
Corso
Efficient AI Model Training with PyTorch
4 h
1.6K
Introdotti per la prima volta nell'articolo Attention is All You Need di Vaswani et al., i Transformer sono diventati una pietra miliare di molti compiti NLP grazie al loro design unico ed efficace.
Al cuore dei Transformer c'è il meccanismo di attention, in particolare il concetto di "self-attention", che permette al modello di pesare e dare priorità a diverse parti dei dati in input. Questo meccanismo consente ai Transformer di gestire dipendenze a lungo raggio nei dati. È fondamentalmente uno schema di pesatura che consente a un modello di concentrarsi su parti diverse dell'input quando produce un output.
Il meccanismo di self-attention permette al modello di considerare parole o caratteristiche diverse nella sequenza di input, assegnando a ciascuna un "peso" che ne indica l'importanza per produrre un determinato output. Ad esempio, in un compito di traduzione, mentre traduce una specifica parola, il modello può assegnare pesi di attention più alti a parole grammaticalmente o semanticamente correlate alla parola target. Questo processo consente al Transformer di catturare dipendenze tra parole o caratteristiche, indipendentemente dalla loro distanza nella sequenza.
L'impatto dei Transformer nel campo dell'NLP non può essere sopravvalutato. Hanno superato i modelli tradizionali in molti compiti, dimostrando una capacità superiore di comprendere e generare linguaggio umano in modo più sfumato.
Per approfondire l'NLP, il corso di DataCamp Introduction to Natural Language Processing in Python è una risorsa consigliata.
Prima di costruire un Transformer, è essenziale configurare correttamente l'ambiente di lavoro. Innanzitutto, è necessario installare PyTorch. PyTorch può essere installato tramite i gestori di pacchetti pip o conda.
Per pip, usa il comando:
pip3 install torch torchvision torchaudioPer conda, usa il comando:
conda install pytorch torchvision -c pytorchPer altre opzioni di installazione ed esecuzione di PyTorch, fai riferimento al sito ufficiale.
Inoltre, è utile avere una conoscenza di base dei concetti di deep learning, fondamentali per capire il funzionamento dei Transformer. Per chi ha bisogno di un ripasso, il corso di DataCamp Deep Learning in Python è una risorsa preziosa che copre i concetti chiave del deep learning.
Per costruire il modello Transformer, sono necessari i seguenti passaggi:
Iniziamo importando la libreria PyTorch per le funzionalità di base, il modulo di reti neurali per creare le reti, il modulo di ottimizzazione per l'addestramento e le utility per la gestione dei dati. Inoltre, importeremo il modulo standard di Python math per le operazioni matematiche e il modulo copy per creare copie di oggetti complessi.
Questi strumenti gettano le basi per definire l'architettura del modello, gestire i dati e impostare il processo di training.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import math
import copyPrima di creare i nostri componenti, dai un'occhiata alla seguente tabella, che descrive i diversi componenti di un Transformer e il loro scopo:
| Componente | Descrizione | Scopo |
|---|---|---|
| Multi-Head Attention | Meccanismo per concentrarsi su parti diverse dell'input | Cattura le dipendenze tra posizioni diverse nella sequenza |
| Feed-Forward Networks | Layer completamente connessi per posizione | Trasformano gli output dell'attention, aggiungendo complessità |
| Positional Encoding | Aggiunge informazioni di posizione alle embedding | Fornisce al modello il contesto dell'ordine nella sequenza |
| Layer Normalization | Normalizza gli input di ogni sotto-layer | Stabilizza il training, migliora la convergenza |
| Residual Connections | Scorciatoie tra layer | Aiutano ad addestrare reti più profonde riducendo i problemi di gradiente |
| Dropout | Az azzera casualmente alcune connessioni di rete | Previene l'overfitting regolarizzando il modello |
Il meccanismo di multi-head attention calcola l'attenzione tra ogni coppia di posizioni in una sequenza. È composto da più "teste di attention" che catturano aspetti diversi della sequenza di input.
