
Cursus
Financiële forecasting in Python
4 Hr
13.2K
Laten we ARIMA bekijken, een van de populairste (zo niet dé populairste) technieken voor tijdreeksvoorspellingen. ARIMA is populair omdat het tijdreeksgegevens effectief modelleert door zowel de autoregressieve (AR) als de voortschrijdend‑gemiddelde (MA) componenten vast te leggen, en niet‑stationariteit aan te pakken via differencing (I). Deze combinatie maakt ARIMA‑modellen bijzonder flexibel; daarom worden ze gebruikt in uiteenlopende domeinen, zoals financiën en weersvoorspelling.
ARIMA‑modellen zijn behoorlijk technisch, maar ik breek de onderdelen op zodat je een goed begrip kunt opbouwen. Voor we beginnen, is het handig om je bekend te maken met wat basisgereedschap. DataCamp biedt veel goede bronnen, zoals onze cursussen ARIMA Models in Python of ARIMA Models in R. Je kunt kiezen op basis van de taal die je verkiest.
In financiën, economie en milieuwetenschappen, enzovoort, is er veel interesse in ARIMA omdat het complexe patronen in onze historische observaties kan identificeren en vertalen naar toekomstige behoeften, wat het een state‑of‑the‑art techniek maakt. Van het voorspellen van aandelenkoersen en weerspatronen tot het inschatten van consumentenvraag: ARIMA is een sterke manier om nauwkeurige en bruikbare voorspellende analyses te maken.
Met ARIMA kunnen we tijdreeksgegevens zowel analyseren als voorspellen op een geavanceerde manier die rekening houdt met patronen, trends en seizoensinvloeden. Dit biedt een 360‑gradenblik op de onderliggende dynamiek voor onderbouwde beslissingen.
Om ARIMA echt te begrijpen, moeten we de bouwstenen ervan ontleden. Als we de componenten eenmaal doorhebben, wordt het makkelijker om te begrijpen hoe deze methode voor tijdreeksvoorspelling als geheel werkt. Hier geef ik een duidelijke uitleg van elke component.
De autoregressieve (AR) component bouwt een trend op basis van eerdere waarden binnen het AR‑kader voor voorspellende modellen. Ter verduidelijking: het ‘autoregressiekader’ werkt als een regressiemodel waarbij je de vertragingen van de eigen vroegere waarden van de tijdreeks als regressoren gebruikt.
Het geïntegreerde (I) deel omvat het differencen van de tijdreeks, met in het achterhoofd dat onze tijdreeks stationair moet zijn, wat in feite betekent dat het gemiddelde en de variantie in de tijd constant blijven. In wezen trekken we de ene observatie van de andere af zodat trends en seizoensinvloeden worden geëlimineerd. Door te differencen krijgen we stationariteit. Deze stap is nodig omdat het het model helpt de data te fitten en niet de ruis.
De moving‑average (MA) component richt zich op de relatie tussen een observatie en een residuele fout. Door te kijken hoe de huidige observatie samenhangt met eerdere fouten, kunnen we nuttige informatie afleiden over eventuele trends in onze data.
We kunnen de residuen zien als een van deze fouten, en het moving‑averagemodel schat of houdt rekening met hun impact op onze meest recente observatie. Dit is vooral nuttig om kortetermijnschommelingen of willekeurige schokken in de data te volgen en op te vangen. In het (MA) deel van een tijdreeks krijgen we waardevolle informatie over het gedrag ervan, wat ons op zijn beurt in staat stelt nauwkeuriger te voorspellen.
Om een ARIMA‑model voor voorspellingen te bouwen, bijvoorbeeld goudprijzen, kun je deze stappen volgen. Laten we het samen uitsplitsen.
De eerste stap is een geschikt dataset klaarzetten en onze omgeving voorbereiden.
Verzamel of zoek een dataset op datasource‑platforms. Je wilt er een met historische gegevens in de tijd. Hier is een link naar de Kaggle‑dataset met goudfuturesprijzen.
