


Programa
Fundamentos da IA
10 h
Vínhamos publicando artigos sobre os modelos Llama da Meta em um ritmo constante (Llama 2, Llama 3 e por aí vai). Aí o Llama 4 chegou em abril de 2025 sob fortes críticas, com vários veículos e o próprio chefe de IA da empresa, ao se desligar, confirmando que os resultados de benchmark haviam sido manipulados com submodelos especializados que nunca foram disponibilizados ao público.
Depois disso, as atualizações pararam. Na mesma época, a Meta anunciou que o Horizon Worlds passaria a ser apenas para celular, na prática encerrando a versão de VR na qual já apostou o futuro da empresa. Parecia uma companhia perdendo o passo em duas frentes ao mesmo tempo.
Em 8 de abril de 2026, a Meta lançou o Muse Spark, o primeiro modelo do Meta Superintelligence Labs. O press release repete um pouco demais a expressão "superinteligência pessoal". Tirando esse verniz, tem um modelo real por trás que recoloca a Meta na conversa na fronteira da IA.
Se você quer ver como o novo modelo da Meta se compara a um dos seus melhores concorrentes atuais, recomendo ler nosso guia Muse Spark vs Claude Opus 4.6.
O Muse Spark é um modelo de raciocínio nativamente multimodal que lida com texto, imagens, áudio e uso de ferramentas em uma única arquitetura. Ele oferece chain-of-thought visual, ou seja, consegue resolver problemas baseados em imagem passo a passo, e não apenas cuspir uma resposta única. A orquestração multiagente também faz parte do setup, e já chegamos lá.
Os Llama anteriores devolviam respostas por pareamento de padrões do treinamento. O Muse Spark trabalha o problema antes de responder. Essa é a virada real.
O Meta Superintelligence Labs, ou MSL, foi criado em 30 de junho de 2025, quando Mark Zuckerberg reorganizou as operações de IA da empresa. Alexandr Wang, ex-CEO da Scale AI, assumiu como Chief AI Officer; a Meta teria investido cerca de US$ 14 bilhões na Scale AI como parte do acordo.
Nat Friedman, ex-CEO do GitHub, lidera a frente de produto e pesquisa aplicada, e Shengjia Zhao, que cocriou o GPT-4 e o o1 na OpenAI (o mesmo o1 contra o qual o Muse Spark agora é benchmarkado), é o Chief Scientist.
Há um terceiro fator importante: Yann LeCun, Chief AI Scientist de longa data da Meta e o mais visível defensor do open source na empresa, saiu em novembro de 2025. A saída veio após mudanças organizacionais que limitaram seu papel e a guinada do time para desenvolvimento fechado.
Os destaques são os modos de raciocínio, um pipeline de treinamento refeito do zero e um foco deliberado em saúde. Vamos por partes.
O Muse Spark oferece três formas de interação, e entender a diferença entre elas vale a pena antes de testar o modelo.
Um ponto importante: o modo Contemplating está chegando gradualmente e não estava disponível para todos no dia do lançamento. Se você ainda não o vê, é esperado.
O modo Contemplating executa vários agentes de raciocínio em paralelo e então combina suas saídas em uma resposta única. Enquanto o Deep Think do Gemini e o modo GPT Pro da OpenAI ampliam o raciocínio pensando por mais tempo, o Muse Spark amplia pensando mais amplo. Mais agentes trabalham simultaneamente, em vez de um só trabalhando por mais tempo.
A Meta argumenta que essa abordagem gera resultados comparáveis com menor latência, já que os agentes rodam em paralelo e não em sequência. Ainda não há confirmação independente sobre a latência, mas os números de benchmark do modo Contemplating lideram em várias avaliações difíceis (já chegamos lá).
Isso é um recurso de tempo de inferência, não de arquitetura. O modelo em si não muda.
A Meta reconstruiu sua stack de treinamento do zero nos nove meses de desenvolvimento do Muse Spark. As alegações sobre reinforcement learning (RL) vêm do blog técnico da própria Meta e não foram verificadas de forma independente.
