
Kursus
Pelatihan Model AI Efisien dengan PyTorch
4 Hr
1.6K
Pertama kali diperkenalkan dalam makalah Attention is All You Need oleh Vaswani dkk., Transformer sejak itu menjadi pilar banyak tugas NLP karena desain dan efektivitasnya yang unik.
Inti dari Transformer adalah mekanisme attention, khususnya konsep 'self-attention', yang memungkinkan model menimbang dan memprioritaskan bagian-bagian berbeda dari data masukan. Mekanisme ini memungkinkan Transformer menangani ketergantungan jarak jauh dalam data. Secara fundamental, ini adalah skema pembobotan yang memungkinkan model fokus pada bagian berbeda dari masukan saat menghasilkan keluaran.
Mekanisme self-attention memungkinkan model mempertimbangkan kata atau fitur berbeda dalam urutan masukan, memberikan setiap elemen sebuah 'bobot' yang menandakan pentingnya untuk menghasilkan keluaran tertentu. Misalnya, dalam tugas penerjemahan kalimat, saat menerjemahkan kata tertentu, model mungkin memberikan bobot perhatian lebih tinggi pada kata-kata yang terkait secara gramatikal atau semantik dengan kata target. Proses ini memungkinkan Transformer menangkap dependensi antar kata atau fitur, tanpa bergantung pada jaraknya dalam urutan.
Dampak Transformer dalam bidang NLP sangat besar. Model ini melampaui model tradisional di banyak tugas, menunjukkan kemampuan unggul untuk memahami dan menghasilkan bahasa manusia secara lebih bernuansa.
Untuk pemahaman lebih mendalam tentang NLP, kursus DataCamp Introduction to Natural Language Processing in Python merupakan sumber yang direkomendasikan.
Sebelum membangun Transformer, penting untuk menyiapkan lingkungan kerja dengan benar. Pertama-tama, PyTorch perlu dipasang. PyTorch dapat dipasang melalui pengelola paket pip atau conda.
Untuk pip, gunakan perintah:
pip3 install torch torchvision torchaudioUntuk conda, gunakan perintah:
conda install pytorch torchvision -c pytorchUntuk opsi lain dalam memasang dan menjalankan PyTorch, rujuk ke situs resmi.
Selain itu, pemahaman dasar tentang konsep deep learning akan bermanfaat, karena hal ini fundamental untuk memahami cara kerja Transformer. Bagi yang perlu penyegaran, kursus DataCamp Deep Learning in Python adalah sumber berharga yang membahas konsep-konsep kunci dalam deep learning.
Untuk membangun model Transformer, langkah-langkah berikut diperlukan:
Kita akan mulai dengan mengimpor pustaka PyTorch untuk fungsi inti, modul jaringan saraf untuk membuat jaringan saraf, modul optimisasi untuk melatih jaringan, dan fungsi utilitas data untuk menangani data. Selain itu, kita akan mengimpor modul Python standar math untuk operasi matematika dan modul copy untuk membuat salinan objek kompleks.
Perangkat ini menjadi landasan untuk mendefinisikan arsitektur model, mengelola data, dan menetapkan proses pelatihan.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import math
import copySebelum kita membangun komponennya, lihat tabel berikut yang menjelaskan berbagai komponen Transformer dan tujuannya:
| Komponen | Deskripsi | Tujuan |
|---|---|---|
| Multi-Head Attention | Mekanisme untuk fokus pada bagian berbeda dari masukan | Menangkap dependensi di berbagai posisi dalam urutan |
| Feed-Forward Networks | Lapisan fully connected per posisi | Mentransformasikan keluaran attention, menambah kompleksitas |
| Positional Encoding | Menambahkan informasi posisi ke embedding | Menyediakan konteks urutan kepada model |
| Layer Normalization | Menormalkan masukan ke setiap sub-lapisan | Menstabilkan pelatihan, meningkatkan konvergensi |
| Residual Connections | Jalur pintas antar lapisan | Membantu melatih jaringan lebih dalam dengan meminimalkan masalah gradien |
| Dropout | Secara acak men-nol-kan beberapa koneksi jaringan | Mencegah overfitting dengan melakukan regularisasi model |
Mekanisme multi-head attention menghitung attention antara setiap pasangan posisi dalam suatu urutan. Mekanisme ini terdiri dari beberapa "kepala attention" yang menangkap aspek berbeda dari urutan masukan.
