
Courses
Python nâng cao
4 giờ
1.4M
Hãy tưởng tượng bạn đang cố vạch ra lộ trình nhanh nhất qua một mê cung, xác định các mối liên kết giữa mọi người trong một mạng xã hội, hoặc tìm cách truyền dữ liệu hiệu quả nhất trên internet. Những thách thức này có chung một mục tiêu: khám phá có hệ thống các mối quan hệ giữa các điểm khác nhau. Tìm kiếm theo chiều rộng là một thuật toán có thể giúp bạn làm điều đó.
Tìm kiếm theo chiều rộng được áp dụng cho nhiều bài toán trong khoa học dữ liệu, từ duyệt đồ thị đến tìm đường đi. Nó đặc biệt hữu ích để tìm đường đi ngắn nhất trong đồ thị không trọng số. Hãy tiếp tục đọc, tôi sẽ trình bày chi tiết về tìm kiếm theo chiều rộng và minh họa cách triển khai trong Python. Nếu ngay khi bắt đầu bạn muốn được hỗ trợ thêm về Python, hãy đăng ký khóa học Introduction to Python toàn diện của chúng tôi.
Tìm kiếm theo chiều rộng (BFS) là một thuật toán duyệt đồ thị khám phá đồ thị hoặc cây theo từng tầng. Bắt đầu từ một nút nguồn xác định, BFS sẽ thăm tất cả các nút kề ngay lập tức của nó trước khi chuyển sang tầng tiếp theo. Điều này đảm bảo các nút ở cùng độ sâu được xử lý trước khi đi sâu hơn. Nhờ vậy, BFS hữu ích cho các bài toán cần xem xét tất cả các đường đi khả dĩ theo cách có cấu trúc và hệ thống.
BFS hữu ích để tìm đường đi ngắn nhất giữa các nút, vì lần đầu tiên BFS đến một nút là thông qua lộ trình ngắn nhất. Điều này khiến BFS phù hợp với những vấn đề như định tuyến mạng, nơi mục tiêu là tìm tuyến đường hiệu quả nhất giữa hai điểm. Sơ đồ dưới đây minh họa đơn giản cách BFS khám phá một cây.
