
Cursus
Python voor gemiddeld niveau
4 Hr
1.4M
Stel je voor dat je de snelste route door een doolhof wilt uitstippelen, verbindingen tussen mensen in een sociaal netwerk wilt identificeren, of de meest efficiënte manier zoekt om data via het internet te versturen. Deze uitdagingen delen een gemeenschappelijk doel: relaties tussen verschillende punten systematisch verkennen. Breadth-first search is een algoritme dat je daarbij kan helpen.
Breadth-first search wordt toegepast op een breed scala aan problemen in data science, van graafdoorzoeking tot padvinden. Het is bijzonder nuttig om het kortste pad in ongewogen grafen te vinden. Lees verder: ik leg breadth-first search in detail uit en laat een implementatie in Python zien. Wil je bij de start al meer hulp bij Python, schrijf je dan in voor onze zeer uitgebreide cursus Introduction to Python.
Breadth-first search (BFS) is een graafdoorzoekingsalgoritme dat een graaf of boom niveau voor niveau verkent. Beginnend bij een opgegeven bronknooppunt bezoekt BFS eerst alle directe buren voordat het doorgaat naar het volgende niveau. Zo worden knooppunten op dezelfde diepte verwerkt voordat dieper wordt gegaan. Daardoor is BFS nuttig voor problemen waarbij je alle mogelijke paden op een gestructureerde, systematische manier moet bekijken.
BFS is handig om het kortste pad tussen knooppunten te vinden, omdat BFS de eerste keer dat het een knooppunt bereikt, de kortste route gebruikt. Dit maakt BFS nuttig voor problemen zoals netwerkroutering, waar het doel is om de meest efficiënte route tussen twee punten te vinden. Het onderstaande diagram laat een vereenvoudigde uitleg zien van hoe BFS een boom verkent.
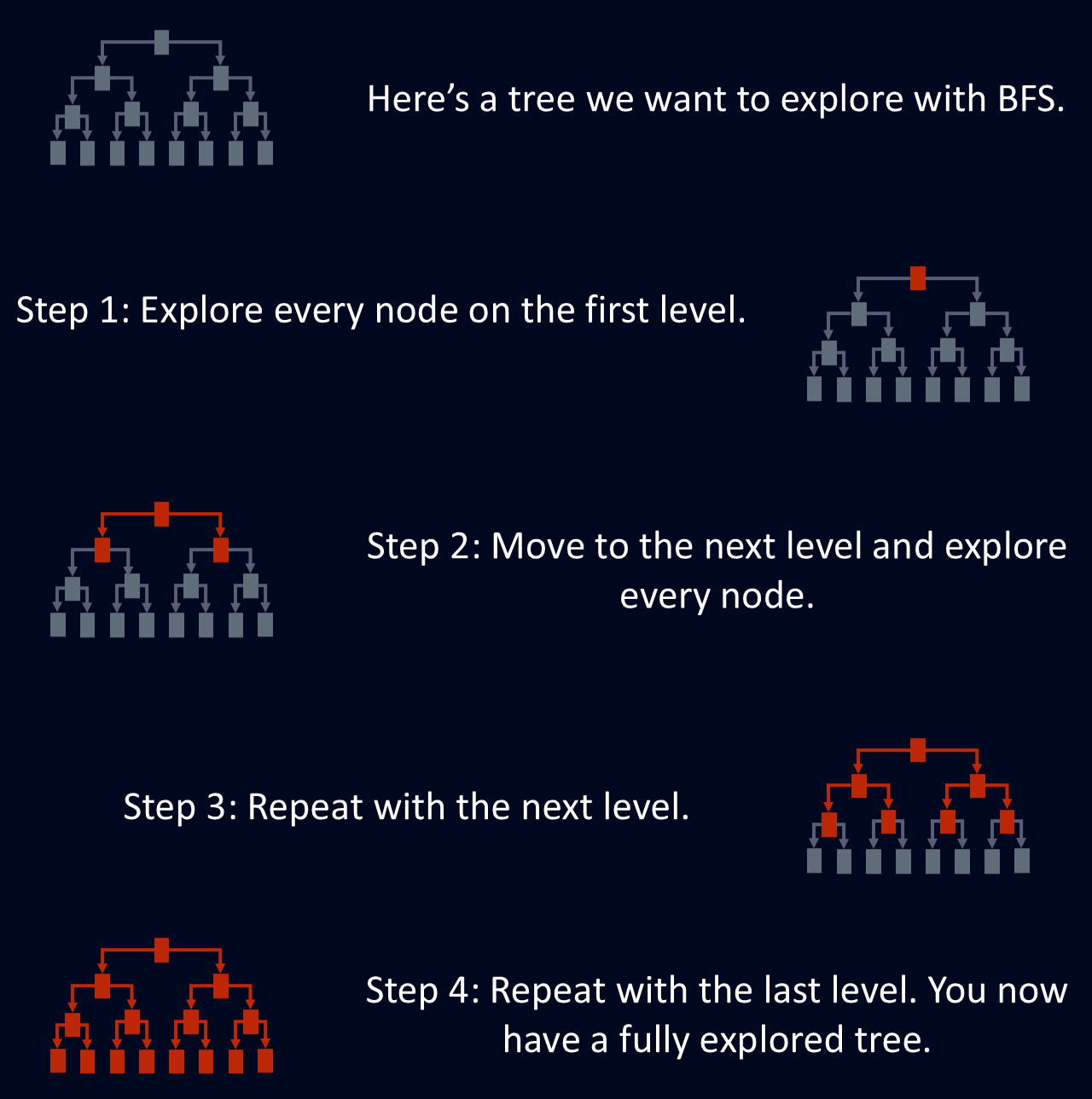
Breadth-first search is ontworpen om een graaf of boom te verkennen door alle buren van een knooppunt te bezoeken voordat het naar de volgende laag gaat. Deze gestructureerde doorzoeking zorgt ervoor dat alle knooppunten op een bepaalde diepte worden bekeken voordat dieper in de structuur wordt gegaan. Deze aanpak per niveau maakt BFS een systematische en betrouwbare manier om door complexe netwerken te navigeren.
