
Cursus
Basis van PySpark
4 Hr
157.6K
Laten we de architectuur van Apache Parquet begrijpen aan de hand van de belangrijkste features:
In tegenstelling tot rijgebaseerde formaten zoals CSV organiseert Parquet data per kolom. Dat betekent dat bij een query alleen de specifieke kolommen worden opgehaald die we nodig hebben, in plaats van alles te laden. Dit verbetert de prestaties en vermindert I/O-gebruik.
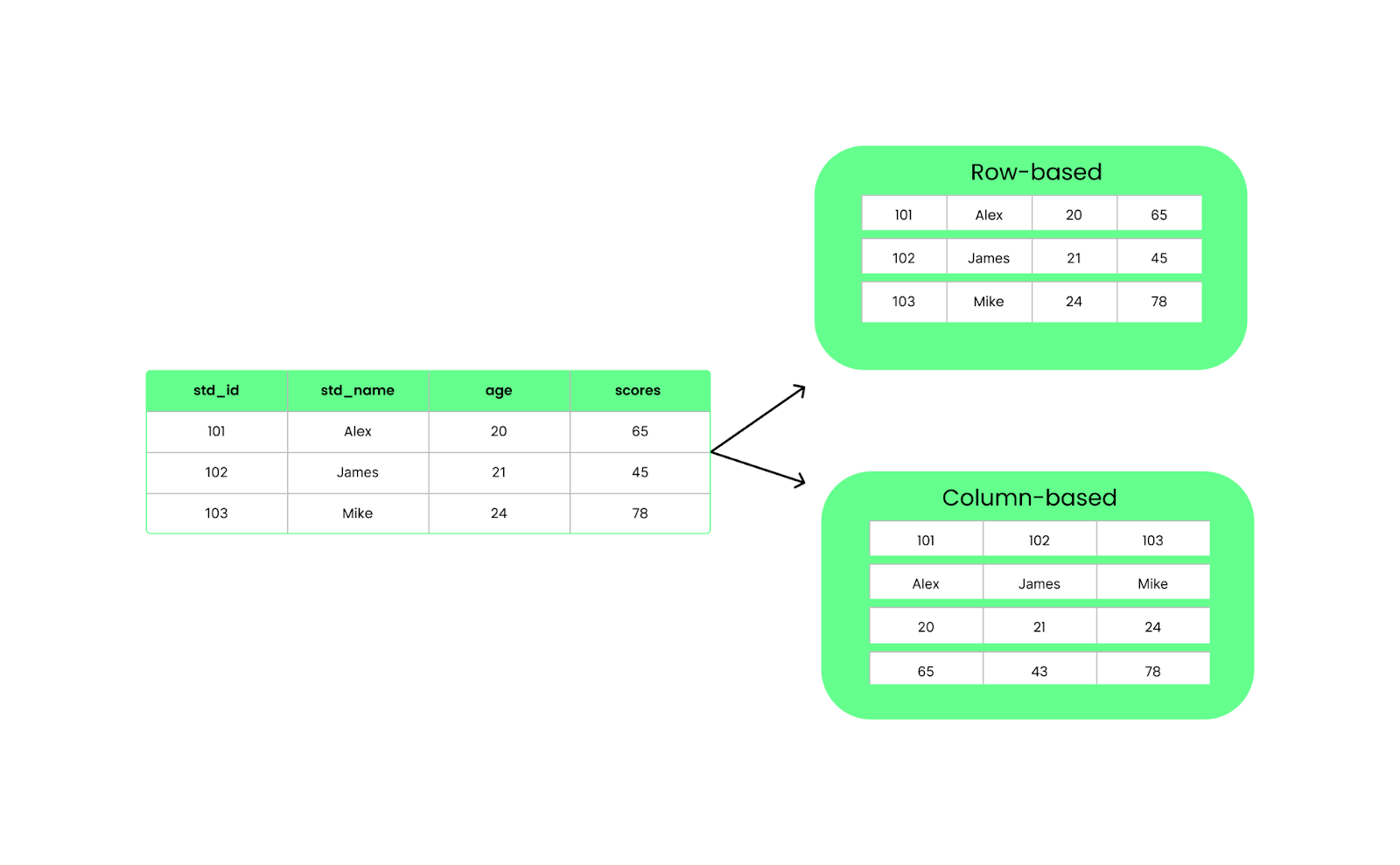
Rij- vs kolomgebaseerde structuur. Afbeelding door de auteur.
