
Curso
Introducción al aprendizaje profundo con PyTorch
4 h
85.9K
Introducidos por primera vez en el artículo Attention is All You Need de Vaswani et al., los Transformadores se han convertido desde entonces en una piedra angular de muchas tareas de PNL debido a su diseño único y a su eficacia.
En el corazón de los Transformadores está el mecanismo de atención, concretamente el concepto de "autoatención", que permite al modelo sopesar y priorizar distintas partes de los datos de entrada. Este mecanismo permite a los Transformadores gestionar las dependencias de largo alcance en los datos. Es fundamentalmente un esquema de ponderación que permite a un modelo centrarse en diferentes partes de la entrada al producir una salida.
El mecanismo de autoatención permite al modelo considerar diferentes palabras o rasgos en la secuencia de entrada, asignando a cada uno un "peso" que significa su importancia para producir una salida determinada. Por ejemplo, en una tarea de traducción de frases, al traducir una palabra concreta, el modelo podría asignar mayor peso de atención a las palabras que están relacionadas gramatical o semánticamente con la palabra objetivo. Este proceso permite al Transformador captar las dependencias entre palabras o rasgos, independientemente de su distancia entre sí en la secuencia.
No se puede exagerar el impacto de Transformers en el campo de la PNL. Han superado a los modelos tradicionales en muchas tareas, demostrando una capacidad superior para comprender y generar lenguaje humano de forma más matizada.
Para una comprensión más profunda de la PNL, el curso Introducción al Procesamiento del Lenguaje Natural en Python de DataCamp es un recurso recomendado.
Antes de construir un Transformador, es esencial preparar correctamente el entorno de trabajo. Lo primero y más importante es instalar PyTorch. PyTorch se instala a través de los gestores de paquetes pip o conda.
Para pip, utiliza el comando
pip3 install torch torchvision torchaudioPara conda, utiliza el comando
conda install pytorch torchvision -c pytorchPara otras opciones de instalación y ejecución de PyTorch, consulta el sitio web oficial.
Además, es beneficioso tener una comprensión básica de los conceptos de aprendizaje profundo, ya que serán fundamentales para entender el funcionamiento de Transformers. Para quienes necesiten un repaso, el curso de DataCamp Aprendizaje profundo en Python es un valioso recurso que cubre conceptos clave del aprendizaje profundo.
Para construir el modelo de Transformador, son necesarios los siguientes pasos:
Empezaremos importando la biblioteca PyTorch para la funcionalidad básica, el módulo de redes neuronales para crear redes neuronales, el módulo de optimización para entrenar redes y las funciones de utilidad de datos para manejar datos. Además, importaremos el módulo estándar de Python math para operaciones matemáticas y el módulo copy para crear copias de objetos complejos.
Estas herramientas sientan las bases para definir la arquitectura del modelo, gestionar los datos y establecer el proceso de entrenamiento.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import math
import copyAntes de empezar a construir nuestros componentes, echa un vistazo a la siguiente tabla, que describe los distintos componentes de un Transformador y su finalidad:
| Componente | Descripción | Propósito |
|---|---|---|
| Atención multicabeza | Mecanismo para centrarse en diferentes partes de la entrada | Capta las dependencias en diferentes posiciones de la secuencia |
| Redes Feed-Forward | Capas totalmente conectadas en función de la posición | Transforma las salidas de atención, añadiendo complejidad |
| Codificación posicional | Añade información posicional a las incrustaciones | Proporciona contexto de orden secuencial al modelo |
| Normalización de capas | Normaliza las entradas de cada subcapa | Estabiliza el entrenamiento, mejora la convergencia |
| Conexiones residuales | Atajos entre capas | Ayuda a entrenar redes más profundas minimizando los problemas de gradiente |
| Abandono | Pone a cero aleatoriamente algunas conexiones de red | Evita el sobreajuste regularizando el modelo |
El mecanismo de atención multicabezal calcula la atención entre cada par de posiciones de una secuencia. Consta de múltiples "cabezas de atención" que captan diferentes aspectos de la secuencia de entrada.
