
Courses
Nền tảng về PySpark
4 giờ
157.6K
Hãy cùng tìm hiểu kiến trúc của Apache Parquet thông qua các tính năng chính:
Không giống các định dạng theo hàng như CSV, Parquet tổ chức dữ liệu theo cột. Điều này có nghĩa khi chạy truy vấn, nó chỉ lấy các cột cụ thể bạn cần thay vì nạp mọi thứ. Cách này cải thiện hiệu năng và giảm I/O.
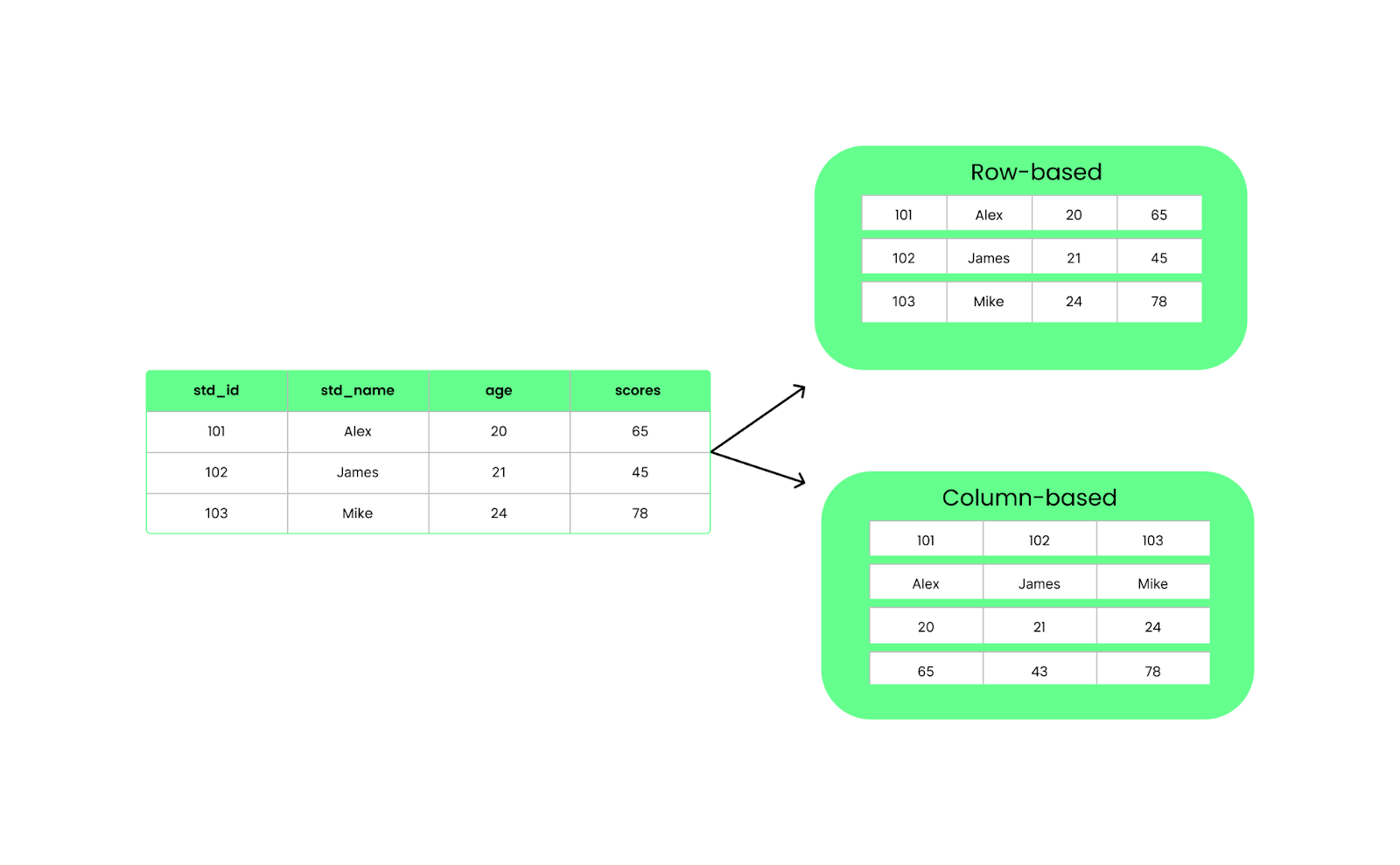
Cấu trúc dựa trên hàng so với dựa trên cột. Hình ảnh: Tác giả.
Các tệp Parquet được chia thành các row group, mỗi nhóm chứa một lô hàng. Mỗi row group được tách thành các column chunk, mỗi chunk chứa dữ liệu cho một cột. Các chunk này tiếp tục được chia nhỏ thành các page, vốn được nén để tiết kiệm dung lượng.
