
Curso
Fundamentos de PySpark
4 h
157.5K
Vamos a entender la arquitectura de Apache Parquet con sus características clave:
A diferencia de los formatos basados en filas, como CSV, Parquet organiza los datos en columnas. Esto significa que cuando ejecutamos una consulta, sólo extrae las columnas específicas que necesitamos en lugar de cargarlo todo. Esto mejora el rendimiento y reduce el uso de E/S.
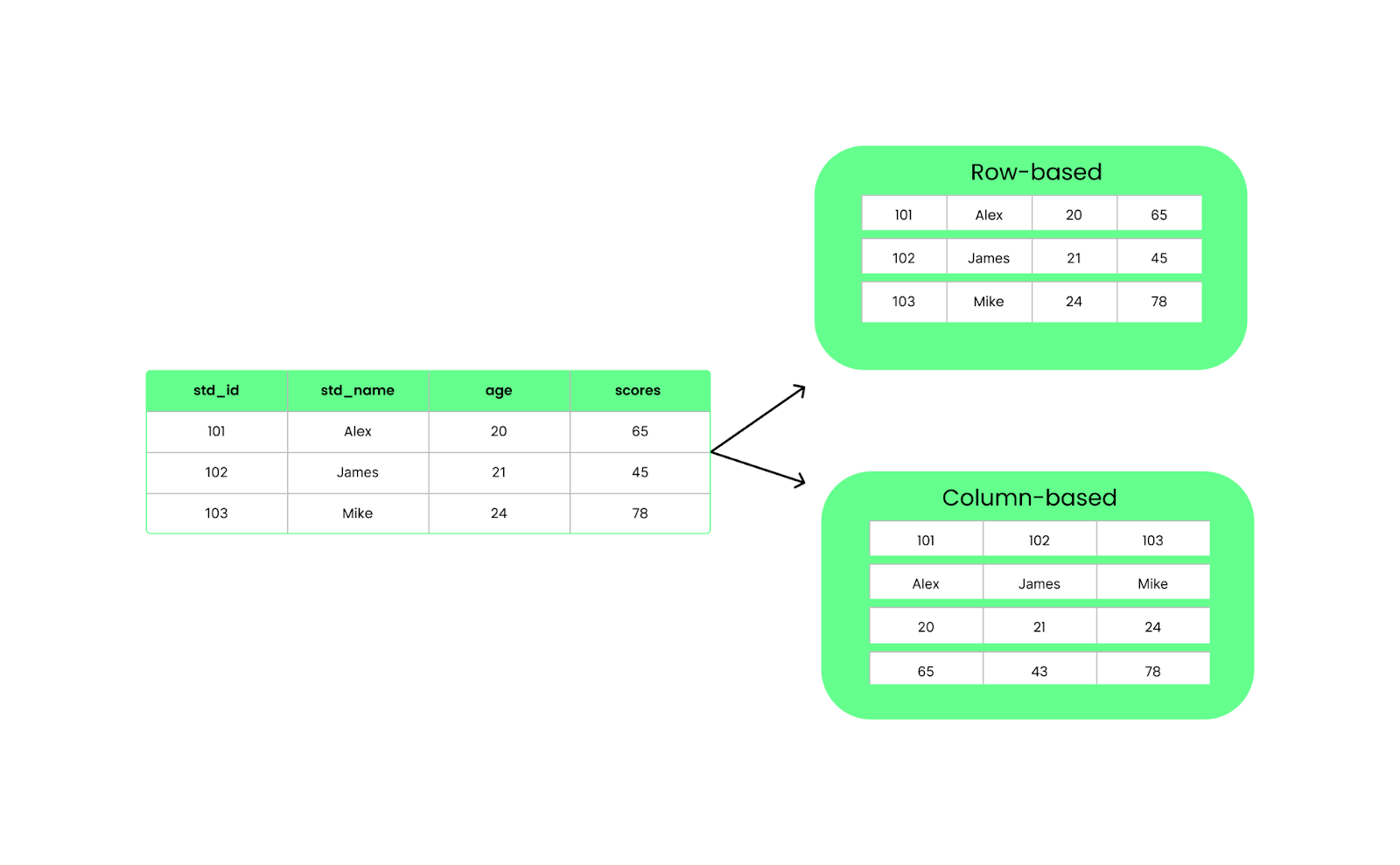
Estructura por filas frente a estructura por columnas. Imagen del autor.