Per saperne di più sulla multi-head attention, dai un'occhiata alla sezione attention mechanisms del corso Large Language Models (LLMs) Concepts.
Figura 1. Multi-Head Attention (fonte: immagine creata dall'autore)
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
# Ensure that the model dimension (d_model) is divisible by the number of heads
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
# Initialize dimensions
self.d_model = d_model # Model's dimension
self.num_heads = num_heads # Number of attention heads
self.d_k = d_model // num_heads # Dimension of each head's key, query, and value
# Linear layers for transforming inputs
self.W_q = nn.Linear(d_model, d_model) # Query transformation
self.W_k = nn.Linear(d_model, d_model) # Key transformation
self.W_v = nn.Linear(d_model, d_model) # Value transformation
self.W_o = nn.Linear(d_model, d_model) # Output transformation
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# Calculate attention scores
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# Apply mask if provided (useful for preventing attention to certain parts like padding)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# Softmax is applied to obtain attention probabilities
attn_probs = torch.softmax(attn_scores, dim=-1)
# Multiply by values to obtain the final output
output = torch.matmul(attn_probs, V)
return output
def split_heads(self, x):
# Reshape the input to have num_heads for multi-head attention
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
def combine_heads(self, x):
# Combine the multiple heads back to original shape
batch_size, _, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
def forward(self, Q, K, V, mask=None):
# Apply linear transformations and split heads
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# Perform scaled dot-product attention
attn_output = self.scaled_dot_product_attention(Q, K, V, mask)
# Combine heads and apply output transformation
output = self.W_o(self.combine_heads(attn_output))
return outputDefinizione e inizializzazione della classe:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):La classe è definita come sottoclasse di nn.Module di PyTorch.
d_model: Dimensionalità dell'input.num_heads: Numero di teste di attention in cui dividere l'input.L'inizializzazione verifica che d_model sia divisibile per num_heads, quindi definisce i pesi di trasformazione per query, key, value e output.
Scaled dot-product attention:
def scaled_dot_product_attention(self, Q, K, V, mask=None):attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k). Qui gli score di attention si ottengono facendo il prodotto scalare tra query (Q) e key (K), poi scalando per la radice quadrata della dimensione delle key (d_k).V).Suddivisione delle teste:
def split_heads(self, x):Questo metodo rimodella l'input x nella forma (batch_size, num_heads, seq_length, d_k). Permette al modello di elaborare più teste di attention in parallelo, abilitando la computazione parallela.
Combinazione delle teste:
def combine_heads(self, x):Dopo aver applicato l'attenzione a ciascuna testa separatamente, questo metodo combina i risultati in un singolo tensore di forma (batch_size, seq_length, d_model). Questo prepara il risultato per l'elaborazione successiva.
Metodo forward:
def forward(self, Q, K, V, mask=None):Il metodo forward è dove avviene il calcolo effettivo:
Q), key (K) e value (V) passano prima attraverso trasformazioni lineari usando i pesi definiti in fase di inizializzazione.Q, K, V vengono suddivise in più teste usando il metodo split_heads.scaled_dot_product_attention sulle teste suddivise.combine_heads.In sintesi, la classe MultiHeadAttention incapsula il meccanismo di multi-head attention comunemente usato nei modelli Transformer. Si occupa di suddividere l'input in più teste di attention, applicare l'attenzione a ciascuna e quindi combinare i risultati. In questo modo, il modello può catturare varie relazioni nei dati di input a scale diverse, migliorando la capacità espressiva del modello.
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))Definizione della classe:
class PositionWiseFeedForward(nn.Module):La classe è una sottoclasse di nn.Module di PyTorch, quindi eredita tutte le funzionalità necessarie per lavorare con layer di reti neurali.