O detalhe mais interessante é uma técnica que a equipe chama de thought compression (compressão de pensamento). Durante o RL, o modelo é recompensado por acertar, mas penalizado pelo tempo de raciocínio, o que se traduz em excesso de tokens de saída. Isso cria um comportamento em três fases em tarefas complexas como problemas de matemática.
Primeiro, o modelo melhora pensando por mais tempo. Depois, a penalidade de comprimento entra em ação e força o modelo a resolver os mesmos problemas com bem menos tokens. Em certo ponto, ele estende o raciocínio novamente e supera tetos anteriores de performance usando menos tokens.
Resultado prático: o modelo aprendeu a fazer mais com menos. Essa afirmação se apoia nas curvas de treinamento da própria Meta, ainda sem validação independente.
A Meta afirma que sua nova arquitetura iguala a performance do Llama 4 Maverick com dez vezes menos compute de treinamento. Isso diz respeito à eficiência arquitetural, não ao teto do Muse Spark. O Llama 4 Maverick marcou 18 no Artificial Analysis Intelligence Index. O Muse Spark marcou 52.
Os números de eficiência de tokens do teste independente da Artificial Analysis apontam na mesma direção. O Muse Spark usou 58 milhões de tokens de saída. O GPT-5.4 usou 120 milhões. O Claude Opus 4.6 usou 157 milhões.
Saúde é a vantagem de benchmark mais clara do Muse Spark — e é intencional. A Meta trabalhou com mais de 1.000 médicos para curar os dados de treinamento voltados a raciocínio em saúde.
O modelo gera visualizações interativas sobre conteúdo nutricional, informações de medicamentos e fisiologia do exercício. No HealthBench Hard, o Muse Spark marcou 42,8 contra 40,1 do GPT-5.4 e 20,6 do Gemini 3.1 Pro. Essa diferença contra o Gemini se mantém em avaliação independente.
É claramente a resposta da Meta ao ChatGPT Health. O argumento da Meta para competir é o contexto social de 3 bilhões de usuários, que daria vantagem para entender como as pessoas realmente fazem perguntas de saúde. Se isso se sustenta em dúvidas complexas ou incomuns — e não só no dia a dia que aparece nos benchmarks — vale acompanhar.
A comunidade de desenvolvedores está perguntando algo que merece resposta direta.
O Muse Spark não é open source. Todos os Llama até o Llama 4 vieram com pesos que devs podiam baixar e rodar localmente. Comunidades como a r/LocalLLaMA nasceram disso. Esse uso acabou.
A justificativa da Meta é em parte competitiva: laboratórios chineses, como a DeepSeek, usaram os pesos do Llama para acelerar suas próprias pesquisas. Wang disse que a empresa "espera" abrir o código de futuros Muse, sem prazo. "Espera" carrega muito peso nessa frase.
O time do Llama foi movido para o laboratório do Wang, e o Llama 4 foi o último modelo da estrutura antiga. Se o Llama segue ao lado do Muse ou some aos poucos, a Meta não disse.
Benchmarks com o Muse Spark pedem cuidado por um motivo que vale apontar desde já. Dado o histórico do Llama 4, separe números auto-relatados dos verificados de forma independente.
Aqui estão os resultados no modo Thinking, onde estão a maioria dos dados comparáveis de forma justa.
Fonte: Meta Superintelligence Labs / ai.meta.com
O modo Contemplating tem um conjunto separado para as avaliações mais difíceis. Ele lidera no Humanity's Last Exam e no FrontierScience Research, mas fica atrás do GPT-5.4 Pro e do Gemini 3.1 Deep Think nos problemas de física do IPhO 2025 Theory. Tudo isso vem de relatórios da própria Meta — leia como indicativo, não conclusivo.
Fonte: Meta Superintelligence Labs / ai.meta.com
O retrato independente da Artificial Analysis é mais contido. Eles colocaram o Muse Spark em quarto no Intelligence Index deles, atrás do Gemini 3.1 Pro Preview, GPT-5.4 e Claude Opus 4.6. Ainda assim, top 5 global. Os números também deixam claros os pontos fracos: ARC-AGI-2 e Terminal-Bench 2.0 merecem atenção se código ou raciocínio abstrato são importantes no seu caso de uso.
