
Courses
Huấn luyện Mô hình AI Hiệu quả với PyTorch
4 giờ
1.6K
Lần đầu được giới thiệu trong bài báo Attention is All You Need của Vaswani và cộng sự, Transformers từ đó đã trở thành nền tảng cho nhiều tác vụ NLP nhờ thiết kế độc đáo và hiệu quả.
Cốt lõi của Transformers là cơ chế attention, cụ thể là khái niệm "tự chú ý" (self-attention), cho phép mô hình cân nhắc và ưu tiên các phần khác nhau của dữ liệu đầu vào. Cơ chế này giúp Transformers xử lý các phụ thuộc dài hạn trong dữ liệu. Về bản chất, đây là một sơ đồ gán trọng số giúp mô hình tập trung vào các phần khác nhau của đầu vào khi tạo ra đầu ra.
Cơ chế self-attention cho phép mô hình xem xét các từ hoặc đặc trưng khác nhau trong chuỗi đầu vào, gán cho mỗi phần một "trọng số" thể hiện mức độ quan trọng khi tạo ra đầu ra tương ứng. Chẳng hạn, trong tác vụ dịch câu, khi dịch một từ cụ thể, mô hình có thể gán trọng số attention cao hơn cho các từ có liên hệ ngữ pháp hoặc ngữ nghĩa với từ đích. Quá trình này cho phép Transformer nắm bắt các phụ thuộc giữa các từ hoặc đặc trưng, bất kể khoảng cách của chúng trong chuỗi.
Tác động của Transformers trong lĩnh vực NLP là không thể phủ nhận. Chúng đã vượt trội hơn các mô hình truyền thống ở nhiều tác vụ, thể hiện năng lực vượt bậc trong việc hiểu và tạo sinh ngôn ngữ tự nhiên theo cách tinh tế hơn.
Để hiểu sâu hơn về NLP, bạn có thể tham khảo khóa học Introduction to Natural Language Processing in Python của DataCamp.
Trước khi xây dựng Transformer, cần thiết lập đúng môi trường làm việc. Trước hết, bạn cần cài đặt PyTorch. PyTorch có thể được cài đặt thông qua trình quản lý gói pip hoặc conda.
Với pip, dùng lệnh:
pip3 install torch torchvision torchaudioVới conda, dùng lệnh:
conda install pytorch torchvision -c pytorchĐể biết thêm các tùy chọn cài đặt và chạy PyTorch, vui lòng tham khảo trang web chính thức.
Ngoài ra, việc nắm vững các khái niệm học sâu cơ bản cũng rất hữu ích, vì chúng là nền tảng để hiểu cách Transformer hoạt động. Nếu cần ôn tập, khóa học Deep Learning in Python của DataCamp là nguồn tài liệu giá trị bao quát các khái niệm chủ chốt trong học sâu.
Để xây dựng mô hình Transformer, cần thực hiện các bước sau:
Chúng ta sẽ bắt đầu bằng cách nhập thư viện PyTorch cho chức năng cốt lõi, mô-đun mạng nơ-ron để tạo mạng nơ-ron, mô-đun tối ưu hóa để huấn luyện mạng, và các hàm tiện ích dữ liệu để xử lý dữ liệu. Ngoài ra, chúng ta sẽ nhập mô-đun Python tiêu chuẩn math cho các phép toán và mô-đun copy để tạo bản sao của các đối tượng phức tạp.
Những công cụ này đặt nền móng cho việc định nghĩa kiến trúc mô hình, quản lý dữ liệu và thiết lập quy trình huấn luyện.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import math
import copyTrước khi xây dựng các thành phần, hãy xem bảng sau mô tả các thành phần khác nhau của Transformer và mục đích của chúng:
| Thành phần | Mô tả | Mục đích |
|---|---|---|
| Multi-Head Attention | Cơ chế tập trung vào các phần khác nhau của đầu vào | Nắm bắt các phụ thuộc trên các vị trí khác nhau trong chuỗi |
| Feed-Forward Networks | Các lớp kết nối đầy đủ theo từng vị trí | Biến đổi đầu ra attention, tăng độ phức tạp |
| Positional Encoding | Thêm thông tin vị trí vào embedding | Cung cấp ngữ cảnh về thứ tự chuỗi cho mô hình |
| Layer Normalization | Chuẩn hóa đầu vào cho mỗi tầng con | Ổn định huấn luyện, cải thiện hội tụ |
| Residual Connections | Đường tắt giữa các lớp | Hỗ trợ huấn luyện mạng sâu bằng cách giảm vấn đề gradient |
| Dropout | Ngẫu nhiên đưa một số kết nối về 0 | Ngăn quá khớp bằng cách regularize mô hình |
Cơ chế multi-head attention tính toán attention giữa từng cặp vị trí trong một chuỗi. Nó gồm nhiều "đầu attention" để nắm bắt các khía cạnh khác nhau của chuỗi đầu vào.
