
Kurs
PySpark Temelleri
4 sa
157.6K
Apache Parquet’in mimarisini, temel özellikleriyle birlikte anlayalım:
CSV gibi satır bazlı biçimlerin aksine Parquet verileri sütunlarda düzenler. Bu, bir sorgu çalıştırdığımızda her şeyi yüklemek yerine yalnızca ihtiyaç duyduğumuz özel sütunların çekileceği anlamına gelir. Bu da performansı artırır ve G/Ç kullanımını azaltır.
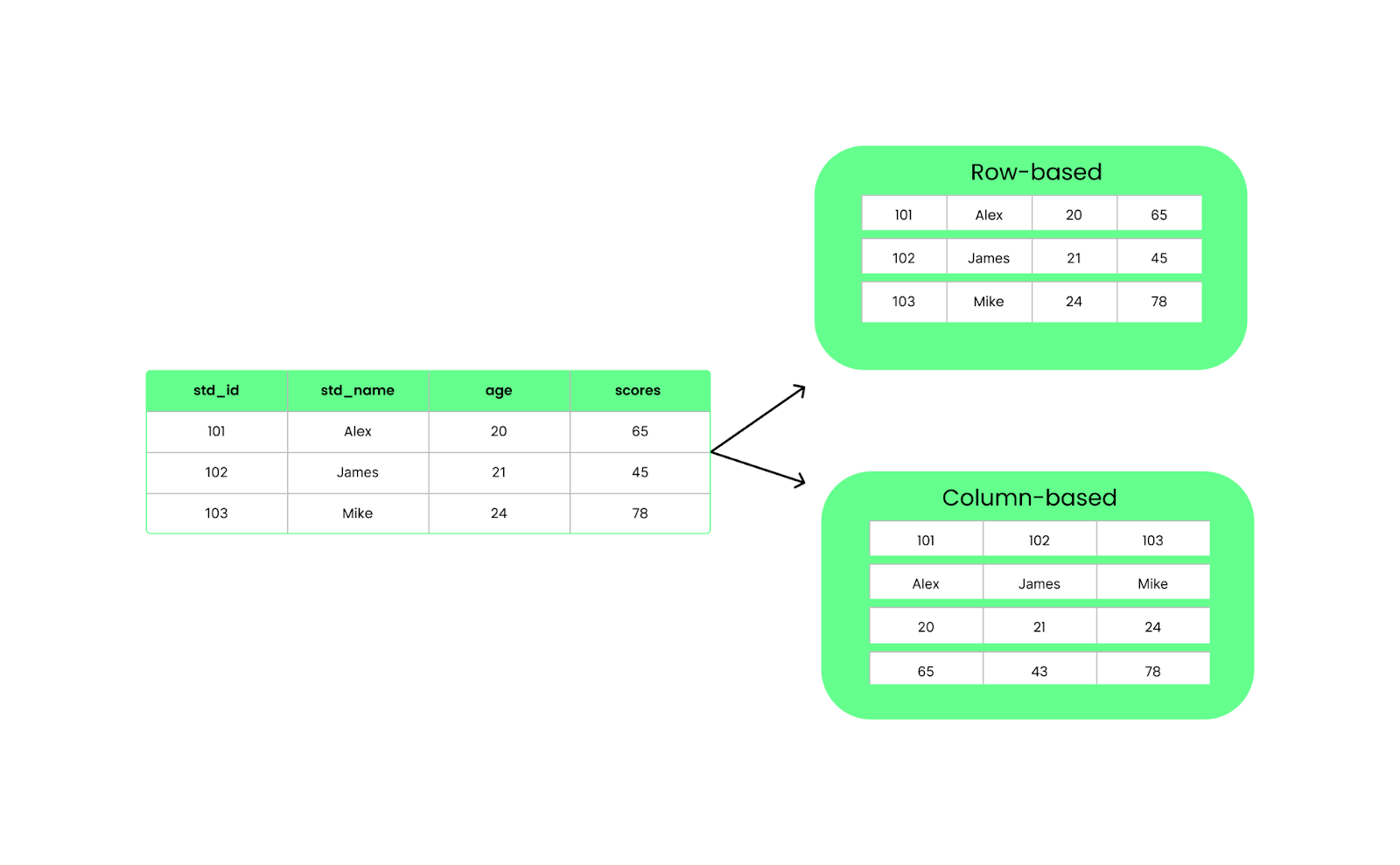
Satır bazlı ve sütun bazlı yapı. Görsel: Yazar.
