
Kurs
PyTorch ile Verimli AI Model Eğitimi
4 sa
1.6K
İlk olarak Vaswani ve arkadaşlarının Attention is All You Need makalesinde tanıtılan Transformer'lar, benzersiz tasarımları ve etkinlikleri nedeniyle birçok NLP görevinin temel yapı taşı haline gelmiştir.
Transformer'ların kalbinde, modelin girdi verisinin farklı kısımlarını tartmasına ve önceliklendirmesine olanak tanıyan dikkat mekanizması, özel olarak da "öz-dikkat" (self-attention) kavramı yer alır. Bu mekanizma, Transformer'ların verideki uzun menzilli bağımlılıkları yönetmesini sağlar. Özünde, modelin çıktı üretirken girdinin farklı bölümlerine odaklanmasını sağlayan bir ağırlıklandırma düzenidir.
Öz-dikkat mekanizması, modelin girdi dizisindeki farklı kelime veya özellikleri dikkate almasını ve her birine, belirli bir çıktı üretmek için önemini ifade eden bir "ağırlık" atamasını sağlar. Örneğin, bir cümle çevirisi görevinde model, belirli bir kelimeyi çevirirken, hedef kelimeyle dilbilgisel veya anlamsal olarak ilişkili kelimelere daha yüksek dikkat ağırlıkları verebilir. Bu süreç, Transformer'ın, dizideki konumları birbirinden ne kadar uzakta olursa olsun kelimeler veya özellikler arasındaki bağımlılıkları yakalamasına olanak tanır.
Transformer'ların NLP alanındaki etkisi abartılamaz. Birçok görevde geleneksel modelleri geride bırakarak insan dilini daha incelikli biçimde anlama ve üretme kapasitesini göstermişlerdir.
NLP'yi daha derinlemesine anlamak için DataCamp'in Introduction to Natural Language Processing in Python kursu yararlı bir kaynaktır.
Bir Transformer inşa etmeden önce, çalışma ortamını doğru şekilde kurmak gerekir. Her şeyden önce, PyTorch kurulmalıdır. PyTorch, pip veya conda paket yöneticileriyle kurulabilir.
pip için şu komutu kullanın:
pip3 install torch torchvision torchaudioconda için şu komutu kullanın:
conda install pytorch torchvision -c pytorchPyTorch'u kurup çalıştırmanın diğer seçenekleri için resmî web sitesine bakın.
Ayrıca, Transformer'ların çalışma prensiplerini anlamak için temel derin öğrenme kavramlarına dair bir bilgi sahibi olmak faydalıdır. Tazeleme ihtiyacı olanlar için DataCamp'teki Deep Learning in Python kursu, derin öğrenmenin temel kavramlarını kapsayan değerli bir kaynaktır.
Transformer modelini inşa etmek için aşağıdaki adımlar gereklidir:
Çekirdek işlevler için PyTorch kütüphanesini, sinir ağı modülünü ağlar oluşturmak için, optimizasyon modülünü ağları eğitmek için ve veri yardımcı işlevlerini veriyi işlemek için içe aktararak başlayacağız. Ayrıca matematiksel işlemler için standart Python math modülünü ve karmaşık nesnelerin kopyalarını oluşturmak için copy modülünü içe aktaracağız.
Bu araçlar, modelin mimarisini tanımlamak, veriyi yönetmek ve eğitim sürecini kurmak için temel oluşturur.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import math
import copyBileşenlerimizi oluşturmaya geçmeden önce, bir Transformer'ın farklı bileşenlerini ve amaçlarını açıklayan aşağıdaki tabloya göz atın:
| Bileşen | Açıklama | Amacı |
|---|---|---|
| Multi-Head Attention | Girdinin farklı kısımlarına odaklanma mekanizması | Dizideki farklı konumlar arasındaki bağımlılıkları yakalar |
| Feed-Forward Networks | Konuma göre tam bağlantılı katmanlar | Dikkat çıktısını dönüştürerek karmaşıklık ekler |
| Positional Encoding | Gömlemelere konumsal bilgi ekler | Modele dizi sırası bağlamı sağlar |
| Layer Normalization | Her alt katmanın girdilerini normalize eder | Eğitimi dengeler, yakınsamayı iyileştirir |
| Residual Connections | Katmanlar arasında kısayollar | Gradyan sorunlarını en aza indirerek daha derin ağların eğitimine yardımcı olur |
| Dropout | Ağ bağlantılarının bir kısmını rastgele sıfırlar | Modeli düzenlileştirerek aşırı uyumu önler |
Çok başlıklı dikkat mekanizması, bir dizideki her konum çifti arasındaki dikkati hesaplar. Girdi dizisinin farklı yönlerini yakalayan birden çok "dikkat başlığından" oluşur.
