
Kursus
Peramalan Keuangan dengan Python
4 Hr
13.2K
Mari kita melihat ARIMA, salah satu teknik peramalan deret waktu yang paling populer (jika bukan yang paling populer). ARIMA populer karena secara efektif memodelkan data deret waktu dengan menangkap komponen autoregressive (AR) dan moving average (MA), sekaligus mengatasi non-stasioneritas melalui pembedaan (I). Kombinasi ini membuat model ARIMA sangat fleksibel, itulah sebabnya model ini digunakan di berbagai industri yang sangat berbeda, seperti keuangan dan prediksi cuaca.
Model ARIMA bersifat sangat teknis, tetapi saya akan menguraikan bagiannya agar Anda dapat memahaminya dengan baik. Sebelum mulai, ada baiknya membiasakan diri dengan beberapa alat dasar. DataCamp menawarkan banyak sumber daya yang baik, seperti kursus ARIMA Models in Python atau ARIMA Models in R. Anda dapat memilih salah satunya sesuai bahasa yang Anda sukai.
Di bidang keuangan, ekonomi, ilmu lingkungan, dan lain-lain, ARIMA sangat diminati karena mampu mengidentifikasi banyak pola kompleks dari pengamatan masa lalu untuk kebutuhan masa depan, menjadikannya teknik mutakhir. Dari memprediksi harga saham, meramalkan pola cuaca hingga memperkirakan permintaan konsumen, ARIMA adalah cara yang hebat untuk menghasilkan analisis prediktif yang akurat dan dapat ditindaklanjuti.
Dengan menggunakan ARIMA, kita dapat menganalisis dan meramalkan data deret waktu secara canggih dengan mempertimbangkan pola, tren, dan musiman. Ini memfasilitasi pandangan 360 derajat atas dinamika yang mendasarinya untuk pengambilan keputusan yang lebih tepat.
Untuk benar-benar memahami ARIMA, kita perlu membongkar blok penyusunnya. Setelah kita memahami komponennya, akan lebih mudah untuk mengerti bagaimana metode peramalan deret waktu ini bekerja secara keseluruhan. Di sini, saya akan memberikan penjelasan rinci untuk setiap komponen.
Komponen Autoregressive (AR) membangun tren dari nilai-nilai masa lalu dalam kerangka AR untuk model prediktif. Untuk memperjelas, 'kerangka autoregression' bekerja seperti model regresi di mana Anda menggunakan lag dari nilai masa lalu deret waktu itu sendiri sebagai peubah penjelas.
Bagian Integrated (I) melibatkan pembedaan komponen deret waktu dengan mempertimbangkan bahwa deret waktu kita harus stasioner, yang pada dasarnya berarti mean dan varians tetap konstan sepanjang waktu. Intinya, kita mengurangkan satu pengamatan dari pengamatan lainnya agar tren dan musiman dieliminasi. Dengan melakukan pembedaan, kita memperoleh kestasioneran. Langkah ini diperlukan karena membantu model menyesuaikan dengan data, bukan kebisingan.
Komponen moving average (MA) berfokus pada hubungan antara sebuah pengamatan dan galat residual. Dengan melihat bagaimana pengamatan saat ini terkait dengan galat masa lalu, kita dapat menyimpulkan informasi berguna tentang kemungkinan tren dalam data.
Kita dapat mempertimbangkan residual sebagai salah satu galat ini, dan konsep model moving average mengestimasi atau mempertimbangkan dampaknya pada pengamatan terbaru kita. Ini sangat berguna untuk melacak dan menangkap perubahan jangka pendek dalam data atau guncangan acak. Pada bagian (MA) deret waktu, kita dapat memperoleh informasi berharga tentang perilakunya yang pada gilirannya memungkinkan kita meramal dengan ketepatan yang lebih tinggi.
Untuk membangun model ARIMA guna peramalan, misalnya harga emas, Anda dapat mengikuti langkah-langkah ini. Mari kita uraikan bersama.
Langkah pertama adalah menyiapkan dataset yang sesuai dan menyiapkan lingkungan kerja.
Kumpulkan atau cari dataset dari platform sumber data. Anda memerlukan dataset yang memiliki data historis sepanjang waktu. Berikut tautan ke dataset Kaggle terkait harga emas berjangka.
