
Kursus
Dasar-Dasar PySpark
4 Hr
157.6K
Mari pahami arsitektur Apache Parquet melalui fitur-fiturnya yang utama:
Berbeda dengan format berbasis baris seperti CSV, Parquet mengatur data dalam kolom. Artinya saat kita menjalankan kueri, ia hanya mengambil kolom spesifik yang dibutuhkan alih-alih memuat semuanya. Ini meningkatkan kinerja dan mengurangi penggunaan I/O.
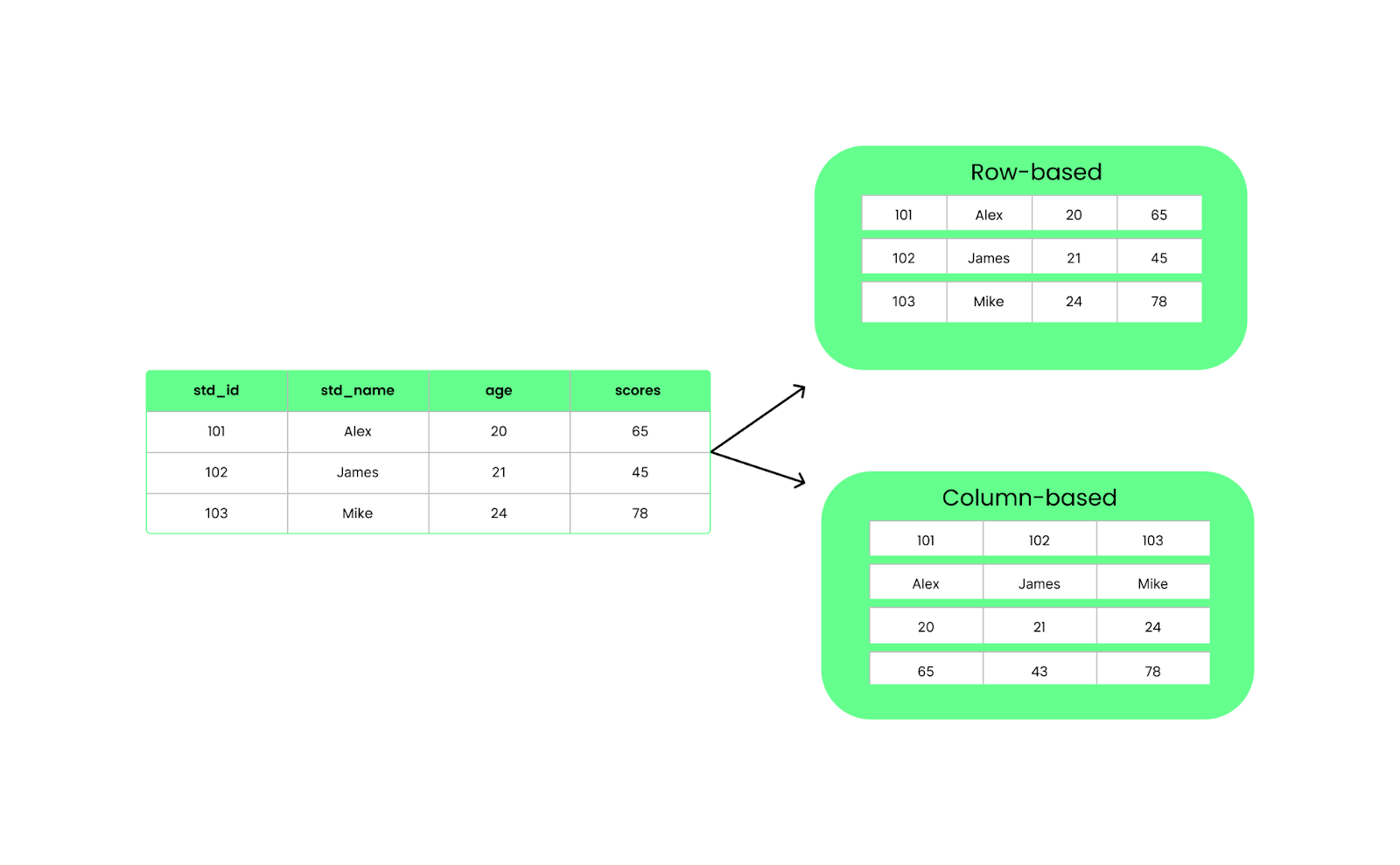
Struktur berbasis baris vs kolom. Gambar oleh Penulis.