Untuk mempelajari lebih lanjut tentang multi-head attention, lihat bagian attention mechanisms pada kursus Large Language Models (LLMs) Concepts.
Gambar 1. Multi-Head Attention (sumber: gambar dibuat oleh penulis)
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
# Ensure that the model dimension (d_model) is divisible by the number of heads
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
# Initialize dimensions
self.d_model = d_model # Model's dimension
self.num_heads = num_heads # Number of attention heads
self.d_k = d_model // num_heads # Dimension of each head's key, query, and value
# Linear layers for transforming inputs
self.W_q = nn.Linear(d_model, d_model) # Query transformation
self.W_k = nn.Linear(d_model, d_model) # Key transformation
self.W_v = nn.Linear(d_model, d_model) # Value transformation
self.W_o = nn.Linear(d_model, d_model) # Output transformation
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# Calculate attention scores
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# Apply mask if provided (useful for preventing attention to certain parts like padding)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# Softmax is applied to obtain attention probabilities
attn_probs = torch.softmax(attn_scores, dim=-1)
# Multiply by values to obtain the final output
output = torch.matmul(attn_probs, V)
return output
def split_heads(self, x):
# Reshape the input to have num_heads for multi-head attention
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
def combine_heads(self, x):
# Combine the multiple heads back to original shape
batch_size, _, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
def forward(self, Q, K, V, mask=None):
# Apply linear transformations and split heads
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# Perform scaled dot-product attention
attn_output = self.scaled_dot_product_attention(Q, K, V, mask)
# Combine heads and apply output transformation
output = self.W_o(self.combine_heads(attn_output))
return outputDefinisi kelas dan inisialisasi:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):Kelas ini didefinisikan sebagai subclass dari nn.Module milik PyTorch.
d_model: Dimensi masukan.num_heads: Jumlah kepala attention yang menjadi pembagian masukan.Inisialisasi memeriksa apakah d_model habis dibagi num_heads, lalu mendefinisikan bobot transformasi untuk query, key, value, dan output.
Scaled dot-product attention:
def scaled_dot_product_attention(self, Q, K, V, mask=None):attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k). Di sini, skor attention dihitung dengan hasil kali titik antara query (Q) dan key (K), lalu diskalakan dengan akar kuadrat dari dimensi key (d_k).V).Memisahkan kepala:
def split_heads(self, x):Metode ini membentuk ulang masukan x menjadi bentuk (batch_size, num_heads, seq_length, d_k). Ini memungkinkan model memproses beberapa kepala attention secara bersamaan untuk komputasi paralel.
Menggabungkan kepala:
def combine_heads(self, x):Setelah menerapkan attention pada tiap kepala secara terpisah, metode ini menggabungkan hasilnya kembali menjadi satu tensor berbentuk (batch_size, seq_length, d_model). Ini menyiapkan hasil untuk pemrosesan lebih lanjut.
Metode forward:
def forward(self, Q, K, V, mask=None):Metode forward adalah tempat komputasi sebenarnya terjadi:
Q), key (K), dan value (V) terlebih dahulu dilewatkan melalui transformasi linear menggunakan bobot yang didefinisikan saat inisialisasi.Q, K, V yang sudah ditransformasikan dipisah menjadi beberapa kepala menggunakan metode split_heads.scaled_dot_product_attention dipanggil pada kepala yang telah dipisah.combine_heads.Singkatnya, kelas MultiHeadAttention merangkum mekanisme multi-head attention yang umum digunakan pada model transformer. Kelas ini menangani pemisahan masukan menjadi beberapa kepala attention, menerapkan attention pada masing-masing kepala, lalu menggabungkan hasilnya. Dengan demikian, model dapat menangkap berbagai relasi dalam data masukan pada berbagai skala, meningkatkan kemampuan ekspresif model.
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))Definisi kelas:
class PositionWiseFeedForward(nn.Module):Kelas ini merupakan subclass dari nn.Module milik PyTorch, sehingga mewarisi semua fungsi yang diperlukan untuk bekerja dengan lapisan jaringan saraf.