BFS verkent elk knooppunt op het huidige diepteniveau voordat het verdergaat naar het volgende. Dit betekent dat alle knooppunten op een bepaalde afstand van het startpunt worden verwerkt voordat dieper wordt gegaan.
BFS gebruikt een wachtrij om bij te houden welke knooppunten bezocht moeten worden. Het algoritme verwerkt een knooppunt, voegt zijn onbezette buren toe aan de wachtrij en gaat zo verder. De wachtrij werkt volgens het first in, first out-principe, waardoor knooppunten in de volgorde waarin ze ontdekt zijn worden verkend.
In ongewogen grafen, of grafen waarin elke verbinding even lang is, garandeert BFS dat het het kortste pad tussen knooppunten vindt. Omdat BFS buren niveau voor niveau verkent, bereikt het een knooppunt de eerste keer via de kortst mogelijke route. Dit maakt BFS vooral effectief voor kortste-padproblemen, in situaties waarin alle randen gelijke gewichten hebben.
BFS werkt met zowel grafen als bomen. Een graaf is een netwerk van verbonden knooppunten dat cycli kan hebben, zoals een sociaal netwerk, terwijl een boom een hiërarchie is met één wortel en geen cycli, zoals een stamboom. BFS is voor beide nuttig en daardoor breed toepasbaar.
Laten we het breadth-first search-algoritme demonstreren op een boom in Python. Moet je je Pythonvaardigheden opfrissen, bekijk dan het Python Programming-skill track bij DataCamp. Voor meer informatie over verschillende datastructuren en de algoritmen, volg onze cursus Data Structures and Algorithms in Python en lees de tutorial Data Structures: A Comprehensive Guide With Python Examples.
Aan de slag. Eerst zetten we een eenvoudige beslissingsboom op waar onze BFS in kan zoeken.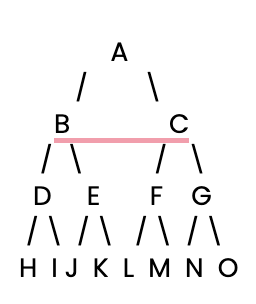
Vervolgens definiëren we deze eenvoudige beslissingsboom met een Python-dictionary, waarbij elke sleutel een knooppunt is en de waarde een lijst met de kinderen van dat knooppunt.
