


Tracks
Cơ bản về Trí tuệ Nhân tạo
10 giờ
Chúng tôi đã đều đặn viết bài về các mô hình Llama của Meta (Llama 2, Llama 3, v.v.). Rồi Llama 4 ra mắt vào tháng 4/2025 và hứng chịu nhiều chỉ trích, với nhiều cơ quan báo chí và cả giám đốc AI sắp rời công ty xác nhận rằng kết quả điểm chuẩn đã bị thao túng bằng các mô hình con chuyên biệt chưa bao giờ được phát hành công khai.
Sau đó, các bản cập nhật không còn xuất hiện. Cùng thời điểm, Meta thông báo chuyển Horizon Worlds sang chỉ dành cho di động, trên thực tế là kết thúc phiên bản VR mà trước đây công ty từng đặt cược tương lai vào đó. Trông như một công ty đang đánh mất chỗ đứng trên hai mặt trận cùng lúc.
Ngày 8/4/2026, Meta ra mắt Muse Spark, mô hình đầu tiên từ Meta Superintelligence Labs. Thông cáo báo chí lặp lại cụm từ "trí tuệ siêu việt cá nhân" hơi quá nhiều lần. Gác điều đó sang một bên, bên dưới là một mô hình thực sự đưa Meta trở lại cuộc trò chuyện ở tuyến đầu.
Nếu bạn muốn xem mô hình mới của Meta so với một trong những đối thủ mạnh nhất hiện nay như thế nào, tôi khuyên bạn đọc hướng dẫn của chúng tôi về Muse Spark so với Claude Opus 4.6.
Muse Spark là một mô hình suy luận đa phương thức bẩm sinh, xử lý văn bản, hình ảnh, âm thanh và sử dụng công cụ trong một kiến trúc duy nhất. Nó hỗ trợ chuỗi suy nghĩ thị giác, nghĩa là mô hình có thể giải các bài toán dựa trên hình ảnh theo từng bước thay vì chỉ đưa ra một đáp án duy nhất. Điều phối đa tác tử cũng là một phần của thiết lập, mà chúng ta sẽ đề cập.
Các mô hình Llama trước đây trả lời dựa trên khớp mẫu từ dữ liệu huấn luyện. Muse Spark xử lý bài toán trước khi phản hồi. Đó mới là sự chuyển dịch thực sự.
Meta Superintelligence Labs, hay MSL, được thành lập ngày 30/6/2025 khi Mark Zuckerberg tái tổ chức hoạt động AI của công ty. Alexandr Wang, cựu CEO Scale AI, đảm nhiệm vị trí Giám đốc AI; Meta đã đầu tư khoảng 14 tỷ đô la vào Scale AI như một phần của thỏa thuận.
Nat Friedman, cựu CEO GitHub, phụ trách mảng sản phẩm và nghiên cứu ứng dụng, và Shengjia Zhao, người đồng sáng tạo GPT-4 và o1 tại OpenAI (chính o1 mà hiện Muse Spark được đem ra so sánh), là Nhà khoa học trưởng.
Có một yếu tố thứ ba đáng nhắc đến: Yann LeCun, Nhà khoa học trưởng về AI lâu năm của Meta và là người ủng hộ nguồn mở nổi bật nhất của công ty, đã rời đi vào tháng 11/2025. Sự ra đi của ông diễn ra sau những thay đổi tổ chức làm hạn chế vai trò của ông và sự chuyển hướng của nhóm sang phát triển đóng.
Các tính năng nổi bật là các chế độ suy luận, quy trình huấn luyện được xây dựng lại, và trọng tâm có chủ đích vào lĩnh vực sức khỏe. Hãy đi theo thứ tự.
Muse Spark cung cấp ba cách tương tác, và sự khác biệt giữa chúng rất đáng để hiểu trước khi bạn thử mô hình.
Một điều cần biết trước: chế độ Contemplating được triển khai dần và chưa có cho tất cả người dùng vào ngày ra mắt. Nếu bạn chưa thấy, điều đó là bình thường.
Chế độ Contemplating khởi chạy nhiều tác tử suy luận hoạt động song song, rồi hợp nhất đầu ra của họ thành một phản hồi duy nhất. Trong khi Deep Think của Gemini và chế độ GPT Pro của OpenAI mở rộng suy luận bằng cách suy nghĩ lâu hơn, Muse Spark mở rộng bằng cách suy nghĩ theo chiều rộng. Nhiều tác tử làm việc đồng thời thay vì một tác tử làm việc lâu hơn.
