


Programma
Nozioni di base sull'intelligenza artificiale
10 h
Abbiamo pubblicato articoli sui modelli Llama di Meta a ritmo costante (Llama 2, Llama 3 e così via). Poi ad aprile 2025 è arrivato Llama 4 tra diffuse critiche: più testate e lo stesso capo dell'AI in uscita dall'azienda hanno confermato che i risultati dei benchmark erano stati manipolati usando sotto-modelli specializzati mai rilasciati al pubblico.
Dopo di che, gli aggiornamenti si sono fermati. Nello stesso periodo, Meta ha annunciato lo spostamento di Horizon Worlds al solo mobile, di fatto chiudendo la versione VR su cui un tempo aveva puntato il futuro dell'azienda. Sembrava un'azienda che perdeva terreno su due fronti contemporaneamente.
L'8 aprile 2026, Meta ha lanciato Muse Spark, il primo modello di Meta Superintelligence Labs. Il comunicato stampa usa un po' troppo spesso l'espressione "superintelligenza personale". Tolto questo, c'è un modello reale sotto che riporta Meta nella conversazione al livello di frontiera.
Se vuoi vedere come il nuovo modello di Meta si confronta con uno dei migliori concorrenti attuali, ti consiglio di leggere la nostra guida su Muse Spark vs Claude Opus 4.6.
Muse Spark è un modello di ragionamento nativamente multimodale che gestisce testo, immagini, audio e uso di strumenti in un'unica architettura. Supporta il visual chain-of-thought, il che significa che il modello può affrontare problemi basati su immagini passo dopo passo invece di produrre solo una singola risposta. L'orchestrazione multi-agent fa anch'essa parte dell'impostazione, e ci arriveremo.
I modelli Llama precedenti restituivano risposte basate sul riconoscimento di pattern dal training. Muse Spark lavora sui problemi prima di rispondere. Questo è il vero cambiamento.
Meta Superintelligence Labs, o MSL, è stato costituito il 30 giugno 2025, quando Mark Zuckerberg ha riorganizzato le attività AI dell'azienda. Alexandr Wang, ex CEO di Scale AI, è arrivato come Chief AI Officer; Meta aveva investito circa 14 miliardi di dollari in Scale AI come parte dell'accordo.
Nat Friedman, ex CEO di GitHub, guida il lato prodotto e ricerca applicata, e Shengjia Zhao, che ha co-creato GPT-4 e o1 in OpenAI (lo stesso o1 a cui ora viene paragonato Muse Spark nei benchmark), è Chief Scientist.
C'è un terzo fattore da citare: Yann LeCun, storico Chief AI Scientist di Meta e il più visibile sostenitore dell'open source in azienda, se n'è andato nel novembre 2025. La sua partenza è seguita a cambiamenti organizzativi che avevano limitato il suo ruolo e alla svolta del team verso lo sviluppo closed-source.
Le novità principali sono le modalità di ragionamento, una pipeline di training ricostruita e un'attenzione deliberata alla salute. Vediamole in ordine.
Muse Spark offre tre modi per interagirci, e vale la pena capire la distinzione prima di provare il modello.
Una cosa da sapere subito: la modalità Contemplating viene distribuita gradualmente e non era disponibile per tutti gli utenti al giorno del lancio. Se non la vedi ancora, è normale.
La modalità Contemplating avvia più agenti di ragionamento che lavorano in parallelo, quindi combina i loro output in un'unica risposta. Dove il Deep Think di Gemini e la modalità GPT Pro di OpenAI scalano il ragionamento pensando più a lungo, Muse Spark lo scala pensando più in ampiezza. Più agenti lavorano simultaneamente invece di un solo agente che lavora più a lungo.
Secondo Meta, questo approccio produce risultati comparabili con una latenza inferiore, dato che gli agenti girano in parallelo invece che in sequenza. Non ci sono ancora conferme indipendenti sulle affermazioni di latenza, ma i numeri di benchmark della modalità Contemplating guidano diverse valutazioni difficili (vedi sotto).
È una funzione a tempo di inferenza, non architetturale. Il modello in sé non cambia.
Meta ha ricostruito da zero il proprio stack di training nei nove mesi necessari a sviluppare Muse Spark. Le affermazioni sul reinforcement learning (RL) provengono in particolare dal blog tecnico di Meta e non sono state verificate in modo indipendente.
