
Cours
Introduction à PySpark
4 h
157.5K
Comprenons l'architecture d'Apache Parquet et ses principales caractéristiques :
Contrairement aux formats basés sur des lignes comme CSV, Parquet organise les données en colonnes. Cela signifie que lorsque nous exécutons une requête, elle ne tire que les colonnes spécifiques dont nous avons besoin au lieu de tout charger. Cela permet d'améliorer les performances et de réduire l'utilisation des E/S.
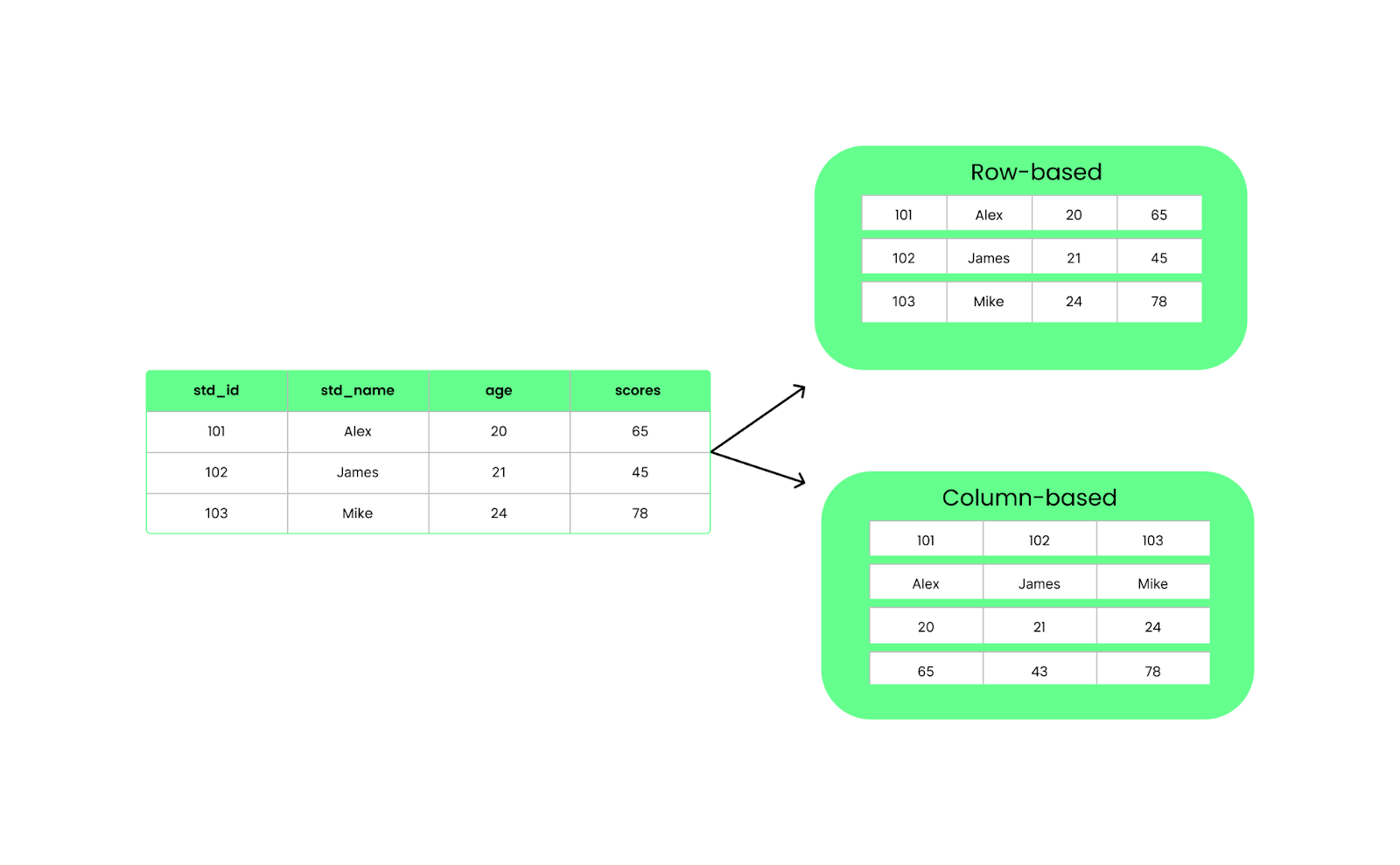
Structure en lignes ou en colonnes. Image par l'auteur.
Les fichiers Parquet sont divisés en groupes de lignes, qui contiennent un lot de lignes. Chaque groupe de lignes est divisé en morceaux de colonnes, chacun contenant les données d'une colonne. Ces blocs sont ensuite divisés en morceaux plus petits appelés pages, qui sont comprimés pour économiser de l'espace.
