
Kurs
Einführung in Deep Learning mit PyTorch
4 Std.
86K
Die Transformatoren wurden erstmals in dem Artikel Attention is All You Need von Vaswani et al. vorgestellt und sind seitdem aufgrund ihres einzigartigen Designs und ihrer Effektivität zu einem Eckpfeiler vieler NLP-Aufgaben geworden.
Das Herzstück von Transformers ist der Aufmerksamkeitsmechanismus, insbesondere das Konzept der "Selbstaufmerksamkeit", das es dem Modell ermöglicht, verschiedene Teile der Eingabedaten zu gewichten und zu priorisieren. Dieser Mechanismus ermöglicht es Transformers, weitreichende Abhängigkeiten in Daten zu verwalten. Es handelt sich im Grunde um ein Gewichtungsschema, das es einem Modell ermöglicht, sich bei der Produktion einer Ausgabe auf verschiedene Teile der Eingabe zu konzentrieren.
Der Selbstbeobachtungsmechanismus ermöglicht es dem Modell, verschiedene Wörter oder Merkmale in der Eingabesequenz zu berücksichtigen und jedem ein "Gewicht" zuzuweisen, das seine Bedeutung für die Produktion einer bestimmten Ausgabe angibt. Bei einer Satzübersetzungsaufgabe zum Beispiel könnte das Modell beim Übersetzen eines bestimmten Wortes den Wörtern, die grammatikalisch oder semantisch mit dem Zielwort verwandt sind, eine höhere Aufmerksamkeitsgewichtung zuweisen. Dieser Prozess ermöglicht es dem Transformer, Abhängigkeiten zwischen Wörtern oder Merkmalen zu erfassen, unabhängig von ihrem Abstand zueinander in der Sequenz.
Der Einfluss von Transformers auf den Bereich NLP kann gar nicht hoch genug eingeschätzt werden. Sie haben die traditionellen Modelle bei vielen Aufgaben übertroffen und gezeigt, dass sie die menschliche Sprache besser verstehen und differenzierter generieren können.
Für ein tieferes Verständnis von NLP ist der Kurs Einführung in die natürliche Sprachverarbeitung in Python von DataCamp zu empfehlen.
Bevor du einen Transformator baust, ist es wichtig, dass du die Arbeitsumgebung richtig einrichtest. Zuallererst muss PyTorch installiert werden. PyTorch wird über die Paketmanager pip oder conda installiert.
Für pip verwendest du den Befehl:
pip3 install torch torchvision torchaudioFür conda verwendest du den Befehl:
conda install pytorch torchvision -c pytorchWeitere Optionen für die Installation und den Betrieb von PyTorch findest du auf der offiziellen Website.
Außerdem ist es von Vorteil, ein grundlegendes Verständnis von Deep Learning-Konzepten zu haben, da diese für das Verständnis der Funktionsweise von Transformers grundlegend sind. Für diejenigen, die eine Auffrischung brauchen, ist der DataCamp-Kurs Deep Learning in Python eine wertvolle Ressource, die die wichtigsten Konzepte des Deep Learning abdeckt.
Um das Transformatormodell zu bauen, sind folgende Schritte notwendig:
Wir beginnen mit dem Import der PyTorch-Bibliothek für die Kernfunktionalität, dem Modul für neuronale Netze zum Erstellen neuronaler Netze, dem Optimierungsmodul zum Trainieren von Netzen und den Data-Utility-Funktionen für den Umgang mit Daten. Außerdem importieren wir das Python-Standardmodul math für mathematische Operationen und das Modul copy zum Erstellen von Kopien komplexer Objekte.
