
Corso
Previsioni finanziarie in Python
4 h
13.2K
Diamo un'occhiata ad ARIMA, una delle tecniche di previsione per serie temporali più diffuse (se non la più diffusa). ARIMA è popolare perché modella in modo efficace i dati di serie temporali catturando sia le componenti autoregressiva (AR) sia di media mobile (MA), affrontando al contempo la non stazionarietà tramite la differenziazione (I). Questa combinazione rende i modelli ARIMA particolarmente flessibili, motivo per cui sono usati in settori molto diversi, come la finanza e le previsioni meteo.
I modelli ARIMA sono piuttosto tecnici, ma ne scomporrò le parti per aiutarti a sviluppare una solida comprensione. Prima di iniziare, è una buona idea familiarizzare con alcuni strumenti di base. DataCamp offre molte risorse valide, come i corsi ARIMA Models in Python o ARIMA Models in R. Puoi scegliere in base al linguaggio che preferisci.
In finanza, economia, scienze ambientali, ecc., ARIMA suscita grande interesse perché riesce a identificare molti pattern complessi dalle osservazioni passate per soddisfare esigenze future, il che lo rende una tecnica all'avanguardia. Dalla previsione del prezzo delle azioni al nowcasting dei modelli meteorologici fino a farsi un'idea della domanda dei consumatori, ARIMA è un ottimo modo per realizzare analisi predittive accurate e azionabili.
Con ARIMA possiamo analizzare e prevedere le serie temporali in modo sofisticato, tenendo conto di pattern, trend e stagionalità. Questo facilita una visione a 360 gradi delle dinamiche sottostanti per prendere decisioni informate.
Per capire davvero ARIMA, dobbiamo scomporne i mattoni. Una volta chiarite le componenti, sarà più semplice comprendere come funziona nel suo complesso questo metodo di previsione per serie temporali. Qui darò una spiegazione dettagliata di ogni componente.
La componente autoregressiva (AR) costruisce un trend a partire dai valori passati nel framework AR per i modelli predittivi. Per chiarire, il "framework autoregressivo" funziona come un modello di regressione in cui usi i ritardi (lag) dei valori passati della serie stessa come regressori.
La parte integrata (I) riguarda la differenziazione della serie tenendo presente che la nostra serie temporale dovrebbe essere stazionaria, il che significa che media e varianza dovrebbero rimanere costanti nel tempo. In pratica, sottraiamo un'osservazione dall'altra per eliminare trend e stagionalità. Con la differenziazione otteniamo la stazionarietà. Questo passaggio è necessario perché aiuta il modello a adattarsi ai dati e non al rumore.
La componente di media mobile (MA) si concentra sulla relazione tra un'osservazione e un errore residuo. Osservando come l'osservazione attuale è legata agli errori passati, possiamo ricavare informazioni utili su eventuali trend nei nostri dati.
Possiamo considerare i residui tra questi errori e il concetto di modello di media mobile stima o tiene conto del loro impatto sulla nostra osservazione più recente. Questo è particolarmente utile per intercettare variazioni di breve periodo o shock casuali nei dati. Nella parte (MA) di una serie temporale, possiamo ottenere informazioni preziose sul suo comportamento che a loro volta consentono previsioni più accurate.
Per costruire un modello ARIMA per la previsione, ad esempio dei prezzi dell'oro, puoi seguire questi passaggi. Vediamoli insieme.
Il primo passo è predisporre un dataset appropriato e preparare l'ambiente.
Raccogli o cerca un dataset su piattaforme di dati. Te ne serve uno che contenga dati storici nel tempo. Ecco un link al dataset Kaggle relativo ai prezzi dei future sull'oro.
Installiamo i pacchetti necessari, tra cui statsmodels e sklearn.
import pandas as pdimport matplotlib.pyplot as pltfrom statsmodels.tsa.stattools import adfullerfrom statsmodels.graphics.tsaplots import plot_acf, plot_pacffrom statsmodels.tsa.arima.model import ARIMAfrom sklearn.metrics import mean_squared_errorQuindi leggiamo i dati nel nostro ambiente locale. Faccio un passaggio in più per assicurarci che le date siano riconosciute nell'ordine corretto.