Inisialisasi:
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()d_model: Dimensi masukan dan keluaran model.d_ff: Dimensi lapisan dalam pada jaringan feed-forward.self.fc1 dan self.fc2: Dua lapisan fully connected (linear) dengan dimensi masukan dan keluaran sebagaimana didefinisikan oleh d_model dan d_ff.self.relu: Fungsi aktivasi ReLU (Rectified Linear Unit) yang menambahkan non-linearitas di antara dua lapisan linear.Metode Forward:
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))x: Masukan ke jaringan feed-forward.self.fc1(x): Masukan terlebih dahulu dilewatkan melalui lapisan linear pertama (fc1).self.relu(...): Keluaran dari fc1 kemudian dilewatkan melalui fungsi aktivasi ReLU. ReLU mengganti semua nilai negatif dengan nol, menambahkan non-linearitas ke model.self.fc2(...): Keluaran yang telah diaktifkan kemudian dilewatkan melalui lapisan linear kedua (fc2), menghasilkan keluaran akhir.Singkatnya, kelas PositionWiseFeedForward mendefinisikan jaringan saraf feed-forward per posisi yang terdiri dari dua lapisan linear dengan fungsi aktivasi ReLU di antaranya. Dalam konteks model transformer, jaringan feed-forward ini diterapkan pada setiap posisi secara terpisah dan identik. Fungsinya membantu mentransformasikan fitur yang dipelajari oleh mekanisme attention dalam transformer, bertindak sebagai langkah pemrosesan tambahan untuk keluaran attention.
Positional Encoding digunakan untuk menyuntikkan informasi posisi setiap token dalam urutan masukan. Pendekatan ini menggunakan fungsi sinus dan cosinus dengan frekuensi berbeda untuk menghasilkan positional encoding.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1)]Definisi kelas:
class PositionalEncoding(nn.Module):Kelas ini didefinisikan sebagai subclass dari nn.Module milik PyTorch, sehingga dapat digunakan sebagai lapisan standar PyTorch.
Inisialisasi:
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))d_model: Dimensi masukan model.max_seq_length: Panjang urutan maksimum untuk pra-komputasi positional encoding.pe: Tensor berisi nol, yang akan diisi dengan positional encoding.position: Tensor yang memuat indeks posisi untuk setiap posisi dalam urutan.div_term: Istilah untuk menskalakan indeks posisi dengan cara tertentu.pe.pe didaftarkan sebagai buffer, artinya menjadi bagian dari state modul tetapi bukan parameter yang dapat dilatih.Metode forward:
def forward(self, x):
return x + self.pe[:, :x.size(1)]Metode forward cukup menambahkan positional encoding ke masukan x.
Metode ini menggunakan x.size(1) elemen pertama dari pe untuk memastikan positional encoding sesuai dengan panjang urutan aktual x.
Ringkasan
Kelas PositionalEncoding menambahkan informasi tentang posisi token di dalam urutan. Karena model transformer tidak memiliki pengetahuan bawaan tentang urutan token (karena mekanisme self-attention), kelas ini membantu model mempertimbangkan posisi token dalam urutan. Fungsi sinusoidal dipilih agar model mudah mempelajari perhatian pada posisi relatif, karena menghasilkan encoding yang unik dan mulus untuk setiap posisi dalam urutan.
Gambar 2. Bagian Encoder dari jaringan transformer (Sumber: gambar dari makalah asli)
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xDefinisi kelas:
class EncoderLayer(nn.Module):Kelas ini didefinisikan sebagai subclass dari nn.Module milik PyTorch, artinya dapat digunakan sebagai blok penyusun jaringan saraf di PyTorch.
