
Kurs
Python ile Finansal Tahminleme
4 sa
13.2K
En popüler (hatta muhtemelen en popüler) zaman serisi tahmin tekniklerinden biri olan ARIMA'ya bir göz atalım. ARIMA, hem otoregresif (AR) hem de hareketli ortalama (MA) bileşenlerini yakalarken, fark alma (I) yoluyla durağan olmama sorununu da ele aldığı için zaman serisi verilerini etkili biçimde modelleyerek popüler hale gelmiştir. Bu kombinasyon, ARIMA modellerini özellikle esnek kılar; bu yüzden finans ve hava tahmini gibi çok farklı sektörlerde kullanılır.
ARIMA modelleri oldukça tekniktir; ancak bölümlere ayırarak güçlü bir anlayış geliştirmenizi sağlayacağım. Başlamadan önce bazı temel araçlara aşina olmak iyi bir fikirdir. DataCamp, tercih ettiğiniz dile bağlı olarak seçebileceğiniz Python ile ARIMA Modelleri veya R ile ARIMA Modelleri gibi birçok iyi kaynak sunuyor.
Finans, ekonomi ve çevre bilimleri gibi alanlarda ARIMA büyük ilgi görür; çünkü geçmiş gözlemlerimizdeki karmaşık örüntüleri belirleyip geleceğe yönelik ihtiyaçlarla ilişkilendirebilir; bu da onu güncel bir teknik yapar. Hisse senedi fiyatlarını tahmin etmekten, hava durumu örüntülerini öngörmeye ve tüketici talebini anlamaya kadar ARIMA, doğru ve eyleme geçirilebilir öngörüler üretmenin harika bir yoludur.
ARIMA kullanarak, kalıpları, eğilimleri ve mevsimselliği hesaba katarak zaman serisi verilerini hem analiz edip hem de ileri dönük tahmin edebiliriz. Bu da bilinçli kararlar almak için altta yatan dinamiklere 360 derecelik bir bakış sağlar.
ARIMA'yı gerçekten anlamak için yapı taşlarını sökmemiz gerekir. Bileşenleri kavradığımızda, bu zaman serisi tahmin yönteminin bütünüyle nasıl çalıştığını görmek kolaylaşacaktır. Burada her bileşeni ayrıntılı olarak açıklayacağım.
Otoregresif (AR) bileşen, tahminleyici modellerde AR çerçevesi içinde geçmiş değerlerden bir eğilim oluşturur. Açıklık getirmek gerekirse, 'otoregresyon çerçevesi', serinin kendi geçmiş değerlerinin gecikmelerini yordayıcı değişkenler olarak kullandığınız bir regresyon modeli gibi çalışır.
Entegre (I) kısmı, zaman serisinin durağan olmasını sağlamak amacıyla fark alma işlemini içerir; bu, ortalama ve varyansın zaman içinde sabit kalması anlamına gelir. Temelde, eğilimleri ve mevsimselliği ortadan kaldırmak için bir gözlemden bir sonrakini çıkarırız. Fark alma yaparak durağanlık elde ederiz. Bu adım, modelin veriye değil gürültüye uyum sağlamasını engellediği için gereklidir.
Hareketli ortalama (MA) bileşeni, bir gözlem ile artık hata arasındaki ilişkiye odaklanır. Mevcut gözlemin geçmiş hatalarla nasıl ilişkili olduğuna bakarak, verimizdeki olası bir eğilim hakkında yararlı bilgiler çıkarabiliriz.
Artıklardan bir kısmını bu hatalardan biri olarak düşünebilir ve hareketli ortalama modelinin kavramı bunların en son gözlemimiz üzerindeki etkisini tahmin eder veya dikkate alır. Bu, özellikle verideki kısa vadeli değişimleri veya rastgele şokları izlemek ve yakalamak için kullanışlıdır. Bir zaman serisinin (MA) kısmında, davranışı hakkında değerli bilgiler edinebiliriz; bu da daha isabetli öngörüler yapmamızı sağlar.
Altın fiyatları gibi bir büyüklüğü tahminlemek için ARIMA modeli kurmak üzere şu adımları izleyebilirsiniz. Gelin birlikte parçalara ayıralım.
İlk adım, uygun bir veri kümesi hazırlamak ve çalışma ortamımızı kurmaktır.
Veri kaynak platformlarından bir veri kümesi toplayın veya arayın. Zaman içinde tarihsel veriler içeren bir küme istemeniz gerekir. Altın vadeli fiyatlarına ilişkin Kaggle veri kümesine bağlantı burada.