Parquet dosyaları, bir grup satırı tutan satır gruplarına bölünür. Her satır grubu, her biri bir sütunun verilerini içeren sütun parçalarına ayrılır. Bu parçalar, sayfalar adı verilen daha küçük parçalara bölünür ve alan tasarrufu için sıkıştırılır.
Ayrıca Parquet dosyaları, yalnızca ihtiyaç duyduğumuz verileri bulup okumamızı sağlayan altbilgide (footer) meta veriler şeklinde ek bilgiler depolar.
Yapı kabaca şu şekildedir:
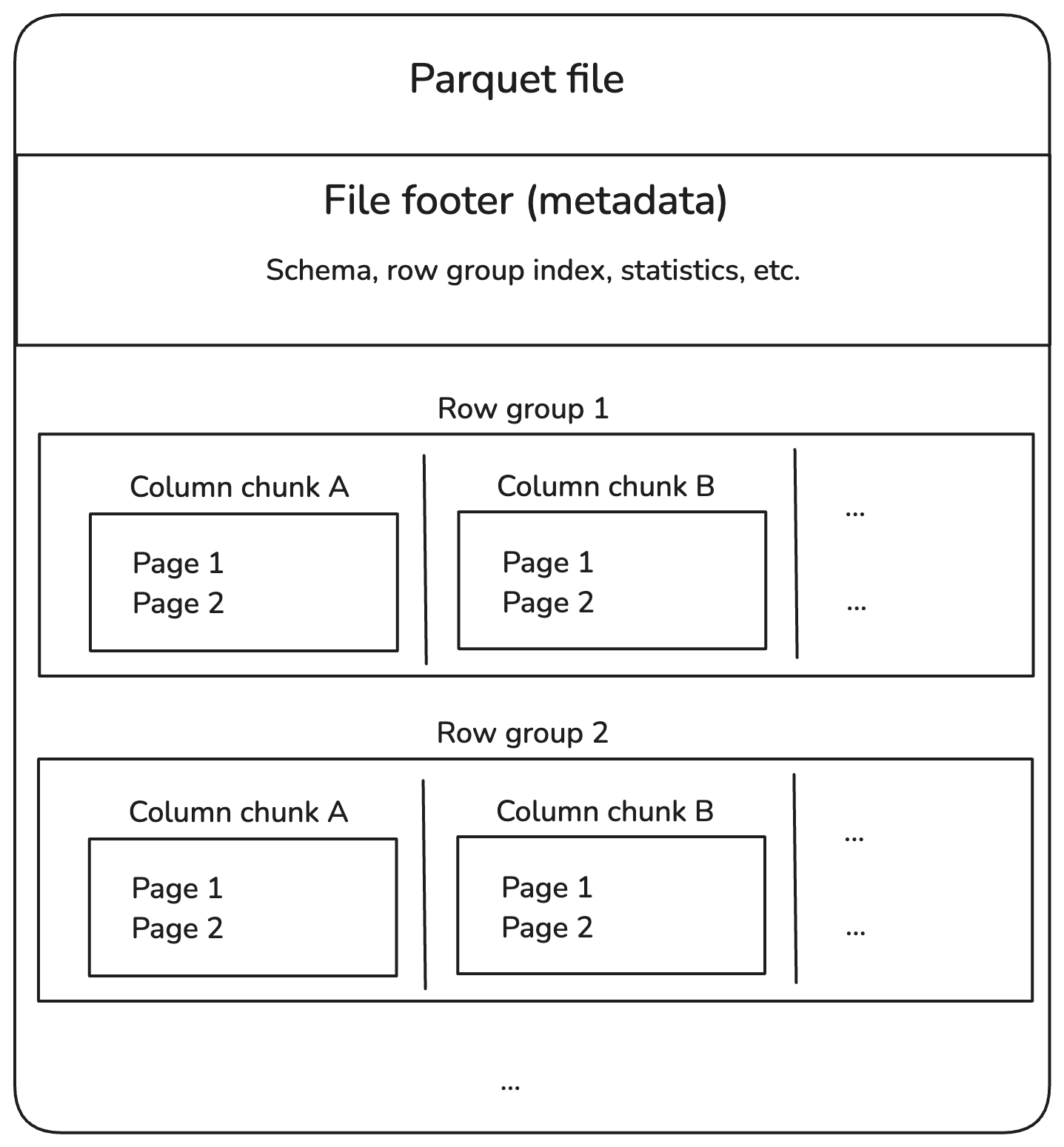
Parquet dosyasının iç yapısı. Görsel: Yazar.
