
Cursus
Efficiënt AI-modellen trainen met PyTorch
4 Hr
1.6K
Voor het eerst geïntroduceerd in de paper Attention is All You Need van Vaswani et al., zijn Transformers sindsdien een hoeksteen geworden van veel NLP-taken dankzij hun unieke ontwerp en effectiviteit.
In het hart van Transformers staat het attention-mechanisme, specifiek het concept van 'self-attention', waarmee het model verschillende delen van de invoergegevens kan wegen en prioriteren. Dit mechanisme stelt Transformers in staat om lange-afstandsafhankelijkheden in data te beheren. Het is in essentie een wegingsschema dat een model toestaat om op verschillende delen van de input te focussen bij het produceren van een output.
Het self-attention-mechanisme laat het model verschillende woorden of features in de inputsequentie in beschouwing nemen, waarbij elk een 'gewicht' krijgt dat de belangrijkheid aangeeft voor het genereren van een bepaalde output. In een zinsvertalingstaak kan het model bijvoorbeeld bij het vertalen van een specifiek woord hogere attention-gewichten toekennen aan woorden die grammaticaal of semantisch gerelateerd zijn aan het doelwoord. Dit proces stelt de Transformer in staat om afhankelijkheden tussen woorden of features vast te leggen, ongeacht hun afstand tot elkaar in de sequentie.
De impact van Transformers op het NLP-veld kan nauwelijks worden overschat. Ze presteren beter dan traditionele modellen bij veel taken en tonen een superieur vermogen om menselijke taal op een meer genuanceerde manier te begrijpen en te genereren.
Voor meer diepgang in NLP is DataCamps cursus Introductie tot Natural Language Processing in Python een aanbevolen bron.
Voordat je een Transformer bouwt, is het essentieel om de werkomgeving correct in te richten. Allereerst moet PyTorch worden geïnstalleerd. PyTorch kan worden geïnstalleerd via de pakketbeheerders pip of conda.
Voor pip, gebruik het commando:
pip3 install torch torchvision torchaudioVoor conda, gebruik het commando:
conda install pytorch torchvision -c pytorchVoor andere opties om PyTorch te installeren en uit te voeren, raadpleeg de officiële website.
Daarnaast is een basisbegrip van deep learning-concepten nuttig, omdat deze fundamenteel zijn voor het begrijpen van de werking van Transformers. Voor wie een opfrisser nodig heeft, is de DataCamp-cursus Deep Learning in Python een waardevolle bron die sleutelconcepten in deep learning behandelt.
Om het Transformer-model te bouwen, zijn de volgende stappen nodig:
We beginnen met het importeren van de PyTorch-bibliotheek voor de kernfunctionaliteit, de neural network-module voor het maken van neurale netwerken, de optimalisatiemodule voor het trainen van netwerken en de datahulpfuncties voor het omgaan met data. Daarnaast importeren we de standaard Python-math-module voor wiskundige operaties en de copy-module voor het maken van kopieën van complexe objecten.
Deze tools vormen de basis voor het definiëren van de architectuur van het model, het beheren van data en het opzetten van het trainingsproces.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import math
import copyVoordat we onze componenten gaan bouwen, bekijk de volgende tabel, die de verschillende componenten van een Transformer en hun doel beschrijft:
| Component | Beschrijving | Doel |
|---|---|---|
| Multi-Head Attention | Mechanisme om op verschillende delen van de input te focussen | Legt afhankelijkheden vast over verschillende posities in de sequentie |
| Feed-Forward Networks | Position-wise volledig verbonden lagen | Transformeert de attention-uitvoer en voegt complexiteit toe |
| Positional Encoding | Voegt positionele informatie toe aan embeddings | Biedt context over de volgorde van de sequentie aan het model |
| Layer Normalization | Normaliseert inputs naar elke sublaag | Stabiliseert training, verbetert convergentie |
| Residual Connections | Snelkoppelingen tussen lagen | Helpt bij het trainen van diepere netwerken door gradiëntproblemen te minimaliseren |
| Dropout | Zet willekeurig sommige netwerkverbindingen op nul | Voorkomt overfitting door het model te regulariseren |
Het multi-head attention-mechanisme berekent de attention tussen elk paar posities in een sequentie. Het bestaat uit meerdere “attention heads” die verschillende aspecten van de inputsequentie vastleggen.
