
Program
Kepemimpinan Kecerdasan Buatan (AI)
6 Hr
Explainable AI mengacu pada serangkaian proses dan metode yang bertujuan memberikan penjelasan yang jelas dan dapat dipahami manusia untuk keputusan yang dihasilkan oleh model AI dan pembelajaran mesin.
Dengan mengintegrasikan lapisan keterjelasan ke dalam model-model ini, Data Scientist dan praktisi Machine Learning dapat menciptakan sistem yang lebih tepercaya dan transparan untuk membantu berbagai pemangku kepentingan seperti pengembang, regulator, dan pengguna akhir.
Berikut beberapa prinsip Explainable AI yang dapat berkontribusi pada pembangunan kepercayaan:
Ada beberapa manfaat dalam menerapkan Explainable AI. Bagi pengambil keputusan dan pemangku kepentingan lainnya, XAI menawarkan pemahaman yang jelas tentang alasan di balik keputusan berbasis AI, sehingga memungkinkan mereka membuat pilihan yang lebih tepat. XAI juga membantu mengidentifikasi kemungkinan bias atau kesalahan pada model, yang mengarah pada hasil yang lebih akurat dan adil.
Ada dua kategori besar keterjelasan model: metode khusus model dan metode agnostik model. Pada bagian ini, kita akan memahami perbedaan keduanya, dengan fokus khusus pada metode agnostik model.
Kedua teknik tersebut dapat memberikan wawasan berharga tentang cara kerja internal model pembelajaran mesin sambil memastikan model efektif dan akuntabel.
Untuk mengilustrasikan alat-alat ini, kita akan menggunakan dataset diabetes dari Kaggle. Pertama, kita akan membangun sebuah classifier sederhana dan kemudian menerapkan keterjelasan. Kode sumber lengkap tersedia di buku kerja DataLab ini.
Sebuah classifier Random Forest dibangun untuk memprediksi hasil diabetes menggunakan dataset diabetes. Kodenya dipecah menjadi beberapa langkah: (1) mengimpor pustaka yang relevan, (2) membuat dataset pelatihan dan pengujian, (3) membangun model, dan (4) melaporkan metrik kinerja melalui classification report.
# Load useful libraries
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
# Separate Features and Target Variables
X = diabetes_data.drop(columns='Outcome')
y = diabetes_data['Outcome']
# Create Train & Test Data
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,
stratify =y,
random_state = 13)
# Build the model
rf_clf = RandomForestClassifier(max_features=2, n_estimators =100 ,bootstrap = True)
rf_clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = rf_clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Pernyataan print terakhir menghasilkan laporan berikut:
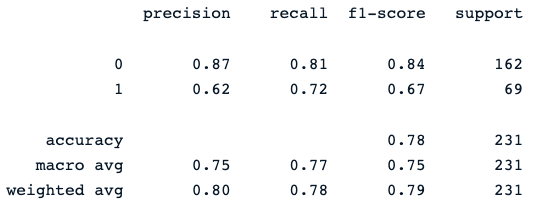
Classifier random forest memberikan kinerja yang cukup baik dalam memprediksi hasil diabetes, dengan ruang yang jelas untuk perbaikan menggunakan model yang berbeda.
Sekarang, kita dapat mengintegrasikan lapisan keterjelasan ke dalam model ini untuk memberikan lebih banyak wawasan tentang prediksinya. Bagian berikut akan berfokus pada dua kategori besar keterjelasan model: metode khusus model dan metode agnostik model.
Artikel kami Klasifikasi dalam Machine Learning: Sebuah Pengantar membantu Anda mempelajari tentang klasifikasi dalam pembelajaran mesin, mencakup apa itu, bagaimana digunakan, dan beberapa contoh algoritma klasifikasi.
Metode ini dapat diterapkan pada model pembelajaran mesin apa pun, terlepas dari struktur atau tipenya. Mereka berfokus pada analisis pasangan masukan-keluaran fitur. Bagian ini akan memperkenalkan dan membahas LIME dan SHAP, dua model surrogate yang banyak digunakan.