Yukarıdaki diyagramdaki her bileşeni kısaca inceleyelim.
Satır grupları
Sütun parçaları
Sayfalar
Altbilgi (meta veriler)
Belirtildiği gibi, Parquet verileri sütun sütun Snappy ve Gzip gibi yöntemlerle sıkıştırır. Ayrıca iki kodlama tekniği kullanır:
Bu, dosya boyutlarını küçültür ve veri okuma hızını artırır; özellikle büyük verilerle çalışırken faydalıdır.
Şema evrimi, sütun eklemek veya değiştirmek gibi veri kümelerinin yapısının değiştirilmesi anlamına gelir. Basit görünse de, verinizin nasıl depolandığına bağlı olarak şemayı değiştirmek yavaş ve kaynak yoğun olabilir.
Bunu, CSV ve Parquet şema evrimini karşılaştırarak anlayalım.
Diyelim ki student_id, student_name ve student_age sütunlarına sahip bir CSV dosyanız var. Yeni bir scores sütunu eklemek istiyorsanız şunları yapmanız gerekir:
scores sütununu içerecek şekilde güncelleyin.NULL gibi yer tutucular gerekebilir).CSV, yerleşik şema desteği olmayan basit bir metin tabanlı biçimdir. Bu, yapıda yapılacak herhangi bir değişikliğin tüm dosyanın yeniden yazılmasını gerektirdiği ve değiştirilen dosyayı okuyan eski sistemlerin farklı bir yapı bekliyorlarsa bozulabileceği anlamına gelir!
Parquet ile alanları, mevcut dosyalarınızı bozmadan ekleyebilir, kaldırabilir veya güncelleyebilirsiniz. Daha önce gördüğümüz gibi Parquet, şema bilgisini dosya altbilgisinde (meta veriler) saklar ve böylece mevcut dosyaları değiştirmeden şemaların evrilmesine olanak tanır.
Nasıl çalıştığına bakalım:
NULL döndürür.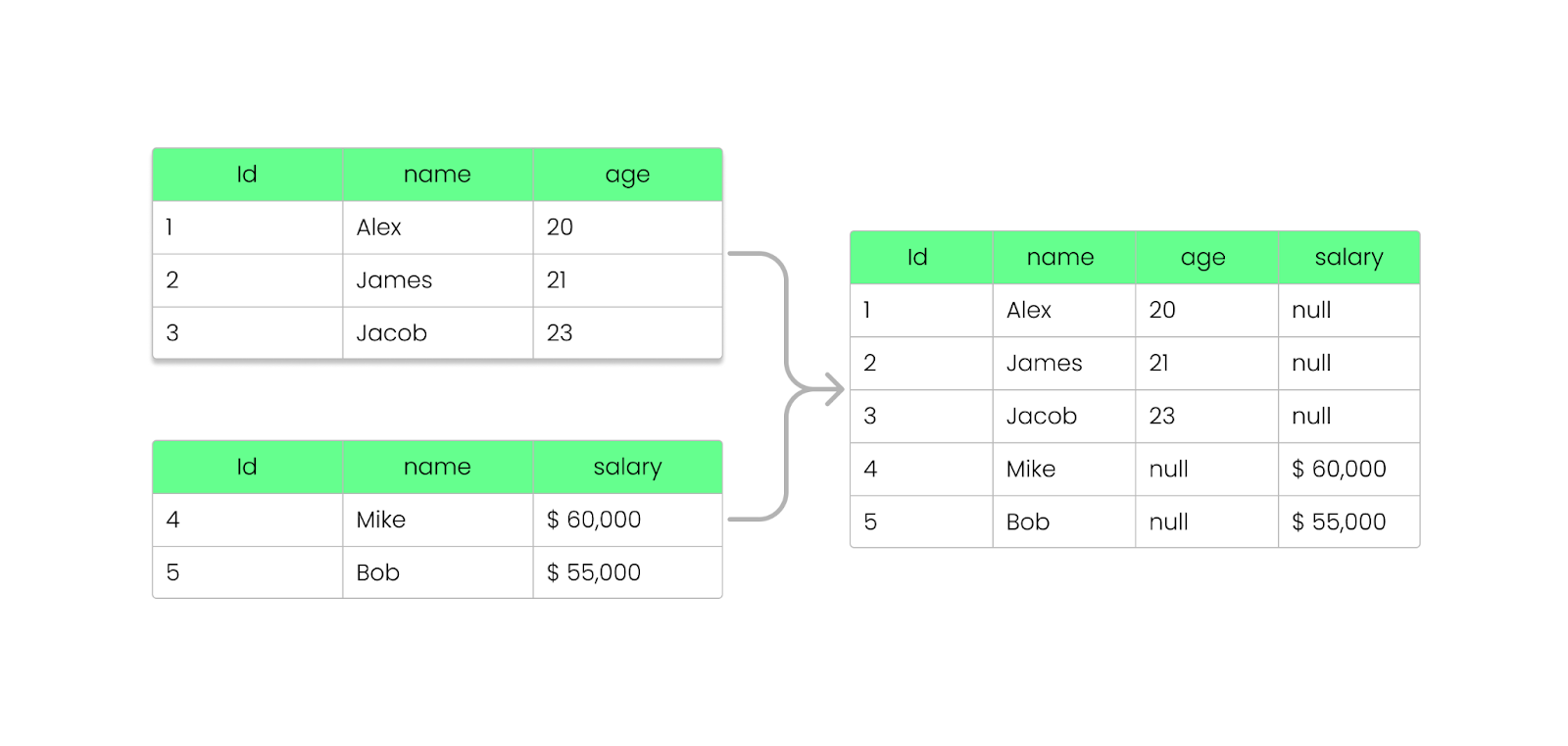
Parquet dosyasına sütun eklemek — dosyayı bozmadan. Görsel: Yazar.
Parquet; Java, Python, C++ ve Rust gibi farklı programlama dillerini destekler. Bu, geliştiricilerin platformdan bağımsız olarak kolayca kullanabileceği anlamına gelir. Ayrıca Apache Spark, Hive, Presto, Flink ve Trino gibi büyük veri çatılarıyla yerel olarak entegredir; bu da ölçekli veri işlemede verim sağlar.