Om meer te leren over multi-head attention, bekijk de sectie attention mechanisms van de cursus Large Language Models (LLMs) Concepts.
Figuur 1. Multi-Head Attention (bron: afbeelding gemaakt door auteur)
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
# Ensure that the model dimension (d_model) is divisible by the number of heads
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
# Initialize dimensions
self.d_model = d_model # Model's dimension
self.num_heads = num_heads # Number of attention heads
self.d_k = d_model // num_heads # Dimension of each head's key, query, and value
# Linear layers for transforming inputs
self.W_q = nn.Linear(d_model, d_model) # Query transformation
self.W_k = nn.Linear(d_model, d_model) # Key transformation
self.W_v = nn.Linear(d_model, d_model) # Value transformation
self.W_o = nn.Linear(d_model, d_model) # Output transformation
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# Calculate attention scores
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# Apply mask if provided (useful for preventing attention to certain parts like padding)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# Softmax is applied to obtain attention probabilities
attn_probs = torch.softmax(attn_scores, dim=-1)
# Multiply by values to obtain the final output
output = torch.matmul(attn_probs, V)
return output
def split_heads(self, x):
# Reshape the input to have num_heads for multi-head attention
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
def combine_heads(self, x):
# Combine the multiple heads back to original shape
batch_size, _, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
def forward(self, Q, K, V, mask=None):
# Apply linear transformations and split heads
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# Perform scaled dot-product attention
attn_output = self.scaled_dot_product_attention(Q, K, V, mask)
# Combine heads and apply output transformation
output = self.W_o(self.combine_heads(attn_output))
return outputClassdefinitie en initialisatie:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):De klasse is gedefinieerd als een subklasse van PyTorchs nn.Module.
d_model: Dimensionaliteit van de input.num_heads: Het aantal attention-heads waarin de input wordt opgesplitst.De initialisatie controleert of d_model deelbaar is door num_heads, en definieert vervolgens de transformatiewegingen voor query, key, value en output.
Scaled dot-product attention:
def scaled_dot_product_attention(self, Q, K, V, mask=None):attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k). Hier worden de attention-scores berekend door het inwendig product te nemen van queries (Q) en keys (K), en vervolgens te schalen met de wortel uit de sleutel-dimensie (d_k).V).Heads splitsen:
def split_heads(self, x):Deze methode herschaalt de input x naar de vorm (batch_size, num_heads, seq_length, d_k). Dit stelt het model in staat meerdere attention-heads gelijktijdig te verwerken, waardoor parallelle berekening mogelijk is.
Heads combineren:
def combine_heads(self, x):Na het afzonderlijk toepassen van attention op elke head combineert deze methode de resultaten weer tot één tensor met vorm (batch_size, seq_length, d_model). Dit bereidt het resultaat voor op verdere verwerking.
Forward-methode:
def forward(self, Q, K, V, mask=None):De forward-methode is waar de daadwerkelijke berekening plaatsvindt:
Q), keys (K) en values (V) gaan eerst door lineaire transformaties met de gewichten die in de initialisatie zijn gedefinieerd.Q, K, V worden opgesplitst in meerdere heads met de methode split_heads.scaled_dot_product_attention wordt aangeroepen op de gesplitste heads.combine_heads.Samengevat omvat de klasse MultiHeadAttention het multi-head attention-mechanisme dat vaak wordt gebruikt in transformermodellen. Het zorgt voor het opsplitsen van de input in meerdere attention-heads, het toepassen van attention op elke head en het vervolgens combineren van de resultaten. Zo kan het model verschillende relaties in de inputdata op verschillende schalen vastleggen, wat het expressieve vermogen van het model verbetert.
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))Classdefinitie:
class PositionWiseFeedForward(nn.Module):De klasse is een subklasse van PyTorchs nn.Module, wat betekent dat hij alle functionaliteit erft die nodig is om met neurale netwerklagen te werken.