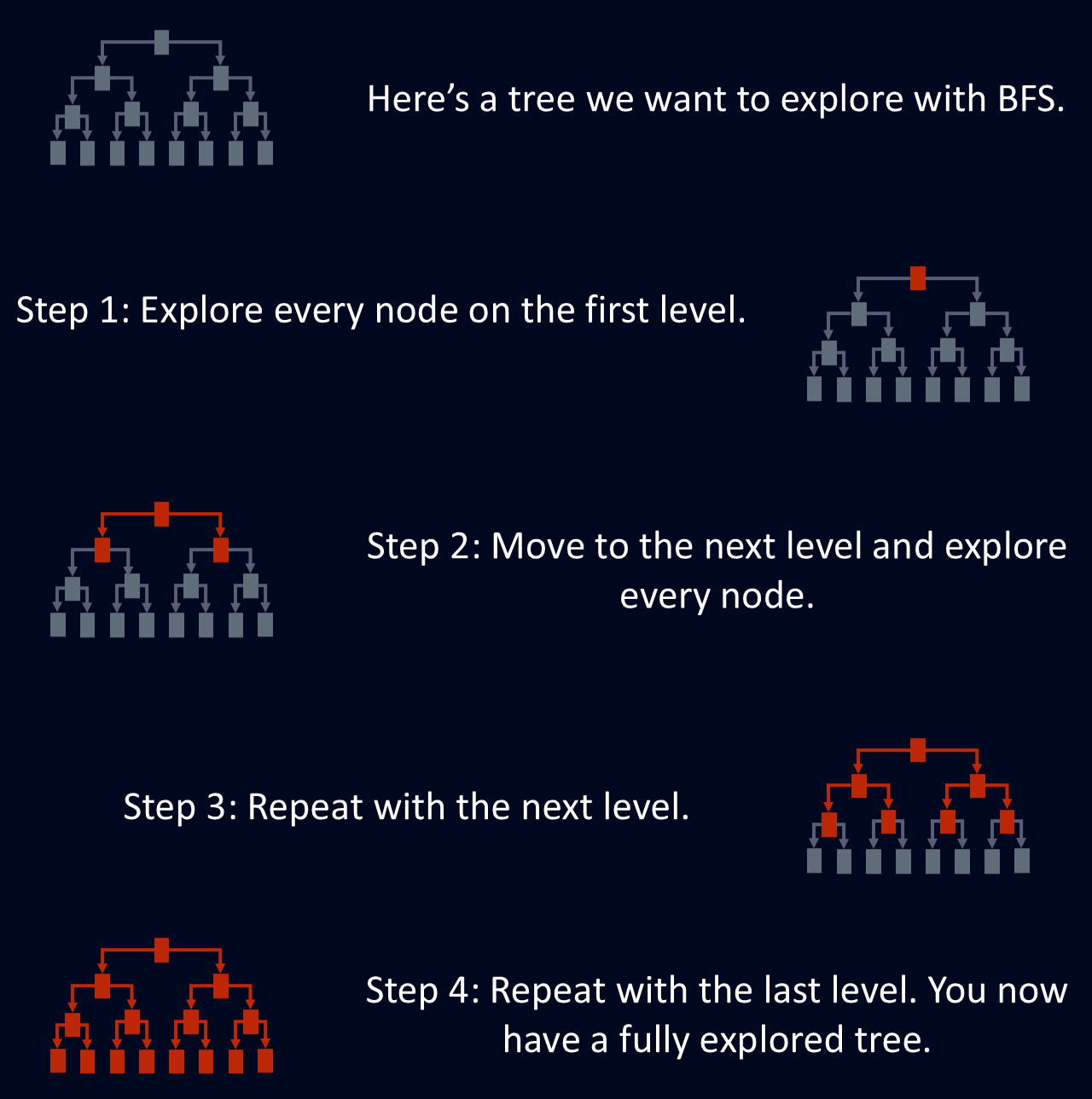
Tìm kiếm theo chiều rộng được thiết kế để khám phá một đồ thị hoặc cây bằng cách thăm tất cả các nút kề của một nút trước khi chuyển sang lớp tiếp theo. Cách duyệt có cấu trúc này đảm bảo rằng mọi nút ở một độ sâu nhất định đều được khám phá trước khi đi sâu hơn vào cấu trúc. Cách tiếp cận theo tầng khiến BFS trở thành phương pháp có hệ thống và đáng tin cậy để điều hướng các mạng phức tạp.
BFS khám phá từng nút ở độ sâu hiện tại trước khi chuyển sang tầng tiếp theo. Điều này có nghĩa là tất cả các nút ở một khoảng cách nhất định so với điểm bắt đầu sẽ được xử lý trước khi đi sâu hơn.
BFS sử dụng một hàng đợi để quản lý các nút cần được thăm. Thuật toán xử lý một nút, thêm các nút kề chưa thăm vào hàng đợi, và tiếp tục theo mô hình này. Hàng đợi hoạt động theo nguyên tắc vào trước ra trước, đảm bảo các nút được khám phá theo đúng thứ tự chúng được phát hiện.
Trong các đồ thị không trọng số, hoặc đồ thị mà mọi liên kết có độ dài như nhau, BFS đảm bảo tìm được đường đi ngắn nhất giữa các nút. Vì BFS khám phá các nút kề theo từng tầng, lần đầu nó đến một nút là thông qua lộ trình ngắn nhất có thể. Điều này khiến BFS đặc biệt hiệu quả để giải các bài toán đường đi ngắn nhất trong những tình huống mọi cạnh có trọng số bằng nhau.