Dolayısıyla Python (PySpark üzerinden) ya da başka bir dil kullanıyor olun, Parquet verileri farklı platformlarda sorgulamayı ve analiz etmeyi kolaylaştıracak şekilde yönetebilir.
Büyük veri çatılarına yeniyseniz, Introduction to PySpark kursunu öneririm. Başlamak için harika bir yoldur.
Artık Apache Parquet’in temellerini bildiğinize göre, Parquet dosyalarını yazma, okuma ve pandas, PyArrow ve Spark gibi diğer büyük veri çatılarıyla tümleştirme adımlarında size yol göstereceğim.
DataFrame’leri Parquet dosyaları olarak kaydetmek için pandas ve PyArrow gibi bir Parquet motoruna ihtiyacınız var:
pip install pandas pyarrowŞimdi aşağıdaki kodu kullanarak bir Parquet dosyası yazalım:
import pandas as pd
# Sample DataFrame
data = {
"Name": ["Alice", "Bob", "Charlie"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
}
df = pd.DataFrame(data)
# Write to Parquet file
df.to_parquet("data.parquet", engine="pyarrow", index=False)
print("Parquet file written successfully!")
pandas ile Parquet dosyası yazma. Görsel: Yazar.
Parquet dosyanızı okumak için basit bir kod:
import pandas as pd
# Read the Parquet file
df = pd.read_parquet("data.parquet", engine="pyarrow")
print("Data from Parquet file:")
print(df)
pandas ile Parquet dosyası okuma. Görsel: Yazar.
PyArrow, Apache Arrow projesinden gelen ve Parquet dosyalarıyla çalışmayı kolaylaştıran bir araçtır. PyArrow kullanarak parquet dosyası nasıl yazılır, görelim:
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# Sample data
df = pd.DataFrame({
"Name": ["Jacob", "Lauren", "Oliver"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
})
# Convert to a PyArrow table
table = pa.Table.from_pandas(df)
# Write to Parquet file
pq.write_table(table, "data.parquet")
print("Parquet file written successfully!")
PyArrow ile Parquet dosyası yazma. Görsel: Yazar.
