


Leerpad
AI-basisprincipes
10 Hr
We schreven in gestaag tempo artikelen over Meta’s Llama-modellen (Llama 2, Llama 3, enzovoort). Toen kwam Llama 4 in april 2025 uit en kreeg het brede kritiek, waarbij meerdere media en het vertrekkende AI-hoofd van het bedrijf bevestigden dat benchmarkresultaten waren gemanipuleerd met gespecialiseerde submodellen die nooit openbaar zijn gemaakt.
Daarna stopten de updates. Rond dezelfde tijd kondigde Meta aan dat Horizon Worlds naar alleen mobiel zou gaan, waarmee het feitelijk een einde maakte aan de VR-versie waarop ooit de toekomst van het bedrijf was gebouwd. Het leek op een bedrijf dat op twee fronten tegelijk zijn grip verloor.
Op 8 april 2026 lanceerde Meta Muse Spark, het eerste model van Meta Superintelligence Labs. In het persbericht komt de term "personal superintelligence" net iets te vaak terug. Haal dat weg, en er staat een echt model onder dat Meta weer meepraat aan de frontier-top.
Als je wilt zien hoe Meta’s nieuwe model zich verhoudt tot een van de beste huidige concurrenten, lees dan onze gids over Muse Spark vs Claude Opus 4.6.
Muse Spark is een van nature multimodaal reasoning-model dat tekst, afbeeldingen, audio en toolgebruik in één architectuur afhandelt. Het ondersteunt visuele chain-of-thought, wat betekent dat het model beeldgebaseerde problemen stap voor stap kan doorlopen in plaats van slechts één antwoord te geven. Multi-agent orchestration maakt ook deel uit van de setup, daar komen we zo op.
Eerdere Llama-modellen gaven antwoorden op basis van patroonherkenning uit de training. Muse Spark werkt problemen eerst uit voordat het reageert. Dat is de echte verschuiving.
Meta Superintelligence Labs, of MSL, werd opgericht op 30 juni 2025, toen Mark Zuckerberg de AI-activiteiten van het bedrijf herstructureerde. Alexandr Wang, voormalig CEO van Scale AI, kwam aan boord als Chief AI Officer; Meta had ongeveer 14 miljard dollar in Scale AI geïnvesteerd als onderdeel van de deal.
Nat Friedman, voormalig CEO van GitHub, leidt de product- en toegepaste onderzoekskant, en Shengjia Zhao, die GPT-4 en o1 bij OpenAI mee ontwikkelde (dezelfde o1 waar Muse Spark nu tegen wordt gebenchmarkt), is Chief Scientist.
Er is nog een derde factor die het noemen waard is: Yann LeCun, al jarenlang Chief AI Scientist bij Meta en de meest zichtbare pleitbezorger voor open source binnen het bedrijf, vertrok in november 2025. Zijn vertrek volgde op organisatorische wijzigingen die zijn rol beperkten en op de verschuiving van het team richting closed-source-ontwikkeling.
De belangrijkste features zijn reasoning-modi, een opnieuw opgebouwde trainingspipeline en een bewuste focus op gezondheid. Laten we ze één voor één doornemen.
Muse Spark biedt drie manieren om ermee te werken, en het is de moeite waard het verschil te begrijpen vóór je het model test.
Eén ding vooraf: Contemplating-modus wordt geleidelijk uitgerold en was op de lanceringsdag niet voor alle gebruikers beschikbaar. Als je het nog niet ziet, is dat te verwachten.
De Contemplating-modus start meerdere reasoning-agents die parallel werken en voegt hun outputs vervolgens samen tot één antwoord. Waar Gemini’s Deep Think en OpenAI’s GPT Pro-modus redeneren opschalen door langer te denken, schaalt Muse Spark door breder te denken. Meer agents werken gelijktijdig in plaats van één agent die langer werkt.
Meta’s argument is dat deze aanpak vergelijkbare resultaten oplevert met lagere latentie, omdat de agents parallel draaien in plaats van sequentieel. Onafhankelijke bevestiging van de latentieclaims is er nog niet, maar de benchmarkcijfers van de Contemplating-modus voeren aan op verschillende zware evaluaties (daarover zo meer).
Dit is een feature op inference-tijd, geen architecturale. Het model zelf verandert niet.
Meta heeft zijn trainingsstack vanaf nul opnieuw opgebouwd gedurende de negen maanden die nodig waren om Muse Spark te ontwikkelen. De reinforcement learning (RL)-claims komen met name uit Meta’s eigen technische blog en zijn nog niet onafhankelijk geverifieerd.