Los archivos Parquet se dividen en grupos de filas, que contienen un lote de filas. Cada grupo de filas se divide en bloques de columnas, cada uno de los cuales contiene los datos de una columna. Estos trozos se dividen a su vez en piezas más pequeñas llamadas páginas, que se comprimen para ahorrar espacio.
Además, los archivos Parquet almacenan información extra en el pie de página, llamada metadatos, que localiza y lee sólo los datos que necesitamos.
Éste es el aspecto de la estructura:
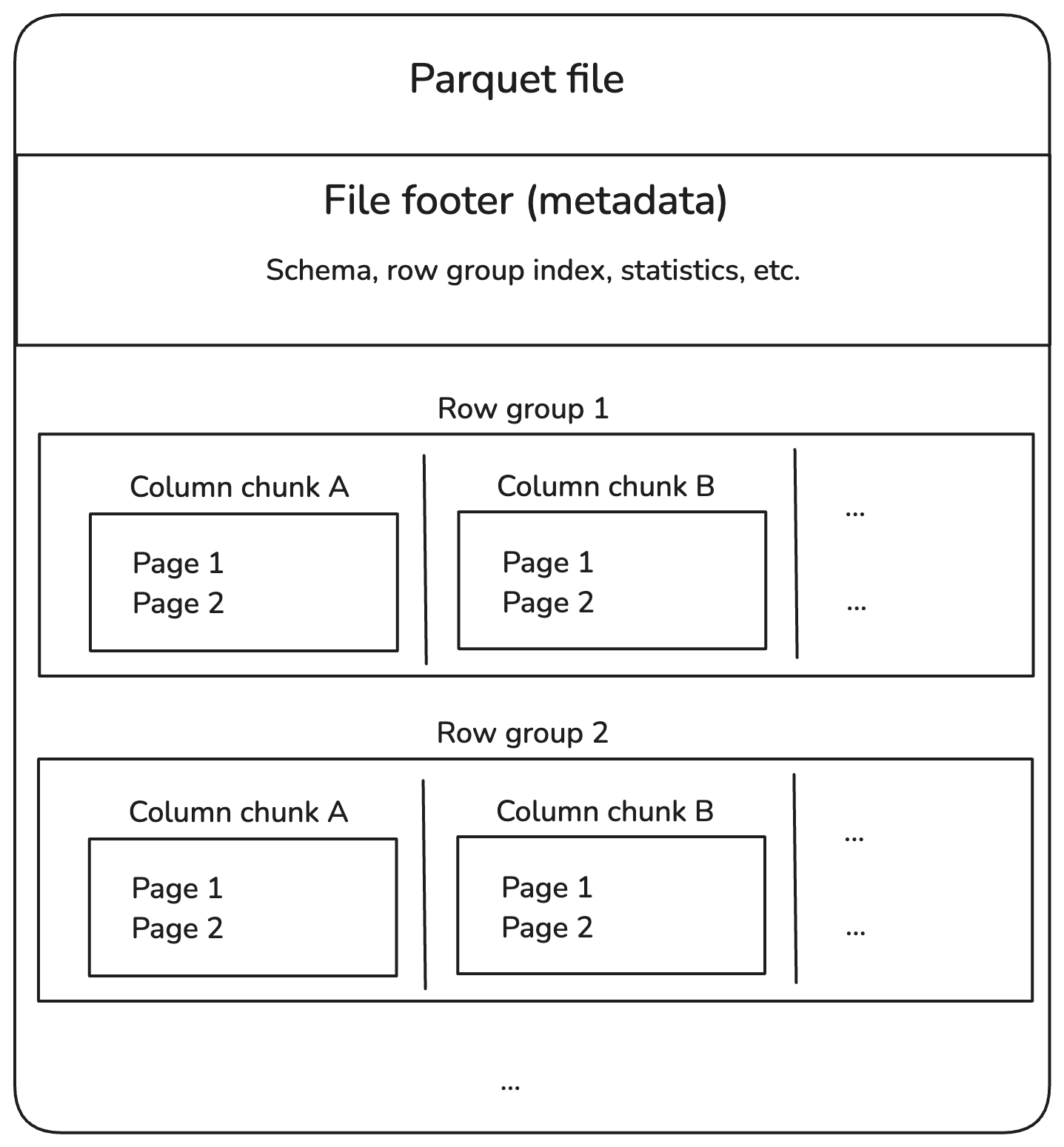
Estructura interna del archivo parquet. Imagen del autor.
