
Courses
Dự báo tài chính với Python
4 giờ
13.2K
Hãy cùng tìm hiểu ARIMA, một trong những kỹ thuật dự báo chuỗi thời gian phổ biến nhất (nếu không muốn nói là phổ biến nhất). ARIMA được ưa chuộng vì nó mô hình hóa dữ liệu chuỗi thời gian hiệu quả bằng cách nắm bắt cả thành phần tự hồi quy (AR) và trung bình trượt (MA), đồng thời xử lý tính không dừng thông qua phép sai phân (I). Sự kết hợp này giúp mô hình ARIMA đặc biệt linh hoạt, vì vậy chúng được dùng trong nhiều ngành rất khác nhau, như tài chính và dự báo thời tiết.
Mô hình ARIMA có tính kỹ thuật cao, nhưng tôi sẽ phân tách các phần để bạn có thể hiểu vững. Trước khi bắt đầu, bạn nên làm quen với một số công cụ nền tảng. DataCamp có nhiều tài nguyên tốt, như các khóa học ARIMA Models in Python hoặc ARIMA Models in R. Bạn có thể chọn tùy theo ngôn ngữ mình thích.
Trong tài chính, kinh tế học, khoa học môi trường, v.v., ARIMA được quan tâm vì có thể nhận diện nhiều mẫu hình phức tạp từ các quan sát quá khứ phục vụ nhu cầu tương lai, khiến nó trở thành một kỹ thuật hiện đại. Từ dự đoán giá cổ phiếu, dự báo thời tiết đến ước lượng nhu cầu tiêu dùng, ARIMA là cách tuyệt vời để tạo ra các phân tích dự đoán chính xác và hữu ích.
Bằng cách sử dụng ARIMA, chúng ta có thể phân tích và dự báo dữ liệu chuỗi thời gian một cách tinh vi, xét đến các mẫu hình, xu hướng và tính mùa vụ. Điều này giúp có cái nhìn toàn diện về động lực nền tảng để ra quyết định sáng suốt.
Để thật sự hiểu ARIMA, chúng ta cần tách rời các khối cấu thành của nó. Khi nắm được các thành phần, sẽ dễ hiểu hơn cách phương pháp dự báo chuỗi thời gian này vận hành như một tổng thể. Ở đây, tôi sẽ giải thích chi tiết từng thành phần.
Thành phần tự hồi quy (AR) xây dựng xu thế từ các giá trị quá khứ trong khung AR cho các mô hình dự đoán. Để làm rõ, "khung tự hồi quy" vận hành giống mô hình hồi quy, nơi bạn dùng các độ trễ của chính chuỗi thời gian làm biến hồi quy.
Phần tích hợp (I) liên quan đến việc sai phân chuỗi thời gian nhằm đảm bảo chuỗi dừng, tức là trung bình và phương sai không đổi theo thời gian. Về cơ bản, ta trừ một quan sát cho quan sát liền trước để loại bỏ xu hướng và tính mùa vụ. Thực hiện sai phân giúp đạt tính dừng. Bước này cần thiết vì giúp mô hình khớp với dữ liệu thay vì khớp với nhiễu.
Thành phần trung bình trượt (MA) tập trung vào mối liên hệ giữa một quan sát và sai số dư. Bằng cách xem quan sát hiện tại liên quan thế nào đến các sai số trong quá khứ, ta có thể suy ra thông tin hữu ích về xu thế khả dĩ trong dữ liệu.
Ta có thể coi các phần dư như một trong những sai số này, và khái niệm mô hình trung bình trượt ước lượng hoặc xét đến ảnh hưởng của chúng lên quan sát mới nhất. Điều này đặc biệt hữu ích để theo dõi và bắt các biến động ngắn hạn hoặc các cú sốc ngẫu nhiên trong dữ liệu. Ở phần (MA) của chuỗi thời gian, ta thu được thông tin giá trị về hành vi của chuỗi, từ đó cho phép dự báo chính xác hơn.
Để xây dựng mô hình ARIMA cho dự báo, như giá vàng, bạn có thể làm theo các bước sau. Hãy cùng chia nhỏ từng bước.
Bước đầu tiên là chuẩn bị bộ dữ liệu phù hợp và thiết lập môi trường.
Thu thập hoặc tìm một bộ dữ liệu từ các nền tảng nguồn dữ liệu. Bạn muốn dữ liệu có lịch sử theo thời gian. Đây là liên kết tới bộ dữ liệu Kaggle liên quan đến giá vàng kỳ hạn.