Inisialisasi:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parameter:
d_model: Dimensi masukan.num_heads: Jumlah kepala attention pada multi-head attention.d_ff: Dimensi lapisan dalam pada jaringan feed-forward per posisi.dropout: Laju dropout untuk regularisasi.Komponen:
self.self_attn: Mekanisme multi-head attention.self.feed_forward: Jaringan saraf feed-forward per posisi.self.norm1 dan self.norm2: Layer normalization, diterapkan untuk memperhalus masukan lapisan.self.dropout: Lapisan dropout, digunakan untuk mencegah overfitting dengan secara acak men-nol-kan sebagian aktivasi selama pelatihan.Metode forward:
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xMasukan:
x: Masukan ke lapisan encoder.mask: Mask opsional untuk mengabaikan bagian tertentu dari masukan.Langkah pemrosesan:
x dilewatkan melalui mekanisme multi-head self-attention.norm1.norm2.Ringkasan:
Kelas EncoderLayer mendefinisikan satu lapisan encoder pada transformer. Kelas ini merangkum mekanisme multi-head self-attention yang diikuti jaringan saraf feed-forward per posisi, dengan residual connection, layer normalization, dan dropout diterapkan sebagaimana mestinya. Gabungan komponen ini memungkinkan encoder menangkap relasi kompleks dalam data masukan dan mengubahnya menjadi representasi yang berguna untuk tugas hilir. Biasanya, beberapa lapisan encoder seperti ini ditumpuk untuk membentuk bagian encoder lengkap pada model transformer.
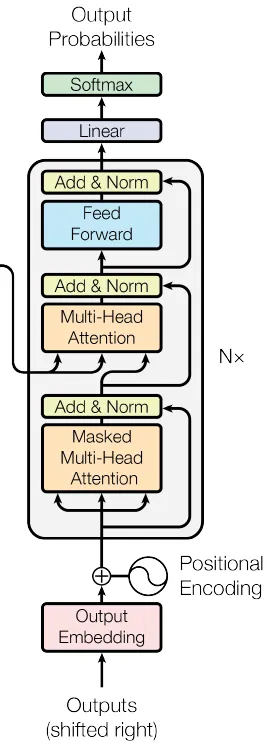
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xDefinisi kelas:
class DecoderLayer(nn.Module):Inisialisasi:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parameter:
d_model: Dimensi masukan.num_heads: Jumlah kepala attention pada multi-head attention.d_ff: Dimensi lapisan dalam pada jaringan feed-forward.dropout: Laju dropout untuk regularisasi.Komponen:
self.self_attn: Mekanisme multi-head self-attention untuk urutan target.self.cross_attn: Mekanisme multi-head attention yang memperhatikan keluaran encoder.self.feed_forward: Jaringan saraf feed-forward per posisi.self.norm1, self.norm2, self.norm3: Komponen layer normalization.self.dropout: Lapisan dropout untuk regularisasi.Metode forward:
ef forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xMasukan:
x: Masukan ke lapisan decoder.enc_output: Keluaran dari encoder terkait (digunakan pada langkah cross-attention).src_mask: Mask sumber untuk mengabaikan bagian tertentu dari keluaran encoder.tgt_mask: Mask target untuk mengabaikan bagian tertentu dari masukan decoder.Langkah pemrosesan:
enc_output.Ringkasan:
Kelas DecoderLayer mendefinisikan satu lapisan decoder pada transformer. Kelas ini terdiri dari mekanisme multi-head self-attention, mekanisme multi-head cross-attention (yang memperhatikan keluaran encoder), jaringan saraf feed-forward per posisi, serta residual connection, layer normalization, dan lapisan dropout terkait. Kombinasi ini memungkinkan decoder menghasilkan keluaran yang bermakna berdasarkan representasi encoder, dengan mempertimbangkan baik urutan target maupun urutan sumber. Seperti pada encoder, beberapa lapisan decoder biasanya ditumpuk untuk membentuk bagian decoder lengkap pada model transformer.
Berikutnya, blok Encoder dan Decoder digabungkan untuk menyusun model Transformer yang komprehensif.