Çok başlıklı dikkat hakkında daha fazla bilgi edinmek için, Büyük Dil Modelleri (LLM'ler) Concepts kursunun dikkat mekanizmaları bölümüne göz atın.
Şekil 1. Çok Başlıklı Dikkat (kaynak: yazar tarafından oluşturulan görsel)
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
# Ensure that the model dimension (d_model) is divisible by the number of heads
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
# Initialize dimensions
self.d_model = d_model # Model's dimension
self.num_heads = num_heads # Number of attention heads
self.d_k = d_model // num_heads # Dimension of each head's key, query, and value
# Linear layers for transforming inputs
self.W_q = nn.Linear(d_model, d_model) # Query transformation
self.W_k = nn.Linear(d_model, d_model) # Key transformation
self.W_v = nn.Linear(d_model, d_model) # Value transformation
self.W_o = nn.Linear(d_model, d_model) # Output transformation
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# Calculate attention scores
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# Apply mask if provided (useful for preventing attention to certain parts like padding)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# Softmax is applied to obtain attention probabilities
attn_probs = torch.softmax(attn_scores, dim=-1)
# Multiply by values to obtain the final output
output = torch.matmul(attn_probs, V)
return output
def split_heads(self, x):
# Reshape the input to have num_heads for multi-head attention
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
def combine_heads(self, x):
# Combine the multiple heads back to original shape
batch_size, _, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
def forward(self, Q, K, V, mask=None):
# Apply linear transformations and split heads
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# Perform scaled dot-product attention
attn_output = self.scaled_dot_product_attention(Q, K, V, mask)
# Combine heads and apply output transformation
output = self.W_o(self.combine_heads(attn_output))
return outputSınıf tanımı ve başlatma:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):Sınıf, PyTorch'un nn.Module sınıfının bir alt sınıfı olarak tanımlanır.
d_model: Girdinin boyutu.num_heads: Girdinin bölüneceği dikkat başlığı sayısı.Başlatma, d_model'in num_heads'e bölünebilir olup olmadığını kontrol eder ve ardından query, key, value ve output için dönüşüm ağırlıklarını tanımlar.
Ölçekli noktasal çarpım dikkati:
def scaled_dot_product_attention(self, Q, K, V, mask=None):attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k). Burada, dikkat puanları Q (sorgular) ve K (anahtarlar) arasındaki noktasal çarpım alınarak ve ardından anahtar boyutunun (d_k) karekökü ile ölçeklendirilerek hesaplanır.V) çarpılmasıyla elde edilir.Başlıkların bölünmesi:
def split_heads(self, x):Bu yöntem, girişi (x) (batch_size, num_heads, seq_length, d_k) şekline dönüştürür. Bu, modelin birden çok dikkat başlığını aynı anda işlemesine ve paralel hesaplama yapmasına olanak tanır.
Başlıkların birleştirilmesi:
def combine_heads(self, x):Dikkat her başlığa ayrı ayrı uygulandıktan sonra, bu yöntem sonuçları (batch_size, seq_length, d_model) şekline sahip tek bir tensörde birleştirir. Bu, sonucu daha ileri işlemeye hazırlar.
