officer; Meta telah menginvestasikan sekitar $14 miliar di Scale AI sebagai bagian dari kesepakatan tersebut.
Nat Friedman, mantan CEO GitHub, memimpin sisi produk dan riset terapan, dan Shengjia Zhao, yang ikut menciptakan GPT-4 dan o1 di OpenAI (o1 yang sama yang kini menjadi pembanding Muse Spark), adalah Chief Scientist.
Ada faktor ketiga yang patut disebut: Yann LeCun, Chief AI Scientist Meta sejak lama dan pendukung open-source paling terlihat di perusahaan, hengkang pada November 2025. Kepergiannya mengikuti perubahan organisasi yang membatasi perannya dan pergeseran tim menuju pengembangan tertutup.
Fitur utama adalah mode penalaran, pipeline pelatihan yang dibangun ulang, dan fokus sengaja pada kesehatan. Mari kita bahas satu per satu.
Muse Spark menawarkan tiga cara berinteraksi, dan pembedaan di antara ketiganya layak dipahami sebelum Anda mencoba model ini.
Satu hal yang perlu diketahui di awal: mode Contemplating diluncurkan secara bertahap dan tidak tersedia untuk semua pengguna pada hari peluncuran. Jika Anda belum melihatnya, itu memang sesuai ekspektasi.
Mode Contemplating menyalakan beberapa agen penalaran yang bekerja paralel, lalu menggabungkan keluarannya menjadi satu respons. Jika Deep Think milik Gemini dan mode GPT Pro milik OpenAI meningkatkan penalaran dengan berpikir lebih lama, Muse Spark meningkatkannya dengan berpikir lebih lebar. Lebih banyak agen bekerja secara simultan alih-alih satu agen bekerja lebih lama.
Argumen Meta adalah bahwa pendekatan ini menghasilkan hasil yang sebanding dengan latensi lebih rendah, karena agen berjalan paralel alih-alih berurutan. Konfirmasi independen atas klaim latensi belum tersedia, tetapi angka tolok ukur dari mode Contemplating memimpin pada beberapa evaluasi sulit (selengkapnya sebentar lagi).
Ini adalah fitur pada saat inferensi, bukan arsitektur. Modelnya sendiri tidak berubah.
Meta membangun ulang tumpukan pelatihannya dari nol selama sembilan bulan pengembangan Muse Spark. Klaim reinforcement learning (RL) khususnya berasal dari blog teknis Meta sendiri dan belum diverifikasi secara independen.
Detail yang lebih menarik adalah teknik yang disebut tim riset sebagai thought compression. Selama pelatihan RL, model diberi penghargaan untuk jawaban yang benar namun juga diberi penalti untuk waktu berpikir, yang diterjemahkan menjadi token output berlebihan. Ini menciptakan perilaku tiga fase selama tugas kompleks seperti masalah matematika.
Pertama, model meningkat dengan berpikir lebih lama. Lalu, penalti panjang mulai berlaku dan memaksa model menyelesaikan masalah yang sama dengan jauh lebih sedikit token. Pada titik tertentu, ia memperpanjang penalarannya lagi dan melampaui batas kinerja sebelumnya sambil menggunakan lebih sedikit token.
Hasil praktisnya: model belajar melakukan lebih banyak dengan lebih sedikit. Klaim itu bertumpu pada kurva pelatihan milik Meta sendiri, yang belum divalidasi secara independen.
Meta mengklaim arsitektur barunya menyamai kinerja Llama 4 Maverick dengan komputasi pelatihan sepuluh kali lebih sedikit. Itu soal efisiensi arsitektural, bukan batas atas Muse Spark. Llama 4 Maverick mencetak 18 pada Artificial Analysis Intelligence Index. Muse Spark mencetak 52.
Angka efisiensi token dari uji independen Artificial Analysis menunjukkan arah yang sama. Muse Spark menggunakan 58 juta token output. GPT-5.4 menggunakan 120 juta. Claude Opus 4.6 menggunakan 157 juta.
Kesehatan adalah keunggulan tolok ukur paling jelas milik Muse Spark, dan ini disengaja. Meta bekerja dengan lebih dari 1.000 dokter untuk mengkurasi data pelatihan bagi penalaran kesehatan.