Para saber más sobre la atención multicabezal, consulta la sección de mecanismos de atención del curso Conceptos de los Grandes Modelos del Lenguaje (LLM).
Figura 1. Atención multicabeza (fuente: imagen creada por el autor)
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
# Ensure that the model dimension (d_model) is divisible by the number of heads
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
# Initialize dimensions
self.d_model = d_model # Model's dimension
self.num_heads = num_heads # Number of attention heads
self.d_k = d_model // num_heads # Dimension of each head's key, query, and value
# Linear layers for transforming inputs
self.W_q = nn.Linear(d_model, d_model) # Query transformation
self.W_k = nn.Linear(d_model, d_model) # Key transformation
self.W_v = nn.Linear(d_model, d_model) # Value transformation
self.W_o = nn.Linear(d_model, d_model) # Output transformation
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# Calculate attention scores
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# Apply mask if provided (useful for preventing attention to certain parts like padding)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# Softmax is applied to obtain attention probabilities
attn_probs = torch.softmax(attn_scores, dim=-1)
# Multiply by values to obtain the final output
output = torch.matmul(attn_probs, V)
return output
def split_heads(self, x):
# Reshape the input to have num_heads for multi-head attention
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
def combine_heads(self, x):
# Combine the multiple heads back to original shape
batch_size, _, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
def forward(self, Q, K, V, mask=None):
# Apply linear transformations and split heads
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# Perform scaled dot-product attention
attn_output = self.scaled_dot_product_attention(Q, K, V, mask)
# Combine heads and apply output transformation
output = self.W_o(self.combine_heads(attn_output))
return outputDefinición e inicialización de clases:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):La clase se define como una subclase de nn.Module de PyTorch.
d_model: Dimensionalidad de la entrada.num_heads: El número de cabezas de atención en que dividir la entrada.La inicialización comprueba si d_model es divisible por num_heads, y luego define los pesos de transformación para query, key, value y output.
Atención al producto punto escalado:
def scaled_dot_product_attention(self, Q, K, V, mask=None):attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k). Aquí, las puntuaciones de atención se calculan tomando el producto punto de las consultas (Q) y las claves (K), y luego escalando por la raíz cuadrada de la dimensión de la clave (d_k).V).Partiendo cabezas:
def split_heads(self, x):Este método remodela la entrada x en la forma (batch_size, num_heads, seq_length, d_k). Permite al modelo procesar varias cabezas de atención simultáneamente, lo que permite el cálculo paralelo.
Combinar cabezas:
def combine_heads(self, x):Tras aplicar la atención a cada cabeza por separado, este método vuelve a combinar los resultados en un único tensor de forma (batch_size, seq_length, d_model). Esto prepara el resultado para su posterior procesamiento.
Método de avance:
def forward(self, Q, K, V, mask=None):El método directo es donde se produce el cálculo real:
Q), las claves (K) y los valores (V) se someten primero a transformaciones lineales utilizando los pesos definidos en la inicialización.Q, K, V se dividen en varias cabezas mediante el método split_heads.scaled_dot_product_attention en las cabezas divididas.combine_heads.En resumen, la clase MultiHeadAttention encapsula el mecanismo de atención multicabezal utilizado habitualmente en los modelos de transformador. Se encarga de dividir la entrada en varias cabezas de atención, aplicar la atención a cada cabeza y luego combinar los resultados. Al hacerlo, el modelo puede captar diversas relaciones en los datos de entrada a diferentes escalas, mejorando la capacidad expresiva del modelo.
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))Definición de clase:
class PositionWiseFeedForward(nn.Module):La clase es una subclase de nn.Module de PyTorch , lo que significa que heredará todas las funcionalidades necesarias para trabajar con capas de redes neuronales.