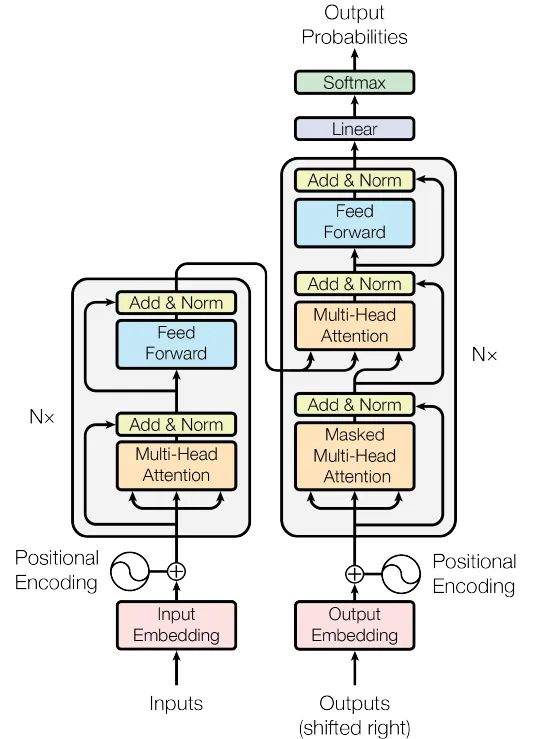
Gambar 4. Jaringan Transformer (Sumber: Gambar dari makalah asli)
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):
super(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_length)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.fc = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def generate_mask(self, src, tgt):
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.size(1)
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask
return src_mask, tgt_mask
def forward(self, src, tgt):
src_mask, tgt_mask = self.generate_mask(src, tgt)
src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))
tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
output = self.fc(dec_output)
return outputDefinisi kelas:
class Transformer(nn.Module):Inisialisasi:
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):Konstruktor menerima parameter berikut:
src_vocab_size: Ukuran kosakata sumber.tgt_vocab_size: Ukuran kosakata target.d_model: Dimensi embedding model.num_heads: Jumlah kepala attention pada mekanisme multi-head attention.num_layers: Jumlah lapisan untuk encoder dan decoder.d_ff: Dimensi lapisan dalam pada jaringan feed-forward.max_seq_length: Panjang urutan maksimum untuk positional encoding.dropout: Laju dropout untuk regularisasi.Dan mendefinisikan komponen berikut:
self.encoder_embedding: Lapisan embedding untuk urutan sumber.self.decoder_embedding: Lapisan embedding untuk urutan target.self.positional_encoding: Komponen positional encoding.self.encoder_layers: Daftar lapisan encoder.self.decoder_layers: Daftar lapisan decoder.self.fc: Lapisan fully connected (linear) akhir yang memetakan ke ukuran kosakata target.self.dropout: Lapisan dropout.Metode generate mask:
def generate_mask(self, src, tgt):Metode ini digunakan untuk membuat mask untuk urutan sumber dan target, memastikan token padding diabaikan dan token masa depan tidak terlihat saat pelatihan untuk urutan target.
Metode forward:
def forward(self, src, tgt):Metode ini mendefinisikan lintasan maju untuk Transformer, menerima urutan sumber dan target serta menghasilkan prediksi keluaran.
Keluaran:
Keluaran akhir adalah tensor yang merepresentasikan prediksi model untuk urutan target.
Ringkasan:
Kelas Transformer memadukan berbagai komponen model Transformer, termasuk embedding, positional encoding, lapisan encoder, dan lapisan decoder. Kelas ini menyediakan antarmuka yang nyaman untuk pelatihan dan inferensi, merangkum kompleksitas multi-head attention, jaringan feed-forward, dan layer normalization.
Implementasi ini mengikuti arsitektur Transformer standar, sehingga cocok untuk tugas sequence-to-sequence seperti penerjemahan mesin, peringkasan teks, dan sebagainya. Penyertaan masking memastikan model mematuhi dependensi kausal dalam urutan, mengabaikan token padding dan mencegah kebocoran informasi dari token masa depan.
Rangkaian langkah ini memberdayakan model Transformer untuk memproses urutan masukan secara efisien dan menghasilkan urutan keluaran yang sesuai.
Untuk tujuan ilustrasi, dataset tiruan akan dibuat pada contoh ini. Namun, dalam skenario praktis, dataset yang lebih besar akan digunakan, dan prosesnya akan melibatkan prapemrosesan teks serta pembuatan pemetaan kosakata untuk bahasa sumber dan target.
