
Kursus
Python Tingkat Menengah
4 Hr
1.4M
Bayangkan Anda mencoba memetakan rute tercepat melalui sebuah labirin, mengidentifikasi koneksi antarorang di jejaring sosial, atau mencari cara paling efisien untuk mengirimkan data di internet. Tantangan-tantangan ini memiliki tujuan yang sama: mengeksplorasi hubungan antar titik secara sistematis. Breadth-first search adalah algoritma yang dapat membantu Anda melakukan hal tersebut.
Breadth-first search diterapkan pada berbagai masalah dalam data science, mulai dari penelusuran graf hingga pencarian jalur. Algoritma ini sangat berguna untuk menemukan jalur terpendek dalam graf tanpa bobot. Teruslah membaca karena saya akan membahas breadth-first search secara mendalam dan menunjukkan implementasinya di Python. Jika saat mulai Anda menginginkan bantuan lebih lanjut dalam Python, ikuti kursus Introduction to Python kami yang sangat komprehensif.
Breadth-first search (BFS) adalah algoritma penelusuran graf yang menjelajahi graf atau pohon per tingkat (level). Dimulai dari sebuah simpul sumber, BFS mengunjungi semua tetangga terdekatnya sebelum beralih ke tingkat simpul berikutnya. Ini memastikan bahwa simpul pada kedalaman yang sama diproses sebelum melangkah lebih dalam. Karena itu, BFS berguna untuk masalah yang memerlukan pemeriksaan semua jalur yang mungkin secara terstruktur dan sistematis.
BFS berguna untuk menemukan jalur terpendek antar simpul, karena saat BFS pertama kali mencapai sebuah simpul, ia menggunakan rute terpendek. Hal ini membuat BFS bermanfaat untuk masalah seperti perutean jaringan, di mana tujuannya adalah menemukan rute paling efisien antara dua titik. Diagram di bawah ini menunjukkan penjelasan sederhana tentang bagaimana BFS menjelajahi sebuah pohon.
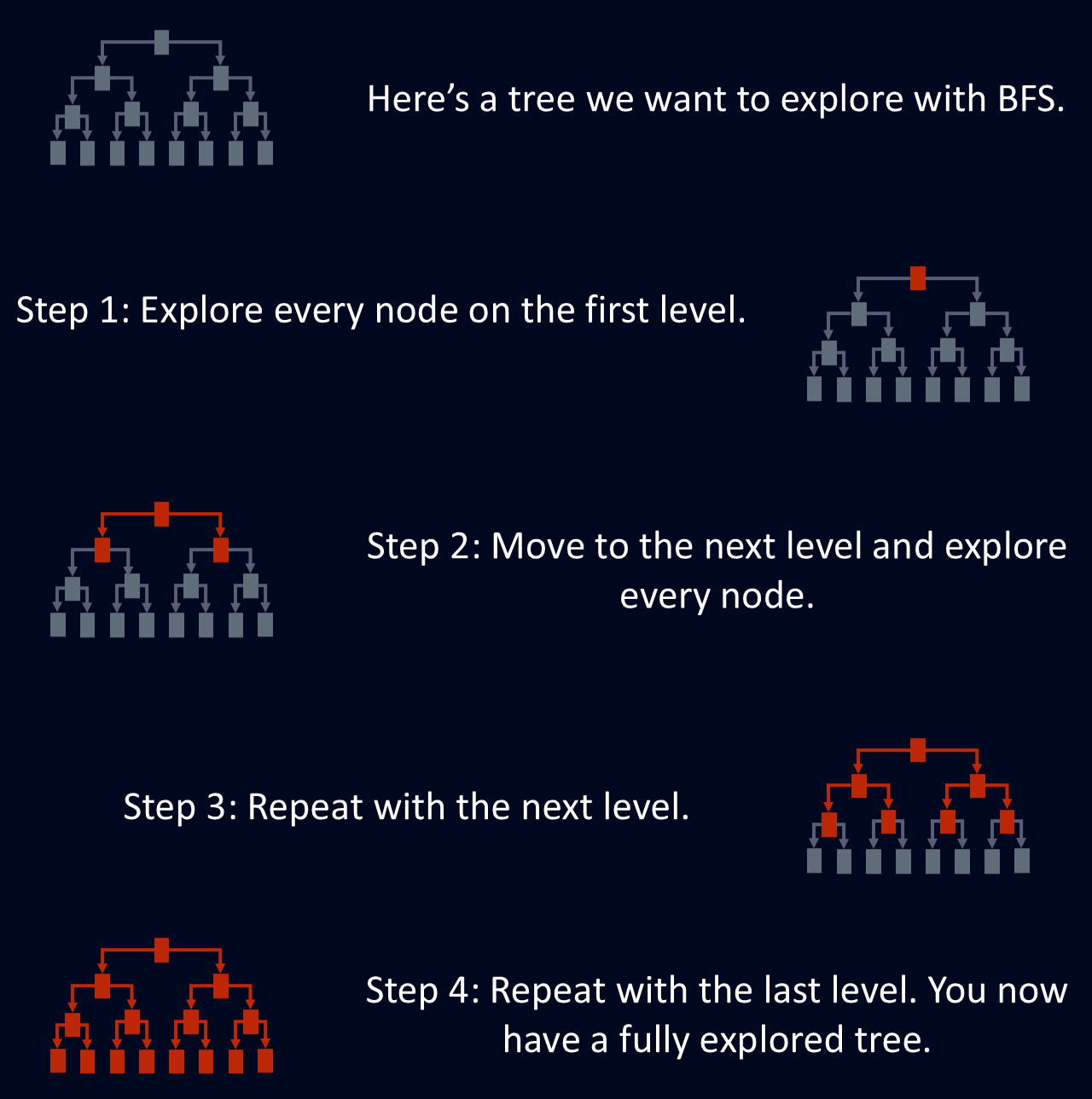
Breadth-first search dirancang untuk menjelajahi graf atau pohon dengan mengunjungi semua tetangga dari sebuah simpul sebelum melanjutkan ke lapisan berikutnya. Penelusuran terstruktur ini memastikan bahwa semua simpul pada kedalaman tertentu dieksplorasi sebelum bergerak lebih dalam ke dalam struktur. Pendekatan per tingkat ini menjadikan BFS cara yang sistematis dan andal untuk menavigasi jaringan yang kompleks.