Lập luận của Meta là cách tiếp cận này tạo ra kết quả tương đương với độ trễ thấp hơn, vì các tác tử chạy song song chứ không tuần tự. Hiện chưa có xác nhận độc lập về các tuyên bố liên quan đến độ trễ, nhưng các con số điểm chuẩn từ chế độ Contemplating dẫn đầu ở một số bài đánh giá khó (sẽ nói kỹ hơn ngay sau).
Đây là tính năng ở thời điểm suy luận, không phải thay đổi kiến trúc. Bản thân mô hình không thay đổi.
Meta xây dựng lại hoàn toàn ngăn xếp huấn luyện trong chín tháng phát triển Muse Spark. Các tuyên bố về học tăng cường (RL) đặc biệt đến từ blog kỹ thuật của Meta và chưa được xác minh độc lập.
Chi tiết thú vị hơn là kỹ thuật nhóm nghiên cứu gọi là nén suy nghĩ (thought compression). Trong quá trình huấn luyện RL, mô hình được thưởng khi trả lời đúng nhưng cũng bị phạt vì thời gian suy nghĩ, điều này chuyển thành số token đầu ra quá mức. Điều này tạo ra hành vi ba giai đoạn trong các tác vụ phức tạp như bài toán toán học.
Đầu tiên, mô hình cải thiện bằng cách suy nghĩ lâu hơn. Sau đó, mức phạt độ dài có hiệu lực và buộc mô hình giải quyết cùng bài toán với ít token hơn rất nhiều. Tới một thời điểm, nó lại mở rộng suy luận và vượt qua trần hiệu năng trước đó trong khi vẫn dùng ít token hơn.
Kết quả thực tế: mô hình học cách làm được nhiều hơn với ít hơn. Tuyên bố này dựa trên các đường cong huấn luyện của chính Meta và chưa được xác thực độc lập.
Meta tuyên bố kiến trúc mới của họ đạt hiệu năng tương đương Llama 4 Maverick với lượng compute huấn luyện ít hơn mười lần. Điều đó liên quan đến hiệu quả kiến trúc, không phải trần hiệu năng của Muse Spark. Llama 4 Maverick đạt 18 trên Artificial Analysis Intelligence Index. Muse Spark đạt 52.
Các số liệu hiệu quả token từ lần chạy độc lập của Artificial Analysis cũng chỉ theo hướng tương tự. Muse Spark dùng 58 triệu token đầu ra. GPT-5.4 dùng 120 triệu. Claude Opus 4.6 dùng 157 triệu.
Sức khỏe là lợi thế điểm chuẩn rõ ràng nhất của Muse Spark, và đó là chủ đích. Meta làm việc với hơn 1.000 bác sĩ để tuyển chọn dữ liệu huấn luyện cho suy luận trong lĩnh vực sức khỏe.
Mô hình có thể tạo các hiển thị tương tác bao quát thành phần dinh dưỡng, thông tin thuốc và sinh lý học vận động. Trên HealthBench Hard, Muse Spark đạt 42,8 so với 40,1 của GPT-5.4 và 20,6 của Gemini 3.1 Pro. Khoảng cách với Gemini vẫn giữ khi đánh giá độc lập.
Đây rõ ràng là câu trả lời của Meta cho ChatGPT Health. Lập luận của Meta về lý do họ có thể cạnh tranh là bối cảnh xã hội từ 3 tỷ người dùng, điều này nên cho họ lợi thế trong việc hiểu cách mọi người thực sự đặt câu hỏi về sức khỏe. Liệu điều đó có đúng với các truy vấn phức tạp hoặc bất thường thay vì những câu hỏi thường ngày xuất hiện trong bộ điểm chuẩn hay không vẫn đáng theo dõi.
Cộng đồng nhà phát triển đang hỏi một điều, và nó xứng đáng có câu trả lời trực diện.
Muse Spark không phải nguồn mở. Mọi mô hình Llama đến Llama 4 đều phát hành kèm trọng số để nhà phát triển có thể tải về và chạy cục bộ. Các cộng đồng như r/LocalLLaMA được xây dựng dựa trên đó. Trường hợp sử dụng đó nay không còn.