En outre, les fichiers Parquet contiennent des informations supplémentaires dans le pied de page, appelées métadonnées, qui permettent de localiser et de lire uniquement les données dont nous avons besoin.
Voici à quoi ressemble la structure :
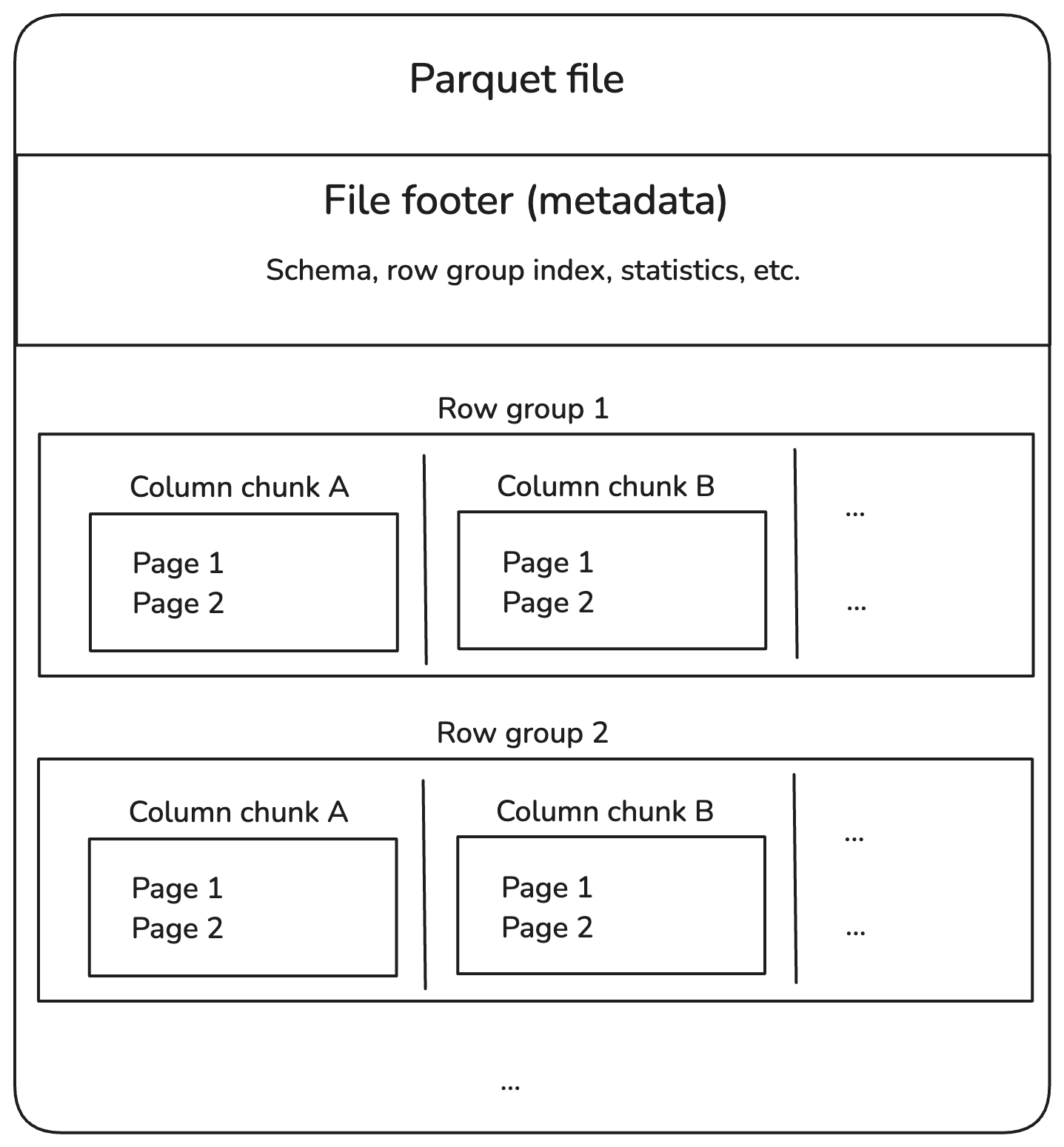
Structure interne du fichier Parquet. Image par l'auteur.
Décomposons chaque élément du diagramme ci-dessus.
Groupes de rangs
Morceaux de colonne
Pages
Pied de page (métadonnées)
Comme nous l'avons mentionné, Parquet compresse les données colonne par colonne en utilisant des méthodes de compression telles que Snappy et Gzip. Il utilise également deux techniques d'encodage :
Cela permet de réduire la taille des fichiers et d'accélérer la lecture des données, ce qui est particulièrement utile lorsque vous travaillez avec des données volumineuses.
