
Curso
Fundamentos do PySpark
4 h
157.5K
Vamos entender a arquitetura do Apache Parquet com seus principais recursos:
Ao contrário dos formatos baseados em linhas, como o CSV, o Parquet organiza os dados em colunas. Isso significa que, quando executamos uma consulta, ela extrai apenas as colunas específicas de que precisamos, em vez de carregar tudo. Isso melhora o desempenho e reduz o uso de E/S.
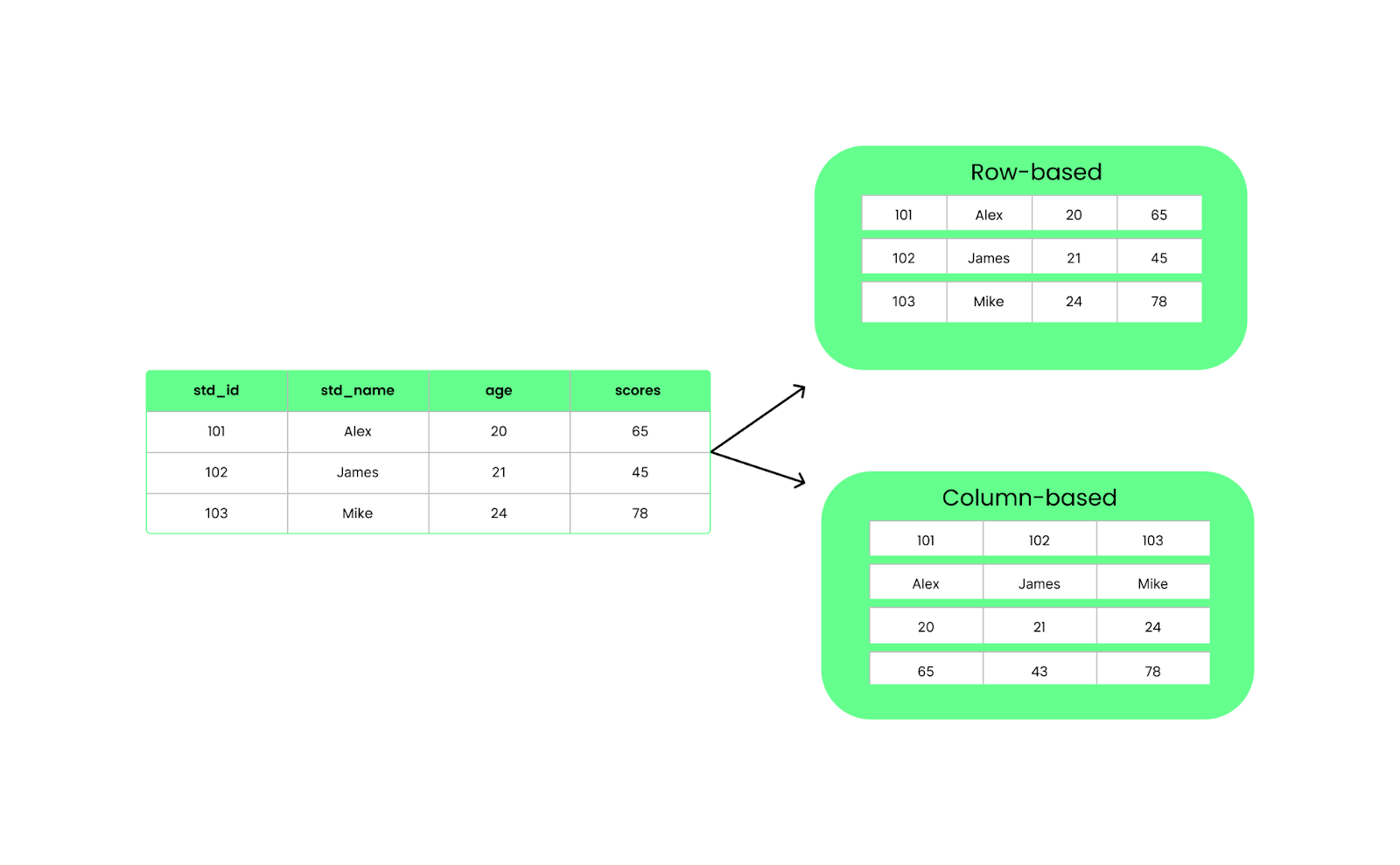
Estrutura baseada em linhas ou colunas. Imagem do autor.
