
Curso
Introdução ao Aprendizado Profundo com o PyTorch
4 h
85.9K
Apresentados pela primeira vez no artigo Attention is All You Need (A atenção é tudo o que você precisa ), de Vaswani et al., os transformadores se tornaram a base de muitas tarefas de PNL devido ao seu design exclusivo e à sua eficácia.
No centro do Transformers está o mecanismo de atenção, especificamente o conceito de "autoatenção", que permite que o modelo pondere e priorize diferentes partes dos dados de entrada. Esse mecanismo permite que os transformadores gerenciem dependências de longo alcance nos dados. Trata-se fundamentalmente de um esquema de ponderação que permite que um modelo se concentre em diferentes partes da entrada ao produzir uma saída.
O mecanismo de autoatenção permite que o modelo considere diferentes palavras ou recursos na sequência de entrada, atribuindo a cada um deles um "peso" que significa sua importância para produzir um determinado resultado. Por exemplo, em uma tarefa de tradução de frases, ao traduzir uma determinada palavra, o modelo pode atribuir pesos de atenção maiores a palavras gramatical ou semanticamente relacionadas à palavra-alvo. Esse processo permite que o Transformer capture dependências entre palavras ou recursos, independentemente da distância entre eles na sequência.
O impacto do Transformers no campo da PNL não pode ser subestimado. Eles superaram os modelos tradicionais em muitas tarefas, demonstrando uma capacidade superior de compreender e gerar linguagem humana com mais nuances.
Para que você tenha uma compreensão mais profunda da PNL, o curso Introduction to Natural Language Processing in Python da DataCamp é um recurso recomendado.
Antes de construir um transformador, é essencial que você configure corretamente o ambiente de trabalho. Em primeiro lugar, o PyTorch precisa ser instalado. O PyTorch pode ser instalado por meio dos gerenciadores de pacotes pip ou conda.
Para o pip, use o comando:
pip3 install torch torchvision torchaudioPara o conda, use o comando:
conda install pytorch torchvision -c pytorchPara outras opções de instalação e execução do PyTorch, consulte o site oficial.
Além disso, é bom que você tenha uma compreensão básica dos conceitos de aprendizagem profunda, pois eles serão fundamentais para entender a operação dos Transformers. Para aqueles que precisam de uma atualização, o curso DataCamp Deep Learning in Python é um recurso valioso que abrange os principais conceitos de aprendizagem profunda.
Para criar o modelo do transformador, são necessárias as seguintes etapas:
Começaremos importando a biblioteca PyTorch para a funcionalidade principal, o módulo de rede neural para criar redes neurais, o módulo de otimização para treinar redes e as funções de utilitário de dados para manipular dados. Além disso, importaremos o módulo padrão do Python math para operações matemáticas e o módulo copy para criar cópias de objetos complexos.
Essas ferramentas estabelecem a base para definir a arquitetura do modelo, gerenciar dados e estabelecer o processo de treinamento.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import math
import copyAntes de começarmos a construir nossos componentes, dê uma olhada na tabela a seguir, que descreve os diferentes componentes de um transformador e sua finalidade:
| Componente | Descrição | Finalidade |
|---|---|---|
| Atenção Multi-Head | Mecanismo para focar em diferentes partes da entrada | Captura dependências em diferentes posições na sequência |
| Redes feed-forward | Camadas totalmente conectadas em termos de posição | Transforma as saídas de atenção, adicionando complexidade |
| Codificação posicional | Adiciona informações de posição aos embeddings | Fornece contexto de ordem de sequência para o modelo |
| Normalização de camadas | Normaliza as entradas para cada subcamada | Estabiliza o treinamento e melhora a convergência |
| Conexões residuais | Atalhos entre camadas | Ajuda a treinar redes mais profundas, minimizando os problemas de gradiente |
| Desistência | Zera aleatoriamente algumas conexões de rede | Evita o excesso de ajuste ao regularizar o modelo |
O mecanismo de atenção de várias cabeças calcula a atenção entre cada par de posições em uma sequência. Ele consiste em várias "cabeças de atenção" que capturam diferentes aspectos da sequência de entrada.