Inizializzazione:
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()d_model: Dimensionalità dell'input e dell'output del modello.d_ff: Dimensionalità del layer interno nella rete feed-forward.self.fc1 e self.fc2: Due layer fully connected (lineari) con dimensioni di input e output definite da d_model e d_ff.self.relu: Funzione di attivazione ReLU (Rectified Linear Unit), che introduce non linearità tra i due layer lineari.Metodo forward:
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))x: L'input alla rete feed-forward.self.fc1(x): L'input passa prima attraverso il primo layer lineare (fc1).self.relu(...): L'output di fc1 passa poi attraverso una ReLU, che sostituisce i valori negativi con zeri, introducendo non linearità.self.fc2(...): L'output attivato passa quindi attraverso il secondo layer lineare (fc2), producendo l'output finale.In sintesi, la classe PositionWiseFeedForward definisce una rete neurale feed-forward per posizione composta da due layer lineari con una ReLU in mezzo. Nel contesto dei Transformer, questa rete viene applicata separatamente e identicamente a ogni posizione. Aiuta a trasformare le caratteristiche apprese dai meccanismi di attention all'interno del Transformer, fungendo da ulteriore passo di elaborazione per gli output dell'attention.
Il Positional Encoding serve a iniettare l'informazione di posizione di ciascun token nella sequenza di input. Usa funzioni seno e coseno a diverse frequenze per generare il positional encoding.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1)]Definizione della classe:
class PositionalEncoding(nn.Module):La classe è definita come sottoclasse di nn.Module di PyTorch, il che le consente di essere usata come un layer standard.
Inizializzazione:
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))d_model: La dimensione dell'input del modello.max_seq_length: La lunghezza massima della sequenza per cui si precomputano i positional encoding.pe: Un tensore inizializzato a zeri, che verrà popolato con i positional encoding.position: Un tensore contenente gli indici di posizione per ciascuna posizione nella sequenza.div_term: Un termine usato per scalare gli indici di posizione in modo specifico.pe.pe viene registrato come buffer, quindi fa parte dello stato del modulo ma non è un parametro addestrabile.Metodo forward:
def forward(self, x):
return x + self.pe[:, :x.size(1)]Il metodo forward aggiunge semplicemente i positional encoding all'input x.
Usa i primi x.size(1) elementi di pe per garantire che i positional encoding combacino con la lunghezza reale della sequenza di x.
Riepilogo
La classe PositionalEncoding aggiunge informazioni sulla posizione dei token nella sequenza. Poiché il modello Transformer non ha conoscenza intrinseca dell'ordine dei token (a causa del meccanismo di self-attention), questa classe aiuta il modello a considerare la posizione dei token nella sequenza. Le funzioni sinusoidali sono scelte per consentire al modello di apprendere facilmente ad attendere a posizioni relative, poiché producono una codifica unica e regolare per ciascuna posizione nella sequenza.
Figura 2. La parte Encoder della rete transformer (Fonte: immagine dall'articolo originale)
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xDefinizione della classe:
class EncoderLayer(nn.Module):La classe è definita come sottoclasse di nn.Module di PyTorch, quindi può essere usata come blocco per reti neurali in PyTorch.
Inizializzazione:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parametri:
d_model: La dimensionalità dell'input.num_heads: Il numero di teste di attention nella multi-head attention.d_ff: La dimensionalità del layer interno nella rete feed-forward per posizione.dropout: Il tasso di dropout usato per la regolarizzazione.Componenti:
self.self_attn: Meccanismo di self-attention multi-head.self.feed_forward: Rete neurale feed-forward per posizione.self.norm1 e self.norm2: Normalizzazione di layer, applicata per regolarizzare l'input del layer.self.dropout: Layer di dropout, usato per prevenire l'overfitting azzerando casualmente alcune attivazioni durante il training.Metodo forward:
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xInput:
x: L'input al layer dell'encoder.mask: Maschera opzionale per ignorare parti dell'input.Passaggi di elaborazione:
x passa attraverso il meccanismo di self-attention multi-head.norm1.norm2.Riepilogo:
La classe EncoderLayer definisce un singolo layer dell'encoder del Transformer. Incapsula un meccanismo di self-attention multi-head seguito da una rete neurale feed-forward per posizione, con connessioni residue, layer normalization e dropout applicati dove opportuno. Insieme, questi componenti consentono all'encoder di catturare relazioni complesse nei dati di input e trasformarli in una rappresentazione utile per i compiti a valle. Tipicamente, più layer encoder di questo tipo vengono impilati per formare la parte encoder completa di un modello Transformer.