Kita menginstal paket yang dibutuhkan, termasuk statsmodels dan sklearn.
import pandas as pdimport matplotlib.pyplot as pltfrom statsmodels.tsa.stattools import adfullerfrom statsmodels.graphics.tsaplots import plot_acf, plot_pacffrom statsmodels.tsa.arima.model import ARIMAfrom sklearn.metrics import mean_squared_errorKemudian kita membaca data ke lingkungan lokal. Saya mengambil langkah ekstra untuk memastikan tanggal dikenali secara berurutan.
# Define the path to your CSV file# You may have to make this path more specific to the location of your file.csv_path = "future-gc00-daily-prices.csv"# Read the CSV, parse 'Date' column as datetime, and set it as the indexdata = pd.read_csv( csv_path, parse_dates=["Date"], dayfirst=False, index_col="Date")# Sort the DataFrame by the Date index in ascending orderdata.sort_index(inplace=True)Dataset kita cukup bersih, namun dalam konteks lain, kita harus menangani masalah pengindeksan, yang penting dalam peramalan deret waktu. Misalnya, karena kita meramalkan nilai penutupan saham pada bursa tertentu, kita harus mempertimbangkan bahwa pasar saham tidak buka pada akhir pekan.
Sebelum melanjutkan, saya juga mengambil langkah cepat untuk menghapus koma dari variabel Close, yang akan saya gunakan.
# Clean the "Close" columndata["Close"] = data["Close"].replace(',', '', regex=True)data["Close"] = pd.to_numeric(data["Close"], errors='coerce')data["Close"].replace([np.inf, -np.inf], np.nan, inplace=True)data.dropna(subset=["Close"], inplace=True)Sebagai bagian dari prapemrosesan data, kita juga sering harus mempertimbangkan cara menangani nilai hilang menggunakan metode imputasi seperti forward filling atau penggantian rata-rata. Perlu diketahui bahwa bahkan satu nilai NA, tergantung pada bahasa pemrograman dan pustaka yang Anda gunakan, dapat mencegah ARIMA berjalan.
Saya telah menyebutkan bahwa hari akhir pekan mungkin dikenali sebagai NA. Itu bisa saja terjadi, dan akan memerlukan langkah tambahan. Untungnya, statsmodels memperlakukan data sebagai indeks berurutan tanpa secara ketat memberlakukan interval waktu reguler, sehingga model kita tetap dapat dikompilasi meskipun ada celah akhir pekan.
Sekarang saat yang tepat untuk membuat plot waktu agar kita dapat melihat deret yang sedang kita kerjakan:
# Plotting the original Close priceplt.figure(figsize=(14, 7))plt.plot(data.index, data["Close"], label='Close Price')plt.title('Close Price Over Time')plt.xlabel('Date')plt.ylabel('Close Price')plt.legend()plt.show()
Meskipun model ARIMA dapat menangani non-stasioneritas sampai batas tertentu, model ini tidak dapat secara efektif memperhitungkan varians yang berubah seiring waktu. Dengan kata lain, agar model ARIMA benar-benar bekerja, datanya harus stasioner.
Melihat plot di atas, kita dapat melihat bahwa data sebenarnya tidak stasioner karena ada tren yang jelas. Selain itu, tampaknya ada varians yang tidak konstan pada titik waktu yang berbeda. Kita dapat menggunakan uji Augmented Dickey-Fuller untuk menguji intuisi kita dan melihat apakah data kita memiliki mean dan varians yang konstan, serta memberi angka padanya.
# Perform the Augmented Dickey-Fuller test on the original seriesresult_original = adfuller(data["Close"])print(f"ADF Statistic (Original): {result_original[0]:.4f}")print(f"p-value (Original): {result_original[1]:.4f}")if result_original[1] < 0.05: print("Interpretation: The original series is Stationary.\n")else: print("Interpretation: The original series is Non-Stationary.\n")# Apply first-order differencingdata['Close_Diff'] = data['Close'].diff()# Perform the Augmented Dickey-Fuller test on the differenced seriesresult_diff = adfuller(data["Close_Diff"].dropna())print(f"ADF Statistic (Differenced): {result_diff[0]:.4f}")print(f"p-value (Differenced): {result_diff[1]:.4f}")if result_diff[1] < 0.05: print("Interpretation: The differenced series is Stationary.")else: print("Interpretation: The differenced series is Non-Stationary.")ADF Statistic (Original): -1.4367p-value (Original): 0.5646Interpretation: The original series is Non-Stationary.ADF Statistic (Differenced): -19.1308p-value (Differenced): 0.0000Interpretation: The differenced series is Stationary.Hasil uji Augmented Dickey-Fuller menunjukkan bahwa deret asli kita memang tidak stasioner, sehingga menggunakan ARIMA secara langsung pada data asli akan menjadi kesalahan.