# Define the path to your CSV file# You may have to make this path more specific to the location of your file.csv_path = "future-gc00-daily-prices.csv"# Read the CSV, parse 'Date' column as datetime, and set it as the indexdata = pd.read_csv( csv_path, parse_dates=["Date"], dayfirst=False, index_col="Date")# Sort the DataFrame by the Date index in ascending orderdata.sort_index(inplace=True)Il nostro dataset è abbastanza pulito, ma in altri contesti dovremmo gestire problemi di indicizzazione, aspetto importante nelle previsioni per serie temporali. Ad esempio, se stiamo prevedendo il valore di chiusura di un titolo su una determinata borsa, dobbiamo considerare che il mercato azionario è chiuso nei weekend.
Prima di proseguire, faccio anche un rapido passaggio per rimuovere le virgole dalla variabile Close, che è quella che userò.
# Clean the "Close" columndata["Close"] = data["Close"].replace(',', '', regex=True)data["Close"] = pd.to_numeric(data["Close"], errors='coerce')data["Close"].replace([np.inf, -np.inf], np.nan, inplace=True)data.dropna(subset=["Close"], inplace=True)Come parte del preprocessing, spesso dobbiamo anche considerare come gestire i valori mancanti usando un metodo di imputazione come il forward fill o la sostituzione con la media. Sappi che anche un solo valore NA, a seconda del linguaggio e della libreria utilizzati, può impedire l'esecuzione di un ARIMA.
Avevo accennato che i giorni del weekend potrebbero essere riconosciuti come NA. Può capitare e richiederebbe un passaggio aggiuntivo. Per fortuna, statsmodels tratta i dati come un indice sequenziale senza imporre rigidamente intervalli temporali regolari, consentendo al nostro modello di compilare anche con i buchi del weekend.
Ora è un buon momento per creare un grafico nel tempo, così possiamo vedere la serie con cui stiamo lavorando:
# Plotting the original Close priceplt.figure(figsize=(14, 7))plt.plot(data.index, data["Close"], label='Close Price')plt.title('Close Price Over Time')plt.xlabel('Date')plt.ylabel('Close Price')plt.legend()plt.show()
Sebbene i modelli ARIMA possano gestire in parte la non stazionarietà, non riescono a tener conto in modo efficace di varianze che variano nel tempo. In altre parole, perché un ARIMA funzioni davvero, i dati devono essere stazionari.
Osservando il grafico sopra, vediamo che i dati non sono stazionari perché c'è un trend evidente. Inoltre, sembra esserci varianza non costante in momenti diversi. Possiamo usare il test di Dickey-Fuller aumentato per verificare questa intuizione e vedere se i nostri dati hanno media e varianza costanti, dando dei numeri alla questione.
# Perform the Augmented Dickey-Fuller test on the original seriesresult_original = adfuller(data["Close"])print(f"ADF Statistic (Original): {result_original[0]:.4f}")print(f"p-value (Original): {result_original[1]:.4f}")if result_original[1] < 0.05: print("Interpretation: The original series is Stationary.\n")else: print("Interpretation: The original series is Non-Stationary.\n")# Apply first-order differencingdata['Close_Diff'] = data['Close'].diff()# Perform the Augmented Dickey-Fuller test on the differenced seriesresult_diff = adfuller(data["Close_Diff"].dropna())print(f"ADF Statistic (Differenced): {result_diff[0]:.4f}")print(f"p-value (Differenced): {result_diff[1]:.4f}")if result_diff[1] < 0.05: print("Interpretation: The differenced series is Stationary.")else: print("Interpretation: The differenced series is Non-Stationary.")ADF Statistic (Original): -1.4367p-value (Original): 0.5646Interpretation: The original series is Non-Stationary.ADF Statistic (Differenced): -19.1308p-value (Differenced): 0.0000Interpretation: The differenced series is Stationary.I risultati del nostro test di Dickey-Fuller aumentato indicano che la serie originale non è stazionaria, quindi usare un ARIMA out-of-the-box sui dati originali sarebbe un errore.
