
Kurs
Einführung in PySpark
4 Std.
157.5K
Lass uns die Architektur von Apache Parquet mit seinen wichtigsten Funktionen verstehen:
Anders als zeilenbasierte Formate wie CSV organisiert Parquet die Daten in Spalten. Das bedeutet, dass bei einer Abfrage nur die benötigten Spalten abgefragt werden, anstatt alles zu laden. Das verbessert die Leistung und reduziert die E/A-Nutzung.
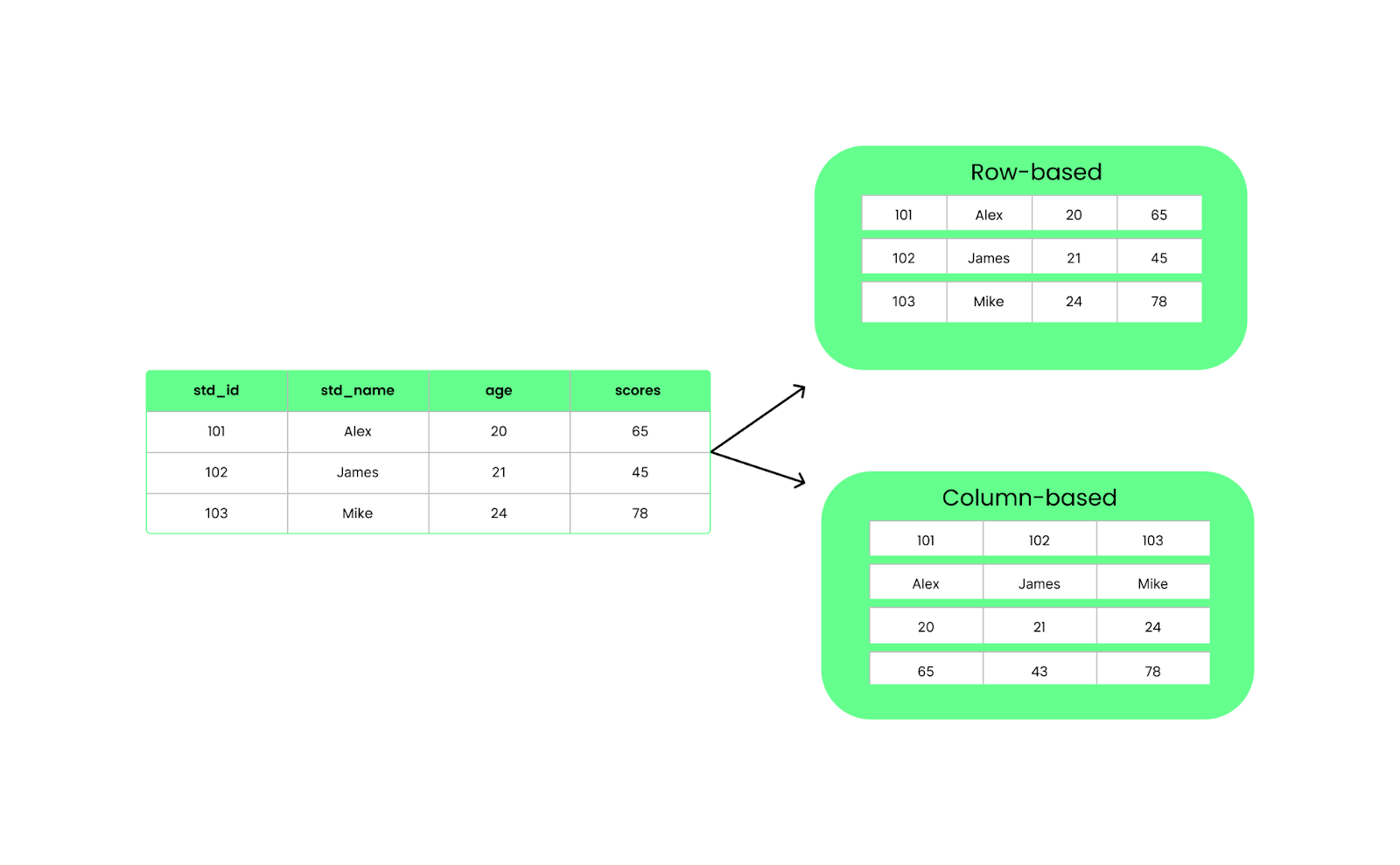
Zeilen- vs. spaltenbasierte Struktur. Bild vom Autor.
Parquet-Dateien sind in Zeilengruppen aufgeteilt, die einen Stapel von Zeilen enthalten. Jede Zeilengruppe ist in Spaltenblöcke unterteilt, die jeweils Daten für eine Spalte enthalten. Diese Chunks werden in kleinere Teile, die sogenannten Seiten, unterteilt, die komprimiert werden, um Platz zu sparen.