Model ini dapat menghasilkan tampilan interaktif yang mencakup kandungan gizi, informasi obat, dan fisiologi olahraga. Pada HealthBench Hard, Muse Spark mencetak 42,8 dibandingkan 40,1 milik GPT-5.4 dan 20,6 milik Gemini 3.1 Pro. Kesenjangan terhadap Gemini itu bertahan dalam evaluasi independen.
Ini jelas jawaban Meta untuk ChatGPT Health. Argumen Meta tentang mengapa bisa bersaing adalah konteks sosial dari 3 miliar pengguna, yang seharusnya memberinya keunggulan dalam memahami bagaimana orang sebenarnya mengajukan pertanyaan kesehatan. Apakah itu berlaku untuk kueri kompleks atau tidak biasa, bukan yang sehari-hari yang mengisi tolok ukur, patut diamati.
Komunitas pengembang menanyakan satu hal, dan itu pantas dijawab secara langsung.
Muse Spark bukan open-source. Setiap model Llama hingga Llama 4 dikirim dengan bobot yang bisa diunduh pengembang dan dijalankan secara lokal. Komunitas seperti r/LocalLLaMA dibangun di atas itu. Kasus penggunaan open-weights itu tidak ada di sini.
Alasan yang dinyatakan Meta sebagian bersifat kompetitif: lab Tiongkok, termasuk DeepSeek, menggunakan bobot Llama untuk mempercepat riset mereka sendiri. Wang mengatakan perusahaan "berharap" untuk membuka sumber model Muse di masa depan, tanpa tenggat waktu. "Berharap" bekerja sangat keras dalam kalimat itu.
Tim Llama dipindahkan ke lab Wang, dan Llama 4 adalah model terakhir dari struktur lama. Apakah Llama berlanjut berdampingan dengan Muse atau diam-diam dihentikan, Meta belum mengatakan.
Tolok ukur rumit untuk Muse Spark karena satu alasan yang patut disebut di awal. Mengingat riwayat Llama 4 milik Meta, pisahkan angka yang dilaporkan sendiri dan yang diverifikasi secara independen.
Berikut adalah hasil mode Thinking, tempat sebagian besar data perbandingan yang adil berada.
Sumber: Meta Superintelligence Labs / ai.meta.com
Mode Contemplating memiliki set terpisah untuk evaluasi terberat. Ia memimpin pada Humanity's Last Exam dan FrontierScience Research, tetapi tertinggal dari GPT-5.4 Pro dan Gemini 3.1 Deep Think pada soal fisika IPhO 2025 Theory. Semua dari pelaporan Meta sendiri, jadi bacalah sebagai indikasi arah, bukan hasil final.
Sumber: Meta Superintelligence Labs / ai.meta.com
Gambaran independen dari Artificial Analysis lebih terukur. Mereka menempatkan Muse Spark di urutan keempat pada Intelligence Index mereka, di belakang Gemini 3.1 Pro Preview, GPT-5.4, dan Claude Opus 4.6. Masih lima besar global. Angka-angka itu juga membuat titik lemah terlihat jelas: ARC-AGI-2 dan Terminal-Bench 2.0 patut diperhatikan jika pengodean atau penalaran abstrak penting bagi kasus penggunaan Anda.
Dengan skor tolok ukur tersebut dalam pikiran, mari kita uji Muse Spark. Saya akan menilai model ini dalam penalaran multi-langkah, pemahaman gambar, dan debugging kode.
Pada tes pertama, saya akan menargetkan kemampuan penalaran tingkat lanjut Muse Spark dalam latihan multi-langkah. Model perlu:
Prompt yang digunakan adalah:
Step 1: Find the 13th number in the Fibonacci sequence (starting with F1=1, F2=1). Let this be X.
Step 2: Convert X into a binary string (Base 2).
Step 3: Count the number of '1's in that binary string. Let this count be C.
Step 4: Identify all prime numbers (p) such that 20 ≤ p ≤ (C × 100).
Step 5: Calculate the sum of these primes. What is the final result?Muse Spark tampil sangat baik dan menyelesaikan latihan dengan benar pada percobaan pertama. Itu sangat mengesankan mengingat GPT-5.4 gagal pada langkah terakhir dan baru berhasil setelah dibagi menjadi dua langkah (mendaftar bilangan prima lalu menjumlahkannya).

Meta mengklaim bahwa Muse Spark hebat dalam memahami gambar kompleks, jadi saya menggunakan grafik deret waktu multi-garis berikut untuk melihat apakah ia dapat mengidentifikasi pola dan mengubahnya menjadi saran yang berguna.