Os arquivos Parquet são divididos em grupos de linhas, que contêm um lote de linhas. Cada grupo de linhas é dividido em partes de colunas, cada uma contendo dados para uma coluna. Esses blocos são divididos em partes menores, chamadas páginas, que são compactadas para economizar espaço.
Além disso, os arquivos Parquet armazenam informações extras no rodapé, chamadas metadados, que localizam e leem somente os dados de que precisamos.
Aqui está a aparência da estrutura:
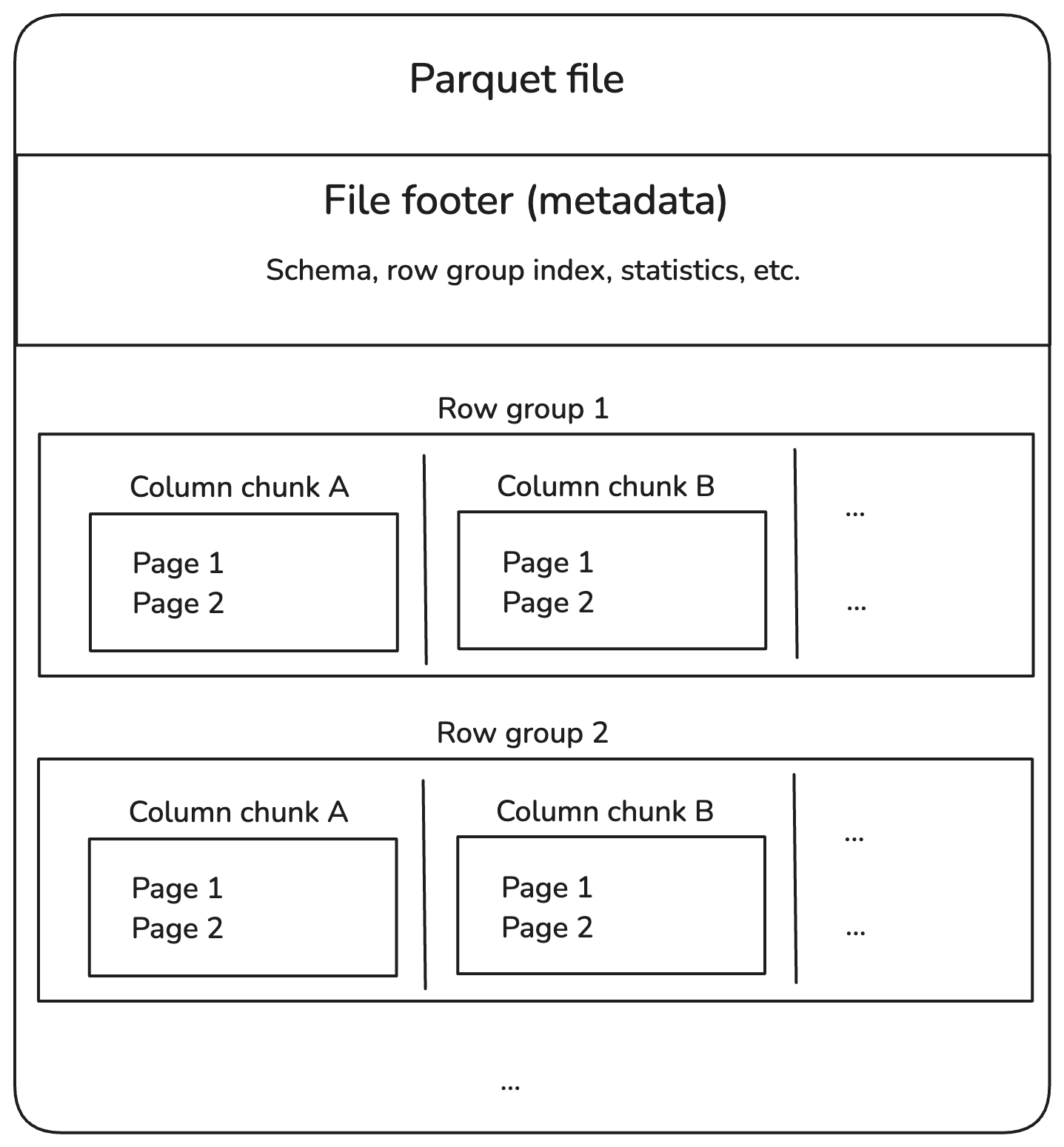
Estrutura interna do arquivo Parquet. Imagem do autor.