Außerdem speichern Parquet-Dateien zusätzliche Informationen in der Fußzeile, die so genannten Metadaten, die nur die Daten finden und lesen, die wir brauchen.
Hier siehst du, wie die Struktur aussieht:
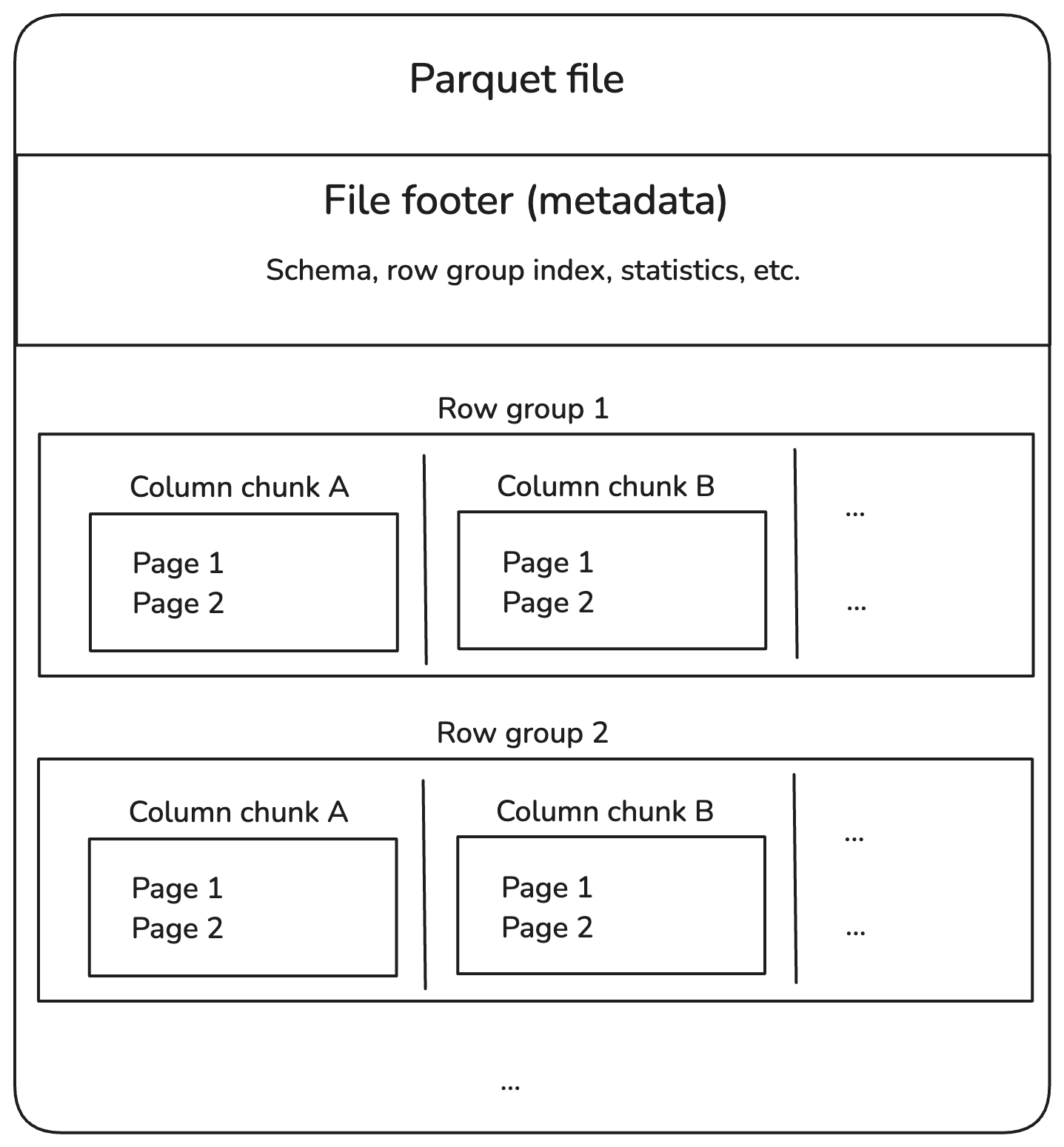
Interne Struktur der Parkettdatei. Bild vom Autor.
Lass uns die einzelnen Komponenten im obigen Diagramm aufschlüsseln.
Zeilengruppen
Spalten-Brocken
Seiten
Fußzeile (Metadaten)
Wie bereits erwähnt, komprimiert Parquet die Daten spaltenweise mit Kompressionsmethoden wie Snappy und Gzip. Außerdem werden zwei Kodierungstechniken verwendet:
Das reduziert die Dateigröße und beschleunigt das Lesen der Daten, was besonders hilfreich ist, wenn du mit großen Daten arbeitest.
Schemaentwicklung bedeutet, dass die Struktur von Datensätzen geändert wird, z. B. durch Hinzufügen oder Ändern von Spalten. Es mag einfach klingen, aber je nachdem, wie deine Daten gespeichert sind, kann die Änderung des Schemas langsam und ressourcenintensiv sein.