Parquet-bestanden worden opgesplitst in row groups, die een batch rijen bevatten. Elke row group is opgedeeld in column chunks, die elk de data voor één kolom bevatten. Deze chunks worden verder verdeeld in kleinere stukken, pages genoemd, die gecomprimeerd worden om ruimte te besparen.
Daarnaast slaan Parquet-bestanden extra informatie op in de footer, de metadata, die helpt om alleen de data te lokaliseren en te lezen die we nodig hebben.
Zo ziet de structuur eruit:
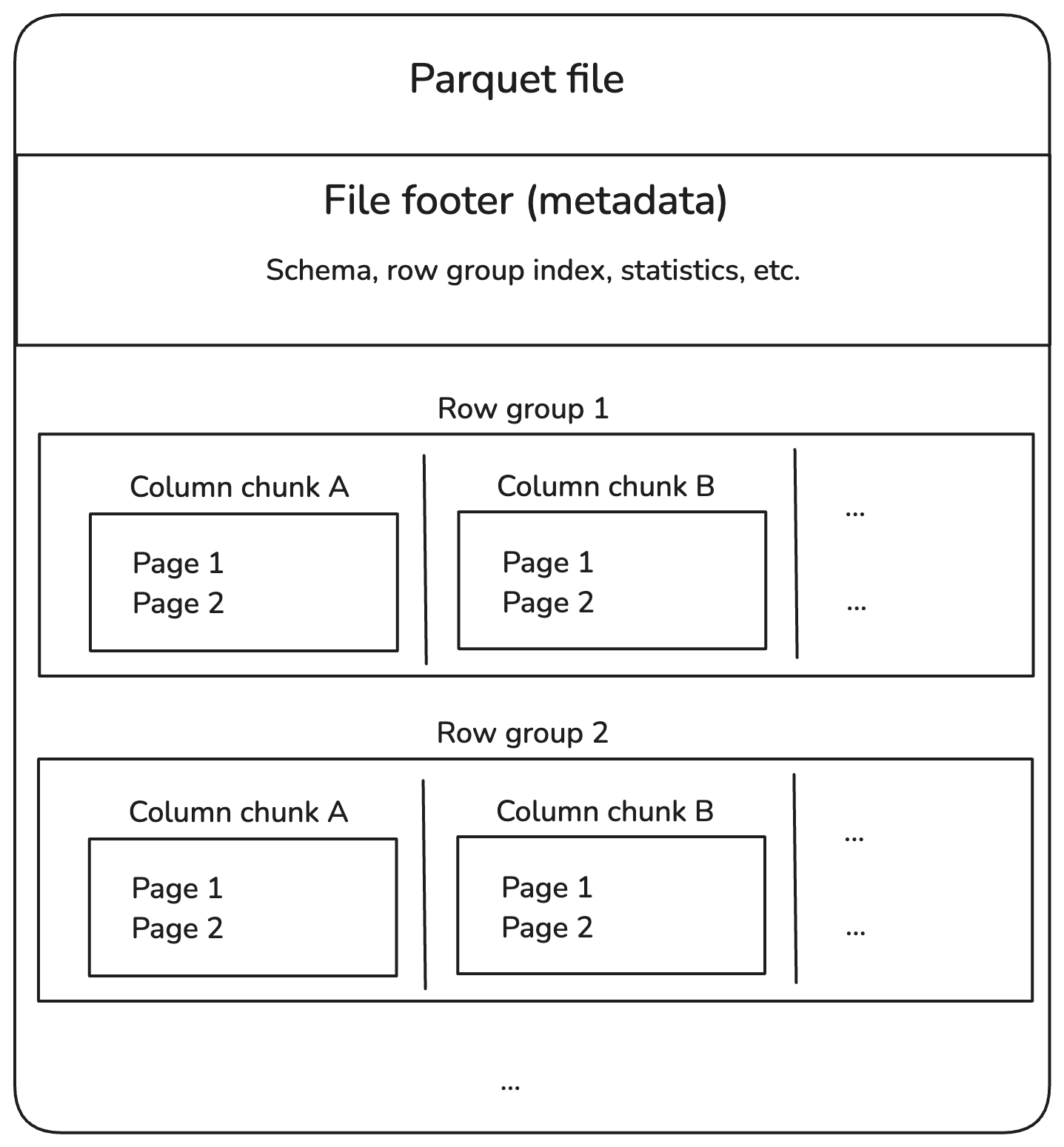
Interne structuur van Parquet-bestand. Afbeelding door de auteur.
