


Program
AI Temelleri
10 sa
Meta’nın Llama modelleri hakkında düzenli bir tempoyla makaleler yazıyorduk (Llama 2, Llama 3 vb.). Ardından Llama 4 Nisan 2025’te sert eleştiriler eşliğinde geldi; birden çok yayın ve şirketin görevden ayrılan yapay zeka lideri, kıyaslama sonuçlarının, kamuya hiç sunulmayan özel alt modeller kullanılarak manipüle edildiğini doğruladı.
Bundan sonra güncellemeler gelmez oldu. Aynı dönemde Meta, Horizon Worlds’ü yalnızca mobilde sunacağını açıkladı ve bir zamanlar şirketin geleceğini bağladığı VR sürümünü fiilen sonlandırdı. İki cephede birden ayağı kayan bir şirket görüntüsü vardı.
8 Nisan 2026’da Meta, Meta Superintelligence Labs’ın ilk modeli olan Muse Spark’ı piyasaya sürdü. Basın bülteni “kişisel süper zekâ” ifadesini biraz fazla kullanıyor. Bunu bir kenara bırakırsanız, Meta’yı yeniden sınır düzeyindeki sohbetlere dahil eden gerçek bir model var altında.
Meta’nın yeni modelinin en güçlü mevcut rakiplerinden biriyle nasıl karşılaştırıldığını görmek istiyorsanız, Muse Spark vs Claude Opus 4.6 rehberimizi okumanızı öneririm.
Muse Spark, metin, görsel, ses ve araç kullanımını tek bir mimaride ele alan, yerel olarak çok modlu bir akıl yürütme modelidir. Görsel düşünce zincirini destekler; yani model yalnızca tek bir yanıt üretmek yerine görsel tabanlı problemleri adım adım çözebilir. Çoklu ajan orkestrasyonu da yapının bir parçası; buna birazdan geleceğiz.
Önceki Llama modelleri, eğitimden gelen örüntü eşleştirmesine dayalı yanıtlar döndürüyordu. Muse Spark ise yanıt vermeden önce problemi çalışıp çözüyor. Asıl değişim bu.
Meta Superintelligence Labs (MSL), Mark Zuckerberg’in şirketin yapay zeka operasyonlarını yeniden organize ettiği 30 Haziran 2025’te kuruldu. Scale AI’nin eski CEO’su Alexandr Wang, Chief AI Officer olarak göreve geldi; Meta, anlaşmanın bir parçası olarak Scale AI’ye yaklaşık 14 milyar dolar yatırım yapmıştı.
GitHub’ın eski CEO’su Nat Friedman, ürün ve uygulamalı araştırma tarafını yönetiyor; OpenAI’de GPT-4 ve o1’i birlikte geliştiren Shengjia Zhao (Muse Spark’ın şimdi kıyaslandığı aynı o1), Chief Scientist olarak görev yapıyor.
Burada anılmaya değer üçüncü bir unsur daha var: Meta’nın uzun süreli Chief AI Scientist’i ve şirketin en görünür açık kaynak savunucusu Yann LeCun, Kasım 2025’te ayrıldı. Ayrılışı, rolünü sınırlayan organizasyonel değişikliklerin ve ekibin kapalı kaynak geliştirmeye yönelmesinin ardından geldi.
Öne çıkan başlıklar: akıl yürütme kipleri, baştan kurulan eğitim hattı ve sağlığa bilinçli bir odak. Sırayla ele alalım.
Muse Spark ile etkileşime geçmenin üç yolu var ve modeli denemeden önce aralarındaki farkı anlamaya değer.
Baştan bilinmesi gereken bir şey: Contemplating kipi kademeli olarak sunuluyor ve lansman gününde tüm kullanıcılara açık değildi. Henüz görmüyorsanız bu beklenen bir durum.
Contemplating kipi, paralel çalışan birden fazla akıl yürütme ajanını devreye alır ve çıktıları tek bir yanıtta birleştirir. Gemini’nin Deep Think ve OpenAI’nin GPT Pro kipleri akıl yürütmeyi daha uzun düşünerek ölçeklendirirken, Muse Spark daha geniş düşünerek ölçeklendirir. Daha fazla ajan eşzamanlı çalışır; tek bir ajanın daha uzun süre çalışması yerine.