Vamos a desglosar cada componente en el diagrama anterior.
Grupos de filas
Trozos de columna
Páginas
Pie de página (metadatos)
Como ya se ha dicho, Parquet comprime los datos columna a columna utilizando métodos de compresión como Snappy y Gzip. También utiliza dos técnicas de codificación:
Esto reduce el tamaño de los archivos y acelera la lectura de datos, lo que es especialmente útil cuando trabajas con big data.
Evolucionar el esquema significa modificar la estructura de los conjuntos de datos, como añadir o alterar columnas. Puede parecer sencillo, pero dependiendo de cómo estén almacenados tus datos, modificar el esquema puede ser lento y consumir muchos recursos.
Comprendámoslo comparando la evolución de los esquemas CSV y Parquet.
Supón que tienes un archivoCSV con columnas como student_id, student_name, y student_age. Si quieres añadir una nueva columna scores, tendrías que hacer lo siguiente:
scores.NULL).CSV es un formato simple basado en texto sin soporte de esquema incorporado. Esto significa que cualquier cambio en la estructura requiere reescribir todo el archivo, ¡y los sistemas antiguos que lean el archivo modificado podrían romperse si esperan una estructura diferente!
Con Parquet, puedes añadir, eliminar o actualizar campos sin romper los archivos existentes. Como vimos antes, Parquet almacena la información del esquema dentro del pie del archivo (metadatos), lo que permite evolucionar los esquemas sin modificar los archivos existentes.
Funciona así:
NULL en lugar de romper la consulta.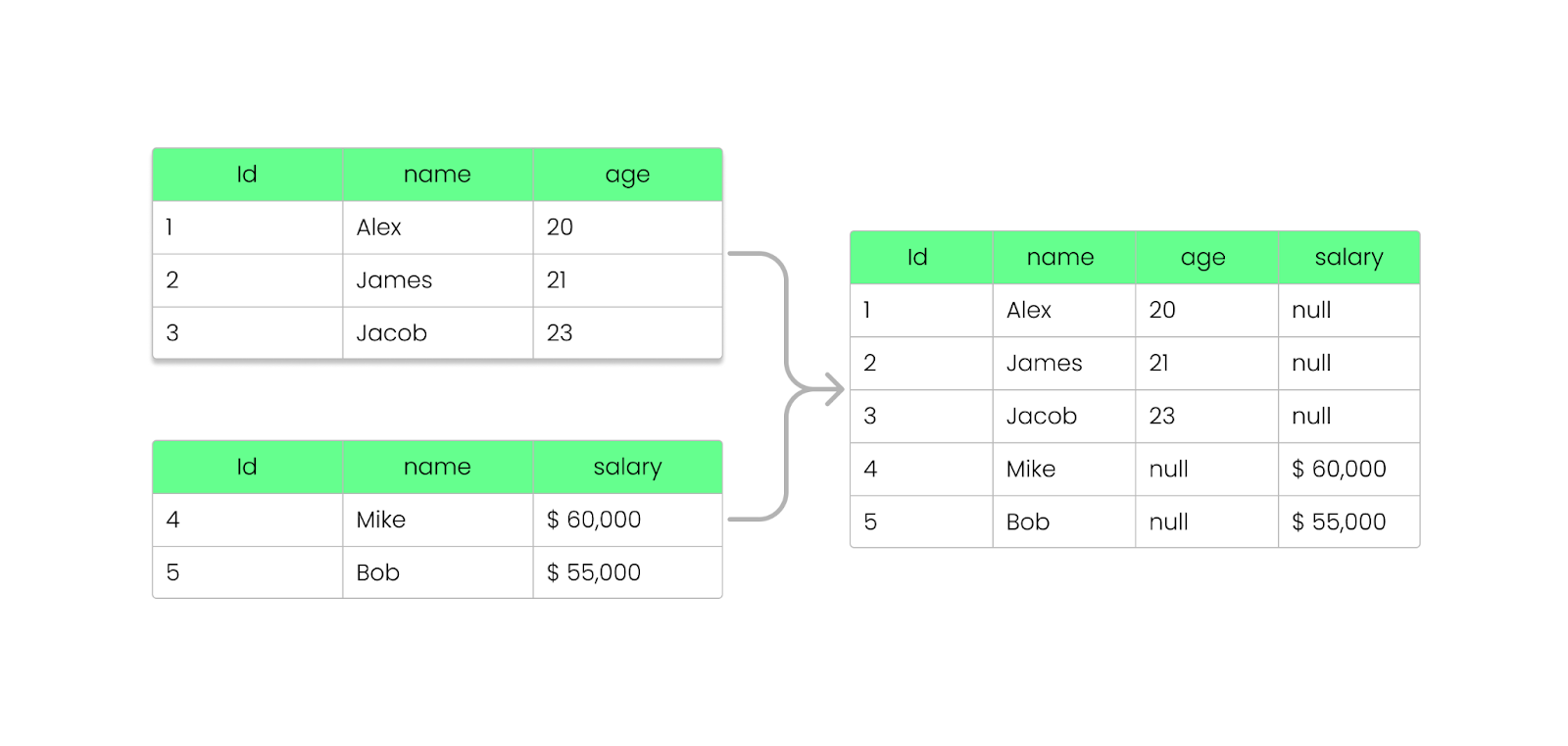
Añadir una columna al archivo Parquet sin romperlo. Imagen del autor.