Laten we elk onderdeel in het bovenstaande diagram doornemen.
Row groups
Column chunks
Pages
Footer (metadata)
Zoals genoemd comprimeert Parquet data kolom voor kolom met compressiemethoden zoals Snappy en Gzip. Het gebruikt ook twee coderingstechnieken:
Dit verkleint bestanden en versnelt het lezen van data, wat vooral handig is bij big data.
Schema-evolutie betekent het wijzigen van de structuur van datasets, zoals kolommen toevoegen of aanpassen. Dat klinkt eenvoudig, maar afhankelijk van hoe je data is opgeslagen, kan het aanpassen van het schema traag en resource-intensief zijn.
Laten we dit begrijpen door de schema-evolutie van CSV en Parquet te vergelijken.
Stel dat je een CSV-bestand hebt met kolommen zoals student_id, student_name en student_age. Als je een nieuwe kolom scores wilt toevoegen, moet je het volgende doen:
scores toe te voegen.NULL).CSV is een simpel tekstformaat zonder ingebouwde schemaondersteuning. Dit betekent dat elke wijziging in de structuur vereist dat je het hele bestand herschrijft, en oudere systemen die het aangepaste bestand lezen kunnen stuklopen als ze een andere structuur verwachten!
Met Parquet kun je velden toevoegen, verwijderen of bijwerken zonder je bestaande bestanden te breken. Zoals we eerder zagen, slaat Parquet schema-informatie op in de footer (metadata) van het bestand, waardoor schema’s kunnen evolueren zonder bestaande bestanden te wijzigen.
Zo werkt het:
NULL terug in plaats van de query te laten falen.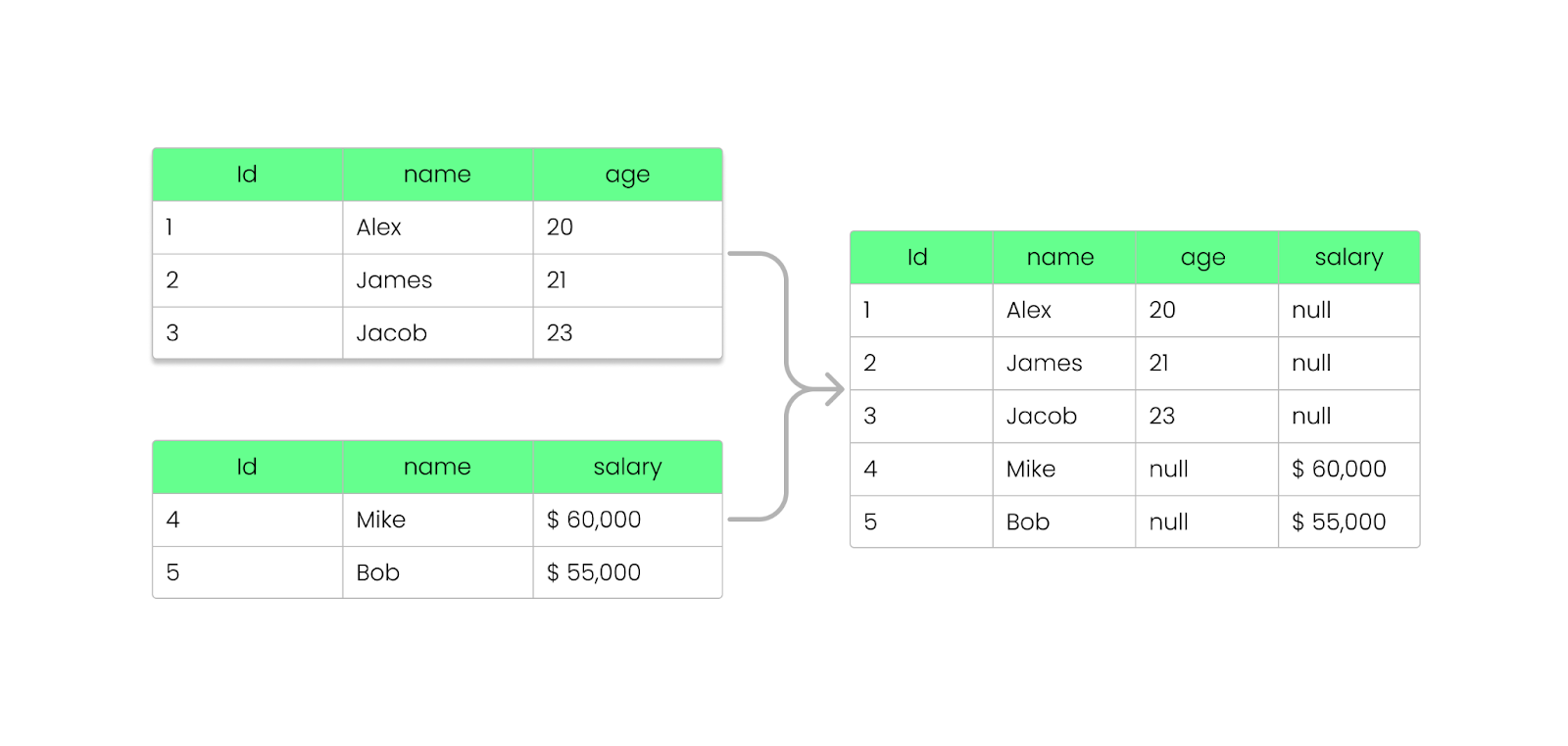
Een kolom toevoegen aan het Parquet-bestand zonder het te breken. Afbeelding door de auteur.