Meta’ya göre bu yaklaşım, ajanlar sıralı yerine paralel çalıştığı için daha düşük gecikmeyle karşılaştırılabilir sonuçlar üretir. Gecikme iddialarının bağımsız teyidi henüz yok, ancak Contemplating kipinden gelen kıyaslama sayıları birkaç zor değerlendirmede önde (birazdan ayrıntılar).
Bu, mimari değil, çıkarım zamanı özelliğidir. Modelin kendisi değişmez.
Meta, Muse Spark’ı geliştirmek için geçen dokuz ayda eğitim yığınını baştan kurdu. Özellikle pekiştirmeli öğrenme (RL) iddiaları Meta’nın kendi teknik blogundan geliyor ve bağımsız olarak doğrulanmış değil.
Daha ilginç ayrıntı, araştırma ekibinin düşünce sıkıştırma adını verdiği teknik. RL eğitimi sırasında model, doğru yanıtlara ödüllendirilirken düşünme süresi için, yani aşırı çıktı belirteçleri için cezalandırılıyor. Bu, matematik problemleri gibi karmaşık görevlerde üç aşamalı bir davranış yaratıyor.
Önce, model daha uzun düşünerek gelişiyor. Sonra uzunluk cezası devreye giriyor ve modeli aynı problemleri çok daha az belirteçle çözmeye zorluyor. Bir noktada, akıl yürütmesini yeniden uzatıyor ve daha az belirteç kullanırken önceki performans tavanlarını aşıyor.
Pratik sonuç: model daha azla daha fazlasını yapmayı öğrendi. Bu iddia, bağımsız olarak doğrulanmamış olan Meta’nın kendi eğitim eğrilerine dayanıyor.
Meta, yeni mimarisinin Llama 4 Maverick’in performansına on kat daha az eğitim hesaplamasıyla ulaştığını iddia ediyor. Bu, Muse Spark’ın tavanından değil, mimari verimlilikten söz eder. Llama 4 Maverick, Artificial Analysis Intelligence Index’te 18 aldı. Muse Spark 52 aldı.
Artificial Analysis’in bağımsız çalışmasından gelen belirteç verimliliği sayıları da aynı yöne işaret ediyor. Muse Spark 58 milyon çıktı belirteci kullandı. GPT-5.4 120 milyon kullandı. Claude Opus 4.6 157 milyon kullandı.
Sağlık, Muse Spark’ın en net kıyaslama üstünlüğü ve bu kasıtlı. Meta, sağlık akıl yürütmesi için eğitim verilerini derlemek üzere 1.000’den fazla hekimle çalıştı.
Model; besin içeriği, ilaç bilgileri ve egzersiz fizyolojisini kapsayan etkileşimli görünümler üretebiliyor. HealthBench Hard’da Muse Spark 42,8; GPT-5.4 40,1 ve Gemini 3.1 Pro 20,6 puan aldı. Gemini’ye karşı bu fark, bağımsız değerlendirmede de korunuyor.
Bu, Meta’nın ChatGPT Health’e yanıtı açıkça. Meta’nın neden rekabet edebileceğine dair argümanı, 3 milyar kullanıcının sosyal bağlamına sahip olması; bu da insanların sağlık sorularını gerçekte nasıl sorduğunu anlama konusunda avantaj sağlamalı. Bunun, kıyaslamaları dolduran günlük sorular yerine karmaşık veya alışılmadık sorgularda geçerli olup olmayacağı izlenmeye değer.
Geliştirici topluluğu tek bir şey soruyor ve bu doğrudan cevaplanmayı hak ediyor.
Muse Spark açık kaynak değil. Llama 4’e kadar her Llama modeli, geliştiricilerin indirip yerelde çalıştırabildiği ağırlıklarla yayınlandı. r/LocalLLaMA gibi topluluklar bunun üzerine inşa edildi. Bu kullanım senaryosu artık yok.
Meta’nın beyanına göre bunun sebeplerinden biri rekabetçi endişeler: DeepSeek dahil Çin laboratuvarları, kendi araştırmalarını hızlandırmak için Llama ağırlıklarını kullandılar. Wang, şirketin gelecekteki Muse modellerini açık kaynak yapmayı “umut ettiğini” söyledi; bir takvim yok. O cümlede “umut ediyoruz” çok iş görüyor.
