
Corso
Python - Livello Intermedio
4 h
1.4M
Immagina di voler tracciare il percorso più rapido attraverso un labirinto, identificare le connessioni tra le persone in un social network o trovare il modo più efficiente per trasmettere dati su internet. Queste sfide condividono un obiettivo comune: esplorare in modo sistematico le relazioni tra punti diversi. Il breadth-first search è un algoritmo che può aiutarti proprio in questo.
Il breadth-first search viene applicato a un'ampia gamma di problemi in data science, dalla visita dei grafi alla ricerca di percorsi. È particolarmente utile per trovare il percorso più breve in grafi non pesati. Continua a leggere: spiegherò nel dettaglio il breadth-first search e mostrerò un'implementazione in Python. Se, man mano che iniziamo, vuoi più aiuto con Python, iscriviti al nostro corso molto completo Introduction to Python.
Il breadth-first search (BFS) è un algoritmo di attraversamento di grafi che esplora un grafo o un albero livello per livello. Partendo da un nodo sorgente specificato, il BFS visita tutti i suoi vicini immediati prima di passare al livello successivo di nodi. In questo modo, i nodi alla stessa profondità vengono elaborati prima di scendere più in profondità. Per questo motivo, il BFS è utile per problemi che richiedono di esaminare tutti i possibili percorsi in modo strutturato e sistematico.
Il BFS è utile per trovare il percorso più breve tra nodi, perché la prima volta che raggiunge un nodo, lo fa usando la rotta più corta. Ciò rende il BFS utile per problemi come l'instradamento di rete, dove l'obiettivo è trovare la rotta più efficiente tra due punti. Il diagramma qui sotto mostra una spiegazione semplificata di come il BFS esplora un albero.
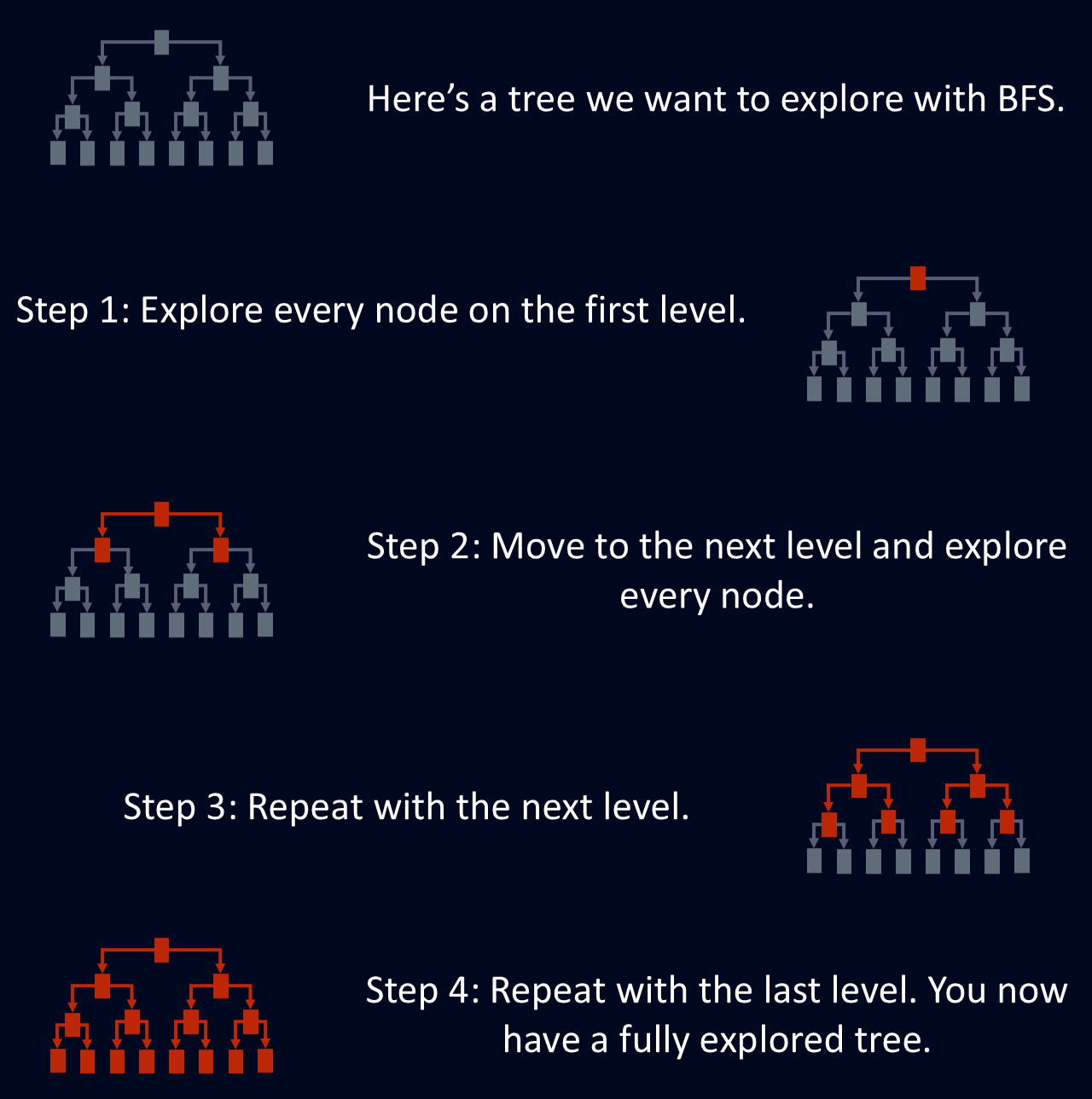
Il breadth-first search è progettato per esplorare un grafo o un albero visitando tutti i vicini di un nodo prima di passare allo strato successivo. Questo attraversamento strutturato garantisce che tutti i nodi a una certa profondità vengano esplorati prima di scendere più in profondità nella struttura. Questo approccio livello per livello rende il BFS un modo sistematico e affidabile per navigare in reti complesse.