Para saber mais sobre a atenção de várias cabeças, confira a seção de mecanismos de atenção do curso Conceitos de modelos de linguagem grande (LLMs).
Figura 1. Atenção a várias cabeças (fonte: imagem criada pelo autor)
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
# Ensure that the model dimension (d_model) is divisible by the number of heads
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
# Initialize dimensions
self.d_model = d_model # Model's dimension
self.num_heads = num_heads # Number of attention heads
self.d_k = d_model // num_heads # Dimension of each head's key, query, and value
# Linear layers for transforming inputs
self.W_q = nn.Linear(d_model, d_model) # Query transformation
self.W_k = nn.Linear(d_model, d_model) # Key transformation
self.W_v = nn.Linear(d_model, d_model) # Value transformation
self.W_o = nn.Linear(d_model, d_model) # Output transformation
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# Calculate attention scores
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# Apply mask if provided (useful for preventing attention to certain parts like padding)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# Softmax is applied to obtain attention probabilities
attn_probs = torch.softmax(attn_scores, dim=-1)
# Multiply by values to obtain the final output
output = torch.matmul(attn_probs, V)
return output
def split_heads(self, x):
# Reshape the input to have num_heads for multi-head attention
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
def combine_heads(self, x):
# Combine the multiple heads back to original shape
batch_size, _, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
def forward(self, Q, K, V, mask=None):
# Apply linear transformations and split heads
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# Perform scaled dot-product attention
attn_output = self.scaled_dot_product_attention(Q, K, V, mask)
# Combine heads and apply output transformation
output = self.W_o(self.combine_heads(attn_output))
return outputDefinição e inicialização da classe:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):A classe é definida como uma subclasse da nn.Module do PyTorch.
d_model: Dimensionalidade da entrada.num_heads: O número de cabeças de atenção em que você deve dividir a entrada.A inicialização verifica se d_model é divisível por num_heads e, em seguida, define os pesos de transformação para query, key, value e output.
Atenção ao produto escalonado de pontos:
def scaled_dot_product_attention(self, Q, K, V, mask=None):attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k). Aqui, as pontuações de atenção são calculadas tomando o produto escalar das consultas (Q) e das chaves (K) e, em seguida, escalonando pela raiz quadrada da dimensão da chave (d_k).V).Cabeças divididas:
def split_heads(self, x):Esse método remodela a entrada x na forma (batch_size, num_heads, seq_length, d_k). Ele permite que o modelo processe vários cabeçotes de atenção simultaneamente, possibilitando a computação paralela.
Combinando cabeças:
def combine_heads(self, x):Depois de aplicar a atenção a cada cabeça separadamente, esse método combina os resultados em um único tensor de forma (batch_size, seq_length, d_model). Isso prepara o resultado para processamento posterior.
Método de encaminhamento:
def forward(self, Q, K, V, mask=None):O método avançado é onde ocorre o cálculo real:
Q), as chaves (K) e os valores (V) passam primeiro por transformações lineares usando os pesos definidos na inicialização.Q, K, V são divididos em várias cabeças usando o método split_heads.scaled_dot_product_attention é chamado nos cabeçotes divididos.combine_heads.Em resumo, a classe MultiHeadAttention encapsula o mecanismo de atenção de várias cabeças comumente usado em modelos de transformadores. Ele se encarrega de dividir a entrada em várias cabeças de atenção, aplicando atenção a cada cabeça e, em seguida, combinando os resultados. Ao fazer isso, o modelo pode capturar várias relações nos dados de entrada em diferentes escalas, melhorando a capacidade expressiva do modelo.
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))Definição de classe:
class PositionWiseFeedForward(nn.Module):A classe é uma subclasse da nn.Module do PyTorch, o que significa que ela herdará todas as funcionalidades necessárias para trabalhar com camadas de redes neurais.