Lý do được Meta nêu một phần là cạnh tranh: các phòng thí nghiệm Trung Quốc, bao gồm DeepSeek, đã dùng trọng số Llama để tăng tốc nghiên cứu của họ. Wang nói công ty "hy vọng" sẽ mở nguồn các phiên bản Muse trong tương lai, nhưng không có mốc thời gian. Từ "hy vọng" đang gánh vác rất nhiều trong câu đó.
Nhóm Llama đã được chuyển vào phòng thí nghiệm của Wang, và Llama 4 là mô hình cuối cùng từ cấu trúc cũ. Liệu Llama tiếp tục song song với Muse hay âm thầm bị loại bỏ, Meta chưa nói.
Điểm chuẩn với Muse Spark phức tạp vì một lý do đáng nêu rõ ngay từ đầu. Với lịch sử của Llama 4 từ Meta, hãy tách bạch các con số tự báo cáo và con số đã được xác minh độc lập.
Dưới đây là kết quả ở chế độ Thinking, nơi có hầu hết dữ liệu so sánh công bằng.
Nguồn: Meta Superintelligence Labs / ai.meta.com
Chế độ Contemplating có một bộ riêng cho các bài đánh giá khó nhất. Nó dẫn đầu ở Humanity's Last Exam và FrontierScience Research, nhưng kém GPT-5.4 Pro và Gemini 3.1 Deep Think ở bài toán vật lý IPhO 2025 Theory. Tất cả đều từ báo cáo của Meta, nên hãy xem như thông tin mang tính định hướng hơn là kết luận cuối cùng.
Nguồn: Meta Superintelligence Labs / ai.meta.com
Bức tranh độc lập từ Artificial Analysis thận trọng hơn. Họ xếp Muse Spark thứ tư trên Chỉ số Trí tuệ của mình, sau Gemini 3.1 Pro Preview, GPT-5.4 và Claude Opus 4.6. Vẫn thuộc top 5 toàn cầu. Các con số cũng cho thấy rõ điểm yếu: ARC-AGI-2 và Terminal-Bench 2.0 đáng chú ý nếu mã hóa hoặc suy luận trừu tượng quan trọng với trường hợp sử dụng của bạn.
Với những điểm số điểm chuẩn đó, hãy thử nghiệm Muse Spark. Tôi sẽ xem xét mô hình ở suy luận nhiều bước, hiểu hình ảnh và gỡ lỗi mã.
Trong bài test đầu tiên, tôi nhắm vào khả năng suy luận nâng cao của Muse Spark qua một bài tập nhiều bước. Mô hình cần:
Prompt sử dụng là:
Step 1: Find the 13th number in the Fibonacci sequence (starting with F1=1, F2=1). Let this be X.
Step 2: Convert X into a binary string (Base 2).
Step 3: Count the number of '1's in that binary string. Let this count be C.
Step 4: Identify all prime numbers (p) such that 20 ≤ p ≤ (C × 100).
Step 5: Calculate the sum of these primes. What is the final result?Muse Spark làm rất tốt và giải đúng ngay lần đầu. Điều này đặc biệt ấn tượng vì GPT-5.4 đã thất bại ở bước cuối và chỉ thành công khi chia thành hai bước (liệt kê các số nguyên tố rồi mới cộng).

Meta cho rằng Muse Spark rất giỏi hiểu các hình ảnh phức tạp, nên tôi dùng biểu đồ chuỗi thời gian nhiều đường dưới đây để xem liệu nó có thể nhận diện các mẫu và chuyển hóa thành gợi ý hữu ích không.