İleri (forward) yöntem:
def forward(self, Q, K, V, mask=None):Gerçek hesaplamanın yapıldığı yer forward yöntemidir:
Q, K ve V önce başlatmada tanımlanan ağırlıklarla doğrusal dönüşümlerden geçirilir.Q, K, V split_heads yöntemiyle birden çok başlığa ayrılır.scaled_dot_product_attention yöntemi bölünmüş başlıklara uygulanır.combine_heads yöntemiyle tek bir tensörde birleştirilir.Özetle, MultiHeadAttention sınıfı, transformer modellerinde yaygın olarak kullanılan çok başlıklı dikkat mekanizmasını kapsüller. Girdiyi birden çok dikkat başlığına ayırır, dikkati her başlığa uygular ve sonuçları birleştirir. Böylece model, girdi verisindeki ilişkileri farklı ölçeklerde yakalayarak ifade gücünü artırır.
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))Sınıf tanımı:
class PositionWiseFeedForward(nn.Module):Sınıf, PyTorch'un nn.Module sınıfının bir alt sınıfıdır; bu da sinir ağı katmanlarıyla çalışmak için gerekli işlevlerin tümünü miras aldığı anlamına gelir.
Başlatma:
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()d_model: Modelin giriş ve çıkış boyutu.d_ff: Beslemeli ileri ağın iç katmanının boyutu.self.fc1 ve self.fc2: d_model ve d_ff ile tanımlanan giriş ve çıkış boyutlarına sahip iki tam bağlantılı (doğrusal) katman.self.relu: İki doğrusal katman arasında doğrusal olmayanlık katan ReLU (Düzeltici Doğrusal Birim) aktivasyon fonksiyonu.Forward yöntemi:
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))x: Beslemeli ileri ağa giriş.self.fc1(x): Girdi önce birinci doğrusal katmandan (fc1) geçirilir.self.relu(...): fc1 çıktısı ReLU aktivasyonundan geçirilir. ReLU, negatif değerleri sıfırla değiştirerek modele doğrusal olmayanlık katar.self.fc2(...): Aktive edilmiş çıktı, ikinci doğrusal katmandan (fc2) geçirilerek nihai çıktı üretilir.Özetle, PositionWiseFeedForward sınıfı, arada ReLU aktivasyonu bulunan iki doğrusal katmandan oluşan konuma göre bir beslemeli ileri sinir ağını tanımlar. Transformer modelleri bağlamında bu ağ, her konuma ayrı ayrı ve özdeş biçimde uygulanır. Dikkat mekanizmalarının öğrendiği özellikleri dönüştürerek dikkat çıktıları için ek bir işleme adımı görevi görür.
Konumsal Kodlama, girdi dizisindeki her bir belirtecin konum bilgisini enjekte etmek için kullanılır. Konumsal kodlamayı üretmek amacıyla farklı frekanslarda sinüs ve kosinüs fonksiyonları kullanır.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1)]Sınıf tanımı:
class PositionalEncoding(nn.Module):Sınıf, PyTorch'un nn.Module sınıfının bir alt sınıfı olarak tanımlanır ve standart bir PyTorch katmanı gibi kullanılmasını sağlar.
Başlatma:
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))d_model: Modelin giriş boyutu.max_seq_length: Konumsal kodlamaların önceden hesaplandığı azami dizi uzunluğu.pe: Konumsal kodlamalarla doldurulacak, başlangıçta sıfırlarla dolu bir tensör.position: Dizideki her konum için konum indekslerini içeren bir tensör.div_term: Konum indekslerini belirli bir şekilde ölçeklendirmek için kullanılan terim.pe'nin çift indekslerine, kosinüs fonksiyonu ise tek indekslerine uygulanır.pe, modülün durumunun parçası olup eğitilebilir bir parametre sayılmayan bir tampon olarak kaydedilir.Forward yöntemi:
def forward(self, x):
return x + self.pe[:, :x.size(1)]Forward yöntemi, konumsal kodlamaları girdi x üzerine basitçe ekler.
x'in gerçek dizi uzunluğuyla eşleşmesi için pe'nin ilk x.size(1) elemanlarını kullanır.