Diese Werkzeuge bilden die Grundlage für die Definition der Modellarchitektur, die Verwaltung der Daten und die Festlegung des Schulungsprozesses.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import math
import copyBevor wir mit dem Bau unserer Komponenten beginnen, wirf einen Blick auf die folgende Tabelle, in der die verschiedenen Komponenten eines Transformators und ihr Zweck beschrieben sind:
| Komponente | Beschreibung | Zweck |
|---|---|---|
| Multi-Head Aufmerksamkeit | Mechanismus zur Fokussierung auf verschiedene Teile des Inputs | Erfasst Abhängigkeiten über verschiedene Positionen in der Sequenz |
| Feed-Forward-Netzwerke | Positionsweise vollständig verbundene Schichten | Verändert die Aufmerksamkeitsleistungen und erhöht die Komplexität |
| Positionelle Kodierung | Fügt den Einbettungen Positionsinformationen hinzu | Bietet dem Modell einen Kontext für die Reihenfolge |
| Ebene Normalisierung | Normalisiert die Eingaben für jede Teilschicht | Stabilisiert das Training, verbessert die Konvergenz |
| Verbleibende Verbindungen | Abkürzungen zwischen Ebenen | Hilft beim Training tieferer Netze durch Minimierung von Gradientenproblemen |
| Ausstieg | Nullt zufällig einige Netzwerkverbindungen | Verhindert Überanpassung durch Regularisierung des Modells |
Der Multi-Head-Attention-Mechanismus berechnet die Aufmerksamkeit zwischen jedem Paar von Positionen in einer Sequenz. Es besteht aus mehreren "Aufmerksamkeitsköpfen", die verschiedene Aspekte der Eingangssequenz erfassen.
Wenn du mehr über Multi-Kopf-Aufmerksamkeit erfahren möchtest, schau dir den Abschnitt über Aufmerksamkeitsmechanismen im Kurs Konzepte für große Sprachmodelle (LLMs) an.
Abbildung 1. Multi-Head Attention (Quelle: vom Autor erstelltes Bild)
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
# Ensure that the model dimension (d_model) is divisible by the number of heads
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
# Initialize dimensions
self.d_model = d_model # Model's dimension
self.num_heads = num_heads # Number of attention heads
self.d_k = d_model // num_heads # Dimension of each head's key, query, and value
# Linear layers for transforming inputs
self.W_q = nn.Linear(d_model, d_model) # Query transformation
self.W_k = nn.Linear(d_model, d_model) # Key transformation
self.W_v = nn.Linear(d_model, d_model) # Value transformation
self.W_o = nn.Linear(d_model, d_model) # Output transformation
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# Calculate attention scores
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# Apply mask if provided (useful for preventing attention to certain parts like padding)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# Softmax is applied to obtain attention probabilities
attn_probs = torch.softmax(attn_scores, dim=-1)
# Multiply by values to obtain the final output
output = torch.matmul(attn_probs, V)
return output
def split_heads(self, x):
# Reshape the input to have num_heads for multi-head attention
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
def combine_heads(self, x):
# Combine the multiple heads back to original shape
batch_size, _, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
def forward(self, Q, K, V, mask=None):
# Apply linear transformations and split heads
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# Perform scaled dot-product attention
attn_output = self.scaled_dot_product_attention(Q, K, V, mask)
# Combine heads and apply output transformation
output = self.W_o(self.combine_heads(attn_output))
return outputKlassendefinition und Initialisierung:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):Die Klasse ist als Unterklasse von nn.Module von PyTorch definiert.
d_model: Dimensionalität des Inputs.num_heads: Die Anzahl der Aufmerksamkeitsköpfe, in die die Eingabe aufgeteilt wird.Die Initialisierung prüft, ob d_model durch num_heads teilbar ist, und definiert dann die Transformationsgewichte für query, key, value und output.
Skalierte Aufmerksamkeit des Punktprodukts:
def scaled_dot_product_attention(self, Q, K, V, mask=None):attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k). Hier werden die Aufmerksamkeitswerte berechnet, indem man das Punktprodukt von Abfragen (Q) und Schlüsseln (K) nimmt und dann mit der Quadratwurzel der Schlüsseldimension (d_k) skaliert.V).Köpfe spalten:
def split_heads(self, x):Diese Methode formt die Eingabe x in die Form (batch_size, num_heads, seq_length, d_k) um. Sie ermöglicht es dem Modell, mehrere Aufmerksamkeitsköpfe gleichzeitig zu verarbeiten, sodass eine parallele Berechnung möglich ist.
Köpfe kombinieren:
def combine_heads(self, x):Nachdem die Aufmerksamkeit auf jeden einzelnen Kopf gerichtet wurde, kombiniert diese Methode die Ergebnisse wieder zu einem einzigen Tensor der Form (batch_size, seq_length, d_model). Dadurch wird das Ergebnis für die weitere Verarbeitung vorbereitet.