Singkatan dari SHapley Additive exPlanations. Metode ini bertujuan menjelaskan prediksi suatu instance/observasi dengan menghitung kontribusi setiap fitur terhadap prediksi, dan dapat diinstal menggunakan perintah pip berikut.
!pip install shapSetelah instalasi:
import shap
import matplotlib.pyplot as plt
# load JS visualization code to notebook
shap.initjs()
# Create the explainer
explainer = shap.TreeExplainer(rf_clf)
shap_values = explainer.shap_values(X_test)SHAP menawarkan beragam alat visualisasi untuk meningkatkan interpretabilitas model, dan bagian berikut akan membahas dua di antaranya: (1) pentingnya variabel dengan summary plot, (2) summary plot untuk target tertentu, dan (3) dependence plot.
Dalam plot ini, fitur diberi peringkat berdasarkan nilai SHAP rata-rata, menampilkan fitur paling penting di bagian atas dan yang paling tidak penting di bagian bawah menggunakan fungsi summary_plot(). Ini membantu memahami dampak setiap fitur pada prediksi model.
print("Variable Importance Plot - Global Interpretation")
figure = plt.figure()
shap.summary_plot(shap_values, X_test)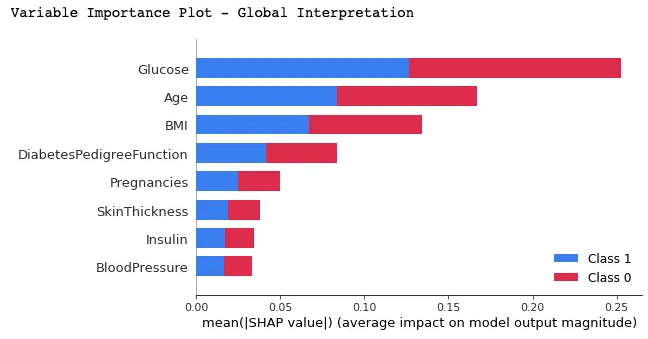
Berikut interpretasi yang dapat dibuat dari grafik di atas:
Pendekatan ini dapat memberikan gambaran yang lebih rinci tentang dampak setiap fitur pada hasil tertentu (label).
Pada contoh di bawah, shap_values[1] digunakan untuk merepresentasikan nilai SHAP untuk instance yang diklasifikasikan sebagai label 1 (mengidap diabetes).
shap.summary_plot(shap_values[1], X_test)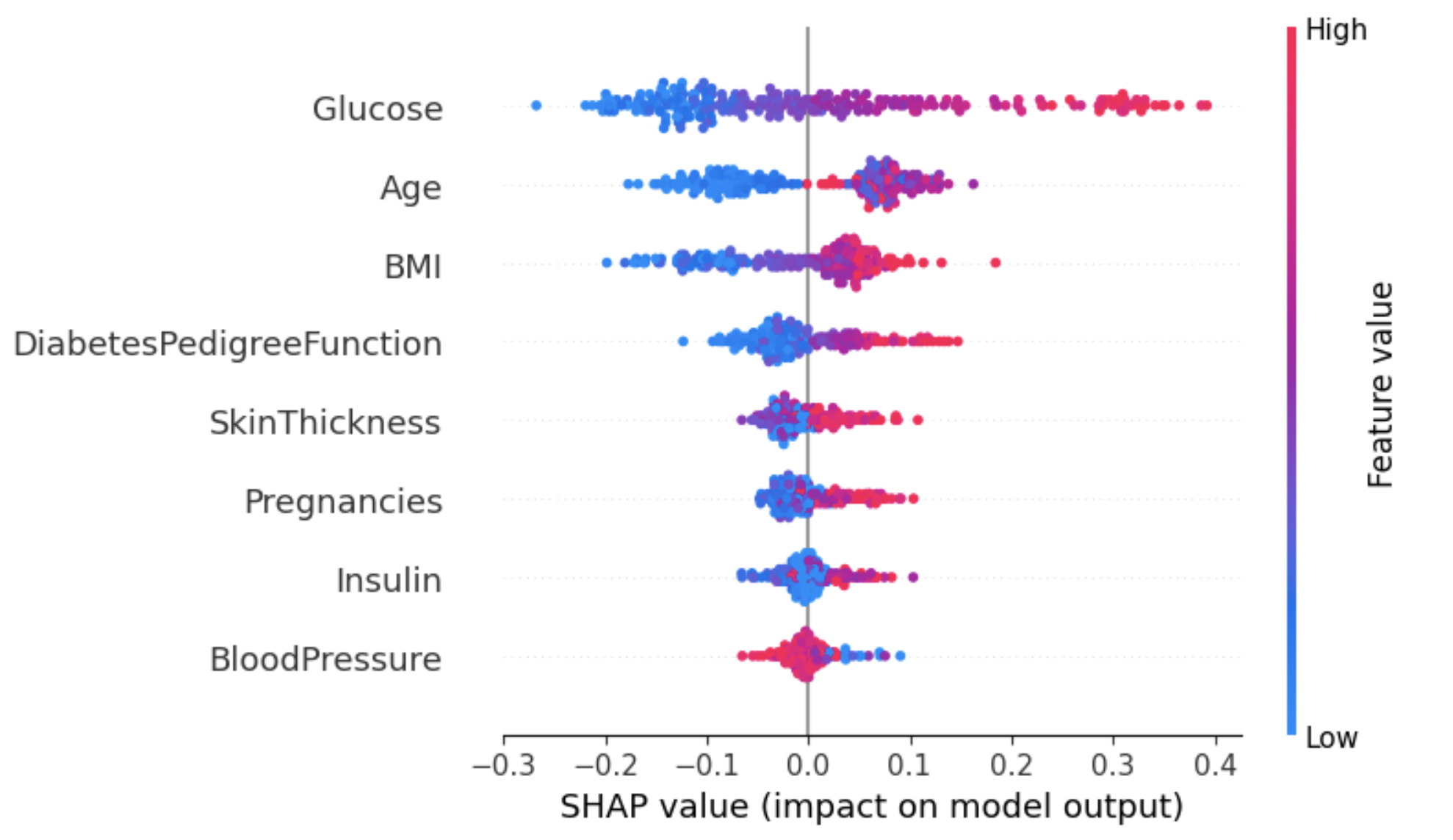
Dari grafik di atas:
Salah satu cara menangani ambiguitas untuk atribut Age adalah menggunakan dependence plot untuk mendapatkan wawasan lebih lanjut.
Berbeda dengan summary plot, dependence plot menunjukkan hubungan antara fitur tertentu dan hasil prediksi untuk setiap instance dalam data. Analisis ini dilakukan untuk berbagai alasan, antara lain untuk memperoleh informasi yang lebih rinci serta memvalidasi pentingnya fitur yang dianalisis dengan mengonfirmasi atau menantang temuan dari summary plot atau ukuran pentingnya fitur global lainnya.
