
Kurs
Finanzprognosen mit Python
4 Std.
13.1K
Schauen wir uns ARIMA an – eine der beliebtesten, wenn nicht die beliebteste Technik für Zeitreihenprognosen. ARIMA ist so gefragt, weil es Zeitreihendaten effektiv modelliert: Es erfasst sowohl die autoregressiven (AR) als auch die gleitenden Durchschnittskomponenten (MA) und macht nicht-stationäre Reihen durch Differenzbildung (I) stationär. Diese Kombination macht ARIMA-Modelle besonders flexibel – deshalb kommen sie in sehr unterschiedlichen Bereichen zum Einsatz, von Finanzen bis Wettervorhersage.
ARIMA-Modelle sind technisch anspruchsvoll, aber ich zerlege die Teile so, dass du ein solides Verständnis aufbauen kannst. Vor dem Einstieg lohnt sich ein Blick auf einige Grundlagen. DataCamp bietet viele gute Ressourcen, zum Beispiel die Kurse ARIMA Models in Python oder ARIMA Models in R. Wähle einfach die Sprache, mit der du lieber arbeitest.
In Finanzen, Volkswirtschaft, Umweltwissenschaften u. a. weckt ARIMA großes Interesse, weil es komplexe Muster in vergangenen Beobachtungen identifiziert und für künftige Entwicklungen nutzbar macht – ein echter State-of-the-Art-Ansatz. Von der Vorhersage von Aktienkursen über Wetterprognosen bis zur Einschätzung von Konsumnachfrage: ARIMA ermöglicht treffsichere, umsetzbare Analysen.
Mit ARIMA analysieren und prognostizieren wir Zeitreihen auf einem Niveau, das Muster, Trends und Saisonalität berücksichtigt. Das liefert einen Rundumblick auf die zugrunde liegende Dynamik und unterstützt fundierte Entscheidungen.
Um ARIMA wirklich zu verstehen, zerlegen wir die Bausteine. Sind die Komponenten klar, wird auch das Gesamtprinzip der Methode deutlich. Hier erkläre ich jede Komponente im Detail.
Die autoregressive Komponente (AR) bildet Trends aus vergangenen Werten und nutzt sie für Vorhersagen. Zur Einordnung: Im „autoregressiven Rahmen“ arbeitet man wie in einer Regression, nur dass man verzögerte Werte der Zeitreihe selbst als Regressoren verwendet.
Der integrierte Teil (I) bezieht sich auf die Differenzierung der Zeitreihe mit dem Ziel, Stationarität zu erreichen – also konstante Mittelwerte und Varianz über die Zeit. Vereinfacht gesagt subtrahieren wir eine Beobachtung von der vorherigen, um Trends und Saisonalität zu eliminieren. Durch Differenzieren stellen wir Stationarität her. Dieser Schritt ist nötig, damit das Modell die Struktur der Daten erfasst – und nicht das Rauschen.
Die MA-Komponente betrachtet die Beziehung zwischen einer Beobachtung und einem Residualfehler. Indem wir analysieren, wie die aktuelle Beobachtung mit vergangenen Fehlern zusammenhängt, lassen sich Hinweise auf mögliche Muster im Datensatz ableiten.
Man kann die Residuen als eine Fehlerreihe betrachten; das MA-Modell schätzt deren Einfluss auf die aktuelle Beobachtung. Das ist besonders nützlich, um kurzfristige Schwankungen oder zufällige Schocks zu erkennen und zu modellieren. Über den MA-Teil gewinnen wir wertvolle Einblicke in das Verhalten der Zeitreihe und erhöhen die Prognosegenauigkeit.
Für eine Prognose, etwa von Goldpreisen, kannst du folgende Schritte gehen. Zerlegen wir den Prozess gemeinsam.
Zuerst besorgen wir ein passendes Dataset und richten die Umgebung ein.
Sammle oder suche einen Datensatz auf Datenplattformen. Wichtig ist eine Historie über die Zeit. Hier ist ein Link zum Kaggle-Datensatz zu Gold-Futures-Preisen.