Vamos detalhar cada componente do diagrama acima.
Grupos de linhas
Partes de coluna
Páginas
Rodapé (metadados)
Conforme mencionado, o Parquet comprime os dados coluna por coluna usando métodos de compactação como Snappy e Gzip. Ele também usa duas técnicas de codificação:
Isso reduz o tamanho dos arquivos e acelera a leitura de dados, o que é especialmente útil quando você trabalha com big data.
A evolução do esquema significa modificar a estrutura dos conjuntos de dados, como adicionar ou alterar colunas. Pode parecer simples, mas dependendo de como os dados são armazenados, a modificação do esquema pode ser lenta e exigir muitos recursos.
Vamos entender isso comparando a evolução dos esquemas CSV e Parquet.
Suponha que você tenha um arquivoCSV com colunas como student_id, student_name e student_age. Se você quiser adicionar uma nova coluna scores, terá de fazer o seguinte:
scores.NULL).O CSV é um formato simples baseado em texto, sem suporte a esquemas incorporados. Isso significa que qualquer alteração na estrutura requer a reescrita de todo o arquivo, e os sistemas mais antigos que lerem o arquivo modificado poderão falhar se esperarem uma estrutura diferente!
Com o Parquet, você pode adicionar, remover ou atualizar campos sem quebrar os arquivos existentes. Como vimos anteriormente, o Parquet armazena as informações do esquema no rodapé do arquivo (metadados), permitindo a evolução dos esquemas sem modificar os arquivos existentes.
Veja como isso funciona:
NULL em vez de interromper a consulta.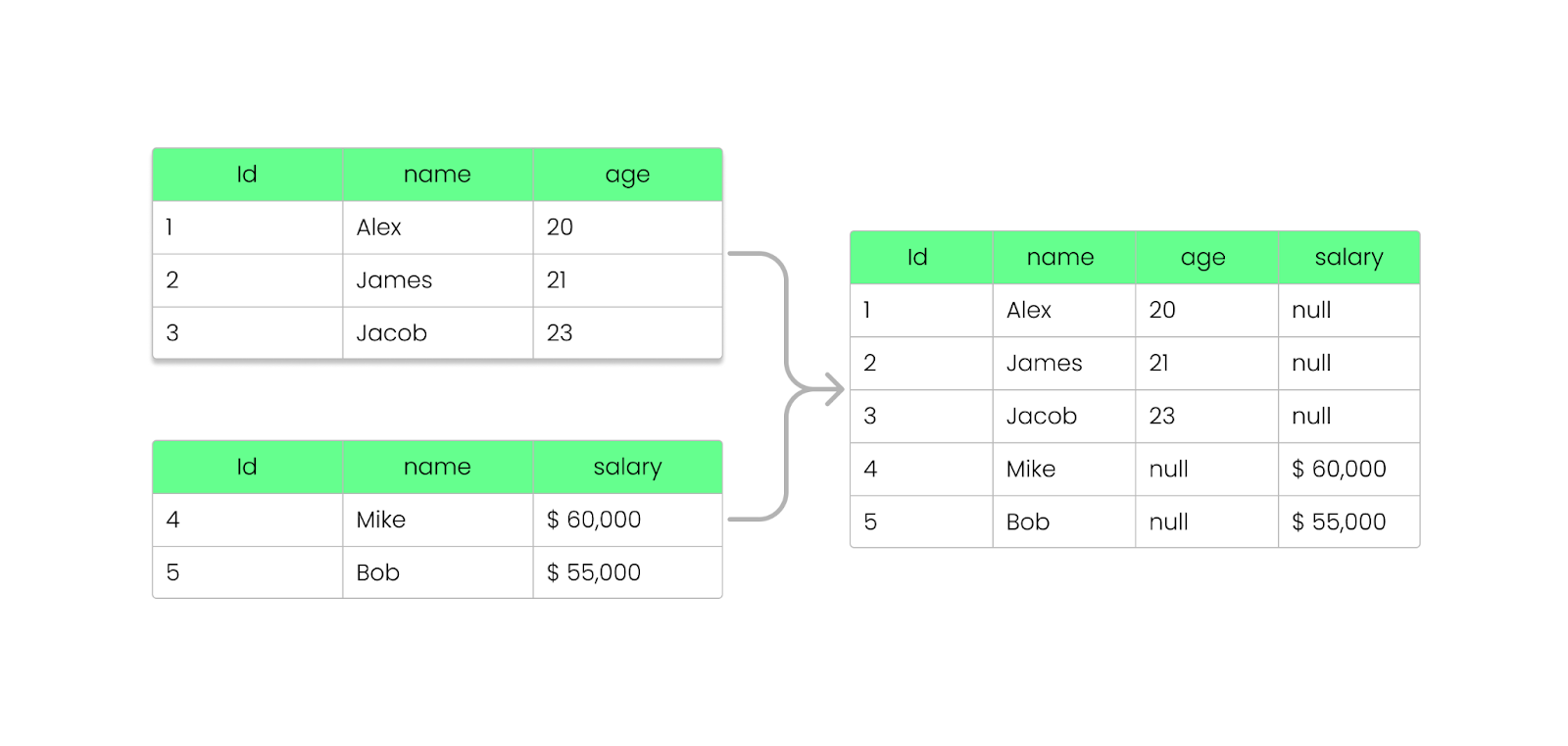
Adicionar uma coluna ao arquivo Parquet sem quebrá-lo. Imagem do autor.