BFS mengeksplorasi setiap simpul pada tingkat kedalaman saat ini sebelum beralih ke tingkat berikutnya. Artinya, semua simpul pada jarak tertentu dari titik awal diproses sebelum melangkah lebih dalam.
BFS menggunakan antrian untuk mengelola simpul yang perlu dikunjungi. Algoritma memproses satu simpul, menambahkan tetangga yang belum dikunjungi ke antrian, dan melanjutkan pola ini. Antrian beroperasi dengan prinsip first-in, first-out, memastikan simpul dieksplorasi sesuai urutan ditemukannya.
Dalam graf tanpa bobot, atau graf di mana setiap tautan memiliki panjang yang sama, BFS menjamin penemuan jalur terpendek antar simpul. Karena BFS mengeksplorasi tetangga per tingkat, saat pertama kali mencapai sebuah simpul, itu terjadi melalui rute terpendek yang mungkin. Ini membuat BFS sangat efektif untuk memecahkan masalah jalur terpendek dalam situasi di mana semua sisi (edge) memiliki bobot yang sama.
BFS bekerja pada graf maupun pohon. Graf adalah jaringan simpul yang terhubung dan dapat memiliki siklus, seperti jejaring sosial, sedangkan pohon adalah hierarki dengan satu akar dan tanpa siklus, seperti silsilah. BFS berguna untuk keduanya, sehingga penerapannya luas pada berbagai tugas.
Mari demonstrasikan algoritma breadth-first search pada sebuah pohon di Python. Jika Anda perlu menyegarkan keterampilan Python, lihat jalur keterampilan Python Programming di DataCamp. Untuk informasi lebih lanjut tentang berbagai struktur data dan algoritma, ikuti kursus Data Structures and Algorithms in Python kami dan baca tutorial Data Structures: A Comprehensive Guide With Python Examples.
Mari mulai. Pertama, kita perlu menyiapkan pohon keputusan sederhana untuk ditelusuri oleh BFS.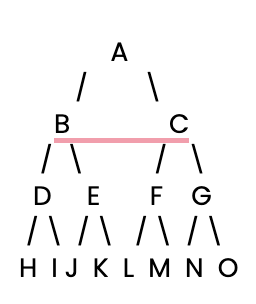
Selanjutnya, kita akan mendefinisikan pohon keputusan sederhana ini menggunakan dictionary Python, di mana setiap key adalah sebuah simpul, dan nilainya adalah daftar anak dari simpul tersebut.