Inicialização:
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()d_model: Dimensionalidade da entrada e saída do modelo.d_ff: Dimensionalidade da camada interna na rede feed-forward.self.fc1 e self.fc2: Duas camadas totalmente conectadas (lineares) com dimensões de entrada e saída definidas por d_model e d_ff.self.relu: Função de ativação ReLU (Rectified Linear Unit), que introduz a não linearidade entre as duas camadas lineares.Método de encaminhamento:
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))x: A entrada para a rede feed-forward.self.fc1(x): A entrada passa primeiro pela primeira camada linear (fc1).self.relu(...): A saída do site fc1 é então passada por uma função de ativação ReLU. O ReLU substitui todos os valores negativos por zeros, introduzindo a não linearidade no modelo.self.fc2(...): A saída ativada é então passada pela segunda camada linear (fc2), produzindo a saída final.Em resumo, a classe PositionWiseFeedForward define uma rede neural feed-forward com base na posição que consiste em duas camadas lineares com uma função de ativação ReLU no meio. No contexto dos modelos de transformadores, essa rede de alimentação é aplicada a cada posição separadamente e de forma idêntica. Ele ajuda a transformar os recursos aprendidos pelos mecanismos de atenção dentro do transformador, atuando como uma etapa de processamento adicional para os resultados da atenção.
A codificação posicional é usada para injetar as informações de posição de cada token na sequência de entrada. Ele usa funções senoidais e cossenoidais de diferentes frequências para gerar a codificação posicional.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1)]Definição de classe:
class PositionalEncoding(nn.Module):A classe é definida como uma subclasse da nn.Module do PyTorch, permitindo que ela seja usada como uma camada padrão do PyTorch.
Inicialização:
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))d_model: A dimensão da entrada do modelo.max_seq_length: O comprimento máximo da sequência para a qual as codificações posicionais são pré-computadas.pe: Um tensor preenchido com zeros, que será preenchido com codificações posicionais.position: Um tensor que contém os índices de posição para cada posição na sequência.div_term: Um termo usado para dimensionar os índices de posição de uma maneira específica.pe.pe é registrado como um buffer, o que significa que ele fará parte do estado do módulo, mas não será considerado um parâmetro treinável.Método de encaminhamento:
def forward(self, x):
return x + self.pe[:, :x.size(1)]O método avançado simplesmente adiciona as codificações posicionais à entrada x.
Ele usa os primeiros x.size(1) elementos de pe para garantir que as codificações posicionais correspondam ao comprimento real da sequência de x.
Resumo
A classe PositionalEncoding adiciona informações sobre a posição dos tokens na sequência. Como o modelo de transformador não tem conhecimento inerente da ordem dos tokens (devido ao seu mecanismo de autoatenção), essa classe ajuda o modelo a considerar a posição dos tokens na sequência. As funções senoidais usadas foram escolhidas para permitir que o modelo aprenda facilmente a atender às posições relativas, pois elas produzem uma codificação única e suave para cada posição na sequência.
Figura 2. A parte do codificador da rede do transformador (Fonte: imagem do documento original)
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xDefinição de classe:
class EncoderLayer(nn.Module):A classe é definida como uma subclasse da nn.Module do PyTorch, o que significa que ela pode ser usada como um bloco de construção para redes neurais no PyTorch.
Inicialização:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parâmetros:
d_model: A dimensionalidade da entrada.num_heads: O número de cabeças de atenção na atenção com várias cabeças.d_ff: A dimensionalidade da camada interna na rede feed-forward de posição.dropout: A taxa de desistência usada para regularização.Componentes:
self.self_attn: Mecanismo de atenção com várias cabeças.self.feed_forward: Rede neural feed-forward com base na posição.self.norm1 e self.norm2: Normalização da camada, aplicada para suavizar a entrada da camada.self.dropout: Camada de abandono, usada para evitar o ajuste excessivo, definindo aleatoriamente algumas ativações como zero durante o treinamento.Método de encaminhamento:
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xEntrada:
x: A entrada para a camada do codificador.mask: Máscara opcional para ignorar determinadas partes da entrada.Etapas de processamento:
x é passada pelo mecanismo de autoatenção de várias cabeças.norm1.norm2.Resumo:
A classe EncoderLayer define uma única camada do codificador do transformador. Ele engloba um mecanismo de autoatenção de várias cabeças seguido pela rede neural feed-forward de posição, com conexões residuais, normalização de camadas e abandono aplicados conforme apropriado. Juntos, esses componentes permitem que o codificador capture relações complexas nos dados de entrada e as transforme em uma representação útil para tarefas posteriores. Normalmente, várias dessas camadas de codificador são empilhadas para formar a parte completa do codificador de um modelo de transformador.