Il BFS esplora ogni nodo all'attuale livello di profondità prima di passare al successivo. Ciò significa che tutti i nodi a una data distanza dal punto di partenza vengono elaborati prima di scendere più in profondità.
Il BFS utilizza una coda per gestire i nodi da visitare. L'algoritmo elabora un nodo, aggiunge i suoi vicini non visitati alla coda e continua secondo questo schema. La coda opera in modalità first-in, first-out, assicurando che i nodi vengano esplorati nell'ordine in cui sono stati scoperti.
Nei grafi non pesati, o nei grafi in cui ogni collegamento ha la stessa lunghezza, il BFS garantisce di trovare il percorso più breve tra i nodi. Poiché il BFS esplora i vicini livello per livello, la prima volta che raggiunge un nodo lo fa attraverso la rotta più breve possibile. Questo rende il BFS particolarmente efficace per risolvere problemi di percorso più breve, nelle situazioni in cui tutti gli archi hanno uguale peso.
Il BFS funziona sia con i grafi sia con gli alberi. Un grafo è una rete di nodi connessi che può avere cicli, come un social network, mentre un albero è una gerarchia con una radice e senza cicli, come un albero genealogico. Il BFS è utile in entrambi i casi, risultando ampiamente applicabile a una vasta gamma di attività.
Dimostriamo l'algoritmo breadth-first search su un albero in Python. Se hai bisogno di ripassare le tue competenze in Python, dai un'occhiata al percorso di abilità Python Programming su DataCamp. Per ulteriori informazioni su diverse strutture dati e algoritmi, segui il nostro corso Data Structures and Algorithms in Python e leggi il tutorial Data Structures: A Comprehensive Guide With Python Examples.
Iniziamo. Per prima cosa, dobbiamo impostare un semplice albero decisionale da esplorare con il nostro BFS.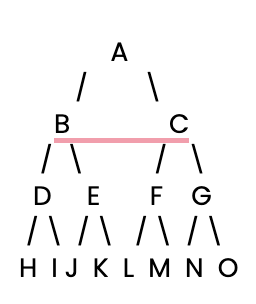
Successivamente, definiremo questo semplice albero decisionale usando un dizionario Python, in cui ogni chiave è un nodo e il suo valore è un elenco dei figli del nodo.