We installeren de benodigde pakketten, waaronder statsmodels en sklearn.
import pandas as pdimport matplotlib.pyplot as pltfrom statsmodels.tsa.stattools import adfullerfrom statsmodels.graphics.tsaplots import plot_acf, plot_pacffrom statsmodels.tsa.arima.model import ARIMAfrom sklearn.metrics import mean_squared_errorWe lezen de data vervolgens in onze lokale omgeving in. Ik neem de extra stap om zeker te zijn dat de datums in de juiste volgorde worden herkend.
# Define the path to your CSV file# You may have to make this path more specific to the location of your file.csv_path = "future-gc00-daily-prices.csv"# Read the CSV, parse 'Date' column as datetime, and set it as the indexdata = pd.read_csv( csv_path, parse_dates=["Date"], dayfirst=False, index_col="Date")# Sort the DataFrame by the Date index in ascending orderdata.sort_index(inplace=True)Onze dataset is vrij schoon, maar in andere contexten zouden we indexeringsproblemen moeten aanpakken, wat belangrijk is bij tijdreeksvoorspellingen. Als we bijvoorbeeld de slotkoers van een aandeel op een bepaalde beurs voorspellen, moeten we er rekening mee houden dat de beurs in het weekend niet open is.
Voor we doorgaan, neem ik ook snel de stap om komma’s te verwijderen uit de variabele Close, die ik ga gebruiken.
# Clean the "Close" columndata["Close"] = data["Close"].replace(',', '', regex=True)data["Close"] = pd.to_numeric(data["Close"], errors='coerce')data["Close"].replace([np.inf, -np.inf], np.nan, inplace=True)data.dropna(subset=["Close"], inplace=True)Als onderdeel van preprocessing moeten we vaak ook omgaan met ontbrekende waarden met een imputatiemethode zoals forward fill of gemiddeldevervanging. Weet dat zelfs één NA‑waarde, afhankelijk van de programmeertaal en bibliotheek die je gebruikt, kan voorkomen dat een ARIMA draait.
Ik had genoemd dat weekenddagen als NA kunnen worden herkend. Dat kan inderdaad, en zou een extra stap vereisen. Gelukkig behandelt statsmodels de data als een sequentiële index zonder strikt regelmatige tijdsintervallen af te dwingen, waardoor ons model zelfs met weekendgaten kan compileren.
Dit is een goed moment om een tijdplot te maken, zodat we de reeks kunnen zien waarmee we werken:
# Plotting the original Close priceplt.figure(figsize=(14, 7))plt.plot(data.index, data["Close"], label='Close Price')plt.title('Close Price Over Time')plt.xlabel('Date')plt.ylabel('Close Price')plt.legend()plt.show()
Hoewel ARIMA‑modellen tot op zekere hoogte met niet‑stationariteit kunnen omgaan, kunnen ze tijdsvariërende variantie niet effectief opvangen. Met andere woorden: opdat een ARIMA‑model echt werkt, moet de data stationair zijn.
Kijkend naar de plot hierboven zien we dat de data inderdaad niet stationair is, omdat er een duidelijke trend is. Ook lijkt er niet‑constante variantie op verschillende tijdstippen. We kunnen de Augmented Dickey‑Fuller‑test gebruiken om onze intuïtie te toetsen en te zien of onze data een constant gemiddelde en constante variantie heeft, en daar getallen aan verbinden.
# Perform the Augmented Dickey-Fuller test on the original seriesresult_original = adfuller(data["Close"])print(f"ADF Statistic (Original): {result_original[0]:.4f}")print(f"p-value (Original): {result_original[1]:.4f}")if result_original[1] < 0.05: print("Interpretation: The original series is Stationary.\n")else: print("Interpretation: The original series is Non-Stationary.\n")# Apply first-order differencingdata['Close_Diff'] = data['Close'].diff()# Perform the Augmented Dickey-Fuller test on the differenced seriesresult_diff = adfuller(data["Close_Diff"].dropna())print(f"ADF Statistic (Differenced): {result_diff[0]:.4f}")print(f"p-value (Differenced): {result_diff[1]:.4f}")if result_diff[1] < 0.05: print("Interpretation: The differenced series is Stationary.")else: print("Interpretation: The differenced series is Non-Stationary.")ADF Statistic (Original): -1.4367p-value (Original): 0.5646Interpretation: The original series is Non-Stationary.ADF Statistic (Differenced): -19.1308p-value (Differenced): 0.0000Interpretation: The differenced series is Stationary.De resultaten van onze Augmented Dickey‑Fuller‑test geven aan dat onze oorspronkelijke reeks inderdaad niet stationair is, dus een ARIMA out‑of‑the‑box op de ruwe data gebruiken zou een fout zijn.