Gereken paketleri kuruyoruz; bunlara statsmodels ve sklearn dahildir.
import pandas as pdimport matplotlib.pyplot as pltfrom statsmodels.tsa.stattools import adfullerfrom statsmodels.graphics.tsaplots import plot_acf, plot_pacffrom statsmodels.tsa.arima.model import ARIMAfrom sklearn.metrics import mean_squared_errorArdından veriyi yerel ortamımıza okuyoruz. Tarihlerin doğru sırada tanındığından emin olmak için fazladan bir adım atıyorum.
# Define the path to your CSV file# You may have to make this path more specific to the location of your file.csv_path = "future-gc00-daily-prices.csv"# Read the CSV, parse 'Date' column as datetime, and set it as the indexdata = pd.read_csv( csv_path, parse_dates=["Date"], dayfirst=False, index_col="Date")# Sort the DataFrame by the Date index in ascending orderdata.sort_index(inplace=True)Veri kümemiz oldukça temiz; ancak başka bağlamlarda zaman serisi tahminlerinde önemli olan indeksleme sorunlarıyla uğraşmamız gerekebilirdi. Örneğin, belirli bir borsadaki bir hissenin kapanış değerini tahmin ederken, borsanın hafta sonları açık olmadığını dikkate almak gerekir.
Devam etmeden önce, kullanacağım Close değişkeninden virgülleri kaldırma adımını da hızlıca atıyorum.
# Clean the "Close" columndata["Close"] = data["Close"].replace(',', '', regex=True)data["Close"] = pd.to_numeric(data["Close"], errors='coerce')data["Close"].replace([np.inf, -np.inf], np.nan, inplace=True)data.dropna(subset=["Close"], inplace=True)Veri ön işlemenin bir parçası olarak, ileri doldurma veya ortalama ile tamamlama gibi bir atama yöntemi kullanarak eksik değerleri nasıl ele alacağımızı da sıkça düşünmemiz gerekir. Kullandığınız programlama dili ve kütüphaneye bağlı olarak tek bir NA değerin bile ARIMA'nın çalışmasını engelleyebileceğini bilin.
Hafta sonu günlerinin NA olarak tanınabileceğinden bahsetmiştim. Bu mümkün olabilir ve ek bir adım gerektirebilir. Neyse ki, statsmodels veriyi düzenli zaman aralıklarını katı biçimde zorunlu kılmadan sıralı bir indeks olarak ele alır; bu da modelimizin hafta sonu boşlukları olsa dahi derlenmesine olanak tanır.
Şimdi, üzerinde çalıştığımız seriyi görebilmek için bir zaman grafiği oluşturmak için iyi bir zaman:
# Plotting the original Close priceplt.figure(figsize=(14, 7))plt.plot(data.index, data["Close"], label='Close Price')plt.title('Close Price Over Time')plt.xlabel('Date')plt.ylabel('Close Price')plt.legend()plt.show()
ARIMA modelleri belli bir noktaya kadar durağan olmama ile başa çıkabilse de, zamanla değişen varyansı etkili biçimde hesaba katamazlar. Başka bir deyişle, bir ARIMA modelinin gerçekten işe yaraması için verinin durağan olması gerekir.
Yukarıdaki grafiğe baktığımızda, belirgin bir eğilim olduğu için verinin aslında durağan olmadığını görebiliriz. Ayrıca farklı zaman noktalarında değişken olmayan bir varyans da var gibi görünüyor. Bu sezgimizi sınamak ve verimizin sabit bir ortalama ve varyansa sahip olup olmadığını görmek için Genişletilmiş Dickey-Fuller testini kullanabilir ve bunu sayısallaştırabiliriz.
# Perform the Augmented Dickey-Fuller test on the original seriesresult_original = adfuller(data["Close"])print(f"ADF Statistic (Original): {result_original[0]:.4f}")print(f"p-value (Original): {result_original[1]:.4f}")if result_original[1] < 0.05: print("Interpretation: The original series is Stationary.\n")else: print("Interpretation: The original series is Non-Stationary.\n")# Apply first-order differencingdata['Close_Diff'] = data['Close'].diff()# Perform the Augmented Dickey-Fuller test on the differenced seriesresult_diff = adfuller(data["Close_Diff"].dropna())print(f"ADF Statistic (Differenced): {result_diff[0]:.4f}")print(f"p-value (Differenced): {result_diff[1]:.4f}")if result_diff[1] < 0.05: print("Interpretation: The differenced series is Stationary.")else: print("Interpretation: The differenced series is Non-Stationary.")ADF Statistic (Original): -1.4367p-value (Original): 0.5646Interpretation: The original series is Non-Stationary.ADF Statistic (Differenced): -19.1308p-value (Differenced): 0.0000Interpretation: The differenced series is Stationary.Genişletilmiş Dickey-Fuller testimizin sonuçları, özgün serimizin gerçekten durağan olmadığını gösteriyor; bu nedenle orijinal veri üzerinde doğrudan bir ARIMA kullanmak hata olurdu.