L'évolution du schéma consiste à modifier la structure des ensembles de données, par exemple en ajoutant ou en modifiant des colonnes. Cela peut paraître simple, mais selon la manière dont vos données sont stockées, la modification du schéma peut s'avérer lente et gourmande en ressources.
Comprenons cela en comparant l'évolution des schémas CSV et Parquet.
Supposons que vous ayez un fichierCSV avec des colonnes telles que student_id, student_name, et student_age. Si vous souhaitez ajouter une nouvelle colonne scores, vous devez procéder comme suit :
scores.NULL).Le format CSV est un format texte simple qui ne prend pas en charge les schémas intégrés. Cela signifie que toute modification de la structure nécessite la réécriture de l'ensemble du fichier et que les systèmes plus anciens qui lisent le fichier modifié risquent de se bloquer s'ils s'attendent à une structure différente !
Avec Parquet, vous pouvez ajouter, supprimer ou mettre à jour des champs sans interrompre vos fichiers existants. Comme nous l'avons vu précédemment, Parquet stocke les informations relatives au schéma dans le pied de page du fichier (métadonnées), ce qui permet de faire évoluer les schémas sans modifier les fichiers existants.
Voici comment cela fonctionne :
NULL au lieu de casser la requête.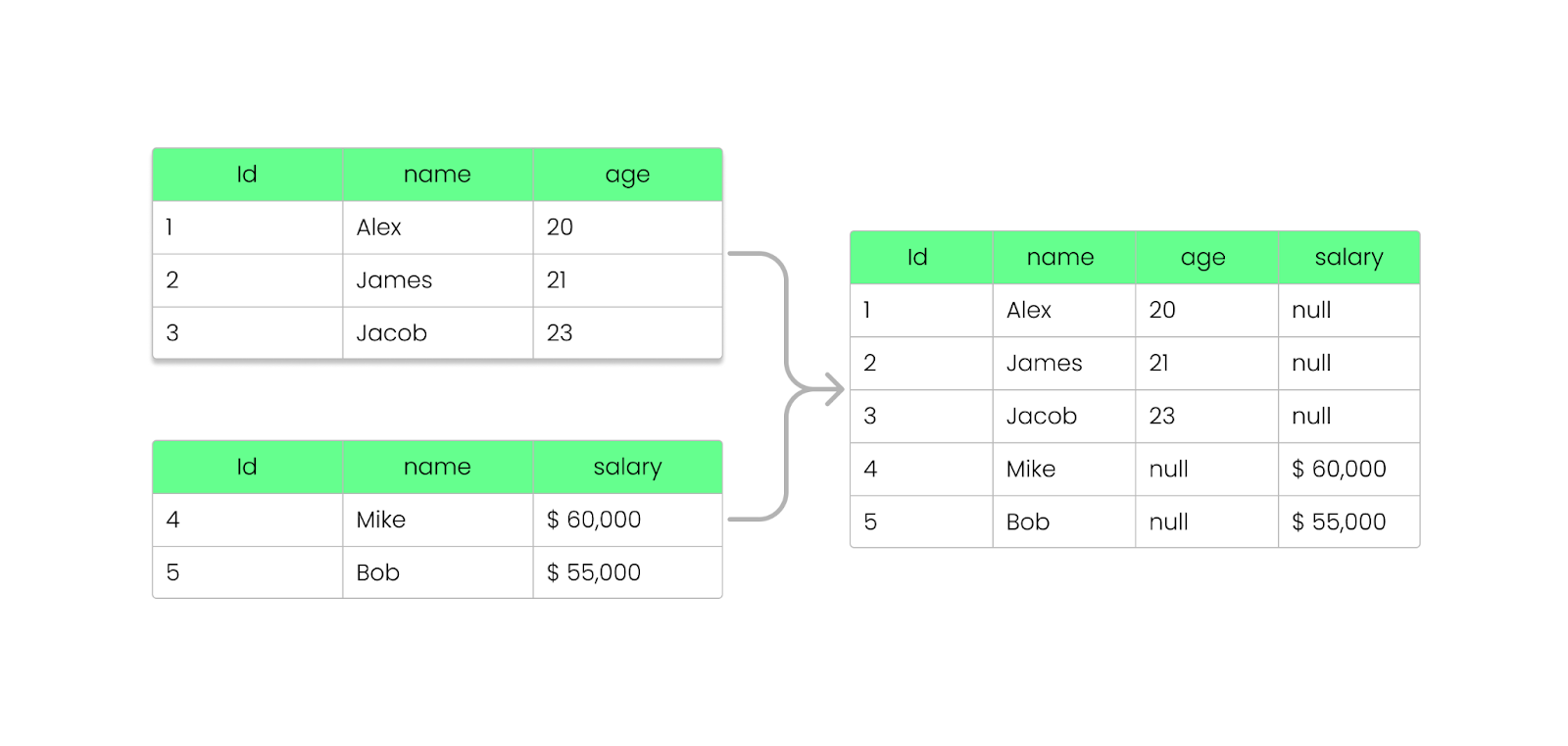
Ajouter une colonne au fichier Parquet sans le casser. Image par l'auteur.