Ngoài ra, tệp Parquet lưu thêm thông tin ở phần footer, gọi là metadata, giúp định vị và chỉ đọc đúng phần dữ liệu cần thiết.
Cấu trúc trông như sau:
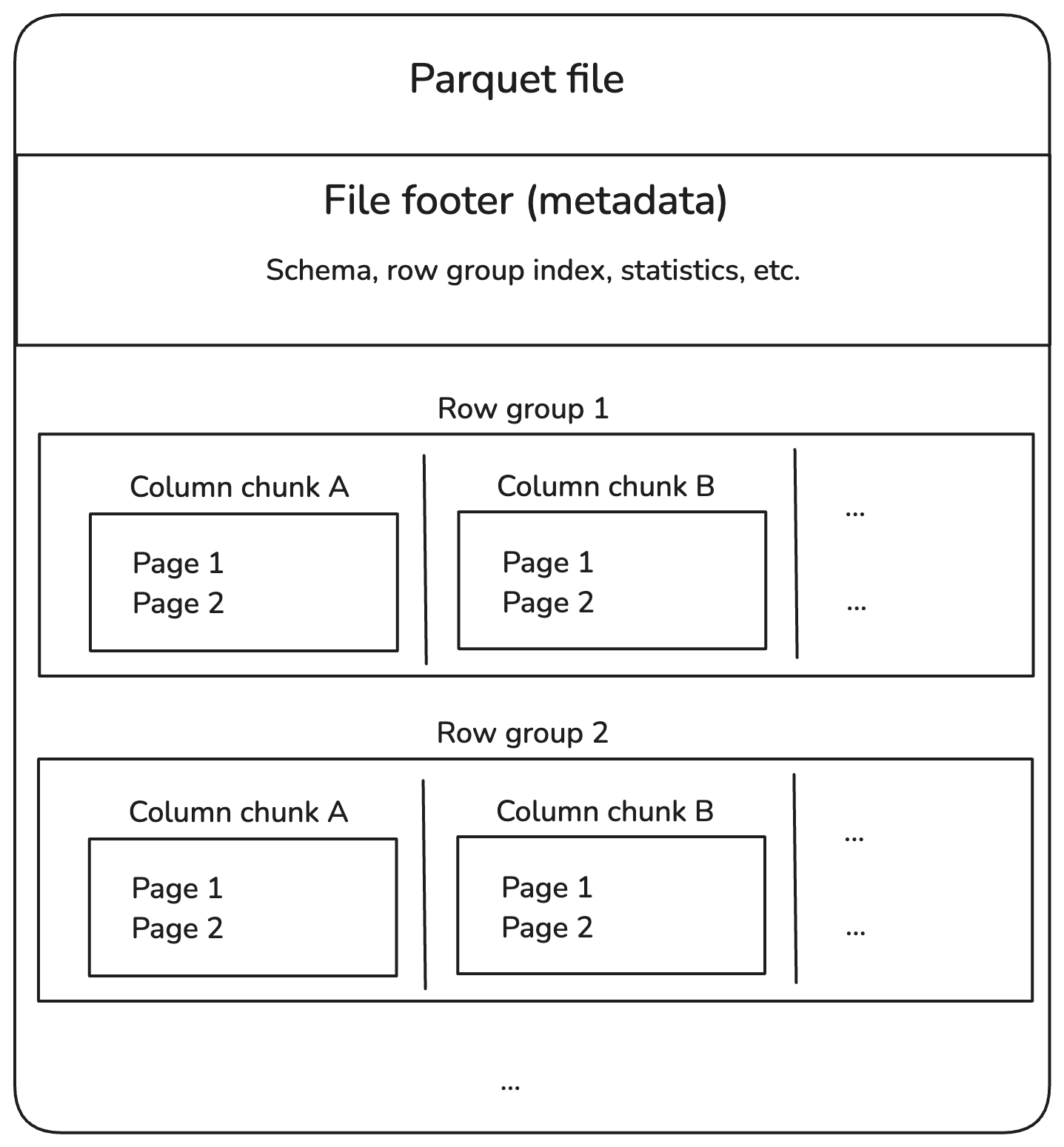
Cấu trúc nội bộ của tệp Parquet. Hình ảnh: Tác giả.
Hãy cùng phân tích từng thành phần trong sơ đồ trên.
Row group
Column chunk
Page
Footer (metadata)
Như đã đề cập, Parquet nén dữ liệu theo từng cột bằng các phương pháp nén như Snappy và Gzip. Nó cũng dùng hai kỹ thuật mã hóa:
Điều này giúp giảm kích thước tệp và tăng tốc độ đọc dữ liệu, đặc biệt hữu ích khi làm việc với big data.
Tiến hóa schema nghĩa là thay đổi cấu trúc tập dữ liệu, như thêm hoặc chỉnh sửa cột. Nghe có vẻ đơn giản, nhưng tùy cách bạn lưu trữ dữ liệu, việc chỉnh sửa schema có thể chậm và tốn tài nguyên.