Namun, uji ADF pada versi data yang dibedakan menunjukkan bahwa versi yang dibedakan adalah stasioner.
Catatan singkat tentang pembedaan. Saya ingin meluangkan waktu untuk menjelaskan ini, karena banyak hal terjadi di balik layar. Untuk melakukan pembedaan, kita mengurangkan setiap pengamatan dari pengamatan sebelumnya untuk memberi kita deret waktu baru berupa beda pertama. (Deret waktu baru sekarang satu elemen lebih pendek daripada yang asli.) Jika deret yang dibedakan masih belum stasioner, kita dapat mengambil beda kedua dengan membedakan deret asli lagi, dan kita dapat terus membedakan deret hingga akhirnya menjadi stasioner. Orde pembedaan yang diperlukan adalah jumlah pembedaan minimum yang dibutuhkan untuk mendapatkan deret tanpa autokorelasi.
Terakhir, jangan melakukan pembedaan lebih dari yang diperlukan, karena Anda dapat menciptakan dinamika semu dalam data. Juga, jika Anda akan membuat model ARIMA musiman, yang tidak kita lakukan dalam tutorial ini, Anda selalu mempertimbangkan pembedaan musiman sebelum beda pertama.
# Plotting the differenced Close priceplt.figure(figsize=(14, 7))plt.plot(data.index, data['Close_Diff'], label='Differenced Close Price', color='orange')plt.title('Differenced Close Price Over Time')plt.xlabel('Date')plt.ylabel('Differenced Close Price')plt.legend()plt.show()
Saat membangun model ARIMA, kita harus mempertimbangkan istilah p, d, dan q yang masuk ke dalam model ARIMA kita.
Kita menggunakan alat seperti ACF (Autocorrelation Function) dan PACF (Partial Autocorrelation Function) untuk menentukan nilai p, d, dan q. Jumlah lag saat ACF terputus adalah q, dan saat PACF terputus adalah p. Kita juga harus memilih nilai yang sesuai untuk d dengan menciptakan kondisi di mana, setelah pembedaan, data menyerupai white noise. Untuk data kita, kita memilih 1 untuk p dan q karena kita melihat lonjakan signifikan pada lag pertama untuk masing-masing.
from statsmodels.graphics.tsaplots import plot_acf, plot_pacfimport matplotlib.pyplot as plt# Plot ACF and PACF for the differenced seriesfig, axes = plt.subplots(1, 2, figsize=(16, 4))# ACF plotplot_acf(data['Close_Diff'].dropna(), lags=40, ax=axes[0])axes[0].set_title('Autocorrelation Function (ACF)')# PACF plotplot_pacf(data['Close_Diff'].dropna(), lags=40, ax=axes[1])axes[1].set_title('Partial Autocorrelation Function (PACF)')plt.tight_layout()plt.show()
Untuk memperjelas, nilai p, d, dan q dalam ARIMA merepresentasikan orde model (lag untuk autoregresi, pembedaan, dan istilah moving average), tetapi bukan parameter sebenarnya yang diestimasi. Setelah nilai p, d, dan q dipilih, model mengestimasi parameter tambahan, seperti koefisien untuk istilah autoregressive dan moving average, melalui maximum likelihood estimation (MLE).
Untuk meramal menggunakan model ARIMA, mulailah dengan menggunakan model yang telah dipasang untuk memprediksi nilai masa depan berdasarkan data. Setelah prediksi dibuat, akan bermanfaat untuk memvisualisasikannya dengan memplot nilai prediksi berdampingan dengan nilai aktual. Ini dilakukan karena kita menggunakan alur kerja train/test, di mana data dibagi menjadi set pelatihan dan pengujian. Dengan melakukan ini, kita dapat melihat seberapa baik performa model pada data yang belum pernah dilihat. Jika Anda belum jelas tentang ini, ikuti kursus Model Validation in Python kami, yang merupakan sumber daya hebat untuk mempelajari seluk-beluk pelatihan dan pengujian.