Parquet ondersteunt verschillende programmeertalen, zoals Java, Python, C++ en Rust. Ontwikkelaars kunnen het daardoor gemakkelijk gebruiken, ongeacht hun platform. Het is ook native geïntegreerd met big data-frameworks zoals Apache Spark, Hive, Presto, Flink en Trino, wat efficiënte dataverwerking op schaal garandeert.
Dus of je nu Python (via PySpark) of een andere taal gebruikt, Parquet kan de data beheren op een manier die het makkelijk maakt om te queryen en te analyseren op verschillende platforms.
Als je nieuw bent met big data-frameworks, raad ik de cursus Introduction to PySpark aan. Een prima startpunt.
Nu je de basis van Apache Parquet kent, laat ik je zien hoe je Parquet-bestanden schrijft, leest en integreert met pandas, PyArrow en andere big data-frameworks zoals Spark.
Om DataFrames als Parquet-bestanden op te slaan, heb je pandas en een Parquet-engine zoals PyArrow nodig:
pip install pandas pyarrowSchrijf nu een Parquet-bestand met de volgende code:
import pandas as pd
# Sample DataFrame
data = {
"Name": ["Alice", "Bob", "Charlie"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
}
df = pd.DataFrame(data)
# Write to Parquet file
df.to_parquet("data.parquet", engine="pyarrow", index=False)
print("Parquet file written successfully!")
Schrijf het Parquet-bestand met pandas. Afbeelding door de auteur.
Hier is eenvoudige code om je Parquet-bestand te lezen:
import pandas as pd
# Read the Parquet file
df = pd.read_parquet("data.parquet", engine="pyarrow")
print("Data from Parquet file:")
print(df)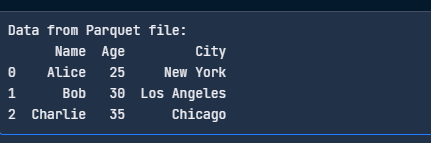
Lees het Parquet-bestand met pandas. Afbeelding door de auteur.