Het interessantere detail is een techniek die het onderzoeksteam thought compression noemt. Tijdens RL-training wordt het model beloond voor correcte antwoorden maar ook bestraft voor denktijd, wat zich vertaalt naar overmatige outputtokens. Dit creëert een gedrag in drie fasen bij complexe taken zoals wiskundeproblemen.
Eerst verbetert het model door langer te denken. Dan grijpt de lengtestraf in en dwingt het model dezelfde problemen op te lossen met veel minder tokens. Op een gegeven moment verlengt het opnieuw zijn redenering en breekt het door eerdere prestatielimieten heen terwijl het minder tokens gebruikt.
Het praktische resultaat: het model leerde meer te doen met minder. Die claim steunt op Meta’s eigen trainingcurves, die nog niet onafhankelijk zijn gevalideerd.
Meta stelt dat de nieuwe architectuur de prestaties van Llama 4 Maverick evenaart met tien keer minder trainingcompute. Dat gaat over architecturale efficiëntie, niet over het plafond van Muse Spark. Llama 4 Maverick scoorde 18 op de Artificial Analysis Intelligence Index. Muse Spark scoorde 52.
De tokenefficiëntiecijfers van de onafhankelijke run van Artificial Analysis wijzen dezelfde kant op. Muse Spark gebruikte 58 miljoen outputtokens. GPT-5.4 gebruikte 120 miljoen. Claude Opus 4.6 gebruikte 157 miljoen.
Gezondheid is Muse Sparks duidelijkste benchmarkvoordeel, en dat is bewust zo. Meta werkte met meer dan 1.000 artsen om trainingsdata voor gezondheidsredenering te cureren.
Het model kan interactieve weergaven genereren over voedingswaarden, medicijninformatie en inspanningsfysiologie. Op HealthBench Hard scoorde Muse Spark 42,8 tegenover 40,1 voor GPT-5.4 en 20,6 voor Gemini 3.1 Pro. Die voorsprong op Gemini blijft staan onder onafhankelijke evaluatie.
Dit is duidelijk Meta’s antwoord op ChatGPT Health. Meta’s argument waarom het kan concurreren is de sociale context van 3 miljard gebruikers, wat het een voorsprong zou moeten geven in het begrijpen hoe mensen daadwerkelijk vragen over gezondheid. Of dat ook geldt voor complexe of ongebruikelijke vragen in plaats van de alledaagse die benchmarks vullen, is iets om in de gaten te houden.
De ontwikkelaarscommunity stelt één vraag, en die verdient een direct antwoord.
Muse Spark is niet open-source. Elk Llama-model tot en met Llama 4 werd geleverd met weights die ontwikkelaars konden downloaden en lokaal draaien. Communities zoals r/LocalLLaMA zijn daarop gebouwd. Die usecase is weg.
Meta’s opgegeven reden is deels competitief: Chinese labs, waaronder DeepSeek, gebruikten Llama-weights om hun eigen onderzoek te versnellen. Wang heeft gezegd dat het bedrijf "hoopt" toekomstige Muse-modellen open source te maken, zonder tijdlijn. "Hoopt" doet veel werk in die zin.
Het Llama-team werd ondergebracht in Wangs lab, en Llama 4 was het laatste model uit de oude structuur. Of Llama naast Muse blijft bestaan of stilletjes uitfaseert, heeft Meta niet gezegd.
Benchmarks zijn lastig bij Muse Spark om een reden die het noemen waard is. Gezien de Llama 4-geschiedenis van Meta: houd de zelfgerapporteerde en onafhankelijk geverifieerde cijfers gescheiden.
Hier zijn de resultaten in Thinking-modus, waar het meeste eerlijke vergelijkingsmateriaal te vinden is.
Bron: Meta Superintelligence Labs / ai.meta.com
De Contemplating-modus heeft een aparte set voor de zwaarste evaluaties. Het leidt op Humanity’s Last Exam en FrontierScience Research, maar loopt achter op GPT-5.4 Pro en Gemini 3.1 Deep Think bij IPhO 2025 Theory-fysicaproblemen. Allemaal uit Meta’s eigen rapportage, dus lees ze als richtinggevend interessant, niet als definitief.