BFS hoạt động với cả đồ thị và cây. Đồ thị là một mạng lưới các nút kết nối có thể có chu trình, như mạng xã hội, trong khi cây là một cấu trúc phân cấp với một gốc và không có chu trình, như phả hệ. BFS hữu ích cho cả hai, nên có thể áp dụng rộng rãi cho nhiều tác vụ.
Hãy minh họa thuật toán tìm kiếm theo chiều rộng trên một cây trong Python. Nếu bạn cần ôn lại kỹ năng Python, hãy xem lộ trình kỹ năng Python Programming tại DataCamp. Để biết thêm về các cấu trúc dữ liệu và thuật toán khác nhau, hãy tham gia khóa học Data Structures and Algorithms in Python và đọc bài hướng dẫn Data Structures: A Comprehensive Guide With Python Examples.
Bắt đầu thôi. Trước hết, chúng ta cần thiết lập một cây quyết định đơn giản để BFS tìm kiếm.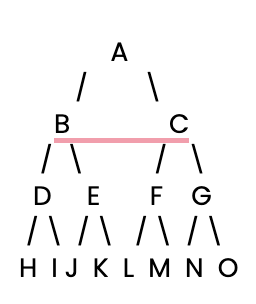
Tiếp theo, chúng ta sẽ định nghĩa cây quyết định đơn giản này bằng một dictionary trong Python, nơi mỗi khóa là một nút và giá trị của nó là danh sách các nút con.
# Define the decision tree as a dictionary
tree = {
'A': ['B', 'C'], # Node A connects to B and C
'B': ['D', 'E'], # Node B connects to D and E
'C': ['F', 'G'], # Node C connects to F and G
'D': ['H', 'I'], # Node D connects to H and I
'E': ['J', 'K'], # Node E connects to J and K
'F': ['L', 'M'], # Node F connects to L and M
'G': ['N', 'O'], # Node G connects to N and O
'H': [], 'I': [], 'J': [], 'K': [], # Leaf nodes have no children
'L': [], 'M': [], 'N': [], 'O': [] # Leaf nodes have no children
}Giờ hãy triển khai thuật toán BFS trong Python. BFS hoạt động bằng cách thăm tất cả các nút ở tầng hiện tại trước khi chuyển sang tầng tiếp theo. Chúng ta sẽ dùng một hàng đợi để quản lý những nút sẽ thăm tiếp theo.
from collections import deque # Import deque for efficient queue operations
# Define the BFS function
def bfs(tree, start):
visited = [] # List to keep track of visited nodes
queue = deque([start]) # Initialize the queue with the starting node
while queue: # While there are still nodes to process
node = queue.popleft() # Dequeue a node from the front of the queue
if node not in visited: # Check if the node has been visited
visited.append(node) # Mark the node as visited
print(node, end=" ") # Output the visited node
# Enqueue all unvisited neighbors (children) of the current node
for neighbor in tree[node]:
if neighbor not in visited:
queue.append(neighbor) # Add unvisited neighbors to the queueSau khi đã tạo hàm BFS, chúng ta có thể chạy nó trên cây, bắt đầu từ nút gốc A.
# Execute BFS starting from node 'A'
bfs(tree, 'A')Khi chạy, nó sẽ in ra từng nút theo thứ tự được thăm.
A B C D E F G H I J K L M N OMẫu duyệt của BFS trên cây khá đơn giản vì bản chất cây không có chu trình. Thuật toán bắt đầu từ gốc và thăm tất cả các nút con trước khi chuyển sang tầng tiếp theo. Cách duyệt theo thứ tự tầng này phản chiếu cấu trúc phân cấp của cây: mỗi nút có một nút cha và nhiều nút con, dẫn đến một mô hình có thể dự đoán.