Vorwärtsmethode:
def forward(self, Q, K, V, mask=None):Bei der Vorwärtsmethode findet die eigentliche Berechnung statt:
Q), Schlüssel (K) und Werte (V) werden zunächst durch lineare Transformationen mit den in der Initialisierung definierten Gewichten geführt.Q, K, V werden mit der Methode split_heads in mehrere Köpfe aufgeteilt.scaled_dot_product_attention wird für die geteilten Köpfe aufgerufen.combine_heads wieder zu einem einzigen Tensor kombiniert.Zusammenfassend lässt sich sagen, dass die Klasse MultiHeadAttention den Multi-Head-Attention-Mechanismus kapselt, der üblicherweise in Transformatorenmodellen verwendet wird. Es sorgt dafür, dass der Input in mehrere Aufmerksamkeitsköpfe aufgeteilt wird, jeder Kopf Aufmerksamkeit erhält und die Ergebnisse dann kombiniert werden. Auf diese Weise kann das Modell verschiedene Beziehungen in den Eingabedaten auf unterschiedlichen Skalen erfassen und die Aussagekraft des Modells verbessern.
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))Klassendefinition:
class PositionWiseFeedForward(nn.Module):Die Klasse ist eine Unterklasse der Klasse nn.Module von PyTorch, d.h. sie erbt alle Funktionen, die für die Arbeit mit neuronalen Netzwerkschichten erforderlich sind.
Initialisierung:
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()d_model: Dimensionalität von Input und Output des Modells.d_ff: Dimensionalität der inneren Schicht im Feed-Forward-Netz.self.fc1 und self.fc2: Zwei vollständig verknüpfte (lineare) Schichten mit Eingangs- und Ausgangsdimensionen, die durch d_model und d_ff definiert sind.self.relu: ReLU (Rectified Linear Unit) Aktivierungsfunktion, die eine Nichtlinearität zwischen den beiden linearen Schichten einführt.Vorwärtsmethode:
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))x: Die Eingabe für das Feed-Forward-Netzwerk.self.fc1(x): Die Eingabe wird zunächst durch die erste lineare Schicht (fc1) geleitet.self.relu(...): Die Ausgabe von fc1 wird dann durch eine ReLU-Aktivierungsfunktion geleitet. ReLU ersetzt alle negativen Werte durch Nullen und bringt so Nichtlinearität in das Modell.self.fc2(...): Die aktivierte Ausgabe wird dann durch die zweite lineare Schicht (fc2) geleitet und erzeugt die endgültige Ausgabe.Zusammenfassend lässt sich sagen, dass die Klasse PositionWiseFeedForward ein positionsbezogenes neuronales Netz mit Vorwärtskopplung definiert, das aus zwei linearen Schichten mit einer ReLU-Aktivierungsfunktion dazwischen besteht. Bei Transformatormodellen wird dieses Feedforward-Netzwerk auf jede Position separat und identisch angewendet. Sie hilft dabei, die von den Aufmerksamkeitsmechanismen gelernten Merkmale innerhalb des Transformators umzuwandeln und fungiert als zusätzlicher Verarbeitungsschritt für die Aufmerksamkeitsausgaben.
Die Positionskodierung wird verwendet, um die Positionsinformationen jedes Tokens in der Eingabesequenz einzubringen. Es verwendet Sinus- und Kosinusfunktionen mit unterschiedlichen Frequenzen, um die Positionskodierung zu erzeugen.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1)]Klassendefinition:
class PositionalEncoding(nn.Module):Die Klasse ist als Unterklasse von PyTorch nn.Module definiert, sodass sie als Standard-PyTorch-Ebene verwendet werden kann.
Initialisierung:
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))d_model: Die Dimension der Eingabe des Modells.max_seq_length: Die maximale Länge der Sequenz, für die Positionskodierungen vorberechnet werden.pe: Ein mit Nullen gefüllter Tensor, der mit Positionskodierungen aufgefüllt wird.position: Ein Tensor, der die Positionsindizes für jede Position in der Sequenz enthält.div_term: Ein Begriff, der verwendet wird, um die Positionsindizes auf eine bestimmte Weise zu skalieren.pe angewendet.pe als Puffer registriert, d.h. er ist Teil des Modulstatus, wird aber nicht als trainierbarer Parameter betrachtet.Vorwärtsmethode:
def forward(self, x):
return x + self.pe[:, :x.size(1)]Bei der Vorwärtsmethode werden die Positionskodierungen einfach zur Eingabe x hinzugefügt.