Langkah pertama kita adalah membagi data menjadi versi pelatihan dan pengujian.
# Split data into train and testtrain_size = int(len(data) * 0.8)train, test = data.iloc[:train_size], data.iloc[train_size:]# Fit ARIMA modemodel = ARIMA(train["Close"], order=(1,1,1))model_fit = model.fit()Langkah berikutnya adalah membuat ramalan dan juga memeriksanya secara visual. Kita dapat melihat bagaimana ramalan kita tampil terhadap versi pengujian dari data kita.
# Forecastforecast = model_fit.forecast(steps=len(test))# Plot the results with specified colorsplt.figure(figsize=(14,7))plt.plot(train.index, train["Close"], label='Train', color='#203147')plt.plot(test.index, test["Close"], label='Test', color='#01ef63')plt.plot(test.index, forecast, label='Forecast', color='orange')plt.title('Close Price Forecast')plt.xlabel('Date')plt.ylabel('Close Price')plt.legend()plt.show()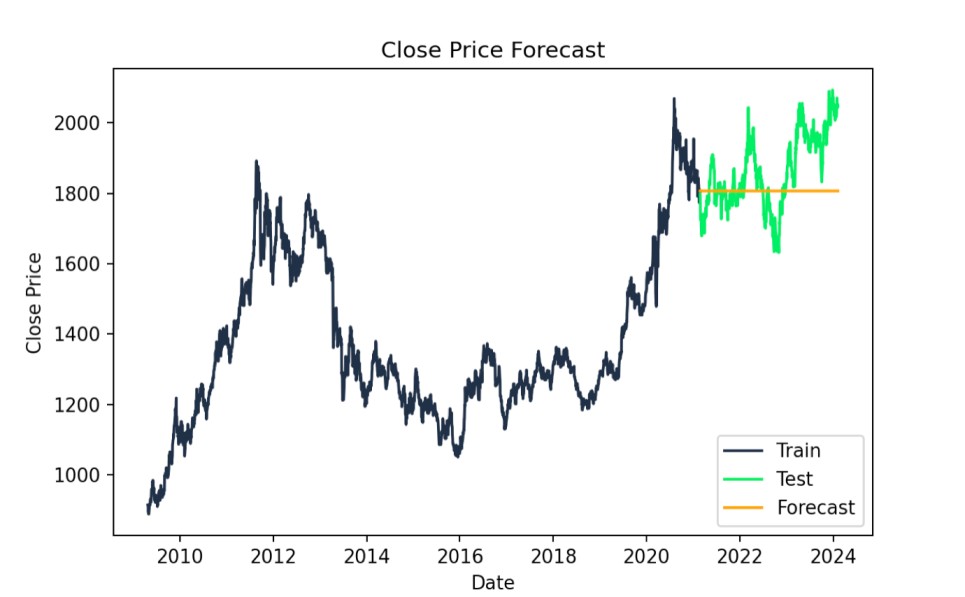
Perbandingan ramalan ARIMA: nilai aktual vs. prediksi. Gambar oleh Penulis
Kita melihat statistik model AIC dan BIC. Nilai yang lebih rendah berarti model lebih sesuai, tetapi kita juga dapat membandingkan hasilnya dengan model yang lebih sederhana untuk menghindari overfitting. Saya mencetak angkanya di sini, tetapi angka tersebut paling masuk akal dalam konteks membandingkan dengan model ARIMA lain pada data yang sama, untuk menemukan model ARIMA yang paling baik.
print(f"AIC: {model_fit.aic}")print(f"BIC: {model_fit.bic}")AIC: 24602.97426066606BIC: 24620.97128230579Kita juga dapat mengevaluasi mean squared error, untuk menilai kesesuaian model. Ini adalah metrik yang praktis. RMSE yang lebih rendah menunjukkan model ARIMA yang lebih baik, mencerminkan perbedaan yang lebih kecil antara nilai aktual dan prediksi, dan berada pada skala data. Artinya, RMSE sebesar 118,5339 menunjukkan bahwa, rata-rata, prediksi model kita menyimpang dari harga Close aktual sekitar $118,53.
forecast = forecast[:len(test)]test_close = test["Close"][:len(forecast)]# Calculate RMSErmse = np.sqrt(mean_squared_error(test_close, forecast))print(f"RMSE: {rmse:.4f}")RMSE: 118.5339Belajar bersama DataCamp
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