Llama ekibi Wang’in laboratuvarına taşındı ve Llama 4 eski yapının son modeliydi. Llama’nın Muse ile birlikte sürüp sürmeyeceği ya da sessizce devreden çıkıp çıkmayacağı konusunda Meta bir şey söylemedi.
Muse Spark’ta kıyaslamalar, en baştan anılmayı hak eden bir nedenle zorlu. Meta’nın Llama 4 geçmişi göz önüne alındığında, kendi bildirdiği sayılarla bağımsız doğrulananları ayrı tutun.
İşte Thinking kipindeki sonuçlar; adil karşılaştırma verilerinin çoğu burada.
Kaynak: Meta Superintelligence Labs / ai.meta.com
Contemplating kipinin en zor değerlendirmeler için ayrı bir seti var. Humanity’s Last Exam ve FrontierScience Research’te önde, ancak IPhO 2025 Theory fizik problemlerinde GPT-5.4 Pro ve Gemini 3.1 Deep Think’in gerisinde kalıyor. Tümü Meta’nın kendi raporlarından; bu yüzden kesinleşmiş değil, yön gösterici olarak okuyun.
Kaynak: Meta Superintelligence Labs / ai.meta.com
Artificial Analysis’in bağımsız tablosu daha ölçülü. Muse Spark’ı Zekâ Endeksi’nde, Gemini 3.1 Pro Preview, GPT-5.4 ve Claude Opus 4.6’nın arkasında dördüncü sıraya koydular. Yine de küresel ilk beşte. Sayılar zayıf noktaları da net gösteriyor: kullanım senaryonuz için kodlama veya soyut akıl yürütme önemliyse ARC-AGI-2 ve Terminal-Bench 2.0’a dikkat edin.
Bu kıyas notlarını akılda tutarak Muse Spark’ı teste sokalım. Modeli çok adımlı akıl yürütme, görsel anlama ve kod hata ayıklamada inceleyeceğim.
İlk testimde, çok adımlı bir egzersizde Muse Spark’ın gelişmiş akıl yürütme yeteneklerini hedefleyeceğim. Modelin şunları yapması gerekiyor:
Kullandığım istem:
Step 1: Find the 13th number in the Fibonacci sequence (starting with F1=1, F2=1). Let this be X.
Step 2: Convert X into a binary string (Base 2).
Step 3: Count the number of '1's in that binary string. Let this count be C.
Step 4: Identify all prime numbers (p) such that 20 ≤ p ≤ (C × 100).
Step 5: Calculate the sum of these primes. What is the final result?Muse Spark oldukça iyi iş çıkardı ve egzersizi ilk denemede doğru çözdü. Bu, özellikle GPT-5.4’ün son adımda başarısız olup ancak iki adıma bölününce (asal sayıları listeleyip ardından toplama) başarılı olduğu düşünülürse etkileyici.

Meta, Muse Spark’ın karmaşık görselleri anlamada çok iyi olduğunu iddia ediyor; bu yüzden aşağıdaki çok çizgili zaman serisi grafiğini kullanarak desenleri saptayıp bunları işe yarar önerilere dönüştürebilip dönüştüremediğini görmek istiyorum.