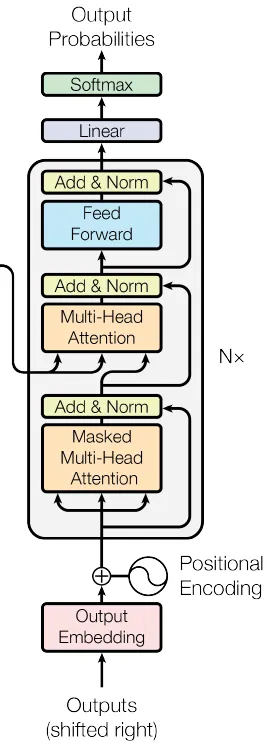
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xDefinizione della classe:
class DecoderLayer(nn.Module):Inizializzazione:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parametri:
d_model: La dimensionalità dell'input.num_heads: Il numero di teste di attention nella multi-head attention.d_ff: La dimensionalità del layer interno nella rete feed-forward.dropout: Il tasso di dropout per la regolarizzazione.Componenti:
self.self_attn: Meccanismo di self-attention multi-head per la sequenza target.self.cross_attn: Meccanismo di attention multi-head che guarda all'output dell'encoder.self.feed_forward: Rete neurale feed-forward per posizione.self.norm1, self.norm2, self.norm3: Componenti di layer normalization.self.dropout: Layer di dropout per la regolarizzazione.Metodo forward:
ef forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xInput:
x: L'input al layer del decoder.enc_output: L'output del corrispondente encoder (usato nello step di cross-attention).src_mask: Maschera della sorgente per ignorare alcune parti dell'output dell'encoder.tgt_mask: Maschera del target per ignorare alcune parti dell'input del decoder.Passaggi di elaborazione:
enc_output.Riepilogo:
La classe DecoderLayer definisce un singolo layer del decoder del Transformer. Consiste in un meccanismo di self-attention multi-head, un meccanismo di cross-attention multi-head (che guarda all'output dell'encoder), una rete neurale feed-forward per posizione e le corrispondenti connessioni residue, layer normalization e dropout. Questa combinazione permette al decoder di generare output significativi basandosi sulle rappresentazioni dell'encoder, tenendo conto sia della sequenza target sia della sequenza sorgente. Come per l'encoder, più layer decoder vengono tipicamente impilati per formare la parte decoder completa di un modello Transformer.
Successivamente, si combinano i blocchi Encoder e Decoder per costruire il modello Transformer completo.