Để tìm hiểu thêm về multi-head attention, hãy xem phần attention mechanisms trong khóa học Khái niệm Mô hình Ngôn ngữ Lớn (LLMs).
Hình 1. Multi-Head Attention (nguồn: ảnh do tác giả tạo)
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
# Ensure that the model dimension (d_model) is divisible by the number of heads
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
# Initialize dimensions
self.d_model = d_model # Model's dimension
self.num_heads = num_heads # Number of attention heads
self.d_k = d_model // num_heads # Dimension of each head's key, query, and value
# Linear layers for transforming inputs
self.W_q = nn.Linear(d_model, d_model) # Query transformation
self.W_k = nn.Linear(d_model, d_model) # Key transformation
self.W_v = nn.Linear(d_model, d_model) # Value transformation
self.W_o = nn.Linear(d_model, d_model) # Output transformation
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# Calculate attention scores
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# Apply mask if provided (useful for preventing attention to certain parts like padding)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# Softmax is applied to obtain attention probabilities
attn_probs = torch.softmax(attn_scores, dim=-1)
# Multiply by values to obtain the final output
output = torch.matmul(attn_probs, V)
return output
def split_heads(self, x):
# Reshape the input to have num_heads for multi-head attention
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
def combine_heads(self, x):
# Combine the multiple heads back to original shape
batch_size, _, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
def forward(self, Q, K, V, mask=None):
# Apply linear transformations and split heads
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# Perform scaled dot-product attention
attn_output = self.scaled_dot_product_attention(Q, K, V, mask)
# Combine heads and apply output transformation
output = self.W_o(self.combine_heads(attn_output))
return outputĐịnh nghĩa lớp và khởi tạo:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):Lớp được định nghĩa như một lớp con của nn.Module trong PyTorch.
d_model: Số chiều của đầu vào.num_heads: Số lượng đầu attention để chia nhỏ đầu vào.Phần khởi tạo kiểm tra d_model có chia hết cho num_heads hay không, rồi định nghĩa các trọng số biến đổi cho query, key, value và output.
Attention tích chập theo tích vô hướng có tỉ lệ:
def scaled_dot_product_attention(self, Q, K, V, mask=None):attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k). Điểm attention được tính bằng tích vô hướng giữa Q và K, sau đó chia theo căn bậc hai của kích thước khóa d_k.V.Tách các đầu:
def split_heads(self, x):Phương thức này reshape đầu vào x thành dạng (batch_size, num_heads, seq_length, d_k). Điều này cho phép mô hình xử lý đồng thời nhiều đầu attention, tận dụng tính song song.
Kết hợp các đầu:
def combine_heads(self, x):Sau khi áp dụng attention cho từng đầu riêng rẽ, phương thức này kết hợp kết quả về một tensor duy nhất có dạng (batch_size, seq_length, d_model), chuẩn bị cho các bước xử lý tiếp theo.
Phương thức forward:
def forward(self, Q, K, V, mask=None):Phương thức forward là nơi thực hiện tính toán:
Q, K, V được đưa qua các biến đổi tuyến tính bằng các trọng số đã định nghĩa.Q, K, V đã biến đổi được chia thành nhiều đầu bằng phương thức split_heads.scaled_dot_product_attention trên các đầu đã tách.combine_heads.Tóm lại, lớp MultiHeadAttention đóng gói cơ chế multi-head attention thường dùng trong các mô hình transformer. Nó xử lý việc chia nhỏ đầu vào thành nhiều đầu attention, áp dụng attention cho từng đầu, rồi kết hợp kết quả. Nhờ vậy, mô hình có thể nắm bắt nhiều mối quan hệ trong dữ liệu ở các thang đo khác nhau, cải thiện khả năng biểu đạt.