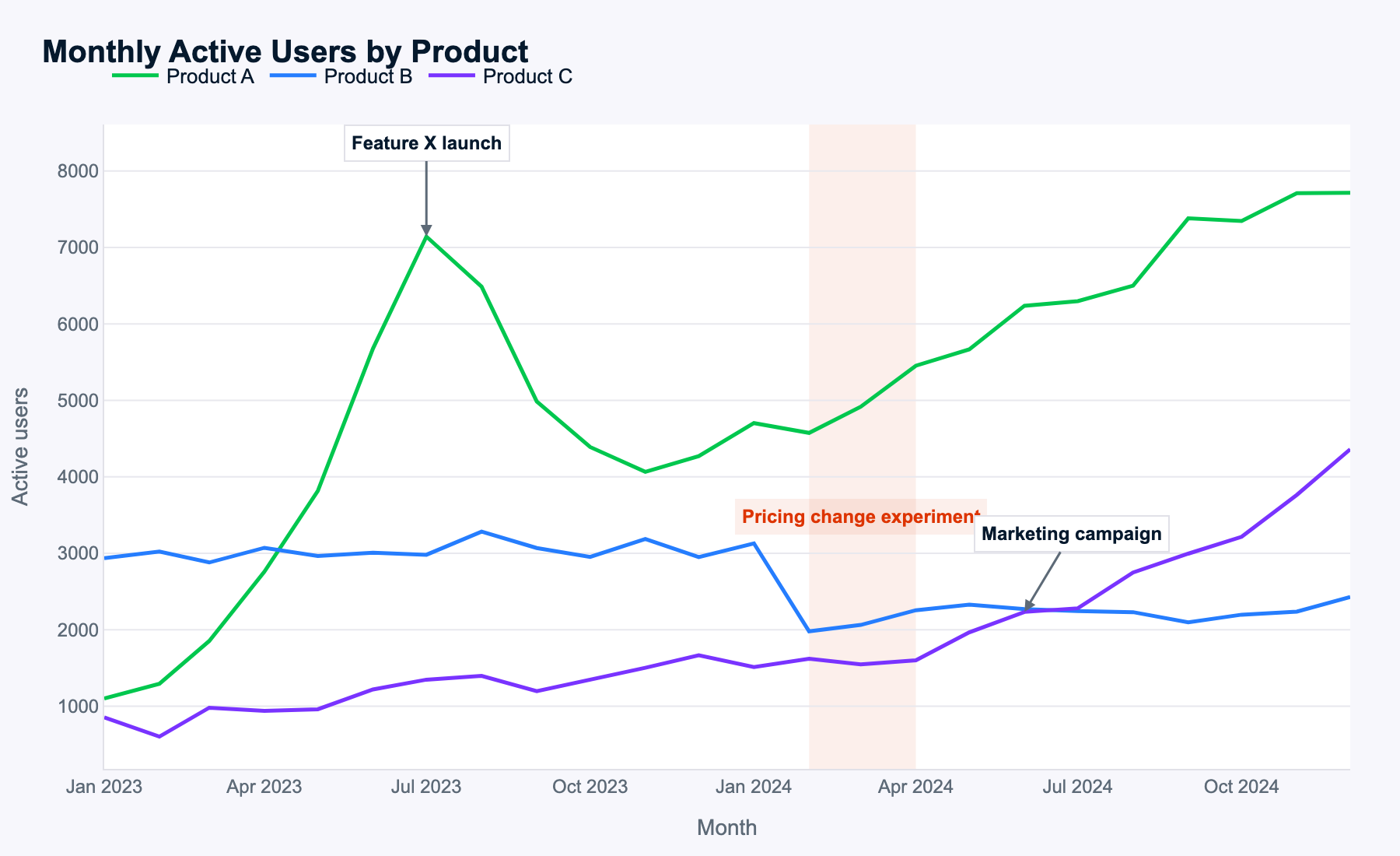
Đây là prompt:
Examine this multi-line time-series of monthly active users for three products. Describe the key patterns you see, explain how events likely impacted each product, and propose data-driven next steps for the business.
Muse Spark nhận diện chính xác tất cả các mẫu, cho thấy khả năng nhận dạng hình ảnh hoạt động tốt.

Dữ liệu sử dụng được tạo ngẫu nhiên, nên không có đáp án đúng sai rõ ràng. Dù vậy, Muse Spark xác định tất cả sự kiện và lập luận theo từng sản phẩm, từng thời điểm cho mỗi sự kiện, và đưa ra kết luận hợp lý. Thậm chí nó còn phân tích thay đổi tổng MAU (người dùng hoạt động hàng tháng) theo tổ hợp sản phẩm mà không cần được gợi ý, đây là điểm cộng thú vị.

Tất cả bước tiếp theo được đề xuất đều phù hợp với phân tích về mẫu MAU sản phẩm và ảnh hưởng sự kiện. Muse Spark xác định chủ đề quan trọng nhất cho mỗi sản phẩm (playbook ra mắt cho A, định giá cho B, mở rộng quy mô cho C) và đưa ra hành động cụ thể hợp lý.