Parquet prend en charge différents langages de programmation, tels que Java, Python, C++ et Rust. Cela signifie que les développeurs peuvent facilement l'utiliser quelle que soit leur plateforme. Il est également nativement intégré aux frameworks big data tels que Apache Spark, Hive, Presto, Flink et Trino, ce qui garantit un traitement efficace des données à l'échelle.
Ainsi, que vous utilisiez Python (via PySpark) ou un autre langage, Parquet peut gérer les données de manière à faciliter l'interrogation et l'analyse sur différentes plateformes.
Si vous êtes novice en matière de cadres de big data, je vous recommande de suivre le cours Introduction à PySpark. C'est une excellente façon de commencer.
Maintenant que vous connaissez les bases d'Apache Parquet, je vais vous accompagner dans l'écriture, la lecture et l'intégration defichiers Parquet avec pandas, PyArrowet d'autres frameworks big data comme Spark.
Pour enregistrer les DataFrame sous forme de fichiers Parquet, vous avez besoin de pandas et d'un moteur Parquet comme PyArrow :
pip install pandas pyarrowMaintenant, écrivez un fichier Parquet en utilisant le code suivant :
import pandas as pd
# Sample DataFrame
data = {
"Name": ["Alice", "Bob", "Charlie"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
}
df = pd.DataFrame(data)
# Write to Parquet file
df.to_parquet("data.parquet", engine="pyarrow", index=False)
print("Parquet file written successfully!")
Ecrivez le fichier Parquet avec pandas. Image par l'auteur.
Voici un code simple pour lire votre fichier Parquet :
import pandas as pd
# Read the Parquet file
df = pd.read_parquet("data.parquet", engine="pyarrow")
print("Data from Parquet file:")
print(df)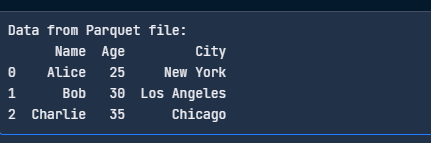
Lisez le fichier Parquet avec pandas. Image par l'auteur.
PyArrow est un outil du projet Apache Arrow qui permet de travailler facilement avec des fichiers Parquet. Voici comment vous pouvez écrire un fichier parquet en utilisant PyArrow :
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# Sample data
df = pd.DataFrame({
"Name": ["Jacob", "Lauren", "Oliver"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
})
# Convert to a PyArrow table
table = pa.Table.from_pandas(df)
# Write to Parquet file
pq.write_table(table, "data.parquet")
print("Parquet file written successfully!")
Ecrire un fichier Parquet avec PyArrow. Image par l'auteur.
Voici comment lire un fichier Parquet avec PyArrow :
import pyarrow.parquet as pq
# Read the Parquet file
table = pq.read_table("data.parquet")
# Convert to a pandas DataFrame
df = table.to_pandas()
print("Data from Parquet file:")
print(df)
Lisez le fichier Parquet avec PyArrow. Image par l'auteur.
Nous pouvons utiliser Spark pour lire et écrire directement des fichiers Parquet. Téléchargezà partir du site web d'Apache Spark ou configurez-le en suivant les instructions.
Une fois cela fait, importez les bibliothèques et créez un DataFrame :
from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName("SparkExample").getOrCreate()
# Define the schema for the dataset
schema = ["Name", "Age", "City"]
# Create a sample data
data = [
("Jacob", 30, "New York"),
("Lauren", 35, "Los Angeles"),
("Billy", 25, "Chicago")
]
# Create a DataFrame from the sample data
df = spark.createDataFrame(data, schema)
# Show the DataFrame
df.show()
Créez un exemple de DataFrame dans Spark. Image par l'auteur.
Ensuite, écrivez ce DataFrame sous la forme d'un fichier Parquet :
# Write DataFrame to Parquet
df.write.parquet("data.parquet")La commande write.parquet() enregistre le DataFrame au format Parquet, et le fichier sera appelé employee.parquet. Maintenant, pour lire ce fichier Parquet, vous pouvez utiliser le code suivant :
# Read the Parquet file
parquet_df = spark.read.parquet("data.parquet")
# Show the DataFrame
parquet_df.show()
Lire le fichier Parquet. Image par l'auteur.