# Define the decision tree as a dictionary
tree = {
'A': ['B', 'C'], # Node A connects to B and C
'B': ['D', 'E'], # Node B connects to D and E
'C': ['F', 'G'], # Node C connects to F and G
'D': ['H', 'I'], # Node D connects to H and I
'E': ['J', 'K'], # Node E connects to J and K
'F': ['L', 'M'], # Node F connects to L and M
'G': ['N', 'O'], # Node G connects to N and O
'H': [], 'I': [], 'J': [], 'K': [], # Leaf nodes have no children
'L': [], 'M': [], 'N': [], 'O': [] # Leaf nodes have no children
}Laten we nu het BFS-algoritme in Python implementeren. BFS werkt door alle knooppunten op het huidige niveau te bezoeken voordat het naar het volgende niveau gaat. We gebruiken een wachtrij om te beheren welke knooppunten we daarna bezoeken.
from collections import deque # Import deque for efficient queue operations
# Define the BFS function
def bfs(tree, start):
visited = [] # List to keep track of visited nodes
queue = deque([start]) # Initialize the queue with the starting node
while queue: # While there are still nodes to process
node = queue.popleft() # Dequeue a node from the front of the queue
if node not in visited: # Check if the node has been visited
visited.append(node) # Mark the node as visited
print(node, end=" ") # Output the visited node
# Enqueue all unvisited neighbors (children) of the current node
for neighbor in tree[node]:
if neighbor not in visited:
queue.append(neighbor) # Add unvisited neighbors to the queueNu we onze BFS-functie hebben gemaakt, kunnen we die uitvoeren op de boom, beginnend bij het wortelknooppunt A.
# Execute BFS starting from node 'A'
bfs(tree, 'A')Wanneer we dit uitvoeren, geeft het elk knooppunt in de volgorde weer waarin het is bezocht.
A B C D E F G H I J K L M N OHet doorzoekingspatroon van BFS is eenvoudig in bomen, omdat ze van nature acyclisch zijn. Het algoritme start bij de wortel en bezoekt alle kinderen voordat het naar het volgende niveau gaat. Deze level-order doorzoeking weerspiegelt de hiërarchische relaties in bomen: elk knooppunt heeft één ouder en meerdere kinderen, wat tot een voorspelbaar patroon leidt.
Daarentegen kunnen grafen cycli bevatten. Meerdere paden tussen knooppunten kunnen terugleiden naar eerder bezochte knooppunten. Dit kan een probleem zijn voor BFS en vereist zorgvuldige omgang met herbezoeken. Bijhouden welke knooppunten zijn bezocht voorkomt onnodige herverwerking en helpt cycli vermijden die tot lussen kunnen leiden. In onze eerdere BFS-implementatie gebruikten we een visited-lijst om ervoor te zorgen dat elk knooppunt slechts één keer werd verwerkt. Als een bezocht knooppunt werd aangetroffen, werd het overgeslagen, zodat BFS soepel kon doorgaan.
Hoe efficiënt is breadth-first search? We kunnen Big O-notatie gebruiken om te evalueren hoe de efficiëntie van BFS verandert als functie van de grootte van de graaf.
De tijdscomplexiteit van BFS is O(V+E), waarbij V het aantal vertices (knooppunten) is en E het aantal randen in de graaf. Dit betekent dat de prestaties van BFS afhangen van zowel het aantal knooppunten als de verbindingen ertussen.
De ruimtecomplexiteit van BFS is O(V) vanwege het geheugen dat nodig is om knooppunten in de wachtrij op te slaan. In brede grafen kan dit betekenen dat je veel knooppunten tegelijk moet opslaan. In het slechtste geval kan het betekenen dat je alle knooppunten tegelijk moet vasthouden.
Breadth-first search heeft tal van praktische toepassingen in onder meer informatica, netwerken en kunstmatige intelligentie. De methodische verkenning per niveau maakt het ideaal voor zoek- en padvindingsproblemen.
Een toepassing van BFS is in routeringsalgoritmen voor netwerken. Wanneer datapakketten een netwerk doorkruisen, gebruiken routers BFS om het kortste pad te vinden. Door eerst alle naburige knooppunten te verkennen voordat dieper wordt gegaan, identificeert BFS snel efficiënte routes, met minder latency en betere prestaties.
BFS is ook handig voor het oplossen van puzzels, zoals doolhoven of schuifpuzzels. Elke positie is een knooppunt en verbindingen zijn randen. BFS kan efficiënt het kortste pad van start naar uitgang vinden.
Een andere krachtige toepassing is in sociale netwerkanalyse. BFS helpt relaties tussen gebruikers te ontdekken en invloedrijke knooppunten te identificeren. Het kan sociale verbindingen verkennen en clusters van gerelateerde gebruikers opsporen, wat inzicht geeft in netwerkstructuren.
BFS is ook nuttig in AI-training. Zo kan het worden gebruikt voor het doorzoeken van speltoestanden in spellen zoals schaken. AI-algoritmen kunnen met BFS mogelijke zetten niveau voor niveau verkennen, toekomstige toestanden evalueren om de beste actie te bepalen en zo het kortste pad naar de overwinning vinden.