O Parquet oferece suporte a diferentes linguagens de programação, como Java, Python, C++ e Rust. Isso significa que os desenvolvedores podem usá-lo facilmente, independentemente de sua plataforma. Ele também é integrado nativamente a estruturas de big data como Apache Spark, Hive, Presto, Flink e Trino, garantindo um processamento de dados eficiente em escala.
Portanto, quer você esteja usando Python (por meio do PySpark) ou outra linguagem, o Parquet pode gerenciar os dados de forma a facilitar a consulta e a análise em diferentes plataformas.
Se você não tem experiência com estruturas de Big Data, recomendo que faça o curso Introduction to PySpark. É uma ótima maneira de você começar.
Agora que você conhece os conceitos básicos do Apache Parquet, vou orientá-lo na gravação, leitura e integração dearquivos Parquet com o pandas, PyArrowe outras estruturas de Big Data, como o Spark.
Para salvar DataFrames como arquivos Parquet, você precisa do pandas e de um mecanismo Parquet como o PyArrow:
pip install pandas pyarrowAgora, escreva um arquivo Parquet usando o código a seguir:
import pandas as pd
# Sample DataFrame
data = {
"Name": ["Alice", "Bob", "Charlie"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
}
df = pd.DataFrame(data)
# Write to Parquet file
df.to_parquet("data.parquet", engine="pyarrow", index=False)
print("Parquet file written successfully!")
Escreva o arquivo Parquet com o pandas. Imagem do autor.
Aqui está um código simples para você ler seu arquivo Parquet:
import pandas as pd
# Read the Parquet file
df = pd.read_parquet("data.parquet", engine="pyarrow")
print("Data from Parquet file:")
print(df)
Leia o arquivo Parquet com o pandas. Imagem do autor.