Cuối cùng, tôi sẽ thử khả năng chẩn đoán lỗi mã của Muse Spark. Bài test được thiết kế để cho thấy mô hình chỉ dò tính đúng đắn từng dòng hay cũng phát hiện các sai sót cơ bản.
Prompt:
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!Hàm luôn chia cho window (3), ngay cả lúc đầu khi chunk có ít hơn 3 phần tử. Kết quả lỗi là [3.33, 10.0, 20.0, 30.0, 40.0], nhưng hai giá trị đầu tiên đáng lẽ phải là 10.0 và 15.0 vì các chunk đó chỉ chứa lần lượt 1 và 2 phần tử. Cách sửa là đổi / window thành / len(chunk).
Các mô hình thường lần theo vòng lặp hoàn hảo, nhưng rồi báo rằng đầu ra có vẻ “đúng”. Chúng thấy các phép tính diễn ra từng bước và không gắn cờ rằng chia một phần tử cho 3 là vô lý. Điều này đòi hỏi mô hình phải giữ được ý định (chạy trung bình trượt cần làm gì) song song với thực thi (mã đang làm gì) và nhận ra khoảng cách giữa chúng.
Muse Spark xác định chạy trung bình trượt là ý định và phát hiện lỗi. Nó đề xuất thay đổi đúng và giải thích lý do cần thiết. Thậm chí nó còn gợi ý phương án khác nếu muốn bỏ qua hoàn toàn các cửa sổ chưa đủ phần tử.
Nhìn chung, mô hình vượt qua cả ba bài test một cách hoàn hảo và để lại ấn tượng ban đầu tốt.
Bạn có thể truy cập Muse Spark tại meta.ai hoặc qua ứng dụng Meta AI trên iOS và Android. Cả hai đều miễn phí. Đợt triển khai ban đầu ưu tiên tại Mỹ, mở rộng sang khu vực khác trong vài tuần tiếp theo. 
Meta dự định triển khai trên WhatsApp, Instagram, Facebook, Messenger và kính Ray-Ban AI trong cùng khung thời gian.
Hiện chưa có API công khai. Bản xem trước riêng tư mở cho một số đối tác doanh nghiệp được chọn, chưa có ngày xác nhận cho quyền truy cập rộng rãi. Về quyền riêng tư: chính sách của Meta đặt ra ít giới hạn về cách các cuộc trò chuyện có thể được dùng để cải thiện mô hình. Nếu bạn định chia sẻ thông tin nhạy cảm, hãy đọc điều khoản trước.
Meta nói thẳng trong blog kỹ thuật: mô hình còn khoảng trống ở các tác vụ tác tử nhiều bước và quy trình làm việc mã hóa.
Trên SWE-Bench Verified, khoảng cách với Gemini và Opus 4.6 là nhỏ. Nó mở rộng ở công việc mang tính tác tử: Terminal-Bench 2.0 (59,0 so với 75,1 của GPT-5.4) và tự động hóa văn phòng GDPval-AA (1.444 so với 1.672 của GPT-5.4). Những con số đó cách biệt đáng kể.
Suy luận thị giác trừu tượng cũng theo mô hình tương tự: ARC-AGI-2 là 42,5 cho Muse Spark so với mức hơn 70 của cả GPT-5.4 và Gemini. Mô hình dẫn đầu ở đọc biểu đồ lại thua sút rõ rệt ở các mẫu hình thị giác mới lạ.
Điểm cuối cùng này đã nhận phản hồi ngay ngày ra mắt. François Chollet, đồng sáng lập ARC Prize và là tác giả Keras và ARC-AGI, gọi mô hình là "tối ưu hóa quá mức cho các con số điểm chuẩn công khai, đánh đổi mọi thứ khác." Wang trả lời, thừa nhận khoảng cách ở ARC-AGI-2 và chỉ ra phản hồi tích cực của người dùng về mã hóa và suy luận thị giác. Liệu điều đó có đúng khi sử dụng rộng rãi hơn hay không vẫn là câu hỏi mở.
Việc thiếu API công khai, như tôi đã đề cập, cũng là một khoảng trống cạnh tranh. Wang thừa nhận điều này vào ngày ra mắt: "Chắc chắn có những góc cạnh chúng tôi sẽ mài giũa theo thời gian trong hành vi của mô hình."
Meta đã tiến hành các đánh giá theo Advanced AI Scaling Framework trước khi ra mắt. Trên BioTIER-refuse, Muse Spark dẫn đầu tập so sánh về khả năng từ chối truy vấn vũ khí sinh học. Những con số này là của chính Meta.