File Parquet dibagi ke dalam row group, yang menampung sekumpulan baris. Setiap row group dipecah menjadi column chunk, masing-masing berisi data untuk satu kolom. Chunk ini kemudian dibagi lagi menjadi bagian yang lebih kecil yang disebut page, yang dikompresi untuk menghemat ruang.
Selain itu, file Parquet menyimpan informasi tambahan di bagian footer, disebut metadata, yang membantu menemukan dan membaca hanya data yang kita butuhkan.
Berikut tampilan strukturnya:
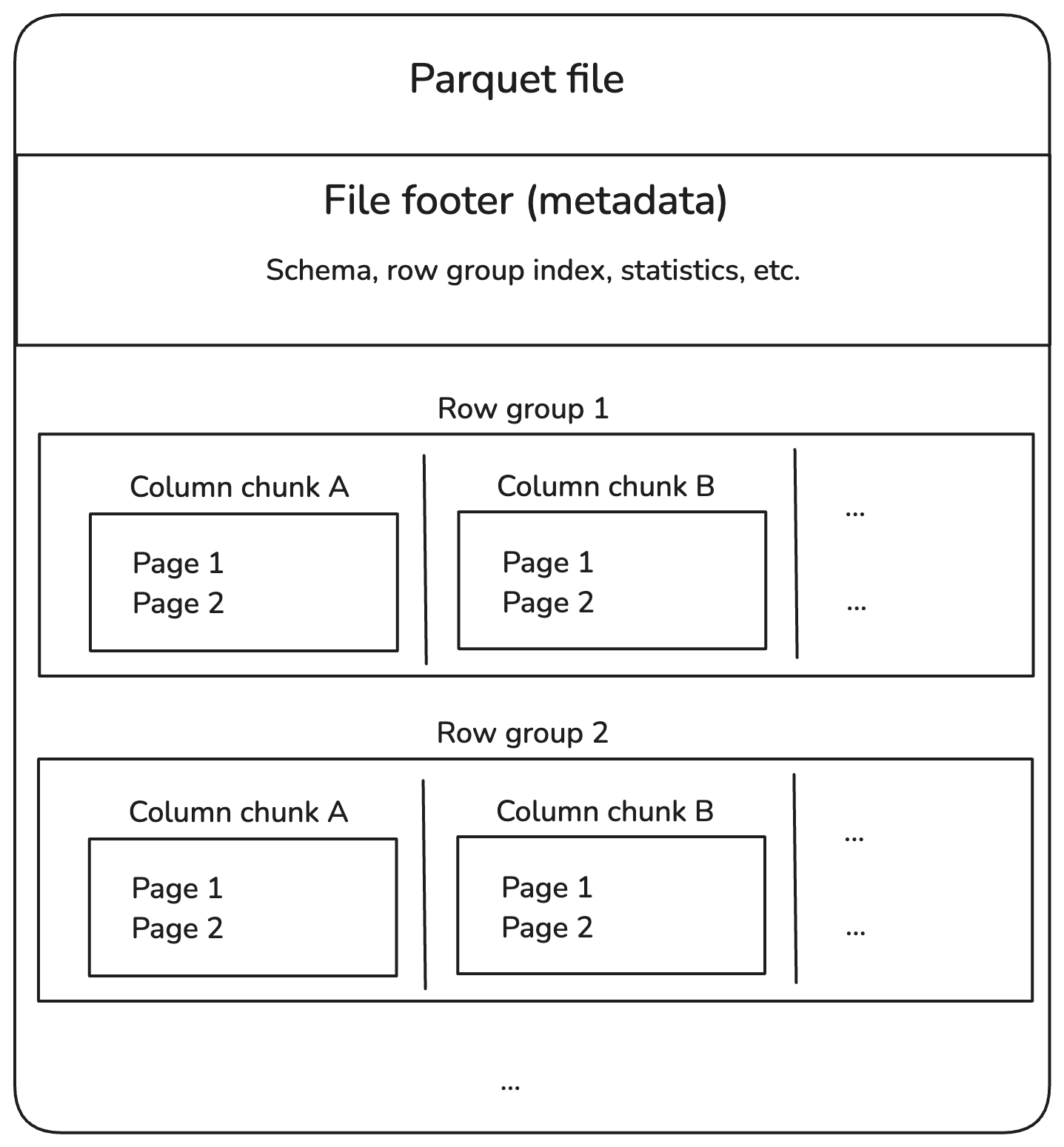
Struktur internal file Parquet. Gambar oleh Penulis.