Inicialización:
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()d_model: Dimensionalidad de la entrada y la salida del modelo.d_ff: Dimensionalidad de la capa interna en la red feed-forward.self.fc1 y self.fc2: Dos capas totalmente conectadas (lineales) con las dimensiones de entrada y salida definidas en d_model y d_ff.self.relu: Función de activación ReLU (Unidad Lineal Rectificada), que introduce la no linealidad entre las dos capas lineales.Método de avance:
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))x: La entrada a la red feed-forward.self.fc1(x): La entrada pasa primero por la primera capa lineal (fc1).self.relu(...): A continuación, la salida de fc1 se pasa por una función de activación ReLU. ReLU sustituye todos los valores negativos por ceros, introduciendo la no linealidad en el modelo.self.fc2(...): A continuación, la salida activada pasa por la segunda capa lineal (fc2), produciendo la salida final.En resumen, la clase PositionWiseFeedForward define una red neuronal feed-forward en función de la posición que consta de dos capas lineales con una función de activación ReLU entre ellas. En el contexto de los modelos de transformador, esta red feed-forward se aplica a cada posición por separado y de forma idéntica. Ayuda a transformar los rasgos aprendidos por los mecanismos de atención dentro del transformador, actuando como un paso de procesamiento adicional para los resultados de la atención.
La codificación posicional se utiliza para inyectar la información de posición de cada token en la secuencia de entrada. Utiliza funciones seno y coseno de distintas frecuencias para generar la codificación posicional.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1)]Definición de clase:
class PositionalEncoding(nn.Module):La clase se define como una subclase de nn.Module de PyTorch, lo que permite utilizarla como una capa estándar de PyTorch.
Inicialización:
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))d_model: La dimensión de la entrada del modelo.max_seq_length: La longitud máxima de la secuencia para la que se precalculan las codificaciones posicionales.pe: Un tensor relleno de ceros, que se rellenará con codificaciones posicionales.position: Un tensor que contiene los índices de posición de cada posición de la secuencia.div_term: Término utilizado para escalar los índices de posición de una forma determinada.pe.pe se registra como un búfer, lo que significa que formará parte del estado del módulo pero no se considerará un parámetro entrenable.Método de avance:
def forward(self, x):
return x + self.pe[:, :x.size(1)]El método de avance simplemente añade las codificaciones posicionales a la entrada x.
Utiliza los primeros x.size(1) elementos de pe para garantizar que las codificaciones posicionales coinciden con la longitud de secuencia real de x.
Resumen
La clase PositionalEncoding añade información sobre la posición de las fichas dentro de la secuencia. Como el modelo del transformador carece de conocimiento inherente del orden de las fichas (debido a su mecanismo de autoatención), esta clase ayuda al modelo a considerar la posición de las fichas en la secuencia. Las funciones sinusoidales utilizadas se eligen para que el modelo aprenda fácilmente a atender a posiciones relativas, ya que producen una codificación única y suave para cada posición de la secuencia.
Figura 2. La parte codificadora de la red de transformadores (Fuente: imagen del documento original)
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xDefinición de clase:
class EncoderLayer(nn.Module):La clase se define como una subclase de nn.Module de PyTorch, lo que significa que puede utilizarse como bloque de construcción de redes neuronales en PyTorch.
Inicialización:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parámetros:
d_model: La dimensionalidad de la entrada.num_heads: El número de cabezas de atención en la atención multicabeza.d_ff: La dimensionalidad de la capa interna en la red feed-forward en función de la posición.dropout: La tasa de abandono utilizada para la regularización.Componentes:
self.self_attn: Mecanismo de atención multicabezal.self.feed_forward: Red neuronal feed-forward en función de la posición.self.norm1 y self.norm2: Normalización de la capa, aplicada para suavizar la entrada de la capa.self.dropout: Capa de abandono, utilizada para evitar el sobreajuste poniendo aleatoriamente a cero algunas activaciones durante el entrenamiento.Método de avance:
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xEntrada:
x: La entrada a la capa codificadora.mask: Máscara opcional para ignorar determinadas partes de la entrada.Pasos de procesamiento:
x pasa a través del mecanismo de autoatención multicabezal.norm1.norm2.Resumen:
La clase EncoderLayer define una sola capa del codificador del transformador. Encierra un mecanismo de autoatención multicabezal seguido de la red neuronal feed-forward en función de la posición, con conexiones residuales, normalización de capas y abandono aplicados según proceda. Juntos, estos componentes permiten al codificador captar relaciones complejas en los datos de entrada y transformarlas en una representación útil para las tareas posteriores. Normalmente, se apilan varias capas codificadoras de este tipo para formar la parte codificadora completa de un modelo de transformador.