Özet
PositionalEncoding sınıfı, dizideki belirteçlerin konumuna dair bilgi ekler. Transformer modeli, öz-dikkat mekanizması nedeniyle belirteçlerin sırası hakkında doğuştan bir bilgiye sahip olmadığından, bu sınıf modelin belirteçlerin konumunu dikkate almasına yardımcı olur. Kullanılan sinüzoidal fonksiyonlar, her konum için benzersiz ve düzgün bir kodlama üreterek modelin göreli konumlara dikkat etmeyi kolayca öğrenmesini sağlar.
Şekil 2. Transformer ağının Encoder kısmı (Kaynak: orijinal makaleden görsel)
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xSınıf tanımı:
class EncoderLayer(nn.Module):Sınıf, PyTorch'un nn.Module sınıfının bir alt sınıfı olarak tanımlanır; bu da PyTorch'ta sinir ağları için bir yapı taşı olarak kullanılabileceği anlamına gelir.
Başlatma:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parametreler:
d_model: Girdi boyutu.num_heads: Çok başlıklı dikkat içindeki başlık sayısı.d_ff: Konuma göre beslemeli ileri ağın iç katman boyutu.dropout: Düzenlileştirme için kullanılan dropout oranı.Bileşenler:
self.self_attn: Çok başlıklı öz-dikkat mekanizması.self.feed_forward: Konuma göre beslemeli ileri sinir ağı.self.norm1 ve self.norm2: Katman girdisini düzleştirmek için kullanılan katman normalizasyonu.self.dropout: Eğitim sırasında bazı aktivasyonları rastgele sıfırlayarak aşırı uyumu önlemek için kullanılan dropout katmanı.Forward yöntemi:
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xGirdi:
x: Encoder katmanına giriş.mask: Girdinin belirli kısımlarını yoksaymak için isteğe bağlı maske.İşleme adımları:
x, çok başlıklı öz-dikkat mekanizmasından geçirilir.norm1 ile normalizasyon uygulanır.norm2 ile normalizasyon uygulanır.Özet:
EncoderLayer sınıfı, transformer'ın encoder'ının tek bir katmanını tanımlar. Uygun şekilde kalıntı bağlantıları, katman normalizasyonu ve dropout ile birlikte çok başlıklı öz-dikkat mekanizması ve konuma göre beslemeli ileri sinir ağını kapsar. Bu bileşenler birlikte, encoder'ın girdideki karmaşık ilişkileri yakalayıp bunları aşağı akış görevleri için yararlı bir gösterime dönüştürmesine olanak tanır. Genellikle bu türden birden çok encoder katmanı istiflenerek transformer modelinin tam encoder bölümü oluşturulur.
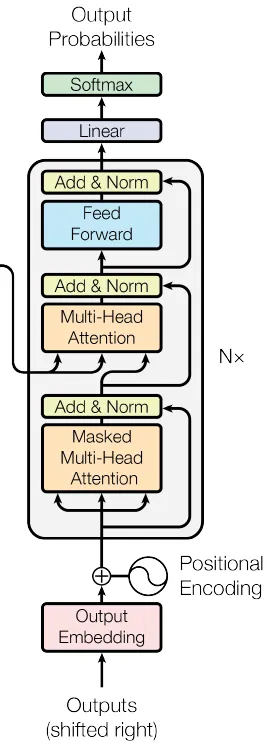
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xSınıf tanımı:
class DecoderLayer(nn.Module):Başlatma:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Parametreler:
d_model: Girdi boyutu.num_heads: Çok başlıklı dikkat içindeki başlık sayısı.d_ff: Beslemeli ileri ağın iç katman boyutu.dropout: Düzenlileştirme için dropout oranı.Bileşenler:
self.self_attn: Hedef dizi için çok başlıklı öz-dikkat mekanizması.self.cross_attn: Encoder çıktısına dikkat eden çok başlıklı çapraz dikkat mekanizması.self.feed_forward: Konuma göre beslemeli ileri sinir ağı.self.norm1, self.norm2, self.norm3: Katman normalizasyonu bileşenleri.self.dropout: Düzenlileştirme için dropout katmanı.Forward yöntemi:
ef forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xGirdi:
x: Decoder katmanına giriş.enc_output: İlgili encoder'dan gelen çıktı (çapraz dikkat adımında kullanılır).src_mask: Encoder çıktısının belirli kısımlarını yoksaymak için kaynak maskesi.tgt_mask: Decoder girdisinin belirli kısımlarını yoksaymak için hedef maskesi.İşleme adımları:
x bir öz-dikkat mekanizmasından geçirilir.x'e eklenir; ardından dropout ve norm1 ile normalizasyon yapılır.enc_output çıktısına dikkat eden bir çapraz dikkat mekanizmasından geçirilir.norm2 ile normalizasyon yapılır.norm3 ile normalizasyon yapılır.Özet:
DecoderLayer sınıfı, transformer'ın decoder'ının tek bir katmanını tanımlar. Çok başlıklı öz-dikkat, encoder çıktısına dikkat eden çok başlıklı çapraz dikkat, konuma göre beslemeli ileri ağ ve ilgili kalıntı bağlantıları, katman normalizasyonu ve dropout katmanlarından oluşur. Bu bileşim, decoder'ın encoder'ın temsillerine dayanarak, hem hedef diziyi hem de kaynak diziyi dikkate alıp anlamlı çıktılar üretmesini sağlar. Encoder'da olduğu gibi, genellikle birden çok decoder katmanı istiflenerek transformer modelinin tam decoder bölümü oluşturulur.
Sırada, kapsamlı Transformer modelini oluşturmak için Encoder ve Decoder bloklarının birleştirilmesi vardır.
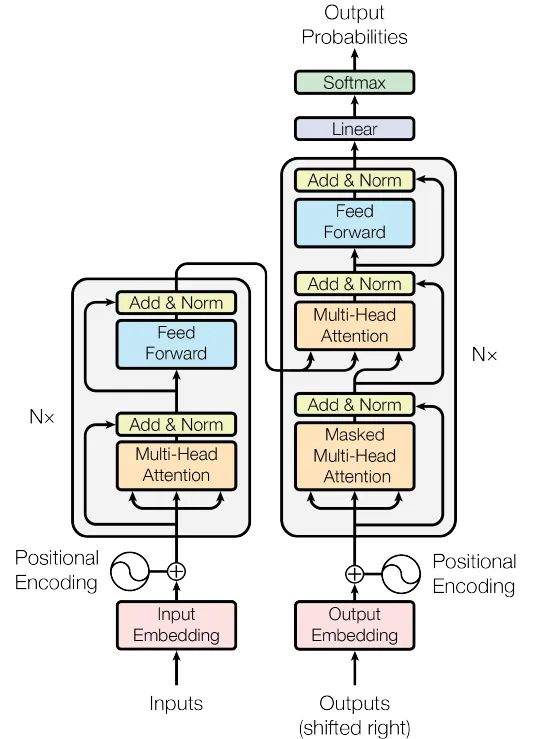
Şekil 4. Transformer Ağı (Kaynak: orijinal makaleden görsel)
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):
super(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_length)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.fc = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def generate_mask(self, src, tgt):
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.size(1)
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask
return src_mask, tgt_mask
def forward(self, src, tgt):
src_mask, tgt_mask = self.generate_mask(src, tgt)
src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))
tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
output = self.fc(dec_output)
return outputSınıf tanımı:
class Transformer(nn.Module):Başlatma:
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):Yapıcı aşağıdaki parametreleri alır:
src_vocab_size: Kaynak sözlük boyutu.tgt_vocab_size: Hedef sözlük boyutu.d_model: Model gömlemelerinin boyutu.num_heads: Çok başlıklı dikkat mekanizmasındaki başlık sayısı.num_layers: Hem encoder hem de decoder için katman sayısı.d_ff: Beslemeli ileri ağın iç katman boyutu.max_seq_length: Konumsal kodlama için azami dizi uzunluğu.dropout: Düzenlileştirme için dropout oranı.Ve şu bileşenleri tanımlar:
self.encoder_embedding: Kaynak dizi için gömme katmanı.self.decoder_embedding: Hedef dizi için gömme katmanı.self.positional_encoding: Konumsal kodlama bileşeni.self.encoder_layers: Encoder katmanlarının listesi.self.decoder_layers: Decoder katmanlarının listesi.self.fc: Hedef sözlük boyutuna eşleyen son tam bağlantılı (doğrusal) katman.self.dropout: Dropout katmanı.Maske üretme yöntemi:
def generate_mask(self, src, tgt):Bu yöntem, kaynak ve hedef diziler için maskeler oluşturmakta kullanılır; böylece doldurma (padding) belirteçleri yoksayılır ve hedef dizi için eğitim sırasında gelecekteki belirteçlerin görünmesi engellenir.