# Define the decision tree as a dictionary
tree = {
'A': ['B', 'C'], # Node A connects to B and C
'B': ['D', 'E'], # Node B connects to D and E
'C': ['F', 'G'], # Node C connects to F and G
'D': ['H', 'I'], # Node D connects to H and I
'E': ['J', 'K'], # Node E connects to J and K
'F': ['L', 'M'], # Node F connects to L and M
'G': ['N', 'O'], # Node G connects to N and O
'H': [], 'I': [], 'J': [], 'K': [], # Leaf nodes have no children
'L': [], 'M': [], 'N': [], 'O': [] # Leaf nodes have no children
}Ora implementiamo l'algoritmo BFS in Python. Il BFS funziona visitando tutti i nodi al livello corrente prima di passare al livello successivo. Useremo una coda per gestire quali nodi visitare dopo.
from collections import deque # Import deque for efficient queue operations
# Define the BFS function
def bfs(tree, start):
visited = [] # List to keep track of visited nodes
queue = deque([start]) # Initialize the queue with the starting node
while queue: # While there are still nodes to process
node = queue.popleft() # Dequeue a node from the front of the queue
if node not in visited: # Check if the node has been visited
visited.append(node) # Mark the node as visited
print(node, end=" ") # Output the visited node
# Enqueue all unvisited neighbors (children) of the current node
for neighbor in tree[node]:
if neighbor not in visited:
queue.append(neighbor) # Add unvisited neighbors to the queueOra che abbiamo creato la nostra funzione BFS, possiamo eseguirla sull'albero, partendo dal nodo radice A.
# Execute BFS starting from node 'A'
bfs(tree, 'A')Quando lo eseguiamo, stampa ogni nodo nell'ordine in cui è stato visitato.
A B C D E F G H I J K L M N OIl pattern di attraversamento del BFS è lineare negli alberi, poiché sono intrinsecamente aciclici. L'algoritmo parte dalla radice e visita tutti i figli prima di passare al livello successivo. Questo attraversamento per livelli rispecchia le relazioni gerarchiche negli alberi: ogni nodo ha un genitore e più figli, portando a un andamento prevedibile.
Al contrario, i grafi possono contenere cicli. Più percorsi tra i nodi possono riportare a nodi già visitati. Questo può rappresentare un problema per il BFS, richiedendo una gestione attenta delle rivisitazioni. Tenere traccia dei nodi già visitati evita rielaborazioni non necessarie e aiuta a evitare cicli che potrebbero causare loop. Nella nostra precedente implementazione del BFS, abbiamo usato una lista dei visitati per garantire che ogni nodo fosse elaborato una sola volta. Se si incontrava un nodo già visitato, veniva saltato, permettendo al BFS di procedere senza intoppi.
Quanto è efficiente il breadth-first search? Possiamo usare la notazione Big O per valutare come l'efficienza del BFS cambia in funzione della dimensione del grafo.
La complessità temporale del BFS è O(V+E), dove V è il numero di vertici (nodi) ed E è il numero di archi nel grafo. Ciò significa che le prestazioni del BFS dipendono sia dal numero di nodi sia dalle connessioni tra di essi.
La complessità spaziale del BFS è O(V) a causa della memoria necessaria per memorizzare i nodi nella coda. Nei grafi più ampi, questo può significare conservare molti nodi contemporaneamente. Nel caso peggiore, potrebbe significare tenere tutti i nodi in una volta.
Il breadth-first search ha numerose applicazioni pratiche in campi come informatica, networking e intelligenza artificiale. La sua esplorazione metodica livello per livello lo rende ideale per problemi di ricerca e pathfinding.
Un'applicazione del BFS è negli algoritmi di routing di rete. Quando i pacchetti di dati attraversano una rete, i router utilizzano il BFS per trovare il percorso più breve. Esplorando tutti i nodi vicini prima di scendere in profondità, il BFS identifica rapidamente rotte efficienti, minimizzando la latenza e migliorando le prestazioni.
Il BFS è utile anche per risolvere puzzle, come labirinti o rompicapi a scorrimento. Ogni posizione è un nodo e le connessioni sono archi. Il BFS può trovare in modo efficiente il percorso più breve dall'inizio all'uscita.
Un altro uso potente è nell'analisi dei social network. Il BFS aiuta a scoprire relazioni tra utenti e a identificare nodi influenti. Può esplorare le connessioni sociali e individuare cluster di utenti correlati, rivelando insight sulle strutture di rete.