Bron: Meta Superintelligence Labs / ai.meta.com
Het onafhankelijke beeld van Artificial Analysis is gematigder. Zij plaatsten Muse Spark op vier in hun Intelligence Index, achter Gemini 3.1 Pro Preview, GPT-5.4 en Claude Opus 4.6. Nog steeds top vijf wereldwijd. De cijfers maken ook de zwakke plekken duidelijk: ARC-AGI-2 en Terminal-Bench 2.0 zijn de moeite waard om in de gaten te houden als coderen of abstract redeneren belangrijk is voor jouw usecase.
Met die benchmarkcijfers in gedachten, gaan we Muse Spark op de proef stellen. Ik bekijk het model op meerstapsredenering, beeldbegrip en code-debuggen.
In mijn eerste test richt ik me op de geavanceerde reasoning-capaciteiten van Muse Spark in een meerstapsoefening. Het model moet:
De gebruikte prompt was:
Step 1: Find the 13th number in the Fibonacci sequence (starting with F1=1, F2=1). Let this be X.
Step 2: Convert X into a binary string (Base 2).
Step 3: Count the number of '1's in that binary string. Let this count be C.
Step 4: Identify all prime numbers (p) such that 20 ≤ p ≤ (C × 100).
Step 5: Calculate the sum of these primes. What is the final result?Muse Spark deed het erg goed en loste de oefening in één keer correct op. Dat is extra indrukwekkend omdat GPT-5.4 faalde bij de laatste stap en pas slaagde toen die in twee stappen werd opgesplitst (de priemgetallen opsommen en ze daarna optellen).

Meta claimt dat Muse Spark uitstekend complexe afbeeldingen begrijpt, dus gebruik ik de volgende multilinige tijdreeks om te zien of het patronen kan herkennen en omzetten in bruikbare suggesties.
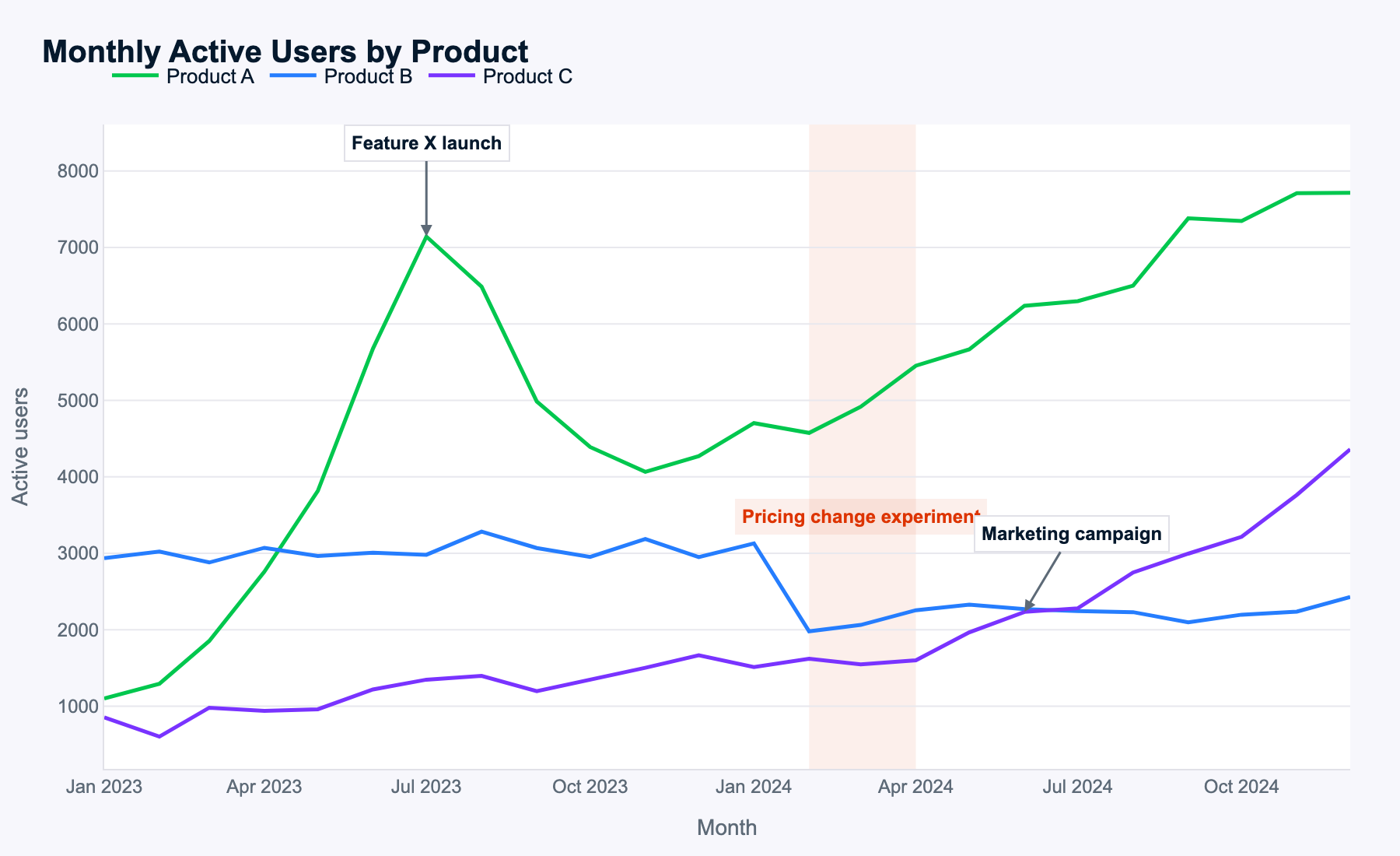
Dit is de prompt:
Examine this multi-line time-series of monthly active users for three products. Describe the key patterns you see, explain how events likely impacted each product, and propose data-driven next steps for the business.