Mari kita uraikan setiap komponen pada diagram di atas.
Row group
Column chunk
Page
Footer (metadata)
Seperti disebutkan, Parquet mengompresi data per kolom menggunakan metode kompresi seperti Snappy dan Gzip. Ia juga menggunakan dua teknik encoding:
Ini mengurangi ukuran file dan mempercepat pembacaan data, yang sangat membantu saat Anda bekerja dengan big data.
Evolusi skema berarti memodifikasi struktur kumpulan data, seperti menambah atau mengubah kolom. Kedengarannya sederhana, tetapi bergantung pada bagaimana data Anda disimpan, memodifikasi skema bisa lambat dan memakan banyak sumber daya.
Mari pahami ini dengan membandingkan evolusi skema CSV dan Parquet.
Misalkan Anda memiliki file CSV dengan kolom seperti student_id, student_name, dan student_age. Jika Anda ingin menambahkan kolom scores baru, Anda harus melakukan hal berikut:
scores.NULL).CSV adalah format berbasis teks sederhana tanpa dukungan skema bawaan. Ini berarti setiap perubahan struktur memerlukan penulisan ulang seluruh file, dan sistem lama yang membaca file yang dimodifikasi dapat gagal jika mereka mengharapkan struktur yang berbeda!
Dengan Parquet, Anda dapat menambah, menghapus, atau memperbarui field tanpa merusak file yang sudah ada. Seperti yang telah kita lihat sebelumnya, Parquet menyimpan informasi skema di dalam footer file (metadata), sehingga memungkinkan evolusi skema tanpa memodifikasi file yang ada.
Begini cara kerjanya:
NULL alih-alih membuat kueri gagal.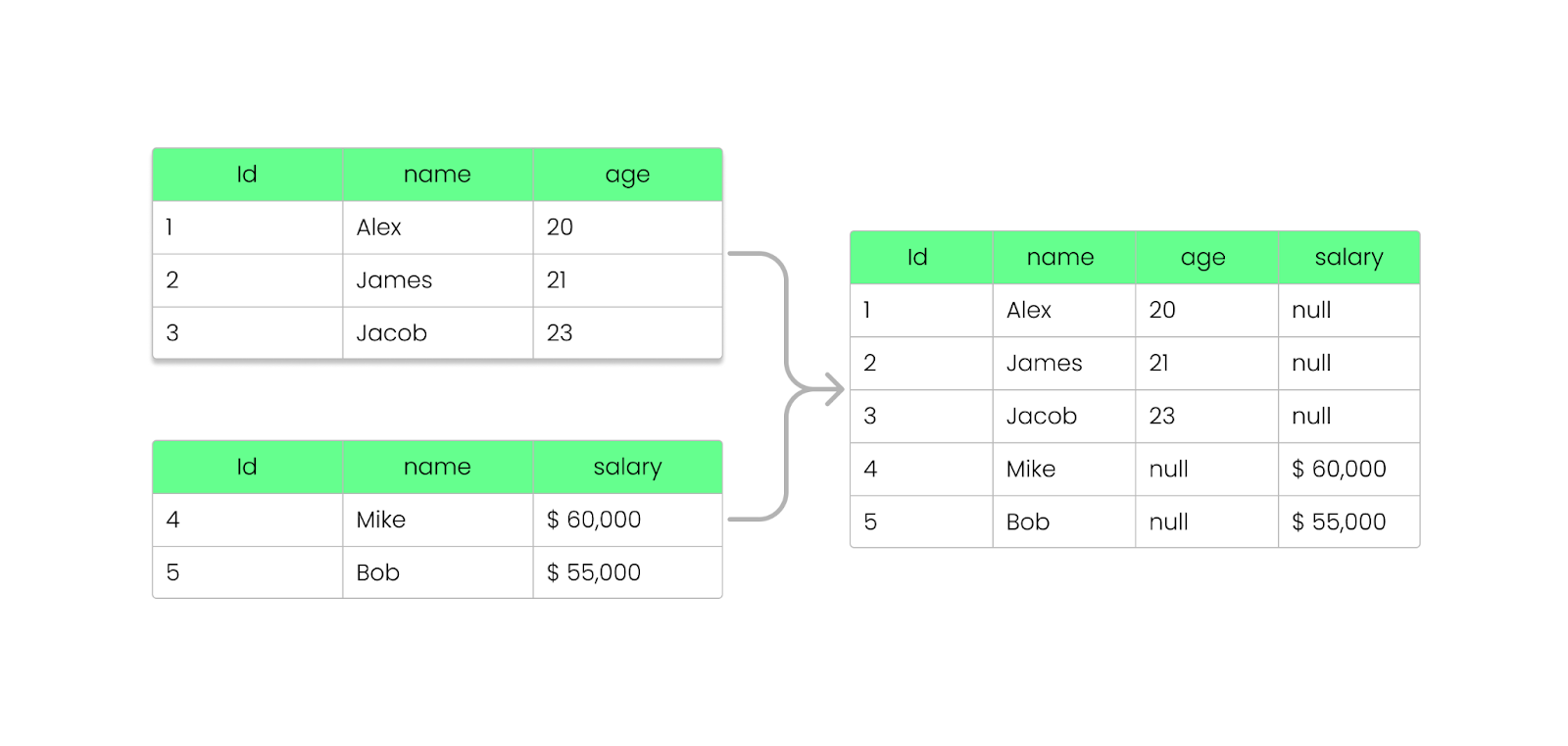
Menambahkan kolom ke file Parquet tanpa merusaknya. Gambar oleh Penulis.
Parquet mendukung berbagai bahasa pemrograman, seperti Java, Python, C++, dan Rust. Ini berarti pengembang dapat dengan mudah menggunakannya terlepas dari platform mereka. Parquet juga terintegrasi secara native dengan kerangka kerja big data seperti Apache Spark, Hive, Presto, Flink, dan Trino, sehingga memastikan pemrosesan data yang efisien dalam skala besar.