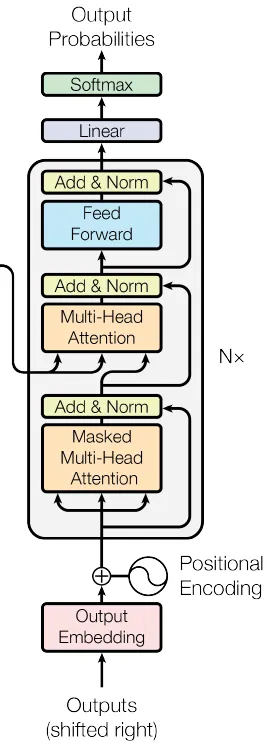
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xDefinição de classe:
class DecoderLayer(nn.Module):Inicialização:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parâmetros:
d_model: A dimensionalidade da entrada.num_heads: O número de cabeças de atenção na atenção com várias cabeças.d_ff: A dimensionalidade da camada interna na rede feed-forward.dropout: A taxa de desistência para regularização.Componentes:
self.self_attn: Mecanismo de autoatenção de várias cabeças para a sequência alvo.self.cross_attn: Mecanismo de atenção com várias cabeças que atende à saída do codificador.self.feed_forward: Rede neural feed-forward com base na posição.self.norm1, self.norm2, self.norm3: Componentes de normalização de camadas.self.dropout: Camada de abandono para regularização.Métodode encaminhamento:
ef forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xEntrada:
x: A entrada para a camada do decodificador.enc_output: A saída do codificador correspondente (usado na etapa de atenção cruzada).src_mask: Máscara de origem para ignorar determinadas partes da saída do codificador.tgt_mask: Máscara de destino para ignorar determinadas partes da entrada do decodificador.Etapas de processamento:
Resumo:
A classe DecoderLayer define uma única camada do decodificador do transformador. Ele consiste em um mecanismo de autoatenção de várias cabeças, um mecanismo de atenção cruzada de várias cabeças (que atende à saída do codificador), uma rede neural de avanço de posição e as conexões residuais correspondentes, a normalização da camada e as camadas de abandono. Essa combinação permite que o decodificador gere saídas significativas com base nas representações do codificador, levando em conta tanto a sequência de destino quanto a sequência de origem. Assim como no codificador, várias camadas do decodificador são normalmente empilhadas para formar a parte completa do decodificador de um modelo de transformador.
Em seguida, os blocos codificador e decodificador são combinados para criar o modelo abrangente do transformador.