Ngược lại, đồ thị có thể chứa các chu trình. Nhiều đường đi giữa các nút có thể dẫn quay lại những nút đã thăm trước đó. Điều này có thể gây vấn đề cho BFS, đòi hỏi quản lý việc thăm lại cẩn thận. Theo dõi những nút đã thăm giúp tránh xử lý lặp lại không cần thiết và giúp tránh các chu trình có thể gây lặp vô hạn. Trong triển khai BFS ở trên, chúng ta dùng một danh sách visited để đảm bảo mỗi nút chỉ được xử lý một lần. Nếu gặp nút đã thăm, thuật toán sẽ bỏ qua, cho phép BFS tiếp tục trôi chảy.
Tìm kiếm theo chiều rộng hiệu quả đến mức nào? Chúng ta có thể dùng ký hiệu Big O để đánh giá mức độ thay đổi hiệu quả của BFS theo kích thước đồ thị.
Độ phức tạp thời gian của BFS là O(V+E), trong đó V là số đỉnh (nút) và E là số cạnh trong đồ thị. Điều này có nghĩa hiệu năng của BFS phụ thuộc cả vào số nút và các kết nối giữa chúng.
Độ phức tạp bộ nhớ của BFS là O(V) do bộ nhớ cần thiết để lưu trữ các nút trong hàng đợi. Ở những đồ thị rộng, điều này có thể đồng nghĩa với việc lưu trữ nhiều nút cùng lúc. Trong trường hợp xấu nhất, có thể phải giữ toàn bộ các nút cùng lúc.
Tìm kiếm theo chiều rộng có vô số ứng dụng thực tế trong các lĩnh vực như khoa học máy tính, mạng máy tính và trí tuệ nhân tạo. Cách khám phá theo từng tầng có phương pháp của nó khiến BFS lý tưởng cho các bài toán tìm kiếm và tìm đường.
Một ứng dụng của BFS là trong các thuật toán định tuyến mạng. Khi các gói dữ liệu đi qua mạng, bộ định tuyến sử dụng BFS để tìm đường đi ngắn nhất. Bằng cách khám phá tất cả các nút kề trước khi đi sâu, BFS nhanh chóng xác định các tuyến hiệu quả, giảm độ trễ và nâng cao hiệu năng.
BFS cũng hữu ích để giải đố, như mê cung hoặc trò trượt ô. Mỗi vị trí là một nút và các kết nối là các cạnh. BFS có thể tìm hiệu quả đường đi ngắn nhất từ điểm bắt đầu đến lối ra.
Một ứng dụng mạnh mẽ khác là trong phân tích mạng xã hội. BFS giúp khám phá các mối quan hệ giữa người dùng và xác định các nút có ảnh hưởng. Nó có thể đi qua các kết nối xã hội và tìm ra các cụm người dùng liên quan, hé lộ những hiểu biết về cấu trúc mạng.
BFS cũng hữu ích trong huấn luyện AI. Chẳng hạn, nó có thể được dùng để tìm kiếm trạng thái trò chơi như cờ vua. Các thuật toán AI có thể dùng BFS để khám phá các nước đi khả dĩ theo từng tầng, đánh giá các trạng thái tương lai để xác định hành động tốt nhất, từ đó tìm đường ngắn nhất tới chiến thắng.
BFS cũng được áp dụng trong robot để lập kế hoạch đường đi. Nó giúp robot điều hướng môi trường phức tạp bằng cách lập bản đồ xung quanh và tìm đường đi trong khi tránh chướng ngại vật.
Hãy so sánh BFS với các thuật toán tìm kiếm phổ biến khác, như tìm kiếm theo chiều sâu và thuật toán Dijkstra.
Tìm kiếm theo chiều rộng và tìm kiếm theo chiều sâu (DFS) đều là các thuật toán duyệt đồ thị, nhưng chúng khám phá đồ thị theo cách khác nhau. BFS thăm tất cả các nút kề ở độ sâu hiện tại trước khi đi sâu hơn, trong khi DFS đi càng xa càng tốt theo một nhánh trước khi quay lui.