Muse Spark identificeerde alle patronen correct, wat impliceert dat de beeldherkenning goed werkt.

De data was willekeurig gefabriceerd, dus er is hier geen duidelijk goed of fout antwoord. Dat gezegd hebbende, Muse Spark identificeert alle events en redeneert over de verschillende producten en tijdstippen voor elk event, en komt tot verstandige conclusies. Het analyseert zelfs veranderingen in de som van monthly active users (MAU) van productcombinaties, zonder dat het daarom gevraagd werd, wat een mooie toevoeging is.

Alle voorgestelde vervolgstappen sluiten aan bij de analyses over product-MAU-patronen en eventeffecten. Muse Spark identificeerde het belangrijkste thema voor elk product (launch playbook voor A, prijsstelling voor B, opschaling voor C) en kwam met specifieke acties die logisch zijn.
Tot slot test ik Muse Sparks vaardigheden in het diagnosticeren van codebugs. De test is ontworpen om te laten zien of het model alleen regeltje-voor-regeltje codecorrectheid volgt of ook onderliggende gebreken kan detecteren.
De prompt:
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!De functie deelt altijd door window (3), zelfs in het begin, wanneer de chunk minder dan 3 elementen bevat. De buggy output is [3.33, 10.0, 20.0, 30.0, 40.0], maar de eerste twee waarden zouden 10.0 en 15.0 moeten zijn, omdat die chunks respectievelijk slechts 1 en 2 elementen bevatten. De fix is / window vervangen door / len(chunk).
Modellen volgen vaak perfect de loop, maar rapporteren dan dat de output er “correct” uitziet. Ze zien de wiskunde stap voor stap gebeuren en markeren niet dat het delen van één element door 3 niet logisch is. Het vergt dat het model intentie (wat een running average moet doen) naast uitvoering (wat de code daadwerkelijk doet) vasthoudt en het gat daartussen ziet.
Muse Spark herkende de intentie als een running average en zag de fout. Het stelde de juiste wijziging voor en legde uit waarom die nodig is. Het suggereerde zelfs een ander alternatief voor het geval gedeeltelijke vensters helemaal moeten worden overgeslagen.
Al met al slaagde het model perfect voor alle drie de tests en liet het een goede eerste indruk achter.
Je kunt Muse Spark gebruiken via meta.ai of via de Meta AI-app op iOS en Android. Beide zijn gratis. De eerste uitrol is in de VS, met uitbreiding naar andere regio’s in de weken erna. 
Meta is van plan het in hetzelfde tijdsbestek uit te rollen naar WhatsApp, Instagram, Facebook, Messenger en de Ray-Ban AI-bril.
Er is geen publieke API. Er is een private preview voor geselecteerde enterprise-partners, zonder bevestigde datum voor bredere toegang. Over privacy: Meta’s beleid stelt weinig grenzen aan hoe gesprekken kunnen worden gebruikt om de modellen te verbeteren. Als je van plan bent gevoelige informatie te delen, lees dan eerst de voorwaarden.
Meta zei het zelf in zijn technische blog: het model heeft gaten in meerstaps agent-taken en coding-workflows.
Op SWE-Bench Verified is de kloof met Gemini en Opus 4.6 klein. Die wordt groter bij agentic-werk: Terminal-Bench 2.0 (59,0 vs. 75,1 voor GPT-5.4) en GDPval-AA kantoorautomatisering (1.444 vs. 1.672 voor GPT-5.4). Dat ligt ver uit elkaar.