# Define the decision tree as a dictionary
tree = {
'A': ['B', 'C'], # Node A connects to B and C
'B': ['D', 'E'], # Node B connects to D and E
'C': ['F', 'G'], # Node C connects to F and G
'D': ['H', 'I'], # Node D connects to H and I
'E': ['J', 'K'], # Node E connects to J and K
'F': ['L', 'M'], # Node F connects to L and M
'G': ['N', 'O'], # Node G connects to N and O
'H': [], 'I': [], 'J': [], 'K': [], # Leaf nodes have no children
'L': [], 'M': [], 'N': [], 'O': [] # Leaf nodes have no children
}Sekarang mari kita implementasikan algoritma BFS di Python. BFS bekerja dengan mengunjungi semua simpul pada tingkat saat ini sebelum beralih ke tingkat berikutnya. Kita akan menggunakan antrian untuk mengelola simpul mana yang akan dikunjungi berikutnya.
from collections import deque # Import deque for efficient queue operations
# Define the BFS function
def bfs(tree, start):
visited = [] # List to keep track of visited nodes
queue = deque([start]) # Initialize the queue with the starting node
while queue: # While there are still nodes to process
node = queue.popleft() # Dequeue a node from the front of the queue
if node not in visited: # Check if the node has been visited
visited.append(node) # Mark the node as visited
print(node, end=" ") # Output the visited node
# Enqueue all unvisited neighbors (children) of the current node
for neighbor in tree[node]:
if neighbor not in visited:
queue.append(neighbor) # Add unvisited neighbors to the queueSekarang kita telah membuat fungsi BFS, kita dapat menjalankannya pada pohon, dimulai dari simpul akar A.
# Execute BFS starting from node 'A'
bfs(tree, 'A')Saat dijalankan, ini menampilkan setiap simpul sesuai urutan kunjungannya.
A B C D E F G H I J K L M N OPola penelusuran BFS pada pohon bersifat langsung, karena secara bawaan tidak memiliki siklus. Algoritma dimulai di akar dan mengunjungi semua anak sebelum beralih ke tingkat berikutnya. Penelusuran level-order ini mencerminkan hubungan hierarkis pada pohon: setiap simpul memiliki satu induk dan beberapa anak, sehingga menghasilkan pola yang dapat diprediksi.
Sebaliknya, graf dapat mengandung siklus. Banyak jalur antar simpul dapat kembali ke simpul yang sudah dikunjungi. Ini bisa menjadi masalah bagi BFS, sehingga memerlukan pengelolaan kunjungan ulang dengan cermat. Melacak simpul yang sudah dikunjungi mencegah pemrosesan ulang yang tidak perlu dan membantu menghindari siklus yang dapat menyebabkan loop. Dalam implementasi BFS sebelumnya, kita menggunakan daftar visited untuk memastikan setiap simpul hanya diproses sekali. Jika ditemui simpul yang sudah dikunjungi, simpul tersebut dilewati, sehingga BFS dapat terus berjalan dengan lancar.
Seberapa efisien breadth-first search? Kita dapat menggunakan notasi Big O untuk mengevaluasi bagaimana efisiensi BFS berubah sebagai fungsi dari ukuran graf.
Kompleksitas waktu BFS adalah O(V+E), di mana V adalah jumlah verteks (simpul) dan E adalah jumlah sisi pada graf. Ini berarti kinerja BFS bergantung pada jumlah simpul dan koneksi di antaranya.
Kompleksitas ruang BFS adalah O(V) karena memori yang dibutuhkan untuk menyimpan simpul dalam antrian. Pada graf yang lebar, ini dapat berarti menyimpan banyak simpul sekaligus. Pada kasus terburuk, bisa berarti menahan semua simpul sekaligus.
Breadth-first search memiliki banyak aplikasi praktis di bidang seperti ilmu komputer, jaringan, dan kecerdasan buatan. Eksplorasinya yang metodis per tingkat membuatnya ideal untuk pencarian dan masalah pencarian jalur.
Salah satu penerapan BFS adalah dalam algoritma perutean jaringan. Saat paket data melintasi jaringan, router menggunakan BFS untuk menemukan jalur terpendek. Dengan mengeksplorasi semua simpul tetangga sebelum bergerak lebih dalam, BFS dengan cepat mengidentifikasi rute yang efisien, meminimalkan latensi dan meningkatkan kinerja.
BFS juga berguna untuk memecahkan teka-teki, seperti labirin atau puzzle geser. Setiap posisi adalah simpul, dan koneksi adalah sisi. BFS dapat secara efisien menemukan jalur terpendek dari awal hingga keluar.
Penggunaan kuat lainnya adalah dalam analisis jejaring sosial. BFS membantu menemukan hubungan antar pengguna dan mengidentifikasi simpul berpengaruh. Algoritma ini dapat mengeksplorasi koneksi sosial dan menemukan klaster pengguna terkait, mengungkap wawasan tentang struktur jaringan.
BFS juga berguna dalam pelatihan AI. Misalnya, algoritma ini dapat digunakan untuk mencari status permainan pada gim seperti catur. Algoritma AI dapat menggunakan BFS untuk mengeksplorasi kemungkinan langkah per tingkat, mengevaluasi keadaan masa depan untuk menentukan tindakan terbaik, sehingga menemukan jalur terpendek menuju kemenangan.