PyArrow ile bir Parquet dosyası nasıl okunur:
import pyarrow.parquet as pq
# Read the Parquet file
table = pq.read_table("data.parquet")
# Convert to a pandas DataFrame
df = table.to_pandas()
print("Data from Parquet file:")
print(df)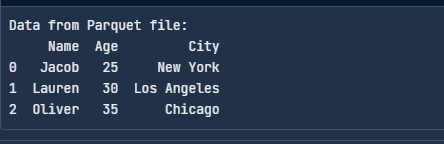
PyArrow ile Parquet dosyası okuma. Görsel: Yazar.
Spark kullanarak Parquet dosyalarını doğrudan okuyup yazabiliriz. Apache Spark’ın web sitesinden indirin veya kurulum talimatlarını izleyerek yapılandırın.
İşlem tamamlandıktan sonra kütüphaneleri içe aktarın ve bir DataFrame oluşturun:
from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName("SparkExample").getOrCreate()
# Define the schema for the dataset
schema = ["Name", "Age", "City"]
# Create a sample data
data = [
("Jacob", 30, "New York"),
("Lauren", 35, "Los Angeles"),
("Billy", 25, "Chicago")
]
# Create a DataFrame from the sample data
df = spark.createDataFrame(data, schema)
# Show the DataFrame
df.show()
Spark’ta örnek bir DataFrame oluşturun. Görsel: Yazar.
Şimdi, bu DataFrame’i bir Parquet dosyası olarak yazalım:
# Write DataFrame to Parquet
df.write.parquet("data.parquet")write.parquet(), DataFrame’i Parquet biçiminde kaydeder ve dosyanın adı employee.parquet olacaktır. Şimdi bu Parquet dosyasını okumak için aşağıdaki kodu kullanabilirsiniz:
# Read the Parquet file
parquet_df = spark.read.parquet("data.parquet")
# Show the DataFrame
parquet_df.show()
Parquet dosyasını okuyun. Görsel: Yazar.
Spark’ın yanı sıra Parquet, Hive ile de çalışabilir. Bir Hive tablosu oluştururken depolama biçimi olarak Parquet kullanmak için STORED AS PARQUET ifadesini kullanın.
Okuma ve yazmanın ötesinde, Parquet dosyalarıyla çalışırken faydalı olan ve her geliştiricinin bilmesi gereken bazı temel işlemler vardır. Bu bölümde bunları gözden geçirelim.
Kavramları örneklemek için pandas ve PyArrow kullanacağım.
Veri ekleme (append), tüm veri kümesini yeniden yazmadan yeni kayıtlar eklemek istediğinizde kullanışlıdır.
import pyarrow.parquet as pq
import pyarrow as pa
# Load existing Parquet file
existing_table = pq.read_table("data.parquet")
# New data
new_data = pd.DataFrame({
"Name": ["David", "Emma"],
"Age": [40, 28],
"City": ["San Francisco", "Seattle"]
})
# Convert new data to PyArrow table
new_table = pa.Table.from_pandas(new_data)
# Concatenate both tables
merged_table = pa.concat_tables([existing_table, new_table])
# Write back to Parquet file
pq.write_table(merged_table, "data.parquet")Tüm veri kümesini yüklemek yerine yalnızca gerekli sütunları seçebilirsiniz; bu da bellek kullanımını azaltır ve performansı artırır. Bu yaklaşım, tüm veri kümesini okumaktan belirgin derecede daha hızlıdır:
df = pd.read_parquet("data.parquet", columns=["Name", "Age"])
print(df)Parquet, depolama düzeyinde verimli filtrelemeye izin verir; predicate pushdown olarak bilinen bu yöntem, gereksiz verilerin yüklenmesini engeller. Bu sayede tüm dosyanın taranması önlenir ve sorgular çok daha hızlı çalışır:
import pyarrow.parquet as pq
# Read only rows where Age > 30
table = pq.read_table("data.parquet", filters=[("Age", ">", 30)])
df = table.to_pandas()
print(df)Çoğu zaman Parquet dosyaları ayrı bölümler (partition) halinde saklanır. Bunları tek bir Parquet dosyasında birleştirebilirsiniz. Bu, farklı kaynaklardan gelen veri kümelerini bir araya getirirken faydalıdır:
import pyarrow.parquet as pq
import pyarrow as pa
# List of Parquet files to merge
file_list = ["data_part1.parquet", "data_part2.parquet"]
# Read all files and merge
tables = [pq.read_table(f) for f in file_list]
merged_table = pa.concat_tables(tables)
# Write merged Parquet file
pq.write_table(merged_table, "merged_data.parquet")Mevcut CSV dosyalarınız varsa, bunları Parquet’e dönüştürmek alan tasarrufu sağlar ve işlemi hızlandırır; bu da dosya boyutunu ciddi ölçüde azaltır ve okuma performansını iyileştirir:
df = pd.read_csv("data.csv")
df.to_parquet("data.parquet", engine="pyarrow", index=False)Bölümlendirme (partitioning), verileri bir sütun değerine göre alt dizinlere düzenler ve sorguları belirgin biçimde hızlandırır.