PyArrow is een tool uit het Apache Arrow-project die het werken met Parquet-bestanden eenvoudig maakt. Zo schrijf je een Parquet-bestand met PyArrow:
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# Sample data
df = pd.DataFrame({
"Name": ["Jacob", "Lauren", "Oliver"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
})
# Convert to a PyArrow table
table = pa.Table.from_pandas(df)
# Write to Parquet file
pq.write_table(table, "data.parquet")
print("Parquet file written successfully!")
Schrijf een Parquet-bestand met PyArrow. Afbeelding door de auteur.
Zo lees je een Parquet-bestand met PyArrow:
import pyarrow.parquet as pq
# Read the Parquet file
table = pq.read_table("data.parquet")
# Convert to a pandas DataFrame
df = table.to_pandas()
print("Data from Parquet file:")
print(df)
Lees het Parquet-bestand met PyArrow. Afbeelding door de auteur.
We kunnen Spark gebruiken om Parquet-bestanden direct te lezen en te schrijven. Download het van de website van Apache Spark of stel het in volgens de instructies.
Als dat klaar is, importeer je de libraries en maak je een DataFrame:
from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName("SparkExample").getOrCreate()
# Define the schema for the dataset
schema = ["Name", "Age", "City"]
# Create a sample data
data = [
("Jacob", 30, "New York"),
("Lauren", 35, "Los Angeles"),
("Billy", 25, "Chicago")
]
# Create a DataFrame from the sample data
df = spark.createDataFrame(data, schema)
# Show the DataFrame
df.show()
Maak een voorbeeld-DataFrame in Spark. Afbeelding door de auteur.
Schrijf vervolgens dit DataFrame als een Parquet-bestand:
# Write DataFrame to Parquet
df.write.parquet("data.parquet")De write.parquet() slaat het DataFrame op in het Parquet-formaat, en het bestand heet employee.parquet. Om dit Parquet-bestand te lezen, kun je de volgende code gebruiken:
# Read the Parquet file
parquet_df = spark.read.parquet("data.parquet")
# Show the DataFrame
parquet_df.show()
Lees het Parquet-bestand. Afbeelding door de auteur.
Naast Spark kan Parquet ook met Hive werken. Wanneer je een Hive-tabel maakt, gebruik dan STORED AS PARQUET om Parquet als opslagformaat te gebruiken.
Naast lezen en schrijven zijn er een paar basisbewerkingen die elke ontwikkelaar zou moeten kennen, omdat ze handig zijn bij het werken met Parquet-bestanden. Laten we die in deze sectie doornemen.
Ik gebruik pandas en PyArrow om de concepten te illustreren.
Data toevoegen (appen) is handig wanneer nieuwe records moeten worden toegevoegd zonder de volledige dataset te herschrijven.
import pyarrow.parquet as pq
import pyarrow as pa
# Load existing Parquet file
existing_table = pq.read_table("data.parquet")
# New data
new_data = pd.DataFrame({
"Name": ["David", "Emma"],
"Age": [40, 28],
"City": ["San Francisco", "Seattle"]
})
# Convert new data to PyArrow table
new_table = pa.Table.from_pandas(new_data)
# Concatenate both tables
merged_table = pa.concat_tables([existing_table, new_table])
# Write back to Parquet file
pq.write_table(merged_table, "data.parquet")In plaats van de hele dataset te laden, kun je alleen de noodzakelijke kolommen selecteren, wat het geheugenverbruik vermindert en de prestaties verbetert. Dit is aanzienlijk sneller dan de volledige dataset lezen:
df = pd.read_parquet("data.parquet", columns=["Name", "Age"])
print(df)Parquet ondersteunt efficiënt filteren op opslagniveau, bekend als predicate pushdown, waardoor onnodige data niet wordt geladen. Dit voorkomt het scannen van het hele bestand en maakt queries veel sneller:
import pyarrow.parquet as pq
# Read only rows where Age > 30
table = pq.read_table("data.parquet", filters=[("Age", ">", 30)])
df = table.to_pandas()
print(df)Vaak worden Parquet-bestanden opgeslagen als afzonderlijke partities. Je kunt ze samenvoegen tot één Parquet-bestand. Dit is handig bij het combineren van datasets uit verschillende bronnen:
import pyarrow.parquet as pq
import pyarrow as pa
# List of Parquet files to merge
file_list = ["data_part1.parquet", "data_part2.parquet"]
# Read all files and merge
tables = [pq.read_table(f) for f in file_list]
merged_table = pa.concat_tables(tables)
# Write merged Parquet file
pq.write_table(merged_table, "merged_data.parquet")Als je bestaande CSV-bestanden hebt, bespaart het converteren naar Parquet ruimte en versnelt het de verwerking, wat de bestandsgrootte drastisch vermindert en de leessnelheid verbetert:
df = pd.read_csv("data.csv")
df.to_parquet("data.parquet", engine="pyarrow", index=False)Partitioneren organiseert data in submappen op basis van een kolomwaarde, waardoor queries aanzienlijk sneller worden.