Sie verwendet die ersten x.size(1) Elemente von pe, um sicherzustellen, dass die Positionskodierungen mit der tatsächlichen Sequenzlänge von x übereinstimmen.
Zusammenfassung
Die Klasse PositionalEncoding fügt Informationen über die Position der Token innerhalb der Sequenz hinzu. Da das Transformatormodell die Reihenfolge der Token nicht kennt (aufgrund seines Selbstbeobachtungsmechanismus), hilft diese Klasse dem Modell, die Position der Token in der Sequenz zu berücksichtigen. Die verwendeten Sinusfunktionen wurden so gewählt, dass das Modell leicht lernen kann, auf relative Positionen zu achten, da sie für jede Position in der Sequenz eine einzigartige und gleichmäßige Kodierung erzeugen.
Abbildung 2. Der Encoder-Teil des Transformatorennetzwerks (Quelle: Bild aus der Originalarbeit)
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xKlassendefinition:
class EncoderLayer(nn.Module):Die Klasse ist als Unterklasse der Klasse nn.Module von PyTorch definiert, was bedeutet, dass sie als Baustein für neuronale Netze in PyTorch verwendet werden kann.
Initialisierung:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parameter:
d_model: Die Dimensionalität der Eingabe.num_heads: Die Anzahl der Aufmerksamkeitsköpfe in der Multi-Head-Aufmerksamkeit.d_ff: Die Dimensionalität der inneren Schicht im positionsweisen Feed-Forward-Netz.dropout: Die Dropout-Rate, die für die Regularisierung verwendet wird.Komponenten:
self.self_attn: Aufmerksamkeitsmechanismus mit mehreren Köpfen.self.feed_forward: Positionsbezogenes neuronales Netz mit Vorwärtskopplung.self.norm1 und self.norm2: Normalisierung der Ebene, um den Eingang der Ebene zu glätten.self.dropout: Dropout-Schicht, die verwendet wird, um eine Überanpassung zu verhindern, indem einige Aktivierungen beim Training zufällig auf Null gesetzt werden.Vorwärtsmethode:
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xEingabe:
x: Die Eingabe für die Encoderschicht.mask: Optionale Maske, um bestimmte Teile des Inputs zu ignorieren.Verarbeitungsschritte:
x wird durch den Mehrkopf-Selbstbehaltmechanismus geleitet.norm1.norm2.Zusammenfassung:
Die Klasse EncoderLayer definiert eine einzelne Schicht des Transformator-Encoders. Es umfasst einen Mechanismus zur Selbstbeobachtung mit mehreren Köpfen, gefolgt von einem neuronalen Netz mit Vorwärtskopplung und Restverbindungen, Normalisierung der Schichten und Dropouts. Zusammen ermöglichen diese Komponenten dem Encoder, komplexe Beziehungen in den Eingabedaten zu erfassen und sie in eine nützliche Darstellung für nachfolgende Aufgaben umzuwandeln. Normalerweise werden mehrere solcher Geberschichten gestapelt, um den kompletten Geberteil eines Transformatormodells zu bilden.
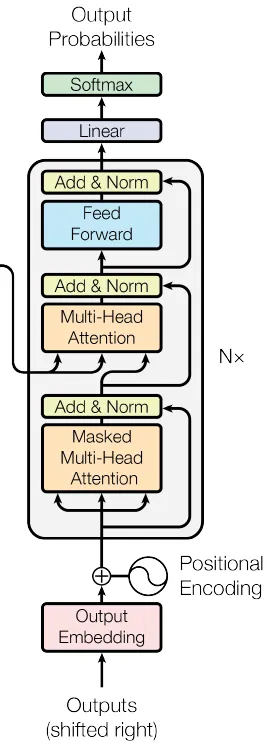
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xKlassendefinition:
class DecoderLayer(nn.Module):Initialisierung:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parameter:
d_model: Die Dimensionalität der Eingabe.num_heads: Die Anzahl der Aufmerksamkeitsköpfe in der Multi-Head-Aufmerksamkeit.d_ff: Die Dimensionalität der inneren Schicht im Feed-Forward-Netz.dropout: Die Abbrecherquote für die Regularisierung.Komponenten:
self.self_attn: Mehrköpfiger Selbstaufmerksamkeitsmechanismus für die Zielsequenz.self.cross_attn: Mehrköpfiger Aufmerksamkeitsmechanismus, der sich um die Ausgabe des Encoders kümmert.self.feed_forward: Positionsbezogenes neuronales Netz mit Vorwärtskopplung.self.norm1, self.norm2, self.norm3: Komponenten zur Normalisierung der Ebenen.self.dropout: Dropout-Schicht für die Regularisierung.Vorwärtsmethode:
ef forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xEingabe:
x: Die Eingabe für die Decoderschicht.enc_output: Der Ausgang des entsprechenden Encoders (der im Schritt "Cross-Attention" verwendet wird).src_mask: Quellenmaske, um bestimmte Teile der Geberausgabe zu ignorieren.tgt_mask: Zielmaske, um bestimmte Teile der Decodereingabe zu ignorieren.Verarbeitungsschritte:
Zusammenfassung:
Die Klasse DecoderLayer definiert eine einzelne Schicht des Decoders des Transformators. Es besteht aus einem Multi-Head-Self-Attention-Mechanismus, einem Multi-Head-Cross-Attention-Mechanismus (der sich um die Ausgabe des Encoders kümmert), einem neuronalen Netzwerk mit Vorwärtskopplung und den entsprechenden Restverbindungen, Schichtnormalisierung und Dropout-Schichten. Diese Kombination ermöglicht es dem Decoder, auf der Grundlage der Repräsentationen des Encoders sinnvolle Ausgaben zu erzeugen, die sowohl die Zielsequenz als auch die Quellsequenz berücksichtigen. Wie beim Encoder werden auch beim Decoder in der Regel mehrere Schichten übereinander gelegt, um den kompletten Decoderteil eines Transformatormodells zu bilden.
Als Nächstes werden die Encoder- und Decoderblöcke kombiniert, um ein umfassendes Transformatormodell zu erstellen.
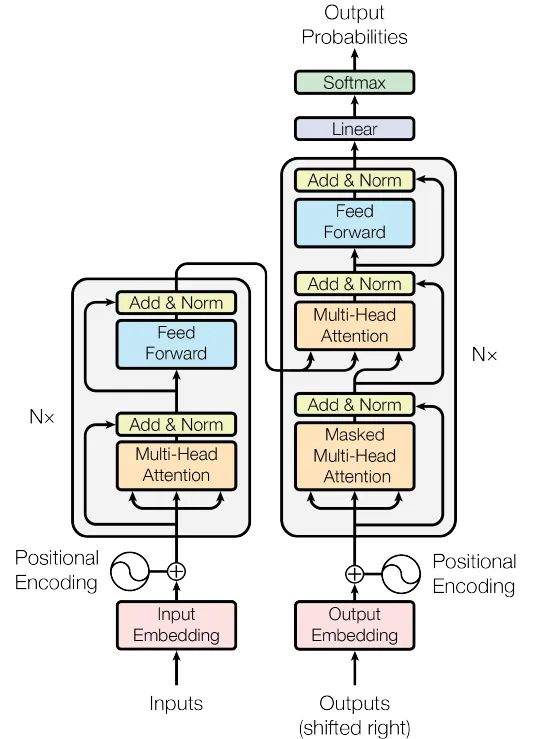
Abbildung 4. Das Transformer Network (Quelle: Bild aus dem Originalbeitrag)
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):
super(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_length)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.fc = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def generate_mask(self, src, tgt):
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.size(1)
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask
return src_mask, tgt_mask
def forward(self, src, tgt):
src_mask, tgt_mask = self.generate_mask(src, tgt)
src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))
tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
output = self.fc(dec_output)
return outputKlassendefinition:
class Transformer(nn.Module):Initialisierung:
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):Der Konstruktor nimmt die folgenden Parameter entgegen:
src_vocab_size: Größe des Quellvokabulars.tgt_vocab_size: Ziel-Wortschatzgröße.d_model: Die Dimensionalität der Einbettungen des Modells.num_heads: Anzahl der Aufmerksamkeitsköpfe im Multi-Head-Attention-Mechanismus.num_layers: Anzahl der Schichten sowohl für den Encoder als auch für den Decoder.d_ff: Dimensionalität der inneren Schicht im Feed-Forward-Netz.max_seq_length: Maximale Sequenzlänge für die Positionskodierung.dropout: Abbrecherquote für die Regularisierung.Und sie definiert die folgenden Komponenten:
self.encoder_embedding: Einbettungsebene für die Quellsequenz.self.decoder_embedding: Einbettungsebene für die Zielsequenz.self.positional_encoding: Komponente zur Positionskodierung.self.encoder_layers: Eine Liste der Geberschichten.self.decoder_layers: Eine Liste der Decoderebenen.self.fc: Endgültige voll verknüpfte (lineare) Schicht, die der Zielvokabelgröße zugeordnet ist.self.dropout: Dropout-Ebene.Erzeuge eine Maske Methode:
def generate_mask(self, src, tgt):Mit dieser Methode werden Masken für die Quell- und die Zielsequenz erstellt. Dadurch wird sichergestellt, dass Auffüllungszeichen ignoriert werden und dass zukünftige Zeichen beim Training der Zielsequenz nicht sichtbar sind.
