
Track
AI Fundamentals
10 hr
I recently finished a contract with an AI company. Among other things, they help researchers post-train LLMs. As a PhD mathematician, I created math prompts that stumped frontier AI models. Trick prompts didn't count; the prompts had to expose reasoning errors.
During that work, I heard repeated references to "Humanity’s Last Exam." I learned that it was an AI benchmark designed to test reasoning in many academic fields. My curiosity led me to dig deeper into what HLE is and what it tells us about the current limits of AI reasoning.
If you’re new to AI and benchmarking, I recommend taking the AI Fundamentals skill track.
As LLMs have advanced, researchers rely on collections of evaluation questions, known as benchmarks, to compare performance and track progress. Humanity's Last Exam (HLE) is a benchmark designed to measure an LLM's reasoning capabilities, not just its ability to pattern match. It aims to evaluate how well a model handles expert-level problems across many academic domains.
With the many benchmarks already in existence, why yet another one? Benchmarks that once challenged LLMs, such as MMLU, are now saturated, with models often scoring above 90 percent. At this point, these benchmarks stop measuring meaningful differences between models.
HLE is a next-generation benchmark that raises the difficulty level by assembling expert-crafted questions that require multi-step reasoning, not merely recall of superficial pattern-matching.
In late 2024, the Centre for AI Safety, a non-profit based on AI safety, partnered with Scale AI, a data company, to develop a more difficult AI benchmark. Dan Hendrycks led the project.
The team crowdsourced graduate-level questions from multiple academic disciplines and offered significant prizes: the top 50 contributors each won $5000, and the next 500 gained $500.
The result was a large pool of expert-level questions across many subjects, such as mathematics, computer science, literature, music analysis, and history.
The HLE paper describes the benchmark as "...the final closed-ended benchmark for broad academic skills." Its questions require multi-step reasoning, which prevents models from guessing or memorizing answers.
HLE consists of 2,500 public questions and about 500 additional questions in a private holdout set.
Each question must be original, have a single correct answer, and resist a simple web search or database lookup. About 76% of the questions use the exact-match answer format and the remaining 24% use multiple choice. Roughly 14% of the questions are multimodal, involving both text and images.
The HLE team had a stringent vetting process for the questions.
Early results showed that frontier models initially scored poorly on the questions, yet expressed high confidence. This gap indicates hallucinations.
Independent groups also raised concerns. Future House, a non-profit research lab, published a blog, "About 30% of Humanity’s Last Exam chemistry/biology answers are likely wrong."
Their analysis focused on the review protocol. Question writers claimed correct answers, but reviewers were instructed to only spend five minutes reviewing answer correctness. They argue this process lets overly complex, contrived, or ambiguous answers slip through that often conflict with scientific literature.
HLE's maintainers responded to the post by commissioning a three-expert review of the disputed subset. As of September 16, 2025, they planned to announce a rolling review process to HLE.
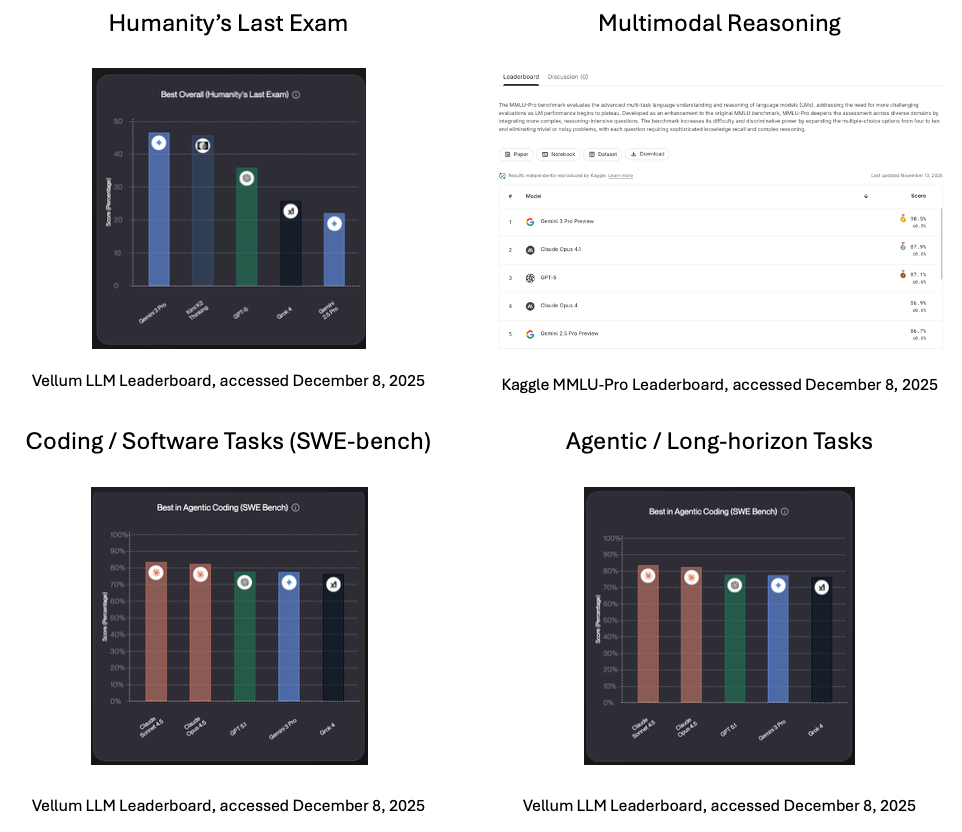
HLE sits within a broader ecosystem of benchmarks that test different aspects of LLM capability.