Initialisatie:
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()d_model: Dimensionaliteit van de input en output van het model.d_ff: Dimensionaliteit van de binnenlaag in het feed-forward netwerk.self.fc1 en self.fc2: Twee volledig verbonden (lineaire) lagen met input- en outputdimensies zoals gedefinieerd door d_model en d_ff.self.relu: ReLU (Rectified Linear Unit) activatiefunctie, die niet-lineariteit introduceert tussen de twee lineaire lagen.Forward-methode:
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))x: De input voor het feed-forward netwerk.self.fc1(x): De input gaat eerst door de eerste lineaire laag (fc1).self.relu(...): De output van fc1 gaat vervolgens door een ReLU-activatiefunctie. ReLU vervangt alle negatieve waarden door nullen en introduceert zo niet-lineariteit in het model.self.fc2(...): De geactiveerde output gaat daarna door de tweede lineaire laag (fc2), wat de uiteindelijke output oplevert.Samengevat definieert de klasse PositionWiseFeedForward een position-wise feed-forward neuraal netwerk dat bestaat uit twee lineaire lagen met daartussen een ReLU-activatie. In de context van transformermodellen wordt dit feed-forward netwerk afzonderlijk en identiek op elke positie toegepast. Het helpt bij het transformeren van de features die door de attention-mechanismen in de transformer zijn geleerd en fungeert als extra verwerkingsstap voor de attention-uitvoer.
Positional Encoding wordt gebruikt om de positie-informatie van elke token in de inputsequentie toe te voegen. Het gebruikt sinus- en cosinusfuncties met verschillende frequenties om de positionele encodering te genereren.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1)]Classdefinitie:
class PositionalEncoding(nn.Module):De klasse is gedefinieerd als een subklasse van PyTorchs nn.Module, zodat hij als een standaard PyTorch-laag kan worden gebruikt.
Initialisatie:
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))d_model: De dimensie van de input van het model.max_seq_length: De maximale lengte van de sequentie waarvoor positionele coderingen vooraf worden berekend.pe: Een tensor gevuld met nullen, die wordt gevuld met positionele coderingen.position: Een tensor met de positie-indexen voor elke positie in de sequentie.div_term: Een term die wordt gebruikt om de positie-indexen op een specifieke manier te schalen.pe.pe geregistreerd als buffer, wat betekent dat het onderdeel is van de toestand van de module, maar niet wordt beschouwd als een trainbare parameter.Forward-methode:
def forward(self, x):
return x + self.pe[:, :x.size(1)]De forward-methode voegt simpelweg de positionele coderingen toe aan de input x.
Hij gebruikt de eerste x.size(1)-elementen van pe om ervoor te zorgen dat de positionele coderingen overeenkomen met de daadwerkelijke sequentielengte van x.
Samenvatting
De klasse PositionalEncoding voegt informatie toe over de positie van tokens binnen de sequentie. Omdat het transformermodel geen ingebakken kennis heeft van de volgorde van tokens (door het self-attention-mechanisme), helpt deze klasse het model om de positie van tokens in de sequentie mee te nemen. De gebruikte sinusoïdale functies zijn gekozen zodat het model gemakkelijk relatieve posities kan leren, omdat ze voor elke positie in de sequentie een unieke en vloeiende codering produceren.
Figuur 2. Het encoder-deel van het transformer-netwerk (Bron: afbeelding uit de originele paper)
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xClassdefinitie:
class EncoderLayer(nn.Module):De klasse is gedefinieerd als een subklasse van PyTorchs nn.Module, wat betekent dat hij kan worden gebruikt als bouwsteen voor neurale netwerken in PyTorch.