Parquet es compatible con distintos lenguajes de programación, como Java, Python, C++ y Rust. Esto significa que los desarrolladores pueden utilizarlo fácilmente independientemente de su plataforma. También se integra de forma nativa con marcos de big data como Apache Spark, Hive, Presto, Flink y Trino, garantizando un procesamiento de datos eficiente a escala.
Así que, tanto si utilizas Python (a través de PySpark) como otro lenguaje, Parquet puede gestionar los datos de forma que sea fácil consultarlos y analizarlos en distintas plataformas.
Si eres nuevo en los marcos de trabajo de big data, te recomiendo que sigas el curso Introducción a PySpark. Es una forma estupenda de empezar.
Ahora que conoces los fundamentos de Apache Parquet, te guiaré a través de la escritura, lectura e integración dearchivos Parquet con pandas, PyArrowy otros marcos de big data como Spark.
Para guardar los DataFrames como archivos Parquet, necesitas pandas y un motor Parquet como PyArrow:
pip install pandas pyarrowAhora, escribe un archivo Parquet utilizando el siguiente código:
import pandas as pd
# Sample DataFrame
data = {
"Name": ["Alice", "Bob", "Charlie"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
}
df = pd.DataFrame(data)
# Write to Parquet file
df.to_parquet("data.parquet", engine="pyarrow", index=False)
print("Parquet file written successfully!")
Escribe el archivo Parquet con pandas. Imagen del autor.
Aquí tienes un código sencillo para leer tu archivo Parquet:
import pandas as pd
# Read the Parquet file
df = pd.read_parquet("data.parquet", engine="pyarrow")
print("Data from Parquet file:")
print(df)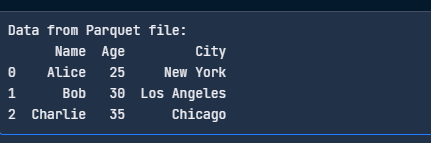
Lee el archivo Parquet con pandas. Imagen del autor.