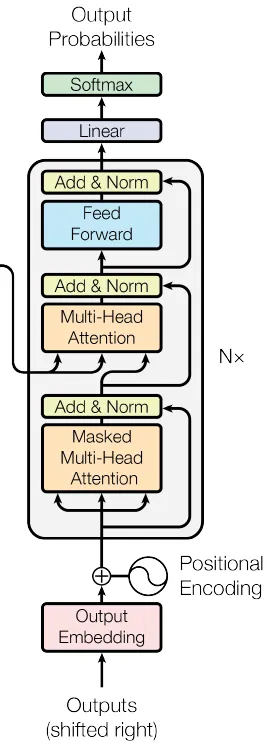
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xDefinición de clase:
class DecoderLayer(nn.Module):Inicialización:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parámetros:
d_model: La dimensionalidad de la entrada.num_heads: El número de cabezas de atención en la atención multicabeza.d_ff: La dimensionalidad de la capa interna en la red feed-forward.dropout: La tasa de abandono de la regularización.Componentes:
self.self_attn: Mecanismo de autoatención multicabezal para la secuencia objetivo.self.cross_attn: Mecanismo de atención multicabezal que atiende a la salida del codificador.self.feed_forward: Red neuronal feed-forward en función de la posición.self.norm1, self.norm2, self.norm3: Componentes de normalización de capas.self.dropout: Capa de abandono para la regularización.Método deavance:
ef forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xEntrada:
x: La entrada a la capa decodificadora.enc_output: La salida del codificador correspondiente (utilizada en el paso de atención cruzada).src_mask: Máscara de fuente para ignorar ciertas partes de la salida del codificador.tgt_mask: Máscara de destino para ignorar determinadas partes de la entrada del descodificador.Pasos de procesamiento:
Resumen:
La clase DecoderLayer define una sola capa del descodificador del transformador. Consta de un mecanismo de autoatención multicabezal, un mecanismo de atención cruzada multicabezal (que atiende a la salida del codificador), una red neuronal feed-forward en función de la posición, y las correspondientes conexiones residuales, normalización de capas y capas de abandono. Esta combinación permite al descodificador generar salidas significativas basadas en las representaciones del codificador, teniendo en cuenta tanto la secuencia objetivo como la secuencia fuente. Al igual que ocurre con el codificador, se suelen apilar varias capas de decodificador para formar la parte decodificadora completa de un modelo de transformador.
A continuación, los bloques Codificador y Decodificador se combinan para construir el modelo completo del Transformador.
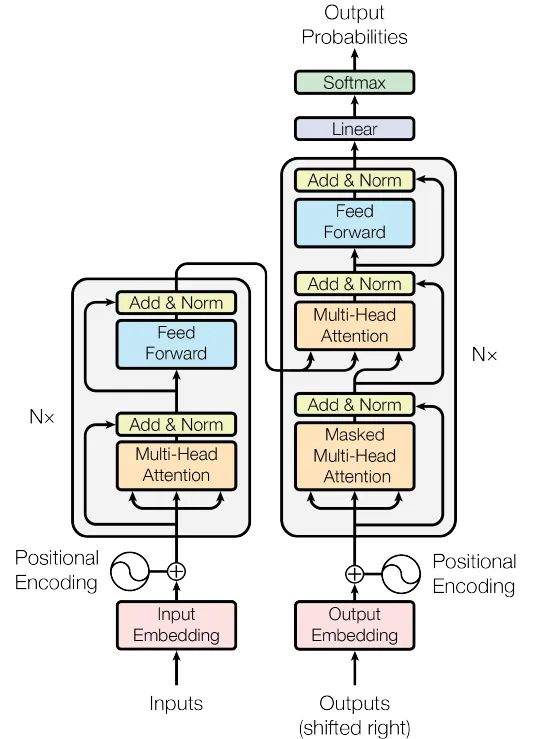
Figura 4. La Red de Transformadores (Fuente: Imagen del documento original)
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):
super(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_length)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.fc = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def generate_mask(self, src, tgt):
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.size(1)
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask
return src_mask, tgt_mask
def forward(self, src, tgt):
src_mask, tgt_mask = self.generate_mask(src, tgt)
src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))
tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
output = self.fc(dec_output)
return outputDefinición de clase:
class Transformer(nn.Module):Inicialización:
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):El constructor toma los siguientes parámetros:
src_vocab_size: Tamaño del vocabulario fuente.tgt_vocab_size: Tamaño del vocabulario objetivo.d_model: La dimensionalidad de las incrustaciones del modelo.num_heads: Número de cabezas de atención en el mecanismo de atención multicabeza.num_layers: Número de capas tanto para el codificador como para el descodificador.d_ff: Dimensionalidad de la capa interna en la red feed-forward.max_seq_length: Longitud máxima de la secuencia para la codificación posicional.dropout: Tasa de abandono por regularización.Y define los siguientes componentes:
self.encoder_embedding: Capa de incrustación de la secuencia fuente.self.decoder_embedding: Capa de incrustación de la secuencia objetivo.self.positional_encoding: Componente de codificación posicional.self.encoder_layers: Una lista de capas del codificador.self.decoder_layers: Una lista de las capas del descodificador.self.fc: Asignación de la capa final totalmente conectada (lineal) al tamaño del vocabulario objetivo.self.dropout: Capa de abandono.Generar método de máscara:
def generate_mask(self, src, tgt):Este método se utiliza para crear máscaras para las secuencias de origen y de destino, garantizando que se ignoren las fichas de relleno y que las fichas futuras no sean visibles durante el entrenamiento para la secuencia de destino.
Método de avance:
def forward(self, src, tgt):Este método define el paso hacia delante del Transformador, tomando las secuencias origen y destino y produciendo las predicciones de salida.
Salida:
El resultado final es un tensor que representa las predicciones del modelo para la secuencia objetivo.
Resumen:
La clase Transformador reúne los distintos componentes de un modelo Transformador, incluidas las incrustaciones, la codificación posicional, las capas codificadoras y las capas decodificadoras. Proporciona una interfaz cómoda para el entrenamiento y la inferencia, encapsulando las complejidades de la atención multicabezal, las redes feed-forward y la normalización de capas.
Esta implementación sigue la arquitectura estándar de Transformer, lo que la hace adecuada para tareas de secuencia a secuencia como la traducción automática, el resumen de textos, etc. Incluir el enmascaramiento garantiza que el modelo se ciña a las dependencias causales dentro de las secuencias, ignorando las fichas de relleno y evitando la fuga de información de las fichas futuras.
Estos pasos secuenciales capacitan al modelo Transformador para procesar eficazmente las secuencias de entrada y producir las secuencias de salida correspondientes.
A efectos ilustrativos, en este ejemplo se elaborará un conjunto de datos ficticio. Sin embargo, en un escenario práctico, se emplearía un conjunto de datos más sustancial, y el proceso implicaría el preprocesamiento del texto junto con la creación de mapeos de vocabulario tanto para la lengua de origen como para la de destino.