Initialisatie:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parameters:
d_model: De dimensionaliteit van de input.num_heads: Het aantal attention-heads in de multi-head attention.d_ff: De dimensionaliteit van de binnenlaag in het position-wise feed-forward netwerk.dropout: Het dropout-percentage dat wordt gebruikt voor regularisatie.Componenten:
self.self_attn: Multi-head attention-mechanisme.self.feed_forward: Position-wise feed-forward neuraal netwerk.self.norm1 en self.norm2: Laagnormalisatie, toegepast om de input van de laag te stabiliseren.self.dropout: Dropout-laag, gebruikt om overfitting te voorkomen door tijdens training willekeurig enkele activaties op nul te zetten.Forward-methode:
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xInput:
x: De input voor de encoderlaag.mask: Optioneel masker om bepaalde delen van de input te negeren.Verwerkingsstappen:
x gaat door het multi-head self-attention-mechanisme.norm1.norm2.Samenvatting:
De klasse EncoderLayer definieert één laag van de encoder van de transformer. Hij omvat een multi-head self-attention-mechanisme, gevolgd door het position-wise feed-forward neuraal netwerk, met residuele verbindingen, laagnormalisatie en dropout waar passend. Samen stellen deze componenten de encoder in staat om complexe relaties in de inputdata vast te leggen en ze te transformeren naar een bruikbare representatie voor vervolgtaken. Meestal worden meerdere van zulke encoderlagen gestapeld om het volledige encoderdeel van een transformermodel te vormen.
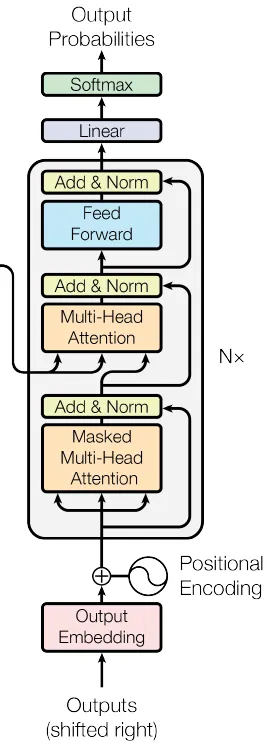
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xClassdefinitie:
class DecoderLayer(nn.Module):Initialisatie:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parameters:
d_model: De dimensionaliteit van de input.num_heads: Het aantal attention-heads in de multi-head attention.d_ff: De dimensionaliteit van de binnenlaag in het feed-forward netwerk.dropout: Het dropout-percentage voor regularisatie.Componenten:
self.self_attn: Multi-head self-attention-mechanisme voor de doelsequentie.self.cross_attn: Multi-head attention-mechanisme dat focust op de output van de encoder.self.feed_forward: Position-wise feed-forward neuraal netwerk.self.norm1, self.norm2, self.norm3: Componenten voor laagnormalisatie.self.dropout: Dropout-laag voor regularisatie.Forward methode:
ef forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xInput:
x: De input voor de decoderlaag.enc_output: De output van de overeenkomstige encoder (gebruikt in de cross-attention-stap).src_mask: Bronnenmasker om bepaalde delen van de encoderuitvoer te negeren.tgt_mask: Doelmasker om bepaalde delen van de decoderinput te negeren.Verwerkingsstappen:
enc_output.Samenvatting:
De klasse DecoderLayer definieert één laag van de decoder van de transformer. Hij bestaat uit een multi-head self-attention-mechanisme, een multi-head cross-attention-mechanisme (dat focust op de encoderuitvoer), een position-wise feed-forward neuraal netwerk en de bijbehorende residuele verbindingen, laagnormalisatie en dropout-lagen. Deze combinatie stelt de decoder in staat om betekenisvolle outputs te genereren op basis van de representaties van de encoder, rekening houdend met zowel de doelsequentie als de bronnensequentie. Net als bij de encoder worden doorgaans meerdere decoderlagen gestapeld om het volledige decoderdeel van een transformermodel te vormen.
Vervolgens worden de Encoder- en Decoder-blokken gecombineerd om het volledige Transformer-model te construeren.