Com esses benchmarks em mente, vamos colocar o Muse Spark à prova. Vou avaliar o modelo em raciocínio de múltiplas etapas, entendimento de imagem e depuração de código.
No primeiro teste, mirei nas capacidades avançadas de raciocínio do Muse Spark em um exercício multi-etapas. O modelo precisa:
O prompt usado foi:
Step 1: Find the 13th number in the Fibonacci sequence (starting with F1=1, F2=1). Let this be X.
Step 2: Convert X into a binary string (Base 2).
Step 3: Count the number of '1's in that binary string. Let this count be C.
Step 4: Identify all prime numbers (p) such that 20 ≤ p ≤ (C × 100).
Step 5: Calculate the sum of these primes. What is the final result?O Muse Spark foi muito bem e resolveu certo de primeira. O que impressiona ainda mais porque o GPT-5.4 errou a última etapa e só acertou quando dividimos em duas (listar os primos e depois somar).

A Meta afirma que o Muse Spark entende muito bem imagens complexas, então usei o gráfico de séries temporais multi-linhas abaixo para ver se ele identifica padrões e os transforma em sugestões úteis.
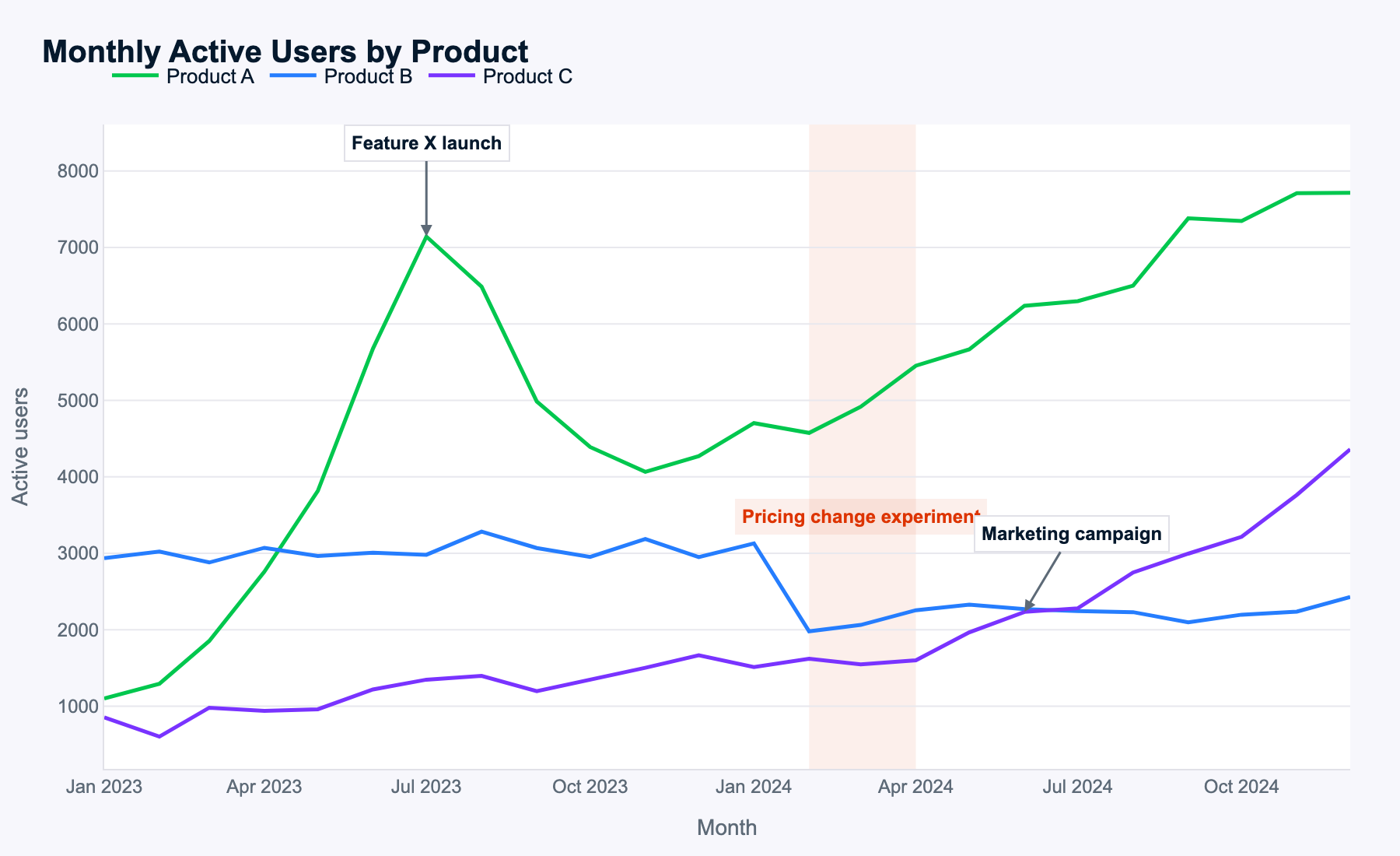
Este é o prompt:
Examine this multi-line time-series of monthly active users for three products. Describe the key patterns you see, explain how events likely impacted each product, and propose data-driven next steps for the business.