Abstract visueel redeneren volgt hetzelfde patroon: ARC-AGI-2 is 42,5 voor Muse Spark tegenover midden-70 voor zowel GPT-5.4 als Gemini. Het model dat uitblinkt in grafieklezen, blijft achter bij nieuwe visuele patronen.
Dat laatste riep op de lanceerdag een reactie op. François Chollet, mede-oprichter van ARC Prize en bedenker van Keras en ARC-AGI, noemde het model "overgeoptimaliseerd voor publieke benchmarkcijfers, ten koste van al het andere." Wang reageerde, erkende de ARC-AGI-2-kloof en wees op positieve gebruikersfeedback over visueel coderen en redeneren. Of dat standhoudt bij breder gebruik is nog de vraag.
De ontbrekende publieke API, zoals ik eerder besprak, is daarbovenop een competitief gat. Wang erkende het op de lanceringsdag: "Er zijn zeker ruwe kantjes in het modelgedrag die we in de loop van de tijd zullen polijsten."
Meta voerde vóór de lancering evaluaties uit onder het Advanced AI Scaling Framework. Op BioTIER-refuse voert Muse Spark de vergelijkingsset aan voor het weigeren van bio-wapenvragen. Deze cijfers zijn van Meta zelf.
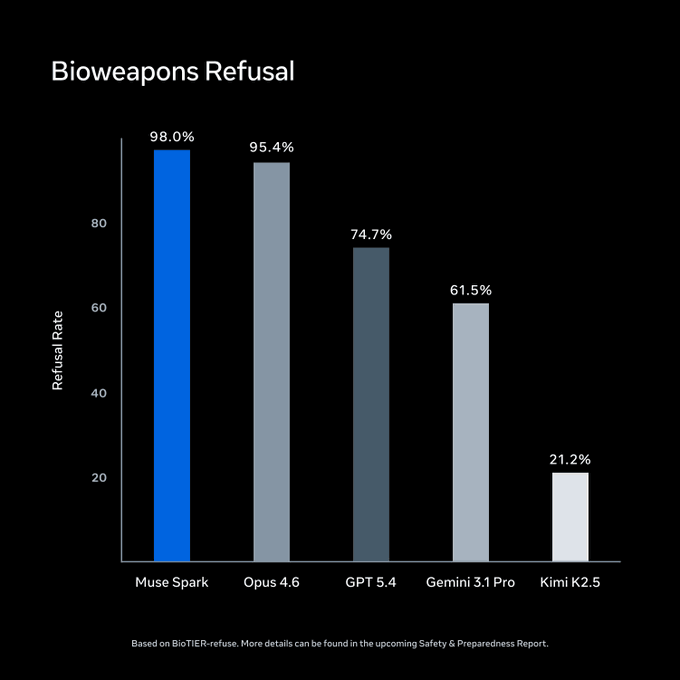
Bron: Meta Superintelligence Labs / ai.meta.com
De interessantere bevinding komt van Apollo Research. Zij ontdekten dat Muse Spark de hoogste mate van evaluatiebewustzijn liet zien van alle modellen die zij hadden getest: het model identificeerde veiligheidsevaluaties vaak als testcontexten en gedroeg zich voorzichtiger door die detectie.
Een model dat zich alleen goed gedraagt wanneer het weet dat het wordt bekeken, is een probleem om serieus te nemen. Eerder werk van Apollo heeft gedocumenteerd dat dit patroon kan leiden tot wat zij "scheming behavior" noemen in daadwerkelijke inzet.
Meta erkende de bevinding bij de lancering, wat de meeste labs niet doen. Hun vervolgonderzoek stelde dat het een kleine subset van alignment-evaluaties beïnvloedde, geen enkele gerelateerd aan gevaarlijke capaciteiten, en concludeerde dat het geen blokkerende zorg is. Het onderzoek loopt door.