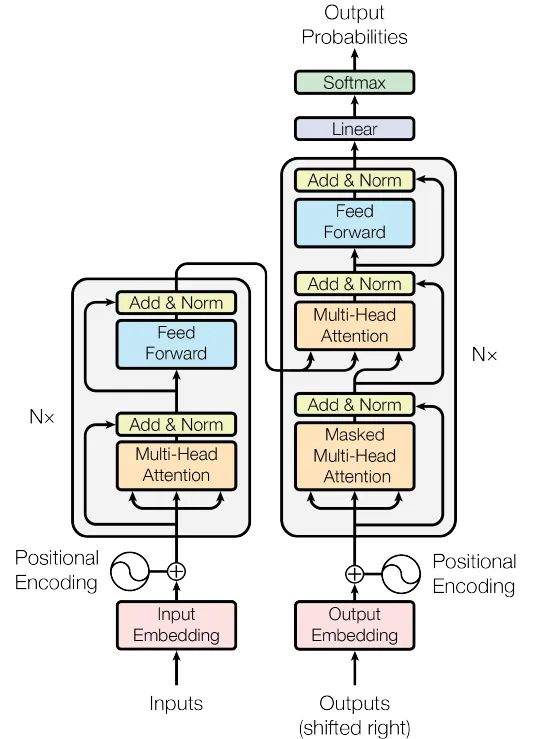
Figuur 4. Het Transformer-netwerk (Bron: afbeelding uit de originele paper)
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):
super(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_length)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.fc = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def generate_mask(self, src, tgt):
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.size(1)
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask
return src_mask, tgt_mask
def forward(self, src, tgt):
src_mask, tgt_mask = self.generate_mask(src, tgt)
src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))
tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
output = self.fc(dec_output)
return outputClassdefinitie:
class Transformer(nn.Module):Initialisatie:
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):De constructor neemt de volgende parameters aan:
src_vocab_size: Grootte van de bronvocabulaire.tgt_vocab_size: Grootte van de doelvocabulaire.d_model: De dimensionaliteit van de embeddings van het model.num_heads: Aantal attention-heads in het multi-head attention-mechanisme.num_layers: Aantal lagen voor zowel de encoder als de decoder.d_ff: Dimensionaliteit van de binnenlaag in het feed-forward netwerk.max_seq_length: Maximale sequentielengte voor positional encoding.dropout: Dropout-percentage voor regularisatie.En hij definieert de volgende componenten:
self.encoder_embedding: Embedding-laag voor de bronnensequentie.self.decoder_embedding: Embedding-laag voor de doelsequentie.self.positional_encoding: Component voor positional encoding.self.encoder_layers: Een lijst met encoderlagen.self.decoder_layers: Een lijst met decoderlagen.self.fc: Finale volledig verbonden (lineaire) laag die naar de doelvocabulairegrootte projecteert.self.dropout: Dropout-laag.Generate mask-methode:
def generate_mask(self, src, tgt):Deze methode wordt gebruikt om maskers te maken voor de bron- en doelsequenties, zodat padding-tokens worden genegeerd en toekomstige tokens niet zichtbaar zijn tijdens training voor de doelsequentie.
Forward-methode:
def forward(self, src, tgt):Deze methode definieert de forward-pass voor de Transformer, waarbij bron- en doelsequenties worden genomen en de outputvoorspellingen worden geproduceerd.
Output:
De uiteindelijke output is een tensor die de voorspellingen van het model voor de doelsequentie vertegenwoordigt.
Samenvatting:
De Transformer-klasse brengt de verschillende componenten van een Transformer-model samen, waaronder de embeddings, positional encoding, encoderlagen en decoderlagen. Hij biedt een handige interface voor training en inferentie en kapselt de complexiteit van multi-head attention, feed-forward netwerken en laagnormalisatie in.
Deze implementatie volgt de standaard Transformer-architectuur en is geschikt voor sequence-to-sequence-taken zoals machinevertaling, samenvatting enzovoort. Het opnemen van maskering zorgt ervoor dat het model zich houdt aan de causale afhankelijkheden binnen sequenties, padding-tokens negeert en informatielekken vanuit toekomstige tokens voorkomt.
Deze opeenvolgende stappen stellen het Transformer-model in staat om invoersequenties efficiënt te verwerken en bijbehorende uitvoersequenties te produceren.
Voor illustratieve doeleinden wordt in dit voorbeeld een dummy-dataset gemaakt. In een praktische setting zou echter een grotere dataset worden gebruikt en zou het proces tekstvoorbewerking omvatten, samen met het aanmaken van vocabulairemappingen voor zowel de bron- als doeltaal.