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))Định nghĩa lớp:
class PositionWiseFeedForward(nn.Module):Lớp là một lớp con của nn.Module trong PyTorch, nghĩa là nó thừa hưởng đầy đủ chức năng để làm việc với các lớp mạng nơ-ron.
Khởi tạo:
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()d_model: Số chiều của đầu vào và đầu ra của mô hình.d_ff: Số chiều của lớp ẩn trong mạng feed-forward.self.fc1 và self.fc2: Hai lớp tuyến tính với kích thước đầu vào/đầu ra theo d_model và d_ff.self.relu: Hàm kích hoạt ReLU, đưa phi tuyến vào giữa hai lớp tuyến tính.Phương thức forward:
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))x: Đầu vào của mạng feed-forward.self.fc1(x): Đầu vào đi qua lớp tuyến tính thứ nhất (fc1).self.relu(...): Đầu ra của fc1 qua ReLU, thay thế các giá trị âm bằng 0, đưa phi tuyến vào mô hình.self.fc2(...): Đầu ra đã kích hoạt đi qua lớp tuyến tính thứ hai (fc2), tạo đầu ra cuối.Tóm lại, lớp PositionWiseFeedForward định nghĩa một mạng feed-forward theo vị trí gồm hai lớp tuyến tính với ReLU ở giữa. Trong transformer, mạng này được áp dụng riêng rẽ và giống hệt nhau ở mỗi vị trí, giúp biến đổi các đặc trưng mà cơ chế attention đã học, đóng vai trò như một bước xử lý bổ sung cho đầu ra attention.
Positional Encoding được dùng để đưa thông tin vị trí của từng token trong chuỗi đầu vào. Nó sử dụng các hàm sin và cos với tần số khác nhau để tạo mã hóa vị trí.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1)]Định nghĩa lớp:
class PositionalEncoding(nn.Module):Lớp được định nghĩa như một lớp con của nn.Module trong PyTorch, cho phép dùng như một lớp tiêu chuẩn.
Khởi tạo:
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))d_model: Số chiều của đầu vào mô hình.max_seq_length: Độ dài chuỗi tối đa để tính trước mã hóa vị trí.pe: Một tensor chứa các số 0, sẽ được điền mã hóa vị trí.position: Tensor chứa chỉ số vị trí cho từng vị trí trong chuỗi.div_term: Thừa số dùng để co giãn chỉ số vị trí theo cách nhất định.pe.pe được đăng ký làm buffer, nghĩa là thuộc trạng thái mô-đun nhưng không phải tham số có thể huấn luyện.Phương thức forward:
def forward(self, x):
return x + self.pe[:, :x.size(1)]Phương thức forward chỉ việc cộng mã hóa vị trí vào đầu vào x.
Nó dùng x.size(1) phần tử đầu tiên của pe để đảm bảo độ dài mã hóa vị trí khớp với độ dài chuỗi thực tế của x.
Tóm tắt
Lớp PositionalEncoding thêm thông tin về vị trí của token trong chuỗi. Vì mô hình transformer không có kiến thức vốn có về thứ tự token (do cơ chế self-attention), lớp này giúp mô hình xem xét vị trí của token. Các hàm hình sin/cos được chọn để mô hình dễ học các vị trí tương đối, vì chúng tạo mã hóa mượt và duy nhất cho mỗi vị trí trong chuỗi.
Hình 2. Phần Encoder của mạng transformer (Nguồn: hình ảnh từ bài báo gốc)
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xĐịnh nghĩa lớp:
class EncoderLayer(nn.Module):Lớp được định nghĩa như một lớp con của nn.Module trong PyTorch, nghĩa là có thể dùng làm khối xây dựng của mạng nơ-ron.