Um das zu verstehen, vergleichen wir die Entwicklung des CSV- und des Parkett-Schemas.
Angenommen, du hast eine CSV Datei mit Spalten wie student_id, student_name und student_age. Wenn du eine neue Spalte scores hinzufügen möchtest, musst du Folgendes tun:
scores.NULL).CSV ist ein einfaches textbasiertes Format ohne integrierte Schemaunterstützung. Das bedeutet, dass bei jeder Änderung der Struktur die gesamte Datei neu geschrieben werden muss. Ältere Systeme, die die geänderte Datei lesen, könnten dann abbrechen, wenn sie eine andere Struktur erwarten!
Mit Parquet kannst du Felder hinzufügen, entfernen oder aktualisieren, ohne deine bestehenden Dateien zu zerstören. Wie wir bereits gesehen haben, speichert Parquet die Schemainformationen in der Fußzeile der Datei (Metadaten), sodass Schemata weiterentwickelt werden können, ohne dass bestehende Dateien verändert werden müssen.
So funktioniert es:
NULL zurück, anstatt die Abfrage abzubrechen.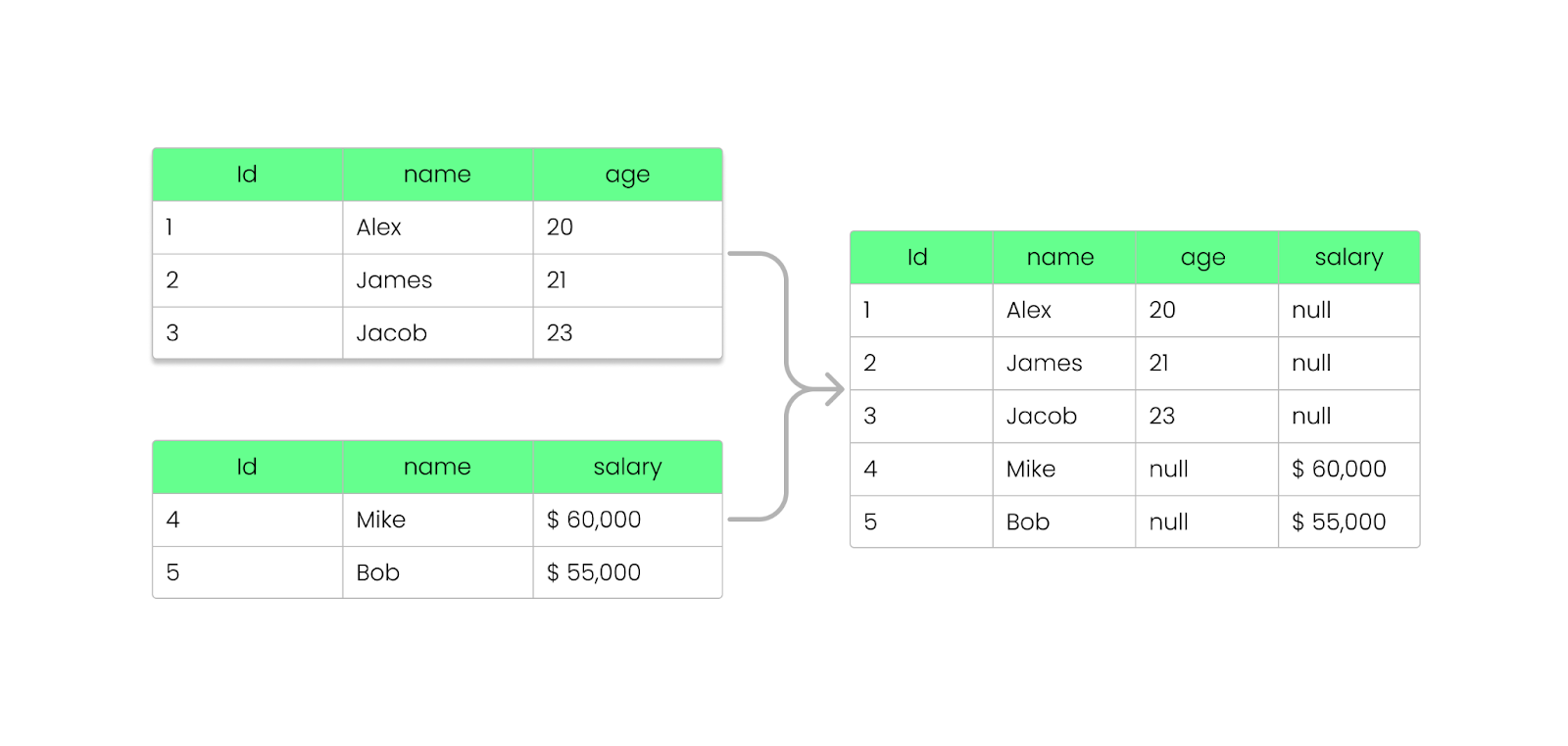
Hinzufügen einer Spalte zur Parkettdatei, ohne sie zu zerstören. Bild vom Autor.