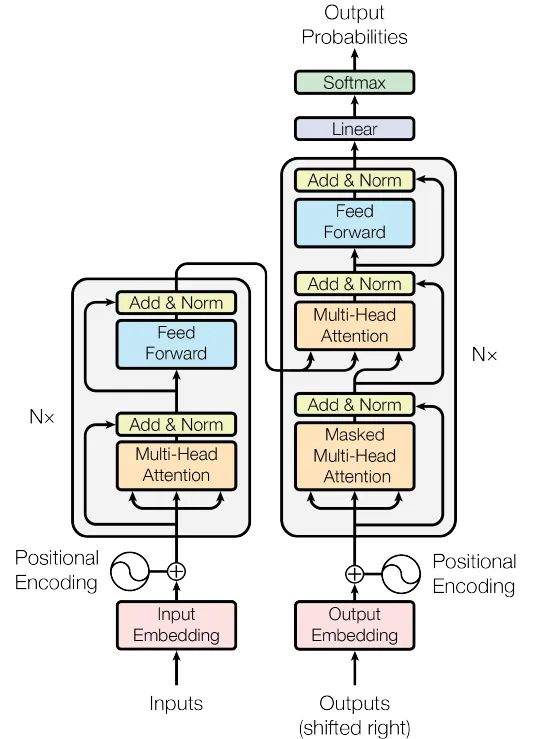
Figura 4. A Rede de Transformadores (Fonte: Imagem do artigo original)
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):
super(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_length)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.fc = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def generate_mask(self, src, tgt):
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.size(1)
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask
return src_mask, tgt_mask
def forward(self, src, tgt):
src_mask, tgt_mask = self.generate_mask(src, tgt)
src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))
tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
output = self.fc(dec_output)
return outputDefinição de classe:
class Transformer(nn.Module):Inicialização:
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):O construtor recebe os seguintes parâmetros:
src_vocab_size: Tamanho do vocabulário da fonte.tgt_vocab_size: Tamanho do vocabulário-alvo.d_model: A dimensionalidade dos embeddings do modelo.num_heads: Número de cabeças de atenção no mecanismo de atenção com várias cabeças.num_layers: Número de camadas para o codificador e o decodificador.d_ff: Dimensionalidade da camada interna na rede feed-forward.max_seq_length: Comprimento máximo da sequência para codificação posicional.dropout: Taxa de abandono para regularização.E define os seguintes componentes:
self.encoder_embedding: Camada de incorporação para a sequência de origem.self.decoder_embedding: Camada de incorporação para a sequência de destino.self.positional_encoding: Componente de codificação posicional.self.encoder_layers: Uma lista de camadas de codificador.self.decoder_layers: Uma lista de camadas de decodificador.self.fc: Mapeamento da camada final totalmente conectada (linear) para o tamanho do vocabulário de destino.self.dropout: Camada de abandono.Método de geração de máscara:
def generate_mask(self, src, tgt):Esse método é usado para criar máscaras para as sequências de origem e de destino, garantindo que os tokens de preenchimento sejam ignorados e que os tokens futuros não sejam visíveis durante o treinamento da sequência de destino.
Método de encaminhamento:
def forward(self, src, tgt):Esse método define a passagem direta para o Transformer, pegando as sequências de origem e destino e produzindo as previsões de saída.
Saída:
O resultado final é um tensor que representa as previsões do modelo para a sequência de destino.
Resumo:
A classe Transformer reúne os vários componentes de um modelo Transformer, incluindo os embeddings, a codificação posicional, as camadas do codificador e as camadas do decodificador. Ele oferece uma interface conveniente para treinamento e inferência, encapsulando as complexidades da atenção a várias cabeças, redes feed-forward e normalização de camadas.
Essa implementação segue a arquitetura padrão do Transformer, tornando-o adequado para tarefas de sequência a sequência, como tradução automática, resumo de texto etc. A inclusão do mascaramento garante que o modelo siga as dependências causais dentro das sequências, ignorando os tokens de preenchimento e evitando o vazamento de informações de tokens futuros.
Essas etapas sequenciais capacitam o modelo Transformer a processar com eficiência as sequências de entrada e produzir as sequências de saída correspondentes.
Para fins ilustrativos, um conjunto de dados fictício será criado neste exemplo. No entanto, em um cenário prático, um conjunto de dados mais substancial seria empregado, e o processo envolveria o pré-processamento de texto juntamente com a criação de mapeamentos de vocabulário para os idiomas de origem e de destino.