Khởi tạo:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Tham số:
d_model: Số chiều của đầu vào.num_heads: Số đầu attention trong multi-head attention.d_ff: Số chiều của lớp ẩn trong mạng feed-forward theo vị trí.dropout: Tỷ lệ dropout để regularize.Thành phần:
self.self_attn: Cơ chế multi-head self-attention.self.feed_forward: Mạng nơ-ron feed-forward theo vị trí.self.norm1 và self.norm2: Chuẩn hóa theo lớp, làm mượt đầu vào mỗi tầng.self.dropout: Lớp dropout, ngăn quá khớp bằng cách ngẫu nhiên đưa một số kích hoạt về 0 khi huấn luyện.Phương thức forward:
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return xĐầu vào:
x: Đầu vào của lớp encoder.mask: Mặt nạ tùy chọn để bỏ qua một số phần của đầu vào.Các bước xử lý:
x đi qua cơ chế multi-head self-attention.norm1.norm2.Tóm tắt:
Lớp EncoderLayer định nghĩa một tầng của encoder trong transformer. Nó bao gồm cơ chế multi-head self-attention tiếp theo là mạng feed-forward theo vị trí, kèm các kết nối tàn dư, chuẩn hóa lớp và dropout. Thông thường, nhiều tầng encoder như vậy được xếp chồng để tạo phần encoder hoàn chỉnh của mô hình transformer.
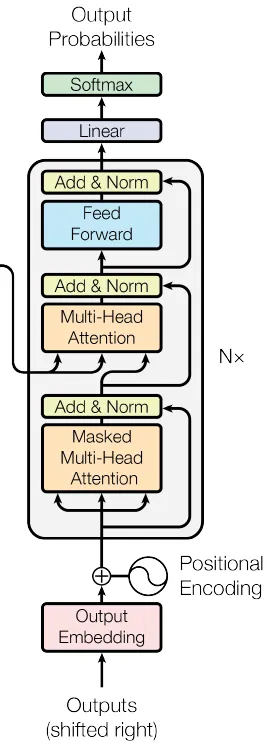
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xĐịnh nghĩa lớp:
class DecoderLayer(nn.Module):Khởi tạo:
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)Tham số:
d_model: Số chiều của đầu vào.num_heads: Số đầu attention trong cơ chế multi-head.d_ff: Số chiều của lớp ẩn trong mạng feed-forward.dropout: Tỷ lệ dropout để regularize.Thành phần:
self.self_attn: Cơ chế multi-head self-attention cho chuỗi đích.self.cross_attn: Cơ chế multi-head attention chú ý đến đầu ra của encoder.self.feed_forward: Mạng nơ-ron feed-forward theo vị trí.self.norm1, self.norm2, self.norm3: Các thành phần chuẩn hóa lớp.self.dropout: Lớp dropout để regularize.Phương thức forward:
ef forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xĐầu vào:
x: Đầu vào của lớp decoder.enc_output: Đầu ra từ encoder tương ứng (dùng trong bước cross-attention).src_mask: Mặt nạ nguồn để bỏ qua một số phần của đầu ra encoder.tgt_mask: Mặt nạ đích để bỏ qua một số phần của đầu vào decoder.Các bước xử lý:
enc_output của encoder.Tóm tắt:
Lớp DecoderLayer định nghĩa một tầng của decoder trong transformer. Nó gồm cơ chế multi-head self-attention, cơ chế multi-head cross-attention (chú ý đến đầu ra encoder), mạng feed-forward theo vị trí và các kết nối tàn dư, chuẩn hóa lớp, dropout tương ứng. Thông thường, nhiều tầng decoder như vậy được xếp chồng để tạo phần decoder hoàn chỉnh.
Tiếp theo, các khối Encoder và Decoder được kết hợp để xây dựng mô hình Transformer tổng thể.