O PyArrow é uma ferramenta do projeto Apache Arrow que facilita o trabalho com arquivos Parquet. Veja como você pode gravar um arquivo parquet usando o PyArrow:
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# Sample data
df = pd.DataFrame({
"Name": ["Jacob", "Lauren", "Oliver"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
})
# Convert to a PyArrow table
table = pa.Table.from_pandas(df)
# Write to Parquet file
pq.write_table(table, "data.parquet")
print("Parquet file written successfully!")
Escreva um arquivo Parquet com o PyArrow. Imagem do autor.
Veja como você pode ler um arquivo Parquet usando o PyArrow:
import pyarrow.parquet as pq
# Read the Parquet file
table = pq.read_table("data.parquet")
# Convert to a pandas DataFrame
df = table.to_pandas()
print("Data from Parquet file:")
print(df)
Leia o arquivo Parquet com o PyArrow. Imagem do autor.
Podemos usar o Spark para ler e gravar arquivos Parquet diretamente. Faça o download dono site do Apache Spark ou configure-o seguindo as instruções .
Quando terminar, importe as bibliotecas e crie um DataFrame:
from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName("SparkExample").getOrCreate()
# Define the schema for the dataset
schema = ["Name", "Age", "City"]
# Create a sample data
data = [
("Jacob", 30, "New York"),
("Lauren", 35, "Los Angeles"),
("Billy", 25, "Chicago")
]
# Create a DataFrame from the sample data
df = spark.createDataFrame(data, schema)
# Show the DataFrame
df.show()
Crie um DataFrame de amostra no Spark. Imagem do autor.
Em seguida, escreva esse DataFrame como um arquivo Parquet:
# Write DataFrame to Parquet
df.write.parquet("data.parquet")O write.parquet() salva o DataFrame no formato Parquet, e o arquivo será chamado de employee.parquet. Agora, para ler esse arquivo Parquet, você pode usar o seguinte código:
# Read the Parquet file
parquet_df = spark.read.parquet("data.parquet")
# Show the DataFrame
parquet_df.show()
Ler o arquivo Parquet. Imagem do autor.
Além do Spark, o Parquet também pode trabalhar com o Hive. Quando você criar uma tabela do Hive, use STORED AS PARQUET para tornar o Parquet o formato de armazenamento.
Além da leitura e da gravação, há algumas operações básicas que todo desenvolvedor deve conhecer, pois elas são úteis ao trabalhar com arquivos Parquet. Vamos analisá-las nesta seção.
Usarei o pandas e o PyArrow para ilustrar os conceitos.
Anexar dados é útil quando novos registros precisam ser adicionados sem reescrever todo o conjunto de dados.
import pyarrow.parquet as pq
import pyarrow as pa
# Load existing Parquet file
existing_table = pq.read_table("data.parquet")
# New data
new_data = pd.DataFrame({
"Name": ["David", "Emma"],
"Age": [40, 28],
"City": ["San Francisco", "Seattle"]
})
# Convert new data to PyArrow table
new_table = pa.Table.from_pandas(new_data)
# Concatenate both tables
merged_table = pa.concat_tables([existing_table, new_table])
# Write back to Parquet file
pq.write_table(merged_table, "data.parquet")Em vez de carregar todo o conjunto de dados, você pode selecionar apenas as colunas necessárias, reduzindo o uso da memória e melhorando o desempenho. Isso é significativamente mais rápido do que ler o conjunto de dados completo:
df = pd.read_parquet("data.parquet", columns=["Name", "Age"])
print(df)O Parquet permite uma filtragem eficiente no nível de armazenamento, conhecida como predicado pushdown, que evita o carregamento de dados desnecessários. Isso evita a varredura de todo o arquivo, tornando as consultas muito mais rápidas:
import pyarrow.parquet as pq
# Read only rows where Age > 30
table = pq.read_table("data.parquet", filters=[("Age", ">", 30)])
df = table.to_pandas()
print(df)Em geral, os arquivos Parquet são armazenados em partições separadas. Você pode mesclá-los em um único arquivo Parquet. Isso é útil ao combinar conjuntos de dados de diferentes fontes:
import pyarrow.parquet as pq
import pyarrow as pa
# List of Parquet files to merge
file_list = ["data_part1.parquet", "data_part2.parquet"]
# Read all files and merge
tables = [pq.read_table(f) for f in file_list]
merged_table = pa.concat_tables(tables)
# Write merged Parquet file
pq.write_table(merged_table, "merged_data.parquet")Se você tiver arquivos CSV existentes, a conversão deles em Parquet economiza espaço e acelera o processamento, o que reduz drasticamente o tamanho do arquivo e melhora o desempenho da leitura:
df = pd.read_csv("data.csv")
df.to_parquet("data.parquet", engine="pyarrow", index=False)O particionamento organiza os dados em subdiretórios com base em um valor de coluna, tornando as consultas significativamente mais rápidas.