Parquet unterstützt verschiedene Programmiersprachen, wie Java, Python, C++ und Rust. Das bedeutet, dass Entwickler es unabhängig von ihrer Plattform einfach nutzen können. Außerdem ist sie nativ in Big-Data-Frameworks wie Apache Spark, Hive, Presto, Flink und Trino integriert, was eine effiziente Datenverarbeitung im großen Maßstab gewährleistet.
Egal, ob du Python (über PySpark) oder eine andere Sprache verwendest, Parquet kann die Daten so verwalten, dass sie auf verschiedenen Plattformen leicht abgefragt und analysiert werden können.
Wenn du dich noch nicht mit Big Data-Frameworks auskennst, empfehle ich dir den Kurs Einführung in PySpark. Das ist eine gute Möglichkeit, um anzufangen.
Nachdem du nun die Grundlagen von Apache Parquet kennst, führe ich dich durch das Schreiben, Lesen und Integrieren vonParquet-Dateien mit Pandas, PyArrowund anderen Big Data Frameworks wie Spark.
Um DataFrames als Parquet-Dateien zu speichern, brauchst du Pandas und eine Parquet-Engine wie PyArrow:
pip install pandas pyarrowSchreibe nun eine Parquet-Datei mit folgendem Code:
import pandas as pd
# Sample DataFrame
data = {
"Name": ["Alice", "Bob", "Charlie"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
}
df = pd.DataFrame(data)
# Write to Parquet file
df.to_parquet("data.parquet", engine="pyarrow", index=False)
print("Parquet file written successfully!")
Schreibe die Parquet-Datei mit Pandas. Bild vom Autor.
Hier ist ein einfacher Code, um deine Parquet-Datei zu lesen:
import pandas as pd
# Read the Parquet file
df = pd.read_parquet("data.parquet", engine="pyarrow")
print("Data from Parquet file:")
print(df)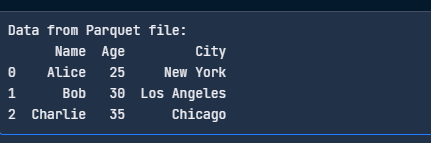
Lies die Parquet-Datei mit Pandas. Bild vom Autor.
PyArrow ist ein Tool aus dem Apache Arrow-Projekt, das die Arbeit mit Parkettdateien erleichtert. Hier erfährst du, wie du mit PyArrow eine Parkettdatei schreiben kannst:
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# Sample data
df = pd.DataFrame({
"Name": ["Jacob", "Lauren", "Oliver"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
})
# Convert to a PyArrow table
table = pa.Table.from_pandas(df)
# Write to Parquet file
pq.write_table(table, "data.parquet")
print("Parquet file written successfully!")
Schreibe eine Parquet-Datei mit PyArrow. Bild vom Autor.
Hier erfährst du, wie du eine Parquet-Datei mit PyArrow lesen kannst:
import pyarrow.parquet as pq
# Read the Parquet file
table = pq.read_table("data.parquet")
# Convert to a pandas DataFrame
df = table.to_pandas()
print("Data from Parquet file:")
print(df)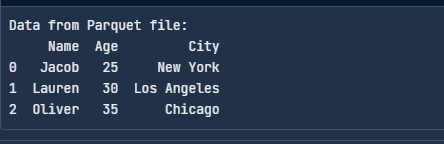
Lies die Parquet-Datei mit PyArrow ein. Bild vom Autor.
Wir können Spark nutzen, um Parquet-Dateien direkt zu lesen und zu schreiben. Lade sie von der Apache Spark-Websiteherunter oder richte sie gemäß den Anweisungen ein.
Anschließend importierst du die Bibliotheken und erstellst einen DataFrame:
from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName("SparkExample").getOrCreate()
# Define the schema for the dataset
schema = ["Name", "Age", "City"]
# Create a sample data
data = [
("Jacob", 30, "New York"),
("Lauren", 35, "Los Angeles"),
("Billy", 25, "Chicago")
]
# Create a DataFrame from the sample data
df = spark.createDataFrame(data, schema)
# Show the DataFrame
df.show()
Erstelle ein DataFrame-Beispiel in Spark. Bild vom Autor.
Als Nächstes schreibst du diesen DataFrame in eine Parquet-Datei:
# Write DataFrame to Parquet
df.write.parquet("data.parquet")write.parquet() speichert den DataFrame im Parquet-Format, und die Datei wird employee.parquet genannt. Um diese Parkettdatei zu lesen, kannst du den folgenden Code verwenden:
# Read the Parquet file
parquet_df = spark.read.parquet("data.parquet")
# Show the DataFrame
parquet_df.show()
Lies die Parkettdatei. Bild vom Autor.