Vorwärtsmethode:
def forward(self, src, tgt):Diese Methode definiert den Vorwärtspass für den Transformer, der Quell- und Zielsequenzen nimmt und die Ausgabevorhersagen erstellt.
Ausgabe:
Die endgültige Ausgabe ist ein Tensor, der die Vorhersagen des Modells für die Zielsequenz darstellt.
Zusammenfassung:
Die Transformer-Klasse fasst die verschiedenen Komponenten eines Transformer-Modells zusammen, darunter die Einbettungen, die Positionskodierung, die Kodierschichten und die Dekodierschichten. Es bietet eine bequeme Schnittstelle für Training und Inferenz, die die Komplexität von Multi-Head-Attention, Feed-Forward-Netzen und Layer-Normalisierung in sich vereint.
Diese Implementierung folgt der Standard-Transformer-Architektur, wodurch sie sich für Sequenz-zu-Sequenz-Aufgaben wie maschinelle Übersetzung, Textzusammenfassung usw. eignet. Die Maskierung stellt sicher, dass das Modell die kausalen Abhängigkeiten innerhalb der Sequenzen einhält, indem es auffüllende Token ignoriert und verhindert, dass Informationen aus zukünftigen Token verloren gehen.
Diese aufeinanderfolgenden Schritte befähigen das Transformer-Modell, Eingangssequenzen effizient zu verarbeiten und entsprechende Ausgangssequenzen zu produzieren.
Zur Veranschaulichung wird in diesem Beispiel ein Dummy-Datensatz erstellt. In einem praktischen Szenario würde jedoch ein umfangreicherer Datensatz verwendet werden, und der Prozess würde eine Textvorverarbeitung zusammen mit der Erstellung von Vokabelzuordnungen sowohl für die Ausgangs- als auch die Zielsprache beinhalten.
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_seq_length = 100
dropout = 0.1
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)
# Generate random sample data
src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)Hyperparameter:
Diese Werte definieren die Architektur und das Verhalten des Transformatormodells:
src_vocab_size, tgt_vocab_size: Vokabelgrößen für Quell- und Zielsequenzen, beide auf 5000 gesetzt.d_model: Dimensionalität der Einbettungen des Modells, eingestellt auf 512.num_heads: Anzahl der Aufmerksamkeitsköpfe im Multi-Head-Attention-Mechanismus, eingestellt auf 8.num_layers: Anzahl der Schichten für den Encoder und den Decoder, eingestellt auf 6.d_ff: Dimensionalität der inneren Schicht im Feed-Forward-Netz, eingestellt auf 2048.max_seq_length: Maximale Sequenzlänge für die Positionskodierung, festgelegt auf 100.dropout: Dropout-Rate für die Regularisierung, eingestellt auf 0,1.In der folgenden Tabelle sind die gängigsten Hyperparameter für Transformer-Modelle und ihre Werte beschrieben:
| Hyperparameter | Typische Werte | Auswirkungen auf die Leistung |
|---|---|---|
| d_model | 256, 512, 1024 | Höhere Werte erhöhen die Modellkapazität, erfordern aber mehr Berechnungen |
| num_heads | 8, 12, 16 | Mehr Köpfe können verschiedene Aspekte der Daten erfassen, sind aber rechenintensiv |
| num_layers | 6, 12, 24 | Mehr Schichten verbessern die Darstellungsleistung, können aber zu einer Überanpassung führen |
| d_ff | 2048, 4096 | Größere Feed-Forward-Netzwerke erhöhen die Robustheit des Modells |
| Aussteigerin | 0.1, 0.3 | Regularisiert das Modell, um eine Überanpassung zu verhindern |
| Lernquote | 0.0001 - 0.001 | Auswirkungen auf Konvergenzgeschwindigkeit und Stabilität |
| Losgröße | 32, 64, 128 | Größere Losgrößen verbessern die Lernstabilität, erfordern aber mehr Speicherplatz |
Erstellen einer Transformer-Instanz:
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)Diese Zeile erstellt eine Instanz der Klasse Transformer und initialisiert sie mit den angegebenen Hyperparametern. Die Instanz hat die Architektur und das Verhalten, das durch diese Hyperparameter definiert wird.