Veja como você pode gravar dados particionados:
df.to_parquet("partitioned_data/", engine="pyarrow", partition_cols=["City"])O código acima cria subdiretórios:
partitioned_data/City=New York/
partitioned_data/City=Los Angeles/
partitioned_data/City=Chicago/Então, você pode ler apenas uma partição específica:
df = pd.read_parquet("partitioned_data/City=New York/")
print(df)Isso acelera a análise, pois você verifica apenas as partições relevantes!
O Parquet oferece suporte a algoritmos de compactação como Snappy, Gzip e Brotli para reduzir o tamanho do arquivo:
df.to_parquet("compressed.parquet", engine="pyarrow", compression="snappy")Quando comecei a usar o Apache Parquet, percebi que pequenos ajustes poderiam melhorar muito sua eficiência. Aqui estão algumas das minhas principais dicas para otimizar o Parquet em cenários do mundo real.
Se você quiser economizar armazenamento, codecs como Snappy ou Gzip podem ser as opções que você precisa - o Snappy oferece compactação e descompactação rápidas, perfeitas para cenários em que a velocidade é mais importante.
Por outro lado, o Gzip é ideal se você tiver pouco espaço de armazenamento, mas puder suportar leituras um pouco mais lentas. A chave é entender sua carga de trabalho - um codec mais rápido como o Snappy geralmente vence se você acessa arquivos com frequência. No entanto, o Gzip é melhor para dados de arquivo.
Divida seus dados em subconjuntos lógicos, como por exemplo, por data, região ou qualquer outro campo consultado com frequência, para reduzir a quantidade de dados examinados durante uma consulta. Certa vez, trabalhei com um conjunto de dados que continha anos de registros de transações e o particionei por ano e mês para buscar períodos específicos em segundos em vez de minutos.
Sempre me certifico de que as novas colunas sejam adicionadas de forma a não interromper os processos existentes. Isso geralmente significa anexá-los em vez de modificar os existentes. Para isso, você pode usar o suporte à evolução de esquemas do Apache Spark para obter transições mais suaves.
Vamos comparar o Parquet com outros formatos de armazenamento de dados.
Já falamos sobre isso na postagem do blog, mas quero enfatizá-lo novamente: Parquet e CSV são dois formatos diferentes que tratam os dados de forma diferente.
O Parquet organiza os dados em colunas, enquanto o CSV os organiza em linhas. Quando você usa o Parquet, todos os dados da mesma coluna são agrupados, de modo que você pode extrair facilmente dados de colunas específicas sem ter que vasculhar todo o resto. Ele é mais rápido e ocupa menos espaço porque o Parquet comprime os dados.
Formato baseado em colunas Parquet. Imagem do autor.
O CSV, por outro lado, armazena os dados linha por linha. É simples e funciona bem para conjuntos de dados pequenos, mas não é ideal para os grandes. Toda consulta precisa ler a linha inteira, mesmo que você só precise de algumas colunas. Isso torna as coisas mais lentas e requer mais memória para processar.