Jadi, apakah Anda menggunakan Python (melalui PySpark) atau bahasa lain, Parquet dapat mengelola data dengan cara yang memudahkan pengkuerian dan analisis di berbagai platform.
Jika Anda baru dalam kerangka kerja big data, saya merekomendasikan mengikuti kursus Introduction to PySpark. Ini cara yang bagus untuk mulai belajar.
Sekarang Anda sudah memahami dasar Apache Parquet, saya akan memandu Anda menulis, membaca, dan mengintegrasikan file Parquet dengan pandas, PyArrow, dan kerangka kerja big data lain seperti Spark.
Untuk menyimpan DataFrame sebagai file Parquet, Anda memerlukan pandas dan engine Parquet seperti PyArrow:
pip install pandas pyarrowSekarang, tulis file Parquet menggunakan kode berikut:
import pandas as pd
# Sample DataFrame
data = {
"Name": ["Alice", "Bob", "Charlie"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
}
df = pd.DataFrame(data)
# Write to Parquet file
df.to_parquet("data.parquet", engine="pyarrow", index=False)
print("Parquet file written successfully!")
Tulis file Parquet dengan pandas. Gambar oleh Penulis.
Berikut kode sederhana untuk membaca file Parquet Anda:
import pandas as pd
# Read the Parquet file
df = pd.read_parquet("data.parquet", engine="pyarrow")
print("Data from Parquet file:")
print(df)
Baca file Parquet dengan pandas. Gambar oleh Penulis.
PyArrow adalah alat dari proyek Apache Arrow yang memudahkan bekerja dengan file Parquet. Berikut cara menulis file Parquet menggunakan PyArrow:
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# Sample data
df = pd.DataFrame({
"Name": ["Jacob", "Lauren", "Oliver"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
})
# Convert to a PyArrow table
table = pa.Table.from_pandas(df)
# Write to Parquet file
pq.write_table(table, "data.parquet")
print("Parquet file written successfully!")