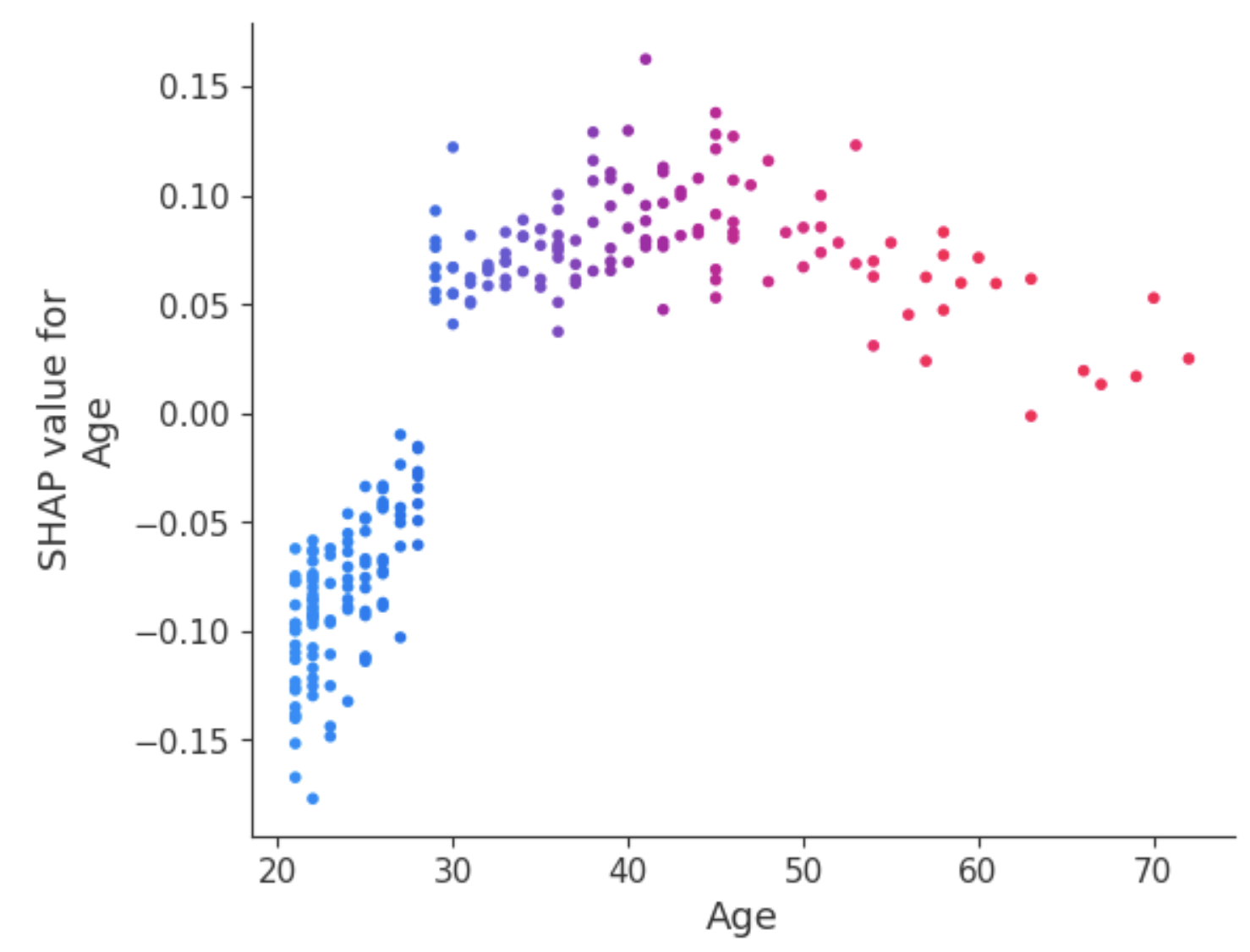
Dependence plot mengungkapkan bahwa pasien di bawah 30 tahun memiliki risiko lebih rendah untuk didiagnosis mengidap diabetes. Sebaliknya, individu di atas 30 tahun menghadapi kemungkinan lebih tinggi untuk menerima diagnosis diabetes.
Local Interpretable Model-agnostic Explanations (disingkat LIME). Alih-alih memberikan pemahaman global tentang model pada seluruh dataset, LIME berfokus pada penjelasan prediksi model untuk instance individual.
LIME explainer dapat disiapkan dalam dua langkah utama: (1) mengimpor modul lime, dan (2) melakukan fit explainer menggunakan data pelatihan dan target. Pada tahap ini, mode disetel ke classification, yang sesuai dengan tugas yang dilakukan.
# Import the LimeTabularExplainer module
from lime.lime_tabular import LimeTabularExplainer
# Get the class names
class_names = ['Has diabetes', 'No diabetes']
# Get the feature names
feature_names = list(X_train.columns)
# Fit the Explainer on the training data set using the LimeTabularExplainer
explainer = LimeTabularExplainer(X_train.values, feature_names =
feature_names,
class_names = class_names,
mode = 'classification')Cuplikan kode di bawah ini menghasilkan dan menampilkan penjelasan LIME untuk instance ke-8 dalam data uji menggunakan classifier random forest dan menyajikan kontribusi fitur akhir dalam format tabel.