PyArrow es una herramienta del proyecto Apache Arrow que facilita el trabajo con archivos Parquet. A continuación te explicamos cómo puedes escribir un archivo parquet utilizando PyArrow:
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# Sample data
df = pd.DataFrame({
"Name": ["Jacob", "Lauren", "Oliver"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
})
# Convert to a PyArrow table
table = pa.Table.from_pandas(df)
# Write to Parquet file
pq.write_table(table, "data.parquet")
print("Parquet file written successfully!")
Escribe un archivo Parquet con PyArrow. Imagen del autor.
He aquí cómo leer un archivo Parquet utilizando PyArrow:
import pyarrow.parquet as pq
# Read the Parquet file
table = pq.read_table("data.parquet")
# Convert to a pandas DataFrame
df = table.to_pandas()
print("Data from Parquet file:")
print(df)
Lee el archivo Parquet con PyArrow. Imagen del autor.
Podemos utilizar Spark para leer y escribir archivos Parquet directamente. Descárgalod del sitio web de Apache Spark o configúralo siguiendo las instrucciones .
Una vez hecho esto, importa las bibliotecas y crea un DataFrame:
from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName("SparkExample").getOrCreate()
# Define the schema for the dataset
schema = ["Name", "Age", "City"]
# Create a sample data
data = [
("Jacob", 30, "New York"),
("Lauren", 35, "Los Angeles"),
("Billy", 25, "Chicago")
]
# Create a DataFrame from the sample data
df = spark.createDataFrame(data, schema)
# Show the DataFrame
df.show()
Crea un DataFrame de ejemplo en Spark. Imagen del autor.
A continuación, escribe este DataFrame como un archivo Parquet:
# Write DataFrame to Parquet
df.write.parquet("data.parquet")El write.parquet() guarda el DataFrame en formato Parquet, y el archivo se llamará employee.parquet. Ahora, para leer este archivo Parquet, puedes utilizar el código siguiente:
# Read the Parquet file
parquet_df = spark.read.parquet("data.parquet")
# Show the DataFrame
parquet_df.show()
Lee el archivo Parquet. Imagen del autor.
Además de con Spark, Parquet también puede trabajar con Hive. Cuando crees una tabla Hive, utiliza STORED AS PARQUET para que Parquet sea el formato de almacenamiento.
Aparte de la lectura y escritura, hay algunas operaciones básicas que todo programador debe conocer, ya que son útiles cuando se trabaja con archivos Parquet. Vamos a repasarlos en esta sección.
Utilizaré pandas y PyArrow para ilustrar los conceptos.
Añadir datos es útil cuando hay que añadir nuevos registros sin reescribir todo el conjunto de datos.
import pyarrow.parquet as pq
import pyarrow as pa
# Load existing Parquet file
existing_table = pq.read_table("data.parquet")
# New data
new_data = pd.DataFrame({
"Name": ["David", "Emma"],
"Age": [40, 28],
"City": ["San Francisco", "Seattle"]
})
# Convert new data to PyArrow table
new_table = pa.Table.from_pandas(new_data)
# Concatenate both tables
merged_table = pa.concat_tables([existing_table, new_table])
# Write back to Parquet file
pq.write_table(merged_table, "data.parquet")En lugar de cargar todo el conjunto de datos, puedes seleccionar sólo las columnas necesarias, reduciendo el uso de memoria y mejorando el rendimiento. Esto es mucho más rápido que leer el conjunto de datos completo:
df = pd.read_parquet("data.parquet", columns=["Name", "Age"])
print(df)Parquet permite un filtrado eficaz a nivel de almacenamiento, conocido como predicado pushdown, que evita cargar datos innecesarios. Esto evita escanear todo el archivo, haciendo que las consultas sean mucho más rápidas:
import pyarrow.parquet as pq
# Read only rows where Age > 30
table = pq.read_table("data.parquet", filters=[("Age", ">", 30)])
df = table.to_pandas()
print(df)A menudo, los archivos Parquet se almacenan como particiones separadas. Puedes fusionarlos en un único archivo Parquet. Esto es útil cuando se combinan conjuntos de datos de distintas fuentes:
import pyarrow.parquet as pq
import pyarrow as pa
# List of Parquet files to merge
file_list = ["data_part1.parquet", "data_part2.parquet"]
# Read all files and merge
tables = [pq.read_table(f) for f in file_list]
merged_table = pa.concat_tables(tables)
# Write merged Parquet file
pq.write_table(merged_table, "merged_data.parquet")Si tienes archivos CSV, convertirlos a Parquet ahorra espacio y acelera el procesamiento, lo que reduce drásticamente el tamaño del archivo y mejora el rendimiento de lectura:
df = pd.read_csv("data.csv")
df.to_parquet("data.parquet", engine="pyarrow", index=False)La partición organiza los datos en subdirectorios en función del valor de una columna, lo que agiliza considerablemente las consultas.