Tulis file Parquet dengan PyArrow. Gambar oleh Penulis.
Berikut cara membaca file Parquet menggunakan PyArrow:
import pyarrow.parquet as pq
# Read the Parquet file
table = pq.read_table("data.parquet")
# Convert to a pandas DataFrame
df = table.to_pandas()
print("Data from Parquet file:")
print(df)
Baca file Parquet dengan PyArrow. Gambar oleh Penulis.
Kita dapat menggunakan Spark untuk membaca dan menulis file Parquet secara langsung. Unduh dari situs Apache Spark atau setel mengikuti instruksinya.
Setelah selesai, impor pustaka dan buat DataFrame:
from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName("SparkExample").getOrCreate()
# Define the schema for the dataset
schema = ["Name", "Age", "City"]
# Create a sample data
data = [
("Jacob", 30, "New York"),
("Lauren", 35, "Los Angeles"),
("Billy", 25, "Chicago")
]
# Create a DataFrame from the sample data
df = spark.createDataFrame(data, schema)
# Show the DataFrame
df.show()
Buat DataFrame contoh di Spark. Gambar oleh Penulis.
Selanjutnya, tulis DataFrame ini sebagai file Parquet:
# Write DataFrame to Parquet
df.write.parquet("data.parquet")Metode write.parquet() menyimpan DataFrame dalam format Parquet, dan file akan bernama employee.parquet. Sekarang, untuk membaca file Parquet ini, Anda dapat menggunakan kode berikut:
# Read the Parquet file
parquet_df = spark.read.parquet("data.parquet")
# Show the DataFrame
parquet_df.show()
Baca file Parquet. Gambar oleh Penulis.
Selain Spark, Parquet juga dapat bekerja dengan Hive. Saat Anda membuat tabel Hive, gunakan STORED AS PARQUET untuk menjadikan Parquet sebagai format penyimpanannya.
Selain membaca dan menulis, ada beberapa operasi dasar yang harus diketahui setiap pengembang karena berguna saat bekerja dengan file Parquet. Mari kita tinjau pada bagian ini.
Saya akan menggunakan pandas dan PyArrow untuk mengilustrasikan konsepnya.
Menambahkan data bermanfaat saat catatan baru perlu ditambahkan tanpa menulis ulang seluruh dataset.
import pyarrow.parquet as pq
import pyarrow as pa
# Load existing Parquet file
existing_table = pq.read_table("data.parquet")
# New data
new_data = pd.DataFrame({
"Name": ["David", "Emma"],
"Age": [40, 28],
"City": ["San Francisco", "Seattle"]
})
# Convert new data to PyArrow table
new_table = pa.Table.from_pandas(new_data)
# Concatenate both tables
merged_table = pa.concat_tables([existing_table, new_table])
# Write back to Parquet file
pq.write_table(merged_table, "data.parquet")Alih-alih memuat seluruh dataset, Anda dapat memilih hanya kolom yang diperlukan, sehingga mengurangi penggunaan memori dan meningkatkan performa. Ini jauh lebih cepat dibandingkan membaca seluruh dataset:
df = pd.read_parquet("data.parquet", columns=["Name", "Age"])
print(df)Parquet memungkinkan penyaringan yang efisien pada level penyimpanan, dikenal sebagai predicate pushdown, yang mencegah pemuatan data yang tidak diperlukan. Ini menghindari pemindaian seluruh file, membuat kueri jauh lebih cepat:
import pyarrow.parquet as pq
# Read only rows where Age > 30
table = pq.read_table("data.parquet", filters=[("Age", ">", 30)])
df = table.to_pandas()
print(df)Sering kali, file Parquet disimpan sebagai partisi terpisah. Anda dapat menggabungkannya menjadi satu file Parquet. Ini berguna saat menggabungkan dataset dari sumber berbeda:
import pyarrow.parquet as pq
import pyarrow as pa
# List of Parquet files to merge
file_list = ["data_part1.parquet", "data_part2.parquet"]
# Read all files and merge
tables = [pq.read_table(f) for f in file_list]
merged_table = pa.concat_tables(tables)
# Write merged Parquet file
pq.write_table(merged_table, "merged_data.parquet")Jika Anda memiliki file CSV yang sudah ada, mengonversinya ke Parquet menghemat ruang dan mempercepat pemrosesan, yang secara drastis mengurangi ukuran file dan meningkatkan performa baca:
df = pd.read_csv("data.csv")
df.to_parquet("data.parquet", engine="pyarrow", index=False)Partisi mengatur data ke dalam subdirektori berdasarkan nilai kolom, sehingga kueri menjadi jauh lebih cepat.