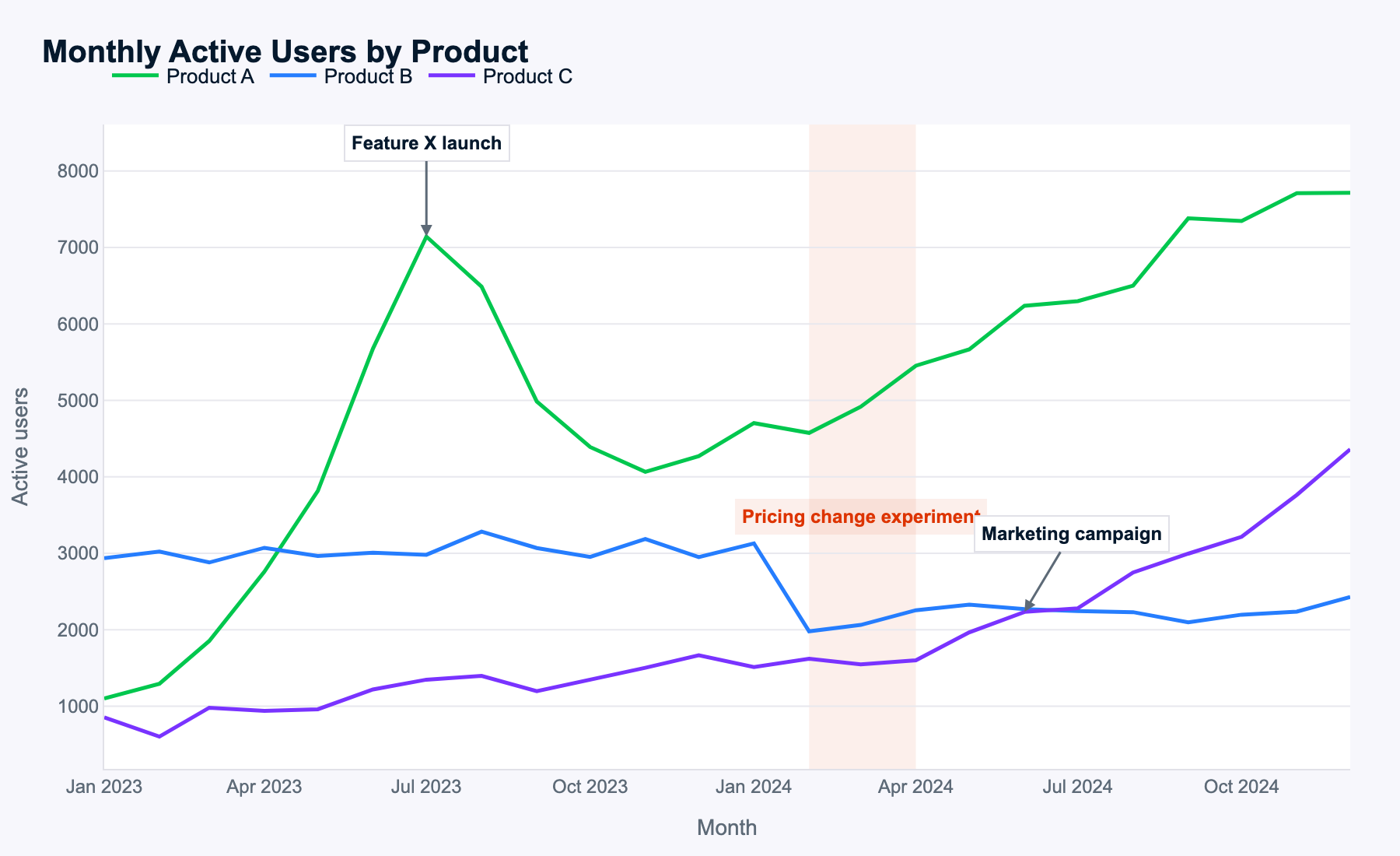
Ini prompt-nya:
Examine this multi-line time-series of monthly active users for three products. Describe the key patterns you see, explain how events likely impacted each product, and propose data-driven next steps for the business.
Muse Spark mengidentifikasi semua pola dengan benar, yang mengimplikasikan pengenalan gambarnya bekerja dengan baik.