Bölümlendirilmiş veriyi şöyle yazabilirsiniz:
df.to_parquet("partitioned_data/", engine="pyarrow", partition_cols=["City"])Yukarıdaki kod şu alt dizinleri oluşturur:
partitioned_data/City=New York/
partitioned_data/City=Los Angeles/
partitioned_data/City=Chicago/Ardından yalnızca belirli bir bölümü okuyabilirsiniz:
df = pd.read_parquet("partitioned_data/City=New York/")
print(df)Bu, yalnızca ilgili bölümleri tarayarak analizi hızlandırır!
Parquet, dosya boyutunu azaltmak için Snappy, Gzip ve Brotli gibi sıkıştırma algoritmalarını destekler:
df.to_parquet("compressed.parquet", engine="pyarrow", compression="snappy")Apache Parquet’i kullanmaya ilk başladığımda, küçük ayarların verimliliği büyük ölçüde artırabildiğini fark ettim. Gerçek dünyadaki senaryolarda Parquet’i optimize etmek için en iyi ipuçlarımdan bazıları şunlar.
Depolama alanı tasarrufu istiyorsanız, Snappy veya Gzip gibi codec’ler ilk tercihleriniz olabilir — Snappy, hızlı sıkıştırma ve açma sunar; hızın kritik olduğu senaryolar için idealdir.
Buna karşılık Gzip, depolama alanının kısıtlı olduğu ancak biraz daha yavaş okumaların tolere edilebildiği durumlar için uygundur. Önemli olan iş yükünüzü anlamaktır — dosyalara sık sık erişiyorsanız Snappy gibi daha hızlı bir codec genellikle daha iyi sonuç verir. Buna karşın, arşiv verileri için Gzip en uygunudur.
Veriyi tarih, bölge veya sıkça sorgulanan başka bir alana göre mantıksal alt kümelere ayırarak sorgu sırasında taranan veri miktarını azaltın. Yıllarca işlem kaydı içeren bir veri kümesiyle çalışırken yılı ve ayı temel alan bir bölümlendirme uygulamıştım; belirli dönemleri dakikalar yerine saniyeler içinde getirebildim.
Yeni sütunların mevcut süreçleri aksatmayacak şekilde eklendiğinden her zaman emin olurum. Bu genellikle mevcut sütunları değiştirmek yerine yenilerini eklemek anlamına gelir. Bunu yapmak için, daha sorunsuz geçişler adına Apache Spark’ın şema evrimi desteğinden yararlanabilirsiniz.
Parquet’i diğer veri depolama biçimleriyle karşılaştıralım.
Bunu yazı boyunca ele aldık ancak bir kez daha vurgulayayım: Parquet ve CSV, veriyi farklı şekilde ele alan iki ayrı biçimdir.
Parquet verileri sütunlarda, CSV ise satırlarda düzenler. Parquet kullandığınızda aynı sütundaki tüm veriler birlikte tutulur; böylece diğer her şeyi elemek zorunda kalmadan belirli sütunlardaki verileri kolayca çekebilirsiniz. Daha hızlıdır ve Parquet verileri sıkıştırdığı için daha az yer kaplar.
Parquet sütun bazlı biçim. Görsel: Yazar.
CSV ise verileri satır satır depolar. Basittir ve küçük veri kümeleri için iyi çalışır; ancak büyük veri kümeleri için ideal değildir. Her sorgu, yalnızca bir-iki sütuna ihtiyaç duysanız bile tüm satırı okumak zorundadır. Bu da işlemleri yavaşlatır ve daha fazla bellek gerektirir.