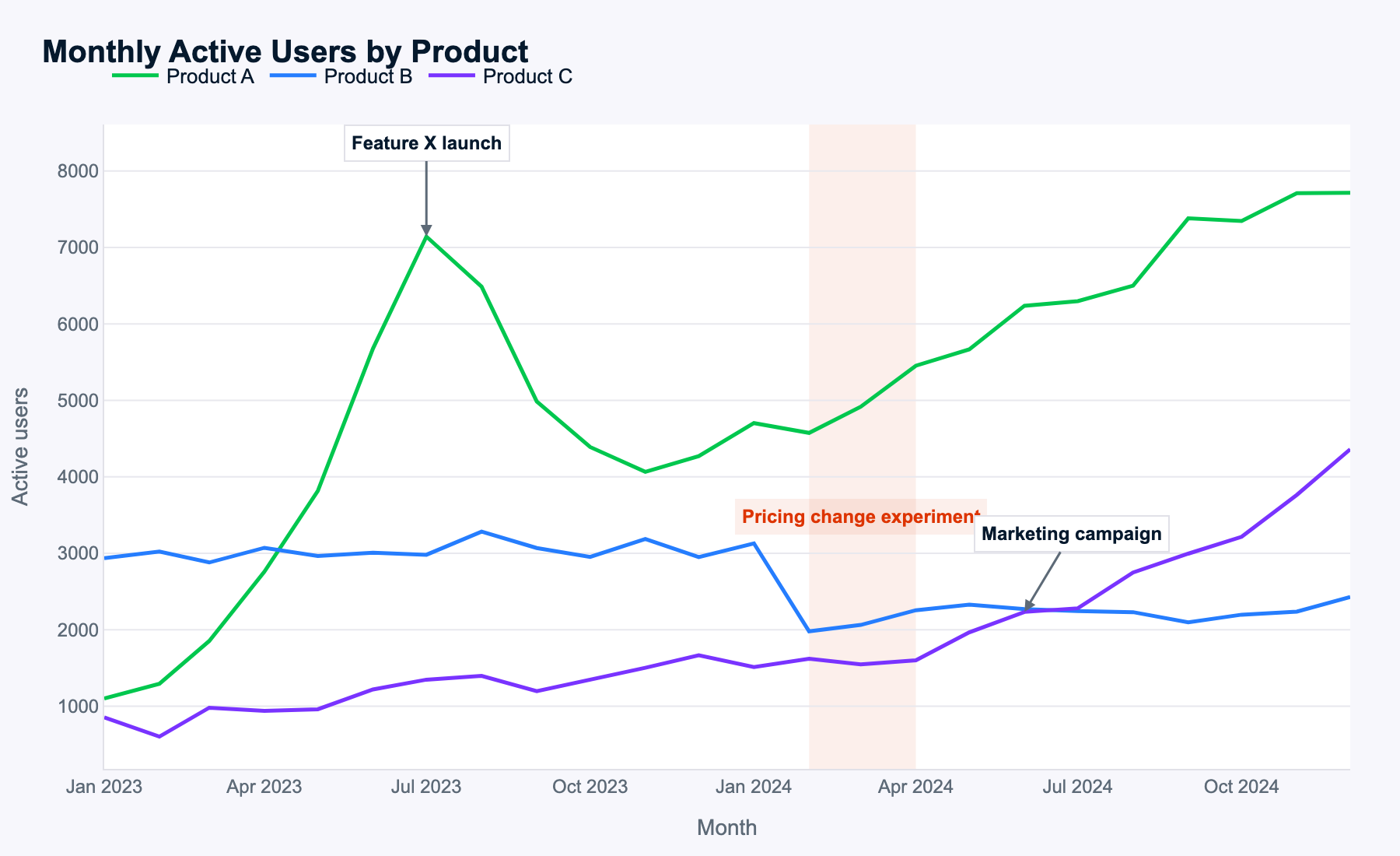
İstem şu:
Examine this multi-line time-series of monthly active users for three products. Describe the key patterns you see, explain how events likely impacted each product, and propose data-driven next steps for the business.
Muse Spark tüm desenleri doğru belirledi; bu da görüntü tanımanın iyi çalıştığına işaret ediyor.

Veriler rastgele uydurulduğundan burada net bir doğru-yanlış yok. Öyle olsa da Muse Spark tüm olayları saptıyor, her bir olay için farklı ürünler ve zamanlar arasında neden sonuç ilişkisi kuruyor ve makul sonuçlara varıyor. Hatta istenmeden, ürün kombinasyonlarının aylık aktif kullanıcı (MAU) toplamındaki değişimleri analiz etmesi de hoş bir ek.

Önerilen tüm sonraki adımlar, ürün MAU desenleri ve olay etkilerine dair analizlerle uyumlu. Muse Spark her ürün için en önemli temayı belirledi (A için lansman oyun kitabı, B için fiyatlandırma, C için ölçekleme) ve mantıklı somut eylemler üretti.