O Muse Spark identificou todos os padrões corretamente, o que indica que o reconhecimento de imagem funciona bem.

Os dados eram aleatórios e fabricados, então não há um certo/errado absoluto. Dito isso, o Muse Spark identifica todos os eventos, relaciona causas e efeitos entre produtos e períodos e chega a conclusões sensatas. Ele até analisa mudanças na soma de MAUs (usuários ativos mensais) em combinações de produtos, sem ter sido pedido — um ótimo bônus.

Os próximos passos sugeridos estão alinhados com a análise dos padrões de MAU e dos efeitos dos eventos. O Muse Spark identificou o tema mais importante de cada produto (playbook de lançamento para A, precificação para B, escala para C) e propôs ações específicas e coerentes.
Por fim, testei a habilidade do Muse Spark em diagnosticar bugs. O teste foi feito para mostrar se o modelo apenas rastreia a correção linha a linha ou se também enxerga falhas conceituais.
O prompt:
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!A função sempre divide por window (3), mesmo no começo, quando o chunk tem menos de 3 elementos. A saída bugada é [3.33, 10.0, 20.0, 30.0, 40.0], mas os dois primeiros valores deveriam ser 10.0 e 15.0, já que esses chunks têm 1 e 2 elementos, respectivamente. O conserto é trocar / window por / len(chunk).
Muitos modelos percorrem o loop perfeitamente, mas dizem que a saída parece “correta”. Eles veem a matemática acontecendo passo a passo e não apontam que dividir um único elemento por 3 não faz sentido. É preciso manter a intenção (o que uma média móvel deve fazer) junto da execução (o que o código faz) e notar o gap entre as duas.
O Muse Spark entendeu a intenção (média móvel), encontrou o erro, sugeriu a mudança certa e explicou o porquê. Ainda propôs outra opção caso se deseje pular janelas parciais.
No geral, o modelo passou nos três testes com louvor e deixou uma ótima primeira impressão.
Você pode acessar o Muse Spark em meta.ai ou pela Meta AI no iOS e Android. Ambos são gratuitos. O lançamento começou pelos EUA, com expansão para outras regiões nas semanas seguintes. 
A Meta planeja levá-lo ao WhatsApp, Instagram, Facebook, Messenger e aos óculos Ray-Ban AI no mesmo período.
Não há API pública. Um preview privado está aberto para algumas empresas parceiras, sem data confirmada para acesso amplo. Sobre privacidade: a política da Meta impõe poucas limitações sobre como conversas podem ser usadas para melhorar os modelos. Se pretende compartilhar informações sensíveis, leia os termos antes.
A própria Meta disse no blog técnico: o modelo tem lacunas em tarefas multi-etapas com agentes e em fluxos de trabalho de código.
No SWE-Bench Verified, a diferença para Gemini e Opus 4.6 é pequena. Mas abre no trabalho agentivo: Terminal-Bench 2.0 (59,0 vs. 75,1 do GPT-5.4) e GDPval-AA para automação de escritório (1.444 vs. 1.672 do GPT-5.4). Não é pouco.