De ADF‑test op een gedifferentieerde versie van de data geeft echter aan dat die versie wel stationair is.
Een korte noot over differencing. Ik wil dit uitleggen, omdat er onder de motorkap veel gebeurt. Om te differencen, trekken we elke observatie van de vorige af om een nieuwe tijdreeks van eerste verschillen te krijgen. (De nieuwe tijdreeks is nu één element korter dan de oorspronkelijke.) Als de gedifferentieerde reeks nog steeds niet stationair is, kunnen we een tweede verschil nemen door de oorspronkelijke reeks nogmaals te differencen, en we kunnen doorgaan met differencen totdat de reeks uiteindelijk stationair wordt. De orde van differencen is het minimum aantal verschillen dat nodig is om een reeks zonder autocorrelatie te krijgen.
Tot slot wil ik zeggen: voer niet meer differencen uit dan nodig is, anders kun je valse dynamiek in je data creëren. En als je een seizoens‑ARIMA zou doen, wat we in deze tutorial niet doen, overweeg je altijd eerst een seizoensverschil vóór een eerste verschil.
# Plotting the differenced Close priceplt.figure(figsize=(14, 7))plt.plot(data.index, data['Close_Diff'], label='Differenced Close Price', color='orange')plt.title('Differenced Close Price Over Time')plt.xlabel('Date')plt.ylabel('Differenced Close Price')plt.legend()plt.show()
Wanneer we een ARIMA‑model bouwen, moeten we rekening houden met de termen p, d en q die in ons ARIMA‑model gaan.
We gebruiken tools zoals ACF (Autocorrelation Function) en PACF (Partial Autocorrelation Function) om de waarden van p, d en q te bepalen. Het aantal vertragingen waarbij ACF afkapt is q, en waar PACF afkapt is p. We moeten ook de juiste waarde voor d kiezen door, na differencen, de data te laten lijken op white noise. Voor onze data kiezen we 1 voor zowel p als q omdat we een significante piek zien in de eerste vertraging voor elk.
from statsmodels.graphics.tsaplots import plot_acf, plot_pacfimport matplotlib.pyplot as plt# Plot ACF and PACF for the differenced seriesfig, axes = plt.subplots(1, 2, figsize=(16, 4))# ACF plotplot_acf(data['Close_Diff'].dropna(), lags=40, ax=axes[0])axes[0].set_title('Autocorrelation Function (ACF)')# PACF plotplot_pacf(data['Close_Diff'].dropna(), lags=40, ax=axes[1])axes[1].set_title('Partial Autocorrelation Function (PACF)')plt.tight_layout()plt.show()
Voor de duidelijkheid: de waarden p, d en q in ARIMA vertegenwoordigen de orde van het model (vertragingen voor autoregressie, differencen en moving‑average termen), maar het zijn niet de daadwerkelijke parameters die worden geschat. Zodra de waarden p, d en q gekozen zijn, schat het model aanvullende parameters, zoals coëfficiënten voor de autoregressieve en moving‑average termen, via maximum likelihood‑schatting (MLE).
Om met een ARIMA‑model te voorspellen, begin je met het gebruikte, gefitte model om toekomstige waarden te voorspellen op basis van de data. Nadat voorspellingen zijn gemaakt, is het handig om ze te visualiseren door de voorspelde waarden naast de werkelijke waarden te plotten. Dit doen we met een train/test‑workflow, waarbij de data wordt gesplitst in trainings‑ en testsets. Zo kunnen we zien hoe goed het model presteert op niet‑geziene data. Als dit niet helder is, volg dan onze cursus Model Validation in Python, een geweldige bron om de finesses van trainen en testen te leren.
Onze eerste stap is de data splitsen in trainings‑ en testversies.