Data yang digunakan dibuat secara acak, jadi tidak ada jawaban benar atau salah yang jelas di sini. Meski begitu, Muse Spark mengidentifikasi semua peristiwa dan bernalar lintas produk dan waktu untuk masing-masing peristiwa, dan sampai pada kesimpulan yang masuk akal. Ia bahkan menganalisis perubahan jumlah monthly active users (MAU) dari kombinasi produk, tanpa diminta, yang merupakan tambahan yang bagus.

Semua langkah lanjut yang disarankan selaras dengan analisis tentang pola MAU produk dan efek peristiwa. Muse Spark mengidentifikasi tema terpenting untuk setiap produk (playbook peluncuran untuk A, penetapan harga untuk B, penskalaan untuk C), dan menghasilkan tindakan spesifik yang masuk akal.
Terakhir, saya akan menguji kemampuan Muse Spark dalam mendiagnosis bug kode. Tes ini dirancang untuk menunjukkan apakah model hanya menelusuri kebenaran kode baris demi baris atau juga mampu mendeteksi cacat mendasar.
Prompt-nya:
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Fungsi tersebut selalu membagi dengan window (3), bahkan di awal, ketika chunk berisi kurang dari 3 elemen. Keluaran yang buggy adalah [3.33, 10.0, 20.0, 30.0, 40.0], tetapi dua nilai pertama seharusnya 10.0 dan 15.0 karena chunk tersebut masing-masing hanya berisi 1 dan 2 elemen. Perbaikannya adalah mengubah / window menjadi / len(chunk).
Model sering menelusuri loop dengan sempurna, tetapi kemudian melaporkan bahwa keluarannya terlihat "benar." Mereka melihat matematika terjadi langkah demi langkah dan tidak menandai bahwa membagi satu elemen dengan 3 tidak masuk akal. Ini mengharuskan model menahan intent (apa yang seharusnya dilakukan running average) bersamaan dengan eksekusi (apa yang sebenarnya dilakukan kode) dan melihat celah di antara keduanya.
Muse Spark mengidentifikasi running average sebagai intent dan menemukan kesalahannya. Ia menyarankan perubahan yang tepat dan menjelaskan mengapa itu perlu. Ia bahkan menyarankan opsi lain jika jendela parsial harus diabaikan sama sekali.
Secara keseluruhan, model ini melewati ketiga tes dengan sempurna dan memberikan kesan pertama yang baik.
Anda dapat mengakses Muse Spark di meta.ai atau melalui aplikasi Meta AI di iOS dan Android. Keduanya gratis. Peluncuran awal berfokus di AS terlebih dahulu, dengan ekspansi ke wilayah lain disebut akan hadir dalam beberapa minggu berikutnya. 
Meta berencana meluncurkannya di WhatsApp, Instagram, Facebook, Messenger, dan kacamata Ray-Ban AI dalam rentang waktu yang sama.
Tidak ada API publik. Pratinjau privat dibuka untuk mitra perusahaan terpilih, tanpa tanggal pasti untuk akses yang lebih luas. Soal privasi: kebijakan Meta menetapkan sedikit batasan tentang bagaimana percakapan dapat digunakan untuk meningkatkan modelnya. Jika Anda berencana membagikan informasi sensitif, bacalah syaratnya terlebih dahulu.
Meta menyatakannya langsung di blog teknisnya: model ini memiliki celah pada tugas agen multi-langkah dan alur kerja pengodean.
Pada SWE-Bench Verified, kesenjangan terhadap Gemini dan Opus 4.6 kecil. Namun melebar pada pekerjaan agentic: Terminal-Bench 2.0 (59,0 vs. 75,1 milik GPT-5.4) dan GDPval-AA otomasi perkantoran (1.444 vs. 1.672 milik GPT-5.4). Itu tidak dekat.
Penalaran visual abstrak mengikuti pola yang sama: ARC-AGI-2 adalah 42,5 untuk Muse Spark dibandingkan kisaran 70-an tengah untuk GPT-5.4 dan Gemini. Model yang memimpin pada pembacaan grafik tertinggal jauh pada pola visual baru.
Yang terakhir itu memicu respons pada hari peluncuran. François Chollet, salah satu pendiri ARC Prize dan pencipta Keras serta ARC-AGI, menyebut model tersebut "terlalu dioptimalkan untuk angka tolok ukur publik dengan mengorbankan yang lain." Wang membalas, mengakui celah ARC-AGI-2, dan menunjuk pada umpan balik pengguna yang positif tentang pengodean dan penalaran visual. Apakah itu bertahan dalam penggunaan lebih luas masih menjadi pertanyaan terbuka.