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_seq_length = 100
dropout = 0.1
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)
# Generate random sample data
src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)Hyperparameters:
Deze waarden definiëren de architectuur en het gedrag van het transformer-model:
src_vocab_size, tgt_vocab_size: Grootte van de vocabulaire voor bron- en doelsequenties, beide op 5000 ingesteld.d_model: Dimensionaliteit van de embeddings van het model, ingesteld op 512.num_heads: Aantal attention-heads in het multi-head attention-mechanisme, ingesteld op 8.num_layers: Aantal lagen voor zowel de encoder als de decoder, ingesteld op 6.d_ff: Dimensionaliteit van de binnenlaag in het feed-forward netwerk, ingesteld op 2048.max_seq_length: Maximale sequentielengte voor positional encoding, ingesteld op 100.dropout: Dropout-percentage voor regularisatie, ingesteld op 0,1.Ter referentie beschrijft de volgende tabel de meest gangbare hyperparameters voor Transformer-modellen en hun waarden:
| Hyperparameter | Typische waarden | Impact op prestaties |
|---|---|---|
| d_model | 256, 512, 1024 | Hogere waarden vergroten de modelcapaciteit maar vereisen meer rekenkracht |
| num_heads | 8, 12, 16 | Meer heads kunnen diverse aspecten van data vastleggen, maar zijn rekenintensiever |
| num_layers | 6, 12, 24 | Meer lagen verbeteren het representatievermogen, maar kunnen tot overfitting leiden |
| d_ff | 2048, 4096 | Grotere feed-forward netwerken vergroten de robuustheid van het model |
| dropout | 0,1, 0,3 | Regulariseert het model om overfitting te voorkomen |
| learning rate | 0,0001 - 0,001 | Beïnvloedt de snelheid en stabiliteit van de convergentie |
| batch size | 32, 64, 128 | Grotere batchgroottes verbeteren de stabiliteit van het leren maar vergen meer geheugen |
Een Transformer-instantie maken:
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)Deze regel maakt een instantie van de klasse Transformer en initialiseert deze met de gegeven hyperparameters. De instantie krijgt de architectuur en het gedrag zoals gedefinieerd door deze hyperparameters.
Willekeurige voorbeelddata genereren:
De volgende regels genereren willekeurige bron- en doelsequenties:
src_data: Willekeurige gehele getallen tussen 1 en src_vocab_size, die een batch bronnensequenties voorstellen met vorm (64, max_seq_length).tgt_data: Willekeurige gehele getallen tussen 1 en tgt_vocab_size, die een batch doelsequenties voorstellen met vorm (64, max_seq_length).Samenvatting:
De code snippet laat zien hoe je een Transformer-model initialiseert en willekeurige bron- en doelsequenties genereert die daarin kunnen worden ingevoerd. De gekozen hyperparameters bepalen de specifieke structuur en eigenschappen van de Transformer. Deze setup kan deel uitmaken van een groter script waarin het model wordt getraind en geëvalueerd op daadwerkelijke sequence-to-sequence-taken, zoals machinevertaling of tekstsamenvatting.
Vervolgens wordt het model getraind met gebruik van de bovenstaande voorbeelddata. In een echte situatie zou echter een aanzienlijk grotere dataset worden gebruikt, die doorgaans wordt opgesplitst in aparte sets voor training en validatie.
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
transformer.train()
for epoch in range(100):
optimizer.zero_grad()
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:].contiguous().view(-1))
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")Lossfunctie en optimizer:
criterion = nn.CrossEntropyLoss(ignore_index=0): Definieert de lossfunctie als cross-entropy loss. Het argument ignore_index is ingesteld op 0, wat betekent dat de loss doelen met index 0 (doorgaans gereserveerd voor padding-tokens) niet meeneemt.optimizer = optim.Adam(...): Definieert de optimizer als Adam met een learning rate van 0,0001 en specifieke beta-waarden.Trainingsmodus van het model:
transformer.train(): Zet het transformer-model in trainingsmodus, waardoor gedrag zoals dropout wordt ingeschakeld dat alleen tijdens training geldt.Trainingslus:
De code snippet traint het model 100 epochs met een typische trainingslus:
for epoch in range(100): Itereert over 100 trainingsepoches.optimizer.zero_grad(): Leegt de gradiënten van de vorige iteratie.output = transformer(src_data, tgt_data[:, :-1]): Voert de brondaten en de doeldaten (exclusief de laatste token in elke sequentie) door de transformer. Dit is gebruikelijk bij sequence-to-sequence-taken waarbij het doel één token verschoven is.loss = criterion(...): Berekent de loss tussen de voorspellingen van het model en de doeldaten (exclusief de eerste token in elke sequentie). De loss wordt berekend door de data te herschikken naar eendimensionale tensors en de cross-entropy lossfunctie te gebruiken.loss.backward(): Berekent de gradiënten van de loss ten opzichte van de parameters van het model.optimizer.step(): Werkt de parameters van het model bij met de berekende gradiënten.print(f"Epoch: {epoch+1}, Loss: {loss.item()}"): Print het huidige epoch-nummer en de losswaarde voor dat epoch.Samenvatting:
Deze code snippet traint het transformer-model op willekeurig gegenereerde bron- en doelsequenties gedurende 100 epochs. Hij gebruikt de Adam-optimizer en de cross-entropy lossfunctie. De loss wordt per epoch geprint, zodat je de voortgang van de training kunt volgen. In een echte toepassing vervang je de willekeurige bron- en doelsequenties door echte data van je taak, zoals machinevertaling.