Outre Spark, Parquet peut également fonctionner avec Hive. Lorsque vous créez un tableau Hive, utilisez STORED AS PARQUET pour faire de Parquet le format de stockage.
Outre la lecture et l'écriture, il existe quelques opérations de base que tout développeur devrait connaître car elles sont utiles pour travailler avec des fichiers Parquet. Passons-les en revue dans cette section.
J'utiliserai pandas et PyArrow pour illustrer les concepts.
L'ajout de données est utile lorsque de nouveaux enregistrements doivent être ajoutés sans réécrire l'ensemble des données.
import pyarrow.parquet as pq
import pyarrow as pa
# Load existing Parquet file
existing_table = pq.read_table("data.parquet")
# New data
new_data = pd.DataFrame({
"Name": ["David", "Emma"],
"Age": [40, 28],
"City": ["San Francisco", "Seattle"]
})
# Convert new data to PyArrow table
new_table = pa.Table.from_pandas(new_data)
# Concatenate both tables
merged_table = pa.concat_tables([existing_table, new_table])
# Write back to Parquet file
pq.write_table(merged_table, "data.parquet")Au lieu de charger l'ensemble des données, vous pouvez sélectionner uniquement les colonnes nécessaires, ce qui permet de réduire l'utilisation de la mémoire et d'améliorer les performances. Cette méthode est nettement plus rapide que la lecture de l'ensemble des données :
df = pd.read_parquet("data.parquet", columns=["Name", "Age"])
print(df)Parquet permet un filtrage efficace au niveau du stockage, connu sous le nom de predicate pushdown, ce qui évite de charger des données inutiles. Cela évite d'analyser l'ensemble du fichier, ce qui rend les requêtes beaucoup plus rapides :
import pyarrow.parquet as pq
# Read only rows where Age > 30
table = pq.read_table("data.parquet", filters=[("Age", ">", 30)])
df = table.to_pandas()
print(df)Souvent, les fichiers Parquet sont stockés dans des partitions séparées. Vous pouvez les fusionner en un seul fichier Parquet. Cette fonction est utile lorsque vous combinez des ensembles de données provenant de différentes sources :
import pyarrow.parquet as pq
import pyarrow as pa
# List of Parquet files to merge
file_list = ["data_part1.parquet", "data_part2.parquet"]
# Read all files and merge
tables = [pq.read_table(f) for f in file_list]
merged_table = pa.concat_tables(tables)
# Write merged Parquet file
pq.write_table(merged_table, "merged_data.parquet")Si vous disposez de fichiers CSV existants, leur conversion en Parquet permet d'économiser de l'espace et d'accélérer le traitement, ce qui réduit considérablement la taille des fichiers et améliore les performances de lecture :
df = pd.read_csv("data.csv")
df.to_parquet("data.parquet", engine="pyarrow", index=False)Le partitionnement organise les données en sous-répertoires sur la base de la valeur d'une colonne, ce qui accélère considérablement les requêtes.
Voici comment vous pouvez écrire des données partitionnées :
df.to_parquet("partitioned_data/", engine="pyarrow", partition_cols=["City"])Le code ci-dessus crée des sous-répertoires :
partitioned_data/City=New York/
partitioned_data/City=Los Angeles/
partitioned_data/City=Chicago/Vous pouvez alors lire uniquement une partition spécifique :
df = pd.read_parquet("partitioned_data/City=New York/")
print(df)Cela permet d'accélérer l'analyse en ne scannant que les partitions pertinentes !
Parquet prend en charge des algorithmes de compression tels que Snappy, Gzip et Brotli pour réduire la taille des fichiers :
df.to_parquet("compressed.parquet", engine="pyarrow", compression="snappy")Lorsque j'ai commencé à utiliser Apache Parquet, j'ai réalisé que des ajustements mineurs pouvaient grandement améliorer son efficacité. Voici quelques-uns de mes meilleurs conseils pour optimiser Parquet dans des scénarios réels.
Si vous souhaitez économiser de l'espace de stockage, des codecs tels que Snappy ou Gzip peuvent être vos options de choix : Snappy permet une compression et une décompression rapides, ce qui est parfait pour les scénarios où la vitesse est la plus importante.
Inversement, Gzip est idéal si vous êtes à court d'espace de stockage mais que vous pouvez supporter des lectures un peu plus lentes. La clé est de comprendre votre charge de travail - un codec plus rapide comme Snappy l'emporte souvent si vous accédez fréquemment à des fichiers. Cependant, Gzip est la meilleure solution pour les données archivées.