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_seq_length = 100
dropout = 0.1
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)
# Generate random sample data
src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)Hiperparameter:
Nilai-nilai ini mendefinisikan arsitektur dan perilaku model transformer:
src_vocab_size, tgt_vocab_size: Ukuran kosakata untuk urutan sumber dan target, masing-masing disetel ke 5000.d_model: Dimensi embedding model, disetel ke 512.num_heads: Jumlah kepala attention pada mekanisme multi-head attention, disetel ke 8.num_layers: Jumlah lapisan untuk encoder dan decoder, disetel ke 6.d_ff: Dimensi lapisan dalam pada jaringan feed-forward, disetel ke 2048.max_seq_length: Panjang urutan maksimum untuk positional encoding, disetel ke 100.dropout: Laju dropout untuk regularisasi, disetel ke 0,1.Sebagai referensi, tabel berikut menjelaskan hiperparameter paling umum untuk model Transformer dan nilainya:
| Hiperparameter | Nilai khas | Dampak pada kinerja |
|---|---|---|
| d_model | 256, 512, 1024 | Nilai lebih tinggi meningkatkan kapasitas model tetapi membutuhkan komputasi lebih besar |
| num_heads | 8, 12, 16 | Lebih banyak kepala dapat menangkap aspek data yang beragam, tetapi lebih intensif komputasi |
| num_layers | 6, 12, 24 | Lebih banyak lapisan meningkatkan kekuatan representasi, tetapi dapat menyebabkan overfitting |
| d_ff | 2048, 4096 | Jaringan feed-forward yang lebih besar meningkatkan ketangguhan model |
| dropout | 0,1, 0,3 | Melakukan regularisasi model untuk mencegah overfitting |
| learning rate | 0,0001 - 0,001 | Mempengaruhi kecepatan dan stabilitas konvergensi |
| batch size | 32, 64, 128 | Ukuran batch yang lebih besar meningkatkan stabilitas pembelajaran tetapi membutuhkan lebih banyak memori |
Membuat instance Transformer:
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)Baris ini membuat instance kelas Transformer, menginisialisasinya dengan hiperparameter yang diberikan. Instance ini akan memiliki arsitektur dan perilaku yang ditentukan oleh hiperparameter tersebut.
Menghasilkan data contoh acak:
Baris berikut menghasilkan urutan sumber dan target acak:
src_data: Bilangan bulat acak antara 1 dan src_vocab_size, merepresentasikan satu batch urutan sumber dengan bentuk (64, max_seq_length).tgt_data: Bilangan bulat acak antara 1 dan tgt_vocab_size, merepresentasikan satu batch urutan target dengan bentuk (64, max_seq_length).Ringkasan:
Cuplikan kode ini menunjukkan cara menginisialisasi model Transformer dan menghasilkan urutan sumber serta target acak yang dapat dimasukkan ke dalamnya. Hiperparameter yang dipilih menentukan struktur dan properti spesifik Transformer. Setup ini dapat menjadi bagian dari skrip yang lebih besar di mana model dilatih dan dievaluasi pada tugas sequence-to-sequence nyata, seperti penerjemahan mesin atau peringkasan teks.
Berikutnya, model akan dilatih menggunakan data contoh di atas. Namun, dalam skenario dunia nyata, dataset yang jauh lebih besar akan digunakan, yang biasanya dibagi menjadi set terpisah untuk pelatihan dan validasi.
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
transformer.train()
for epoch in range(100):
optimizer.zero_grad()
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:].contiguous().view(-1))
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")Fungsi loss dan optimizer:
criterion = nn.CrossEntropyLoss(ignore_index=0): Mendefinisikan fungsi loss sebagai cross-entropy loss. Argumen ignore_index disetel ke 0, artinya loss tidak mempertimbangkan target dengan indeks 0 (biasanya digunakan untuk token padding).optimizer = optim.Adam(...): Mendefinisikan optimizer sebagai Adam dengan learning rate 0,0001 dan nilai beta tertentu.Mode pelatihan model:
transformer.train(): Menyetel model transformer ke mode pelatihan, mengaktifkan perilaku seperti dropout yang hanya berlaku saat pelatihan.Loop pelatihan:
Cuplikan kode ini melatih model selama 100 epoch menggunakan loop pelatihan umum:
for epoch in range(100): Melakukan iterasi selama 100 epoch pelatihan.optimizer.zero_grad(): Mengosongkan gradien dari iterasi sebelumnya.output = transformer(src_data, tgt_data[:, :-1]): Melewatkan data sumber dan data target (kecuali token terakhir di setiap urutan) melalui transformer. Ini umum pada tugas sequence-to-sequence di mana target digeser satu token.loss = criterion(...): Menghitung loss antara prediksi model dan data target (kecuali token pertama di setiap urutan). Loss dihitung dengan membentuk ulang data menjadi tensor satu dimensi dan menggunakan fungsi cross-entropy loss.loss.backward(): Menghitung gradien loss terhadap parameter model.optimizer.step(): Memperbarui parameter model menggunakan gradien yang dihitung.print(f"Epoch: {epoch+1}, Loss: {loss.item()}"): Mencetak nomor epoch saat ini dan nilai loss untuk epoch tersebut.Ringkasan:
Cuplikan kode ini melatih model transformer pada urutan sumber dan target yang dihasilkan secara acak selama 100 epoch. Kode ini menggunakan optimizer Adam dan fungsi loss cross-entropy. Nilai loss dicetak untuk setiap epoch, memungkinkan Anda memantau kemajuan pelatihan. Dalam skenario dunia nyata, Anda akan mengganti urutan sumber dan target acak dengan data nyata dari tugas Anda, seperti penerjemahan mesin.