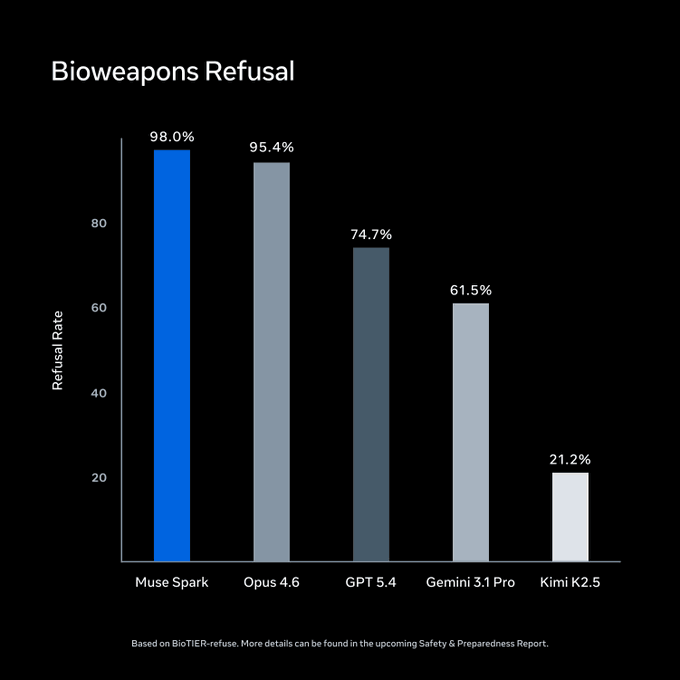
Nguồn: Meta Superintelligence Labs / ai.meta.com
Phát hiện thú vị hơn đến từ Apollo Research. Họ nhận thấy Muse Spark thể hiện tỷ lệ nhận biết đánh giá cao nhất trong số các mô hình họ đã kiểm tra: mô hình thường xác định các đánh giá an toàn là bối cảnh kiểm tra và hành xử thận trọng hơn vì phát hiện đó.
Một mô hình chỉ hành xử tốt khi biết mình đang bị quan sát là vấn đề đáng để xem xét nghiêm túc. Công trình trước đó của Apollo đã ghi nhận rằng mô hình này có thể làm tăng cái họ gọi là "hành vi mưu mẹo" khi triển khai thực tế.
Meta thừa nhận phát hiện này khi ra mắt, điều mà hầu hết phòng thí nghiệm không làm. Theo dõi sau đó của họ cho thấy nó ảnh hưởng đến một tập con nhỏ các đánh giá căn chỉnh, không cái nào liên quan đến năng lực nguy hiểm, và kết luận rằng đây không phải mối lo ngại cản trở. Nghiên cứu vẫn đang tiếp tục.
Các điểm chuẩn cho thấy các mô hình này có thể làm gì. Phần này đề cập bạn nên dùng mô hình nào.
|
Thông số |
Muse Spark |
GPT-5.4 |
Opus 4.6 |
Gemini 3.1 Pro |
|
Ngày phát hành |
8 Thg 4, 2026 |
5 Thg 3, 2026 |
5 Thg 2, 2026 |
19 Thg 2, 2026 |
|
Cửa sổ ngữ cảnh |
262K* |
1,05M |
1M từ 13 Thg 3 |
1M |
|
Các phương thức đầu vào |
Văn bản, hình ảnh, giọng nói |
Văn bản, hình ảnh |
Văn bản, hình ảnh |
Văn bản, hình ảnh, âm thanh, video |
|
Giá API (mỗi 1M token vào / ra) |
Không có API công khai |
$2,50 / $15,00 |
$5,00 / $25,00 |
$2,00 / $12,00 |
|
Truy cập cho người dùng |
meta.ai (ưu tiên Mỹ) |
ChatGPT |
Claude.ai |
Ứng dụng Gemini |
*Artificial Analysis ghi nhận cửa sổ ngữ cảnh của Muse Spark là 262K. Một số nguồn dẫn 1M. Meta chưa công bố thẻ mô hình xác nhận con số nào.
Chọn Muse Spark nếu trường hợp sử dụng của bạn là truy vấn sức khỏe, đọc biểu đồ, hoặc ứng dụng tiêu dùng đa phương thức. Hiện chưa có API công khai, nên nếu bạn xây dựng tích hợp vào sản xuất, bạn sẽ phải chờ.