Wir installieren die benötigten Pakete, darunter statsmodels und sklearn.
import pandas as pdimport matplotlib.pyplot as pltfrom statsmodels.tsa.stattools import adfullerfrom statsmodels.graphics.tsaplots import plot_acf, plot_pacffrom statsmodels.tsa.arima.model import ARIMAfrom sklearn.metrics import mean_squared_errorNun lesen wir die Daten in unsere Umgebung ein. Ich achte zusätzlich darauf, dass Datumsangaben korrekt erkannt und sortiert werden.
# Define the path to your CSV file# You may have to make this path more specific to the location of your file.csv_path = "future-gc00-daily-prices.csv"# Read the CSV, parse 'Date' column as datetime, and set it as the indexdata = pd.read_csv( csv_path, parse_dates=["Date"], dayfirst=False, index_col="Date")# Sort the DataFrame by the Date index in ascending orderdata.sort_index(inplace=True)Unser Datensatz ist recht sauber, aber in anderen Kontexten müssten wir Index-Themen beachten – zentral für Zeitreihenprognosen. Beispiel: Wenn wir Schlusskurse einer Börse prognostizieren, ist die Börse am Wochenende geschlossen.
Bevor es weitergeht, entferne ich noch schnell Kommas aus der Variable Close, die ich verwenden werde.
# Clean the "Close" columndata["Close"] = data["Close"].replace(',', '', regex=True)data["Close"] = pd.to_numeric(data["Close"], errors='coerce')data["Close"].replace([np.inf, -np.inf], np.nan, inplace=True)data.dropna(subset=["Close"], inplace=True)Als Teil der Vorverarbeitung müssen wir oft auch Fehlwerte behandeln, z. B. per Vorwärtsauffüllen oder Mittelwertersatz. Beachte: Schon ein einziges NA kann je nach Sprache/Bibliothek verhindern, dass ARIMA läuft.
Ich hatte erwähnt, dass Wochenendtage als NA erscheinen könnten. Das kann vorkommen und erfordert ggf. einen Zusatzschritt. Glücklicherweise behandelt statsmodels die Daten als sequentiellen Index, ohne strikt regelmäßige Intervalle zu erzwingen – so kompiliert unser Modell auch mit Wochenendlücken.
Jetzt ist ein guter Zeitpunkt, die Reihe zu visualisieren:
# Plotting the original Close priceplt.figure(figsize=(14, 7))plt.plot(data.index, data["Close"], label='Close Price')plt.title('Close Price Over Time')plt.xlabel('Date')plt.ylabel('Close Price')plt.legend()plt.show()
ARIMA-Modelle können bis zu einem gewissen Grad mit Nicht-Stationarität umgehen, aber nicht mit zeitvariierender Varianz. Für ein gut funktionierendes ARIMA braucht es daher stationäre Daten.
Der Plot oben zeigt klar einen Trend – die Reihe ist also nicht stationär; zudem scheint die Varianz über die Zeit zu schwanken. Mit dem erweiterten Dickey-Fuller-Test prüfen wir diese Intuition und erhalten Kennzahlen zu Mittelwert- und Varianzkonstanz.
# Perform the Augmented Dickey-Fuller test on the original seriesresult_original = adfuller(data["Close"])print(f"ADF Statistic (Original): {result_original[0]:.4f}")print(f"p-value (Original): {result_original[1]:.4f}")if result_original[1] < 0.05: print("Interpretation: The original series is Stationary.\n")else: print("Interpretation: The original series is Non-Stationary.\n")# Apply first-order differencingdata['Close_Diff'] = data['Close'].diff()# Perform the Augmented Dickey-Fuller test on the differenced seriesresult_diff = adfuller(data["Close_Diff"].dropna())print(f"ADF Statistic (Differenced): {result_diff[0]:.4f}")print(f"p-value (Differenced): {result_diff[1]:.4f}")if result_diff[1] < 0.05: print("Interpretation: The differenced series is Stationary.")else: print("Interpretation: The differenced series is Non-Stationary.")ADF Statistic (Original): -1.4367p-value (Original): 0.5646Interpretation: The original series is Non-Stationary.ADF Statistic (Differenced): -19.1308p-value (Differenced): 0.0000Interpretation: The differenced series is Stationary.Die Ergebnisse des ADF-Tests zeigen: Die Originalreihe ist nicht stationär – ein ARIMA „out of the box“ auf dieser Basis wäre ein Fehler.