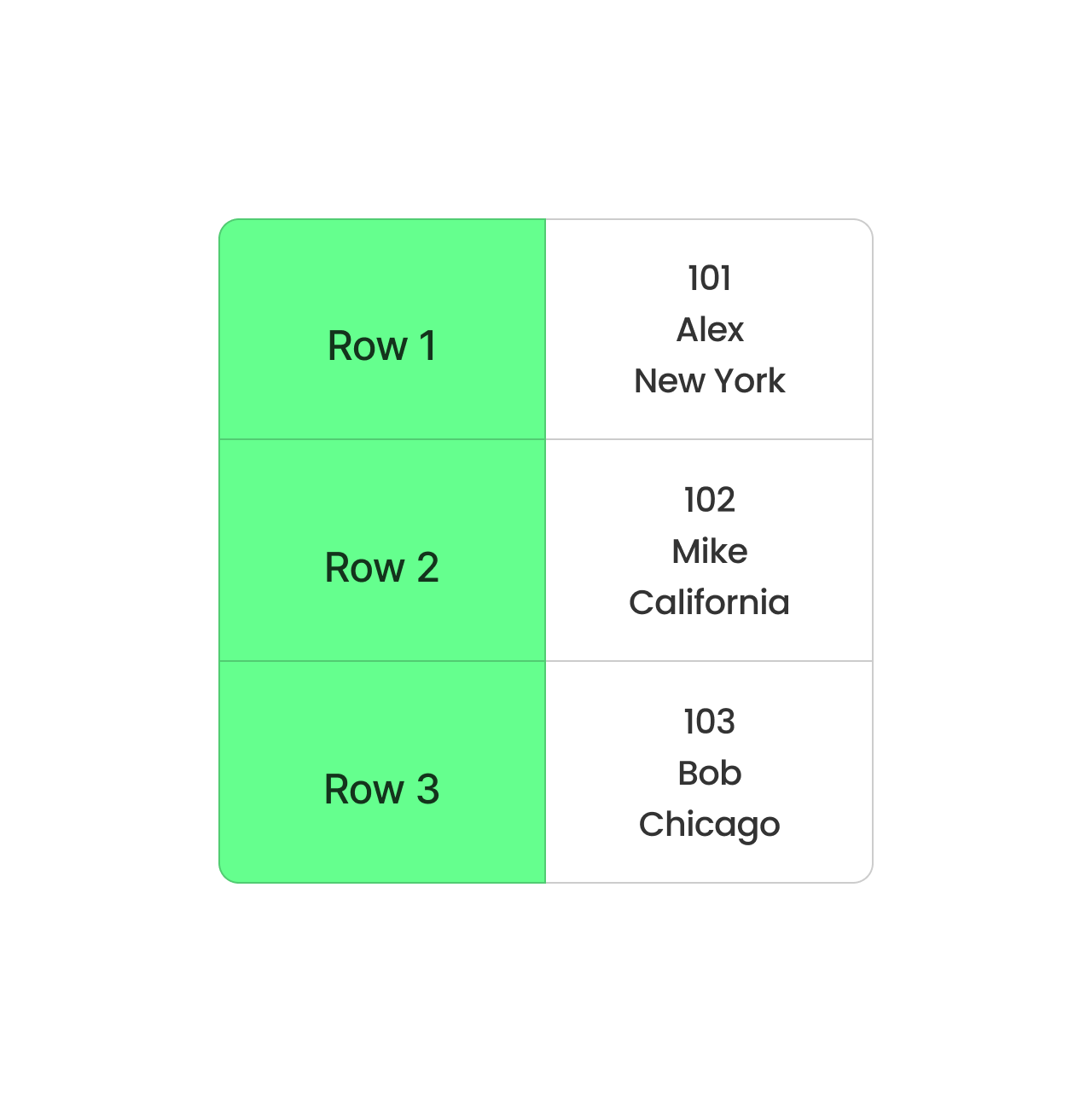
Formato baseado em linhas CSV. Imagem do autor.
O JSON é ótimo para estruturar dados de uma forma fácil de entender, mas tem uma desvantagem: não é muito eficiente em termos de armazenamento ou velocidade. Então, deixe-me explicar por que o Parquet é mais eficiente do que o JSON com um exemplo.