Berikut cara menulis data terpartisi:
df.to_parquet("partitioned_data/", engine="pyarrow", partition_cols=["City"])Kode di atas membuat subdirektori:
partitioned_data/City=New York/
partitioned_data/City=Los Angeles/
partitioned_data/City=Chicago/Lalu, Anda dapat membaca hanya partisi tertentu:
df = pd.read_parquet("partitioned_data/City=New York/")
print(df)Ini mempercepat analisis dengan hanya memindai partisi yang relevan!
Parquet mendukung algoritma kompresi seperti Snappy, Gzip, dan Brotli untuk mengurangi ukuran file:
df.to_parquet("compressed.parquet", engine="pyarrow", compression="snappy")Saat pertama kali menggunakan Apache Parquet, saya menyadari bahwa penyesuaian kecil dapat sangat meningkatkan efisiensinya. Berikut beberapa tips utama saya untuk mengoptimalkan Parquet dalam skenario nyata.
Jika Anda ingin menghemat penyimpanan, codec seperti Snappy atau Gzip dapat menjadi andalan Anda — Snappy menawarkan kompresi dan dekompresi cepat, cocok untuk skenario yang mengutamakan kecepatan.
Sebaliknya, Gzip ideal jika penyimpanan terbatas tetapi Anda dapat menerima pembacaan yang sedikit lebih lambat. Kuncinya adalah memahami beban kerja Anda — codec yang lebih cepat seperti Snappy sering kali lebih unggul jika Anda sering mengakses file. Namun, Gzip terbaik untuk data arsip.
Pecah data Anda menjadi subset logis, seperti membaginya berdasarkan tanggal, wilayah, atau field lain yang sering dikueri untuk mengurangi jumlah data yang dipindai saat kueri. Saya pernah bekerja dengan kumpulan data yang berisi log transaksi bertahun-tahun dan mempartisikannya berdasarkan tahun dan bulan untuk mengambil periode spesifik dalam hitungan detik, bukan menit.
Saya selalu memastikan kolom baru ditambahkan dengan cara yang tidak mengganggu proses yang ada. Ini biasanya berarti menambahkannya, bukan memodifikasi yang sudah ada. Untuk melakukannya, Anda dapat menggunakan dukungan evolusi skema Apache Spark agar transisi lebih mulus.
Mari bandingkan Parquet dengan format penyimpanan data lainnya.
Kita sudah membahas ini sepanjang blog, tetapi izinkan saya menekankannya lagi: Parquet dan CSV adalah dua format berbeda yang menangani data dengan cara berbeda.
Parquet mengatur data dalam kolom, sedangkan CSV menyusunnya dalam baris. Saat Anda menggunakan Parquet, semua data dari kolom yang sama dikelompokkan bersama, sehingga Anda dapat dengan mudah mengambil data dari kolom spesifik tanpa harus memilah semua yang lain. Ini lebih cepat dan memakan lebih sedikit ruang karena Parquet mengompresi data.
Format berbasis kolom Parquet. Gambar oleh Penulis.
CSV, di sisi lain, menyimpan data per baris. Ini sederhana dan bekerja baik untuk kumpulan data kecil, tetapi tidak ideal untuk yang besar. Setiap kueri harus membaca seluruh baris, bahkan jika Anda hanya membutuhkan beberapa kolom. Ini memperlambat proses dan membutuhkan lebih banyak memori untuk memprosesnya.