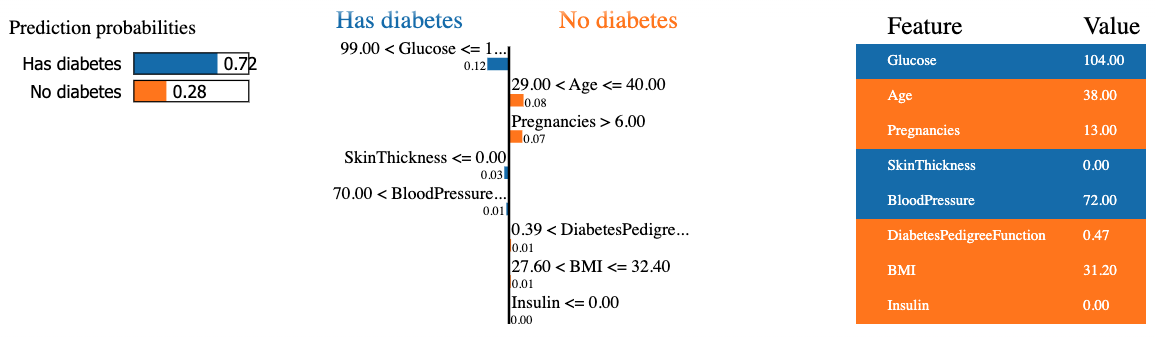
Hasilnya memuat tiga informasi utama dari kiri ke kanan: (1) prediksi model, (2) kontribusi fitur, dan (3) nilai aktual untuk setiap fitur.
Kita dapat mengamati bahwa pasien kedelapan diprediksi mengidap diabetes dengan keyakinan 72%. Alasan yang membuat model mengambil keputusan ini adalah karena:
Nilai-nilai tersebut dapat diverifikasi dari tabel di sebelah kanan.
Berbeda dengan metode agnostik model, metode ini hanya dapat diterapkan pada kategori model tertentu. Beberapa di antaranya mencakup regresi linear, pohon keputusan, dan interpretabilitas jaringan saraf. Berbagai teknik seperti DeepLIFT, Grad-CAM, atau Integrated Gradients dapat dimanfaatkan untuk menjelaskan model deep learning.
Saat menggunakan model pohon keputusan, pohon grafis dapat dihasilkan dengan fungsi plot_tree dari scikit-learn untuk menjelaskan proses pengambilan keputusan model dari atas ke bawah, dan ilustrasinya diberikan di bawah.
Artikel Deep Learning - Tutorial untuk Data Scientist kami akan menjawab pertanyaan paling sering tentang deep learning dan mengeksplorasi berbagai aspek deep learning dengan contoh dunia nyata.
Mari melatih classifier pohon keputusan dengan hiperparameter spesifik seperti max_depth dan min_samples_leaf sebelum menghasilkan pohon grafis.
from sklearn.tree import DecisionTreeClassifier, plot_tree
dt_clf = DecisionTreeClassifier(max_depth = 3, min_samples_leaf = 2)
dt_clf.fit(X_train, y_train)
# Predict on the test data and evaluate the model
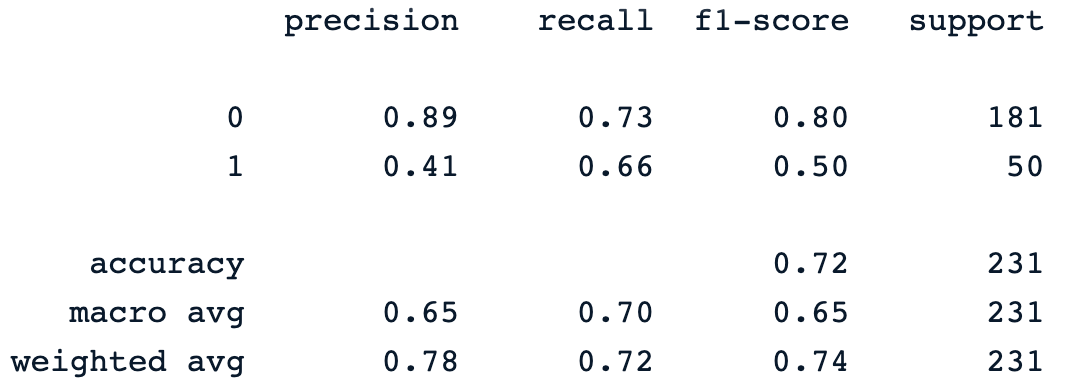
y_pred = dt_clf.predict(X_test)
print(classification_report(y_pred, y_test))Pernyataan print sebelumnya menghasilkan classification report model berikut.