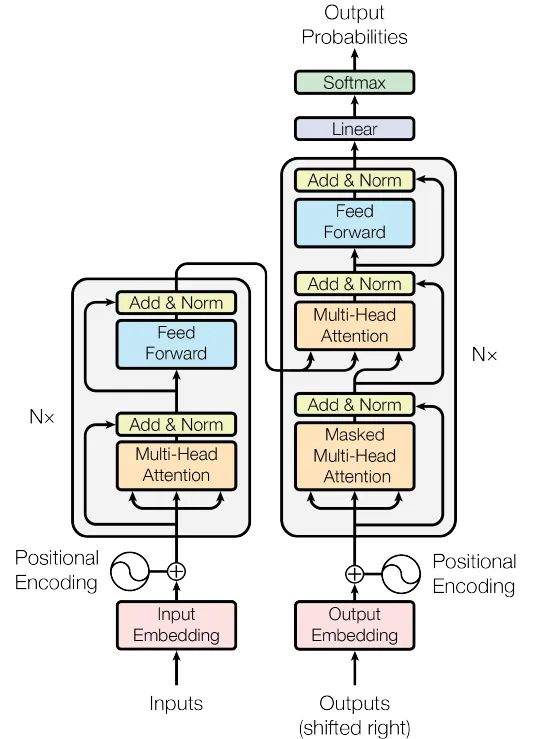
Hình 4. Mạng Transformer (Nguồn: Hình ảnh từ bài báo gốc)
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):
super(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_length)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.fc = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def generate_mask(self, src, tgt):
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.size(1)
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask
return src_mask, tgt_mask
def forward(self, src, tgt):
src_mask, tgt_mask = self.generate_mask(src, tgt)
src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))
tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
output = self.fc(dec_output)
return outputĐịnh nghĩa lớp:
class Transformer(nn.Module):Khởi tạo:
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):Hàm khởi tạo nhận các tham số sau:
src_vocab_size: Kích thước từ vựng nguồn.tgt_vocab_size: Kích thước từ vựng đích.d_model: Số chiều embedding của mô hình.num_heads: Số đầu attention trong cơ chế multi-head.num_layers: Số lớp cho cả encoder và decoder.d_ff: Số chiều của lớp ẩn trong mạng feed-forward.max_seq_length: Độ dài chuỗi tối đa cho mã hóa vị trí.dropout: Tỷ lệ dropout để regularize.Và định nghĩa các thành phần sau:
self.encoder_embedding: Lớp embedding cho chuỗi nguồn.self.decoder_embedding: Lớp embedding cho chuỗi đích.self.positional_encoding: Thành phần mã hóa vị trí.self.encoder_layers: Danh sách các lớp encoder.self.decoder_layers: Danh sách các lớp decoder.self.fc: Lớp tuyến tính cuối cùng ánh xạ sang kích thước từ vựng đích.self.dropout: Lớp dropout.Phương thức tạo mask:
def generate_mask(self, src, tgt):Phương thức này tạo mặt nạ cho chuỗi nguồn và đích, đảm bảo bỏ qua các token đệm và không cho phép nhìn thấy token tương lai khi huấn luyện chuỗi đích.
Phương thức forward:
def forward(self, src, tgt):Phương thức này định nghĩa lan truyền tiến cho Transformer, nhận chuỗi nguồn và đích và tạo ra dự đoán đầu ra.
Đầu ra:
Đầu ra cuối cùng là một tensor biểu diễn dự đoán của mô hình cho chuỗi đích.
Tóm tắt:
Lớp Transformer tập hợp các thành phần của mô hình Transformer, gồm embedding, mã hóa vị trí, các lớp encoder và decoder. Nó cung cấp giao diện thuận tiện cho huấn luyện và suy luận, bao quát các phức tạp của multi-head attention, mạng feed-forward và chuẩn hóa lớp.
Cài đặt này tuân theo kiến trúc Transformer chuẩn, phù hợp cho các tác vụ chuỗi-đến-chuỗi như dịch máy, tóm tắt văn bản, v.v. Việc đưa mask đảm bảo mô hình tuân thủ phụ thuộc nhân quả trong chuỗi, bỏ qua token đệm và ngăn rò rỉ thông tin từ các token tương lai.
Chuỗi bước này giúp mô hình Transformer xử lý hiệu quả các chuỗi đầu vào và sinh ra các chuỗi đầu ra tương ứng.
Để minh họa, ví dụ này sẽ tạo một bộ dữ liệu giả. Tuy nhiên, trong thực tế, bạn sẽ dùng một bộ dữ liệu lớn hơn nhiều, kèm theo tiền xử lý văn bản và tạo ánh xạ từ vựng cho cả ngôn ngữ nguồn và đích.