Erzeugen von Stichprobendaten:
Die folgenden Zeilen erzeugen zufällige Quell- und Zielsequenzen:
src_data: Zufällige ganze Zahlen zwischen 1 und src_vocab_size, die einen Stapel von Quellsequenzen mit der Form (64, max_seq_length) darstellen.tgt_data: Zufällige ganze Zahlen zwischen 1 und tgt_vocab_size, die einen Stapel von Zielsequenzen mit der Form (64, max_seq_length) darstellen.Zusammenfassung:
Das Codeschnipsel zeigt, wie man ein Transformer-Modell initialisiert und zufällige Quell- und Zielsequenzen erzeugt, die in das Modell eingespeist werden können. Die gewählten Hyperparameter bestimmen die spezifische Struktur und die Eigenschaften des Transformers. Dieses Setup könnte Teil eines größeren Skripts sein, in dem das Modell für tatsächliche Sequenz-zu-Sequenz-Aufgaben wie maschinelle Übersetzung oder Textzusammenfassung trainiert und bewertet wird.
Als Nächstes wird das Modell mit den oben erwähnten Beispieldaten trainiert. In einem realen Szenario würde jedoch ein wesentlich größerer Datensatz verwendet werden, der in der Regel in verschiedene Sätze für Trainings- und Validierungszwecke aufgeteilt wird.
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
transformer.train()
for epoch in range(100):
optimizer.zero_grad()
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:].contiguous().view(-1))
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")Verlustfunktion und Optimierer:
criterion = nn.CrossEntropyLoss(ignore_index=0): Definiert die Verlustfunktion als Kreuzentropieverlust. Das Argument ignore_index wird auf 0 gesetzt, was bedeutet, dass der Verlust Ziele mit einem Index von 0 (normalerweise für Auffüllungs-Token reserviert) nicht berücksichtigt.optimizer = optim.Adam(...): Definiert den Optimierer als Adam mit einer Lernrate von 0,0001 und bestimmten Beta-Werten.Modellschulungsmodus:
transformer.train(): Setzt das Transformatormodell in den Trainingsmodus und ermöglicht so Verhaltensweisen wie Dropout, die nur während des Trainings gelten.Trainingsschleife:
Das Codeschnipsel trainiert das Modell für 100 Epochen mit einer typischen Trainingsschleife:
for epoch in range(100): Iteriert über 100 Trainingsepochen.optimizer.zero_grad(): Löscht die Farbverläufe aus der vorherigen Iteration.output = transformer(src_data, tgt_data[:, :-1]): Lässt die Quelldaten und die Zieldaten (mit Ausnahme des letzten Tokens in jeder Sequenz) durch den Transformer laufen. Das ist üblich bei Sequenz-zu-Sequenz-Aufgaben, bei denen das Ziel um ein Token verschoben wird.loss = criterion(...): Berechnet den Verlust zwischen den Vorhersagen des Modells und den Zieldaten (mit Ausnahme des ersten Tokens in jeder Sequenz). Der Verlust wird berechnet, indem die Daten in eindimensionale Tensoren umgewandelt werden und die Kreuzentropie-Verlustfunktion verwendet wird.loss.backward(): Berechnet die Gradienten des Verlusts in Bezug auf die Parameter des Modells.optimizer.step(): Aktualisiert die Parameter des Modells anhand der berechneten Gradienten.print(f"Epoch: {epoch+1}, Loss: {loss.item()}"): Gibt die aktuelle Epochennummer und den Verlustwert für diese Epoche aus.Zusammenfassung:
Dieses Codeschnipsel trainiert das Transformationsmodell auf zufällig generierten Quell- und Zielsequenzen für 100 Epochen. Sie verwendet den Adam-Optimierer und die Cross-Entropy-Verlustfunktion. Der Verlust wird für jede Epoche ausgedruckt, so dass du den Trainingsfortschritt verfolgen kannst. In einem realen Szenario würdest du die zufälligen Quell- und Zielsequenzen durch tatsächliche Daten aus deiner Aufgabe, wie z.B. der maschinellen Übersetzung, ersetzen.