Zo schrijf je gepartitioneerde data:
df.to_parquet("partitioned_data/", engine="pyarrow", partition_cols=["City"])De bovenstaande code maakt submappen aan:
partitioned_data/City=New York/
partitioned_data/City=Los Angeles/
partitioned_data/City=Chicago/Vervolgens kun je slechts één specifieke partitie lezen:
df = pd.read_parquet("partitioned_data/City=New York/")
print(df)Dit versnelt analyses door alleen relevante partities te scannen!
Parquet ondersteunt compressie-algoritmen zoals Snappy, Gzip en Brotli om de bestandsgrootte te verkleinen:
df.to_parquet("compressed.parquet", engine="pyarrow", compression="snappy")Toen ik begon met Apache Parquet, merkte ik dat kleine aanpassingen de efficiëntie flink kunnen verbeteren. Hier zijn enkele van mijn top-tips om Parquet te optimaliseren in praktijksituaties.
Als je opslag wilt besparen, zijn codecs zoals Snappy of Gzip vaak je beste opties — Snappy biedt snelle compressie en decompressie, perfect wanneer snelheid het belangrijkst is.
Gzip is daarentegen ideaal als je krap zit met opslag maar iets tragere reads accepteert. De sleutel is je werklast begrijpen — een snellere codec zoals Snappy wint vaak als je bestanden vaak opent. Gzip is juist beter voor archiveringsdata.
Verdeel je data in logische subsets, zoals per datum, regio of een ander vaak gequeryde kolom, om de hoeveelheid gescande data tijdens een query te verminderen. Ik werkte eens met een dataset met jaren aan transactie-logs en partitioneerde die per jaar en maand, waardoor specifieke perioden in seconden in plaats van minuten opgehaald werden.
Ik zorg er altijd voor dat nieuwe kolommen zo worden toegevoegd dat bestaande processen niet worden verstoord. Dat betekent meestal toevoegen in plaats van bestaande wijzigen. Gebruik hiervoor de ondersteuning voor schema-evolutie in Apache Spark om overgangen soepeler te laten verlopen.
Laten we Parquet vergelijken met andere opslagformaten.
Dit kwam al aan bod in de blogpost, maar ik benadruk het graag nog een keer: Parquet en CSV zijn twee verschillende formaten die data anders behandelen.
Parquet organiseert data in kolommen, terwijl CSV het in rijen plaatst. Met Parquet wordt alle data uit dezelfde kolom gegroepeerd, zodat je eenvoudig data uit specifieke kolommen kunt ophalen zonder door de rest te gaan. Het is sneller en neemt minder ruimte in omdat Parquet data comprimeert.
Kolomgebaseerd formaat van Parquet. Afbeelding door de auteur.
CSV daarentegen slaat data rij voor rij op. Het is eenvoudig en werkt goed voor kleine datasets, maar is niet ideaal voor grote. Elke query moet de hele rij lezen, zelfs als je maar een paar kolommen nodig hebt. Dit vertraagt en kost meer geheugen om te verwerken.