Forward yöntemi:
def forward(self, src, tgt):Bu yöntem, Transformer'ın ileri geçişini tanımlar; kaynak ve hedef dizileri alıp çıktı tahminlerini üretir.
Çıktı:
Nihai çıktı, modelin hedef dizi için tahminlerini temsil eden bir tensördür.
Özet:
Transformer sınıfı, gömmeler, konumsal kodlama, encoder ve decoder katmanları dâhil bir Transformer modelinin çeşitli bileşenlerini bir araya getirir. Çok başlıklı dikkat, beslemeli ileri ağlar ve katman normalizasyonunun karmaşıklıklarını kapsülleyecek şekilde eğitim ve çıkarsama için uygun bir arayüz sunar.
Bu uygulama, standart Transformer mimarisini takip eder ve makine çevirisi, metin özetleme gibi sıralıdan sıralıya (sequence-to-sequence) görevlere uygundur. Maskelemenin dâhil edilmesi, modelin diziler içindeki nedensel bağımlılıklara uymasını, doldurma belirteçlerini yoksaymasını ve gelecekteki belirteçlerden bilgi sızıntısını önlemesini sağlar.
Bu sıralı adımlar, Transformer modelinin girdi dizilerini verimli şekilde işleyip karşılık gelen çıktı dizilerini üretmesini sağlar.
Gösterim amacıyla bu örnekte sahte (dummy) bir veri kümesi oluşturulacaktır. Ancak pratikte, daha kapsamlı bir veri kümesi kullanılır; süreç, hem kaynak hem de hedef diller için sözlük eşlemelerinin oluşturulmasının yanı sıra metin ön işlemeyi de içerir.
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_seq_length = 100
dropout = 0.1
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)
# Generate random sample data
src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)Hiperparametreler:
Bu değerler, transformer modelinin mimarisini ve davranışını tanımlar:
src_vocab_size, tgt_vocab_size: Kaynak ve hedef diziler için sözlük boyutları; her ikisi de 5000 olarak ayarlanmıştır.d_model: Model gömlemelerinin boyutu; 512 olarak ayarlanmıştır.num_heads: Çok başlıklı dikkat mekanizmasındaki başlık sayısı; 8 olarak ayarlanmıştır.num_layers: Hem encoder hem de decoder için katman sayısı; 6 olarak ayarlanmıştır.d_ff: Beslemeli ileri ağın iç katman boyutu; 2048 olarak ayarlanmıştır.max_seq_length: Konumsal kodlama için azami dizi uzunluğu; 100 olarak ayarlanmıştır.dropout: Düzenlileştirme için dropout oranı; 0.1 olarak ayarlanmıştır.Referans olması açısından, aşağıdaki tablo Transformer modelleri için en yaygın hiperparametreleri ve değerlerini açıklar:
| Hiperparametre | Tipik değerler | Performansa etkisi |
|---|---|---|
| d_model | 256, 512, 1024 | Daha yüksek değerler model kapasitesini artırır ancak daha fazla hesaplama gerektirir |
| num_heads | 8, 12, 16 | Daha fazla başlık verinin çeşitli yönlerini yakalayabilir ancak hesaplama açısından yoğundur |
| num_layers | 6, 12, 24 | Daha fazla katman temsil gücünü artırır ancak aşırı uyuma yol açabilir |
| d_ff | 2048, 4096 | Daha büyük beslemeli ileri ağlar modelin dayanıklılığını artırır |
| dropout | 0.1, 0.3 | Modeli düzenlileştirerek aşırı uyumu önler |
| learning rate | 0.0001 - 0.001 | Yakınsama hızını ve kararlılığı etkiler |
| batch size | 32, 64, 128 | Daha büyük yığın boyutları öğrenme kararlılığını artırır ancak daha fazla bellek gerektirir |
Bir Transformer örneği oluşturma:
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)Bu satır, belirtilen hiperparametrelerle Transformer sınıfından bir örnek oluşturur. Örnek, bu hiperparametrelerce tanımlanan mimari ve davranışa sahip olacaktır.