A continuación te explicamos cómo puedes escribir datos particionados:
df.to_parquet("partitioned_data/", engine="pyarrow", partition_cols=["City"])El código anterior crea subdirectorios:
partitioned_data/City=New York/
partitioned_data/City=Los Angeles/
partitioned_data/City=Chicago/Entonces, sólo podrás leer una partición concreta:
df = pd.read_parquet("partitioned_data/City=New York/")
print(df)¡Esto acelera el análisis al escanear sólo las particiones relevantes!
Parquet admite algoritmos de compresión como Snappy, Gzip y Brotli para reducir el tamaño de los archivos:
df.to_parquet("compressed.parquet", engine="pyarrow", compression="snappy")Cuando empecé a utilizar Apache Parquet, me di cuenta de que unos pequeños ajustes podían mejorar mucho su eficacia. Éstos son algunos de mis principales consejos para optimizar Parquet en situaciones reales.
Si quieres ahorrar almacenamiento, códecs como Snappy o Gzip pueden ser tus mejores opciones: Snappy ofrece una compresión y descompresión rápidas, perfectas para situaciones en las que la velocidad es lo más importante.
Por el contrario, Gzip es ideal si tienes poco espacio de almacenamiento pero puedes soportar lecturas algo más lentas. La clave está en conocer tu carga de trabajo: un códec más rápido como Snappy suele salir ganando si accedes con frecuencia a los archivos. Sin embargo, Gzip es mejor para archivar datos.
Divide tus datos en subconjuntos lógicos, como dividirlos por fecha, región o cualquier otro campo consultado con frecuencia, para reducir la cantidad de datos escaneados durante una consulta. Una vez trabajé con un conjunto de datos que contenía años de registros de transacciones y lo dividí por año y mes para obtener periodos específicos en segundos en lugar de minutos.
Siempre me aseguro de que las nuevas columnas se añadan de forma que no interrumpan los procesos existentes. Esto suele significar añadirlas en lugar de modificar las existentes. Para ello, puedes utilizar el soporte de evolución de esquemas de Apache Spark para transiciones más suaves.
Comparemos Parquet con otros formatos de almacenamiento de datos.
Esto ya lo hemos tratado en la entrada del blog, pero permíteme que vuelva a insistir en ello: Parquet y CSV son dos formatos diferentes que tratan los datos de forma distinta.
Parquet organiza los datos en columnas, mientras que CSV lo hace en filas. Cuando utilizas Parquet, todos los datos de la misma columna se agrupan, de modo que puedes extraer fácilmente datos de columnas concretas sin tener que rebuscar entre todo lo demás. Es más rápido y ocupa menos espacio porque Parquet comprime los datos.
Formato basado en columnas Parquet. Imagen del autor.
El CSV, en cambio, almacena los datos fila a fila. Es sencillo y funciona bien para conjuntos de datos pequeños, pero no es ideal para los grandes. Cada consulta tiene que leer toda la fila, aunque sólo necesites un par de columnas. Esto ralentiza las cosas y requiere más memoria para procesarlas.