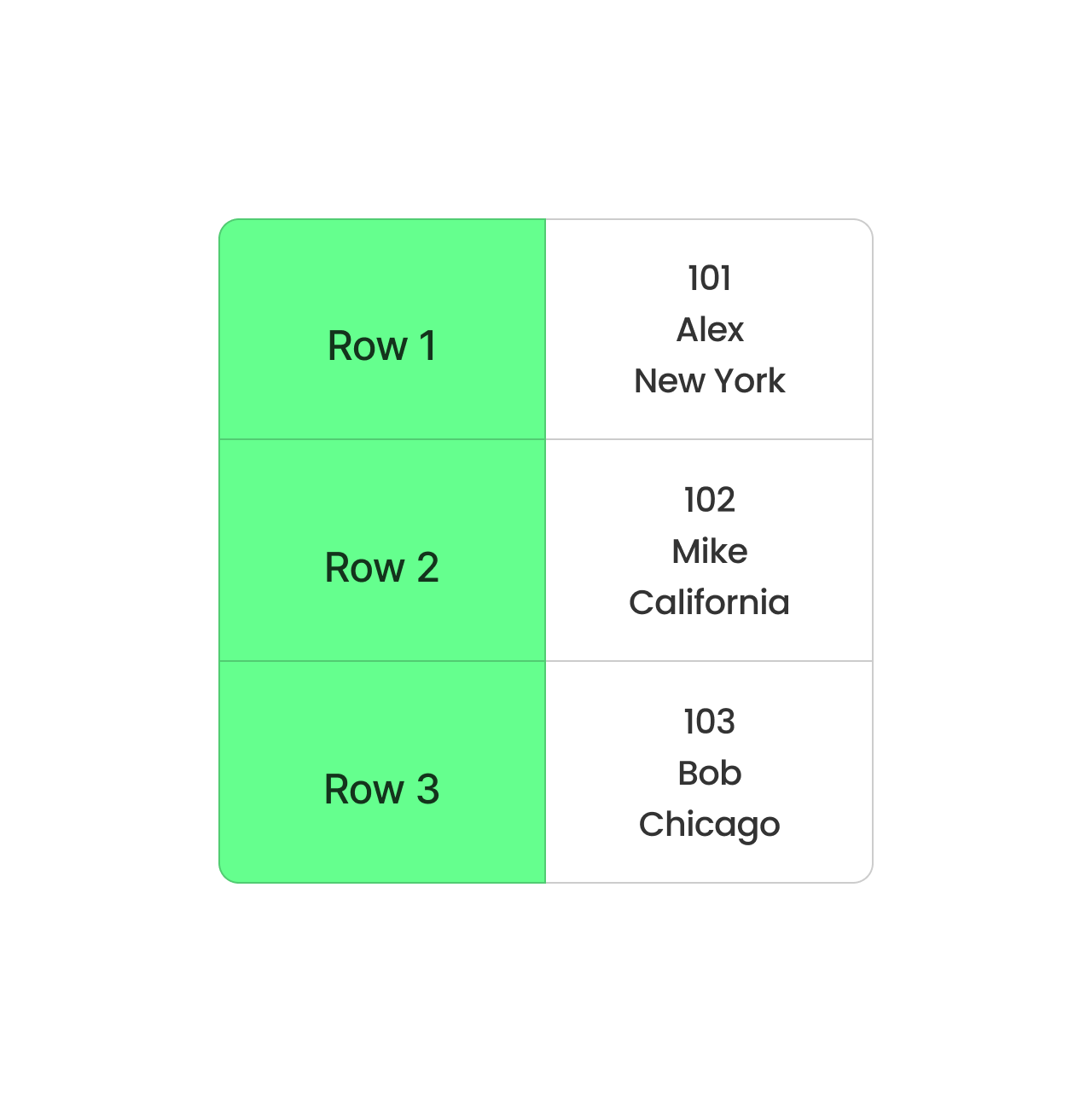
CSV satır bazlı biçim. Görsel: Yazar.
JSON, verileri anlaşılması kolay bir şekilde yapılandırmak için harikadır; ancak bir dezavantajı vardır: depolama ya da hız açısından pek verimli değildir. Parquet’in JSON’dan neden daha verimli olduğunu bir örnekle açıklayayım.