Divisez vos données en sous-ensembles logiques, par exemple par date, par région ou par tout autre champ fréquemment interrogé, afin de réduire la quantité de données analysées lors d'une requête. J'ai travaillé une fois avec un ensemble de données contenant des années de journaux de transactions et je l'ai partitionné par année et par mois pour récupérer des périodes spécifiques en secondes plutôt qu'en minutes.
Je veille toujours à ce que les nouvelles colonnes soient ajoutées de manière à ne pas perturber les processus existants. Cela signifie généralement qu'il faut les ajouter plutôt que de modifier ceux qui existent déjà. Pour ce faire, vous pouvez utiliser la prise en charge de l'évolution des schémas d'Apache Spark pour des transitions plus fluides.
Comparons Parquet à d'autres formats de stockage de données.
Nous avons déjà abordé ce sujet dans l'article du blog, mais permettez-moi d'insister à nouveau : Parquet et CSV sont deux formats différents qui traitent les données différemment.
Parquet organise les données en colonnes, tandis que CSV les organise en lignes. Lorsque vous utilisez Parquet, toutes les données d'une même colonne sont regroupées, ce qui vous permet d'extraire facilement des données de colonnes spécifiques sans avoir à passer au crible toutes les autres. Il est plus rapide et occupe moins d'espace car Parquet compresse les données.
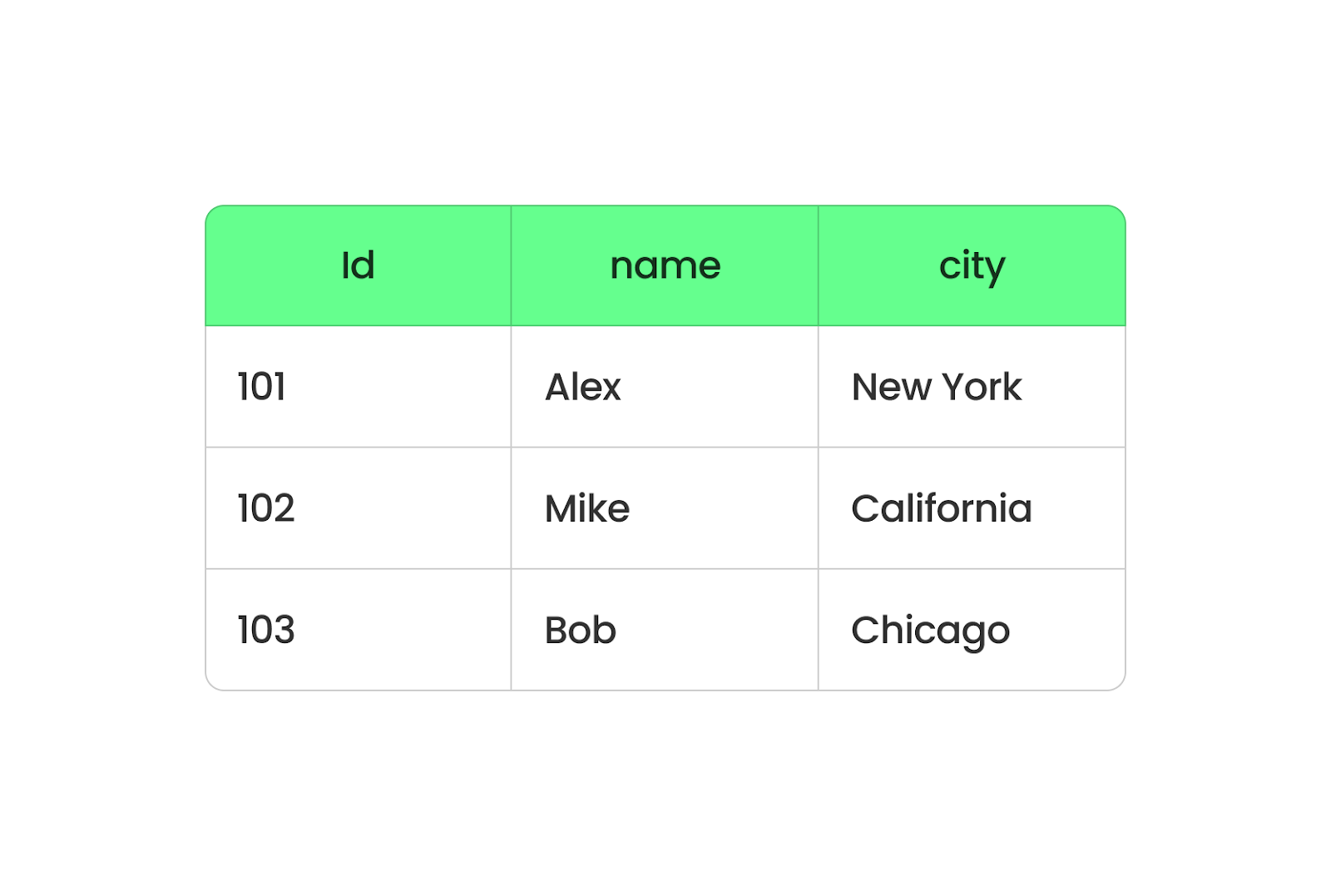
Format Parquet basé sur des colonnes. Image par l'auteur.