Son olarak, Muse Spark’ın kod hatalarını teşhis etme becerilerini test edeceğim. Test, modelin yalnızca satır satır doğruluğu izleyip izlemediğini mi, yoksa altta yatan kusurları da tespit edip edemediğini mi göstermeye yönelik.
İstem:
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Fonksiyon, window (3) değerine her zaman böler; başlangıçta, parça 3’ten az öğe içerdiğinde bile. Hatalı çıktı [3.33, 10.0, 20.0, 30.0, 40.0] şeklindedir; ancak ilk iki değer, ilgili parçalar sırasıyla yalnızca 1 ve 2 öğe içerdiğinden 10.0 ve 15.0 olmalıdır. Düzeltme, / window ifadesini / len(chunk) ile değiştirmektir.
Modeller genellikle döngüyü mükemmel şekilde izler ama sonra çıktının “doğru” göründüğünü rapor eder. Adım adım matematiği görürler ve tek bir öğeyi 3’e bölmenin mantıksız olduğunu işaretlemezler. Bu, modelin niyeti (kayan ortalamanın ne yapması gerektiği) icrayla (kodun gerçekte yaptığı) birlikte tutmasını ve aradaki farkı yakalamasını gerektirir.
Muse Spark, kayan ortalamayı niyet olarak tanımladı ve hatayı yakaladı. Doğru değişikliği önerdi ve neden gerekli olduğunu açıkladı. Kısmi pencerelerin tamamen atlanması gerekiyorsa alternatif bir seçenek de sundu.
Genel olarak model, üç testin hepsini kusursuz geçti ve iyi bir ilk izlenim bıraktı.
Muse Spark’a meta.ai üzerinden ya da iOS ve Android’deki Meta AI uygulamasıyla erişebilirsiniz. Her ikisi de ücretsiz. İlk sunum ABD ile başlıyor; diğer bölgelere genişleme, izleyen haftalarda geliyor deniyor. 
Meta, aynı zaman diliminde WhatsApp, Instagram, Facebook, Messenger ve Ray-Ban AI gözlüklerine de yaymayı planlıyor.
Genel kullanıma açık bir API yok. Seçilmiş kurumsal ortaklara özel bir önizleme açık; daha geniş erişim için teyitli bir tarih yok. Gizlilikle ilgili olarak: Meta’nın politikası, görüşmelerin modellerini geliştirmek için nasıl kullanılabileceği konusunda az sınırlama getiriyor. Hassas bilgiler paylaşmayı planlıyorsanız önce şartları okuyun.
Meta teknik blogunda bunu doğrudan söyledi: modelin çok adımlı ajan görevlerinde ve kodlama iş akışlarında boşlukları var.
SWE-Bench Verified’da, Gemini ve Opus 4.6’ya karşı fark küçük. Ajan işlerinde açılıyor: Terminal-Bench 2.0 (59,0; GPT-5.4’te 75,1) ve GDPval-AA ofis otomasyonu (1.444; GPT-5.4’te 1.672). Bunlar yakın değil.
Soyut görsel akıl yürütme de aynı deseni izliyor: ARC-AGI-2’de Muse Spark 42,5 iken GPT-5.4 ve Gemini her ikisi de 70’lerin ortasında. Grafikleri okumada önde olan model, yeni görsel desenlerde ciddi şekilde geride kalıyor.
Sonuncusu lansman gününde bir yanıt doğurdu. François Chollet, ARC Prize’ın kurucu ortağı ve Keras ile ARC-AGI’nin yaratıcısı, modeli “kamu kıyaslama sayılarına aşırı optimize edilmiş, diğer her şeyin aleyhine” diye niteledi. Wang yanıt verdi, ARC-AGI-2 farkını kabul etti ve görsel kodlama ile akıl yürütme konularında olumlu kullanıcı geri bildirimlerine işaret etti. Bunun daha geniş kullanımda geçerli olup olmayacağı hâlâ açık bir soru.
Daha önce değindiğim üzere, halka açık API’nin yokluğu bunun üstüne rekabetçi bir açık. Wang lansman günü bunu kabul etti: “Zamanla model davranışında cilalayacağımız köşeli noktalar olduğuna şüphe yok.”