Chúng ta cài các gói cần thiết, bao gồm statsmodels và sklearn.
import pandas as pdimport matplotlib.pyplot as pltfrom statsmodels.tsa.stattools import adfullerfrom statsmodels.graphics.tsaplots import plot_acf, plot_pacffrom statsmodels.tsa.arima.model import ARIMAfrom sklearn.metrics import mean_squared_errorTiếp theo, chúng ta đọc dữ liệu vào môi trường cục bộ. Tôi thực hiện thêm bước bảo đảm các ngày được nhận diện theo đúng thứ tự.
# Define the path to your CSV file# You may have to make this path more specific to the location of your file.csv_path = "future-gc00-daily-prices.csv"# Read the CSV, parse 'Date' column as datetime, and set it as the indexdata = pd.read_csv( csv_path, parse_dates=["Date"], dayfirst=False, index_col="Date")# Sort the DataFrame by the Date index in ascending orderdata.sort_index(inplace=True)Bộ dữ liệu của chúng ta khá sạch, nhưng trong bối cảnh khác, chúng ta sẽ cần xử lý các vấn đề lập chỉ mục, điều này quan trọng trong dự báo chuỗi thời gian. Ví dụ, nếu dự báo giá đóng cửa của một cổ phiếu trên một sàn cụ thể, cần lưu ý thị trường chứng khoán không mở cửa vào cuối tuần.
Trước khi tiếp tục, tôi cũng thực hiện bước nhanh là loại bỏ dấu phẩy khỏi biến Close, đây là biến tôi sẽ dùng.
# Clean the "Close" columndata["Close"] = data["Close"].replace(',', '', regex=True)data["Close"] = pd.to_numeric(data["Close"], errors='coerce')data["Close"].replace([np.inf, -np.inf], np.nan, inplace=True)data.dropna(subset=["Close"], inplace=True)Trong tiền xử lý dữ liệu, chúng ta cũng thường phải cân nhắc cách xử lý giá trị thiếu bằng phương pháp bù như điền chuyển tiếp hoặc thay bằng trung bình. Lưu ý rằng chỉ một giá trị NA, tùy theo ngôn ngữ lập trình và thư viện bạn dùng, cũng có thể ngăn ARIMA chạy.
Tôi đã đề cập rằng ngày cuối tuần có thể được ghi nhận là NA. Điều đó có thể xảy ra và sẽ cần thêm một bước. May mắn là statsmodels xử lý dữ liệu như một chỉ mục tuần tự mà không bắt buộc khoảng thời gian đều đặn, cho phép mô hình biên dịch ngay cả khi có khoảng trống cuối tuần.
Bây giờ là thời điểm tốt để tạo một biểu đồ thời gian để xem chuỗi mà chúng ta đang làm việc:
# Plotting the original Close priceplt.figure(figsize=(14, 7))plt.plot(data.index, data["Close"], label='Close Price')plt.title('Close Price Over Time')plt.xlabel('Date')plt.ylabel('Close Price')plt.legend()plt.show()
Mặc dù mô hình ARIMA có thể xử lý tính không dừng ở một mức độ nào đó, chúng không thể tính đến phương sai thay đổi theo thời gian một cách hiệu quả. Nói cách khác, để ARIMA thực sự hoạt động, dữ liệu phải dừng.
Nhìn vào đồ thị ở trên, có thể thấy dữ liệu thực sự không dừng vì có xu hướng rõ rệt. Ngoài ra, có vẻ có phương sai không hằng tại các thời điểm khác nhau. Ta có thể dùng kiểm định Augmented Dickey-Fuller để kiểm chứng trực giác và xem dữ liệu có trung bình và phương sai không đổi hay không, đồng thời lượng hóa điều đó.
# Perform the Augmented Dickey-Fuller test on the original seriesresult_original = adfuller(data["Close"])print(f"ADF Statistic (Original): {result_original[0]:.4f}")print(f"p-value (Original): {result_original[1]:.4f}")if result_original[1] < 0.05: print("Interpretation: The original series is Stationary.\n")else: print("Interpretation: The original series is Non-Stationary.\n")# Apply first-order differencingdata['Close_Diff'] = data['Close'].diff()# Perform the Augmented Dickey-Fuller test on the differenced seriesresult_diff = adfuller(data["Close_Diff"].dropna())print(f"ADF Statistic (Differenced): {result_diff[0]:.4f}")print(f"p-value (Differenced): {result_diff[1]:.4f}")if result_diff[1] < 0.05: print("Interpretation: The differenced series is Stationary.")else: print("Interpretation: The differenced series is Non-Stationary.")ADF Statistic (Original): -1.4367p-value (Original): 0.5646Interpretation: The original series is Non-Stationary.ADF Statistic (Differenced): -19.1308p-value (Differenced): 0.0000Interpretation: The differenced series is Stationary.Kết quả kiểm định Augmented Dickey-Fuller cho thấy chuỗi gốc thực sự không dừng, nên dùng ARIMA ngay trên dữ liệu gốc sẽ là sai lầm.