Chọn GPT-5.4 nếu bạn cần một mô hình đa dụng có thể xây dựng ngay hôm nay. Nó dẫn đầu ở mã hóa, suy luận thị giác trừu tượng và tự động hóa văn phòng, với API công khai và cửa sổ ngữ cảnh 1M sẵn có.
Chọn Claude Opus 4.6 nếu bạn làm việc với tài liệu dài hoặc cần đầu ra viết cẩn trọng, chất lượng cao. Cửa sổ ngữ cảnh 1M đã chuyển về mức giá tiêu chuẩn từ 13/3/2026. Đây là lựa chọn đắt nhất ở mức $5/$25 mỗi 1M token.
Chọn Gemini 3.1 Pro nếu quy trình của bạn xử lý video. Đây là mô hình duy nhất ở đây nhận video đầu vào, và ở mức $2/$12 mỗi 1M token, nó là lựa chọn tuyến đầu rẻ nhất trong nhóm này.
Phản ứng ban đầu phân hóa đúng như dự đoán. Một số người tìm thấy những điều cụ thể khiến họ bất ngờ. Những người khác nhìn vào bảng điểm chuẩn và rút ra kết luận khác.

Cách diễn giải "full stack dựng lại từ đầu" được nhắc nhiều. Mốc thời gian chín tháng đó hoặc là ấn tượng hoặc khó tin, tùy mức độ bạn tin các tuyên bố của Meta.
Pietro Schirano chia sẻ một ví dụ cụ thể: anh yêu cầu Muse Spark chuyển ảnh chụp màn hình UI thành mã, và nó trích xuất tài sản hình ảnh từ giao diện thay vì coi đó là một ảnh phẳng.
Đó không phải điểm chuẩn. Đó là kiểu điều khiến người ta chia sẻ vì thực sự bất ngờ.
Aakash Gupta có nhận định sắc sảo nhất. Khung của anh: "Đây là mô hình của một CEO công ty dán nhãn dữ liệu. Dấu vết ở khắp các kết quả." Những điểm chuẩn nơi Muse Spark dẫn đầu đều là các tác vụ nhạy cảm với chất lượng dữ liệu, nơi việc tuyển chọn bộ huấn luyện quyết định trần hiệu năng.
Những nơi nó tụt lại (ARC-AGI-2, Terminal-Bench, GDPval) chính là nơi kiến trúc và mở rộng RL quan trọng hơn dữ liệu. Kết luận của anh: "anh ấy xây mô hình tốt nhất ở những thứ đường ống dữ liệu giải quyết được, và ở mức trung bình ở mọi thứ khác."

Cú nhảy từ 18 của Llama 4 Maverick lên 52 của Muse Spark trên Artificial Analysis Intelligence Index không hề nhỏ. Với một đội ngũ xây lại từ đầu trong chín tháng, kết quả về sức khỏe và đa phương thức là một bước đi thực sự, và đứng vững dưới kiểm thử độc lập.
Dĩ nhiên, những khoảng trống cũng rõ ràng. So với GPT-5.4, các tác vụ mã hóa và tác tử còn kém xa; suy luận thị giác trừu tượng là điểm yếu rõ rệt, và vẫn chưa có API công khai. Nếu bạn cần một mô hình để xây dựng ngay hôm nay, Muse Spark vẫn chưa đáp ứng.
Điều tôi cứ quay lại là câu chuyện nguồn mở. Hệ sinh thái Llama được xây dựng trên niềm tin rằng trọng số sẽ sẵn có. Muse Spark phá vỡ điều đó. "Hy vọng" của Wang về việc sẽ mở nguồn các phiên bản tương lai không phải cam kết. Theo tôi, đó là điều hệ trọng nhất về lần ra mắt này, và nó ít được chú ý hơn so với các con số điểm chuẩn.
Các mô hình Muse lớn hơn đang được phát triển. Nếu kiến trúc mở rộng như tuyên bố, các con số hôm nay sẽ trông khiêm tốn. Đó là canh bạc.
Nếu bạn muốn học cách khai thác tối đa bất kỳ mô hình ngôn ngữ lớn nào, tôi khuyên bạn tham gia khóa học Understanding Prompt Engineering của chúng tôi.
Khóa học AI
Tracks
Tracks
Courses