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_seq_length = 100
dropout = 0.1
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)
# Generate random sample data
src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)Hiperparámetros:
Estos valores definen la arquitectura y el comportamiento del modelo de transformador:
src_vocab_size, tgt_vocab_size: Tamaño de los vocabularios de las secuencias origen y destino, ambos fijados en 5000.d_model: Dimensionalidad de las incrustaciones del modelo, fijada en 512.num_heads: Número de cabezales de atención en el mecanismo de atención multicabezal, fijado en 8.num_layers: Número de capas tanto para el codificador como para el descodificador, fijado en 6.d_ff: Dimensionalidad de la capa interna de la red feed-forward, fijada en 2048.max_seq_length: Longitud máxima de la secuencia para la codificación posicional, fijada en 100.dropout: Tasa de abandono para la regularización, fijada en 0,1.Como referencia, la tabla siguiente describe los hiperparámetros más comunes de los modelos Transformer y sus valores:
| Hiperparámetro | Valores típicos | Impacto en el rendimiento |
|---|---|---|
| d_model | 256, 512, 1024 | Los valores más altos aumentan la capacidad del modelo, pero requieren más cálculo |
| num_heads | 8, 12, 16 | Más cabezales pueden captar diversos aspectos de los datos, pero son computacionalmente intensivos |
| número_capas | 6, 12, 24 | Más capas mejoran el poder de representación, pero pueden llevar a un sobreajuste |
| d_ff | 2048, 4096 | Las redes feed-forward más grandes aumentan la robustez del modelo |
| abandono | 0.1, 0.3 | Regulariza el modelo para evitar el sobreajuste |
| ritmo de aprendizaje | 0.0001 - 0.001 | Afecta a la velocidad de convergencia y a la estabilidad |
| tamaño del lote | 32, 64, 128 | Los lotes de mayor tamaño mejoran la estabilidad del aprendizaje, pero requieren más memoria |
Crear una instancia de Transformador:
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)Esta línea crea una instancia de la clase Transformer, inicializándola con los hiperparámetros dados. La instancia tendrá la arquitectura y el comportamiento definidos por estos hiperparámetros.
Generar datos de muestras aleatorias:
Las siguientes líneas generan secuencias aleatorias de origen y destino:
src_data: Números enteros aleatorios entre 1 y src_vocab_size, que representan un lote de secuencias fuente con forma (64, max_seq_length).tgt_data: Números enteros aleatorios entre 1 y tgt_vocab_size, que representan un lote de secuencias objetivo con forma (64, max_seq_length).Resumen:
El fragmento de código muestra cómo inicializar un modelo Transformer y generar secuencias aleatorias de origen y destino que se pueden introducir en él. Los hiperparámetros elegidos determinan la estructura y las propiedades específicas del Transformador. Esta configuración podría formar parte de un guión más amplio en el que el modelo se entrenara y evaluara en tareas reales de secuencia a secuencia, como la traducción automática o el resumen de textos.
A continuación, se entrenará el modelo utilizando los datos de muestra antes mencionados. Sin embargo, en un escenario real, se emplearía un conjunto de datos significativamente mayor, que normalmente se dividiría en conjuntos distintos con fines de entrenamiento y validación.
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
transformer.train()
for epoch in range(100):
optimizer.zero_grad()
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:].contiguous().view(-1))
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")Función de pérdida y optimizador:
criterion = nn.CrossEntropyLoss(ignore_index=0): Define la función de pérdida como pérdida de entropía cruzada. El argumento ignore_index se establece en 0, lo que significa que la pérdida no tendrá en cuenta los objetivos con un índice 0 (normalmente reservado para los tokens de relleno).optimizer = optim.Adam(...): Define el optimizador como Adam con una tasa de aprendizaje de 0,0001 y valores beta específicos.Modo de entrenamiento del modelo:
transformer.train(): Establece el modelo del transformador en modo de entrenamiento, permitiendo comportamientos como el abandono que sólo se aplican durante el entrenamiento.Bucle de entrenamiento:
El fragmento de código entrena el modelo durante 100 épocas utilizando un bucle de entrenamiento típico:
for epoch in range(100): Itera más de 100 épocas de entrenamiento.optimizer.zero_grad(): Borra los degradados de la iteración anterior.output = transformer(src_data, tgt_data[:, :-1]): Pasa los datos de origen y los datos de destino (excluyendo el último token de cada secuencia) a través del transformador. Esto es habitual en tareas de secuencia a secuencia en las que el objetivo se desplaza un token.loss = criterion(...): Calcula la pérdida entre las predicciones del modelo y los datos objetivo (excluyendo el primer token de cada secuencia). La pérdida se calcula remodelando los datos en tensores unidimensionales y utilizando la función de pérdida de entropía cruzada.loss.backward(): Calcula los gradientes de la pérdida con respecto a los parámetros del modelo.optimizer.step(): Actualiza los parámetros del modelo utilizando los gradientes calculados.print(f"Epoch: {epoch+1}, Loss: {loss.item()}"): Imprime el número de época actual y el valor de pérdida de esa época.Resumen:
Este fragmento de código entrena el modelo transformador con secuencias de origen y destino generadas aleatoriamente durante 100 épocas. Utiliza el optimizador Adam y la función de pérdida de entropía cruzada. La pérdida se imprime para cada época, lo que te permite controlar el progreso del entrenamiento. En un escenario real, sustituirías las secuencias aleatorias de origen y destino por datos reales de tu tarea, como la traducción automática.