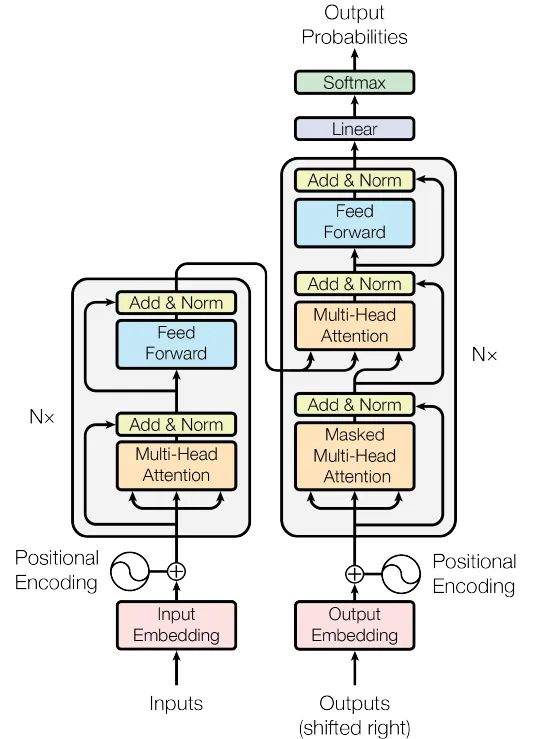
Figura 4. La rete Transformer (Fonte: immagine dall'articolo originale)
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):
super(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_length)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.fc = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def generate_mask(self, src, tgt):
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.size(1)
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask
return src_mask, tgt_mask
def forward(self, src, tgt):
src_mask, tgt_mask = self.generate_mask(src, tgt)
src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))
tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
output = self.fc(dec_output)
return outputDefinizione della classe:
class Transformer(nn.Module):Inizializzazione:
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):Il costruttore accetta i seguenti parametri:
src_vocab_size: Dimensione del vocabolario sorgente.tgt_vocab_size: Dimensione del vocabolario target.d_model: Dimensionalità delle embedding del modello.num_heads: Numero di teste nella multi-head attention.num_layers: Numero di layer sia per l'encoder sia per il decoder.d_ff: Dimensionalità del layer interno nella rete feed-forward.max_seq_length: Lunghezza massima della sequenza per il positional encoding.dropout: Tasso di dropout per la regolarizzazione.E definisce i seguenti componenti:
self.encoder_embedding: Layer di embedding per la sequenza sorgente.self.decoder_embedding: Layer di embedding per la sequenza target.self.positional_encoding: Componente di positional encoding.self.encoder_layers: Un elenco di layer dell'encoder.self.decoder_layers: Un elenco di layer del decoder.self.fc: Layer finale fully connected (lineare) che mappa alla dimensione del vocabolario target.self.dropout: Layer di dropout.Metodo generate mask:
def generate_mask(self, src, tgt):Questo metodo crea maschere per le sequenze sorgente e target, assicurando che i token di padding vengano ignorati e che, durante l'addestramento, i token futuri non siano visibili nella sequenza target.
Metodo forward:
def forward(self, src, tgt):Questo metodo definisce il passaggio forward del Transformer, prendendo sequenze sorgente e target e producendo le predizioni in output.
Output:
L'output finale è un tensore che rappresenta le predizioni del modello per la sequenza target.
Riepilogo:
La classe Transformer riunisce i vari componenti di un modello Transformer, incluse le embedding, il positional encoding, i layer dell'encoder e del decoder. Fornisce un'interfaccia comoda per training e inferenza, incapsulando le complessità di multi-head attention, reti feed-forward e layer normalization.
Questa implementazione segue l'architettura standard del Transformer, rendendola adatta a compiti sequence-to-sequence come traduzione automatica, riassunto di testo, ecc. L'inclusione delle maschere garantisce che il modello rispetti le dipendenze causali all'interno delle sequenze, ignorando i token di padding e prevenendo la fuga di informazioni dai token futuri.
Questi passaggi sequenziali consentono al modello Transformer di elaborare efficacemente le sequenze di input e produrre le corrispondenti sequenze di output.
A scopo illustrativo, in questo esempio verrà creato un dataset fittizio. In uno scenario pratico, invece, si userebbe un dataset più ampio e il processo includerebbe la pre-elaborazione del testo e la creazione di mapping di vocabolario sia per la lingua sorgente sia per quella target.