Der ADF-Test auf der differenzierten Reihe weist hingegen Stationarität nach.
Ein kurzes Wort zur Differenzierung: Dabei subtrahieren wir jede Beobachtung von der vorherigen und erhalten so eine neue Zeitreihe erster Differenzen. (Diese ist um ein Element kürzer.) Falls die differenzierte Reihe noch nicht stationär ist, können wir ein zweites Mal differenzieren und so fort, bis Stationarität erreicht ist. Die benötigte Differenzierungsordnung ist die minimale Anzahl an Differenzen, die eine Reihe ohne Autokorrelation ergibt.
Wichtig: Differenziere nicht öfter als nötig – sonst erzeugst du künstliche Dynamiken. Und falls du ein saisonales ARIMA (SARIMA) aufbauen willst, würdest du eine saisonale Differenz in der Regel vor einer ersten (nicht-saisonalen) Differenz prüfen.
# Plotting the differenced Close priceplt.figure(figsize=(14, 7))plt.plot(data.index, data['Close_Diff'], label='Differenced Close Price', color='orange')plt.title('Differenced Close Price Over Time')plt.xlabel('Date')plt.ylabel('Differenced Close Price')plt.legend()plt.show()
Beim Aufbau eines ARIMA-Modells wählen wir die Terme p, d und q.
Zur Bestimmung von p, d und q nutzen wir ACF (Autokorrelationsfunktion) und PACF (partielle Autokorrelationsfunktion). Wo ACF abrupt abfällt, liefert Hinweise auf q, und wo PACF abfällt, auf p. Den passenden Wert für d wählen wir so, dass die differenzierte Reihe näherungsweise wie weißes Rauschen wirkt. Für unsere Daten wählen wir jeweils 1 für p und q, da beim ersten Lag in beiden Fällen ein deutlicher Ausschlag zu sehen ist.
from statsmodels.graphics.tsaplots import plot_acf, plot_pacfimport matplotlib.pyplot as plt# Plot ACF and PACF for the differenced seriesfig, axes = plt.subplots(1, 2, figsize=(16, 4))# ACF plotplot_acf(data['Close_Diff'].dropna(), lags=40, ax=axes[0])axes[0].set_title('Autocorrelation Function (ACF)')# PACF plotplot_pacf(data['Close_Diff'].dropna(), lags=40, ax=axes[1])axes[1].set_title('Partial Autocorrelation Function (PACF)')plt.tight_layout()plt.show()
Zur Klarstellung: Die Werte p, d und q beschreiben die Modellordnung (Lags für AR, Differenzierung und MA), sind aber nicht die zu schätzenden Parameter selbst. Nachdem p, d und q feststehen, schätzt das Modell weitere Parameter – etwa Koeffizienten der AR- und MA-Terme – per Maximum-Likelihood-Schätzung (MLE).
Für Vorhersagen mit ARIMA nutzt du das angepasste Modell, um auf Basis der Daten zukünftige Werte zu schätzen. Anschließend visualisierst du die Prognosen sinnvollerweise gemeinsam mit den Ist-Werten. Das gelingt über einen Train/Test-Workflow, bei dem die Daten in Trainings- und Testmenge aufgeteilt werden. So siehst du, wie gut das Modell auf unbekannten Daten performt. Falls das neu für dich ist, schau dir unseren Kurs Model Validation in Python an.
Zuerst teilen wir die Daten in Trainings- und Testdaten auf.
# Split data into train and testtrain_size = int(len(data) * 0.8)train, test = data.iloc[:train_size], data.iloc[train_size:]# Fit ARIMA modelmodel = ARIMA(train["Close"], order=(1,1,1))model_fit = model.fit()Als Nächstes erzeugen wir die Prognose und prüfen sie visuell. So sehen wir, wie sich die Vorhersage gegenüber den Testdaten schlägt.