Rastgele örnek veri üretimi:
Aşağıdaki satırlar rastgele kaynak ve hedef dizileri üretir:
src_data: (64, max_seq_length) şekline sahip bir kaynak dizi yığını temsil eden, 1 ile src_vocab_size arasında rastgele tamsayılar.tgt_data: (64, max_seq_length) şekline sahip bir hedef dizi yığını temsil eden, 1 ile tgt_vocab_size arasında rastgele tamsayılar.Özet:
Kod parçası, bir Transformer modelinin nasıl başlatılacağını ve ona beslenebilecek rastgele kaynak ve hedef dizilerinin nasıl üretileceğini gösterir. Seçilen hiperparametreler, Transformer'ın özgül yapısını ve özelliklerini belirler. Bu kurulum, modelin makine çevirisi veya metin özetleme gibi gerçek sıralıdan sıralıya görevlerde eğitilip değerlendirildiği daha büyük bir betiğin parçası olabilir.
Sırada, yukarıda belirtilen örnek veriler kullanılarak modelin eğitilmesi vardır. Ancak, gerçek bir senaryoda genellikle eğitim ve doğrulama için ayrı kümelere bölünen çok daha büyük bir veri kümesi kullanılır.
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
transformer.train()
for epoch in range(100):
optimizer.zero_grad()
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:].contiguous().view(-1))
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")Kayıp fonksiyonu ve iyileştirici (optimizer):
criterion = nn.CrossEntropyLoss(ignore_index=0): Kayıp fonksiyonunu çapraz entropi olarak tanımlar. ignore_index argümanı 0 olarak ayarlanmıştır; bu, kaybın genellikle doldurma belirteçleri için ayrılan 0 indeksli hedefleri dikkate almayacağı anlamına gelir.optimizer = optim.Adam(...): İyileştiriciyi, 0.0001 öğrenme oranına ve belirli beta değerlerine sahip Adam olarak tanımlar.Modeli eğitim kipine alma:
transformer.train(): Transformer modelini eğitim kipine alır; bu, eğitim sırasında geçerli olan dropout gibi davranışları etkinleştirir.Eğitim döngüsü:
Kod parçası, modeli 100 dönem boyunca tipik bir eğitim döngüsüyle eğitir:
for epoch in range(100): 100 eğitim dönemi üzerinde yineleme yapar.optimizer.zero_grad(): Önceki yinelemeden kalan gradyanları temizler.output = transformer(src_data, tgt_data[:, :-1]): Kaynak veriyi ve hedef veriyi (her dizideki son belirteç hariç) transformer'dan geçirir. Bu, hedefin bir belirteç sola kaydırıldığı sıralıdan sıralıya görevlerde yaygındır.loss = criterion(...): Modelin tahminleri ile hedef veri (her dizideki ilk belirteç hariç) arasındaki kaybı hesaplar. Kayıp, veriler bir boyutlu tensörlere yeniden şekillendirilerek ve çapraz entropi kaybı kullanılarak hesaplanır.loss.backward(): Kaybın, model parametrelerine göre gradyanlarını hesaplar.optimizer.step(): Hesaplanan gradyanları kullanarak modelin parametrelerini günceller.print(f"Epoch: {epoch+1}, Loss: {loss.item()}"): O dönem için geçerli dönem numarasını ve kayıp değerini yazdırır.Özet:
Bu kod parçası, transformer modelini rastgele oluşturulmuş kaynak ve hedef diziler üzerinde 100 dönem eğitir. Adam iyileştiricisini ve çapraz entropi kayıp fonksiyonunu kullanır. Kayıp, her dönem için yazdırılır ve eğitim ilerlemesini izlemenizi sağlar. Gerçek bir senaryoda, rastgele kaynak ve hedef diziler, makine çevirisi gibi görevinizden gerçek verilerle değiştirilmelidir.