Dan proses pengambilan keputusan model dapat divisualisasikan dari kode di bawah:
fig = plt.figure(figsize=(25,20))
_ = plot_tree(dt_clf,
feature_names = feature_names,
class_names = class_names,
filled=True)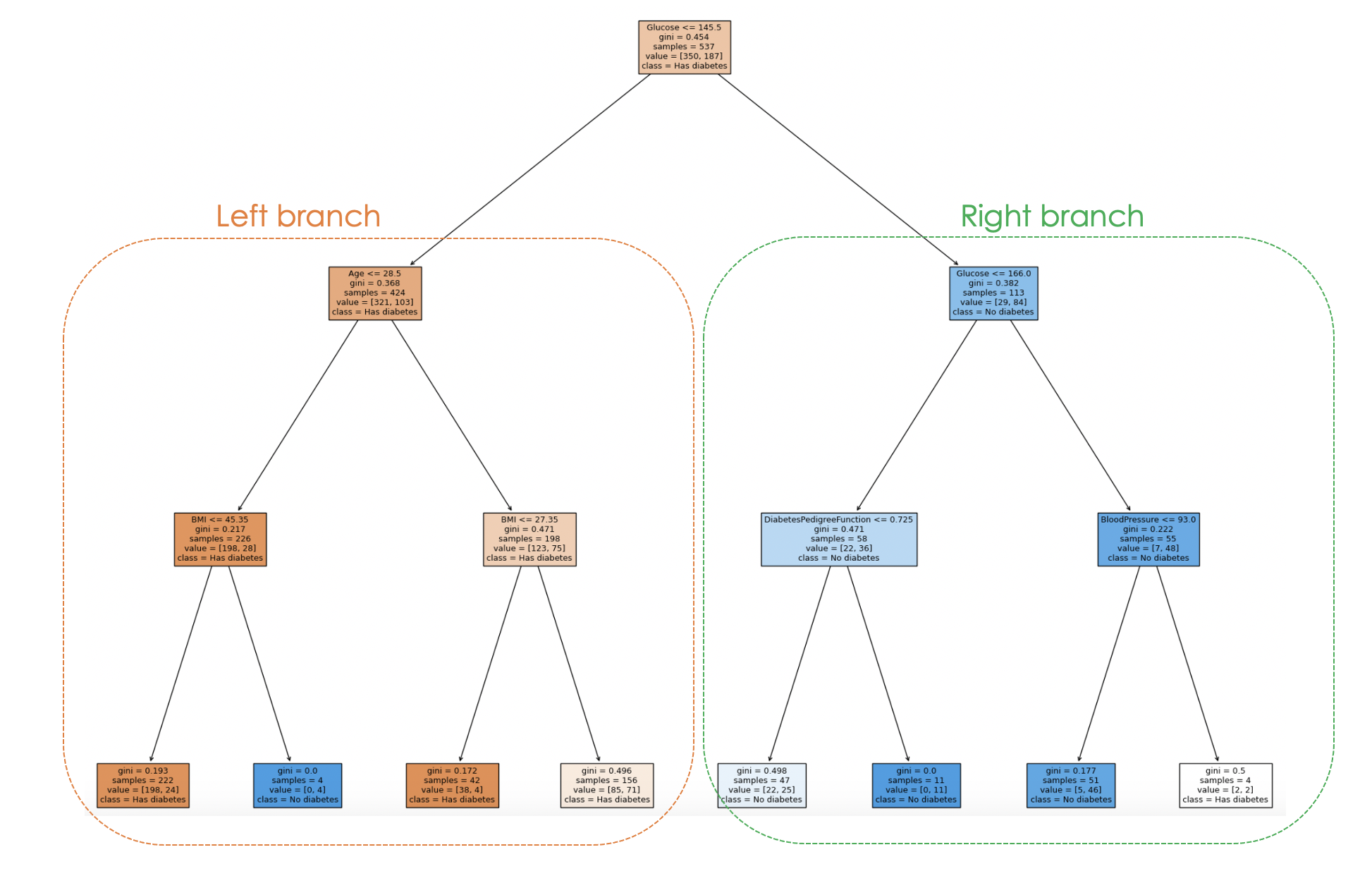
Dengan memeriksa struktur pohon, kita dapat menelusuri proses pengambilan keputusan untuk setiap sampel, memberikan wawasan tentang perilaku dan interpretabilitas model.
Pada plot di atas, setiap node merepresentasikan keputusan atau pemisahan berdasarkan nilai fitur tertentu. Untuk setiap node internal, plot menampilkan fitur yang digunakan untuk pemisahan, nilai kriteria pemisahan, ketidakmurnian Gini, dan jumlah sampel yang mencapai node tersebut.
Pada node daun, kelas mayoritas dan jumlah sampel ditampilkan. Selain itu, warna pada node merepresentasikan kelas mayoritas, dengan intensitas warna mengindikasikan proporsi kelas dominan dalam node tersebut. Misalnya, node berwarna oranye pada cabang kiri berkorelasi dengan label diabetes, sedangkan yang berwarna biru berkorelasi dengan tidak diabetes.
Seiring teknologi AI terus maju dan menjadi lebih canggih, memahami dan menafsirkan algoritma untuk mengetahui bagaimana mereka menghasilkan keluaran menjadi semakin menantang, mendorong peneliti untuk terus mengeksplorasi pendekatan baru dan menyempurnakan yang sudah ada.