Hãy hiểu rõ điều này bằng cách so sánh tiến hóa schema của CSV và Parquet.
Giả sử bạn có một tệp CSV với các cột như student_id, student_name và student_age. Nếu muốn thêm cột scores mới, bạn sẽ phải làm như sau:
scores.NULL).CSV là định dạng văn bản đơn giản, không có hỗ trợ schema tích hợp. Điều này có nghĩa mọi thay đổi cấu trúc đều cần ghi lại toàn bộ tệp, và các hệ thống cũ đọc tệp đã chỉnh sửa có thể lỗi nếu chúng kỳ vọng một cấu trúc khác!
Với Parquet, bạn có thể thêm, xóa hoặc cập nhật trường mà không làm hỏng các tệp hiện có. Như đã thấy, Parquet lưu thông tin schema trong footer (metadata) của tệp, cho phép phát triển schema mà không cần sửa các tệp cũ.
Cách hoạt động như sau:
NULL thay vì làm lỗi truy vấn.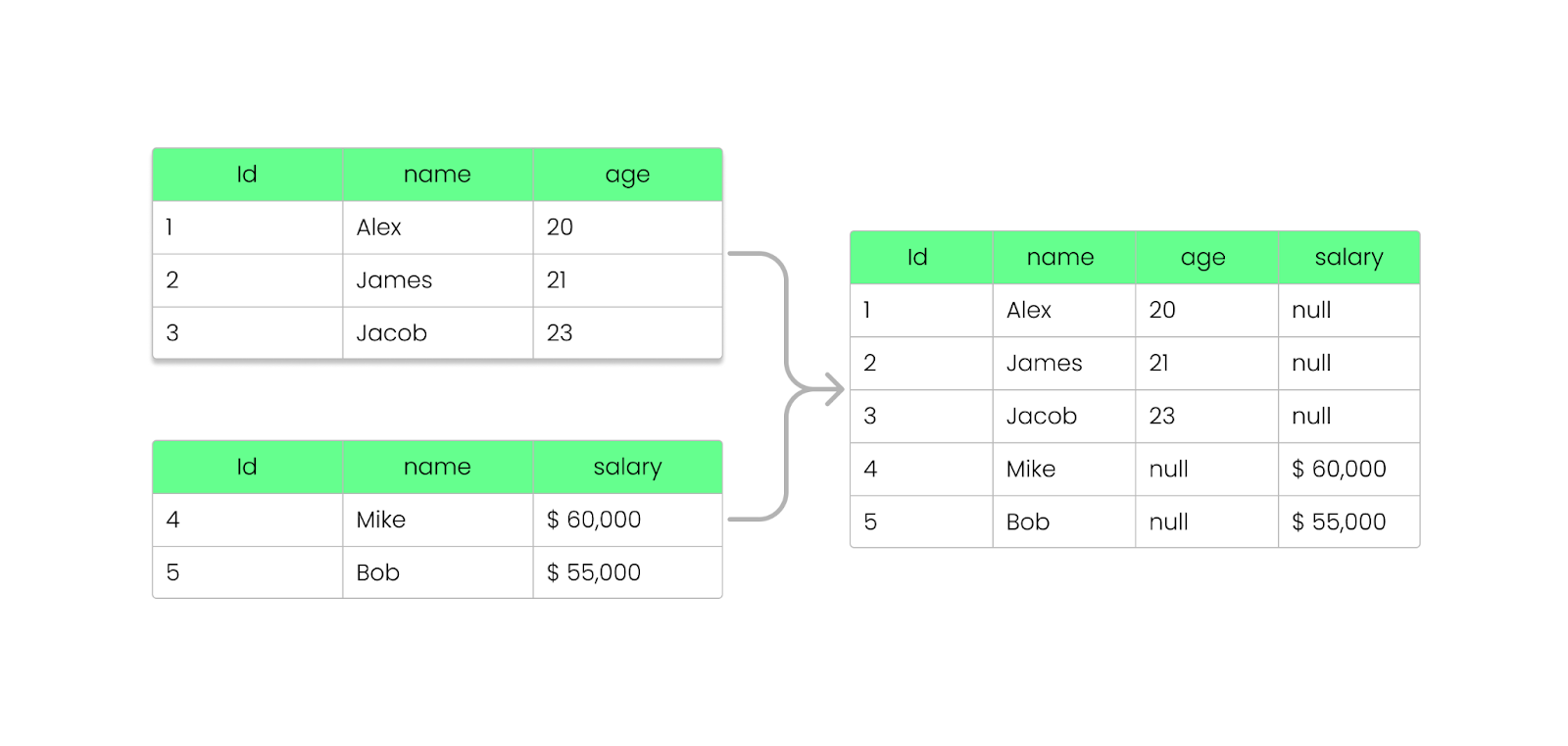
Thêm cột vào tệp Parquet mà không làm hỏng tệp. Hình ảnh: Tác giả.