Neben Spark kann Parquet auch mit Hive arbeiten. Wenn du eine Hive-Tabelle erstellst, verwende STORED AS PARQUET, um Parquet als Speicherformat festzulegen.
Neben dem Lesen und Schreiben gibt es einige grundlegende Operationen, die jeder Entwickler kennen sollte, da sie bei der Arbeit mit Parkettdateien nützlich sind. In diesem Abschnitt gehen wir sie durch.
Ich werde Pandas und PyArrow verwenden, um die Konzepte zu veranschaulichen.
Das Anhängen von Daten ist nützlich, wenn neue Datensätze hinzugefügt werden müssen, ohne den gesamten Datensatz neu zu schreiben.
import pyarrow.parquet as pq
import pyarrow as pa
# Load existing Parquet file
existing_table = pq.read_table("data.parquet")
# New data
new_data = pd.DataFrame({
"Name": ["David", "Emma"],
"Age": [40, 28],
"City": ["San Francisco", "Seattle"]
})
# Convert new data to PyArrow table
new_table = pa.Table.from_pandas(new_data)
# Concatenate both tables
merged_table = pa.concat_tables([existing_table, new_table])
# Write back to Parquet file
pq.write_table(merged_table, "data.parquet")Anstatt den gesamten Datensatz zu laden, kannst du nur die benötigten Spalten auswählen, was den Speicherbedarf reduziert und die Leistung verbessert. Das ist deutlich schneller als das Lesen des gesamten Datensatzes:
df = pd.read_parquet("data.parquet", columns=["Name", "Age"])
print(df)Parquet ermöglicht eine effiziente Filterung auf der Speicherebene, bekannt als Prädikats-Pushdown, der das Laden unnötiger Daten verhindert. Dadurch muss nicht die gesamte Datei gescannt werden, was Abfragen viel schneller macht:
import pyarrow.parquet as pq
# Read only rows where Age > 30
table = pq.read_table("data.parquet", filters=[("Age", ">", 30)])
df = table.to_pandas()
print(df)Oft werden die Parkettdateien in separaten Partitionen gespeichert. Du kannst sie in einer einzigen Parkettdatei zusammenführen. Dies ist nützlich, wenn du Datensätze aus verschiedenen Quellen kombinierst:
import pyarrow.parquet as pq
import pyarrow as pa
# List of Parquet files to merge
file_list = ["data_part1.parquet", "data_part2.parquet"]
# Read all files and merge
tables = [pq.read_table(f) for f in file_list]
merged_table = pa.concat_tables(tables)
# Write merged Parquet file
pq.write_table(merged_table, "merged_data.parquet")Wenn du vorhandene CSV-Dateien hast, spart die Konvertierung in Parquet Platz und beschleunigt die Verarbeitung, was die Dateigröße drastisch reduziert und die Leseleistung verbessert:
df = pd.read_csv("data.csv")
df.to_parquet("data.parquet", engine="pyarrow", index=False)Durch die Partitionierung werden Daten auf der Grundlage eines Spaltenwerts in Unterverzeichnissen organisiert, wodurch Abfragen deutlich schneller werden.
Hier erfährst du, wie du partitionierte Daten schreiben kannst:
df.to_parquet("partitioned_data/", engine="pyarrow", partition_cols=["City"])Der obige Code erstellt Unterverzeichnisse:
partitioned_data/City=New York/
partitioned_data/City=Los Angeles/
partitioned_data/City=Chicago/Dann kannst du nur eine bestimmte Partition lesen:
df = pd.read_parquet("partitioned_data/City=New York/")
print(df)Dies beschleunigt die Analyse, da nur relevante Partitionen gescannt werden!
Parquet unterstützt Komprimierungsalgorithmen wie Snappy, Gzip und Brotli, um die Dateigröße zu reduzieren:
df.to_parquet("compressed.parquet", engine="pyarrow", compression="snappy")Als ich anfing, Apache Parquet zu benutzen, merkte ich, dass kleine Anpassungen seine Effizienz erheblich verbessern können. Hier sind einige meiner besten Tipps für die Optimierung von Parkett in realen Szenarien.
Wenn du Speicherplatz sparen willst, können Codecs wie Snappy oder Gzip Snappy bietet eine schnelle Komprimierung und Dekomprimierung und eignet sich perfekt für Situationen, in denen es auf Geschwindigkeit ankommt.
Umgekehrt ist Gzip ideal, wenn du wenig Speicherplatz zur Verfügung hast, aber etwas langsamere Lesevorgänge verkraften kannst. Entscheidend ist, dass du dein Arbeitspensum verstehst - ein schneller Codec wie Snappy ist oft die bessere Wahl, wenn du häufig auf Dateien zugreifst. Für die Archivierung von Daten ist Gzip jedoch am besten geeignet.