Buna karşın, fark alınmış sürüm üzerindeki ADF testi fark alınmış verinin durağan olduğunu gösteriyor.
Fark alma üzerine kısa bir not. Kaputun altında çok şey olduğu için bunu açıklamak istiyorum. Fark alma yapmak için, her gözlemden bir önceki çıkarılır ve bize birinci farkların yeni bir zaman serisini verir. (Yeni zaman serisi artık orijinalden bir eleman daha kısadır.) Eğer fark alınmış seri hâlâ durağan değilse, orijinal seride ikinci kez fark alarak bir ikinci fark daha alınabilir ve seri durağan olana kadar bu işleme devam edilebilir. Gerekli fark alma derecesi, seride otokorelasyon kalmayana kadar gereken asgari fark sayısıdır.
Son olarak şunu söylemek isterim: Gerekenden fazla fark almayın; aksi halde verinizde sahte dinamikler yaratabilirsiniz. Ayrıca, bu eğitimde yapmadığımız mevsimsel bir ARIMA modeli kuracak olsaydınız, her zaman birinci farktan önce mevsimsel farkı düşünürdünüz.
# Plotting the differenced Close priceplt.figure(figsize=(14, 7))plt.plot(data.index, data['Close_Diff'], label='Differenced Close Price', color='orange')plt.title('Differenced Close Price Over Time')plt.xlabel('Date')plt.ylabel('Differenced Close Price')plt.legend()plt.show()
Bir ARIMA modeli kurarken modele girecek p, d ve q terimlerini dikkate almalıyız.
ACF (Otokorelasyon Fonksiyonu) ve PACF (Kısmi Otokorelasyon Fonksiyonu) gibi araçları kullanarak p, d ve q değerlerini belirleriz. ACF'nin kesildiği gecikme sayısı q, PACF'nin kesildiği yer ise p'dir. Ayrıca, d için de uygun değeri seçmemiz gerekir; fark aldıktan sonra verinin beyaz gürültüye benzemesini sağlariz. Verimiz için, her birinde ilk gecikmede anlamlı bir sıçrama gördüğümüzden p ve q için 1'i seçiyoruz.
from statsmodels.graphics.tsaplots import plot_acf, plot_pacfimport matplotlib.pyplot as plt# Plot ACF and PACF for the differenced seriesfig, axes = plt.subplots(1, 2, figsize=(16, 4))# ACF plotplot_acf(data['Close_Diff'].dropna(), lags=40, ax=axes[0])axes[0].set_title('Autocorrelation Function (ACF)')# PACF plotplot_pacf(data['Close_Diff'].dropna(), lags=40, ax=axes[1])axes[1].set_title('Partial Autocorrelation Function (PACF)')plt.tight_layout()plt.show()
Açıklık için: ARIMA'daki p, d ve q değerleri modelin mertebesini (otoregresyon gecikmeleri, fark alma ve hareketli ortalama terimleri) temsil eder; ancak bunlar tahmin edilen asıl parametreler değildir. p, d ve q değerleri seçildikten sonra, model, otoregresif ve hareketli ortalama terimlerinin katsayıları gibi ek parametreleri en büyük olabilirlik kestirimi (MLE) ile tahmin eder.
Bir ARIMA modeli kullanarak tahmin yapmak için, önce uyumlanmış modeli veriye dayalı olarak gelecekteki değerleri öngörmekte kullanın. Tahminler yapıldıktan sonra, tahmin edilen değerleri gerçek değerlerle birlikte çizerek görselleştirmek faydalıdır. Bunu, veriyi eğitim ve test kümelerine ayırdığımız bir eğitim/test iş akışıyla gerçekleştiririz. Böylece modelin görülmemiş veride nasıl performans gösterdiğini görebiliriz. Bu konuda net değilseniz, eğitim ve testin inceliklerini öğrenmek için harika bir kaynak olan Python'da Model Doğrulama kursumuzu alın.