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_seq_length = 100
dropout = 0.1
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)
# Generate random sample data
src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)Siêu tham số:
Các giá trị này xác định kiến trúc và hành vi của mô hình transformer:
src_vocab_size, tgt_vocab_size: Kích thước từ vựng cho chuỗi nguồn và đích, đều là 5000.d_model: Số chiều embedding của mô hình, đặt là 512.num_heads: Số đầu attention trong multi-head attention, đặt là 8.num_layers: Số lớp cho cả encoder và decoder, đặt là 6.d_ff: Số chiều của lớp ẩn trong mạng feed-forward, đặt là 2048.max_seq_length: Độ dài chuỗi tối đa cho mã hóa vị trí, đặt là 100.dropout: Tỷ lệ dropout để regularize, đặt là 0.1.Tham khảo, bảng sau mô tả các siêu tham số thường gặp của mô hình Transformer và giá trị của chúng:
| Siêu tham số | Giá trị điển hình | Tác động đến hiệu năng |
|---|---|---|
| d_model | 256, 512, 1024 | Giá trị cao hơn tăng năng lực mô hình nhưng tốn nhiều tính toán hơn |
| num_heads | 8, 12, 16 | Nhiều đầu hơn giúp nắm bắt đa dạng khía cạnh dữ liệu nhưng tốn tài nguyên |
| num_layers | 6, 12, 24 | Nhiều lớp tăng khả năng biểu diễn nhưng có thể gây quá khớp |
| d_ff | 2048, 4096 | Mạng feed-forward lớn hơn tăng độ vững của mô hình |
| dropout | 0.1, 0.3 | Regularize mô hình để tránh quá khớp |
| learning rate | 0.0001 - 0.001 | Ảnh hưởng tốc độ và độ ổn định hội tụ |
| batch size | 32, 64, 128 | Kích thước batch lớn cải thiện ổn định học nhưng cần nhiều bộ nhớ |
Tạo một thể hiện Transformer:
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)Dòng này tạo một thể hiện của lớp Transformer, khởi tạo với các siêu tham số đã cho. Thể hiện sẽ có kiến trúc và hành vi được xác định bởi các siêu tham số này.
Tạo dữ liệu mẫu ngẫu nhiên:
Các dòng sau tạo chuỗi nguồn và đích ngẫu nhiên:
src_data: Số nguyên ngẫu nhiên từ 1 đến src_vocab_size, đại diện một batch chuỗi nguồn dạng (64, max_seq_length).tgt_data: Số nguyên ngẫu nhiên từ 1 đến tgt_vocab_size, đại diện một batch chuỗi đích dạng (64, max_seq_length).Tóm tắt:
Đoạn mã minh họa cách khởi tạo mô hình Transformer và tạo chuỗi nguồn, đích ngẫu nhiên để đưa vào. Các siêu tham số được chọn quyết định cấu trúc và đặc tính cụ thể của Transformer. Thiết lập này có thể là một phần trong kịch bản lớn hơn, nơi mô hình được huấn luyện và đánh giá trên các tác vụ chuỗi-đến-chuỗi thực tế như dịch máy hoặc tóm tắt văn bản.
Tiếp theo, mô hình sẽ được huấn luyện bằng dữ liệu mẫu nói trên. Tuy nhiên, trong thực tế, bạn sẽ dùng bộ dữ liệu lớn hơn nhiều, thường được chia thành tập huấn luyện và tập xác thực riêng biệt.
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
transformer.train()
for epoch in range(100):
optimizer.zero_grad()
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:].contiguous().view(-1))
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")Hàm mất mát và bộ tối ưu:
criterion = nn.CrossEntropyLoss(ignore_index=0): Định nghĩa hàm mất mát là cross-entropy. Tham số ignore_index đặt là 0, nghĩa là bỏ qua các mục tiêu có chỉ số 0 (thường dành cho token đệm).optimizer = optim.Adam(...): Định nghĩa bộ tối ưu Adam với learning rate 0.0001 và các giá trị beta cụ thể.Chế độ huấn luyện mô hình:
transformer.train(): Đặt mô hình vào chế độ huấn luyện, bật các hành vi như dropout chỉ áp dụng khi huấn luyện.Vòng lặp huấn luyện:
Đoạn mã huấn luyện mô hình trong 100 epoch theo vòng lặp điển hình:
for epoch in range(100): Lặp qua 100 epoch.optimizer.zero_grad(): Xóa gradient từ vòng lặp trước.output = transformer(src_data, tgt_data[:, :-1]): Đưa dữ liệu nguồn và dữ liệu đích (bỏ token cuối mỗi chuỗi) qua transformer. Đây là cách làm phổ biến trong các tác vụ chuỗi-đến-chuỗi khi mục tiêu được dịch chuyển một vị trí.loss = criterion(...): Tính mất mát giữa dự đoán của mô hình và dữ liệu đích (bỏ token đầu mỗi chuỗi). Mất mát tính bằng cách reshape dữ liệu thành tensor một chiều và dùng hàm cross-entropy.loss.backward(): Tính gradient của mất mát theo các tham số mô hình.optimizer.step(): Cập nhật tham số mô hình dùng gradient đã tính.print(f"Epoch: {epoch+1}, Loss: {loss.item()}"): In số epoch hiện tại và giá trị mất mát.Tóm tắt:
Đoạn mã huấn luyện mô hình transformer trên các chuỗi nguồn và đích được tạo ngẫu nhiên trong 100 epoch. Nó dùng bộ tối ưu Adam và hàm mất mát cross-entropy. Mất mát được in ra mỗi epoch để theo dõi tiến trình huấn luyện. Trong thực tế, bạn sẽ thay thế các chuỗi ngẫu nhiên bằng dữ liệu thật từ tác vụ của bạn, như dịch máy.