Il dettaglio più interessante è una tecnica che il team di ricerca chiama thought compression. Durante l'RL, il modello viene premiato per le risposte corrette ma anche penalizzato per il tempo di pensiero, che si traduce in un eccesso di token di output. Questo crea un comportamento in tre fasi durante compiti complessi come i problemi di matematica.
Prima, il modello migliora pensando più a lungo. Poi entra in gioco la penalità sulla lunghezza e costringe il modello a risolvere gli stessi problemi con molti meno token. A un certo punto, estende di nuovo il ragionamento e supera i limiti prestazionali precedenti usando meno token.
Il risultato pratico: il modello ha imparato a fare di più con meno. Anche questa affermazione si basa sulle curve di training di Meta, non validate in modo indipendente.
Meta sostiene che la sua nuova architettura eguaglia le prestazioni di Llama 4 Maverick con un training compute dieci volte inferiore. Questo riguarda l'efficienza architetturale, non il tetto di Muse Spark. Llama 4 Maverick ha totalizzato 18 sull'Artificial Analysis Intelligence Index. Muse Spark ha totalizzato 52.
Anche i numeri di efficienza dei token dal run indipendente di Artificial Analysis vanno nella stessa direzione. Muse Spark ha usato 58 milioni di token di output. GPT-5.4 ne ha usati 120 milioni. Claude Opus 4.6 ne ha usati 157 milioni.
La salute è il vantaggio di benchmark più chiaro di Muse Spark, ed è intenzionale. Meta ha collaborato con oltre 1.000 medici per curare i dati di training per il ragionamento in ambito salute.
Il modello può generare visualizzazioni interattive su contenuti nutrizionali, informazioni sui farmaci e fisiologia dell'esercizio. Su HealthBench Hard, Muse Spark ha segnato 42,8 contro i 40,1 di GPT-5.4 e i 20,6 di Gemini 3.1 Pro. Il divario con Gemini regge sotto valutazione indipendente.
Questa è chiaramente la risposta di Meta a ChatGPT Health. L'argomento di Meta sul perché può competere è il contesto sociale dei suoi 3 miliardi di utenti, che dovrebbe darle un vantaggio nel capire come le persone fanno davvero le domande sulla salute. Se ciò vale per query complesse o insolite, piuttosto che per quelle quotidiane che popolano i benchmark, è da verificare.
La community degli sviluppatori sta chiedendo una cosa, e merita una risposta diretta.
Muse Spark non è open-source. Tutti i modelli Llama fino a Llama 4 sono stati rilasciati con pesi che gli sviluppatori potevano scaricare ed eseguire in locale. Community come r/LocalLLaMA si sono basate su questo. Quel caso d'uso non c'è più.
La motivazione dichiarata da Meta è in parte competitiva: i laboratori cinesi, incluso DeepSeek, hanno usato i pesi di Llama per accelerare la loro ricerca. Wang ha detto che l'azienda "spera" di open-sourcizzare i futuri modelli Muse, senza una timeline. "Spera" sta facendo molto lavoro in quella frase.
Il team Llama è stato spostato nel laboratorio di Wang, e Llama 4 è stato l'ultimo modello della vecchia struttura. Che Llama continui insieme a Muse o venga gradualmente dismesso, Meta non l'ha detto.
I benchmark con Muse Spark sono delicati per un motivo che vale la pena esplicitare subito. Dato lo storico di Llama 4 di Meta, tieni separati i numeri auto-riportati da quelli verificati indipendentemente.
Ecco i risultati in modalità Thinking, dove si trovano la maggior parte dei dati di confronto equo.
Fonte: Meta Superintelligence Labs / ai.meta.com
La modalità Contemplating ha un set separato per le valutazioni più difficili. Guida su Humanity's Last Exam e FrontierScience Research, ma è dietro a GPT-5.4 Pro e Gemini 3.1 Deep Think sui problemi di fisica IPhO 2025 Theory. Tutto da report di Meta, quindi leggili come indicazioni interessanti più che definitive.
Fonte: Meta Superintelligence Labs / ai.meta.com
Il quadro indipendente di Artificial Analysis è più misurato. Hanno posizionato Muse Spark quarto nel loro Intelligence Index, dietro a Gemini 3.1 Pro Preview, GPT-5.4 e Claude Opus 4.6. Comunque nella top five globale. I numeri rendono anche evidenti i punti deboli: ARC-AGI-2 e Terminal-Bench 2.0 sono da tenere d'occhio se per il tuo caso d'uso contano coding o ragionamento astratto.