Tras entrenar el modelo, se puede evaluar su rendimiento en un conjunto de datos de validación o de prueba. El siguiente es un ejemplo de cómo podría hacerse:
transformer.eval()
# Generate random sample validation data
val_src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
val_tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
with torch.no_grad():
val_output = transformer(val_src_data, val_tgt_data[:, :-1])
val_loss = criterion(val_output.contiguous().view(-1, tgt_vocab_size), val_tgt_data[:, 1:].contiguous().view(-1))
print(f"Validation Loss: {val_loss.item()}")Modo de evaluación:
transformer.eval(): Pone el modelo de transformador en modo de evaluación. Esto es importante porque desactiva ciertos comportamientos, como el abandono, que sólo se utilizan durante el entrenamiento.Genera datos de validación aleatorios:
val_src_data: Números enteros aleatorios entre 1 y src_vocab_size, que representan un lote de secuencias fuente de validación con forma (64, max_seq_length).val_tgt_data: Números enteros aleatorios entre 1 y tgt_vocab_size, que representan un lote de secuencias objetivo de validación con forma (64, max_seq_length).Bucle de validación:
with torch.no_grad(): Desactiva el cálculo de gradientes, ya que no necesitamos calcular gradientes durante la validación. Esto puede reducir el consumo de memoria y acelerar los cálculos.val_output = transformer(val_src_data, val_tgt_data[:, :-1]): Pasa los datos de origen de la validación y los datos de destino de la validación (excluyendo el último token de cada secuencia) a través del transformador.val_loss = criterion(...): Calcula la pérdida entre las predicciones del modelo y los datos objetivo de validación (excluyendo el primer token de cada secuencia). La pérdida se calcula remodelando los datos en tensores unidimensionales y utilizando la función de pérdida de entropía cruzada definida anteriormente.print(f"Validation Loss: {val_loss.item()}"): Imprime el valor de pérdida de validación.Resumen:
Este fragmento de código evalúa el modelo transformador en un conjunto de datos de validación generado aleatoriamente, calcula la pérdida de validación y la imprime. En un escenario real, los datos de validación aleatorios deberían sustituirse por datos de validación reales de la tarea en la que estás trabajando. La pérdida de validación puede darte una indicación de lo bien que funciona tu modelo con datos no vistos, que es una medida crítica de la capacidad de generalización del modelo.
Para más detalles sobre los Transformadores y la Cara Abrazada, es útil nuestro tutorial Introducción al uso de los Transformadores y la Cara Abrazada.
En conclusión, este tutorial ha demostrado cómo construir un modelo Transformer utilizando PyTorch, una de las herramientas más versátiles para el aprendizaje profundo. Con su capacidad de paralelización y de captar dependencias a largo plazo en los datos, los Transformadores tienen un inmenso potencial en diversos campos, especialmente en tareas de PNL como la traducción, el resumen y el análisis de sentimientos.
Para quienes deseen profundizar en los conceptos y técnicas avanzados del aprendizaje profundo, considera la posibilidad de explorar el curso Aprendizaje profundo avanzado con Keras en DataCamp. También puedes leer sobre la construcción de una red neuronal sencilla con PyTorch en otro tutorial.
¡Aprende más sobre PyTorch con estos cursos!
Curso
Curso
Curso
Tutorial
Tutorial
Bex Tuychiev
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes
Tutorial
Moez Ali