Banyak model Explainable AI memerlukan penyederhanaan model dasar, yang dapat menyebabkan penurunan kinerja prediktif. Selain itu, metode keterjelasan saat ini mungkin tidak mencakup semua aspek proses pengambilan keputusan, yang dapat membatasi manfaat penjelasan, terutama saat menangani model yang lebih kompleks.
Metode penelitian baru berfokus pada peningkatan teknik Explainable AI dengan mengembangkan algoritma yang lebih efektif untuk mengatasi isu etika sekaligus menciptakan penjelasan yang ramah pengguna.
Akhirnya, dengan riset yang berkelanjutan, kemungkinan besar kita akan memiliki metode yang lebih canggih yang mendorong transparansi, keandalan, dan keadilan.
Artikel ini memberikan gambaran umum yang baik tentang apa itu Explainable AI serta beberapa prinsip yang berkontribusi pada pembangunan kepercayaan dan dapat membekali Data Scientist serta pemangku kepentingan lain dengan keterampilan yang relevan untuk membangun model tepercaya guna membantu pengambilan keputusan yang dapat ditindaklanjuti.
Kami juga membahas metode agnostik model dan khusus model dengan fokus khusus pada yang pertama menggunakan LIME dan SHAP. Selain itu, tantangan, keterbatasan, dan beberapa area penelitian telah disoroti terkait Explainable AI.
Untuk mempelajari lebih lanjut tentang etika di balik teknologi semacam ini, lihat kursus Pengantar Etika Data kami, yang membahas prinsip-prinsip etika data, hubungannya dengan etika AI, dan karakteristiknya di berbagai tahap siklus hidup data.
Pelajari lebih lanjut tentang AI!
Program
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