Il test ADF su una versione differenziata dei dati indica invece che la serie differenziata è stazionaria.
Una breve nota sulla differenziazione. Voglio prendermi il tempo di spiegarla, visto che sotto il cofano succedono parecchie cose. Per eseguire la differenziazione, sottraiamo ogni osservazione dalla precedente per ottenere una nuova serie temporale di prime differenze. (La nuova serie temporale ha ora un elemento in meno rispetto all'originale.) Se la serie differenziata non è ancora stazionaria, possiamo prendere una seconda differenza differenziando nuovamente la serie originale e possiamo continuare a differenziare finché non diventa stazionaria. L'ordine di differenziazione richiesto è il numero minimo di differenze necessario per ottenere una serie senza autocorrelazione.
Infine, non eseguire più differenziazioni del necessario, altrimenti potresti creare dinamiche spurie nei dati. Inoltre, se stessi facendo un modello ARIMA stagionale, cosa che non facciamo in questo tutorial, dovresti sempre considerare una differenziazione stagionale prima della prima differenza.
# Plotting the differenced Close priceplt.figure(figsize=(14, 7))plt.plot(data.index, data['Close_Diff'], label='Differenced Close Price', color='orange')plt.title('Differenced Close Price Over Time')plt.xlabel('Date')plt.ylabel('Differenced Close Price')plt.legend()plt.show()
Quando costruiamo un modello ARIMA, dobbiamo considerare i termini p, d e q che entrano nel nostro modello ARIMA.
Usiamo strumenti come ACF (Autocorrelation Function) e PACF (Partial Autocorrelation Function) per determinare i valori di p, d e q. Il numero di lag in cui l'ACF si tronca è q, e dove si tronca il PACF è p. Dobbiamo anche scegliere il valore appropriato per d creando una situazione in cui, dopo la differenziazione, i dati somiglino al rumore bianco. Per i nostri dati, scegliamo 1 sia per p che per q perché vediamo un picco significativo al primo lag per entrambi.
from statsmodels.graphics.tsaplots import plot_acf, plot_pacfimport matplotlib.pyplot as plt# Plot ACF and PACF for the differenced seriesfig, axes = plt.subplots(1, 2, figsize=(16, 4))# ACF plotplot_acf(data['Close_Diff'].dropna(), lags=40, ax=axes[0])axes[0].set_title('Autocorrelation Function (ACF)')# PACF plotplot_pacf(data['Close_Diff'].dropna(), lags=40, ax=axes[1])axes[1].set_title('Partial Autocorrelation Function (PACF)')plt.tight_layout()plt.show()
Per chiarezza, i valori p, d e q in ARIMA rappresentano l'ordine del modello (lag per l'autoregressione, differenziazione e termini di media mobile), ma non sono i parametri effettivamente stimati. Una volta scelti i valori di p, d e q, il modello stima ulteriori parametri, come i coefficienti per i termini AR e MA, tramite massima verosimiglianza (MLE).
Per fare previsioni con un modello ARIMA, inizia usando il modello addestrato per prevedere i valori futuri sulla base dei dati. Una volta ottenute le previsioni, è utile visualizzarle tracciando i valori previsti accanto ai valori reali. Questo si realizza perché usiamo un workflow train/test, in cui i dati sono suddivisi in set di training e di test. In questo modo possiamo vedere quanto bene il modello si comporta su dati mai visti. Se non ti è chiaro, segui il nostro corso Model Validation in Python, un'ottima risorsa per imparare nel dettaglio training e testing.
Il primo passo è suddividere i dati in versioni di training e di test.