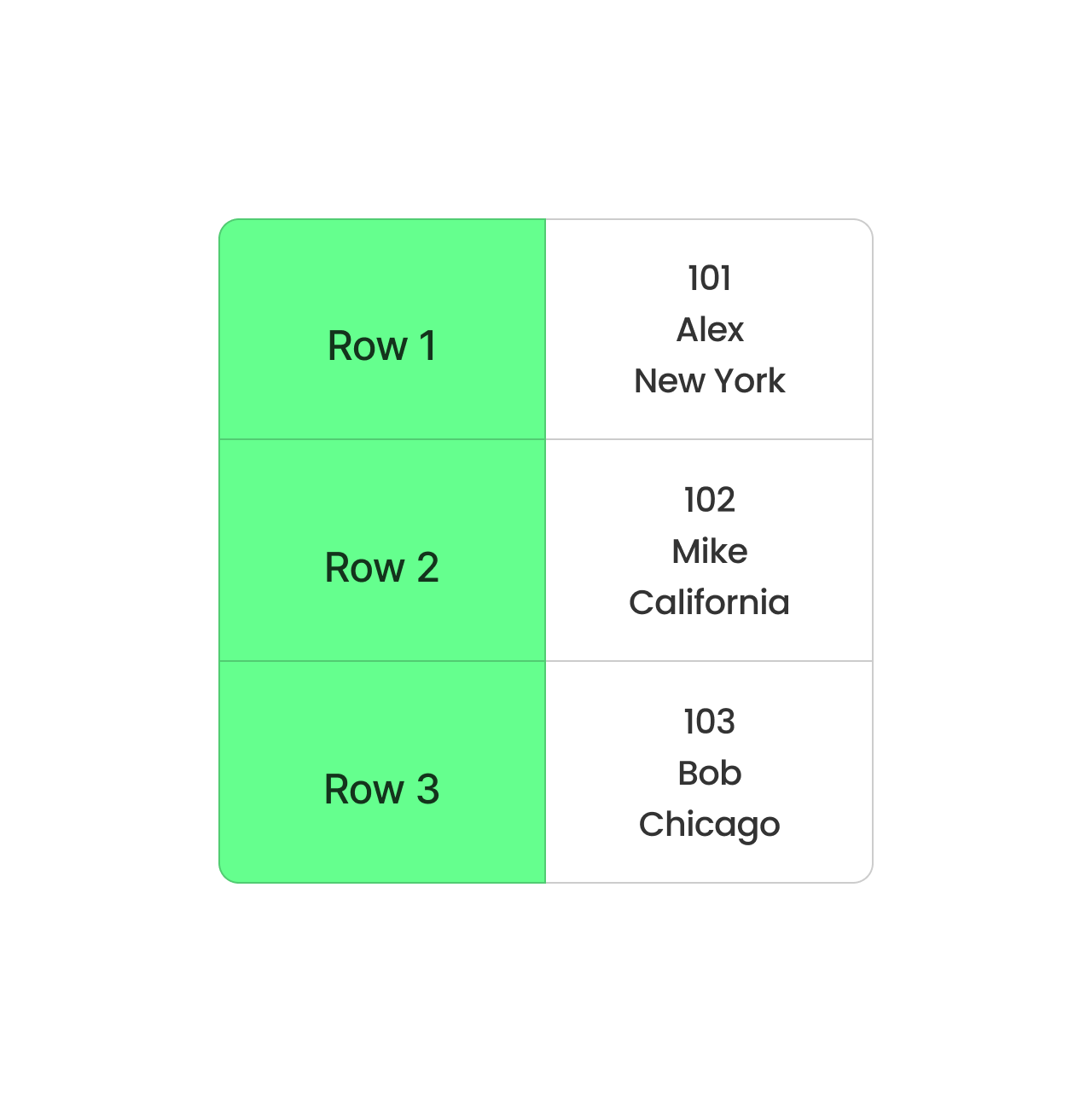
Rijgebaseerd formaat van CSV. Afbeelding door de auteur.