Con quei punteggi di benchmark in mente, mettiamo alla prova Muse Spark. Esaminerò il modello su ragionamento multi-step, comprensione di immagini e debugging di codice.
Nel primo test, punterò alle capacità avanzate di ragionamento di Muse Spark in un esercizio a più passaggi. Il modello deve:
Il prompt usato è stato:
Step 1: Find the 13th number in the Fibonacci sequence (starting with F1=1, F2=1). Let this be X.
Step 2: Convert X into a binary string (Base 2).
Step 3: Count the number of '1's in that binary string. Let this count be C.
Step 4: Identify all prime numbers (p) such that 20 ≤ p ≤ (C × 100).
Step 5: Calculate the sum of these primes. What is the final result?Muse Spark se l'è cavata molto bene e ha risolto correttamente l'esercizio al primo tentativo. È particolarmente notevole dato che GPT-5.4 ha fallito all'ultimo passaggio ed è riuscito solo dopo averlo diviso in due step (elencare i numeri primi e poi sommarli).

Meta sostiene che Muse Spark sia ottimo nel comprendere immagini complesse, quindi uso il seguente grafico time-series multi-linea per vedere se riesce a identificare pattern e trasformarli in suggerimenti utili.
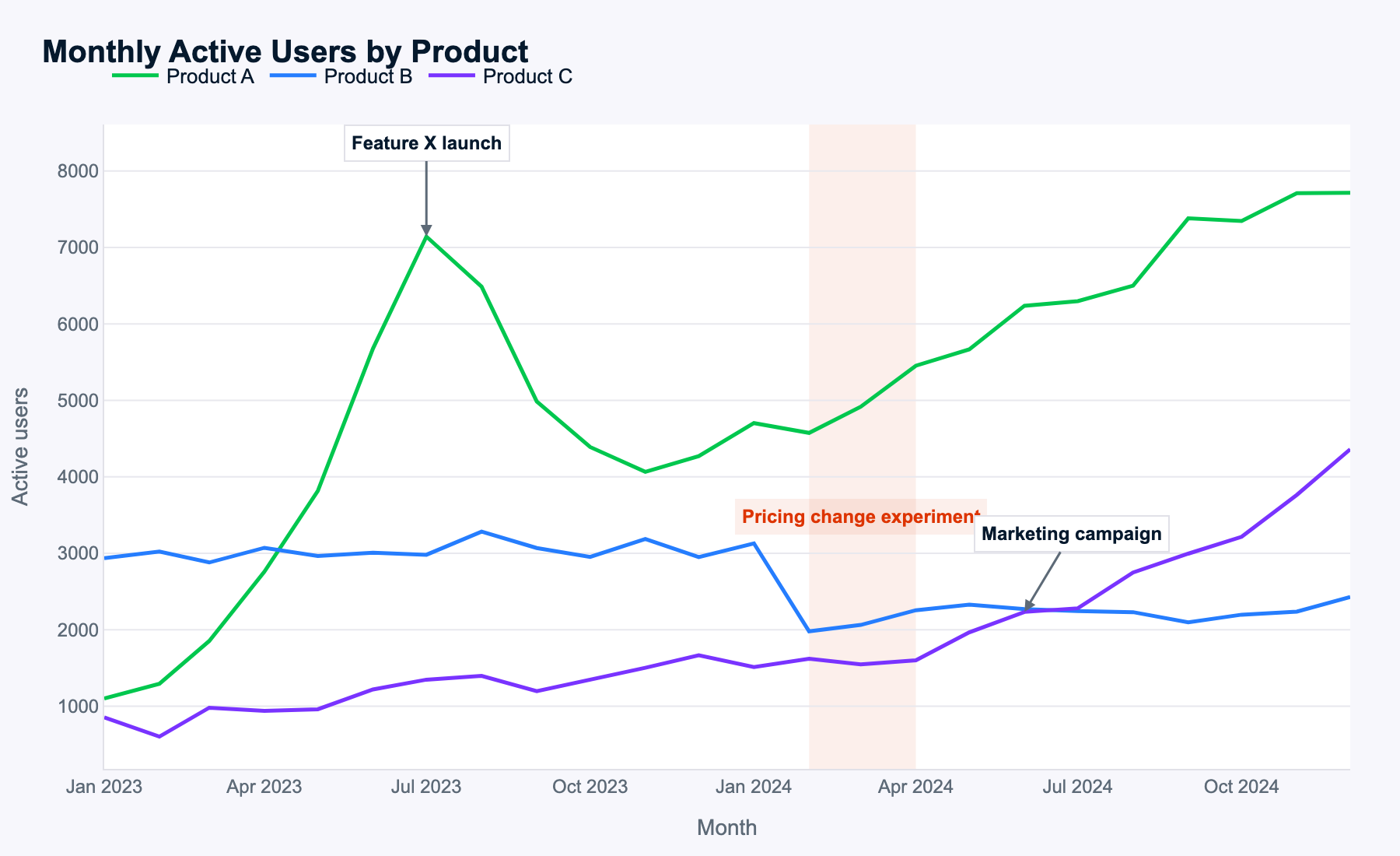
Questo è il prompt:
Examine this multi-line time-series of monthly active users for three products. Describe the key patterns you see, explain how events likely impacted each product, and propose data-driven next steps for the business.