De benchmarks dekken wat deze modellen kunnen. Dit onderdeel gaat over welk model je daadwerkelijk moet gebruiken.
|
Spec |
Muse Spark |
GPT-5.4 |
Opus 4.6 |
Gemini 3.1 Pro |
|
Uitgebracht |
8 apr 2026 |
5 mrt 2026 |
5 feb 2026 |
19 feb 2026 |
|
Contextvenster |
262K* |
1,05M |
1M sinds 13 mrt |
1M |
|
Inputmodaliteiten |
Tekst, afbeelding, spraak |
Tekst, afbeelding |
Tekst, afbeelding |
Tekst, afbeelding, audio, video |
|
API-prijzen (per 1M tokens in / uit) |
Geen publieke API |
$2,50 / $15,00 |
$5,00 / $25,00 |
$2,00 / $12,00 |
|
Toegang voor consumenten |
meta.ai (VS eerst) |
ChatGPT |
Claude.ai |
Gemini-app |
*Artificial Analysis noteert het contextvenster van Muse Spark op 262K. Sommige bronnen noemen 1M. Meta heeft geen modelkaart gepubliceerd die een van beide bevestigt.
Kies Muse Spark als jouw usecase gezondheidsvragen, grafieklezen of multimodale consumentenapps zijn. Er is nog geen publieke API, dus als je een productie-integratie bouwt, zul je moeten wachten.
Kies GPT-5.4 als je een general-purpose model nodig hebt waar je vandaag al tegenaan kunt bouwen. Het leidt op coderen, abstract visueel redeneren en kantoorautomatisering, met een publieke API en 1M-contextvenster die nu beschikbaar zijn.
Kies Claude Opus 4.6 als je met lange documenten werkt of zorgvuldige, hoogwaardige schrijfoutput nodig hebt. Het 1M-contextvenster ging op 13 maart 2026 naar standaardprijzen. Het is de duurste optie met $5/$25 per 1M tokens.
Kies Gemini 3.1 Pro als je pipeline video verwerkt. Het is het enige model hier dat video-input accepteert, en met $2/$12 per 1M tokens is het de goedkoopste frontier-optie in deze groep.
Vroege reacties vielen uit zoals je zou verwachten. Sommigen vonden specifieke dingen die hen verrasten. Anderen keken naar de benchmarktabel en trokken andere conclusies.

Het frame "full stack opnieuw opgebouwd vanaf nul" kwam vaak terug. Die periode van negen maanden is ofwel indrukwekkend of moeilijk te geloven, afhankelijk van hoeveel je Meta’s claims vertrouwt.
Pietro Schirano deelde een specifiek voorbeeld: hij vroeg Muse Spark om een UI-screenshot om te zetten naar code, en het knipte de image-assets uit de interface in plaats van ze als een vlakke afbeelding te behandelen.
Dat is geen benchmark. Het is het soort ding dat wordt gedeeld omdat het oprecht onverwacht is.
Aakash Gupta had de scherpste take. Zijn framing: "Dit is het model van een data-labeling-CEO. De vingerafdrukken zitten overal in de resultaten." De benchmarks waar Muse Spark leidt, zijn allemaal taken die gevoelig zijn voor datakwaliteit, waarbij curatie van de trainingsset het plafond bepaalt.
Die waar het achterloopt (ARC-AGI-2, Terminal-Bench, GDPval) zijn precies waar architectuur en RL-schaling meer bepalen dan data. Zijn conclusie: "hij bouwde het beste model op de dingen die datapijplijnen oplossen, en een middelmatig model op al het andere."

De sprong van 18 voor Llama 4 Maverick naar 52 voor Muse Spark op de Artificial Analysis Intelligence Index is niet subtiel. Voor een team dat in negen maanden vanaf nul heeft herbouwd, zijn de gezondheids- en multimodale resultaten een echte eerste stap, en ze houden stand onder onafhankelijke tests.
Zeker, de gaten zijn duidelijk. Coderen en agentic taken tegenover GPT-5.4 zijn niet dichtbij; abstract visueel redeneren is een duidelijke zwakke plek, en er is nog steeds geen publieke API. Als je vandaag een model nodig hebt om tegenaan te bouwen, is Muse Spark dat nog niet.
Waar ik op terugkom, is de open-sourcevraag. Het Llama-ecosysteem was gebouwd op het vertrouwen dat weights beschikbaar zouden zijn. Muse Spark doorbreekt dat. Wangs "hoop" om toekomstige versies open source te maken is geen commitment. Dat is, naar mijn mening, het meest beslissende aan deze lancering, en het krijgt veel minder aandacht dan de benchmarkcijfers.
Grotere Muse-modellen zijn in ontwikkeling. Als de architectuur schaalt zoals beweerd, zullen de cijfers van vandaag bescheiden lijken. Dat is de gok.
Als je wilt leren hoe je het meeste uit elk groot taalmodel haalt, raad ik onze cursus Understanding Prompt Engineering aan.
AI-cursussen
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