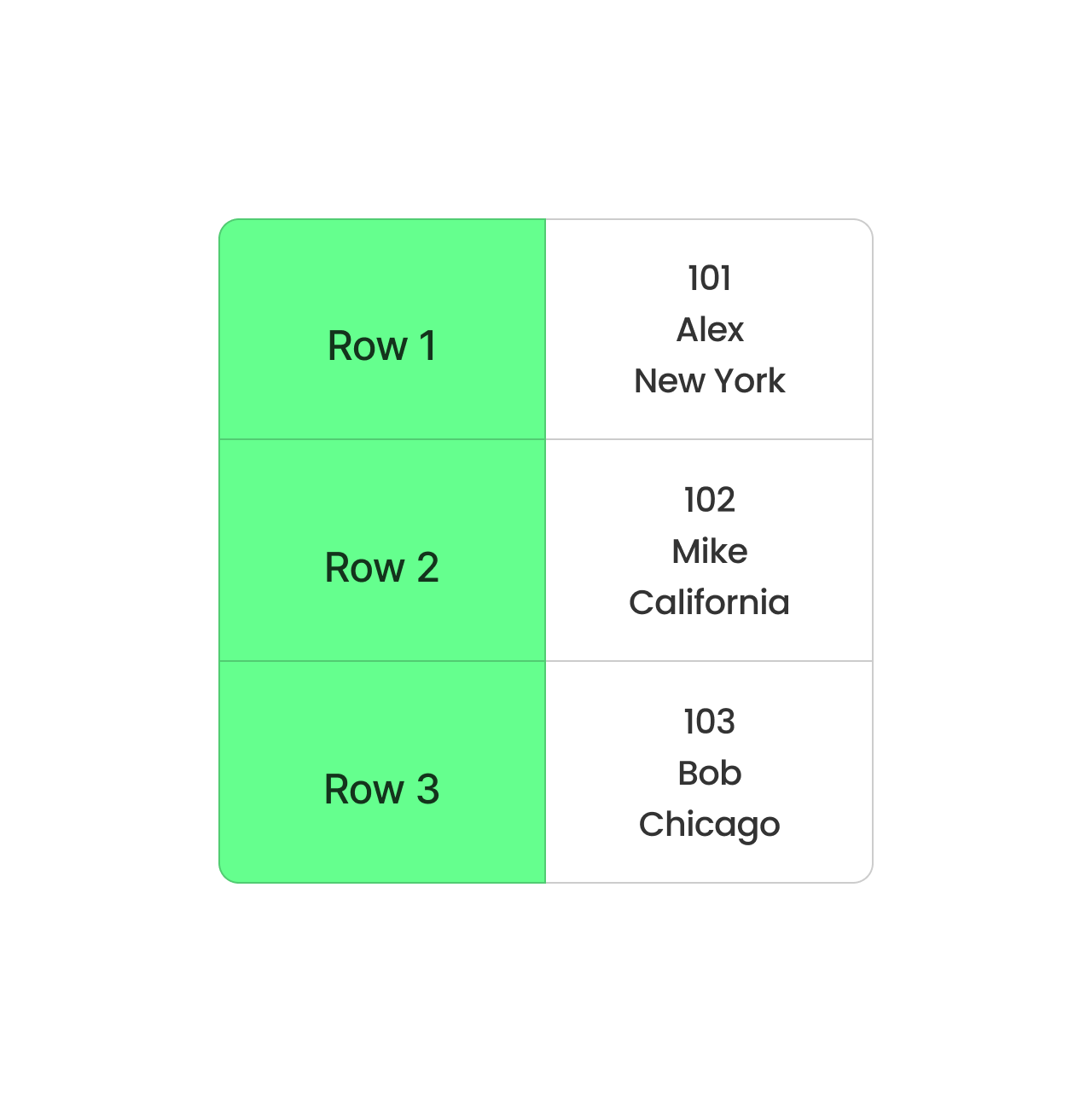
Formato CSV basado en filas. Imagen del autor.
JSON es estupendo para estructurar datos de forma que sean fáciles de entender, pero tiene un inconveniente: no es muy eficiente en cuanto a almacenamiento o velocidad. Permíteme explicarte por qué Parquet es más eficiente que JSON con un ejemplo.