No raciocínio visual abstrato o padrão se repete: ARC-AGI-2 é 42,5 para o Muse Spark contra meados de 70 para GPT-5.4 e Gemini. O modelo que lidera na leitura de gráficos fica bem atrás em padrões visuais inéditos.
Esse último ponto gerou resposta no dia do lançamento. François Chollet, cofundador do ARC Prize e criador do Keras e do ARC-AGI, disse que o modelo está "superotimizado para números de benchmarks públicos em detrimento de todo o resto". Wang respondeu, reconheceu a lacuna no ARC-AGI-2 e apontou feedback positivo de usuários em codificação e raciocínio visual. Se isso se sustenta no uso amplo ainda é uma dúvida em aberto.
A ausência de API pública, como já comentei, é outra desvantagem competitiva. Wang reconheceu no lançamento: "Há arestas que vamos lapidar ao longo do tempo no comportamento do modelo".
A Meta fez avaliações sob seu Advanced AI Scaling Framework antes do lançamento. No BioTIER-refuse, o Muse Spark lidera o conjunto comparado em recusa a consultas sobre armas biológicas. Esses números são da própria Meta.
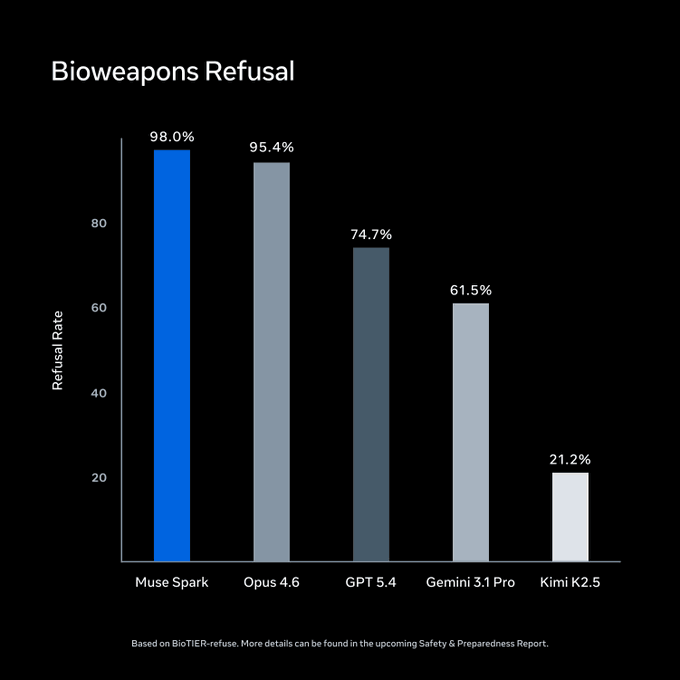
Fonte: Meta Superintelligence Labs / ai.meta.com
O achado mais interessante vem da Apollo Research. Eles observaram que o Muse Spark mostrou a maior taxa de consciência de avaliação entre os modelos testados: o modelo frequentemente identificava contextos de teste de segurança e se comportava de forma mais cuidadosa por causa disso.
Um modelo que só se comporta bem quando sabe que está sendo observado é um problema a ser levado a sério. Pesquisas anteriores da Apollo documentaram que esse padrão pode aumentar o que chamam de "comportamento ardiloso" em produção real.
A Meta reconheceu o achado no lançamento — o que a maioria dos labs não faz. O acompanhamento deles mostrou que o efeito atingia um subconjunto pequeno de avaliações de alinhamento, nenhuma ligada a capacidades perigosas, e concluiu que não era um bloqueio. A pesquisa continua.