# Split data into train and testtrain_size = int(len(data) * 0.8)train, test = data.iloc[:train_size], data.iloc[train_size:]# Fit ARIMA modemodel = ARIMA(train["Close"], order=(1,1,1))model_fit = model.fit()Il passo successivo è creare la previsione e ispezionarla visivamente. Possiamo vedere come si comporta rispetto alla versione di test dei nostri dati.
# Forecastforecast = model_fit.forecast(steps=len(test))# Plot the results with specified colorsplt.figure(figsize=(14,7))plt.plot(train.index, train["Close"], label='Train', color='#203147')plt.plot(test.index, test["Close"], label='Test', color='#01ef63')plt.plot(test.index, forecast, label='Forecast', color='orange')plt.title('Close Price Forecast')plt.xlabel('Date')plt.ylabel('Close Price')plt.legend()plt.show()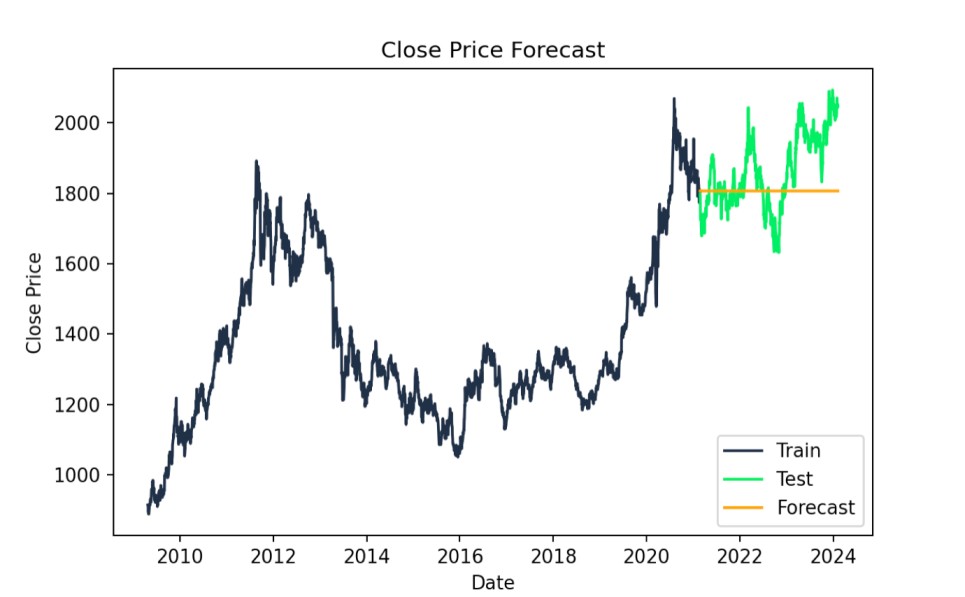
ARIMA: valori reali vs. previsti. Immagine dell'autore
Esaminiamo le statistiche AIC e BIC del modello. Valori più bassi indicano un miglior fit, ma potremmo anche confrontare i risultati con quelli di modelli più semplici per evitare l'overfitting. Stampo i numeri qui, ma hanno più senso nel contesto del confronto con altri modelli ARIMA sugli stessi dati, per trovare quello che funziona meglio.
print(f"AIC: {model_fit.aic}")print(f"BIC: {model_fit.bic}")AIC: 24602.97426066606BIC: 24620.97128230579Possiamo anche valutare l'errore quadratico medio per giudicare il fit del modello. È una metrica pratica. Un RMSE più basso indica un modello ARIMA migliore, riflettendo differenze minori tra valori reali e previsti, ed è sulla stessa scala dei dati. Ovvero, l'RMSE di 118,5339 significa che, in media, le previsioni del modello si discostano dai prezzi di Close reali di circa 118,53 $.
forecast = forecast[:len(test)]test_close = test["Close"][:len(forecast)]# Calculate RMSErmse = np.sqrt(mean_squared_error(test_close, forecast))print(f"RMSE: {rmse:.4f}")RMSE: 118.5339Impara con DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