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_seq_length = 100
dropout = 0.1
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)
# Generate random sample data
src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)Iperparametri:
Questi valori definiscono l'architettura e il comportamento del modello Transformer:
src_vocab_size, tgt_vocab_size: Dimensioni del vocabolario per le sequenze sorgente e target, entrambe impostate a 5000.d_model: Dimensionalità delle embedding del modello, impostata a 512.num_heads: Numero di teste nella multi-head attention, impostato a 8.num_layers: Numero di layer sia per l'encoder sia per il decoder, impostato a 6.d_ff: Dimensionalità del layer interno nella rete feed-forward, impostata a 2048.max_seq_length: Lunghezza massima della sequenza per il positional encoding, impostata a 100.dropout: Tasso di dropout per la regolarizzazione, impostato a 0,1.Per riferimento, la seguente tabella descrive gli iperparametri più comuni per i modelli Transformer e i loro valori:
| Iperparametro | Valori tipici | Impatto sulle prestazioni |
|---|---|---|
| d_model | 256, 512, 1024 | Valori più alti aumentano la capacità del modello ma richiedono più calcolo |
| num_heads | 8, 12, 16 | Più teste possono catturare aspetti diversi dei dati, ma sono computazionalmente onerose |
| num_layers | 6, 12, 24 | Più layer migliorano il potere rappresentativo, ma possono portare a overfitting |
| d_ff | 2048, 4096 | Reti feed-forward più grandi aumentano la robustezza del modello |
| dropout | 0.1, 0.3 | Regolarizza il modello per prevenire l'overfitting |
| learning rate | 0.0001 - 0.001 | Influisce sulla velocità e stabilità della convergenza |
| batch size | 32, 64, 128 | Batch più grandi migliorano la stabilità dell'apprendimento ma richiedono più memoria |
Creare un'istanza di Transformer:
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)Questa riga crea un'istanza della classe Transformer, inizializzandola con gli iperparametri forniti. L'istanza avrà l'architettura e il comportamento definiti da tali iperparametri.
Generare dati di esempio casuali:
Le seguenti righe generano sequenze sorgente e target casuali:
src_data: Interi casuali tra 1 e src_vocab_size, che rappresentano un batch di sequenze sorgente con forma (64, max_seq_length).tgt_data: Interi casuali tra 1 e tgt_vocab_size, che rappresentano un batch di sequenze target con forma (64, max_seq_length).Riepilogo:
Lo snippet mostra come inizializzare un modello Transformer e generare sequenze sorgente e target casuali da passargli in input. Gli iperparametri scelti determinano la struttura e le proprietà specifiche del Transformer. Questo setup può far parte di uno script più ampio in cui il modello viene addestrato e valutato su compiti reali di tipo sequence-to-sequence, come la traduzione o il riassunto di testo.
Successivamente, il modello verrà addestrato utilizzando i dati di esempio sopra menzionati. Tuttavia, in uno scenario reale si userebbe un dataset molto più grande, tipicamente suddiviso in insiemi distinti per training e validazione.
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
transformer.train()
for epoch in range(100):
optimizer.zero_grad()
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:].contiguous().view(-1))
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")Funzione di loss e ottimizzatore:
criterion = nn.CrossEntropyLoss(ignore_index=0): Definisce la funzione di loss come cross-entropy. L'argomento ignore_index è impostato a 0, quindi la loss non considera target con indice 0 (tipicamente riservato ai token di padding).optimizer = optim.Adam(...): Definisce l'ottimizzatore Adam con learning rate 0,0001 e specifici valori di beta.Modalità training del modello:
transformer.train(): Imposta il modello in modalità addestramento, abilitando comportamenti come il dropout che si applicano solo durante il training.Loop di training:
Il codice addestra il modello per 100 epoche con un tipico ciclo di training:
for epoch in range(100): Itera per 100 epoche.optimizer.zero_grad(): Azzera i gradienti dell'iterazione precedente.output = transformer(src_data, tgt_data[:, :-1]): Passa i dati sorgente e i dati target (escludendo l'ultimo token in ogni sequenza) al Transformer. Questo è comune nei compiti sequence-to-sequence dove il target è traslato di un token.loss = criterion(...): Calcola la loss tra le predizioni del modello e i dati target (escludendo il primo token in ogni sequenza). La loss si calcola rimodellando i dati in tensori monodimensionali e usando la cross-entropy.loss.backward(): Calcola i gradienti della loss rispetto ai parametri del modello.optimizer.step(): Aggiorna i parametri del modello usando i gradienti calcolati.print(f"Epoch: {epoch+1}, Loss: {loss.item()}"): Stampa il numero di epoca corrente e il valore della loss per quell'epoca.Riepilogo:
Questo snippet addestra il modello Transformer su sequenze sorgente e target generate casualmente per 100 epoche. Usa l'ottimizzatore Adam e la cross-entropy come funzione di loss. La loss viene stampata a ogni epoca, consentendoti di monitorare l'andamento del training. In uno scenario reale, sostituiresti le sequenze casuali con dati effettivi del tuo compito, come la traduzione automatica.