Parquet hỗ trợ nhiều ngôn ngữ lập trình như Java, Python, C++ và Rust. Điều này có nghĩa các nhà phát triển có thể dễ dàng sử dụng bất kể nền tảng. Nó cũng được tích hợp nguyên bản với các framework big data như Apache Spark, Hive, Presto, Flink và Trino, đảm bảo xử lý dữ liệu hiệu quả ở quy mô lớn.
Vì vậy, dù bạn dùng Python (qua PySpark) hay ngôn ngữ khác, Parquet có thể quản lý dữ liệu theo cách giúp truy vấn và phân tích dễ dàng trên nhiều nền tảng.
Nếu bạn mới với các framework big data, tôi khuyến nghị học khóa Introduction to PySpark. Đây là cách khởi đầu tuyệt vời.
Giờ bạn đã biết những điều cơ bản về Apache Parquet, tôi sẽ hướng dẫn bạn ghi, đọc và tích hhợp tệp Parquet với pandas, PyArrow và các framework big data khác như Spark.
Để lưu DataFrame thành tệp Parquet, bạn cần pandas và một engine Parquet như PyArrow:
pip install pandas pyarrowGiờ hãy ghi một tệp Parquet bằng đoạn mã sau:
import pandas as pd
# Sample DataFrame
data = {
"Name": ["Alice", "Bob", "Charlie"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
}
df = pd.DataFrame(data)
# Write to Parquet file
df.to_parquet("data.parquet", engine="pyarrow", index=False)
print("Parquet file written successfully!")
Ghi tệp Parquet với pandas. Hình ảnh: Tác giả.
Đây là đoạn mã đơn giản để đọc tệp Parquet của bạn:
import pandas as pd
# Read the Parquet file
df = pd.read_parquet("data.parquet", engine="pyarrow")
print("Data from Parquet file:")
print(df)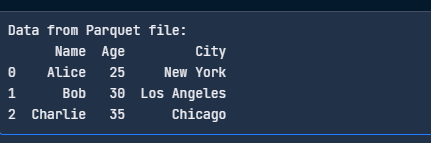
Đọc tệp Parquet với pandas. Hình ảnh: Tác giả.
PyArrow là một công cụ từ dự án Apache Arrow giúp làm việc với tệp Parquet dễ dàng. Sau đây là cách ghi một tệp Parquet bằng PyArrow:
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# Sample data
df = pd.DataFrame({
"Name": ["Jacob", "Lauren", "Oliver"],
"Age": [25, 30, 35],
"City": ["New York", "Los Angeles", "Chicago"]
})
# Convert to a PyArrow table
table = pa.Table.from_pandas(df)
# Write to Parquet file
pq.write_table(table, "data.parquet")
print("Parquet file written successfully!")
Ghi tệp Parquet với PyArrow. Hình ảnh: Tác giả.
Cách đọc tệp Parquet bằng PyArrow như sau:
import pyarrow.parquet as pq
# Read the Parquet file
table = pq.read_table("data.parquet")
# Convert to a pandas DataFrame
df = table.to_pandas()
print("Data from Parquet file:")
print(df)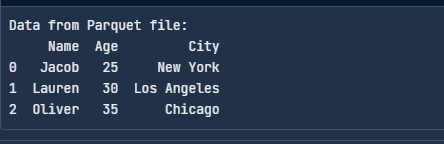
Đọc tệp Parquet với PyArrow. Hình ảnh: Tác giả.
Chúng ta có thể dùng Spark để đọc và ghi tệp Parquet trực tiếp. Tải nó từ trang web Apache Spark hoặc thiết lập theo hướng dẫn.
Sau khi xong, hãy import thư viện và tạo một DataFrame:
from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName("SparkExample").getOrCreate()
# Define the schema for the dataset
schema = ["Name", "Age", "City"]
# Create a sample data
data = [
("Jacob", 30, "New York"),
("Lauren", 35, "Los Angeles"),
("Billy", 25, "Chicago")
]
# Create a DataFrame from the sample data
df = spark.createDataFrame(data, schema)
# Show the DataFrame
df.show()
Tạo một DataFrame mẫu trong Spark. Hình ảnh: Tác giả.
Tiếp theo, ghi DataFrame này thành tệp Parquet:
# Write DataFrame to Parquet
df.write.parquet("data.parquet")Phương thức write.parquet() lưu DataFrame theo định dạng Parquet, và tệp sẽ có tên employee.parquet. Giờ để đọc tệp Parquet này, bạn có thể dùng đoạn mã sau:
# Read the Parquet file
parquet_df = spark.read.parquet("data.parquet")
# Show the DataFrame
parquet_df.show()
Đọc tệp Parquet. Hình ảnh: Tác giả.