Sau khi huấn luyện mô hình, bạn có thể đánh giá hiệu năng trên tập xác thực hoặc tập kiểm tra. Ví dụ sau minh họa cách thực hiện:
transformer.eval()
# Generate random sample validation data
val_src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
val_tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
with torch.no_grad():
val_output = transformer(val_src_data, val_tgt_data[:, :-1])
val_loss = criterion(val_output.contiguous().view(-1, tgt_vocab_size), val_tgt_data[:, 1:].contiguous().view(-1))
print(f"Validation Loss: {val_loss.item()}")Chế độ đánh giá:
transformer.eval(): Đặt mô hình vào chế độ đánh giá. Điều này tắt các hành vi như dropout vốn chỉ dùng khi huấn luyện.Tạo dữ liệu xác thực ngẫu nhiên:
val_src_data: Số nguyên ngẫu nhiên từ 1 đến src_vocab_size, đại diện một batch chuỗi nguồn xác thực dạng (64, max_seq_length).val_tgt_data: Số nguyên ngẫu nhiên từ 1 đến tgt_vocab_size, đại diện một batch chuỗi đích xác thực dạng (64, max_seq_length).Vòng lặp xác thực:
with torch.no_grad(): Tắt tính gradient vì không cần cập nhật trọng số khi xác thực. Điều này giảm dùng bộ nhớ và tăng tốc tính toán.val_output = transformer(val_src_data, val_tgt_data[:, :-1]): Đưa dữ liệu xác thực nguồn và đích (bỏ token cuối) qua transformer.val_loss = criterion(...): Tính mất mát giữa dự đoán của mô hình và dữ liệu đích xác thực (bỏ token đầu). Mất mát tính bằng cross-entropy như trước.print(f"Validation Loss: {val_loss.item()}"): In giá trị mất mát xác thực.Tóm tắt:
Đoạn mã này đánh giá mô hình transformer trên một tập xác thực được tạo ngẫu nhiên, tính mất mát xác thực và in ra. Trong thực tế, hãy thay dữ liệu ngẫu nhiên bằng dữ liệu xác thực thật của tác vụ. Mất mát xác thực cho biết mô hình hoạt động trên dữ liệu chưa thấy tốt đến đâu, là thước đo quan trọng về khả năng tổng quát hóa.
Để tìm hiểu thêm về Transformers và Hugging Face, hãy tham khảo hướng dẫn An Introduction to Using Transformers and Hugging Face của chúng tôi.
Tóm lại, hướng dẫn này đã trình bày cách xây dựng mô hình Transformer bằng PyTorch, một trong những công cụ linh hoạt nhất cho học sâu. Với khả năng song song hóa và nắm bắt phụ thuộc dài hạn trong dữ liệu, Transformers có tiềm năng to lớn ở nhiều lĩnh vực, đặc biệt là các tác vụ NLP như dịch thuật, tóm tắt và phân tích cảm xúc.
Nếu bạn muốn đào sâu các khái niệm và kỹ thuật học sâu nâng cao, hãy khám phá khóa học Advanced Deep Learning with Keras trên DataCamp. Bạn cũng có thể đọc hướng dẫn xây dựng mạng nơ-ron đơn giản với PyTorch trong một bài viết riêng.
Tìm hiểu thêm về PyTorch với các khóa học này!
Courses
Courses
Courses