BFS juga diterapkan pada robotika untuk perencanaan jalur. Algoritma ini memungkinkan robot menavigasi lingkungan yang kompleks dengan memetakan sekitar dan menemukan jalur sambil menghindari rintangan.
Mari bandingkan BFS dengan algoritma pencarian umum lainnya, seperti depth-first search dan algoritma Dijkstra.
Breadth-first search dan depth-first search (DFS) sama-sama algoritma penelusuran graf, tetapi cara menjelajahnya berbeda. BFS mengunjungi semua tetangga pada kedalaman saat ini sebelum bergerak lebih dalam, sementara DFS menelusuri sedalam mungkin pada satu jalur sebelum mundur (backtracking).
BFS sangat baik untuk menemukan jalur terpendek dalam graf tanpa bobot. Keunggulan ini membuatnya cocok untuk masalah seperti navigasi labirin dan jaringan. Sebaliknya, DFS mungkin tidak selalu menemukan jalur terpendek, tetapi dapat lebih efisien dalam penggunaan ruang pada graf yang dalam dan lebar. Hal ini membuatnya lebih disukai untuk tugas seperti topological sorting atau penjadwalan, di mana penelusuran lengkap diperlukan tanpa penggunaan memori berlebih.
Algoritma Dijkstra adalah algoritma penelusuran graf yang dirancang untuk graf berbobot, di mana sisi memiliki biaya bervariasi. Tidak seperti BFS, yang memperlakukan semua sisi secara setara, Dijkstra menghitung jalur terpendek berdasarkan bobot sisi. Algoritma ini paling berguna untuk aplikasi yang memerhatikan biaya, seperti mencari rute optimal dengan mempertimbangkan waktu tempuh.
Walaupun Dijkstra kuat untuk graf berbobot, algoritma ini lebih kompleks dan intensif secara komputasi. Dijkstra memiliki kompleksitas waktu O((V+E)logV) saat menggunakan priority queue, yang secara signifikan lebih tinggi daripada kompleksitas waktu BFS O(V+E). Anda dapat mempelajari lebih lanjut tentang Algoritma Dijkstra di Implementing the Dijkstra Algorithm in Python: A Step-by-Step Tutorial.
Salah satu masalah yang mungkin Anda temui saat menggunakan BFS adalah terjebak dalam sebuah siklus. Siklus terjadi ketika suatu jalur kembali ke simpul yang sudah dikunjungi, menciptakan loop dalam penelusuran. Jika BFS tidak melacak simpul yang dikunjungi dengan benar, ini dapat menyebabkan loop tak berujung. Penting untuk mempertahankan daftar simpul yang dikunjungi atau menandai setiap simpul sebagai telah dieksplorasi setelah diproses. Pendekatan sederhana ini akan memastikan BFS Anda menjelajahi graf secara efisien dan berakhir dengan benar.
Kendala umum lainnya adalah penggunaan antrian yang tidak tepat. BFS bergantung pada antrian untuk melacak simpul mana yang perlu dieksplorasi. Jika antrian tidak dikelola dengan benar, hal ini dapat mengakibatkan simpul terlewat atau jalur yang tidak benar dalam penelusuran. Untuk menghindarinya, tambahkan simpul ke antrian sesuai urutan yang perlu dieksplorasi lalu keluarkan. Ini membantu BFS mengeksplorasi simpul per tingkat, sesuai yang dimaksudkan. Menggunakan struktur data yang andal, seperti collections.deque di Python, sangat membantu.
Meski serbaguna, BFS bukanlah pilihan terbaik di setiap situasi. Misalnya, BFS tidak selalu cocok untuk graf yang sangat besar atau dalam, di mana depth-first search mungkin lebih praktis. Selain itu, BFS tidak sesuai untuk graf berbobot, karena BFS memperlakukan semua sisi secara sama. Algoritma seperti Dijkstra atau A* lebih cocok untuk kasus ini, karena memperhitungkan biaya yang bervariasi saat menghitung jalur terpendek.
BFS sangat berharga untuk menemukan jalur terpendek dalam graf tanpa bobot. Eksplorasinya per tingkat menjadikannya alat yang sangat baik untuk situasi yang memerlukan penelusuran menyeluruh terhadap simpul pada setiap tingkat kedalaman.
Jika Anda tertarik pada algoritma pencarian, pastikan untuk membaca artikel saya yang lain dalam seri ini, termasuk Binary Search in Python: A Complete Guide for Efficient Searching. Anda juga mungkin tertarik pada AVL Tree: Complete Guide With Python Implementation, dan Introduction to Network Analysis in Python.
Belajar Python bersama DataCamp
Kursus
Kursus
Kursus
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