Ngoài Spark, Parquet cũng có thể làm việc với Hive. Khi tạo bảng Hive, dùng STORED AS PARQUET để chọn Parquet làm định dạng lưu trữ.
Ngoài đọc và ghi, có một số thao tác cơ bản mọi lập trình viên nên biết vì hữu ích khi làm việc với tệp Parquet. Hãy cùng điểm qua trong phần này.
Tôi sẽ dùng pandas và PyArrow để minh họa các khái niệm.
Nối thêm dữ liệu hữu ích khi cần thêm bản ghi mới mà không phải ghi lại toàn bộ tập dữ liệu.
import pyarrow.parquet as pq
import pyarrow as pa
# Load existing Parquet file
existing_table = pq.read_table("data.parquet")
# New data
new_data = pd.DataFrame({
"Name": ["David", "Emma"],
"Age": [40, 28],
"City": ["San Francisco", "Seattle"]
})
# Convert new data to PyArrow table
new_table = pa.Table.from_pandas(new_data)
# Concatenate both tables
merged_table = pa.concat_tables([existing_table, new_table])
# Write back to Parquet file
pq.write_table(merged_table, "data.parquet")Thay vì nạp toàn bộ tập dữ liệu, bạn có thể chọn chỉ những cột cần thiết, giúp giảm bộ nhớ và cải thiện hiệu năng. Cách này nhanh hơn đáng kể so với đọc toàn bộ dữ liệu:
df = pd.read_parquet("data.parquet", columns=["Name", "Age"])
print(df)Parquet cho phép lọc hiệu quả ở tầng lưu trữ, gọi là predicate pushdown, giúp tránh nạp dữ liệu không cần thiết. Điều này tránh quét toàn bộ tệp, khiến truy vấn nhanh hơn nhiều:
import pyarrow.parquet as pq
# Read only rows where Age > 30
table = pq.read_table("data.parquet", filters=[("Age", ">", 30)])
df = table.to_pandas()
print(df)Thường thì các tệp Parquet được lưu thành các phân vùng riêng. Bạn có thể gộp chúng lại thành một tệp Parquet duy nhất. Điều này hữu ích khi kết hợp dữ liệu từ các nguồn khác nhau:
import pyarrow.parquet as pq
import pyarrow as pa
# List of Parquet files to merge
file_list = ["data_part1.parquet", "data_part2.parquet"]
# Read all files and merge
tables = [pq.read_table(f) for f in file_list]
merged_table = pa.concat_tables(tables)
# Write merged Parquet file
pq.write_table(merged_table, "merged_data.parquet")Nếu bạn có các tệp CSV hiện có, chuyển đổi sang Parquet sẽ tiết kiệm dung lượng và tăng tốc xử lý, giúp giảm mạnh kích thước tệp và cải thiện hiệu suất đọc:
df = pd.read_csv("data.csv")
df.to_parquet("data.parquet", engine="pyarrow", index=False)Phân vùng tổ chức dữ liệu vào các thư mục con dựa trên giá trị cột, giúp truy vấn nhanh hơn đáng kể.
Cách ghi dữ liệu được phân vùng như sau:
df.to_parquet("partitioned_data/", engine="pyarrow", partition_cols=["City"])Đoạn mã trên tạo các thư mục con:
partitioned_data/City=New York/
partitioned_data/City=Los Angeles/
partitioned_data/City=Chicago/Sau đó, bạn có thể chỉ đọc một phân vùng cụ thể:
df = pd.read_parquet("partitioned_data/City=New York/")
print(df)Cách này tăng tốc phân tích bằng cách chỉ quét các phân vùng liên quan!
Parquet hỗ trợ các thuật toán nén như Snappy, Gzip và Brotli để giảm kích thước tệp:
df.to_parquet("compressed.parquet", engine="pyarrow", compression="snappy")Khi mới dùng Apache Parquet, tôi nhận ra rằng những điều chỉnh nhỏ có thể cải thiện hiệu quả đáng kể. Dưới đây là một số mẹo hàng đầu của tôi để tối ưu Parquet trong các tình huống thực tế.
Nếu muốn tiết kiệm lưu trữ, các codec như Snappy hoặc Gzip là lựa chọn đáng tin cậy — Snappy cung cấp tốc độ nén/giải nén nhanh, hoàn hảo cho các tình huống ưu tiên tốc độ.
Ngược lại, Gzip phù hợp nếu bạn hạn chế dung lượng lưu trữ nhưng chấp nhận đọc chậm hơn một chút. Mấu chốt là hiểu khối lượng công việc — codec nhanh như Snappy thường thắng nếu bạn truy cập tệp thường xuyên. Tuy nhiên, Gzip tốt cho dữ liệu lưu trữ dài hạn.