Le format CSV, quant à lui, stocke les données ligne par ligne. Cette méthode est simple et fonctionne bien pour les petits ensembles de données, mais elle n'est pas idéale pour les grands ensembles. Chaque requête doit lire la ligne entière, même si vous n'avez besoin que de quelques colonnes. Cela ralentit les choses et nécessite plus de mémoire pour le traitement.
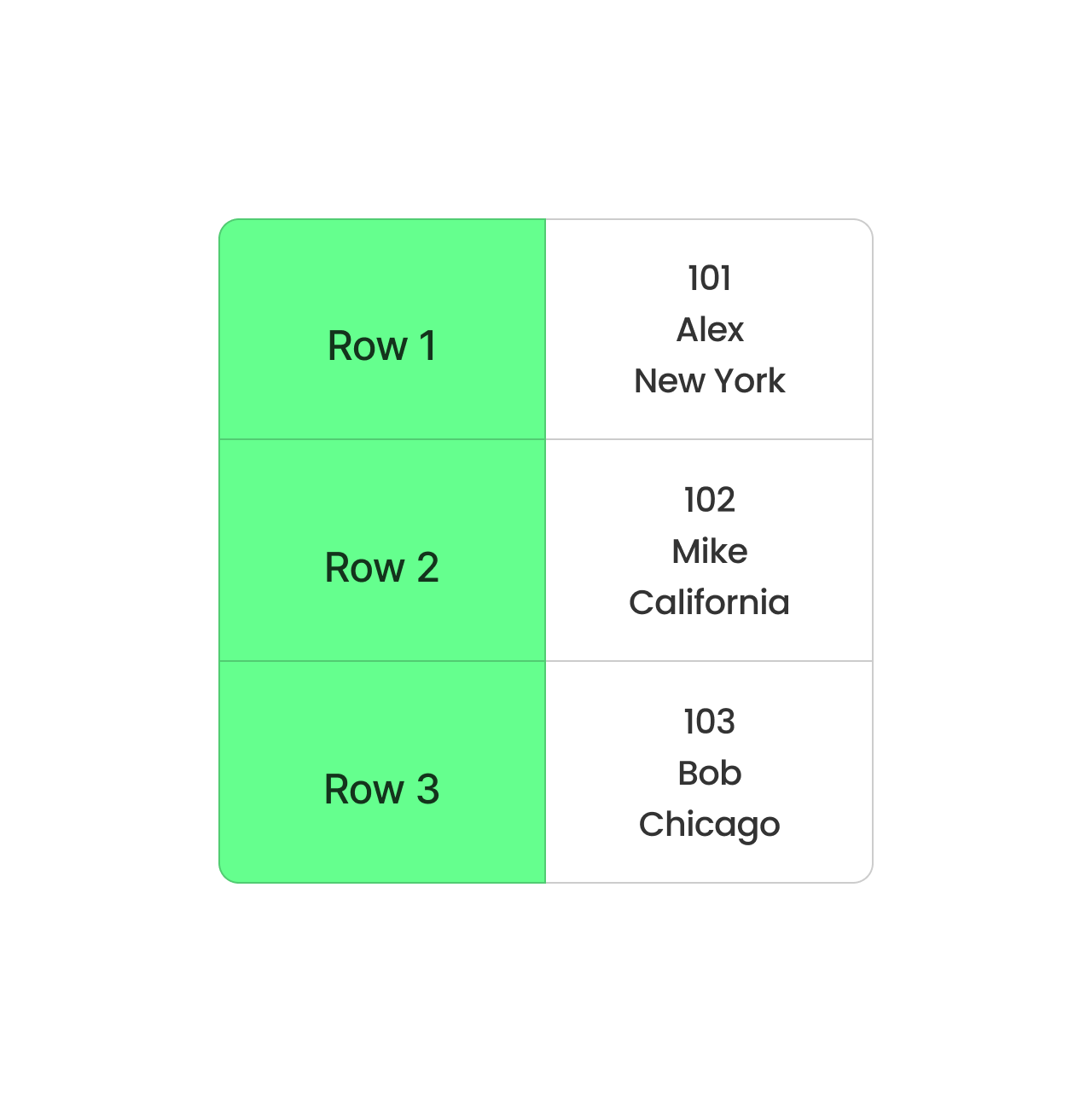
Format CSV basé sur des lignes. Image par l'auteur.