Na het trainen van het model kan de prestatie worden geëvalueerd op een validatieset of testset. Het volgende is een voorbeeld van hoe dit kan worden gedaan:
transformer.eval()
# Generate random sample validation data
val_src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
val_tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
with torch.no_grad():
val_output = transformer(val_src_data, val_tgt_data[:, :-1])
val_loss = criterion(val_output.contiguous().view(-1, tgt_vocab_size), val_tgt_data[:, 1:].contiguous().view(-1))
print(f"Validation Loss: {val_loss.item()}")Evaluatiemodus:
transformer.eval(): Zet het transformer-model in evaluatiemodus. Dit is belangrijk omdat het bepaald gedrag uitschakelt, zoals dropout, dat alleen tijdens training wordt gebruikt.Willekeurige validatiedata genereren:
val_src_data: Willekeurige gehele getallen tussen 1 en src_vocab_size, die een batch validatie-bronnensequenties voorstellen met vorm (64, max_seq_length).val_tgt_data: Willekeurige gehele getallen tussen 1 en tgt_vocab_size, die een batch validatie-doelsequenties voorstellen met vorm (64, max_seq_length).Validatielus:
with torch.no_grad(): Schakelt gradiëntberekening uit, omdat we tijdens validatie geen gradiënten hoeven te berekenen. Dit kan het geheugenverbruik verminderen en berekeningen versnellen.val_output = transformer(val_src_data, val_tgt_data[:, :-1]): Voert de validatie-brondaten en de validatie-doeldaten (exclusief de laatste token in elke sequentie) door de transformer.val_loss = criterion(...): Berekent de loss tussen de voorspellingen van het model en de validatie-doeldaten (exclusief de eerste token in elke sequentie). De loss wordt berekend door de data te herschikken naar eendimensionale tensors en de eerder gedefinieerde cross-entropy lossfunctie te gebruiken.print(f"Validation Loss: {val_loss.item()}"): Print de validatielosswaarde.Samenvatting:
Deze code snippet evalueert het transformer-model op een willekeurig gegenereerde validatieset, berekent de validatieloss en print deze. In een echte toepassing vervang je de willekeurige validatiedata door echte validatiedata van de taak waaraan je werkt. De validatieloss geeft een indicatie van hoe goed je model presteert op onzichtbare data, wat cruciaal is voor het generalisatievermogen van het model.
Voor meer details over Transformers en Hugging Face is onze tutorial Een introductie tot het gebruik van Transformers en Hugging Face nuttig.
Kortom, deze tutorial liet zien hoe je een Transformer-model opzet met PyTorch, een van de meest veelzijdige tools voor deep learning. Dankzij hun vermogen tot parallelisatie en het vastleggen van langetermijnafhankelijkheden in data hebben Transformers enorm potentieel in verschillende domeinen, vooral bij NLP-taken zoals vertalen, samenvatten en sentimentanalyse.
Voor wie zijn begrip van geavanceerde deep learning-concepten en -technieken wil verdiepen, overweeg de cursus Advanced Deep Learning with Keras op DataCamp te verkennen. Je kunt ook in een aparte tutorial lezen over het bouwen van een eenvoudig neuraal netwerk met PyTorch.
Leer meer over PyTorch met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