Üç sütundan oluşan bir çalışan veri tablomuz olsun: EmployeeID, Department ve Location:
|
EmployeeID |
Department |
Location |
|
1 |
HR |
New York |
|
2 |
HR |
New York |
|
3 |
HR |
New York |
|
4 |
IT |
San Francisco |
|
5 |
IT |
San Francisco |
Şimdi bu veriyi JSON olarak kaydedersek şöyle görünecektir:
[
{"EmployeeID": 1, "Department": "HR", "Location": "New York"},
{"EmployeeID": 2, "Department": "HR", "Location": "New York"},
{"EmployeeID": 3, "Department": "HR", "Location": "New York"},
{"EmployeeID": 4, "Department": "IT", "Location": "San Francisco"},
{"EmployeeID": 5, "Department": "IT", "Location": "San Francisco"}
]JSON’un her kayıt için EmployeeID, Department ve Location gibi sütun adlarını tekrarladığına dikkat edin. Ayrıca HR ve New York değerlerini de defalarca tekrarlar. Bu da dosyayı daha büyük ve daha yavaş hale getirir.
Şimdi aynı veriyi Parquet olarak kaydettiğimizi hayal edelim (Parquet insan tarafından okunabilir değildir):
Satır satır depolamak yerine Parquet, verileri sütunlara göre düzenler ve tekrar eden değerleri sıkıştırır.
Avro satır bazlı bir biçimdir. Sürekli yeni kayıtların eklendiği ya da tam satırların alındığı akış (streaming) verisi veya log işleme gibi görevler için idealdir. Parquet’in sütun bazlı biçimi ise analitik için mükemmeldir. Büyük miktarda veriyi analiz etmek için sorgular çalıştırıyorsanız Parquet en iyi sonucu verir. Gerekli sütunlardan verileri çeker, geri kalanını atlar; böylece zaman ve kaynak tasarrufu sağlar.
Kısacası, Parquet büyük veri kümelerini okuma ve analiz etmede daha iyidir; Avro ise verileri hızlı yazma ve kolay güncellenecek şekilde depolama için idealdir.
İşte Parquet, CSV, JSON ve Avro’nun artıları, eksileri ve kullanım alanlarını içeren bir karşılaştırma tablosu:
|
Format |
Artılar |
Eksiler |
Kullanım alanları |
|
Parquet |
✅ Analitik için hızlı sütun bazlı biçim ✅ Yüksek sıkıştırma verimliliği ✅ Şema evrimini destekler ✅ Büyük veri çatıları için optimize edilmiştir (Spark, Hive, Presto) ✅ Predicate pushdown (etkin filtreleme) desteği |
❌ İnsan tarafından okunabilir değil ❌ Satır bazlı işlemler için daha yavaş ❌ Yazma işlemleri daha karmaşık |
|
|
CSV |
✅ İnsan tarafından okunabilir ve basit ✅ Üretmesi ve ayrıştırması kolay ✅ Neredeyse tüm araçlarla uyumlu |
❌ Şema desteği yok ❌ Büyük veri kümelerinde yavaş ❌ Büyük dosya boyutları (sıkıştırma yok) ❌ Sorgular için tüm dosyanın taranması gerekir |
|
|
JSON |
✅ İç içe ve yarı yapılandırılmış verileri destekler ✅ İnsan tarafından okunabilir ✅ Web API’lerinde yaygın ✅ Esnek şema |
❌ Metin biçimi nedeniyle daha büyük dosyalar ❌ Büyük veri sorgularında yavaş ❌ Yerleşik indeksleme yok |
|
|
Avro |
✅ Hızlı yazmalar için satır bazlı biçim ✅ Kompakt ikili format (verimli depolama) ✅ Şema evrimini destekler ✅ Akış ve mesaj kuyrukları için uygun |
❌ İnsan tarafından okunabilir değil ❌ Analitik sorgularda Parquet kadar verimli değil ❌ İşleme için Avro kütüphaneleri gerekir |
|
Özetle, Parquet’in en iyi seçenek olduğu bazı durumlar şunlardır:
Apache Parquet, büyük veriyi yönetmek için idealdir. Hızlıdır, depolama alanından tasarruf sağlar ve Spark gibi araçlarla birlikte çalışır. Daha fazlasını öğrenmek isterseniz, şu kaynaklara göz atın:
Bu kurslarla veri mühendisliği hakkında daha fazla bilgi edinin!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