İlk adımımız, veriyi eğitim ve test sürümlerine ayırmaktır.
# Split data into train and testtrain_size = int(len(data) * 0.8)train, test = data.iloc[:train_size], data.iloc[train_size:]# Fit ARIMA modelmodel = ARIMA(train["Close"], order=(1,1,1))model_fit = model.fit()Sıradaki adımımız, tahminimizi oluşturmak ve görsel olarak incelemektir. Tahminimizin, verimizin test sürümüne karşı nasıl performans gösterdiğini görebiliriz.
# Forecastforecast = model_fit.forecast(steps=len(test))# Plot the results with specified colorsplt.figure(figsize=(14,7))plt.plot(train.index, train["Close"], label='Train', color='#203147')plt.plot(test.index, test["Close"], label='Test', color='#01ef63')plt.plot(test.index, forecast, label='Forecast', color='orange')plt.title('Close Price Forecast')plt.xlabel('Date')plt.ylabel('Close Price')plt.legend()plt.show()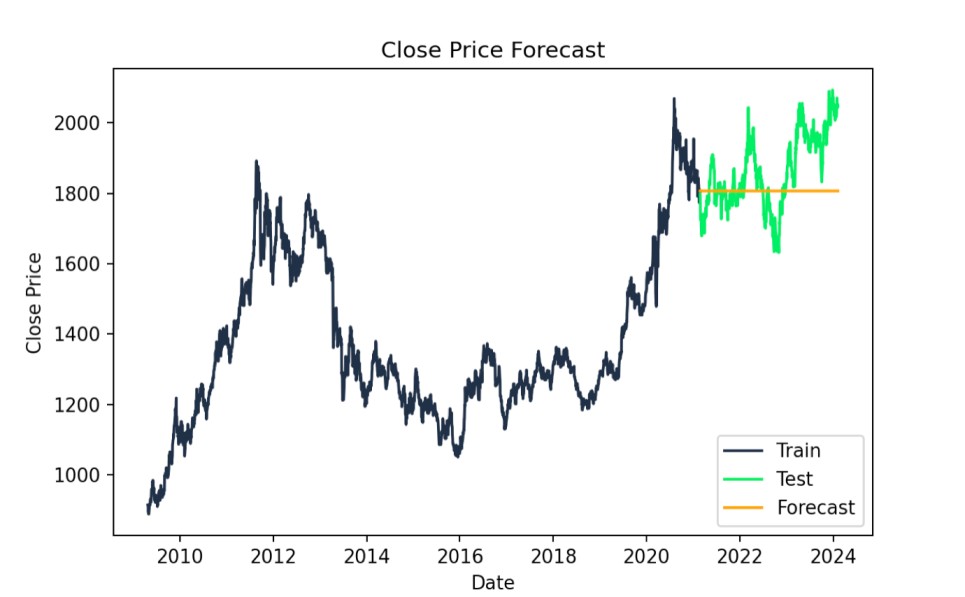
ARIMA tahmini: gerçek ve tahmin edilen değerler. Görsel: Yazar
AIC ve BIC model istatistiklerine bakıyoruz. Daha düşük değerler daha iyi uyuma işaret eder; ancak aşırı uyumu önlemek için sonuçları daha basit modellerle de karşılaştırabiliriz. Burada sayıları yazdırıyorum; fakat en çok, aynı veri üzerinde farklı ARIMA modelleriyle karşılaştırırken anlamlıdır; böylece en iyi çalışan ARIMA modelini buluruz.
print(f"AIC: {model_fit.aic}")print(f"BIC: {model_fit.bic}")AIC: 24602.97426066606BIC: 24620.97128230579Modelin uyumunu değerlendirmek için ortalama karesel hatayı da değerlendirebiliriz. Bu pratik bir metriktir. Daha düşük RMSE, ARIMA modelinin daha iyi olduğunu, yani gerçek ve tahmin edilen değerler arasındaki farkların daha küçük olduğunu ve verinin ölçeğinde olduğunu gösterir. Örneğin, 118,5339 RMSE, modelimizin tahminlerinin ortalama olarak gerçek Close fiyatlarından yaklaşık 118,53 $ saptığını gösterir.
forecast = forecast[:len(test)]test_close = test["Close"][:len(forecast)]# Calculate RMSErmse = np.sqrt(mean_squared_error(test_close, forecast))print(f"RMSE: {rmse:.4f}")RMSE: 118.5339DataCamp ile Öğrenin
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