JSON est idéal pour structurer les données d'une manière facile à comprendre, mais il présente un inconvénient : il n'est pas très efficace en termes de stockage ou de vitesse. Laissez-moi donc vous expliquer pourquoi Parquet est plus efficace que JSON à l'aide d'un exemple.
Supposons que nous ayons un tableau de données sur les employés avec trois colonnes : EmployeeID, Department, et Location:
|
ID de l'employé |
Département |
Localisation |
|
1 |
HR |
New York (en anglais) |
|
2 |
HR |
New York (en anglais) |
|
3 |
HR |
New York (en anglais) |
|
4 |
IT |
San Francisco |
|
5 |
IT |
San Francisco |
Si nous enregistrons ces données au format JSON, elles ressembleront à ceci :
[
{"EmployeeID": 1, "Department": "HR", "Location": "New York"},
{"EmployeeID": 2, "Department": "HR", "Location": "New York"},
{"EmployeeID": 3, "Department": "HR", "Location": "New York"},
{"EmployeeID": 4, "Department": "IT", "Location": "San Francisco"},
{"EmployeeID": 5, "Department": "IT", "Location": "San Francisco"}
]Remarquez que JSON répète les noms de colonnes tels que EmployeeID, Department, et Location pour chaque enregistrement. Il répète également plusieurs fois les valeurs pour HR et New York. Le fichier est alors beaucoup plus volumineux et lent.
Imaginons maintenant (parce que Parquet n'est pas lisible par l'homme) que nous sauvegardions les mêmes données que Parquet :
Au lieu de stocker les données ligne par ligne, Parquet les organise par colonnes et compresse les valeurs répétitives.
Avro est un format basé sur les lignes. Il est idéal pour les tâches telles que la diffusion de données en continu ou le traitement de journaux, où vous ajoutez constamment de nouveaux enregistrements ou récupérez des lignes complètes. Mais le format en colonnes de Parquet est parfait pour l'analyse. Si vous exécutez des requêtes pour analyser de grandes quantités de données, Parquet est la solution la plus adaptée. Il extrait les données des colonnes nécessaires et saute le reste pour économiser du temps et des ressources.
En résumé, Parquet est plus adapté à la lecture et à l'analyse de grands ensembles de données, tandis qu'Avro est idéal pour l'écriture et le stockage de données faciles à mettre à jour.
Voici un tableau comparatif de Parquet vs. CSV vs. JSON vs. Avro, y compris les avantages, les inconvénients et les cas d'utilisation :
|
Format |
Pour |
Cons |
Cas d'utilisation |
|
Parquet |
✅ Format colonne pour une analyse rapide ✅ Efficacité élevée de la compression ✅ Prise en charge de l'évolution des schémas ✅ Optimisé pour les frameworks big data (Spark, Hive, Presto) ✅ Prise en charge des prédicats pushdown (filtrage efficace) |
❌ Pas lisible par l'homme ❌ Plus lent pour les opérations basées sur les lignes ❌ Opérations d'écriture plus complexes |
|
|
CSV |
✅ Lisible par l'homme et simple ✅ Facile à générer et à analyser ✅ Compatible avec presque tous les outils |
❌ Pas de prise en charge des schémas ❌ Lenteur pour les grands ensembles de données ❌ Fichiers de grande taille (pas de compression) doit rechercher des requêtes dans l'ensemble du fichier |
|
|
JSON |
✅ Prise en charge des données imbriquées et semi-structurées ✅ Lisible par l'homme ✅ Largement utilisé dans les API web ✅ Schéma flexible |
❌ Taille des fichiers plus importante (en raison du format texte) ❌ Lent pour les requêtes de données volumineuses (big data) ❌ Pas d'indexation native |
|
|
Avro |
✅ Format basé sur les rangées pour des écritures rapides Format binaire compact (stockage efficace) ✅ Prise en charge de l'évolution des schémas ✅ Bon pour le streaming et les files d'attente de messages |
❌ Pas lisible par l'homme ❌ Moins efficace que Parquet pour les requêtes analytiques ❌ Nécessite les bibliothèques Avro pour le traitement |
|
En résumé, voici quelques situations où le parquet est le meilleur choix :
Apache Parquet est parfait pour traiter les données volumineuses. Il est rapide, permet d'économiser de l'espace de stockage et fonctionne avec des outils comme Spark. Si vous souhaitez en savoir plus, consultez les ressources suivantes :
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Zoumana Keita
15 min
Tutoriel
Moez Ali
Tutoriel
DataCamp Team
Tutoriel
Tutoriel
Matt Crabtree