Tuy nhiên, kiểm định ADF trên phiên bản đã sai phân cho thấy chuỗi sau sai phân là dừng.
Một lưu ý nhanh về sai phân. Tôi muốn giải thích điều này vì có khá nhiều thứ diễn ra bên dưới. Để thực hiện sai phân, chúng ta trừ mỗi quan sát cho quan sát liền trước để tạo ra chuỗi thời gian mới là sai phân bậc một. (Chuỗi mới giờ ngắn hơn chuỗi gốc một phần tử.) Nếu chuỗi sau sai phân vẫn chưa dừng, ta có thể lấy sai phân bậc hai bằng cách sai phân chuỗi gốc thêm lần nữa, và có thể tiếp tục sai phân cho đến khi chuỗi trở nên dừng. Bậc sai phân yêu cầu là số sai phân tối thiểu để thu được chuỗi không còn tự tương quan.
Cuối cùng, xin lưu ý: đừng sai phân nhiều hơn mức cần thiết, nếu không bạn có thể tạo ra động lực giả trong dữ liệu. Ngoài ra, nếu bạn định dùng mô hình ARIMA theo mùa (không thực hiện trong hướng dẫn này), bạn luôn nên cân nhắc sai phân theo mùa trước khi sai phân bậc một.
# Plotting the differenced Close priceplt.figure(figsize=(14, 7))plt.plot(data.index, data['Close_Diff'], label='Differenced Close Price', color='orange')plt.title('Differenced Close Price Over Time')plt.xlabel('Date')plt.ylabel('Differenced Close Price')plt.legend()plt.show()
Khi xây dựng mô hình ARIMA, chúng ta phải cân nhắc các hạng p, d và q đưa vào mô hình ARIMA.
Chúng ta dùng các công cụ như ACF (Hàm tự tương quan) và PACF (Hàm tự tương quan từng phần) để xác định các giá trị p, d và q. Số độ trễ tại đó ACF cắt ngưỡng là q, và PACF cắt ngưỡng là p. Ta cũng phải chọn giá trị phù hợp cho d bằng cách tạo tình huống mà, sau khi sai phân, dữ liệu giống như nhiễu trắng. Với dữ liệu của chúng ta, chọn 1 cho cả p và q vì thấy một đột biến đáng kể ở độ trễ đầu tiên của mỗi hàm.
from statsmodels.graphics.tsaplots import plot_acf, plot_pacfimport matplotlib.pyplot as plt# Plot ACF and PACF for the differenced seriesfig, axes = plt.subplots(1, 2, figsize=(16, 4))# ACF plotplot_acf(data['Close_Diff'].dropna(), lags=40, ax=axes[0])axes[0].set_title('Autocorrelation Function (ACF)')# PACF plotplot_pacf(data['Close_Diff'].dropna(), lags=40, ax=axes[1])axes[1].set_title('Partial Autocorrelation Function (PACF)')plt.tight_layout()plt.show()
Cần làm rõ rằng các giá trị p, d và q trong ARIMA biểu thị bậc của mô hình (số trễ cho AR, sai phân và MA), nhưng không phải là các tham số thực sự được ước lượng. Khi đã chọn p, d, q, mô hình sẽ ước lượng thêm các tham số như hệ số cho các thành phần AR và MA thông qua ước lượng hợp lý tối đa (MLE).
Để dự báo bằng mô hình ARIMA, bắt đầu bằng cách dùng mô hình đã khớp để dự đoán các giá trị tương lai dựa trên dữ liệu. Sau khi có dự đoán, việc trực quan hóa bằng cách vẽ giá trị dự đoán cùng với giá trị thực sẽ hữu ích. Điều này đạt được vì ta dùng quy trình train/test, trong đó dữ liệu được chia thành tập huấn luyện và kiểm tra. Cách làm này cho phép thấy mô hình hoạt động thế nào trên dữ liệu chưa thấy. Nếu bạn chưa rõ, hãy học khóa Model Validation in Python, một tài nguyên tuyệt vời để học chi tiết về huấn luyện và kiểm tra.