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_seq_length = 100
dropout = 0.1
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)
# Generate random sample data
src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)Hiperparâmetros:
Esses valores definem a arquitetura e o comportamento do modelo do transformador:
src_vocab_size, tgt_vocab_size: Tamanhos de vocabulário para sequências de origem e destino, ambas definidas como 5000.d_model: Dimensionalidade dos embeddings do modelo, definida como 512.num_heads: Número de cabeças de atenção no mecanismo de atenção com várias cabeças, definido como 8.num_layers: Número de camadas para o codificador e o decodificador, definido como 6.d_ff: Dimensionalidade da camada interna na rede feed-forward, definida como 2048.max_seq_length: Comprimento máximo da sequência para codificação posicional, definido como 100.dropout: Taxa de abandono para regularização, definida como 0,1.Para referência, a tabela a seguir descreve os hiperparâmetros mais comuns para modelos de transformador e seus valores:
| Hiperparâmetro | Valores típicos | Impacto no desempenho |
|---|---|---|
| d_model | 256, 512, 1024 | Valores mais altos aumentam a capacidade do modelo, mas exigem mais computação |
| num_heads | 8, 12, 16 | Mais cabeças podem capturar diversos aspectos dos dados, mas são computacionalmente intensivas |
| num_layers | 6, 12, 24 | Mais camadas melhoram o poder de representação, mas podem levar a um ajuste excessivo |
| d_ff | 2048, 4096 | Redes feed-forward maiores aumentam a robustez do modelo |
| abandono | 0.1, 0.3 | Regulariza o modelo para evitar o ajuste excessivo |
| taxa de aprendizado | 0.0001 - 0.001 | Impacta a velocidade e a estabilidade da convergência |
| tamanho do lote | 32, 64, 128 | Tamanhos maiores de lotes melhoram a estabilidade da aprendizagem, mas exigem mais memória |
Criando uma instância do Transformer:
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)Essa linha cria uma instância da classe Transformer, inicializando-a com os hiperparâmetros fornecidos. A instância terá a arquitetura e o comportamento definidos por esses hiperparâmetros.
Geração de dados de amostras aleatórias:
As linhas a seguir geram sequências aleatórias de origem e destino:
src_data: Inteiros aleatórios entre 1 e src_vocab_size, representando um lote de sequências de origem com formato (64, max_seq_length).tgt_data: Inteiros aleatórios entre 1 e tgt_vocab_size, representando um lote de sequências de destino com formato (64, max_seq_length).Resumo:
O trecho de código demonstra como inicializar um modelo Transformer e gerar sequências aleatórias de origem e destino que podem ser alimentadas nele. Os hiperparâmetros escolhidos determinam a estrutura e as propriedades específicas do Transformer. Essa configuração pode fazer parte de um script maior em que o modelo é treinado e avaliado em tarefas reais de sequência a sequência, como tradução automática ou resumo de texto.
Em seguida, o modelo será treinado utilizando os dados de amostra mencionados anteriormente. No entanto, em um cenário do mundo real, seria empregado um conjunto de dados significativamente maior, que normalmente seria particionado em conjuntos distintos para fins de treinamento e validação.
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
transformer.train()
for epoch in range(100):
optimizer.zero_grad()
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:].contiguous().view(-1))
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")Função de perda e otimizador:
criterion = nn.CrossEntropyLoss(ignore_index=0): Define a função de perda como perda de entropia cruzada. O argumento ignore_index é definido como 0, o que significa que a perda não considerará alvos com um índice de 0 (normalmente reservado para tokens de preenchimento).optimizer = optim.Adam(...): Define o otimizador como Adam com uma taxa de aprendizado de 0,0001 e valores beta específicos.Modo de treinamento de modelos:
transformer.train(): Define o modelo do transformador para o modo de treinamento, ativando comportamentos como o abandono que só se aplicam durante o treinamento.Circuito de treinamento:
O trecho de código treina o modelo por 100 épocas usando um loop de treinamento típico:
for epoch in range(100): Itera mais de 100 épocas de treinamento.optimizer.zero_grad(): Limpa os gradientes da iteração anterior.output = transformer(src_data, tgt_data[:, :-1]): Passa os dados de origem e os dados de destino (excluindo o último token em cada sequência) pelo transformador. Isso é comum em tarefas de sequência a sequência em que o alvo é deslocado em um token.loss = criterion(...): Calcula a perda entre as previsões do modelo e os dados de destino (excluindo o primeiro token em cada sequência). A perda é calculada remodelando os dados em tensores unidimensionais e usando a função de perda de entropia cruzada.loss.backward(): Calcula os gradientes da perda em relação aos parâmetros do modelo.optimizer.step(): Atualiza os parâmetros do modelo usando os gradientes computados.print(f"Epoch: {epoch+1}, Loss: {loss.item()}"): Imprime o número da época atual e o valor da perda para essa época.Resumo:
Esse trecho de código treina o modelo do transformador em sequências de origem e destino geradas aleatoriamente por 100 épocas. Ele usa o otimizador Adam e a função de perda de entropia cruzada. A perda é impressa para cada época, permitindo que você monitore o progresso do treinamento. Em um cenário do mundo real, você substituiria as sequências aleatórias de origem e destino por dados reais da sua tarefa, como tradução automática.