Unterteile deine Daten in logische Teilmengen, z. B. nach Datum, Region oder einem anderen häufig abgefragten Feld, um die Datenmenge zu reduzieren, die bei einer Abfrage durchsucht wird. Ich habe einmal mit einem Datensatz gearbeitet, der Jahre von Transaktionsprotokollen enthielt, und ihn nach Jahr und Monat unterteilt, um bestimmte Zeiträume in Sekunden statt in Minuten abzurufen.
Ich achte immer darauf, dass neue Spalten so hinzugefügt werden, dass sie die bestehenden Prozesse nicht stören. Das bedeutet in der Regel, dass sie angehängt werden, anstatt bestehende zu ändern. Dazu kannst du die Schema-Evolution von Apache Spark nutzen, um sanftere Übergänge zu schaffen.
Lass uns Parquet mit anderen Datenspeicherformaten vergleichen.
Wir haben das bereits in diesem Blogpost behandelt, aber ich möchte es noch einmal betonen: Parquet und CSV sind zwei verschiedene Formate, die Daten unterschiedlich verarbeiten.
Parquet organisiert die Daten in Spalten, während CSV sie in Zeilen anordnet. Wenn du Parquet verwendest, werden alle Daten aus derselben Spalte gruppiert, so dass du ganz einfach Daten aus bestimmten Spalten abrufen kannst, ohne alles andere durchsuchen zu müssen. Es ist schneller und braucht weniger Platz, weil Parquet die Daten komprimiert.
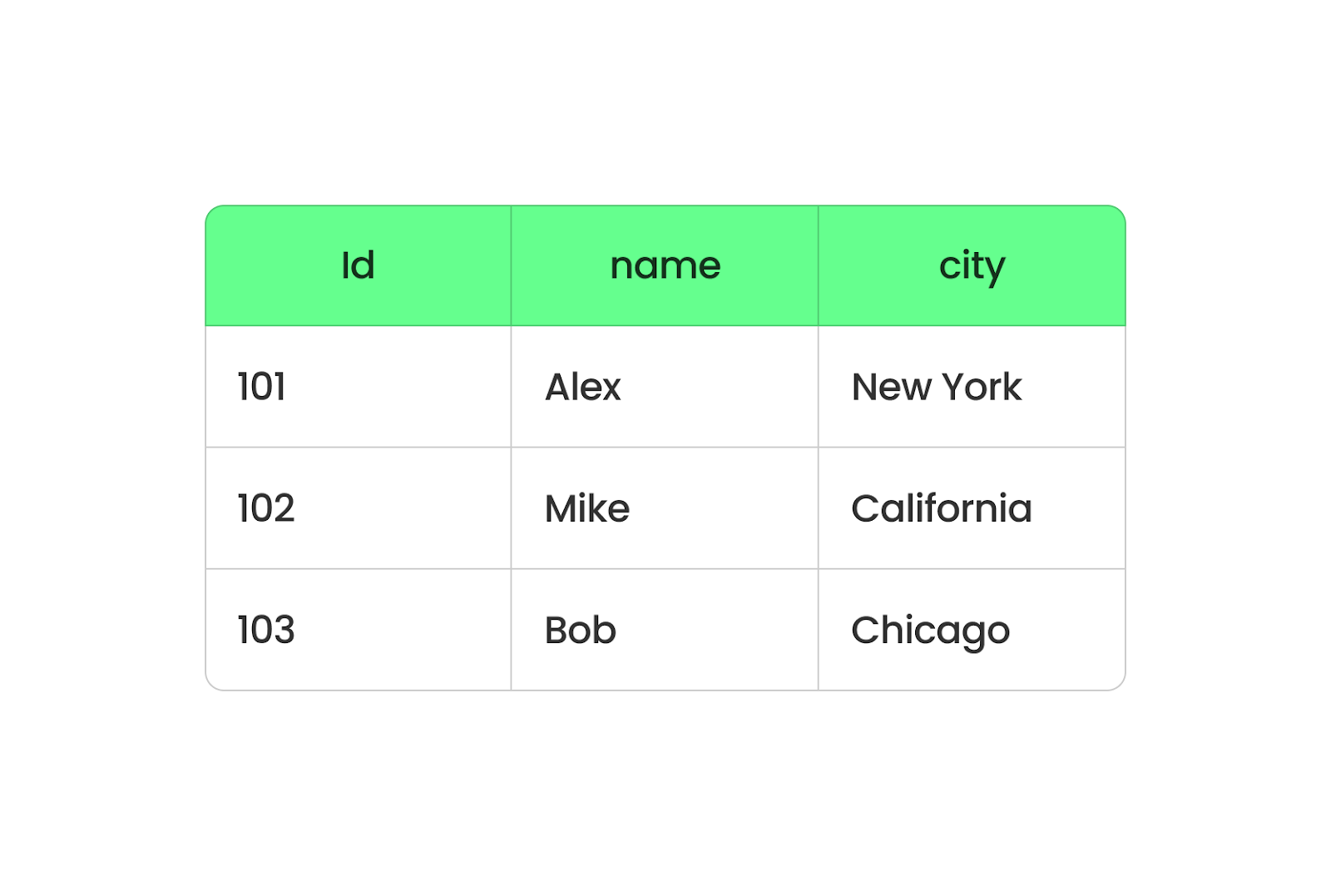
Spaltenbasiertes Parkettformat. Bild vom Autor.