JSON is geweldig om data op een begrijpelijke manier te structureren, maar heeft een nadeel: het is niet erg efficiënt qua opslag of snelheid. Laat me met een voorbeeld uitleggen waarom Parquet efficiënter is dan JSON.
Stel dat we een tabel met werknemersdata hebben met drie kolommen: EmployeeID, Department en Location:
|
EmployeeID |
Department |
Location |
|
1 |
HR |
New York |
|
2 |
HR |
New York |
|
3 |
HR |
New York |
|
4 |
IT |
San Francisco |
|
5 |
IT |
San Francisco |
Als we deze data als JSON opslaan, ziet het er ongeveer zo uit:
[
{"EmployeeID": 1, "Department": "HR", "Location": "New York"},
{"EmployeeID": 2, "Department": "HR", "Location": "New York"},
{"EmployeeID": 3, "Department": "HR", "Location": "New York"},
{"EmployeeID": 4, "Department": "IT", "Location": "San Francisco"},
{"EmployeeID": 5, "Department": "IT", "Location": "San Francisco"}
]Merk op dat JSON kolomnamen zoals EmployeeID, Department en Location bij elk record herhaalt. Ook worden de waarden HR en New York meerdere keren herhaald. Dat maakt het bestand veel groter en trager.
Laten we ons nu voorstellen (want Parquet is niet menselijk leesbaar) dat we dezelfde data als Parquet opslaan:
In plaats van rij voor rij op te slaan, organiseert Parquet de data per kolom en comprimeert herhalende waarden.
Avro is een rijgebaseerd formaat. Het is ideaal voor taken zoals streamingdata of logverwerking, waarbij je voortdurend nieuwe records toevoegt of complete rijen ophaalt. Maar het kolomgebaseerde formaat van Parquet is perfect voor analytics. Als je queries draait om grote hoeveelheden data te analyseren, werkt Parquet het best. Het haalt data op uit de benodigde kolommen en slaat de rest over om tijd en resources te besparen.
Kortom: Parquet is beter voor het lezen en analyseren van grote datasets, terwijl Avro ideaal is voor het snel schrijven en opslaan van data die eenvoudig te updaten is.
Hier is een vergelijkingstabel van Parquet vs. CSV vs. JSON vs. Avro, inclusief voor- en nadelen en use-cases:
|
Formaat |
Voordelen |
Nadelen |
Use-cases |
|
Parquet |
✅ Kolomformaat voor snelle analytics ✅ Hoge compressie-efficiëntie ✅ Ondersteunt schema-evolutie ✅ Geoptimaliseerd voor big data-frameworks (Spark, Hive, Presto) ✅ Ondersteunt predicate pushdown (efficiënt filteren) |
❌ Niet menselijk leesbaar ❌ Trager voor rijgebaseerde operaties ❌ Complexere schrijfoperaties |
|
|
CSV |
✅ Menselijk leesbaar en eenvoudig ✅ Makkelijk te genereren en parsen ✅ Compatibel met vrijwel alle tools |
❌ Geen schema-ondersteuning ❌ Traag voor grote datasets ❌ Grote bestanden (geen compressie) ❌ Hele bestand scannen voor queries |
|
|
JSON |
✅ Ondersteunt geneste en semi-gestructureerde data ✅ Menselijk leesbaar ✅ Veelgebruikt in web-API’s ✅ Flexibel schema |
❌ Grotere bestanden (vanwege tekstformaat) ❌ Traag voor big data-queries ❌ Geen native indexing |
|
|
Avro |
✅ Rijgebaseerd formaat voor snelle writes ✅ Compact binair formaat (efficiënte opslag) ✅ Ondersteunt schema-evolutie ✅ Goed voor streaming en message queues |
❌ Niet menselijk leesbaar ❌ Minder efficiënt voor analytische queries dan Parquet ❌ Vereist Avro-libraries voor verwerking |
|
Samenvattend, dit zijn situaties waarin Parquet de beste keuze is:
Apache Parquet is perfect voor het werken met big data. Het is snel, bespaart opslagruimte en werkt met tools zoals Spark. Als je meer wilt leren, bekijk dan de volgende resources:
Leer meer over data engineering met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