Dopo l'addestramento, le prestazioni del modello possono essere valutate su un dataset di validazione o di test. Di seguito un esempio di come farlo:
transformer.eval()
# Generate random sample validation data
val_src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
val_tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
with torch.no_grad():
val_output = transformer(val_src_data, val_tgt_data[:, :-1])
val_loss = criterion(val_output.contiguous().view(-1, tgt_vocab_size), val_tgt_data[:, 1:].contiguous().view(-1))
print(f"Validation Loss: {val_loss.item()}")Modalità valutazione:
transformer.eval(): Mette il modello in modalità valutazione. È importante perché disattiva comportamenti come il dropout, usati solo durante il training.Generare dati di validazione casuali:
val_src_data: Interi casuali tra 1 e src_vocab_size, che rappresentano un batch di sequenze sorgente di validazione con forma (64, max_seq_length).val_tgt_data: Interi casuali tra 1 e tgt_vocab_size, che rappresentano un batch di sequenze target di validazione con forma (64, max_seq_length).Loop di validazione:
with torch.no_grad(): Disabilita il calcolo dei gradienti, poiché in validazione non servono. Questo riduce l'uso di memoria e accelera i calcoli.val_output = transformer(val_src_data, val_tgt_data[:, :-1]): Passa i dati sorgente e target di validazione (escludendo l'ultimo token) attraverso il Transformer.val_loss = criterion(...): Calcola la loss tra le predizioni del modello e i dati target di validazione (escludendo il primo token). La loss è calcolata rimodellando i dati in tensori monodimensionali e usando la cross-entropy definita in precedenza.print(f"Validation Loss: {val_loss.item()}"): Stampa il valore della loss di validazione.Riepilogo:
Questo snippet valuta il modello Transformer su un dataset di validazione generato casualmente, calcola la loss di validazione e la stampa. In uno scenario reale, i dati di validazione casuali andrebbero sostituiti con dati effettivi relativi al tuo compito. La loss di validazione indica quanto bene il modello si comporta su dati non visti, misura cruciale della capacità di generalizzazione.
Per ulteriori dettagli sui Transformer e Hugging Face, il nostro tutorial An Introduction to Using Transformers and Hugging Face è utile.
In conclusione, questo tutorial ha mostrato come costruire un modello Transformer usando PyTorch, uno degli strumenti più versatili per il deep learning. Grazie alla capacità di parallelizzazione e di catturare dipendenze di lungo periodo nei dati, i Transformer hanno un enorme potenziale in vari ambiti, soprattutto in compiti di NLP come traduzione, riassunto e analisi del sentiment.
Se vuoi approfondire concetti e tecniche avanzate di deep learning, valuta il corso Advanced Deep Learning with Keras su DataCamp. Puoi anche leggere, in un tutorial separato, come costruire una semplice rete neurale con PyTorch.
Approfondisci PyTorch con questi corsi!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