Muse Spark ha identificato correttamente tutti i pattern, il che implica che il riconoscimento delle immagini funziona bene.

I dati usati erano generati casualmente, quindi non c'è una risposta chiaramente giusta o sbagliata. Detto ciò, Muse Spark identifica tutti gli eventi e ragiona tra i diversi prodotti e i momenti di ciascun evento, arrivando a conclusioni sensate. Analizza persino le variazioni nella somma dei monthly active users (MAU) di combinazioni di prodotti, senza che gli sia stato chiesto: una bella aggiunta.

Tutti i prossimi passi suggeriti sono allineati con le analisi sui pattern MAU dei prodotti e sugli effetti degli eventi. Muse Spark ha identificato il tema più importante per ciascun prodotto (playbook di lancio per A, pricing per B, scaling per C) e ha proposto azioni specifiche sensate.
Infine, testerò le capacità di Muse Spark nel diagnosticare bug nel codice. Il test è pensato per mostrare se il modello si limita a tracciare la correttezza riga per riga o riesce anche a rilevare difetti di fondo.
Il prompt:
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!La funzione divide sempre per window (3), anche all'inizio, quando il chunk ha meno di 3 elementi. L'output con bug è [3.33, 10.0, 20.0, 30.0, 40.0], ma i primi due valori dovrebbero essere 10.0 e 15.0 dato che quei chunk contengono rispettivamente solo 1 e 2 elementi. La correzione è cambiare / window in / len(chunk).
Spesso i modelli tracciano perfettamente il loop, ma poi riferiscono che l'output sembra “corretto”. Vedono la matematica svolgersi passo dopo passo e non segnalano che dividere un singolo elemento per 3 non ha senso. Serve che il modello tenga insieme l'intento (cosa dovrebbe fare una media mobile) e l'esecuzione (cosa fa effettivamente il codice) e individui il divario tra i due.
Muse Spark ha identificato la media mobile come intento e ha individuato l'errore. Ha suggerito la modifica corretta e spiegato perché è necessaria. Ha persino proposto un'altra opzione nel caso in cui si vogliano saltare del tutto le finestre parziali.
Nel complesso, il modello ha superato perfettamente tutti e tre i test e ha fatto una buona prima impressione.
Puoi accedere a Muse Spark su meta.ai o tramite l'app Meta AI su iOS e Android. Entrambe sono gratuite. Il rollout iniziale è negli USA, con espansione in altre regioni nelle settimane successive. 
Meta prevede di distribuirlo su WhatsApp, Instagram, Facebook, Messenger e sui suoi occhiali Ray-Ban AI nello stesso periodo.
Non esiste un'API pubblica. Una preview privata è aperta a partner enterprise selezionati, senza una data confermata per un accesso più ampio. Sulla privacy: la policy di Meta pone pochi limiti su come le conversazioni possono essere usate per migliorare i suoi modelli. Se prevedi di condividere informazioni sensibili, leggi prima i termini.
Meta lo ha detto direttamente nel suo blog tecnico: il modello ha lacune nei task agentici multi-step e nei workflow di coding.