These benchmarks evaluate academic knowledge and reasoning.
These benchmarks measure reasoning that involves both text and images.
Still other benchmarks focus specifically on software engineering and tool use.
Stanford's Center for Research on Foundation Models (CRFM) developed Holistic Evaluation of Language Models (HELM) to support responsible AI evaluation.
HELM evaluates models on a battery of standardized scenarios, such as question answering, summarization, safety-critical queries, and social/ethical content. These scenarios are scored across multiple dimensions, not only accuracy, but also calibration, robustness, and toxicity.
HELM has grown into a family of related frameworks.
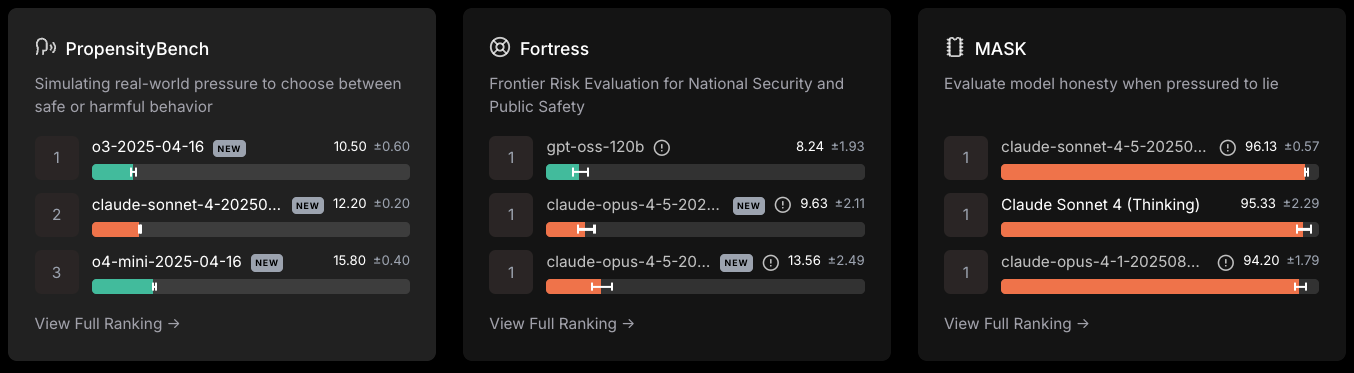
Safety frameworks measure risk rather than intellectual competence.
Many public leaderboards track LLM performance across various metrics.
Here are some scores as of the time of this writing in December 2025.
Scale LLM Safety Leaderboard, accessed December 8, 2025
So far, I’ve outlined what HLE is and how it was developed. Let’s now look at how the test is used in practical terms.
HLE provides a standardized evaluation method across domains. It highlights the strengths and weaknesses of a model. It reveals the gap between it and human expert performance. Teams can use these patterns to guide model development and focused post-training.
HLE provides a public, global metric of AI reasoning progress. It creates a shared reference point across countries and regulatory bodies and can anchor discussions about thresholds, oversight, and governance in reality, not hype.
AI benchmarks shape how we measure AI progress. As earlier benchmarks have saturated, the need for a new benchmark, focused on reasoning, not just recall or pattern matching, became apparent.
Humanity's Last Exam attempts to fill that gap by crowdsourcing graduate-level questions from experts all over the globe to expose the limitations of LLMs. It is not the final word, but it does clarify where AI stands today in relation to human expert reasoning.
For more information about LLMs and how they work, I recommend the following resources:
Top AI Courses
Track
Course
Course
blog
Vinod Chugani
15 min
blog
Andrea Valenzuela
10 min
blog
Vinod Chugani
12 min
blog
Matt Crabtree
15 min
blog
François Aubry
8 min
Tutorial
Abid Ali Awan