Il BFS è utile anche nell'addestramento dell'IA. Ad esempio, può essere utilizzato per esplorare gli stati di gioco in giochi come gli scacchi. Gli algoritmi di IA possono usare il BFS per esplorare le mosse possibili livello per livello, valutando stati futuri per determinare l'azione migliore, trovando così il percorso più breve verso la vittoria.
Il BFS è applicato anche alla robotica per la pianificazione dei percorsi. Consente ai robot di navigare in ambienti complessi mappando i dintorni e trovando percorsi evitando gli ostacoli.
Confrontiamo il BFS con altri algoritmi di ricerca comuni, come il depth-first search e l'algoritmo di Dijkstra.
Il breadth-first search e il depth-first search (DFS) sono entrambi algoritmi di attraversamento di grafi, ma esplorano i grafi in modo diverso. Il BFS visita tutti i vicini al livello di profondità corrente prima di scendere, mentre il DFS esplora quanto più possibile lungo un singolo percorso prima di tornare indietro.
Il BFS è ottimo per trovare il percorso più breve nei grafi non pesati. Questo vantaggio lo rende adatto a problemi come la navigazione nei labirinti e il networking. Al contrario, il DFS potrebbe non trovare sempre il percorso più breve, ma può essere più efficiente in termini di spazio in grafi profondi e ampi. Ciò lo rende preferibile per attività come l'ordinamento topologico o i problemi di schedulazione, dove è necessaria un'attraversamento completo senza un uso eccessivo di memoria.
L'algoritmo di Dijkstra è un algoritmo di attraversamento progettato per grafi pesati, in cui gli archi hanno costi variabili. A differenza del BFS, che tratta tutti gli archi allo stesso modo, Dijkstra calcola il percorso più breve in base ai pesi degli archi. È più utile per applicazioni in cui il costo conta, come trovare la rotta ottimale considerando il tempo di viaggio.
Sebbene Dijkstra sia potente per i grafi pesati, è più complesso e intensivo dal punto di vista computazionale. Dijkstra ha una complessità temporale di O((V+E)logV) quando si utilizzano code di priorità, significativamente superiore alla complessità temporale del BFS O(V+E). Puoi saperne di più sull'algoritmo di Dijkstra in Implementing the Dijkstra Algorithm in Python: A Step-by-Step Tutorial.
Un problema che potresti incontrare usando il BFS è rimanere intrappolato in un ciclo. Un ciclo si verifica quando un percorso ritorna a un nodo già visitato, creando un loop nell'attraversamento. Se il BFS non tiene traccia correttamente dei nodi visitati, ciò può portare a un ciclo infinito. È importante mantenere un elenco dei nodi visitati o contrassegnare ciascun nodo come esplorato una volta elaborato. Questo semplice approccio dovrebbe garantire che il tuo BFS esplori il grafo in modo efficiente e termini correttamente.
Un altro errore comune è l'uso scorretto della coda. Il BFS dipende da una coda per tenere traccia dei nodi da esplorare. Se la coda non è gestita correttamente, può comportare la perdita di nodi o percorsi errati nell'attraversamento. Per evitarlo, aggiungi i nodi alla coda nell'ordine in cui devono essere esplorati e poi rimuovili. Questo aiuta il BFS a esplorare i nodi livello per livello, come previsto. Usare una struttura dati affidabile, come collections.deque in Python, aiuta.
Nonostante la sua versatilità, il BFS non è la scelta migliore in ogni situazione. Per esempio, il BFS non è sempre adatto a grafi molto grandi o profondi, dove il depth-first search può essere più pratico. Inoltre, il BFS non è appropriato per i grafi pesati, perché tratta tutti gli archi allo stesso modo. Algoritmi come Dijkstra o A* sono più adatti in questi casi, poiché tengono conto dei costi variabili nel calcolare il percorso più breve.
Il BFS è particolarmente prezioso per trovare il percorso più breve nei grafi non pesati. La sua esplorazione per livelli lo rende uno strumento eccellente per situazioni che richiedono un'esplorazione approfondita dei nodi a ogni livello di profondità.
Se ti interessano gli algoritmi di ricerca, dai un'occhiata anche agli altri miei articoli di questa serie, tra cui: Binary Search in Python: A Complete Guide for Efficient Searching. Potrebbero interessarti anche AVL Tree: Complete Guide With Python Implementation e Introduction to Network Analysis in Python.
Impara Python con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