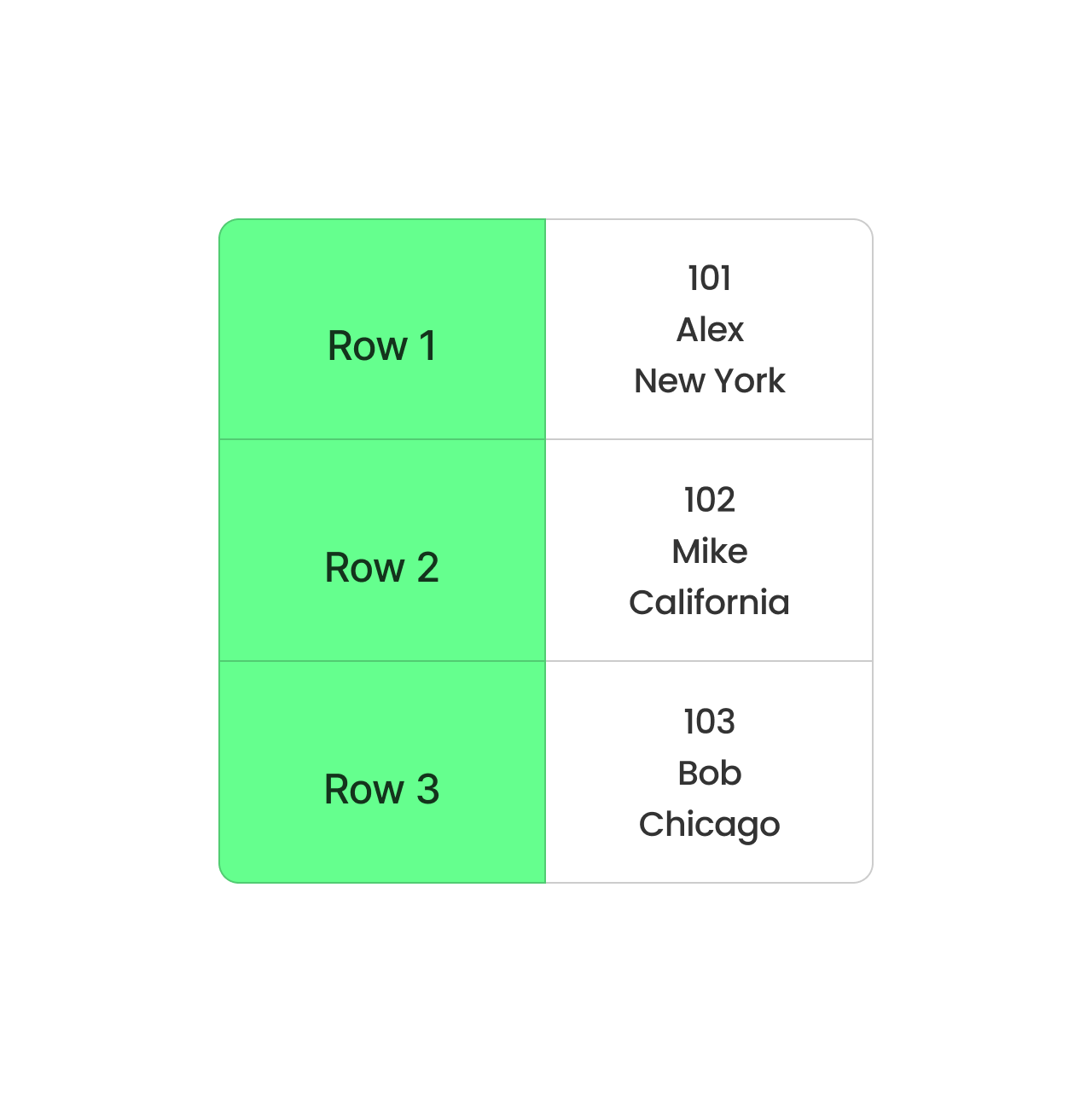
Format berbasis baris CSV. Gambar oleh Penulis.
JSON bagus untuk menyusun data dengan cara yang mudah dipahami, tetapi memiliki kelemahan: tidak terlalu efisien untuk penyimpanan atau kecepatan. Jadi, izinkan saya jelaskan mengapa Parquet lebih efisien daripada JSON melalui contoh.