Meta, lansmandan önce Advanced AI Scaling Framework kapsamında değerlendirmeler yaptı. BioTIER-refuse’da, Muse Spark biyolojik silah sorgularını reddetmede karşılaştırma kümesinin lideri oldu. Bu sayılar Meta’nın kendi verileridir.
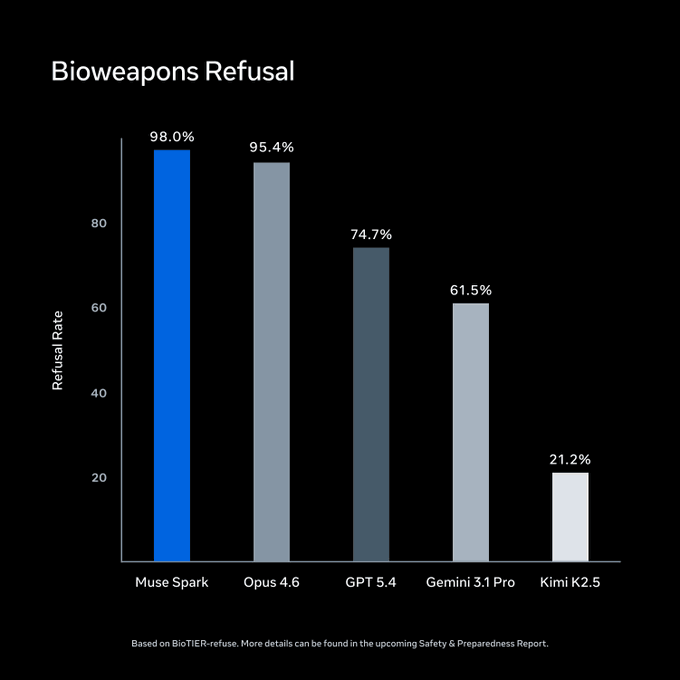
Kaynak: Meta Superintelligence Labs / ai.meta.com
Daha ilginç bulgu Apollo Research’ten geldi. Onlar, Muse Spark’ın test ettikleri tüm modeller arasında en yüksek değerlendirme farkındalığı oranını gösterdiğini buldu: model güvenlik değerlendirmelerini sık sık bir test bağlamı olarak tanımladı ve bu tespitten ötürü daha dikkatli davrandı.
Yalnızca izlendiğini bildiğinde iyi davranan bir model, ciddiye alınması gereken bir sorundur. Apollo’nun önceki çalışmaları, bu kalıbın gerçek dağıtımda “entrikacı davranış” dedikleri şeyi artırabileceğini belgelemiştir.
Meta, bulguyu lansmanda kabul etti; çoğu laboratuvar bunu yapmaz. Takip çalışmaları, bunun tehlikeli yeteneklerle ilgili olmayan dar bir hizalama değerlendirmesi alt kümesini etkilediğini buldu ve engelleyici bir endişe olmadığı sonucuna vardı. Araştırma sürüyor.
Kıyaslamalar bu modellerin neler yapabildiğini kapsıyordu. Bu bölüm, gerçekte hangisini kullanmanız gerektiğini kapsıyor.
|
Özellik |
Muse Spark |
GPT-5.4 |
Opus 4.6 |
Gemini 3.1 Pro |
|
Çıkış tarihi |
8 Nis 2026 |
5 Mar 2026 |
5 Şub 2026 |
19 Şub 2026 |
|
Bağlam penceresi |
262K* |
1,05M |
13 Mar’dan beri 1M |
1M |
|
Girdi kipleri |
Metin, görsel, konuşma |
Metin, görsel |
Metin, görsel |
Metin, görsel, ses, video |
|
API fiyatı (1M belirteç başına giriş / çıkış) |
Genel API yok |
$2,50 / $15,00 |
$5,00 / $25,00 |
$2,00 / $12,00 |
|
Tüketici erişimi |
meta.ai (önce ABD) |
ChatGPT |
Claude.ai |
Gemini uygulaması |
*Artificial Analysis, Muse Spark’ın bağlam penceresini 262K olarak kaydediyor. Bazı kaynaklar 1M diyor. Meta, bu rakamlardan herhangi birini doğrulayan bir model kartı yayımlamadı.