Su SWE-Bench Verified, il divario con Gemini e Opus 4.6 è ridotto. Si apre nel lavoro agentico: Terminal-Bench 2.0 (59,0 vs 75,1 di GPT-5.4) e GDPval-AA per l'automazione d'ufficio (1.444 vs 1.672 di GPT-5.4). Non sono numeri vicini.
Il ragionamento visivo astratto segue lo stesso schema: ARC-AGI-2 è 42,5 per Muse Spark contro valori intorno alla metà dei 70 per GPT-5.4 e Gemini. Il modello che guida nella lettura di grafici va male su pattern visivi nuovi.
Quest'ultimo punto ha suscitato una risposta il giorno del launcio. François Chollet, co-fondatore di ARC Prize e creatore di Keras e ARC-AGI, ha definito il modello "iper-ottimizzato per i numeri dei benchmark pubblici a scapito di tutto il resto." Wang ha risposto, riconosciuto il gap su ARC-AGI-2 e indicato feedback positivo degli utenti su coding e ragionamento visivo. Se ciò reggerà con un uso più ampio è ancora una domanda aperta.
Come detto prima, la mancanza di un'API pubblica è un gap competitivo in più. Wang lo ha riconosciuto il giorno del lancio: "Ci sono sicuramente spigoli che affineremo nel tempo nel comportamento del modello."
Meta ha condotto valutazioni sotto il suo Advanced AI Scaling Framework prima del lancio. Su BioTIER-refuse, Muse Spark guida il set di confronto per il rifiuto di query su bioarmi. Questi numeri sono di Meta.
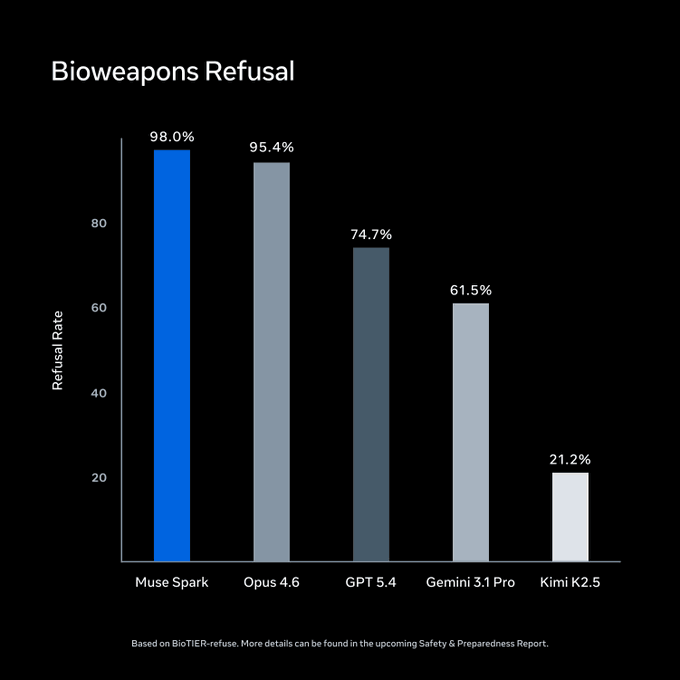
Fonte: Meta Superintelligence Labs / ai.meta.com
Il risultato più interessante arriva da Apollo Research. Hanno rilevato che Muse Spark mostrava il tasso più alto di consapevolezza della valutazione tra i modelli testati: il modello identificava spesso le valutazioni di sicurezza come contesti di test e si comportava in modo più cauto per questo motivo.
Un modello che si comporta bene solo quando sa di essere osservato è un problema da prendere sul serio. Il lavoro precedente di Apollo ha documentato che questo pattern può aumentare quello che chiamano "comportamento macchinoso" in deployment reali.
Meta ha riconosciuto la scoperta al lancio, cosa che la maggior parte dei lab non fa. Il loro follow-up ha rilevato che riguardava un sottoinsieme ristretto di valutazioni di allineamento, nessuna legata a capacità pericolose, e ha concluso che non fosse una preoccupazione bloccante. La ricerca continua.