Chia dữ liệu thành các tập con hợp lý, như theo ngày, khu vực, hoặc trường hay được truy vấn, để giảm lượng dữ liệu phải quét khi truy vấn. Tôi từng làm việc với tập dữ liệu nhật ký giao dịch nhiều năm và phân vùng theo năm và tháng để truy xuất các giai đoạn cụ thể trong vài giây thay vì vài phút.
Tôi luôn đảm bảo rằng các cột mới được thêm theo cách không làm gián đoạn quy trình hiện có. Thông thường nghĩa là thêm cột mới thay vì chỉnh sửa cột cũ. Bạn có thể dùng hỗ trợ tiến hóa schema của Apache Spark để chuyển đổi mượt mà.
Hãy so sánh Parquet với các định dạng lưu trữ dữ liệu khác.
Chúng ta đã đề cập trong suốt bài viết, nhưng tôi muốn nhấn mạnh: Parquet và CSV là hai định dạng xử lý dữ liệu theo cách khác nhau.
Parquet tổ chức dữ liệu theo cột, trong khi CSV sắp xếp theo hàng. Khi dùng Parquet, tất cả dữ liệu của cùng một cột được nhóm lại, nên bạn có thể dễ dàng lấy dữ liệu từ các cột cụ thể mà không phải lọc qua những phần còn lại. Nó nhanh hơn và chiếm ít dung lượng hơn vì Parquet nén dữ liệu.
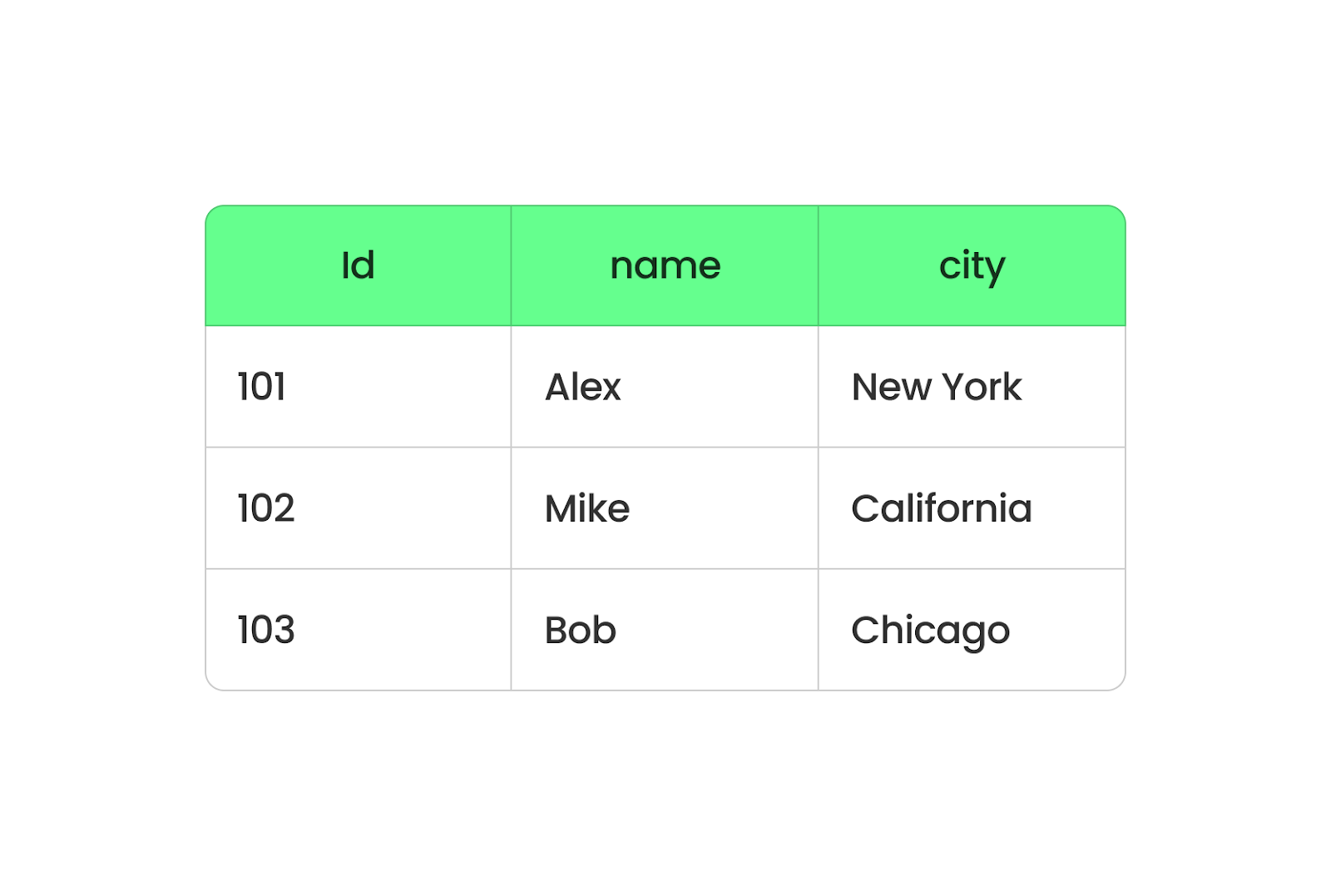
Định dạng Parquet dựa trên cột. Hình ảnh: Tác giả.