BFS wordt ook toegepast in robotica voor padplanning. Het stelt robots in staat om door complexe omgevingen te navigeren door de omgeving in kaart te brengen en paden te vinden terwijl obstakels worden vermeden.
Laten we BFS vergelijken met andere veelvoorkomende zoekalgoritmen, zoals depth-first search en Dijkstra’s algoritme.
Breadth-first search en depth-first search (DFS) zijn allebei graafdoorzoekingsalgoritmen, maar ze verkennen grafen op verschillende manieren. BFS bezoekt alle buren op het huidige diepteniveau voordat het dieper gaat, terwijl DFS zo ver mogelijk langs één pad gaat voordat het terugkeert.
BFS is ideaal om het kortste pad in ongewogen grafen te vinden. Dit voordeel maakt het geschikt voor problemen zoals doolhofnavigatie en netwerken. DFS vindt daarentegen niet altijd het kortste pad, maar kan ruimte-efficiënter zijn in diepe, brede grafen. Daardoor is het te verkiezen voor taken zoals topologische sortering of planningsproblemen, waar een volledige doorzoeking nodig is zonder excessief geheugenverbruik.
Dijkstra’s algoritme is een graafdoorzoekingsalgoritme voor gewogen grafen, waar randen verschillende kosten hebben. In tegenstelling tot BFS, dat alle randen gelijk behandelt, berekent Dijkstra het kortste pad op basis van randgewichten. Het is vooral nuttig voor toepassingen waar kosten ertoe doen, zoals het vinden van de optimale route rekening houdend met reistijd.
Hoewel Dijkstra krachtig is voor gewogen grafen, is het complexer en rekentechnisch intensiever. Dijkstra heeft een tijdscomplexiteit van O((V+E)logV) bij gebruik van prioriteitswachtrijen, wat aanzienlijk hoger is dan de tijdscomplexiteit O(V+E) van BFS. Je kunt meer leren over Dijkstra’s algoritme in Implementing the Dijkstra Algorithm in Python: A Step-by-Step Tutorial.
Een probleem dat je kunt tegenkomen bij het gebruik van BFS is vastlopen in een cyclus. Een cyclus ontstaat wanneer een pad terugkeert naar een eerder bezocht knooppunt, waardoor een lus in de doorzoeking ontstaat. Als BFS bezochte knooppunten niet goed bijhoudt, kan dit tot een oneindige lus leiden. Het is belangrijk om een lijst met bezochte knooppunten bij te houden of elk knooppunt te markeren als verkend zodra het is verwerkt. Deze eenvoudige aanpak zorgt ervoor dat je BFS de graaf efficiënt verkent en correct eindigt.
Een andere veelvoorkomende valkuil is onjuiste wachtrijverwerking. BFS is afhankelijk van een wachtrij om bij te houden welke knooppunten moeten worden verkend. Als de wachtrij niet goed wordt beheerd, kan dit leiden tot gemiste knooppunten of onjuiste paden in de doorzoeking. Voorkom dit door knooppunten in de volgorde waarin ze moeten worden verkend aan de wachtrij toe te voegen en ze vervolgens te verwijderen. Dit helpt BFS knooppunten niveau voor niveau te verkennen, zoals bedoeld. Het gebruik van een betrouwbare datastructuur, zoals collections.deque in Python, helpt.
Ondanks de veelzijdigheid is BFS niet in elke situatie de beste keuze. Zo is BFS niet altijd geschikt voor zeer grote of diepe grafen, waar depth-first search praktischer kan zijn. Ook is BFS niet geschikt voor gewogen grafen, omdat BFS alle randen gelijk behandelt. Algoritmen zoals dat van Dijkstra of A* zijn beter voor deze gevallen, omdat ze met variërende kosten rekening houden bij het berekenen van het kortste pad.
BFS is bijzonder waardevol voor het vinden van het kortste pad in ongewogen grafen. De verkenning per niveau maakt het een uitstekend hulpmiddel voor situaties waarin je knooppunten op elk diepteniveau grondig moet verkennen.
Ben je geïnteresseerd in zoekalgoritmen, bekijk dan zeker mijn andere artikelen in deze serie, waaronder: Binary Search in Python: A Complete Guide for Efficient Searching. Misschien vind je ook AVL Tree: Complete Guide With Python Implementation en Introduction to Network Analysis in Python interessant.
Leer Python met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