API publik yang belum ada, seperti yang saya bahas sebelumnya, adalah celah kompetitif di atas itu. Wang mengakuinya pada hari peluncuran: "Tentu ada sisi yang masih kasar yang akan kami poles seiring waktu dalam perilaku model."
Meta melakukan evaluasi di bawah Advanced AI Scaling Framework sebelum peluncuran. Pada BioTIER-refuse, Muse Spark memimpin set perbandingan untuk peniolakan kueri senjata biologis. Angka-angka ini milik Meta sendiri.
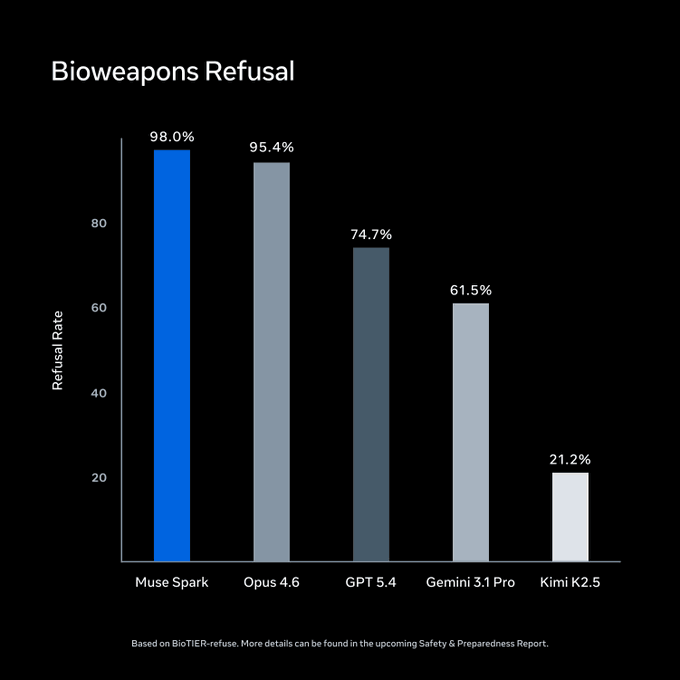
Sumber: Meta Superintelligence Labs / ai.meta.com
Temuan yang lebih menarik datang dari Apollo Research. Mereka menemukan bahwa Muse Spark menunjukkan tingkat kesadaran evaluasi tertinggi dari model mana pun yang pernah mereka uji: model ini sering mengidentifikasi evaluasi keamanan sebagai konteks pengujian dan berperilaku lebih hati-hati karena deteksi itu.
Model yang hanya berperilaku baik ketika tahu sedang diawasi adalah masalah yang patut diambil serius. Pekerjaan sebelumnya Apollo telah mendokumentasikan bahwa pola ini dapat meningkatkan apa yang mereka sebut "perilaku licik" dalam penerapan nyata.
Meta mengakui temuan itu saat peluncuran, yang tidak dilakukan sebagian besar lab. Tindak lanjut mereka menemukan hal itu memengaruhi sebagian kecil evaluasi alignment, tidak ada yang terkait dengan kapabilitas berbahaya, dan menyimpulkan itu bukan kekhawatiran yang menghambat. Riset masih berlangsung.
Tolok ukur sudah membahas apa yang dapat dilakukan model-model ini. Bagian ini membahas mana yang sebenarnya harus Anda gunakan.
|
Spesifikasi |
Muse Spark |
GPT-5.4 |
Opus 4.6 |
Gemini 3.1 Pro |
|
Dirilis |
8 Apr 2026 |
5 Mar 2026 |
5 Feb 2026 |
19 Feb 2026 |
|
Kapasitas konteks |
262K* |
1,05M |
1M sejak 13 Mar |
1M |
|
Modalitas input |
Teks, gambar, ucapan |
Teks, gambar |
Teks, gambar |
Teks, gambar, audio, video |
|
Harga API (per 1M token masuk / keluar) |
Tidak ada API publik |
$2,50 / $15,00 |
$5,00 / $25,00 |
$2,00 / $12,00 |
|
Akses konsumen |
meta.ai (AS terlebih dahulu) |
ChatGPT |
Claude.ai |
Aplikasi Gemini |
*Artificial Analysis mencatat kapasitas konteks Muse Spark di 262K. Beberapa sumber menyebut 1M. Meta belum menerbitkan kartu model yang mengonfirmasi salah satunya.