Depois de treinar o modelo, seu desempenho pode ser avaliado em um conjunto de dados de validação ou de teste. A seguir, um exemplo de como isso poderia ser feito:
transformer.eval()
# Generate random sample validation data
val_src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
val_tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
with torch.no_grad():
val_output = transformer(val_src_data, val_tgt_data[:, :-1])
val_loss = criterion(val_output.contiguous().view(-1, tgt_vocab_size), val_tgt_data[:, 1:].contiguous().view(-1))
print(f"Validation Loss: {val_loss.item()}")Modo de avaliação:
transformer.eval(): Coloca o modelo do transformador no modo de avaliação. Isso é importante porque desativa determinados comportamentos, como o abandono, que são usados somente durante o treinamento.Gerar dados de validação aleatórios:
val_src_data: Inteiros aleatórios entre 1 e src_vocab_size, representando um lote de sequências de origem de validação com formato (64, max_seq_length).val_tgt_data: Inteiros aleatórios entre 1 e tgt_vocab_size, representando um lote de sequências-alvo de validação com formato (64, max_seq_length).Loop de validação:
with torch.no_grad(): Desativa o cálculo do gradiente, pois não precisamos calcular gradientes durante a validação. Isso pode reduzir o consumo de memória e acelerar os cálculos.val_output = transformer(val_src_data, val_tgt_data[:, :-1]): Passa os dados de origem da validação e os dados de destino da validação (excluindo o último token em cada sequência) pelo transformador.val_loss = criterion(...): Calcula a perda entre as previsões do modelo e os dados de destino da validação (excluindo o primeiro token em cada sequência). A perda é calculada remodelando os dados em tensores unidimensionais e usando a função de perda de entropia cruzada definida anteriormente.print(f"Validation Loss: {val_loss.item()}"): Imprime o valor da perda de validação.Resumo:
Esse trecho de código avalia o modelo de transformação em um conjunto de dados de validação gerado aleatoriamente, calcula a perda de validação e a imprime. Em um cenário do mundo real, os dados de validação aleatórios devem ser substituídos por dados de validação reais da tarefa em que você está trabalhando. A perda de validação pode dar a você uma indicação do desempenho do seu modelo em dados não vistos, o que é uma medida crítica da capacidade de generalização do modelo.
Para obter mais detalhes sobre Transformers e Hugging Face, nosso tutorial, Uma introdução ao uso de Transformers e Hugging Face, é útil.
Em conclusão, este tutorial demonstrou como você pode construir um modelo Transformer usando o PyTorch, uma das ferramentas mais versáteis para aprendizagem profunda. Com sua capacidade de paralelização e de capturar dependências de longo prazo nos dados, os transformadores têm um imenso potencial em vários campos, especialmente em tarefas de PLN, como tradução, resumo e análise de sentimentos.
Para aqueles que desejam aprofundar seus conhecimentos sobre conceitos e técnicas avançadas de aprendizagem profunda, considere explorar o curso Advanced Deep Learning with Keras no DataCamp. Você também pode ler sobre a criação de uma rede neural simples com o PyTorch em um tutorial separado.
Saiba mais sobre o PyTorch com estes cursos!
Curso
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
Tutorial
Tutorial
Natassha Selvaraj
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