Setelah melatih model, kinerjanya dapat dievaluasi pada dataset validasi atau dataset uji. Berikut adalah contoh bagaimana hal ini dapat dilakukan:
transformer.eval()
# Generate random sample validation data
val_src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
val_tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
with torch.no_grad():
val_output = transformer(val_src_data, val_tgt_data[:, :-1])
val_loss = criterion(val_output.contiguous().view(-1, tgt_vocab_size), val_tgt_data[:, 1:].contiguous().view(-1))
print(f"Validation Loss: {val_loss.item()}")Mode evaluasi:
transformer.eval(): Menempatkan model transformer dalam mode evaluasi. Ini penting karena mematikan perilaku tertentu seperti dropout yang hanya digunakan saat pelatihan.Menghasilkan data validasi acak:
val_src_data: Bilangan bulat acak antara 1 dan src_vocab_size, merepresentasikan satu batch urutan sumber validasi dengan bentuk (64, max_seq_length).val_tgt_data: Bilangan bulat acak antara 1 dan tgt_vocab_size, merepresentasikan satu batch urutan target validasi dengan bentuk (64, max_seq_length).Loop validasi:
with torch.no_grad(): Menonaktifkan komputasi gradien, karena kita tidak perlu menghitung gradien saat validasi. Ini dapat mengurangi konsumsi memori dan mempercepat komputasi.val_output = transformer(val_src_data, val_tgt_data[:, :-1]): Melewatkan data sumber validasi dan data target validasi (kecuali token terakhir di setiap urutan) melalui transformer.val_loss = criterion(...): Menghitung loss antara prediksi model dan data target validasi (kecuali token pertama di setiap urutan). Loss dihitung dengan membentuk ulang data menjadi tensor satu dimensi dan menggunakan fungsi cross-entropy loss yang telah didefinisikan sebelumnya.print(f"Validation Loss: {val_loss.item()}"): Mencetak nilai loss validasi.Ringkasan:
Cuplikan kode ini mengevaluasi model transformer pada dataset validasi yang dihasilkan secara acak, menghitung loss validasi, dan mencetaknya. Dalam skenario dunia nyata, data validasi acak harus diganti dengan data validasi nyata dari tugas yang sedang Anda kerjakan. Loss validasi dapat memberi indikasi seberapa baik model Anda bekerja pada data yang tidak terlihat, yang merupakan ukuran kritis dari kemampuan generalisasi model.
Untuk detail lebih lanjut tentang Transformer dan Hugging Face, tutorial kami, An Introduction to Using Transformers and Hugging Face, berguna.
Sebagai penutup, tutorial ini menunjukkan cara membangun model Transformer menggunakan PyTorch, salah satu alat paling serbaguna untuk deep learning. Dengan kapasitas paralelisasi dan kemampuan menangkap ketergantungan jangka panjang dalam data, Transformer memiliki potensi besar di berbagai bidang, khususnya tugas NLP seperti penerjemahan, peringkasan, dan analisis sentimen.
Bagi Anda yang ingin memperdalam pemahaman tentang konsep dan teknik deep learning tingkat lanjut, pertimbangkan untuk mengeksplorasi kursus Advanced Deep Learning with Keras di DataCamp. Anda juga dapat membaca tentang membangun jaringan saraf sederhana dengan PyTorch di tutorial terpisah.
Pelajari lebih lanjut tentang PyTorch dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