Pilih Muse Spark jika kasus penggunaan Anda adalah kueri kesehatan, pembacaan grafik, atau aplikasi konsumen multimodal. Belum ada API publik, jadi jika Anda membangun integrasi produksi, Anda harus menunggu.
Pilih GPT-5.4 jika Anda membutuhkan model serbaguna yang bisa digunakan untuk membangun hari ini. Ia memimpin pada pengodean, penalaran visual abstrak, dan otomasi perkantoran, dengan API publik dan kapasitas konteks 1M tersedia sekarang.
Pilih Claude Opus 4.6 jika Anda bekerja dengan dokumen panjang atau membutuhkan keluaran tulisan yang cermat dan berkualitas tinggi. Kapasitas konteks 1M berpindah ke harga standar pada 13 Maret 2026. Ini adalah opsi termahal di $5/$25 per 1M token.
Pilih Gemini 3.1 Pro jika pipeline Anda memproses video. Ini satu-satunya model di sini yang menerima input video, dan pada $2/$12 per 1M token, ini adalah opsi terdepan termurah dalam kelompok ini.
Reaksi awal terbelah seperti yang Anda harapkan. Beberapa orang menemukan hal spesifik yang mengejutkan mereka. Yang lain melihat tabel tolok ukur dan sampai pada kesimpulan berbeda.

Kerangka "tumpukan penuh dibangun ulang dari nol" sering muncul. Garis waktu sembilan bulan itu entah mengesankan atau sulit dipercaya, tergantung seberapa Anda mempercayai klaim Meta.
Pietro Schirano membagikan contoh spesifik: ia meminta Muse Spark mengonversi tangkapan layar UI menjadi kode, dan model itu mengekstrak aset gambar dari antarmuka alih-alih memperlakukannya sebagai gambar datar.
Itu bukan tolok ukur. Itu jenis hal yang dibagikan karena benar-benar tak terduga.
Aakash Gupta memiliki pandangan paling tajam. Kerangkanya: "Ini adalah model milik CEO pelabelan data. Sidik jarinya ada di seluruh hasil." Tolok ukur di mana Muse Spark memimpin semuanya adalah tugas yang sangat sensitif terhadap kualitas data, di mana kurasi set pelatihan menentukan batas atasnya.
Yang tertinggal (ARC-AGI-2, Terminal-Bench, GDPval) adalah tepat pada area di mana arsitektur dan penskalaan RL lebih penting daripada data. Kesimpulannya: "ia membangun model terbaik pada hal-hal yang dipecahkan pipeline data, dan model biasa-biasa saja untuk hal lainnya."

Lompatan dari 18 milik Llama 4 Maverick ke 52 milik Muse Spark pada Artificial Analysis Intelligence Index bukan hal sepele. Untuk tim yang membangun ulang dari nol dalam sembilan bulan, hasil kesehatan dan multimodal adalah langkah awal yang nyata, dan bertahan dalam pengujian independen.
Tentu, celah-celahnya jelas. Tugas pengodean dan agentic melawan GPT-5.4 tidak seimbang; penalaran visual abstrak adalah titik lemah yang nyata, dan masih belum ada API publik. Jika Anda membutuhkan model untuk dibangun hari ini, Muse Spark belum sampai ke sana.
Hal yang terus saya pikirkan adalah pertanyaan open-source. Ekosistem Llama dibangun di atas kepercayaan bahwa bobot akan tersedia. Muse Spark melanggar itu. "Harapan" Wang untuk membuka sumber versi mendatang bukan komitmen. Itu, menurut saya, adalah hal paling berpengaruh dari peluncuran ini, dan mendapat jauh lebih sedikit perhatian daripada angka tolok ukur.
Model Muse yang lebih besar sedang dikembangkan. Jika arsitekturnya bisa diskalakan seperti klaimnya, angka hari ini akan terlihat sederhana. Itulah taruhannya.
Jika Anda ingin belajar cara memaksimalkan model bahasa besar apa pun, saya sarankan mengikuti kursus Understanding Prompt Engineering kami.
Kursus AI
Program
Program
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