Supongamos que tenemos una tabla de datos de empleados con tres columnas: EmployeeID, Department, y Location:
|
EmployeeID |
Departamento |
Ubicación |
|
1 |
HR |
Nueva York |
|
2 |
HR |
Nueva York |
|
3 |
HR |
Nueva York |
|
4 |
IT |
San Francisco |
|
5 |
IT |
San Francisco |
Ahora, si guardamos estos datos como JSON, tendrán un aspecto parecido a éste:
[
{"EmployeeID": 1, "Department": "HR", "Location": "New York"},
{"EmployeeID": 2, "Department": "HR", "Location": "New York"},
{"EmployeeID": 3, "Department": "HR", "Location": "New York"},
{"EmployeeID": 4, "Department": "IT", "Location": "San Francisco"},
{"EmployeeID": 5, "Department": "IT", "Location": "San Francisco"}
]Observa cómo JSON repite nombres de columnas como EmployeeID, Department, y Location para cada uno de los registros. También repite varias veces los valores de HR y New York. Esto hace que el archivo sea mucho más grande y lento.
Ahora imaginemos (porque Parquet no es legible por humanos) que guardamos los mismos datos que Parquet:
En lugar de almacenar fila por fila, Parquet organiza los datos por columnas y comprime los valores que se repiten.
Avro es un formato basado en filas. Es ideal para tareas como el flujo de datos o el procesamiento de registros, en las que añades constantemente nuevos registros o recuperas filas completas. Pero el formato basado en columnas de Parquet es perfecto para la analítica. Si ejecutas consultas para analizar grandes cantidades de datos, Parquet funcionaría mejor. Extrae los datos de las columnas necesarias y omite el resto para ahorrar tiempo y recursos.
En resumen, Parquet es mejor para leer y analizar grandes conjuntos de datos, mientras que Avro es ideal para escribir y almacenar datos de forma fácil de actualizar.
Aquí tienes una tabla comparativa de Parquet frente a. CSV vs. JSON vs. Avro, incluyendo pros, contras y casos de uso:
|
Formato |
Pros |
Contras |
Casos prácticos |
|
Parquet |
✅ Formato en columnas para un análisis rápido ✅ Alta eficacia de compresión ✅ Admite la evolución del esquema ✅ Optimizado para marcos de big data (Spark, Hive, Presto) ✅ Admite el pushdown de predicados (filtrado eficaz) |
❌ No legible por humanos ❌ Más lento para operaciones basadas en filas ❌ Operaciones de escritura más complejas |
|
|
CSV |
✅ Lectura humana y sencilla ✅ Fácil de generar y analizar ✅ Compatible con casi todas las herramientas |
❌ No admite esquemas ❌ Lento para grandes conjuntos de datos ❌ Archivos de gran tamaño (sin compresión) ❌ Debe escanear todo el archivo en busca de consultas |
|
|
JSON |
✅ Admite datos anidados y semiestructurados ✅ Lectura humana ✅ Muy utilizado en las API web ✅ Esquema flexible |
❌ Mayor tamaño de los archivos (debido al formato de texto) ❌ Lento para consultas de big data ❌ Sin indexación nativa |
|
|
Avro |
✅ Formato basado en filas para escrituras rápidas ✅ Formato binario compacto (almacenamiento eficaz) ✅ Admite la evolución del esquema ✅ Bueno para streaming y colas de mensajes |
❌ No legible por humanos ❌ Menos eficaz para las consultas analíticas que Parquet ❌ Requiere bibliotecas Avro para su procesamiento |
|
En resumen, he aquí algunas situaciones en las que el parquet es la mejor opción:
Apache Parquet es perfecto para manejar big data. Es rápido, ahorra espacio de almacenamiento y funciona con herramientas como Spark. Si quieres saber más, consulta los siguientes recursos :
¡Aprende más sobre ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Matt Crabtree
10 min
blog
Mike Shakhomirov
11 min
Tutorial
Tim Lu
Tutorial
Natassha Selvaraj
Tutorial
Joleen Bothma
Tutorial
Oluseye Jeremiah