CSV hingegen speichert die Daten Zeile für Zeile. Es ist einfach und funktioniert gut für kleine Datensätze, aber es ist nicht ideal für große Datensätze. Jede Abfrage muss die gesamte Zeile lesen, auch wenn du nur ein paar Spalten brauchst. Das verlangsamt die Abläufe und benötigt mehr Speicherplatz für die Verarbeitung.
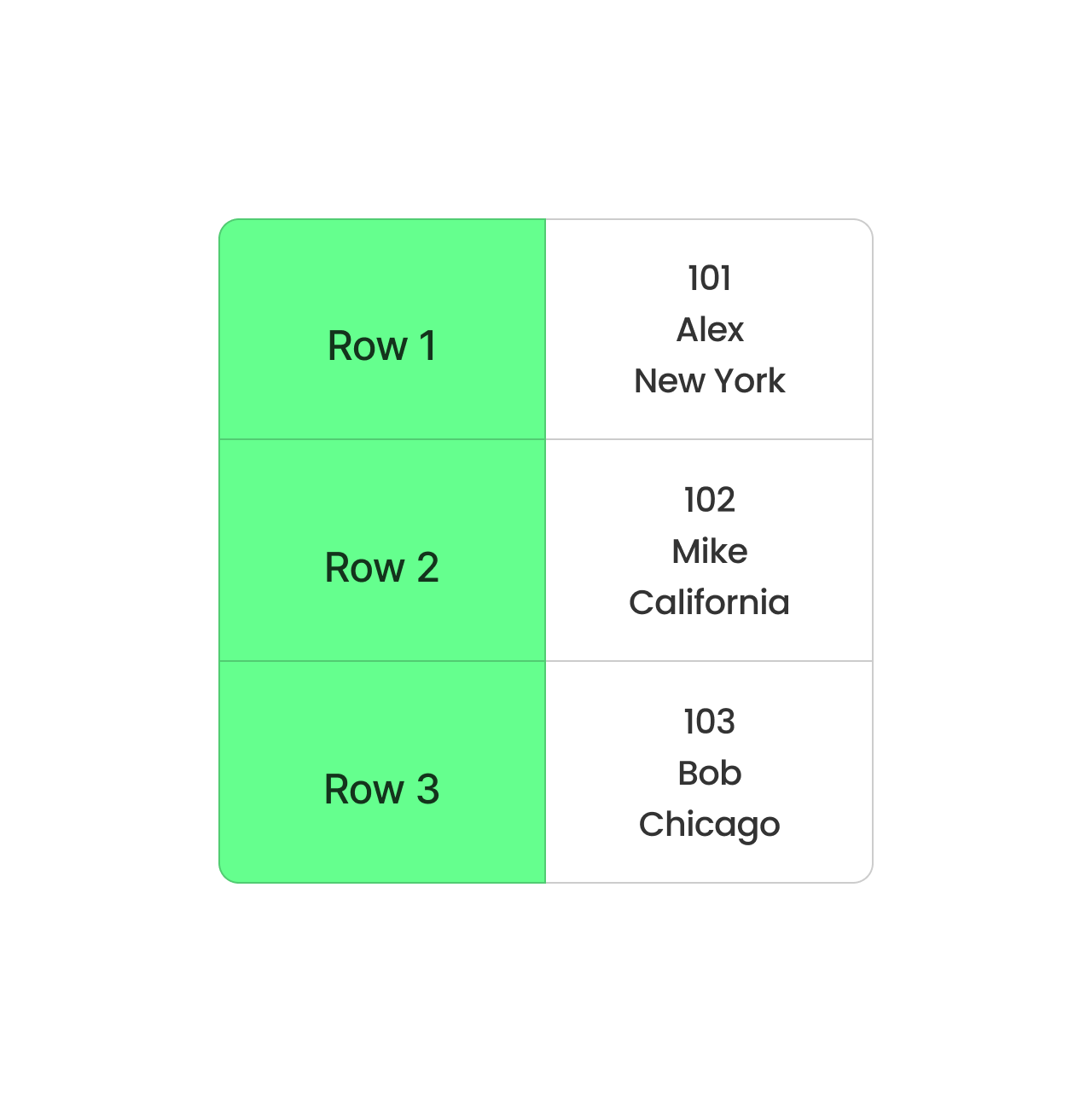
Zeilenbasiertes CSV-Format. Bild vom Autor.