BFS rất phù hợp để tìm đường đi ngắn nhất trong đồ thị không trọng số. Lợi thế này khiến nó phù hợp cho các bài toán như dẫn đường trong mê cung và mạng máy tính. Ngược lại, DFS có thể không luôn tìm đường đi ngắn nhất, nhưng có thể tiết kiệm bộ nhớ hơn trong các đồ thị sâu và rộng. Điều này khiến DFS thích hợp cho các tác vụ như sắp xếp topo hoặc lập lịch, nơi cần duyệt toàn diện mà không dùng quá nhiều bộ nhớ.
Thuật toán Dijkstra là một thuật toán duyệt đồ thị dành cho đồ thị có trọng số, nơi các cạnh có chi phí khác nhau. Khác với BFS, vốn coi mọi cạnh như nhau, Dijkstra tính đường đi ngắn nhất dựa trên trọng số cạnh. Nó hữu ích nhất cho các ứng dụng mà chi phí là yếu tố quan trọng, như tìm tuyến tối ưu có xét đến thời gian di chuyển.
Mặc dù Dijkstra mạnh mẽ cho đồ thị có trọng số, nó phức tạp và tốn tài nguyên tính toán hơn. Dijkstra có độ phức tạp thời gian O((V+E)logV) khi dùng hàng đợi ưu tiên, cao hơn đáng kể so với độ phức tạp thời gian O(V+E) của BFS. Bạn có thể tìm hiểu thêm về Thuật toán Dijkstra trong bài Implementing the Dijkstra Algorithm in Python: A Step-by-Step Tutorial.
Một vấn đề bạn có thể gặp khi dùng BFS là bị mắc kẹt trong chu trình. Chu trình xảy ra khi một đường đi quay lại một nút đã thăm trước đó, tạo thành một vòng lặp trong quá trình duyệt. Nếu BFS không theo dõi đúng các nút đã thăm, điều này có thể dẫn đến vòng lặp vô hạn. Điều quan trọng là duy trì danh sách các nút đã thăm hoặc đánh dấu mỗi nút là đã khám phá sau khi xử lý. Cách tiếp cận đơn giản này sẽ giúp BFS khám phá đồ thị hiệu quả và kết thúc đúng cách.
Một cạm bẫy phổ biến khác là sử dụng hàng đợi không đúng cách. BFS phụ thuộc vào hàng đợi để theo dõi các nút cần được khám phá. Nếu hàng đợi không được quản lý đúng, có thể dẫn đến bỏ sót nút hoặc đường đi sai trong quá trình duyệt. Để tránh điều này, hãy thêm các nút vào hàng đợi theo thứ tự cần khám phá rồi lần lượt loại bỏ chúng. Điều này giúp BFS khám phá các nút theo từng tầng như dự định. Sử dụng một cấu trúc dữ liệu tin cậy như collections.deque trong Python sẽ hữu ích.
Dù linh hoạt, BFS không phải luôn là lựa chọn tốt nhất trong mọi tình huống. Chẳng hạn, BFS không luôn phù hợp với các đồ thị rất lớn hoặc rất sâu, nơi tìm kiếm theo chiều sâu có thể thực tế hơn. Ngoài ra, BFS không phù hợp cho đồ thị có trọng số, vì BFS coi các cạnh là như nhau. Các thuật toán như Dijkstra hoặc A* phù hợp hơn cho những trường hợp này, vì chúng tính đến chi phí khác nhau khi tính toán đường đi ngắn nhất.
BFS đặc biệt có giá trị để tìm đường đi ngắn nhất trong đồ thị không trọng số. Cách khám phá theo từng tầng khiến nó trở thành công cụ tuyệt vời cho các tình huống cần khảo sát kỹ các nút ở mỗi mức độ sâu.
Nếu bạn quan tâm đến các thuật toán tìm kiếm, hãy xem các bài viết khác trong chuỗi này, bao gồm: Binary Search in Python: A Complete Guide for Efficient Searching. Bạn cũng có thể quan tâm đến AVL Tree: Complete Guide With Python Implementation, và Introduction to Network Analysis in Python.
Học Python cùng DataCamp
Courses
Courses
Courses