Ngược lại, CSV lưu dữ liệu theo từng hàng. Nó đơn giản và hoạt động tốt với tập dữ liệu nhỏ, nhưng không lý tưởng cho dữ liệu lớn. Mỗi truy vấn phải đọc toàn bộ hàng, ngay cả khi bạn chỉ cần vài cột. Điều này làm chậm và tốn nhiều bộ nhớ xử lý.
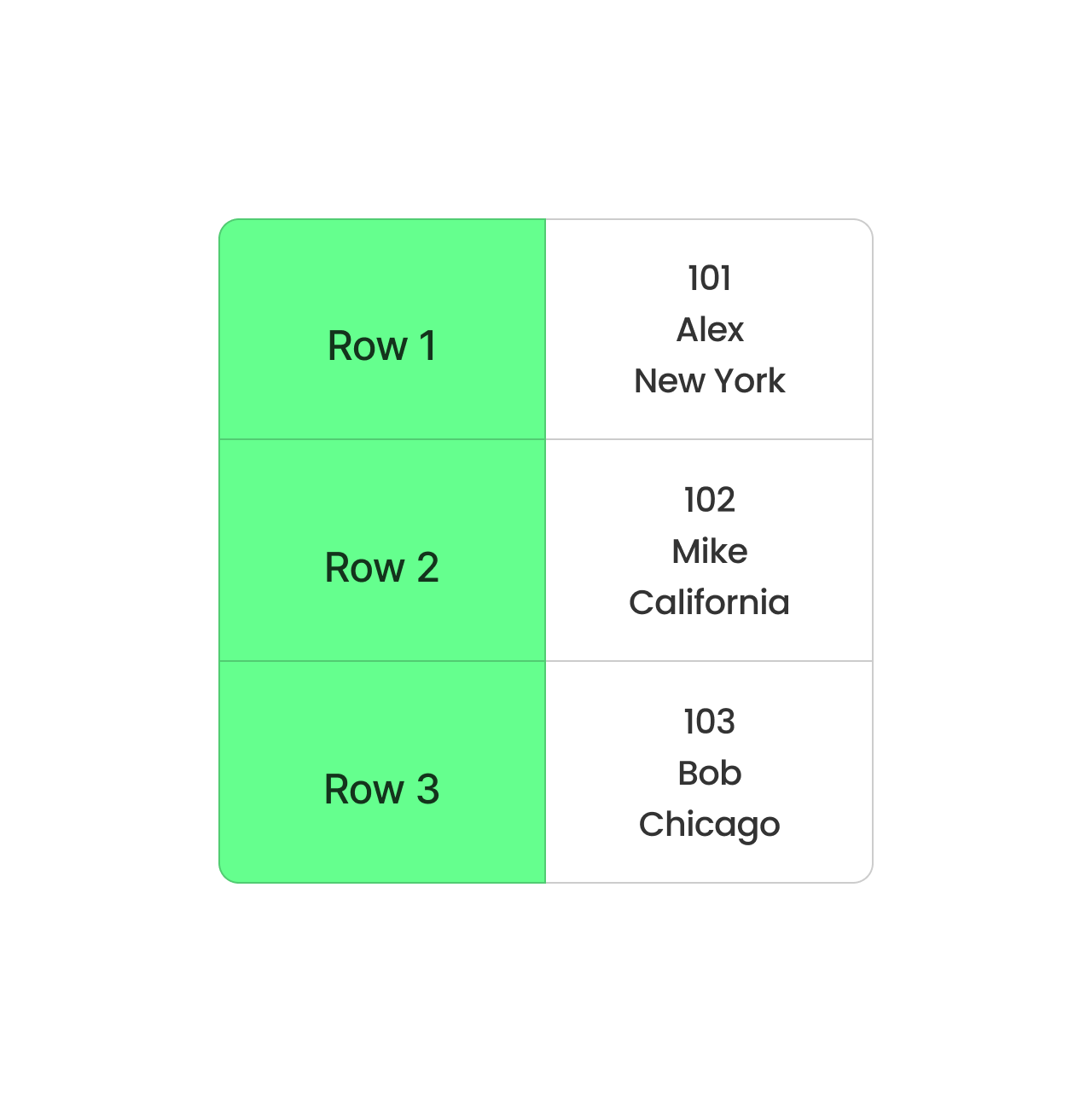
Định dạng CSV dựa trên hàng. Hình ảnh: Tác giả.