# Split data into train and testtrain_size = int(len(data) * 0.8)train, test = data.iloc[:train_size], data.iloc[train_size:]# Fit ARIMA modelmodel = ARIMA(train["Close"], order=(1,1,1))model_fit = model.fit()Onze volgende stap is onze forecast maken en die ook visueel inspecteren. We kunnen zien hoe onze voorspelling presteert tegen de testversie van onze data.
# Forecastforecast = model_fit.forecast(steps=len(test))# Plot the results with specified colorsplt.figure(figsize=(14,7))plt.plot(train.index, train["Close"], label='Train', color='#203147')plt.plot(test.index, test["Close"], label='Test', color='#01ef63')plt.plot(test.index, forecast, label='Forecast', color='orange')plt.title('Close Price Forecast')plt.xlabel('Date')plt.ylabel('Close Price')plt.legend()plt.show()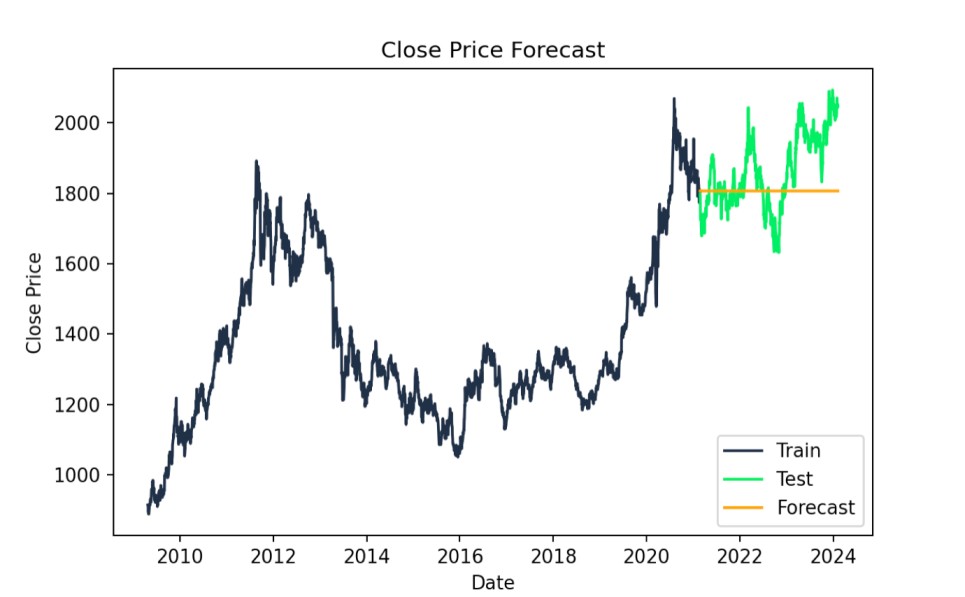
ARIMA‑voorspelling: werkelijke vs. voorspelde waarden. Afbeelding door de auteur
We bekijken de AIC‑ en BIC‑modelstatistieken. Lagere waarden betekenen een betere fit, maar we kunnen de resultaten ook vergelijken met die van eenvoudigere modellen om overfitting te vermijden. Ik print de cijfers hier, maar ze zijn het meest zinvol in de context van vergelijking met andere ARIMA‑modellen op dezelfde data, om zo het best werkende ARIMA‑model te vinden.
print(f"AIC: {model_fit.aic}")print(f"BIC: {model_fit.bic}")AIC: 24602.97426066606BIC: 24620.97128230579We kunnen ook de mean squared error evalueren om de fit van ons model te beoordelen. Dit is een praktische metriek. Een lagere RMSE duidt op een beter ARIMA‑model, met kleinere verschillen tussen werkelijke en voorspelde waarden, en het ligt op de schaal van de data. Dat wil zeggen: de RMSE van 118,5339 betekent dat onze modelvoorspellingen gemiddeld ongeveer $118,53 afwijken van de werkelijke Close‑prijzen.
forecast = forecast[:len(test)]test_close = test["Close"][:len(forecast)]# Calculate RMSErmse = np.sqrt(mean_squared_error(test_close, forecast))print(f"RMSE: {rmse:.4f}")RMSE: 118.5339Leren met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