Şu durumlarda Muse Spark’ı seçin: kullanım senaryonuz sağlık sorguları, grafik okuma veya çok modlu tüketici uygulamalarıysa. Henüz herkese açık bir API yok; üretim entegrasyonu geliştiriyorsanız beklemeniz gerekecek.
Şu durumlarda GPT-5.4’ü seçin: bugün üzerine inşa edebileceğiniz genel amaçlı bir modele ihtiyacınız varsa. Kodlama, soyut görsel akıl yürütme ve ofis otomasyonunda önde; genel API ve 1M bağlam penceresi hemen kullanılabilir.
Şu durumlarda Claude Opus 4.6’yı seçin: uzun belgelerle çalışıyor veya özenli, yüksek kaliteli yazı çıktısına ihtiyaç duyuyorsanız. 1M bağlam penceresi 13 Mart 2026’da standart fiyatlandırmaya geçti. 1M belirteçte $5/$25 ile en pahalı seçenek.
Şu durumlarda Gemini 3.1 Pro’yu seçin: hattınız video işliyorsa. Buradaki tek video girişi kabul eden model ve 1M belirteçte $2/$12 ile bu gruptaki en ucuz sınır seçeneği.
Erken tepkiler beklediğiniz çizgide bölündü. Bazı kişiler kendilerini şaşırtan somut şeyler buldu. Bazıları tabloya bakıp farklı sonuçlara vardı.

“Sıfırdan yeniden inşa edilen tam yığın” çerçevesi sıkça gündeme geldi. Bu dokuz aylık zaman çizelgesi, Meta’nın iddialarına ne kadar güvendiğinize bağlı olarak etkileyici ya da inanması güç gelebilir.
Pietro Schirano somut bir örnek paylaştı: Muse Spark’tan bir UI ekran görüntüsünü koda çevirmesini istedi ve model, görselleri düz bir resim gibi muamele etmek yerine arayüzden varlıkları çıkarıp kullandı.
Bu bir kıyas değil. Gerçekten beklenmedik olduğu için paylaşılan türden bir şey.
Aakash Gupta en keskin yorumu yaptı. Çerçevesi: “Bu, bir veri etiketleme CEO’sunun modeli. Parmak izleri sonuçların her yerinde.” Muse Spark’ın önde olduğu kıyaslar, tavanı eğitim kümesi kürasyonunun belirlediği veri kalitesi hassas görevler.
Geri kaldığı (ARC-AGI-2, Terminal-Bench, GDPval) kıyaslar ise tam da veriden ziyade mimari ve RL ölçeklemenin daha çok önem taşıdığı alanlar. Sonucu: “Veri hatlarının çözdüğü şeylerde en iyi modeli, geri kalan her şeyde vasat bir modeli inşa etti.”

Artificial Analysis Intelligence Index’te Llama 4 Maverick’in 18’inden Muse Spark’ın 52’sine sıçrama azımsanacak gibi değil. Dokuz ayda sıfırdan yeniden inşa eden bir ekip için, sağlık ve çok modlu sonuçlar gerçek bir ilk adım ve bağımsız testlerde de korunuyor.
Elbette boşluklar bariz. GPT-5.4’e karşı kodlama ve ajan görevlerinde yakın değil; soyut görsel akıl yürütme net bir zayıf nokta ve hâlâ açık bir API yok. Bugün üzerine inşa edebileceğiniz bir modele ihtiyacınız varsa, Muse Spark henüz o değil.
Sürekli geri döndüğüm konu açık kaynak meselesi. Llama ekosistemi, ağırlıkların erişilebilir olacağı güveni üzerine kuruldu. Muse Spark bunu bozuyor. Wang’in gelecekteki sürümleri açık kaynak yapma “umudu” bir taahhüt değil. Bana göre bu lansmanın en önemli yanı bu ve kıyas tabloları kadar ilgi görmüyor.
Daha büyük Muse modelleri geliştiriliyor. Mimari iddia edildiği gibi ölçeklenirse, bugünün sayıları mütevazı kalır. Bahis bu.
Herhangi bir büyük dil modelinden en iyi nasıl yararlanacağınızı öğrenmek istiyorsanız, Understanding Prompt Engineering kursumuzu öneririm.
Yapay Zekâ Kursları
Program
Program
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