Model eğitildikten sonra, performansı bir doğrulama veya test veri kümesi üzerinde değerlendirilebilir. Aşağıda bunun nasıl yapılabileceğine dair bir örnek yer alıyor:
transformer.eval()
# Generate random sample validation data
val_src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
val_tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
with torch.no_grad():
val_output = transformer(val_src_data, val_tgt_data[:, :-1])
val_loss = criterion(val_output.contiguous().view(-1, tgt_vocab_size), val_tgt_data[:, 1:].contiguous().view(-1))
print(f"Validation Loss: {val_loss.item()}")Değerlendirme kipi:
transformer.eval(): Transformer modelini değerlendirme kipine alır. Bu, yalnızca eğitim sırasında kullanılan dropout gibi belirli davranışları kapattığı için önemlidir.Rastgele doğrulama verisi üretme:
val_src_data: (64, max_seq_length) şekline sahip bir doğrulama kaynak dizi yığını temsil eden, 1 ile src_vocab_size arasında rastgele tamsayılar.val_tgt_data: (64, max_seq_length) şekline sahip bir doğrulama hedef dizi yığını temsil eden, 1 ile tgt_vocab_size arasında rastgele tamsayılar.Doğrulama döngüsü:
with torch.no_grad(): Doğrulama sırasında gradyan hesaplamasına gerek olmadığı için gradyan hesaplamasını devre dışı bırakır. Bu, bellek kullanımını azaltabilir ve hesaplamaları hızlandırabilir.val_output = transformer(val_src_data, val_tgt_data[:, :-1]): Doğrulama kaynak verisini ve doğrulama hedef verisini (her dizideki son belirteç hariç) transformer'dan geçirir.val_loss = criterion(...): Modelin tahminleri ile doğrulama hedef verisi (her dizideki ilk belirteç hariç) arasındaki kaybı hesaplar. Kayıp, veriler bir boyutlu tensörlere yeniden şekillendirilerek ve daha önce tanımlanan çapraz entropi kaybı kullanılarak hesaplanır.print(f"Validation Loss: {val_loss.item()}"): Doğrulama kayıp değerini yazdırır.Özet:
Bu kod parçası, rastgele oluşturulmuş bir doğrulama veri kümesi üzerinde transformer modelini değerlendirir, doğrulama kaybını hesaplar ve yazdırır. Gerçek bir senaryoda, rastgele doğrulama verileri, üzerinde çalıştığınız görevden gerçek doğrulama verileriyle değiştirilmelidir. Doğrulama kaybı, modelinizin görülmemiş verilerde ne kadar iyi performans gösterdiğine dair bir fikir verebilir; bu da modelin genelleme yeteneğinin kritik bir ölçüsüdür.
Transformer'lar ve Hugging Face hakkında daha fazla ayrıntı için, An Introduction to Using Transformers and Hugging Face eğitimimiz yararlıdır.
Sonuç olarak, bu eğitim, derin öğrenme için en çok yönlü araçlardan biri olan PyTorch kullanılarak bir Transformer modelinin nasıl inşa edileceğini gösterdi. Paralelleştirme kapasiteleri ve verideki uzun vadeli bağımlılıkları yakalama becerileriyle Transformer'ların, özellikle çeviri, özetleme ve duygu analizi gibi NLP görevlerinde büyük bir potansiyeli vardır.
İleri düzey derin öğrenme kavram ve tekniklerini derinlemesine öğrenmek isteyenler için DataCamp'teki Advanced Deep Learning with Keras kursunu incelemeyi düşünebilirsiniz. Ayrıca ayrı bir eğitimde PyTorch ile basit bir sinir ağının sıfırdan nasıl kurulduğunu da okuyabilirsiniz.
Bu kurslarla PyTorch hakkında daha fazlasını öğrenin!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