# Forecastforecast = model_fit.forecast(steps=len(test))# Plot the results with specified colorsplt.figure(figsize=(14,7))plt.plot(train.index, train["Close"], label='Train', color='#203147')plt.plot(test.index, test["Close"], label='Test', color='#01ef63')plt.plot(test.index, forecast, label='Forecast', color='orange')plt.title('Close Price Forecast')plt.xlabel('Date')plt.ylabel('Close Price')plt.legend()plt.show()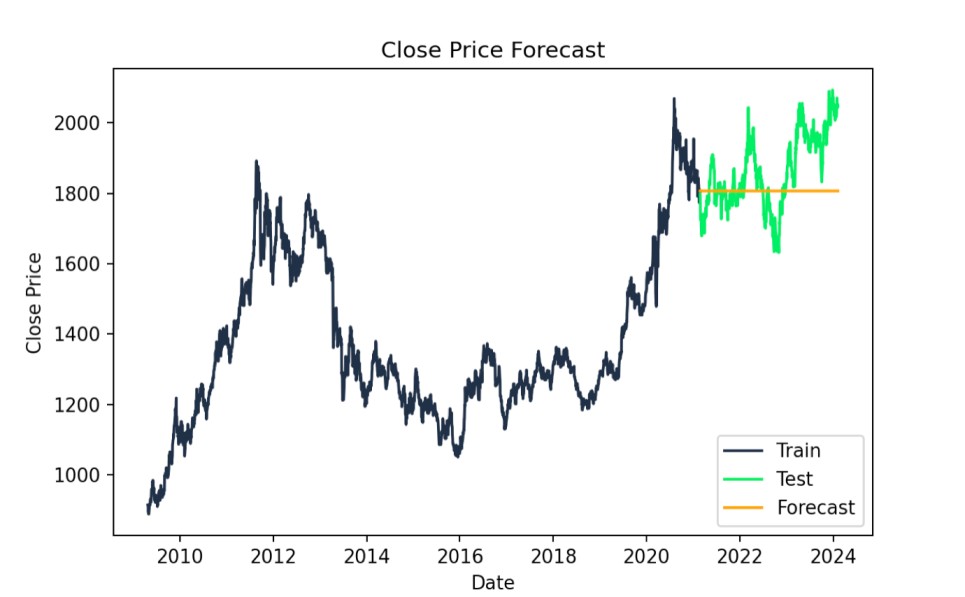
ARIMA-Prognose: Ist- vs. Vorhersagewerte. Bild: Autorin/Autor
Wir prüfen AIC- und BIC-Werte. Kleinere Werte deuten auf bessere Passung hin – allerdings vergleichen wir idealerweise mit einfacheren Modellen, um Overfitting zu vermeiden. Ich drucke die Werte hier aus; sinnvoll werden sie vor allem im Vergleich mehrerer ARIMA-Varianten auf denselben Daten, um das beste Modell zu finden.
print(f"AIC: {model_fit.aic}")print(f"BIC: {model_fit.bic}")AIC: 24602.97426066606BIC: 24620.97128230579Zusätzlich können wir den mittleren quadratischen Fehler auswerten, um die Passung praktisch zu beurteilen. Ein geringerer RMSE steht für ein besseres ARIMA-Modell und ist auf der Skala der Daten interpretierbar. Ein RMSE von 118,5339 bedeutet hier, dass die Vorhersagen im Mittel um etwa 118,53 $ vom tatsächlichen Close abweichen.
forecast = forecast[:len(test)]test_close = test["Close"][:len(forecast)]# Calculate RMSErmse = np.sqrt(mean_squared_error(test_close, forecast))print(f"RMSE: {rmse:.4f}")RMSE: 118.5339Lerne mit DataCamp
Kurs
Kurs
Kurs
Tutorial
Laiba Siddiqui
Tutorial
Adel Nehme
Tutorial
Matt Crabtree
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Mark Pedigo