Bước đầu tiên là tách dữ liệu thành phiên bản huấn luyện và kiểm tra.
# Split data into train and testtrain_size = int(len(data) * 0.8)train, test = data.iloc[:train_size], data.iloc[train_size:]# Fit ARIMA modelmodel = ARIMA(train["Close"], order=(1,1,1))model_fit = model.fit()Bước tiếp theo là tạo dự báo và trực quan để kiểm tra. Ta có thể xem dự báo hoạt động ra sao so với tập kiểm tra.
# Forecastforecast = model_fit.forecast(steps=len(test))# Plot the results with specified colorsplt.figure(figsize=(14,7))plt.plot(train.index, train["Close"], label='Train', color='#203147')plt.plot(test.index, test["Close"], label='Test', color='#01ef63')plt.plot(test.index, forecast, label='Forecast', color='orange')plt.title('Close Price Forecast')plt.xlabel('Date')plt.ylabel('Close Price')plt.legend()plt.show()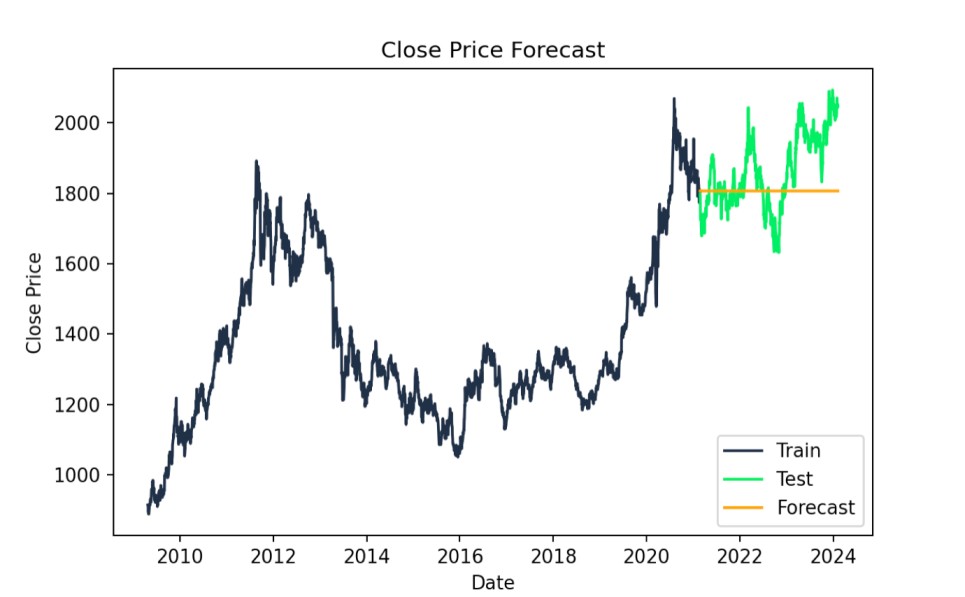
Dự báo ARIMA: giá trị thực so với giá trị dự đoán. Ảnh: Tác giả
Chúng ta xem các thống kê mô hình AIC và BIC. Giá trị thấp hơn nghĩa là mô hình khớp tốt hơn, nhưng ta cũng có thể so sánh với các mô hình đơn giản hơn để tránh overfitting. Tôi in các con số ở đây nhưng chúng có ý nghĩa nhất khi so sánh với các mô hình ARIMA khác trên cùng dữ liệu, nhằm tìm mô hình ARIMA hoạt động tốt nhất.
print(f"AIC: {model_fit.aic}")print(f"BIC: {model_fit.bic}")AIC: 24602.97426066606BIC: 24620.97128230579Chúng ta cũng có thể đánh giá sai số bình phương trung bình để xem độ khớp của mô hình. Đây là một chỉ số thực tiễn. RMSE thấp hơn cho thấy mô hình ARIMA tốt hơn, phản ánh chênh lệch nhỏ hơn giữa giá trị thực và dự đoán, và nó cùng thang đo với dữ liệu. Tức là, RMSE 118,5339 cho thấy trung bình dự đoán của mô hình lệch khỏi giá Close thực khoảng 118,53 đô la.
forecast = forecast[:len(test)]test_close = test["Close"][:len(forecast)]# Calculate RMSErmse = np.sqrt(mean_squared_error(test_close, forecast))print(f"RMSE: {rmse:.4f}")RMSE: 118.5339Học cùng DataCamp
Courses
Courses
Courses