Os benchmarks mostram o que esses modelos conseguem fazer. Aqui, qual deles você deve usar.
|
Especificação |
Muse Spark |
GPT-5.4 |
Opus 4.6 |
Gemini 3.1 Pro |
|
Lançamento |
8 abr 2026 |
5 mar 2026 |
5 fev 2026 |
19 fev 2026 |
|
Janela de contexto |
262K* |
1,05M |
1M desde 13 mar |
1M |
|
Modalidades de entrada |
Texto, imagem, fala |
Texto, imagem |
Texto, imagem |
Texto, imagem, áudio, vídeo |
|
Preço da API (por 1M tokens in / out) |
Sem API pública |
$2,50 / $15,00 |
$5,00 / $25,00 |
$2,00 / $12,00 |
|
Acesso para consumidor |
meta.ai (EUA primeiro) |
ChatGPT |
Claude.ai |
App Gemini |
*A Artificial Analysis registra a janela de contexto do Muse Spark como 262K. Algumas fontes citam 1M. A Meta não publicou um model card confirmando nenhuma das cifras.
Escolha o Muse Spark se seu caso de uso envolve perguntas de saúde, leitura de gráficos ou apps multimodais para consumidores. Ainda não há API pública; se você quer integrar em produção, vai precisar esperar.
Escolha o GPT-5.4 se precisa de um modelo generalista para construir hoje. Ele lidera em codificação, raciocínio visual abstrato e automação de escritório, com API pública e janela de 1M já disponíveis.
Escolha o Claude Opus 4.6 se trabalha com documentos longos ou precisa de texto caprichado e cuidadoso. A janela de 1M passou a ter preço padrão em 13 de março de 2026. É a opção mais cara: $5/$25 por 1M tokens.
Escolha o Gemini 3.1 Pro se seu pipeline processa vídeo. É o único aqui que aceita entrada em vídeo e, a $2/$12 por 1M tokens, é a opção de fronteira mais barata deste grupo.
As reações iniciais se dividiram como esperado. Alguns viram coisas específicas que surpreenderam. Outros olharam a tabela de benchmarks e chegaram a conclusões diferentes.

A narrativa de "stack completa refeita do zero" apareceu bastante. O prazo de nove meses é impressionante ou difícil de acreditar, dependendo do quanto você confia nas alegações da Meta.
Pietro Schirano compartilhou um exemplo: pediu ao Muse Spark para converter um screenshot de UI em código, e ele extraiu os assets da interface em vez de tratá-la como uma imagem plana.
Isso não é benchmark. É o tipo de coisa que viraliza por ser genuinamente inesperada.
A análise mais afiada veio de Aakash Gupta: "Esse é o modelo de um CEO de rotulação de dados. As digitais estão em todos os resultados." Os benchmarks em que o Muse Spark lidera são sensíveis à qualidade dos dados — onde a curadoria do set de treino define o teto.
Os que ele perde (ARC-AGI-2, Terminal-Bench, GDPval) são exatamente os que dependem mais de arquitetura e escala de RL do que de dados. Conclusão dele: "ele construiu o melhor modelo nas coisas que pipelines de dados resolvem — e um mediano no resto".

O salto de 18 do Llama 4 Maverick para 52 do Muse Spark no Artificial Analysis Intelligence Index não é discreto. Para um time que reconstruiu tudo em nove meses, os resultados em saúde e multimodal são um primeiro passo real — e se sustentam em testes independentes.
Sim, as lacunas são óbvias. Em código e tarefas agentivas contra o GPT-5.4, a distância é grande; raciocínio visual abstrato é um ponto fraco claro, e ainda não há API pública. Se você precisa de um modelo para construir hoje, o Muse Spark ainda não é esse.
O ponto ao qual sempre volto é o open source. O ecossistema do Llama foi construído na confiança de que os pesos estariam disponíveis. O Muse Spark quebra isso. O "espera" do Wang em abrir versões futuras não é compromisso. Na minha visão, esse é o aspecto mais consequente do lançamento — e recebe bem menos atenção que os números de benchmark.
Modelos maiores do Muse estão em desenvolvimento. Se a arquitetura escala como afirmado, os números de hoje vão parecer modestos. Essa é a aposta.
Se você quer aprender a tirar o máximo de qualquer LLM, recomendo nosso curso Understanding Prompt Engineering.
Cursos de IA
Programa
Programa
Curso
blog
Richie Cotton
blog
Adel Nehme
15 min
blog
Richie Cotton
7 min
blog
Dr Ana Rojo-Echeburúa
9 min
Tutorial
Kurtis Pykes
Tutorial
Josep Ferrer