JSON eignet sich hervorragend, um Daten so zu strukturieren, dass sie leicht zu verstehen sind, aber es hat einen Nachteil: Es ist nicht sehr effizient, was die Speicherung oder Geschwindigkeit angeht. Lass mich also anhand eines Beispiels erklären, warum Parquet effizienter ist als JSON.
Angenommen, wir haben eine Tabelle mit Mitarbeiterdaten mit drei Spalten: EmployeeID, Department, und Location:
|
EmployeeID |
Abteilung |
Standort |
|
1 |
HR |
New York |
|
2 |
HR |
New York |
|
3 |
HR |
New York |
|
4 |
IT |
San Francisco |
|
5 |
IT |
San Francisco |
Wenn wir diese Daten nun als JSON speichern, sehen sie etwa so aus:
[
{"EmployeeID": 1, "Department": "HR", "Location": "New York"},
{"EmployeeID": 2, "Department": "HR", "Location": "New York"},
{"EmployeeID": 3, "Department": "HR", "Location": "New York"},
{"EmployeeID": 4, "Department": "IT", "Location": "San Francisco"},
{"EmployeeID": 5, "Department": "IT", "Location": "San Francisco"}
]Beachte, dass JSON Spaltennamen wie EmployeeID, Department und Location für jeden einzelnen Datensatz wiederholt. Außerdem werden die Werte für HR und New York mehrfach wiederholt. Dadurch wird die Datei viel größer und langsamer.
Stellen wir uns nun vor (weil Parquet nicht für Menschen lesbar ist), wir speichern die gleichen Daten wie Parquet:
Anstatt Zeile für Zeile zu speichern, organisiert Parquet die Daten nach Spalten und komprimiert sich wiederholende Werte.
Avro ist ein zeilenbasiertes Format. Sie eignet sich hervorragend für Aufgaben wie das Streaming von Daten oder die Verarbeitung von Protokollen, bei denen du ständig neue Datensätze hinzufügst oder komplette Zeilen abrufst. Aber das spaltenbasierte Format von Parquet ist perfekt für Analysen. Wenn du Abfragen durchführst, um große Datenmengen zu analysieren, ist Parquet am besten geeignet. Es zieht die Daten aus den notwendigen Spalten und überspringt den Rest, um Zeit und Ressourcen zu sparen.
Kurz gesagt: Parquet eignet sich besser zum Lesen und Analysieren großer Datensätze, während Avro ideal zum Schreiben und Speichern von Daten ist, die sich leicht aktualisieren lassen.
Hier ist eine Tabelle zum Vergleich zwischen Parkett und CSV vs. JSON vs. Avro, einschließlich Vor- und Nachteile sowie Anwendungsfälle:
|
Format |
Pros |
Nachteile |
Anwendungsfälle |
|
Parkett |
✅ Säulenförmiges Format für schnelle Analysen ✅ Hohe Verdichtungseffizienz ✅ Unterstützt die Schemaentwicklung ✅ Optimiert für Big Data Frameworks (Spark, Hive, Presto) ✅ Unterstützt Prädikat-Pushdown (effiziente Filterung) |
❌ Nicht für Menschen lesbar Langsamer für zeilenbasierte Operationen ❌ Komplexere Schreiboperationen |
|
|
CSV |
✅ Menschenlesbar und einfach ✅ Einfach zu generieren und zu parsen ✅ Kompatibel mit fast allen Werkzeugen |
❌ Keine Schema-Unterstützung ❌ Langsam für große Datenmengen ❌ Große Dateigrößen (keine Komprimierung) ❌ Muss die gesamte Datei nach Abfragen durchsuchen |
|
|
JSON |
✅ Unterstützt verschachtelte und halbstrukturierte Daten ✅ Menschenlesbar ✅ Weit verbreitet in Web-APIs ✅ Flexibles Schema |
❌ Größere Dateigrößen (aufgrund des Textformats) ❌ Langsam für große Datenabfragen ❌ Keine native Indizierung |
|
|
Avro |
✅ Zeilenbasiertes Format für schnelles Schreiben ✅ Kompaktes Binärformat (effiziente Speicherung) ✅ Unterstützt die Schemaentwicklung ✅ Gut für Streaming und Nachrichtenwarteschlangen |
❌ Nicht für Menschen lesbar ❌ Weniger effizient für analytische Abfragen im Vergleich zu Parquet ❌ Benötigt Avro-Bibliotheken für die Verarbeitung |
|
Zusammengefasst gibt es hier einige Situationen, in denen Parkett die beste Wahl ist:
Apache Parquet ist perfekt für die Verarbeitung großer Datenmengen. Es ist schnell, spart Speicherplatz und funktioniert mit Tools wie Spark. Wenn du mehr erfahren möchtest, schau dir die folgenden Ressourcen an:
Lerne mehr über Data Engineering mit diesen Kursen!
Kurs
Kurs
Kurs
Tutorial
Javier Canales Luna
Tutorial
Matt Crabtree
Tutorial
Moez Ali
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Mark Pedigo