Misalkan kita memiliki tabel data karyawan dengan tiga kolom: EmployeeID, Department, dan Location:
|
EmployeeID |
Department |
Location |
|
1 |
HR |
New York |
|
2 |
HR |
New York |
|
3 |
HR |
New York |
|
4 |
IT |
San Francisco |
|
5 |
IT |
San Francisco |
Sekarang, jika kita menyimpan data ini sebagai JSON, tampilannya akan seperti ini:
[
{"EmployeeID": 1, "Department": "HR", "Location": "New York"},
{"EmployeeID": 2, "Department": "HR", "Location": "New York"},
{"EmployeeID": 3, "Department": "HR", "Location": "New York"},
{"EmployeeID": 4, "Department": "IT", "Location": "San Francisco"},
{"EmployeeID": 5, "Department": "IT", "Location": "San Francisco"}
]Perhatikan bagaimana JSON mengulang nama kolom seperti EmployeeID, Department, dan Location untuk setiap catatan. Ia juga mengulang nilai HR dan New York berkali-kali. Ini membuat file jauh lebih besar dan lebih lambat.
Sekarang mari kita bayangkan (karena Parquet tidak dapat dibaca manusia) kita menyimpan data yang sama sebagai Parquet:
Alih-alih menyimpan per baris, Parquet mengatur data berdasarkan kolom dan mengompresi nilai yang berulang.
Avro adalah format berbasis baris. Ini sangat baik untuk tugas seperti streaming data atau memproses log, di mana Anda terus menambahkan catatan baru atau mengambil seluruh baris. Namun format berbasis kolom Parquet sangat cocok untuk analitik. Jika Anda menjalankan kueri untuk menganalisis sejumlah besar data, Parquet akan bekerja paling baik. Ia mengambil data dari kolom yang diperlukan dan melewatkan sisanya untuk menghemat waktu dan sumber daya.
Singkatnya, Parquet lebih baik untuk membaca dan menganalisis kumpulan data besar, sementara Avro ideal untuk menulis dan menyimpan data dengan cara yang mudah diperbarui.
Berikut tabel perbandingan Parquet vs. CSV vs. JSON vs. Avro, termasuk kelebihan, kekurangan, dan kasus penggunaan:
|
Format |
Kelebihan |
Kekurangan |
Kasus penggunaan |
|
Parquet |
✅ Format kolumnar untuk analitik cepat ✅ Efisiensi kompresi tinggi ✅ Mendukung evolusi skema ✅ Dioptimalkan untuk kerangka kerja big data (Spark, Hive, Presto) ✅ Mendukung predicate pushdown (penyaringan efisien) |
❌ Tidak dapat dibaca manusia ❌ Lebih lambat untuk operasi berbasis baris ❌ Operasi penulisan lebih kompleks |
|
|
CSV |
✅ Dapat dibaca manusia dan sederhana ✅ Mudah dibuat dan diurai ✅ Kompatibel dengan hampir semua alat |
❌ Tidak ada dukungan skema ❌ Lambat untuk kumpulan data besar ❌ Ukuran file besar (tanpa kompresi) ❌ Harus memindai seluruh file untuk kueri |
|
|
JSON |
✅ Mendukung data bertingkat dan semi-terstruktur ✅ Dapat dibaca manusia ✅ Banyak digunakan dalam web API ✅ Skema fleksibel |
❌ Ukuran file lebih besar (karena format teks) ❌ Lambat untuk kueri big data ❌ Tidak ada pengindeksan native |
|
|
Avro |
✅ Format berbasis baris untuk penulisan cepat ✅ Format biner ringkas (penyimpanan efisien) ✅ Mendukung evolusi skema ✅ Baik untuk streaming dan antrian pesan |
❌ Tidak dapat dibaca manusia ❌ Kurang efisien untuk kueri analitik dibanding Parquet ❌ Memerlukan pustaka Avro untuk pemrosesan |
|
Sebagai rangkuman, berikut beberapa situasi di mana Parquet adalah pilihan terbaik:
Apache Parquet sangat cocok untuk menangani big data. Ini cepat, hemat ruang penyimpanan, dan bekerja dengan alat seperti Spark. Jika Anda tertarik mempelajari lebih jauh, lihat sumber daya berikut:
Pelajari lebih lanjut tentang data engineering dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