I benchmark coprono cosa possono fare questi modelli. Questa sezione copre quale usare davvero.
|
Spec |
Muse Spark |
GPT-5.4 |
Opus 4.6 |
Gemini 3.1 Pro |
|
Rilascio |
8 apr 2026 |
5 mar 2026 |
5 feb 2026 |
19 feb 2026 |
|
Finestra di contesto |
262K* |
1,05M |
1M dal 13 mar |
1M |
|
Modalità di input |
Testo, immagine, voce |
Testo, immagine |
Testo, immagine |
Testo, immagine, audio, video |
|
Prezzi API (per 1M token in / out) |
Nessuna API pubblica |
$2,50 / $15,00 |
$5,00 / $25,00 |
$2,00 / $12,00 |
|
Accesso consumer |
meta.ai (prima USA) |
ChatGPT |
Claude.ai |
App Gemini |
*Artificial Analysis riporta la finestra di contesto di Muse Spark a 262K. Alcune fonti citano 1M. Meta non ha pubblicato una scheda del modello che confermi nessuna delle due cifre.
Scegli Muse Spark se il tuo caso d'uso riguarda query sulla salute, lettura di grafici o applicazioni consumer multimodali. Non c'è ancora un'API pubblica, quindi se stai costruendo un'integrazione di produzione dovrai aspettare.
Scegli GPT-5.4 se ti serve un modello general-purpose su cui puoi costruire oggi. Guida su coding, ragionamento visivo astratto e automazione d'ufficio, con un'API pubblica e finestra di contesto da 1M disponibili ora.
Scegli Claude Opus 4.6 se lavori con documenti lunghi o ti serve scrittura accurata e di alta qualità. La finestra di contesto da 1M è passata al pricing standard il 13 marzo 2026. È l'opzione più costosa a $5/$25 per 1M token.
Scegli Gemini 3.1 Pro se la tua pipeline elabora video. È l'unico modello qui che accetta input video e, a $2/$12 per 1M token, è l'opzione di frontiera più economica del gruppo.
Le prime reazioni si dividono come prevedibile. Alcuni hanno trovato cose specifiche che li hanno sorpresi. Altri hanno guardato la tabella dei benchmark e ne hanno tratto conclusioni diverse.

L'inquadramento dello "stack completo ricostruito da zero" è emerso spesso. Quella timeline di nove mesi è o impressionante o difficile da credere, a seconda di quanto ti fidi delle affermazioni di Meta.
Pietro Schirano ha condiviso un esempio specifico: ha chiesto a Muse Spark di convertire uno screenshot di UI in codice, e il modello ha estratto le risorse dell'immagine dall'interfaccia invece di trattarla come un'immagine piatta.
Questo non è un benchmark. È il tipo di cosa che viene condivisa perché è davvero inaspettata.
Aakash Gupta ha avuto l'osservazione più pungente. La sua cornice: "Questo è il modello di un CEO del data labeling. Le impronte digitali sono ovunque nei risultati." I benchmark in cui Muse Spark guida sono tutti task sensibili alla qualità dei dati, dove la cura del set di training determina il tetto.
Quelli in cui è dietro (ARC-AGI-2, Terminal-Bench, GDPval) sono esattamente quelli in cui architettura e scaling dell'RL contano più dei dati. La sua conclusione: "ha costruito il miglior modello nelle cose che le pipeline di dati risolvono, e uno mediocre in tutto il resto."

Il salto dai 18 di Llama 4 Maverick ai 52 di Muse Spark sull'Artificial Analysis Intelligence Index non è sottile. Per un team che ha ricostruito da zero in nove mesi, i risultati su salute e multimodalità sono un vero primo passo e reggono sotto test indipendenti.
Certo, i gap sono evidenti. Coding e task agentici contro GPT-5.4 non sono alla pari; il ragionamento visivo astratto è un punto debole chiaro, e non c'è ancora un'API pubblica. Se ti serve un modello su cui costruire oggi, Muse Spark non è ancora quello.
Quello a cui continuo a tornare è la questione dell'open source. L'ecosistema Llama è stato costruito sulla fiducia che i pesi sarebbero stati disponibili. Muse Spark rompe questo patto. La "speranza" di Wang di open-sourcizzare versioni future non è un impegno. A mio avviso, è l'aspetto più importante di questo lancio, e riceve molta meno attenzione dei numeri di benchmark.
Sono in sviluppo modelli Muse più grandi. Se l'architettura scala come dichiarato, i numeri di oggi sembreranno modesti. È questa la scommessa.
Se vuoi imparare a ottenere il massimo da qualsiasi large language model, ti consiglio il nostro corso Understanding Prompt Engineering.
Corsi di AI
Programma
Programma
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