JSON rất tốt để cấu trúc dữ liệu một cách dễ hiểu, nhưng có nhược điểm: không hiệu quả về lưu trữ hoặc tốc độ. Sau đây là lý do Parquet hiệu quả hơn JSON qua một ví dụ.
Giả sử chúng ta có một bảng dữ liệu nhân viên với ba cột: EmployeeID, Department và Location:
|
EmployeeID |
Department |
Location |
|
1 |
HR |
New York |
|
2 |
HR |
New York |
|
3 |
HR |
New York |
|
4 |
IT |
San Francisco |
|
5 |
IT |
San Francisco |
Giờ nếu lưu dữ liệu này dưới dạng JSON, nó sẽ trông như sau:
[
{"EmployeeID": 1, "Department": "HR", "Location": "New York"},
{"EmployeeID": 2, "Department": "HR", "Location": "New York"},
{"EmployeeID": 3, "Department": "HR", "Location": "New York"},
{"EmployeeID": 4, "Department": "IT", "Location": "San Francisco"},
{"EmployeeID": 5, "Department": "IT", "Location": "San Francisco"}
]Hãy chú ý JSON lặp lại tên cột như EmployeeID, Department và Location cho từng bản ghi. Nó cũng lặp các giá trị HR và New York nhiều lần. Điều này khiến tệp lớn hơn và chậm hơn.
Giờ hãy hình dung (vì Parquet không đọc được bằng mắt) chúng ta lưu cùng dữ liệu đó dưới dạng Parquet:
Thay vì lưu theo từng hàng, Parquet tổ chức dữ liệu theo cột và nén các giá trị lặp lại.
Avro là định dạng theo hàng. Nó rất phù hợp cho các tác vụ như streaming dữ liệu hoặc xử lý log, nơi bạn liên tục thêm bản ghi mới hoặc truy xuất toàn bộ hàng. Nhưng định dạng theo cột của Parquet lại hoàn hảo cho phân tích. Nếu bạn chạy truy vấn để phân tích lượng dữ liệu lớn, Parquet sẽ hoạt động tốt nhất. Nó chỉ lấy dữ liệu từ các cột cần thiết và bỏ qua phần còn lại để tiết kiệm thời gian và tài nguyên.
Tóm lại, Parquet tốt hơn cho đọc và phân tích các tập dữ liệu lớn, trong khi Avro lý tưởng cho việc ghi và lưu trữ dữ liệu theo cách dễ cập nhật.
Dưới đây là bảng so sánh Parquet so với CSV, JSON và Avro, bao gồm ưu, nhược điểm và trường hợp sử dụng:
|
Định dạng |
Ưu điểm |
Nhược điểm |
Trường hợp sử dụng |
|
Parquet |
✅ Định dạng dạng cột cho phân tích nhanh ✅ Hiệu quả nén cao ✅ Hỗ trợ tiến hóa schema ✅ Tối ưu cho các framework big data (Spark, Hive, Presto) ✅ Hỗ trợ predicate pushdown (lọc hiệu quả) |
❌ Không đọc được bằng mắt ❌ Chậm hơn cho thao tác theo hàng ❌ Ghi phức tạp hơn |
|
|
CSV |
✅ Dễ đọc và đơn giản ✅ Dễ tạo và phân tích cú pháp ✅ Tương thích với hầu hết công cụ |
❌ Không hỗ trợ schema ❌ Chậm với tập dữ liệu lớn ❌ Kích thước tệp lớn (không nén) ❌ Phải quét toàn bộ tệp khi truy vấn |
|
|
JSON |
✅ Hỗ trợ dữ liệu lồng nhau và bán cấu trúc ✅ Dễ đọc ✅ Dùng rộng rãi trong web API ✅ Schema linh hoạt |
❌ Kích thước tệp lớn (do dạng văn bản) ❌ Chậm cho truy vấn big data ❌ Không có indexing gốc |
|
|
Avro |
✅ Định dạng theo hàng cho tốc độ ghi nhanh ✅ Định dạng nhị phân gọn (lưu trữ hiệu quả) ✅ Hỗ trợ tiến hóa schema ✅ Tốt cho streaming và hàng đợi thông điệp |
❌ Không đọc được bằng mắt ❌ Kém hiệu quả cho truy vấn phân tích so với Parquet ❌ Cần thư viện Avro để xử lý |
|
Tóm lại, đây là một vài tình huống Parquet là lựa chọn tốt nhất:
Apache Parquet rất phù hợp để xử lý big data. Nó nhanh, tiết kiệm dung lượng lưu trữ và hoạt động tốt với các công cụ như Spark. Nếu bạn muốn tìm hiểu thêm, hãy xem các tài nguyên sau:
Tìm hiểu thêm về data engineering với các khóa học này!
Courses
Courses
Courses