Suponhamos que você tenha uma tabela de dados de funcionários com três colunas: EmployeeID, Department, e Location:
|
EmployeeID |
Departamento |
Localização |
|
1 |
HR |
Nova York |
|
2 |
HR |
Nova York |
|
3 |
HR |
Nova York |
|
4 |
TI |
San Francisco |
|
5 |
TI |
San Francisco |
Agora, se salvarmos esses dados como JSON, eles terão a seguinte aparência:
[
{"EmployeeID": 1, "Department": "HR", "Location": "New York"},
{"EmployeeID": 2, "Department": "HR", "Location": "New York"},
{"EmployeeID": 3, "Department": "HR", "Location": "New York"},
{"EmployeeID": 4, "Department": "IT", "Location": "San Francisco"},
{"EmployeeID": 5, "Department": "IT", "Location": "San Francisco"}
]Observe como o JSON repete nomes de colunas como EmployeeID, Department e Location para cada registro. Você também repete os valores de HR e New York várias vezes. Isso torna o arquivo muito maior e mais lento.
Agora vamos imaginar (porque o Parquet não é legível por humanos) que salvamos os mesmos dados que o Parquet:
Em vez de armazenar linha por linha, o Parquet organiza os dados por colunas e comprime os valores repetidos.
O Avro é um formato baseado em linhas. É excelente para tarefas como streaming de dados ou processamento de logs, em que você adiciona constantemente novos registros ou recupera linhas completas. Mas o formato baseado em colunas do Parquet é perfeito para análises. Se você executar consultas para analisar grandes quantidades de dados, o Parquet funcionará melhor. Ele extrai dados das colunas necessárias e ignora o restante para economizar tempo e recursos.
Em resumo, o Parquet é melhor para ler e analisar grandes conjuntos de dados, enquanto o Avro é ideal para gravar e armazenar dados de forma fácil de atualizar.
Aqui está uma tabela de comparação entre o Parquet e o Parquet . CSV vs. JSON vs. Avro, incluindo prós, contras e casos de uso:
|
Formato |
Prós |
Contras |
Casos de uso |
|
Parquet |
Formato colunar para análises rápidas Alta eficiência de compressão Suporta a evolução do esquema Otimizado para estruturas de big data (Spark, Hive, Presto) Suporte a pushdown de predicados (filtragem eficiente) |
Não legível por humanos Mais lento para operações baseadas em linhas Operações de gravação mais complexas |
|
|
CSV |
Simples e legível por humanos Fácil de gerar e analisar Compatível com quase todas as ferramentas |
Sem suporte a esquemas Lento para grandes conjuntos de dados Tamanhos de arquivo grandes (sem compactação) Você deve verificar todo o arquivo em busca de consultas |
|
|
JSON |
Suporta dados aninhados e semiestruturados Legível por humanos Amplamente usado em APIs da Web Esquema flexível |
Tamanhos de arquivo maiores (devido ao formato de texto) Lento para consultas de big data Sem indexação nativa |
|
|
Avro |
Formato baseado em linhas para gravações rápidas Formato binário compacto (armazenamento eficiente) Suporta a evolução do esquema Bom para streaming e filas de mensagens |
Não legível por humanos Menos eficiente para consultas analíticas em comparação com o Parquet Requer bibliotecas Avro para processamento |
|
Em resumo, aqui estão algumas situações em que o Parquet é a melhor opção:
O Apache Parquet é perfeito para lidar com big data. Ele é rápido, economiza espaço de armazenamento e funciona com ferramentas como o Spark. Se você está animado para saber mais, confira os seguintes recursos :
Saiba mais sobre engenharia de dados com estes cursos!
Curso
Curso
Curso
blog
Moez Ali
11 min
blog
Mike Shakhomirov
11 min
Tutorial
Tim Lu
Tutorial
Zoumana Keita
Tutorial
Natassha Selvaraj
Tutorial
Joleen Bothma