Nachdem das Modell trainiert wurde, kann seine Leistung anhand eines Validierungs- oder Testdatensatzes bewertet werden. Im Folgenden findest du ein Beispiel dafür, wie dies geschehen könnte:
transformer.eval()
# Generate random sample validation data
val_src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
val_tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
with torch.no_grad():
val_output = transformer(val_src_data, val_tgt_data[:, :-1])
val_loss = criterion(val_output.contiguous().view(-1, tgt_vocab_size), val_tgt_data[:, 1:].contiguous().view(-1))
print(f"Validation Loss: {val_loss.item()}")Bewertungsmodus:
transformer.eval(): Schaltet das Transformatormodell in den Bewertungsmodus. Das ist wichtig, denn dadurch werden bestimmte Verhaltensweisen wie z.B. das Abbrechen ausgeschaltet, die nur im Training verwendet werden.Erstelle zufällige Validierungsdaten:
val_src_data: Zufällige ganze Zahlen zwischen 1 und src_vocab_size, die einen Stapel von Validierungsquellensequenzen mit der Form (64, max_seq_length) darstellen.val_tgt_data: Zufällige ganze Zahlen zwischen 1 und tgt_vocab_size, die einen Stapel von Validierungszielsequenzen mit der Form (64, max_seq_length) darstellen.Validierungsschleife:
with torch.no_grad(): Deaktiviert die Gradientenberechnung, da wir während der Validierung keine Gradienten berechnen müssen. Das kann den Speicherverbrauch reduzieren und die Berechnungen beschleunigen.val_output = transformer(val_src_data, val_tgt_data[:, :-1]): Leitet die Validierungsquelldaten und die Validierungszieldaten (mit Ausnahme des letzten Tokens in jeder Sequenz) durch den Transformator.val_loss = criterion(...): Berechnet den Verlust zwischen den Vorhersagen des Modells und den Validierungs-Zieldaten (mit Ausnahme des ersten Tokens in jeder Sequenz). Der Verlust wird berechnet, indem die Daten in eindimensionale Tensoren umgewandelt werden und die zuvor definierte Kreuzentropie-Verlustfunktion verwendet wird.print(f"Validation Loss: {val_loss.item()}"): Druckt den Wert des Validierungsverlustes aus.Zusammenfassung:
Dieses Codeschnipsel evaluiert das Transformatormodell auf einem zufällig generierten Validierungsdatensatz, berechnet den Validierungsverlust und gibt ihn aus. In einem realen Szenario sollten die zufälligen Validierungsdaten durch tatsächliche Validierungsdaten aus der Aufgabe, an der du arbeitest, ersetzt werden. Der Validierungsverlust kann dir einen Hinweis darauf geben, wie gut dein Modell bei ungesehenen Daten abschneidet, was ein wichtiges Maß für die Generalisierungsfähigkeit des Modells ist.
Weitere Informationen zu Transformers und Hugging Face findest du in unserem Tutorial, An Introduction to Using Transformers and Hugging Face.
Abschließend wurde in diesem Tutorial gezeigt, wie man mit PyTorch, einem der vielseitigsten Tools für Deep Learning, ein Transformer-Modell konstruiert. Mit ihrer Fähigkeit zur Parallelisierung und der Möglichkeit, langfristige Abhängigkeiten in Daten zu erfassen, haben Transformers ein immenses Potenzial in verschiedenen Bereichen, insbesondere bei NLP-Aufgaben wie Übersetzung, Zusammenfassung und Sentimentanalyse.
Wenn du dein Wissen über fortgeschrittene Deep Learning-Konzepte und -Techniken vertiefen möchtest, solltest du den Kurs Advanced Deep Learning with Keras auf DataCamp besuchen. Du kannst auch in einem separaten Tutorial nachlesen, wie du ein einfaches neuronales Netzwerk mit PyTorch aufbaust.
Lerne mehr über PyTorch mit diesen Kursen!
Kurs
Kurs
Kurs
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Satyabrata Pal
Tutorial
Moez Ali